{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于粗糙用户聚类的协同过滤推荐模型
[王晓耘, 钱璐 , 黄时友]
, 黄时友]
, 黄时友]
|
|


作者贡献声明:
王晓耘, 钱璐: 提出研究思路, 设计研究方案;
黄时友: 采集和分析数据, 进行实验;
钱璐: 论文起草;
王晓耘: 论文最终版本修订。
【目的】将粗糙集引入到基于用户聚类的协同过滤中, 提高推荐质量。【方法】提出一种基于粗糙用户聚类的协同过滤推荐模型: 离线时采用粗糙K-means用户聚类算法, 根据用户与聚类中心的相似度将其分配到K个类的上、下近似中, 形成用户的初始近邻集; 在线时从目标用户的初始近邻集中搜索其最近邻, 预测项目评分并向其产生推荐。【结果】通过实验对比发现,该模型比传统的和基于项目的协同过滤推荐算法降低约14%的平均绝对误差, 比基于用户聚类的协同过滤推荐算法降低约10%的平均误差。【局限】在考虑上、下近似对聚类中心调整的重要程度时, 忽略了用户聚类数目和最近邻集用户数阈值的变化所产生的影响。【结论】该模型能有效提高推荐精度, 具有较强的可行性和现实意义。
[Objective] In order to improve the quality of recommendation, rough set is introduced into collaborative filtering based on user clustering.[Methods] This paper proposes a collaborative filtering recommendation model based on rough user clustering. When off-line, it clusters all users by rough K-means user clustering algorithm, which assigns user to upper or lower approximation based on similarity and thus generates his initial neighbor. When on-line, the model starts searching the nearest neighbor from the target user’s initial neighbor, forecasts his ratings and makes recommendation.[Results] Experimental results show that the proposed model decreases the Mean Absolute Error (MAE) about 14% when compared with traditional and item-based collaborative filtering, and decreases MAE about 10% when compared with collaborative filtering based on user clustering.[Limitations] When considering the importance of upper and lower approximation to adjusting the centroid of cluster, this paper ignores the impact of the number of user clusters and the threshold of the number of nearest neighbors.[Conclusions] This model can effectively improve recommendation accuracy, and has high feasibility and practical significance.
