



{kind=link}
{kind=link}
{kind=link}
{kind=link}
一种主动学习和协同训练相结合的半监督微博情感分类方法
[毕秋敏1 , 李明2  , 曾志勇
, 曾志勇3 ]
, 曾志勇|
|


作者贡献声明:
毕秋敏, 曾志勇: 提出研究思路, 设计研究方案;
毕秋敏, 李明: 进行实验;
李明: 采集、清洗和分析数据;
毕秋敏, 李明: 起草论文;
毕秋敏: 论文最终版本修订。
【目的】针对微博情感分类时未标注样本多和已标注集少的问题, 提出一种新的方法。【方法】在协同训练算法的基础上引入主动学习思想, 从低置信度样本中选取最有价值的、信息含量大的, 提交标注, 标注完后添加到训练集中, 重新训练分类器进行情感分类。【结果】使用不同的数据集进行实验, 实验结果表明该方法所构建的分类器性能优于其他方法, 分类准确率明显提高。特别是在已标注样本占40%的情况下, 提升5%左右。【局限】在协同训练过程中使用随机特征子空间生成方法不能保证每次构建的两个分类器都是强分类器, 因此未能充分地满足协同训练的假设条件。【结论】引入主动学习思想后, 能够解决协同训练对低置信度样本处理的不足, 进而增强分类器性能, 提高分类准确率。
[Objective] Aimed at less labeled data and more unlabeled samples in micro-blog sentiment classification, a novel method is proposed.[Methods] Active learning is introduced into co-training, the method selects the most valuable ones from low confidence samples, then labels and adds them into training dataset, trains classifiers again.[Results] Experimental results show that classifiers have better performance in this way, and the accuracy is improved obviously. Especially when labeled data reaches 40%, the accuracy increases by about 5%.[Limitations] In the collaborative process, random feature subspace generation can not build two strong classifiers, so hypothesis are not fulfilled.[Conclusions] This method solves the defects of co-training after introducing active learning; the performance and accuracy of classifiers are enhanced.
随着互联网的快速发展, 微博的出现不断地改变着人们的生活方式。由于其强大的影响力和渗透力, 越来越多的人喜欢通过微博发表自己的观点和看法。随着微博用户的不断增加, 网络上微博数量也越来越多。这些海量文本信息带有明显的情感色彩, 具有很高的价值, 对其进行情感分析研究, 能够对企业、政府、个人等决策提供有效帮助。
情感分类是情感分析中一项重要的研究任务, 主要是根据作者所表达的观点和态度对文本进行分类。基于全监督的情感分类是目前主流的方法, 它在分类准确性方面可能比无监督方法有一定的优势, 但却需要大规模标注语料作为训练集。在实际应用中, 能够很容易通过一些方法从网上获得大量微博, 但由于这些数据都未标注, 因此需要消耗巨大的人力和时间来完成这一过程。如果仅使用少量已标注数据作为训练集, 获得的分类器往往难以具有强泛化能力。针对该问题, 本文提出了一种基于主动学习和协同训练的半监督微博情感分类方法。
目前文本情感分类方法大致分为三类: 全监督分类、无监督分类和半监督分类。
(1) 全监督分类。主要采用机器学习的方法, 首先对大规模语料进行标注, 利用标注后的语料训练分类器, 然后对测试集分类。Pang等[1]最早使用机器学习方法对整篇文本进行情感分类, 并选取电影评论作为语料, 分别用支持向量机、最大熵和朴素贝叶斯三种方法进行实验。
