
{kind=link}
{kind=link}
一种基于维基百科的多策略词义消歧方法
[任海英, 于立婷 ]
]
]
|
|


目的 提出一种基于维基百科的多策略词义消歧方法, 充分利用维基百科中的潜在知识进行消歧。方法 设计类别一致性、内容相关性以及词义重要程度三个指标, 并通过动态熵权线性融合各指标值以及二次消歧的方法来确定歧义词在特定语境的最佳词义。结果 通过实验, 该方法取得了74.82%的准确率, 可以验证其有效性。【局限】候选词义粒度较细, 且主要针对英文进行消歧, 对其他语言缺少一定的普适性。结论 维基百科为消歧提供更多的语义知识和背景信息, 能够提高消歧准确率。
[Objective] This paper proposes a multi-strategy method for Word Sense Disambiguation (WSD) based on Wikipedia which makes full use of the latent knowledge in Wikipedia. [Methods] Design three indicators including category commonness, content relatedness and the importance of the word sense, make an entropy-based dynamic linear fusion of these three indicators, combined with re-disambiguation to choose the best sense of an ambiguous term in its context. [Results] Experimental result shows an average precision of 74.82%, therefore validating the feasibility and effectiveness of this method. [Limitations] The proposed method mainly aims at WSD in English with a setting of fine grained candidate senses, lacking certain generality to other languages. [Conclusions] This method provides more semantic knowledge and background information based on Wikipedia which enhance the precision of disambiguation tasks.
词义消歧就是在给定上下文基础上为歧义词选择最佳词义[1]。自动或半自动的词义消歧是计算机自然语言处理领域研究的重要组成部分, 在信息检索、机器翻译、信息抽取等诸多方面都有着非常重要的应用。目前, 比较有代表性的消歧方法有数据驱动的方法[2]和基于知识的方法[3, 4]两大类。数据驱动的方法将消歧化为一个有监督的学习任务, 其准确性在很大程度上依赖于可获得的词义标注数据集。而基于知识的方法主要依靠从广泛的词汇语义资源中抽取的信息来进行消歧, 这种方法通常受限于有限的词汇和语义信息量, 但与数据驱动的方法相比能利用更为广泛的网络知识资源, 更具发展前景。
基于知识的方法的消歧效果取决于所获取的相关知识的丰富程度。维基百科作为一个可靠的知识源, 其类别体系和各种链接方式在文档内容之间建立了丰富的语义关系。与知网、WordNet等传统资源相比, 其覆盖范围更广、知识更全面、内容更新更快, 为消歧工作提供了更丰富的背景知识[5], 这使得维基百科成为词义消歧的有力的研究工具。Mihalcea[6]通过抽取维基百科文档页面中的锚文本信息建立起词义标注集, 之后通过有监督的方法进行消歧, 并且在Senseval-2和Senseval-3测试集中进行测试, 获得 84.65%的准确率; 然而这种有监督的消歧方法在一定程度上会受到标注集质量的限制。Fogarolli[7]通过维基百科链接结构进行无监督词义消歧并对其进行评估。史天艺等[8]计算了歧义词所在文档与各候选词义解释文档之间的相似度、歧义词与候选词义在上下文语境以及类别之间的重叠程度, 通过线性加权(也称为指标融合)来选取最佳词义。Dandala等[4]将维基百科作为词义注释来源, 并在4种语言上验证了基于维基百科的词义注释的有效性。Li等[9]提出一个通用的基于维基百科的词义消歧框架, 并指出一个特定的相关度消歧方法对不同语言歧义词的消歧具有一定的局限性。