面对互联网上大量的商品信息, 用户(消费者)往往难以快捷地获取自己最感兴趣的商品, 他们很希望电子商务系统具有一种类似采购助手的功能来帮助其选购商品, 将其最可能感兴趣的商品推荐出来[1]。在这种背景和需求下, 推荐系统应运而生, 其中协同过滤推荐是目前研究最多且应用最为成功的一种[2, 3]。协同过滤通常分为基于用户(User-Based)和基于项目(Item- Based)的协同过滤两种, 前者通过计算用户之间的相似度, 利用与目标用户相似度较高的邻居对其他产品的评价来预测目标用户对特定产品的喜好程度, 据此对其进行推荐[4]。它是基于这样一个假设, 即如果用户对一些项目的评分比较相似, 则他们对其他项目的评分也比较相似。然而随着用户和项目数量的急剧增加, 传统的协同过滤面临着一些严峻的问题, 比如数据稀疏性[5]、算法的可扩展性[6]、冷启动[7]和推荐的实时性(推荐速度)[8]等。这些问题直接或间接导致了推荐精度降低, 推荐质量急剧下降。
针对这些问题, 研究者提出了许多改进方法。其中, 聚类技术经常与协同过滤组合在一起[9, 10]。基于用户聚类的协同过滤推荐算法[11]利用用户对项目评分的相似性对用户进行聚类, 相似度较大的用户处于同一用户聚类中。当目标用户出现时, 在其所处的用户聚类中搜索最近邻, 大大降低了搜索空间, 提高了推荐速度和算法的可扩展性, 并在一定程度上缓解了稀疏性问题[12]。因此该算法得到了广泛的运用, 但仍存在两个问题: 处于聚类边缘的用户与聚类中心的相似度较低, 算法对该用户的推荐精度会比较低[13]; 该算法中用户只存在于一个固定的用户聚类中, 不符合现实中消费者往往属于多个消费群体的现象, 即该算法不能体现用户的多兴趣性, 严重影响推荐精度。目前, 研究者通常采用处理不确定性问题的方法来解决, 不确定聚类[14]是考虑样本归属关系的不确定性而提出来的一类有效的聚类算法。将其运用于基于用户聚类的协同过滤中, 不是简单地用“ 属于” 或“ 不属于” 来表示用户的归属关系, 而是通过用户归属关系的不确定性表达将用户划分到多个类中, 以解决上述不足, 提高推荐精度。
不确定聚类被广泛地运用于数据挖掘、机器学习、专家系统等领域中, 其典型代表有模糊聚类和粗糙聚类。Ruspini[15]最早提出了模糊聚类的概念, 使用隶属度来描述数据对象隶属各个簇的不确定性。粗糙集理论(Rough Set Theory)是由波兰学者Pawlak[16]在1982年提出的一种刻画不完整性和不确定性等问题的数学工具。Lingras等[17]首次将粗糙集引入到聚类问题中, 提出了粗糙聚类算法。在计算样本归属关系时通过引入上、下近似的思想, 通过将样本划分到一个簇的上近似或下近似中来描述该样本确定属于或可能属于这个簇, 以提高聚类边界的聚类精度。
许多研究学者尝试将不确定聚类引入推荐系统中。在模糊聚类方面, Verma等[18]提出一种模糊C-means聚类和协同过滤的混合推荐系统, 以解决稀疏性和可扩展性问题。Birtolo等[19]提出一种基于项目模糊聚类的协同过滤推荐算法, 实验证明有较高的推荐精度。李华等[20]提出一种基于用户情景模糊聚类的协同过滤推荐算法, 根据用户情景信息利用模糊聚类算法得到情景相似的用户群分类, 以改善数据稀疏性和实时性问题。王明佳等[21]利用模糊聚类的方法对项目进行聚类, 结果证明能有效提高冷启动问题下的相似度计算精度。在粗糙聚类方面, Saha等[22]提出一种粗糙聚类的方法来对用户交易(Transaction)数据进行聚类, 用以分析用户的交易行为并缓解稀疏问题。Tseng等[23]提出一种基于粗糙集和协同过滤的推荐算法RSCF, 在粗糙集的基础上综合协同信息和内容特征共同预测用户的偏好, 以解决传统协同过滤的不足。Chen等[24]为解决协同过滤推荐中的稀疏性问题, 运用粗糙集理论对目标用户未评分项目值进行预测填充, 再根据用户项目评分进行模糊用户聚类。杜金涛[25]提出一种基于粗糙集的协同推荐模型, 将粗糙集理论同时运用于用户聚类和项目值预测填充中, 取得较好的推荐效果。
基于国内外研究发现, 不确定聚类经常用于项目聚类中, 而对用户聚类的研究则相对较少。此外, 模糊聚类应用于推荐系统中的研究很多, 已经比较成熟; 而将粗糙聚类应用于推荐系统中的研究则相对较少, 处于起步阶段。粗糙聚类算法的思想认为是数据对象属性的多态性导致簇边界的不确定性, 本文认为这与用户多兴趣性的描述非常相似, 比模糊聚类更适合应用于用户聚类。因此, 本文将粗糙聚类引入到基于用户聚类的协同过滤中, 拟从以下方面解决协同过滤中用户聚类存在的不足:
(1) 采用用户与聚类中心相似度的绝对差来体现相似度之间的差异性, 从而作为判断用户归属关系的依据。而传统的粗糙聚类算法和文献[25]提出的算法均使用欧式距离作为用户归属的评判标准, 聚类结果很大程度上受到孤立点的影响[26], 并且没有考虑相似度之间的差异性, 不能很好应用于协同过滤推荐中。
(2) 提出一种粗糙K-means用户聚类算法, 将相似度差异较大(即归属关系明确)的用户划分到该类的下近似中, 将相似度差异较小(即归属关系不明确)的用户划分到该类的上近似中, 避免了用户处于类边缘的情况。此外, 处于上近似的用户往往属于多个类, 以此来体现用户的多兴趣性。
(3) 将模型设计为离线和在线两个部分。离线时判断用户归属关系, 形成初始近邻集; 在线时在用户所在类的上、下近似中搜索其最近邻, 能够有效缩短搜索的空间和时间, 提高推荐速度。
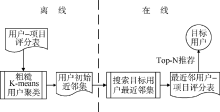
针对基于用户聚类的协同过滤的不足, 本文引入粗糙集, 提出一种基于粗糙K-means用户聚类的协同过滤推荐模型, 该模型由离线和在线两个部分组成: 离线时, 依据修正的余弦相似性方法计算用户与聚类中心之间的相似度, 采用粗糙K-means用户聚类算法根据相似度对用户进行粗糙聚类, 将所有用户分配到K个用户聚类的上近似和下近似中, 形成用户的初始近邻集; 在线时, 在目标用户的初始近邻集中搜索其最近邻, 预测目标用户的项目评分并产生Top-N推荐。整个推荐模型如图1所示:
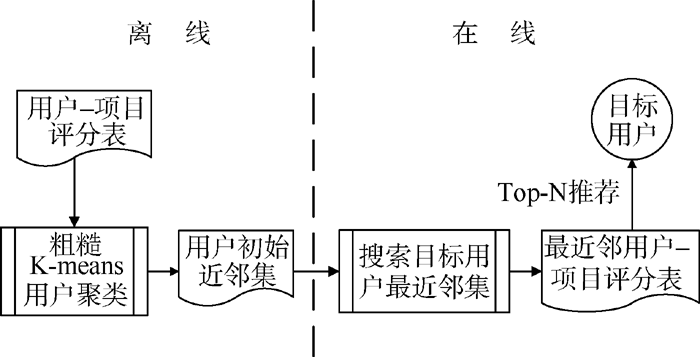 | 图1 粗糙K-means用户聚类的协同过滤推荐模型 |
(1) 粗糙聚类算法
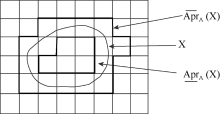
粗糙聚类算法与一般聚类算法的区别在于计算样本归属关系时引入上、下近似的思想, 根据用户与聚类中心之间的相似度, 将确定属于某一类的样本归属到其相应的下近似中, 将不确定属于该类的样本归属到其相应的上近似中。其次, 更新的聚类中心由下近似集合中样本的算术平均与上近似集合中样本的算术平均线性加权而得。Pawlak[16]给出粗糙集理论中上、下近似的示意图(见图2), Lingras等[17]给出三个粗糙聚类性质, 均有助于对该算法的理解:
性质1: 一个对象只能属于一个簇的下近似;
性质2: 一个对象如果属于一个簇的下近似, 那么它也属于这个簇的上近似;
性质3: 如果一个对象不属于任何簇的下近似, 那么它至少属于两个簇的上近似。
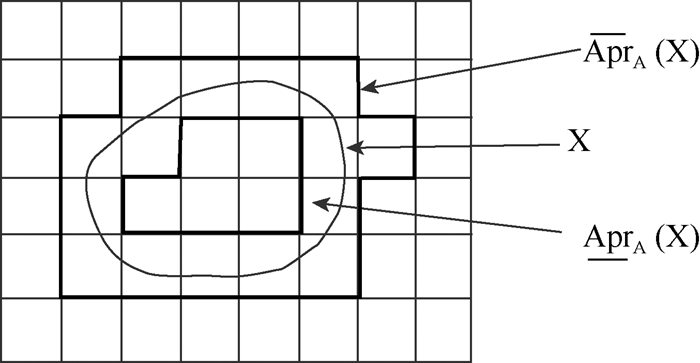 | 图2 粗糙集上、下近似[16] |
(2) 粗糙用户聚类算法
本文将粗糙K-means算法引入基于用户聚类的协同过滤中, 提出一种粗糙K-means用户聚类算法。该算法根据用户与聚类中心之间的相似度对其进行粗糙聚类, 将用户分配到K个用户聚类的上近似和下近似中, 这样就允许类之间有重叠的现象, 以此体现用户的多兴趣性, 并同时避免了用户处于类边缘的情况。
在该算法中, 用户相似度的计算是算法成功实施的关键因素之一。文献[27]罗列了5种经常用于协同过滤中衡量用户相似度的方法: 皮尔森相关性(COR)、余弦相似性(COS)、修正的余弦相似性(ACOS)[28]、限制的皮尔森相关性(CPC)和史匹曼等级相关性(SRC)。本文对这5种方法进行对比发现, ACOS比起COR、CPC这些受到用户共同评分项目数量限制的方法, 更适用于数据稀疏的情况; 并且ACOS通过减去用户的平均评分来考虑不同用户的评分尺度问题, 比COS更具有相关性, 因此可以直接用相似度的绝对差来体现相似度之间的差异, 非常适合用于粗糙用户聚类中作为判断用户归属关系的依据— — 相似度差异较大即归属关系明确, 相似度差异较小即归属关系不明确。因此本文在粗糙K-means用户聚类算法中采用修正的余弦相似性来计算相似度。
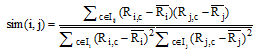 |
其中, Ri, c表示用户i对项目c的评分, 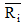
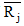
粗糙K-means用户聚类算法的具体步骤如下:
输入: 用户-项目评分矩阵, 用户聚类数目K, 上、下近似集的阈值threshold, 聚类中心调整参数w1和wu。