(2) 无监督分类。该类方法依靠情感词典、语料库等一些先验知识, 获取文本的情感极性。Turney[2]选取Excellent和Poor两个情感词作为种子词, 采用SO-PMI方法计算评价词的情感倾向性, 进而通过加权求和得到整个文本的极性。徐群岭[3]在 SO-PMI 方法基础上提出一种新的词语倾向性计算模型, 并将其应用于中文文本情感分类。朱嫣岚等[4]结合HowNet中语义相似度和语义相关场的概念, 计算中文词汇的感情倾向。Hu等[5]利用 WordNet中的同义词和反义词, 得到词语的倾向性, 最后由句子中情感词的极性来判断该句子的感情倾向。无监督方法无需标注语料, 但分类准确率相对较低。
(3) 半监督分类。这是近年来提出的一种新方法, 它可以使用少量标注样本进行情感分类。Wan[6]基于人工标注的英文语料与未标注的中文语料, 采用基于协同训练的半监督分类方法对中文文本进行情感分类。Li等[7]通过构造 Personal与Impersonal两个视图进行协同学习。代大明等[8]首先利用情绪词自动标注样本, 然后选取一些正确率高的作为训练集, 训练分类器用于情感分类。
微博情感分类是目前研究的热点之一, 国内外很多学者都从事相关的研究工作。Go等[9]将表情符号作为标签自动标注Tweets, 并提出利用距离监督的方法对Tweets进行情感分类。Pak等[10]实现了英文微博语料的自动标注, 并使用自动标注的语料进行情感分析与意见挖掘研究。由于中文微博较复杂, 不同于Twitter, 庞磊等[11]将情绪表情和情绪词共同作为情绪知识, 结合一些规则, 实现了中文微博文本自动标注, 且自动标注的正确率达到80%以上。
为了减少数据标注的工作量, 减小标注成本, 本文采用基于协同训练的半监督方法, 利用少量标注的语料来实现微博情感分类。不同于以往的工作, 本文在协同训练框架的基础上引入主动学习思想, 解决了协同过程中对低置信度样本未充分利用的不足, 同时也减少了噪音的干扰, 增强了分类器的性能, 提高了分类的准确率。
协同训练是一种比较常用的半监督学习方法, 它最初由是Blum等[12]在20世纪90年代提出的。他们假定对于给定的标注样本集存在两个充分冗余的视图, 即符合下列条件的两个属性集: 每一个属性集都能够很好地描述该问题, 也就是说如果训练集比较充足, 在每个属性集上都能够训练出一个强分类器; 两个属性集彼此之间条件独立。基本思路为: 在两个视图上基于已标注样本构建两个分类器, 然后分别对未标注样本标注, 且从中选取一些置信度高的添加到已标注样本集中, 将更新后的已标注集作为训练集, 重新训练分类器, 重复这一过程直至满足条件时结束。
协同训练算法的过程描述如下所示:
输入: 已标注样本集L; 未标注样本集U; 数据集U'(初始为空)
输出: 已标注样本集L
过程:
(1) 从未标注样本集U中随机选择K个样本放入U'中
(2) 循环迭代N次直至满足条件
①使用视图1对应的数据集训练分类器C1
②使用视图2对应的数据集训练分类器C2
③利用分类器C1对U'进行标注, 并从中选择置信度高的P个正例和N个负例, 构成数据集L1
④利用分类器C2对U'进行标注, 并从中选择置信度高的P个正例和N 个负例, 构成数据集L2
⑤将L1UL2添加到已标注集L中, 并将其从U中删除, 同时重新从U中随机选取L1UL2个更新U'
从3.1节可知, 在每次迭代过程中, 协同训练方法都是选择当前分类器下置信度高的未标注样本添加到已标注集(训练集)中, 而对于低置信度样本则不作处理。这种策略虽然降低了引入错误标注样本的概率, 但随着迭代次数的增加, 引入的噪音会不断累积, 导致错误标注样本的概率变大, 将更多不正确的样本添加到训练集中, 最终造成分类器性能下降。
此外, 与低置信度样本相比, 高置信度样本所包含的信息量比较少, 对提高分类器性能的影响也较小。因为如果一个未标注样本获得的分类置信度很高, 说明在训练集中类似样本比较多, 分类器已经对该类特征进行了充分学习, 所以即使再添加, 也不能有效地提高分类器性能。而低置信度样本由于包含现有分类模型所不具备的信息, 因此所含有的信息量更大, 对分类器更有价值。对于这些低置信度样本, 如果能够准确地获取其类别, 然后添加到训练集中, 则可以大幅度提升分类器性能。
主动学习是Lewis等[13]在1994年提出的, 与被动接收训练数据的学习方法不同, 它主动地选取对于当前分类模型最有价值的、富含信息量大的未标注样例交由“ 神谕” (Oracle), 通过查询获得类别标记, 然后添加到训练集中, 重新构建分类器, 从而实现在少量标注语料下构造好的分类器, 提高分类准确率。
