
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
利用《知网》和领域关键词集扩展方法的短文本分类研究
[李湘东1, 2 , 曹环1 , 丁丛1 , 黄莉3  ]
]
]
|
|


作者贡献声明:
李湘东: 提出研究思路和方案, 论文审阅和最终版本修订;
曹环: 系统实现, 进行实验, 论文撰写;
丁丛: 进行实验, 文献调研;
黄莉: 系统设计, 数据采集, 最终版本修订。
【目的】实现短文本特征扩展, 提高短文本分类性能。【方法】按照特征词和隐含主题两种特征粒度, 分别抽取训练集中各类别的高频词和主题核心词作为领域关键词集。利用概率主题模型提取待分类文本的主题概率分布, 将概率大于某一阈值的主题对应的关键词扩展到待分类文本中。借助《知网》计算待分类文本与各领域关键词集的语义相似度。【结果】与LDA模型的短文本分类算法相比, 本文提出的分类算法在复旦语料、Sogou语料和微博语料上的Macro_F1分别平均提高4.9%、5.9%和4.2%, 在Micro_F1上分别平均提高4.6%、6.2%和2.8%。而与VSM的短文本分类算法相比, 本文方法在各语料上都提高13%以上。且实验证明结合领域高频词和主题核心词的特征扩展方法的分类性能优于仅使用领域高频词或主题核心词进行特征扩展的方法。【局限】 短文本中存在很多《知网》未收录的特征词, 无法利用《知网》计算相似度, 影响分类效果。【结论】本文方法能有效提高短文本分类性能。
[Objective] This paper aims to implement characteristic extension of short-text and improve short-text classification performance.[Methods] Extract the high frequency words and topic core words of each class of the training set as domain keyword set based on two different feature granularity, which is word and potential topic, and derive the topic probability distribution of the testing text using LDA model, while some topic probability is greater than a certain threshold, extend the keywords of the topic into the testing text. Calculate the sematic similarity of the testing text and the domain keyword set of each class by using HowNet.[Results] Compared with the short-text classification method based on LDA model, the proposed classification algorithm in Fudan corpora, Sogou corpus and the Micro-blog corpus average increase by 4.9%, 5.9% and 4.2% on Macro F1, on the Micro F1 average increased by 4.6%, 6.2% and 4.6%. Compared with the short-text classification method based on VSM model, the method can increase F-measure more than 13% in the all three corpus. And experimental proof in combination with characteristics of high frequency words and subject core words in the field of extension method classification performance is better than the extension method that only using high frequency words or subject core words.