输出: K个由上、下近似集组成的用户聚类, 每个用户所在的类标号。
步骤:
①随机挑选K个用户在n维项目空间上的评分向量c1, c2, L , cK作为初始聚类中心。
②计算用户与聚类中心的相似度
设u为待聚类用户, 采用公式(1)计算u分别与K个聚类中心的相似度, sim(u, ci)表示用户u与聚类中心ci的最大相似度, 即 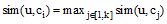
③计算用户归属关系
相似度之间的差异可以用相似度的绝对差来表示。给定上、下近似集的阈值threshold, 对于集合 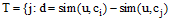
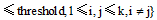
规则1: 若 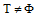
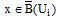
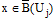
规则2: 若 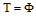
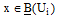
④调整聚类中心
聚类中心的调整依赖于上、下近似中的用户, 通过确定属于该类的用户向量和可能属于该类的用户向量的算术平均加权组合来得到。具体计算公式[17]如下。
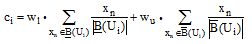 |
其中, 参数w1和wu定义了上、下近似对用户聚类的重要程度, w1+wu=1。 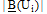
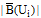
⑤重复步骤 ②-步骤④, 直至准则函数 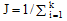
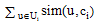
该离线算法依据用户与聚类中心之间的相似度完成对所有用户的粗糙聚类, 形成用户的初始近邻集, 且每个近邻集由上近似集和下近似集组成。
当目标用户在线时, 可以通过以下搜索算法从目标用户的初始近邻集中搜索出其最近邻集。
输入: 目标用户, 用户的初始近邻集, 最近邻集用户数阈值Nu。
输出: 目标用户的最近邻集。
步骤(分两种情况):
(1)目标用户属于用户聚类的下近似
①设N为最近邻集用户数。将目标用户所属的下近似集作为其最近邻集。判断 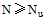
②将目标用户所属的上近似集作为其最近邻集。判断
③统计目标用户所属上近似集中所有用户的类标号, 将出现频数最高的类中用户加入到目标用户的最近邻集。判断
④将出现频数次高的类中用户加入到目标用户的最近邻集。以此类推, 直至
(2)目标用户属于至少两个以上用户聚类的上近似
①设N为最近邻集用户数。将目标用户所属的上近似集合并, 作为其最近邻集。判断
②依照情况(1)步骤②和步骤④中的方法进行最近邻集的用户扩充, 直至
通过以上两种情况的搜索算法, 可以输出目标用户的最近邻集。然后依据最近邻用户-项目评分表, 采用平均加权策略来预测目标用户的项目评分, 并最终产生Top-N推荐。根据文献[4]给出的协同过滤算法框架, 用户v为目标用户u的最近邻, 则u对未评分项目i的预测值为:
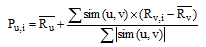 |
为测试本文提出的基于粗糙用户聚类的协同过滤推荐模型的性能, 实验平台选用PC机, 配置为Intel(R) Core(TM)2 Duo CPU T7250 @2.00GHz、DDRII 2GB的内存, 操作系统为Windows XP, 算法均在Matlab R2009a中实现。
采用MovieLens站点所提供的测试数据集[29], 该站点由美国明尼苏达大学GroupLens研究项目组创建, 根据用户对电影的评分向其提供电影推荐列表, 被广泛应用于个性化推荐研究中。从GroupLens下载的数据包中含有943个用户对1 682部电影的100 000条评分记录, 并被分为5个互不相交的子数据集, 其中4个合为Base集, 另一个作为Test集。选取前150名用户及其相应的项目评分进行实验, 实验数据情况统计如表1所示, 数据稀疏等级达到92.31%, 极其稀疏。