上述研究将维基百科用于词义消歧, 验证了维基百科在词义消歧研究中的可行性和有用性, 但目前的研究或者限于有监督的方法, 或者仅利用维基百科链接信息或词的重叠程度进行消歧, 没有充分利用维基百科丰富的语义信息获取更多的消歧知识, 从而影响了消歧质量。此外, 在进行消歧指标融合时通常采用传统模糊综合评判法或样本学习法, 评价过程要么较为主观, 要么依赖于学习样本的质量, 其客观性、科学性与合理性不能全面满足。
在前人研究的基础上, 本文提出了一种基于维基百科的多策略词义消歧方法, 该方法包含类别一致性、内容相关性和词义重要程度三个消歧指标, 通过熵权对指标进行动态模糊综合评价, 并采用二次消歧的方法, 充分利用维基百科中的语义知识和背景信息, 满足了指标评价的客观性、科学性与合理性, 提高了消歧的准确率。
本文提出的消歧方法建立在维基百科知识库基础上, 该知识库是一个由页面所组成的超文本文档集合, 主要包含解释页面、重定向页面、超链接、消歧页面及类别等部分[5]。“ 概念” 是维基百科中最基本的组成单元, 指有具体解释页面的维基文章标题, 本文也将其称为“ 维基概念” , 每个维基概念都对应维基百科中的一个解释页面, 即文章[10]。本文将消歧任务定义为一个4元组Q=< T, D, S, W> , T为给定的文档, D(T)={d1, d2, …, dn}为T中的歧义词集合, S(d)={s1, s2, …, sm}是歧义词d的候选词义的集合, 该集合从维基百科的消歧页面提取, 每一个候选词义都是一个维基概念。W(T)={W1, W2, …, Wk}是文档T中所有无歧义词和歧义词各候选词义所对应的维基概念的集合, 因而有 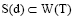
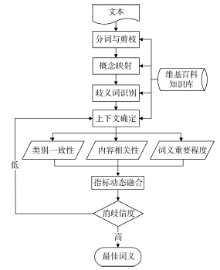
该方法重点设计了三个指标: 类别一致性(Category Commonness)、内容相关性(Content Relatedness)以及词义重要程度(Importance of the Word Sense), 通过二次消歧选取S(d)中歧义词d在文档T中的最佳词义s。笔者将此方法称为CCI2, 其流程如图1所示, 可以看出, CCI2消歧方法包括4大部分: 文档预处理、上下文确定、消除歧义以及二次消歧。
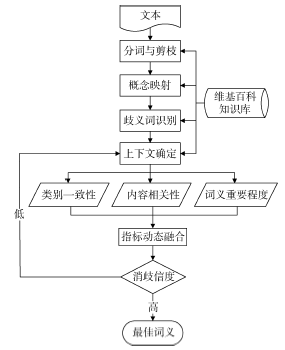 | 图1 基于维基百科的词义消歧方法流程图 |
对需要消岐的文档进行分词和剪枝。在分词阶段, 根据长度优先原则, 抽取文档中的所有关键词, 比如, 对于短语“ Word Sense Disambiguation” , 抽取关键词“ Word Sense Disambiguation” , 而不是两个关键词“ Word Sense” 和“ Disambiguation” 。同时, 去除其中的停用词、无意义频繁词等噪音信息; 将这些抽取的关键词映射到维基概念; 根据映射的结果识别文档中的歧义词。如果一个关键词恰与一篇维基百科文章相关联, 称其为无歧义词。对于那些映射到多篇维基百科文章的关键词, 则定义为歧义词[9]。
歧义词所在上下文的确定, 对消歧效果的好坏有重要影响。上下文的确定是在歧义词前后一定窗口(范围)内进行, 窗口过大会引入更多的噪声, 降低消歧的准确性。本文将窗口大小限定在歧义词所在的句子以及它的前一句和后一句, 将这三个句子中的无歧义词确定为歧义词所在上下文C(C∈ T)。
然而, 无歧义词所带来消歧信息可能有局限, 例如, 选定的上下文中只包含少量的无歧义词或无歧义词无法为消歧提供更多有价值的信息。CCI2的二次消歧将第一轮中消歧效果好的歧义词加入到上下文中, 为消歧效果差的歧义词增加更多的消歧信息。
每个词语都与其所在的上下文有深层次的语义关系, 正如语言学家Firth[11]所言: “ 观其伴而知其义” (You shall know a word by the company it keeps)。因此, 歧义词的最佳词义与其所在上下文一定存在较高的相关度。同时, 当多个候选词义具有类似的相关度时, 其中最重要(即最常用)的词义往往最为合适。CCI2综合了这两方面的指标。