[Limitations] There are many words not included by HowNet, and these words cannot use HowNet to calculate similarity. It will affect classification results.[Conclusions] The method of this paper can effectively improve the short-text classification performance.
随着互联网技术的高速发展和信息传播手段的不断进步, 微博、手机短信、商品评论等中文短文本(通常不超过140个字)形式的信息近几年呈爆发式的增长, 已经成为重要的信息传播方式。如何从这些丰富多样的短文本信息中寻找有用信息并将其归属到正确的类别是信息管理领域亟待解决的问题之一。因此, 短文本分类已经成为该领域的一个重要研究方向。
由于短文本存在内容较短、特征稀疏等特点, 因此传统的向量空间模型(Vector Space Model, VSM)以及KNN、贝叶斯、SVM等经典分类算法不能很好地应用于短文本分类。为了解决短文本分类的特征稀疏性问题, 目前研究者通常借助外部资源或内部语义关联对短文本进行特征扩展。
本文结合特征词和隐含主题两种不同粒度, 提出一种基于《知网》和领域关键词集扩展的短文本分类算法。在较细粒度的词特征上, 通过特征词词频统计获得训练集各类别的领域高频词; 在较粗粒度的隐含主题特征上, 采用概率主题模型提取各类别的主题核心词。合并各类别的领域高频词和主题核心词, 去掉重复特征词, 构成训练集各类别的领域关键词集。对分类文本, 通过概率主题模型建模获得待分类文本的文本-主题概率分布, 将主题概率大于某一阈值的主题在训练集中对应的关键词扩展到待分类文本, 借助《知网》计算扩展后的待分类文本与训练集各类别的领域关键词集间的相似度, 相似度最高的类别即为待分类文本所属类别。本方法一方面通过提取各类别的领域关键词集作为训练集, 有效降低了短文本的噪声影响; 另一方面利用训练集中的领域关键词集对测试集文本进行扩展, 一定程度上降低了短文本特征稀疏对分类性能的影响, 也增加了测试集与训练集的共现程度。
短文本具有内容较短和特征稀疏等特点, 因此相对长文本, 短文本自动分类的实现更具挑战。传统的VSM和词频统计模型应用在短文本分类上的效果并不理想。而基于语义的模型虽可以提高短文本的分类效果, 但其计算复杂而且效率低下。Zelikovitz等[1]将潜在语义索引(Latent Semantic Indexing, LSI)引入短文本分类, 发现分类效果有所提高, 但总体效果欠佳。Pu等[2]利用LSI进行文本预处理, 使用独立部件分析分类器对短文本进行分类。实验结果表明使用LSI的实验组分类效果较好, 但由于短文本的特征稀疏, 总体效果仍不理想。目前, 研究者一般通过对短文本进行特征扩展来解决短文本的特征稀疏性问题。王细薇等[3]针对短文本所描述信号弱的特点, 提出一种基于特征扩展的中文短文本分类方法。实验结果表明, 这种方法具有较高的分类性能, 其微平均值和宏平均值都高于常规的文本分类方法。
短文本的特征扩展方法一般分为外部资源扩展和借助内部语义关联规则进行扩展。外部资源扩展主要借助WordNet、知网、维基百科等语义词典。赵辉等[4]借助维基百科知识库挖掘短文本所蕴含的隐性信息, 通过选取在语义层面与特征词高度相关的词, 对特征词进行扩展以辅助短文本分类; 张素智等[5]利用知网对使用基于字的分词策略提取出的文本关键字进行概念映射, 扩展语义表达能力。另一方面, 通过内部关联规则, 利用语料集中特征词的关联性, 建立领域关键词集, 亦可实现短文本的特征扩展。