{kind=link}
{kind=link}
{kind=link}
{kind=link}
Web数据到RDF数据的框架实现
[陈涛 , 张永娟, 陈恒]
, 张永娟, 陈恒]
, 张永娟, 陈恒]
|
|


作者贡献声明:
陈涛: 提出研究思路, 设计研究方案及框架, 论文起草及最终版本修订;
张永娟: 验证方案, 数据采集, 进行实验;
陈恒: 系统本体结构分析及构建。
【目的】构建Web数据到RDF数据(W2R)转换框架, 实现Web数据的RDF结构化。【方法】采用W2R词表构建转换框架的底层结构, 并根据设计的系统本体和Web页面元素组成映射文件进行数据的RDF结构化, 同时采用Virtuoso数据库进行数据存储。【结果】通过对映射文件的灵活配置, 在不修改任何程序代码的基础上, 实现Web数据的RDF结构化、不同数据源之间数据的整合以及RDF数据的Named Graph存储及推理。【局限】 系统的本体结构以期刊和文献结构为主, 尚不支持其他知识领域。此外, 针对RDF数据的持久化存储, W2R框架目前仅支持Virtuoso数据库。【结论】W2R框架实现Web数据的RDF结构化, 为语义网络和关联数据的应用提供标准化数据。
[Objective] The article aims at building W2R framework for converting Web data to RDF format.[Methods] Build the bottom infrastructure of the framework with W2R vocabulary, and convert Web data to RDF format with mapping file which is consisted of system Ontology and Web page elements extracted in XPath syntax. Furthermore, use Virtuoso database as the persistent storage of RDF data.[Results] With the W2R framework, it is convenient for converting Web data to RDF format, merging data in different resources, storing them in named graphs and implementing simple inferences without changing any source code.[Limitations] The system Ontology is made up of public namespaces that describe the bibliographies currently. RDF data is only stored in Virtuoso database.[Conclusions] Through the W2R framework, this paper provides a new way of generating the standardized RDF data for semantic network and linked data applications.
互联网上存在着大量非结构化数据和采用不同标准的结构化数据, 关联数据是一种简单的语义网实现技术, 可以将多种数据开放并连接在一起, 允许用户发现、关联、描述并再利用各种数据, 它使互联网迈出了向语义网(Semantic Web)进化的重要一步。
近年来, 越来越多的机构、组织及政府部门都对外开放其数据, 并与其他机构发布的数据关联, 实现跨数据库的数据交换, 范围涉及多媒体、文献出版、生命科学、地理信息等。美国、英国、巴西、新西兰等国家也逐渐将政府信息(涵盖卫生、农业、税务、教育等方面)发布成可重用的关联数据。因此, “ 文档的网络(the Web of Document)” 向“ 数据的网络(the Web of Data)” 转变, 已经是大势所趋[1]。