相关度是指两个词语之间的相互关联程度, 一般是一个[0, 1]区间的实数[12], 代表了概念对另一个概念的解释能力[13]。歧义词某一候选词义与上下文的相关度等于该候选词义与上下文各词语相关度的平均值[14]。本文在计算歧义词与其所在上下文的相关度时, 分别从类别一致性和内容相关性两方面考虑。借助于维基百科背景知识, 计算各候选词义的重要程度, 为最佳词义的选择提供进一步的消歧指标, 以获得更好的消歧效果。采用熵权法将上述三个指标进行动态线性融合, 选择具有最大融合值的候选词义作为歧义词在第一轮消歧过程中的最佳词义。
(1) 类别一致性
在维基百科中, 所有文章都有多个所属类别, 而一个类别也可能拥有多个父类别或子类别, 这使得维基百科的类别体系是一个比树状结构更加复杂、包含语义关系更加丰富的图型结构[10]。
歧义词各候选词义与其所在上下文在类别上的差异能够为消歧提供一定的语义线索, 可将这一线索作为消歧的指标之一。然而, 在维基百科的类别体系中, 通常会有多条路径将一个节点和另一个节点连通, 因此, 本文对文献[12]的基于树型类别体系的相关度算法进行扩展, 使之适用于维基百科的图型类别体系, 并以此计算词语之间的类别一致性。
文献[12]的相关度算法根据两个概念之间的最小公共父节点来计算, 公式如下:

其中, W1, W2表示需要进行相关度计算的两个概念; L指两概念在层次体系中的路径长度; a是一个可调节参数(本文取a=0.35)。后文将公式(1)简称为SimL。
由于维基百科类别体系的特点, 传统的SimL算法将忽略许多非最小公共父节点所提供的语义知识, 本文对每个具有公共父节点的路径都采用SimL算法进行相关度计算, 通过加权融合得到两个词语的类别一致性指标值。
将需要进行类别一致性计算的词语映射到维基概念。在维基百科的类别体系中找到连接这两个概念的所有独立路径, 这里的独立路径是指该路径的最小公共父节点与其他连接这两个概念的路径的最小公共父节点之间不存在父子关系。根据最小公共父节点在维基百科类别体系中的深度对所有独立路径相关度计算结果进行加权, 从而得到歧义词某一候选词义与上下文中单个词语的类别一致性指标值。
笔者在公式(1)基础上进行改进, 用以计算类别一致性:
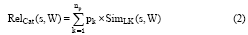
RelCat(s, W)指根据维基百科多路径方法计算得到的候选词义s与上下文中单个词语W的类别一致性; pk表示根据深度计算得到的第k条路径的权值; SimLK(s, W)指在第k条路径根据公式(1)计算出的s与W在类别上的相关度。
由公式(2)得到的只是歧义词某一候选词义与上下文中单个词语的类别一致性值, 要得到该候选词义与上下文的类别一致性, 还需计算该候选词义与上下文各词语类别一致性的平均值, 公式如下[14]:
RelCat(s, C)=avg(RelCat(s, Wi)) (3)
RelCat(s, C)指歧义词某一候选词义s与该歧义词所在上下文C的类别一致性; Wi为上下文C中的词语。
(2) 内容相关性
仅仅有类别上的差异通常不足以判断一个歧义词的准确含义, 内容的相关性能够提供更多的消歧信息, 从而有助于提高消歧的准确性。
由于每一个维基概念指向一篇维基百科文章, 因此词语或短语之间的相关度计算可转换为与该词语或短语相关联维基百科文章之间的相关度计算问题[15]。
在维基百科中, 页面与页面之间的联系通过文章中所包含的超链接来实现, 超链接体现了概念之间一定的语义关系。本文的内容相关性是基于歧义词各候选词义所对应的维基百科解释页面和歧义词所在上下文词语所对应的解释页面中的链接信息, 通过相关度计算得到的。为减少计算成本并获得较高的计算准确性, 借鉴WLM(Wikipedia Link-based Measure)算法来计算歧义词各候选词义与其所在上下文的内容相关性。
WLM算法充分利用维基概念所对应文章中的链入链接和链出链接计算词语的相关度, 考虑到计算的效率以及对最终相关度结果的影响程度, 主要参考针对链入链接的相关度计算, 其公式如下[16]:

其中, a, b分别表示进行相关度计算的两概念所对应的维基百科文章, A和B分别是链入页面a和b的所有维基百科文章的集合, W0是全部维基百科文章的集合。公式(4)源于标准化的谷歌距离[17], 其值越小则相关度越高。