其中, 宁亚辉等[6]抽取领域高频词作为特征词, 借助知网从语义方面对短文本进行扩展; 湛燕等[7]利用领域高频词作为关键词集, 在此基础上进行特征扩展; 胡勇军等[8]基于概率主题模型, 将潜在主题中的高频词扩展到短文本中。Sriram等[9]将用户的信息和微博特征等特征词作为领域关键词集, 从而进行特征扩展, 以此实现微博类短文本的分类。在基于内部关联的短文本特征扩展算法中, 现有研究主要通过细粒度(即特征词)或粗粒度(即主题)中的某一个角度, 建立知识库, 实现短文本特征扩展, 但少有研究同时考虑粗细两种粒度。因此本文提出的基于《知网》和领域关键词集扩展的短文本分类算法结合了特征词和隐含主题两种不同粒度, 对短文本分类效果的提高具有一定的创新意义。
LDA(Latent Dirichlet Allocation)[10]是一种概率主题模型, 将文本表示成一个由文本、主题和特征词组成的三层概率模型。模型假设文本集中每篇文本为隐含主题集上的随机混合, 按照一定概率共享隐含主题集; 而隐含主题则是特征词上的多项式分布, 每个主题由一系列相关特征词组成。
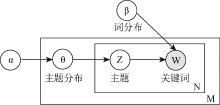
LDA模型如图1所示, θ 代表主题分布, Z表示文档分配在每个词上的隐含主题权重, w是文档的词向量。N为每个文档中词的个数, M为文档个数。在构建模型时, LDA假设主题分布以及词分布分别先验地服从参数α 和β 的Dirichlet分布。 其中, α , β 是Dirichlet分布的超参数, α 可理解为获得文本集中的文本之前, 主题被抽样的次数; β 可理解为得到文本集中的特征词之前, 从主题抽样获得的特征词频数。由于不同主题和不同特征词被利用的方式基本相同, 因此可以假定对称的Dirichlet分布, 即所有的α , β 取相同的值。
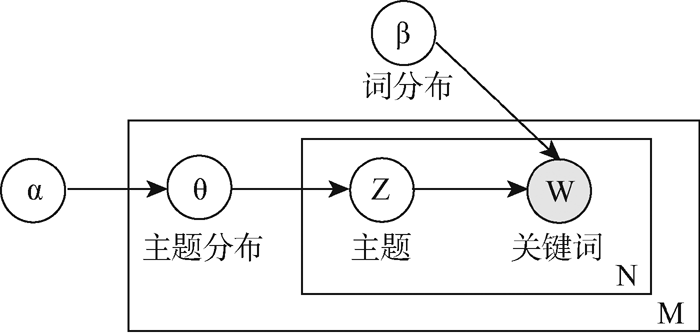 | 图1 LDA模型 |
领域关键词集是某一领域中有较强指示性、领域区分能力较好的关键特征词集合, 能有效地捕获领域知识, 明确区分其他领域, 本文提出一种基于不同特征粒度的领域关键词获取方法。特征粒度即特征对文本内容刻画的程度[11], 在文本表示中, 特征词是粒度较细的特征, 直接刻画了文本中的每个词, 如VSM; 隐含主题是粒度较粗的特征, 刻画的是文本中多个相关特征词的分布, 如LDA模型。不同粒度的特征描述文本的能力不同, 本文基于不同粒度特征提取训练集各类别的关键词构成领域关键词集: 基于细粒度, 通过特征词词频统计获取领域高频词; 基于粗粒度, 采用LDA建模获得各领域的主题核心词。
(1) 领域高频词
领域高频词指在某一领域出现概率大, 而在其他领域出现概率小的特征词(即具有领域区分能力的词), 高频词对领域辨识度高, 能唯一确定某个领域, 因此可以利用这些领域高频词对待分类文本进行分类[6]。低频词对类别识别能力低, 对分类作用不大, 反而会增加短文本的噪声, 影响短文本的分类效果。因此, 本文提取高频词进行分类, 剔除对分类贡献较少的低频词。领域高频词的获取算法具体如下:
输入: 训练集D, 训练集类别数K, 特征词类别比重阈值weight
输出: 各类别的领域高频词
①对训练集进行词性过滤, 仅保留对分类影响较大的名词、动词和形容词;
②对词性过滤后的训练语料进行特征词词频统计, 获得每个特征词在各类别中出现的频数, 过滤掉在所有类中的频数均小于5的特征词;
③对每个特征词在各类中的频数按比重进行归一化处理, 设特征词w在类别Ci中的频数为xi, 归一化后w在类别Ci中的比重为 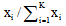
(2) 主题核心词
主题核心词是某一主题下能有效代表该主题的特征词集合, 以类别为主题, 通过LDA建模获得训练语料中各主题的核心特征词。主题核心词抽取算法具体如下:
输入: 训练集D, 训练集类别数K, 特征词数阈值M
输出: 各类别的主题核心词
①对训练集进行词性过滤, 仅保留对分类影响较大的名词、动词和形容词;
②以类别为主题, 对过滤后的训练集进行LDA建模, 获得各主题下的特征词概率分布;
③对某一主题下的特征词概率分布, 选择概率值排名前M的特征词作为该主题的核心特征词。