RDF(Resource Description Framework)为Web资源描述提供了一种通用框架, 即通过“ 资源-属性-值” 的三元组形式描述Web上的各种资源。它以一种机器可理解的方式被表示出来, 提供了Web数据集成的元数据解决方案, 可以很方便地进行数据交换。相对于其他数据形式, RDF数据具有易控制、易扩展、易综合以及高包容性和可交换性等特点。通过RDF的帮助, Web可以实现一系列应用, 如可以更有效地发现资源, 提供个性化服务, 分级与过滤Web的内容, 建立信任机制, 实现智能浏览和语义Web等[2, 3, 4]。
目前, 将关系型数据库中的数据转为RDF数据, 即RDB2RDF的研究较多, 主要有D2R (http://d2rq. org/d2r-server)、R2RML (http://www.w3.org/TR/r2rml)。实现方法主要是通过映射文件(Mapping File), 将关系型数据库中的表和字段依据相互之间的关系映射成RDF三元组数据[5, 6]。RDB2RDF的映射方式主要适用于企业和机构进行内部数据的RDF转换, 但是在制定映射文件时, 必须获取数据库的访问权限, 并对数据结构具有相当程度的了解。而对于Web数据转换, 一般不太可能获取其数据结构以及访问权限, 因此RDB2RDF不太适合Web数据的RDF结构化。
当然, 也存在一些将Web数据转为RDF数据的方法, 如: Apache Marmotta LDClient (http://marmotta.apache. org)和Apache Any23 (http://any23.apache.org)。这些方法主要以提供API为主, 需要用户从逻辑层的角度自行转换Web数据, 不仅要求使用者具有一定的编程能力, 而且还需要熟悉语义网络及关联数据的相关技术, 使用门槛较高。本文则从应用层的角度出发, 试图对Web数据的转换机制进行封装, 使用者只需通过简单的模板设置就可以实现对Web数据的RDF结构化。
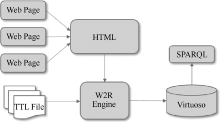
目前流行的关联数据和语义网络开源框架主要有Jena (http://jena.apache.org)和Sesame (http://www.penrdf. org), 本文提出的W2R转换框架后台采用Jena框架, 可以集成到Java应用中, 作为数据转换接口实现Web数据的RDF结构化[7, 8, 9]。转换框架设计如图1所示:
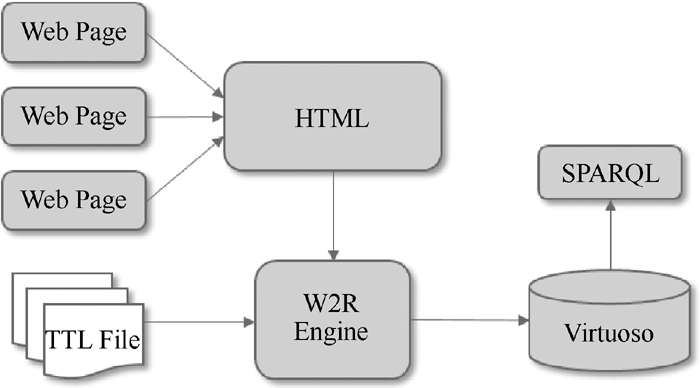 | 图1 W2R转换框架 |
具体转换流程如下:
(1) 通过Get或者Post方法从网络页面(Web Page)中获取HTML源文件。
(2) 制定系统本体, 根据Web页面元素从本体中抽取相应属性构成抓取模板, 即TTL文件。
(3) 数据转换方面采用自行研发的W2R转换引擎。该引擎根据TTL映射模板, 从HTML源文件中抽取所需字段信息, 并将信息转换为RDF三元组格式进行持久化存储。
(4) 数据的持久化存储采用Triple Store数据库, 这里选用Virtuoso数据库(http://www.openlinksw.com/), 该数据库不仅支持RDF数据管理, 同时还针对RDF数据提供SPARQL访问节点。
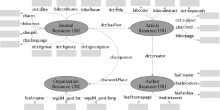
类似于RDB2RDF, Web数据的RDF结构化同样需要映射文件, W2R框架的映射文件主要由系统结构本体中的相关属性组成。本文的系统结构本体如图2所示, 主要涉及4涉及到持久化存储采用的otta.apache.org/个办法山谷个类: 期刊(Journal)、文献(Article)、作者(Author)以及组织机构(Organization), 当然也可以扩展到其他类, 如基金类、主题词类等。
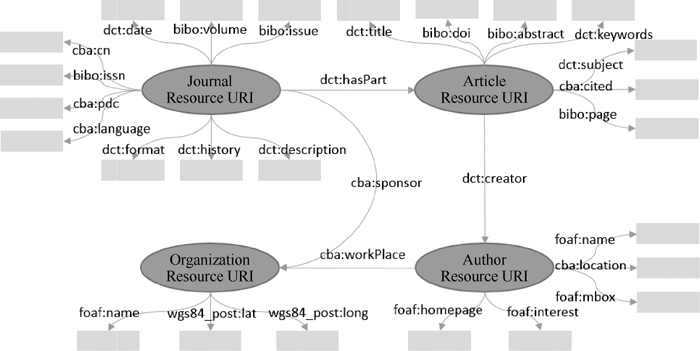 | 图2 系统本体设计 |
项目设计本体时, 主要是在采用已有的开放词表的基础上, 扩展一些私有词表, 这里采用的开放本体词表主要有dct (dcterms)、foaf、wgs84_post、bibo等。而cba词表则为扩展的私有词表, 这些词表的属性暂称为知识属性, 用于描述不同对象间的知识结构。系统结构本体在设计时, 建议尽可能采用开放本体词表, 这样可以方便不同系统之间数据的共享、关联与复用。对于私有词表, 可以通过owl:sameAs建立与其他开放本体词表属性的连接关系, 实现与其他系统之间数据的关联。
系统的结构本体除了定义的知识属性外, 还包括一些用于系统框架的底层结构, 即结构属性。这些结构属性, 主要是以W2R词表为主的底层词表。