主动学习这一思想正好可以弥补协同训练算法未充分利用低置信度样本的不足。因此本文在协同训练基础上引入主动学习的思想, 每次根据主动学习策略从当前分类器下剩余的低置信度样本中选择最有价值的、富含信息量大的样例, 交由人工标注, 然后添加到训练集中, 利用这些新增样本来提升原有分类器的性能。
由于不同的未标注样本对分类器性能所带来的影响不同, 因此样本的选择很重要。根据协同训练算法的特点, 本文主要利用以下两种策略选择应主动交由人工标注的样例。
(1) 委员会选择学习策略
委员会选择策略[14]是一种有效的主动学习策略, 它根据委员会对未标注样本投票的分歧度来衡量样本所含的信息量。分歧度越大, 样本所含信息越多越丰富。
由于协同训练方法使用两个分类器, 如果这两个分类器之间的差异比较大, 就可以将两个分类器组成一个“ 委员会” , 计算剩余低置信度样本的分歧度, 根据分歧度排序, 选择分歧最大的M个样本交由人工标注。在实际获取的语料中, 类似的样例很多。比如, 一些既含有正面情感词又含有负面情感词的评论文本。分歧度利用相对熵[15]度量, 如公式(1)所示:
 |
其中, m为委员会成员的个数, 

 |




 |
相对熵D(di)越大, 说明一个成员n对样本di所属类别的判定与其他成员相比差异较大, 

委员会中各成员之间差异性越大, 组建的委员会越好。为了确保协同训练的两子分类器之间差异足够大, 本文使用不同的分类模型构造, 并在每次迭代过程中利用随机特征子空间生成的方法将整个特征集划分为数量相等的两个子集, 用于生成两个充分冗余的视图。
(2) 不确定策略
不确定策略[13]主要根据当前分类器对未标注样本所属类别的不确定程度进行挑选。通常在分类时, 如果分类器越是无法确定样本的类别, 说明样本对提高分类器性能贡献越大。因此根据这种策略分别从中选取协同训练的两个子分类器最不确定的未标注样本, 交由人工标注。样本的不确定性利用后验概率来计算, 具体的计算如公式(4)所示:
 |
其中, 
此外, 这一过程中为了避免对不确定性较低的样本标注, 以减少人工标注的工作量。笔者预先设置一个阈值, 选择不确定性最大且高于阈值的K个样本。
基于主动学习和协同训练的半监督情感分类方法, 主要是利用随机特征子空间生成方法将整个特征空间划分成两个数量相等的特征子空间, 进而使用两个子空间构造两个子分类器, 然后利用它们对未标注语料进行标注, 并且分别从中选择一些高置信度的样本, 添加到已标注集。同时在协同训练算法的每一次循环迭代过程中, 使用不确定性策略和委员会投票策略, 选择两个子分类器判别结果分歧最大的n个未标注样本, 以及不确定性最大的且高于预定阈值的m个未标注样本, 交由人工标注, 标注完成后添加到已标注集中, 并更新训练集, 重新训练分类器。不断重复这一过程, 直到满足给定的条件结束。最后将最终得到的已标注集作为训练集, 构建分类器, 用于情感分类。算法的过程描述如下所示:
输入: 已标注样本集L; 未标注样本集U; 数据集U1、U2和A(初始均为空); 阈值e
输出: 已标注样本集合L
过程:
(1) 从未标注样本集U中随机选择k个样本放入U1、U2中
(2) 迭代N次直到满足条件
①基于随机特征子空间生成的方法将已标注样本集L的整个特征集F, 划分为两个数量相同的特征子集F1和F2
②基于特征子集F1使用分类模型M1生成分类器C1
③基于特征子集F2使用分类模型M2生成分类器C2
④利用分类器C1对U1中的未标注样本进行标注, 并从中选择置信度高的N个(正例和负例), 添加到数据集L1
⑤利用分类器C2对U2中的未标注样本进行标注, 并从中选择置信度高的N个(正例和负例), 添加到数据集L2
⑥调用主动学习策略1
⑦根据两个分类器的分类结果, 计算剩余未标注样本的分歧度, 从中选择分歧度最高的n个选择交由人工标注, 标注完以后存放在数据集A中
⑧调用主学习策略2
⑨计算数据集U1、U2中剩余未标注样本的不确定性, 并根据不确定程度进行排序, 选择不确定性最大且高于阈值e的m个样本交由人工标注, 标注完以后存放在数据集A中
⑩将 

(3) 使用最终的标注集L构建分类器, 进行情感分类
实验使用爬虫工具DataScraper[16]从网上收集了关于《谍影重重4》、《飓风营救2》、《人再囧途之泰囧》三部电影的微博评论。为了获取干净的语料, 首先对数据进行清洗, 去除广告性微博和重复性微博, 以及微博评论中的链接信息、@信息、问句等。清洗完之后, 由两名人员标注, 剔除感情倾向不明显以及标注结果不一致的评论, 分别从这三个语料中随机抽取3 000篇作为实验的训练集, 500篇作为测试集。然后按照已标注样本集占20%、40%、60%、80%的比例将训练集随机划分为已标注样本集L和未标注样本集U两部分。