然而, WLM算法没有考虑双向链接这种特殊情况, 也就是一个概念解释页面a中有直接链接到另一个概念的链接, 而在另一个概念的解释页面b中, 也有直接链向a页面的链接, 这种链接称为双向链接[13]。如: “ Operating System” 和“ Microsoft Windows” , 在这两个概念的解释页面中, 分别有链向对方的链接, 在这样链接下的两个概念往往有非常密切的语义关系。
考虑到双向链接的重要性及其对相关度的影响, 笔者在公式(4)的基础上进行如下改进:

其中, Rel(Wa, Wb)表示根据维基百科文章中的链接计算得到的两个概念Wa和Wb的内容相关性; a, b分别表示两个概念映射到的维基百科解释页面; [1-relatedness(a, b)]是采用WLM算法计算出的相关度, 其值越大, 两概念的相关度越高; 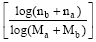
由于候选词义与歧义词所在上下文词语都可以映射到维基概念, 因此将公式(5)中的Wa和Wb分别用歧义词某一候选词义与上下文中单个词语所对应的维基概念s和W来替换便可得到候选词义与上下文单个词语的内容相关性, 即RelCon(s, W)。然而, 要得到候选词义与上下文的内容相关性还需进行如下计算[14]:
RelCon(s, C)=avg(RelCon(s, Wi)) (6)
RelCon(s, C)指歧义词某一候选词义s与该歧义词所在上下文C的内容相关性; Wi为上下文C中的词语。
(3) 词义重要程度
为充分利用维基百科中的背景信息, 本文通过歧义词各候选词义的使用频度来衡量该词义在维基百科知识库中的重要性, 使用频度越高, 则表明该词义越重要, 反之则表明该词义的重要性越差。如果一个歧义词在类别和内容上都难以区分某些候选词义, 这时, 词义的重要程度将在一定程度上为消歧提供指导。借鉴逆文档频率(IDF)[18]的思想, 笔者提出以下公式, 用于衡量一个词义的重要程度:
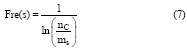
其中, Fres(s)表示候选词义s的使用频度(Frequency of Use); ms表示链接到候选词义s解释页面的维基概念数; nc表示维基百科中的维基概念总数。
(4) 消歧指标的动态线性融合
由于上述三个消歧指标对于不同歧义词在不同语境中的重要程度可能有差异, 采用固定权重进行线性融合的方法有时不能充分反映某些指标的重要程度, 在一定程度上会降低消歧的准确性。因此, 本文通过熵权对三个消歧指标进行动态模糊综合评价, 用不同候选词义在消歧指标下的差异程度来计算熵权, 不同歧义词、不同语境在消歧指标权重的赋值上是不完全相同的, 这样的赋权方法更具有客观性、科学性与合理性。熵权计算步骤[19]如下:
1数据的收集与整理。将候选词义与消歧指标写成决策矩阵V=(vij)nm, vij表示在有m个候选词义、n个消歧指标(本文中n=3)的决策矩阵中, 在第i个候选词义下的第j个指标的值。
2数据标准化处理。对矩阵V中的元素进行标准化处理, 以消除因量纲不同对评选结果造成的影响, 从而得到标准化后的矩阵R=(rij)nm。
3计算指标信息熵值e。其中第j项指标的信息熵值计算公式如下:

④计算消歧指标的权重。利用熵值法计算各指标权重其实质是该指标的信息价值系数, 价值系数越高, 对消歧的重要性就越大。计算公式如下。
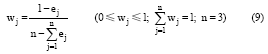
通过计算得到的权重对消歧指标进行线性融合, 计算公式如下:
RelCom(s)=w1× RelCon(s, C)+w2× RelCat(s, C)+w3× Fre(s) (10)
其中, RelCon(s, C)表示根据扩充的基于维基百科链接结构的WLM算法计算得到的候选词义s在上下文C中的内容相关性(公式(6)), RelCat(s, C)表示根据维基百科类别体系计算得到的候选词义s在上下文C中的类别一致性(公式(3)), Fre(s)是该候选词义的使用频度(公式(7)); RelCom(s)是对以上计算结果的动态线性融合值, w1, w2, w3(w1+w2+w3=1)通过熵权法计算得到。
第一轮消歧通过考虑类别信息、内容和背景信息并动态融合各消歧指标, 选取具有最高融合值的候选词义作为该轮的最佳词义。对于无歧义词所带来的消歧信息的局限性, 本文通过二次消歧(也就是第二轮消歧)来解决这一问题, 二次消歧实质是第一轮消歧的一次迭代过程。
通过以下信度公式[9]来衡量第一轮对每个歧义词消歧的质量, 也就是消歧结果的可信性:
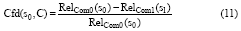