(1) w2r:graph, 目标Graph(图), 用来进行Named Graph的数据存储。从页面转换后的数据将被存储到定义的Graph中, 每个模板至少有一个Graph。
例如: [ ] w2r:graph bibo:Journal, 表示将抓取的数据存储到Journal Graph中。
(2) w2r:target, 指向页面中目标采集区域。
(3) w2r:mode, 抓取模式, 与w2r:target结合使用, 表明在哪个目标域中进行模式抓取, 这里的模式分为solo(单例)和repeat(循环)。其中, solo为单例抓取, 主要用于单个文献、单个期刊信息的抓取; repeat为循环采集, 主要用于某个期刊中所有文献列表的抓取。
(4) w2r:merge, 用于信息合并、增量采集, 可以定义多个合并因子。
例如: [ ] w2r:merge “ %%ISSN%%, %%TITLE%%” , 表示根据期刊“ ISSN号” 和“ 标题” 这两个因子进行不同数据源之间文献信息的合并。
(5) w2r:refer, 指定引用对象, 获取对象的主语。
例如: [ ] w2r:refer “ %%dcterms:title%%” , 表示根据标题获取资源主语。与w2r:merge区别在于, w2r:refer仅获取资源主语, 而w2r:merge获取主语后, 还与资源中的信息进行合并操作。
(6) w2r:uniPattern, 用于定义主语生成规则。当该属性为空时, 则为空节点BNode, RDF数据在实际使用过程中, 尽量避免使用空节点, 空节点只能内部识别, 不能用于数据之间的关联。
例如: [ ] w2r:uniPattern “ %%uuid%%” , 表示生成的主语采用UUID唯一码进行标识。
(7) w2r:rules, 用于定义推理规则, 与w2r:graph结合使用, 表明在哪个Graph中应用推理规则。
例如: [ ] w2r:rules “ %%rule2%%, %%rule6%%” ; w2r:graph graph:Journal, 表示在期刊Graph中采用规则2和规则6共同推理。
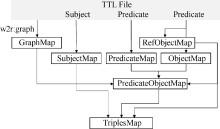
系统本体设计好后, 可以通过W2R转换引擎实现HTML数据的RDF结构化。W2R引擎接口如图3所示:
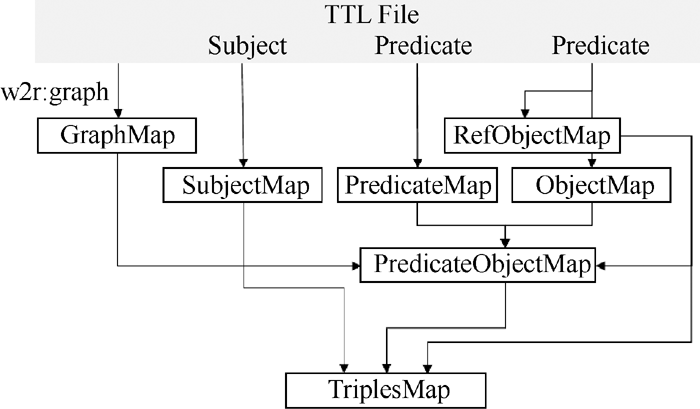 | 图3 W2R转换引擎 |
具体操作如下:
(1) GraphMap的实现。每个模板可以有一个或多个Graph, 每个主语节点只能有一个Graph。转换时, 根据模板中不同主语所拥有的w2r:graph属性, 进行Graph的匹配。如果该主语节点没有w2r:graph属性, 则需要寻找上一层父节点的Graph, 即该主语节点是其他主语节点中对象属性的宾语。
(2) SubjectMap的实现。该操作主要完成所有主语的实例化。实例化根据该主语节点中的w2r:uniPattern属性生成。如果某个节点中没有w2r:uniPattern属性, 则该主语为空节点。
(3) PredicateMap和ObjectMap的实现。谓语属性分为两类, 数据属性和对象属性。当判断到该谓语属性是数据属性时, 从模板中获取该属性对应的宾语格式, 并从HTML中进行宾语的实例化; 当该谓语属性是对象属性时, 根据引用关系从SubjectMap中选取实例化后的主语。PredicateMap和实例化后的ObjectMap组成PredicateObjectMap对, 并与SubjectMap实例化的主语一起构成三元组Triples。
(4) TriplesMap的实现。在步骤(3)中, 已经完成Triples的转换, 本步骤则完成数据的持久化存储。当采集完一篇页面数据后, 可以将转换后的所有RDF数据放置到内存模型MemoryModel中, 待所有的数据都采集结束, 统一写入数据库中, 这样可以减少数据库的频繁读写操作。
系统结构设计和实现后, 可以通过对本体属性元素的随意组合, 定义所需目标页面元素的抓取模板。页面元素的分析, 主要通过Jsoup (http://jsoup.org/)实现, Jsoup 是一款Java 的HTML解析器, 可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API, 可通过DOM、CSS以及类似于jQuery的操作方法读取和操作数据。对于不同的数据源, 可以定义不同的采集模板, 这里的模板主要采用TTL数据格式, 以期刊采集为例, 模板由以下块信息段组成:
(1) @prefix段定义了期刊采集中使用的词表前缀。
@prefix dcterms: < http://purl.org/dc/terms/> .
@prefix w2r: < http://www.cba.ac.cn/w2r/ontology/1.0/> .
@prefix : < http://www.cba.ac.cn/ontology/1.0/> .
@prefix host: < http://www.cba.ac.cn/> .
@prefix graph: < http://www.cba.ac.cn/graph/> .
@prefix rdfs: < http://www.w3.org/2000/01/rdf-schema#> .
@prefix rdf: < http://www.w3.org/1999/02/22-rdf-svntax-ns#> .
@prefix foaf: < http://xmlns.com/foaf/0.1/> .
@prefix bibo: < http://purl.org/ontology/bibo/> .
@prefix skos: < http://www.w3.org/2004/02/skos/core#> .
(2) host:template段定义抓取模板自身的信息段, 该段信息不写入数据库。
host:template rdf:type :Template;
rdfs:comment “ 期刊模板” ;
w2r:target “ div.left” ;
w2r:mode “ solo” .
该段指明文件类型为“ 期刊模板” , 除此以外, 系统还支持“ 文献模板” 。模板的制定和选择主要根据实际的Web页面结构进行设计, 如想获取专家学者的个人信息, 可以指定“ 专家模板” 进行采集。该段还指明了抓取的目标域, 即从HTML的div.left节点抓取信息。抓取模式为“ 单例solo” 。w2r:target和w2r:mode为W2R框架的底层结构属性。
(3) host:journal段定义期刊信息段, 产生的RDF数据将存入目标Graph中, 即属性w2r:graph所对应的宾语值。
host:journal rdf:type bibo:Journal;
:date “ yyyy-MM-dd” ;
:image “ div.pic > a > img” ;
dcterms:title “ div#tdInfo > p:eq(1) > a:eq(0)” ;
:sponsor host:Organization;
:period “ div#tdInfo > p:eq(1) > a:eq(2)” ;
:location “ div#tdInfo > p:eq(1) > a:eq(3)” ;
:language “ div#tdInfo > p:eq(1) > a:eq(4)” ;
:size “ div#tdInfo > p:eq(1) > a:eq(5)” ;
bibo:issn “ div#tdInfo > p:eq(1) > a:eq(6)” ;
:cn “ div#tdInfo > p:eq(1) > a:eq(7)” ;
:pdc “ div#tdInfo > p:eq(1) > a:eq(8)” ;
skos:historyNote “ div#tdInfo > p:eq(1) > a:eq(11)” ;
skos:note “ div#tdInfo > p:eq(1) > a:eq(12)” ;
w2r:uniPattern “ %%uuid%%” ;
w2r:graph graph:Journal.
该段指明需要抓取的期刊信息: 期刊名(:title)、主办单位(:sponsor)、周期(:period)、语种(:language)、开本(:size)、ISSN(bibo:issn)、CN(:cn)、邮发代号(:pdc)等信息。其中, :sponsor为对象属性, 用于连接期刊和主办单位, w2r:uniPattern和w2r:graph为W2R框架的底层结构属性。
(4) host:organization段定义期刊主办单位信息段。
host:organization rdf:type foaf:Organization;
foaf:name “ div#tdInfo > p:eq(1) > a:eq(1)” .