在实验过程中, 采用中国科学院计算技术研究所分词软件ICTCLAS[17]实现分词, 选取最大熵和朴素贝叶斯两种方法来构造分类器, 两者都是基于Mallet[18]机器学习工具包实现的, 在使用过程中所有参数均设为默认值。选取Unigram 和 Bigram 作为特征, 利用信息增益(IG)特征选择方法, 特征权重用布尔值表示, 最终根据置信度将微博电影评论分为正面和负面两类, 置信度的大小由样本属于每个类别的后验概率决定, 选取常用的准确率作为评测指标。
实验选取协同训练方法(Co-training)[12]、自学习方法(Self-training)[19]和基于不确定的协同训练方法(Uncertain-Co-training)作为基准方法与本文提出的方法(Active-Co-training)进行对比。Uncertain-Co-training方法主要是将协同训练方法和不确定性策略相结合, 在每次循环迭代过程中, 分别从各自的未标注集中选择最不确定的T个, 交由人工标注, 然后加入到训练集中。
为了防止因每次选取的未标注样本过多, 导致迭代过程快速结束, 失去协作学习的效果, 在实验过程中, k值为400, N值为15, 阈值e为0.4, m值为4, n值为1, T值为10。图1-图3分别是利用《谍影重重4》、《飓风营救2》、《人再囧途之泰囧》三部电影的微博评论数据在不同比例的已标注样本集下分别使用4种方法进行分类的效果。
 | 图1 《谍影重重4》的分类效果 |
 | 图2 《飓风营救2》的分类效果 |
 | 图3 《人再囧途之泰囧》的分类效果 |
从图1-图3可以看出, 使用不同的电影评论语料在4种不同比例的已标注样本集下, Active-Co-training 方法的分类效果都优于其他三种方法。这也说明了本文提出的方法在协同训练过程中能够有效地利用未标注样本提升分类器性能。Co-training方法由于利用两个分类器协作, 彼此之间可以相互学习, 分类效果要好于Self-training方法。随着已标注样本集所占比例越来越大, Active-Co-training和Uncertain-Co-training两个方法之间差异也越来越小。特别是《人再囧途之泰囧》的已标注样本集占80%的情况下, 两种方法的分类准确率非常相近。
4种方法在已标注样本集占20%的情况下, 利用《人再囧途之泰囧》的微博评论进行实验, 每一次迭代后分类准确率的变化情况如图4所示:
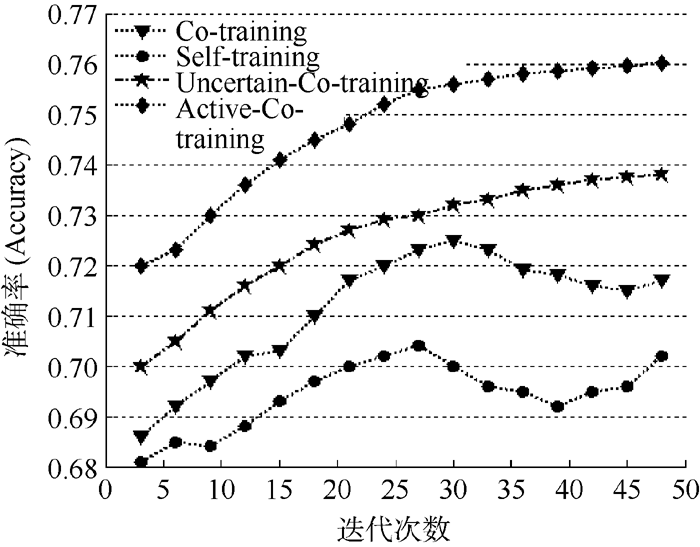 | 图4 在已标注集占20%时4种方法每次迭代过程中的分类效果 |
从图4可以看出, Active-Co-training方法在整个迭代过程中, 分类准确率都高于其他三种方法。Co-training方法和Self-training方法在迭代次数增加到一定程度后, 出现了准确率下降的情况。原因在于每次循环过程中, 两种方法都选择将置信度高的未标注样本添加到训练集中, 随着迭代次数的增加, 引入的噪音也越来越多, 使分类器错误分类的概率增大, 弱化了分类器的性能, 导致分类准确率下降。而Active- Co-training方法和Uncertain-Co-training方法则由于引入主动学习策略, 将那些分类器未能很好识别的未标注样本交由人工标注, 减少了噪音, 避免学习过多错误标注的样本。Uncertain-Co-training方法的效果之所以没有Active-Co-training方法好, 是因为每次迭代过程中该方法选取的样本并不是特别具有代表性, 改善分类器性能的作用没有本文方法明显。此外, 由于Uncertain-Co-training方法每次只是选择不确定性高的未标注样本, 而没有对不确定程度进行限制, 在迭代后期可能会将一些不确定性低的样本提交标注, 增加了人工标注的负担。
本文通过将协同训练和主动学习相结合, 避免协同过程中引入过多错误标注的样本, 进而实现利用少量标注样本构建高性能分类器进行情感分类的目的。实验结果表明本文提出的方法比其他方法在分类准确率上有明显提高。微博情感分类目前是自然语言处理中的一个热点问题, 还有许多问题需要更深入的研究。比如, 由于微博情感分类方法同样具有领域依赖性, 可能会导致使用不同领域的语料进行实验时, 产生不同的效果, 特别是在电影领域中。因此以后会对电影评论领域中的半监督情感分类问题做进一步研究。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|