| 表1 实验数据统计 |
采用常用的一种评价推荐系统推荐质量的度量方法— — 平均绝对偏差(Mean Absolute Error, MAE)作为度量标准[30, 31], 计算预测的用户评分与实际用户评分之间的偏差, MAE值越小, 推荐精度越高。假设预测的用户评分集合为 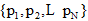
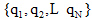
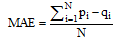 |
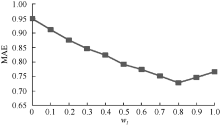
(1) 由于参数w1和u在更新聚类中心时定义了上、下近似对用户聚类的重要程度, 所以该取值会对推荐精度产生很大的影响。实验1设计w1的取值从0到1.0, 每次增加0.1(即wu的取值从1.0到0, 每次减少0.1), 观察MAE值的变化。由于该实验主要用于测试参数w1和wu对MAE值的影响, 因此需要控制以下变量: 用户聚类数目K取值7, 最近邻集用户数阈值Nu取值20, 上、下近似集阈值threshold为经验值, 固定为0.05。实验结果如图3所示, 可以明显看出当w1=0.8, wu=0.2时推荐效果最好。即下近似中的用户比上近似中的用户在计算聚类中心时有更大的影响作用, 与现实情况也相符。
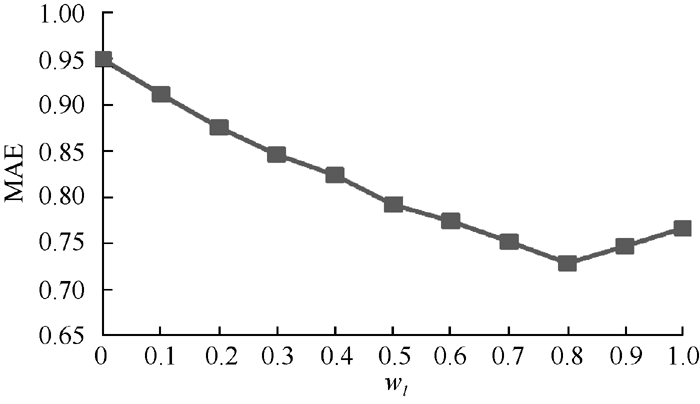 | 图3 参数w1和wu对MAE值的影响 |
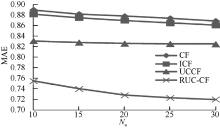
(2) 为了验证本文提出的基于粗糙用户聚类的协同过滤(Collaborative Filtering Based on Rough User Clustering, RUC-CF)的有效性, 笔者进行了实验对比。参与对比试验的算法有: 传统的协同过滤算法 (Traditional Collaborative Filtering, CF)[32]、Sarwar等[28]提出的基于项目的协同过滤算法(Item-based Collaborative Filtering, ICF)、李涛等[11]提出的基于多层相似性用户聚类的协同过滤算法(Clustering Basal Users Based Collaborative Filtering, UCCF)。实验中, 最近邻集用户数阈值Nu从10变化到30, 间隔为5。其他参数设置如表2所示:
| 表2 实验2参数设置 |
实验结果如图4所示, 可以看出RUC-CF的平均绝对误差值低于CF、ICF等对比算法14%左右, 低于UCCF对比算法10%左右, 说明本文提出的基于粗糙用户聚类的协同过滤推荐模型的推荐质量要优于其他对比算法, 能有效提高推荐精度。
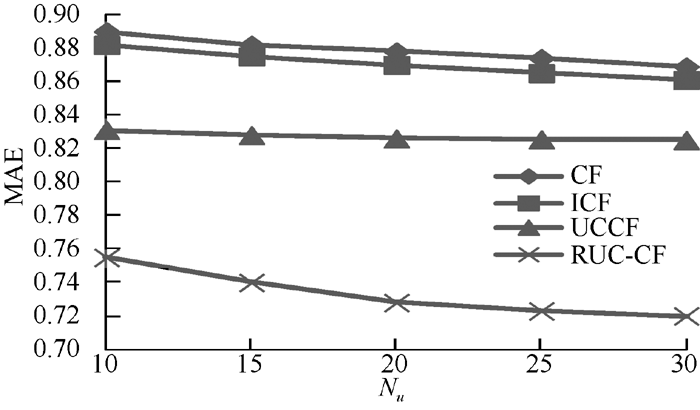 | 图4 RUC-CF与对比算法的MAE值比较 |
本文提出了基于粗糙K-means用户聚类的协同过滤推荐模型, 粗糙集的引入不仅解决了用户的多兴趣性问题, 同时避免了用户处于聚类边缘的情况。在计算相似度时, 采用修正的余弦相似度的绝对差进行用户归属关系的判断, 比传统粗糙聚类中基于欧式距离的相似度计算更适用于协同过滤。此外, 该模型离线和在线两部分的设计缩小了在线时目标用户最近邻的搜索空间和时间, 能够有效提高推荐速度。最后通过实验证明了该模型能有效提高推荐精度, 具有较高的可行性和现实意义。
本文的不足之处在于:
(1) 在粗糙K-means用户聚类算法中, 随机挑选K个用户的评分向量作为初始聚类中心, 没有考虑不同初始聚类中心的选择对聚类结果造成的影响;
(2) 在实验中测试参数w1和wu对MAE值的影响时, 将用户聚类数目K与最近邻集用户数阈值Nu作为定量, 没有验证和考虑该值的变化是否会对实验结果产生影响。
协同过滤推荐是重点研究和应用领域, 随着用户需求水平的不断提高, 推荐算法的研究在不断地发展与完善。下一步的研究重点除了解决以上两个不足之外, 还应确定该模型的应用范围。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|