该段简单指明了期刊主办单位的基本信息(主办单位)。需要注意的是本信息段没有单独制定数据需要存储的目标Graph, 即不含w2r:graph属性, 因此主办单位信息将与期刊信息存储在同一Graph中。当然也可以为本信息段单独指定w2r:graph属性, 如graph: Organization, 将主办单位信息存储到组织机构Graph中。
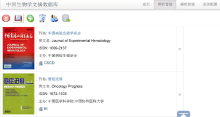
本文提出的W2R转换框架可以根据需要构建多个基于RDF数据的应用系统。图4为构建的文献数据库期刊管理系统, 其中的期刊为Web数据RDF格式化的显示结果, 可以在“ 模板管理” 菜单中制定不同的抓取模板以及数据的采集和整合规则。抓取后的期刊RDF三元组数据存储到Virtuoso数据库中, 页面显示可以根据需要重新组合。以“ 癌症进展” 为例, 数据库中的RDF三元组如表1所示:
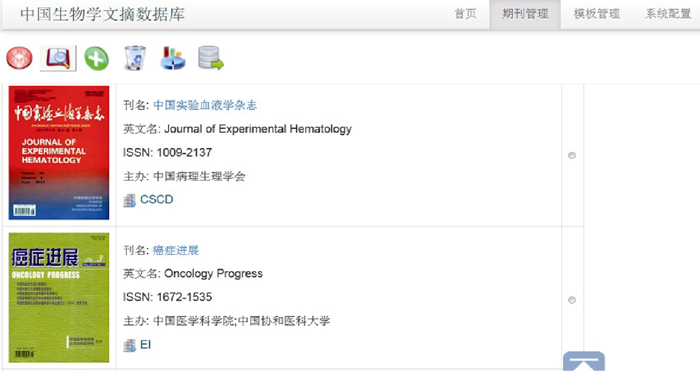 | 图4 文献数据库期刊管理系统 |
| 表1 Web数据的RDF结构化三元组 |
对期刊的Web数据进行RDF结构化后, 可以进行RDF三元组数据的发布。关联数据的发布方式有很多种[10, 11], 如采用Fuseki发布TDB中的数据[12]; 采用Pubby (http://wifo5-03.informatik.uni-mannheim.de/pubby)构建关联数据的SPARQL端点; 采用RDFa语义标识HTML数据等[13]。本文采用Virtuoso进行RDF三元组数据的存储, 因此可以直接利用Virtuoso自带的SPARQL端点, 无需进行其他配置。然而, RDF数据的发布只是关联数据和语义网应用的第一步, 如何将转换后的RDF数据与其他开放数据建立关联, 是目前框架欠缺的部分。此外, 关联数据的发现机制也正在研发之中, 如通过关联机制, 可以和PubMed (http://pubmed.bio2rdf.org/sparql)进行文献关联; 可以根据期刊的主办单位从Dbpedia (http://dbpedia.org/sparql)中获取更多单位信息; 也可以根据地域从GeoNames (http://www.geonames.org/)中获取更多地域信息。
目前, 系统的数据采集及RDF结构化只是在小范围内进行准确性验证, 后期将进入大数据量的并发采集, 并对采集和转化的效率进行量化评估, 以便适用于更多的应用场景。
RDF数据是语义网络和关联数据的数据基础, 将Web数据转换为RDF数据, 是进行数据整合及信息交互的前提。本文提出的W2R转换框架, 具有一定的通用性, 用户可以根据Web数据的实际需求, 自行定义系统结构本体, 并可制定多样的采集模板, 对Web数据进行RDF的格式化、整合、推理等操作。尽管如此, 除了正在研究的关联发现机制外, 还需要在以下三个方面进行改进, 以适应更多的应用场景:
(1) 目前框架仅支持Virtuoso数据库, 后期将扩展更多数据库的存储;
(2) 完善本体结构, 加入更多的初始模板, 适应更多应用场合;
(3) 开发页面插件, 使用可视化的方式进行页面元素的选择和RDF的转换。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|