其中, s0和s1分别指某一歧义词具有最高和次高融合值的两候选词义, RelCom0(s0)与RelCom1(s1)分别指这两个候选词义所对应的融合值。消歧信度Cfd(s0, C)是s0和s1这两个候选词义的相对偏差, 而且取值在[0, 1]范围内。
非常低的信度表明该词义是在两个相关度非常相近的候选词义中随机选择的, 其消歧的准确性较差, 说明第一轮消歧所使用的上下文对该歧义词没有提供充足的、有识别力的信息[9]。因此, 有必要将第一轮的被消歧词通过一个预定的阈值ζ (通过实验, 本文设定ζ =0.03)分为高信度被消歧词和低信度被消歧词。超过ζ 的被消歧词具有高信度, 反之则具有低信度, 前者可以为后者提供更多的有用信息。
因此, 二次消歧阶段将高信度被消歧词添加到低信度被消歧词的上下文(更新的上下文记为C’ )。根据更新的上下文按照第一轮的计算过程重新计算低信度被消歧词三个指标值, 并通过线性融合重新得到融合值RelCom(s), 选择融合值最大的候选词义作为该歧义词的最佳词义, 从而完成消歧。
为了验证上述算法的有效性, 本文使用2014年9月3日发布的维基百科数据构建维基百科知识库[20]。下载的数据如表1所示:
| 表1 下载的维基百科数据信息 |
通过解析和噪音处理后得到的维基百科知识库中数据如表2所示:
| 表2 维基百科知识库 |
随机选取维基百科一篇文章中的一部分内容, 如图2所示, 对歧义词tree(“ “ 标记)采用CCI2进行消歧。首先, 通过预处理识别歧义词, 并选取上下文中有意义的无歧义词作为消歧单词tree的上下文语境(“ ” 标记), 其中包括Depth-first search (DFS), algorithm, data structures, backtracking。
 | 图2 待消歧的Wikipedia文章片段 |
对歧义词tree进行消歧指标计算, 表3详细给出了歧义词tree去除相关性较小(三个指标值分别小于各指标均值的候选词义)的候选词义后, 其余各候选词义与上下文的类别一致性、内容相关性和词义使用频度。
| 表3 歧义词tree各指标值 |
通过熵权法对三个指标值进行线性融合, 得到各候选词义融合值如表4所示:
| 表4 歧义词tree各候选词义融合值 |
由表4可以看出, 候选词义Tree (data structure)具有较高的融合值, 且消歧信度超过预定义的阈值, 可选定为最佳词义。
为进一步验证CCI2消歧方法的有效性, 再次随机选取维基百科中的5篇文章以及《纽约时报》中的5篇文章, 其中包含138个名词歧义词(同一歧义词出现多次记为一次), 共1 510个候选词义, 选取的文章中涉及到其中的147个候选词义, 每个候选词义平均出现约3次。使用本文方法对这些名词歧义词进行消歧, 以准确率P(Precision)作为衡量指标, 并与随机词义选择法(Random Sense)、最常用词义(Most Frequent Sense, MFS)方法以及本文中第一轮消歧方法(用CCI表示)进行对比, 结果如表5所示:
| 表5 各消歧方法的准确率 |
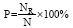
其中, NR表示测试数据中正确消歧的名词歧义词数量; N表示测试数据中进行消歧的名词歧义词总数。
可以看出, 使用CCI2进行消歧的准确率达到74.82%, 高出MFS方法14.56%, 并且比单轮消歧的效果更好, 这表明本文所提出的消歧方法的有效性, 且在一定程度上提高了消歧的准确率。
本文提出了一种基于维基百科的多策略的词义消歧方法, 充分利用维基百科中的类别、链接和背景信息, 计算歧义词与其所在上下文的类别一致性、内容相关性以及词义重要程度三个消歧指标; 为提高指标评价的客观性、科学性与合理性, 采用熵权对其进行动态线性融合, 选择融合值最大的候选词义作为第一轮最佳词义, 之后通过消歧信度评估, 将高信度被消歧词添加到上下文中对低信度被消歧词进行二次消歧, 从而达到较好的整体消歧效果。
本文方法仍有一些不足之处需要改进。对于消歧而言, 候选词义粒度并不是越细越好, 如果粒度过细, 一个歧义词会有很多候选词义且区分度较小, 这不仅导致计算量过大, 同时影响最佳词义的选择。因此, 合适的候选词义粒度对消歧准确率的提升有着重要的影响。此外, 该方法主要是针对英文进行消歧, 对于其他语言缺乏通用性。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|