合并获得的训练集各类别的领域高频词和主题核心词, 去掉重复特征词, 得到各类别的领域关键词集。
为解决短文本特征稀疏、信息描述能力弱等问题, 本文提出一种基于LDA模型的领域关键词扩展算法。在提取各类别领域关键词集后, 通过LDA模型对待分类文本进行特征扩展, 具体算法如下:
输入: 训练集领域关键词集S, 测试集D, 主题概率阈值C2, 主题词数抽取阈值N
输出: 特征扩展后的测试集
①对测试集进行词性过滤, 仅保留对分类影响较大的名词、动词和形容词;
②对词性过滤后的测试集文本进行LDA建模, 获得测试集文本-主题概率分布;
③对任一待分类文本d及其主题分布θ , 若待分类文本d中主题i的概率大于阈值C2, 则将主题i对应的领域关键词集中与该待分类文本最相关的N个关键词扩展到待分类文本d中, 去掉重复特征词, 相关性计算公式如下:
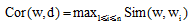 |
其中, Cor(w, d)是特征词w和文本d的相关性, Sim(w, wi)是特征词w和wi的语义相似度, n是文本d的长度;
④若短文本d中所有主题的概率均小于阈值C2, 则继续执行下一篇待分类文本。
通过训练集领域关键词集对测试集文本进行扩展, 一定程度上解决了测试集文本的特征稀疏问题。同时, 对测试集文本的扩展, 本质上就是在训练集特征和测试集特征之间建立一种共现, 将训练集中相关联的特征词扩展到测试集文本中, 增加训练集文本与测试集文本之间的关联, 进而提高分类效果。
基于《知网》和领域关键词集扩展的短文本分类的基础是短文本相似度计算。目前常用的文本相似度计算方法主要分为基于统计与基于语义词典两种。基于统计的计算方法易受训练集词语分布频率的影响, 考虑到短文本具有特征稀疏等特点, 本文借助《知网》语义词典计算短文本之间的语义相似度。《知网》是一个以汉语和英语的词语概念为描述对象, 以揭示概念与概念之间以及概念所具有的属性之间的关系为基本内容的常识知识库。文本是由词语组成的, 因此, 短文本之间的相似度可转化为计算词语之间的相似度。
(1) 词语相似度计算
在《知网》中, 每个词语包含若干个义项, 因而词语间的相似度计算可转化为义项间的相似度计算; 义原是描述义项的最基本单位, 即所有义项最终归结为义原, 所以义项间的相似度计算又可以转化为义原间的相似度计算。
①义原相似度计算
义原相似度计算是词语相似度计算的基础。在《知网》中, 所有的义原根据上下位关系构成了一个树状的义原层次体系(即义原树), 刘群等[12]通过计算义原树中义原间的路径长度来计算义原相似度。设两个义原的路径长度为d, 则这两个义原之间的相似度为:
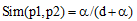 |
其中, p1, p2表示两个义原, d为p1和p2在义原树中的路径长度, α 是一个可调节的参数。
吴健等[13]在此基础上引入义原层次深度, 对于相同路径长度的两组义原, 层次越深, 义原描述的含义越清晰具体, 范围越小, 相似度越大。义原相似度计算公式为:
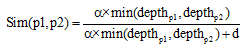 |
其中, 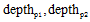
②义项相似度计算
在《知网》中收录的词语主要有两种: 虚词和实词。在实际的文本中, 虚词和实词总是不能相互替换的, 因此虚词义项和实词义项的语义相似度为零。虚词义项的相似度即为义原间的相似度, 实词义项是由语义描述式来表示的, 包含主要特征、次要特征、关系义原特征以及关系符号特征描述式4部分。义项的相似度为语义描述式的各个对应组成部分间的相似度的加权和。义项s1和义项s2的相似度计算公式[14]如下:
 |
其中, simi(s1, s2)分别为义项s1与s2的语义描述式中各个组成部分间的相似度, β i为各部分的相似度所占比重, 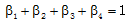
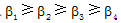
③词语相似度计算
两个词语的相似度是它们在不同的上下文中可以互相替换且不改变文本的句法语义结构的可能性大小。对于两个词语w1和w2, 若w1含有m个义项: 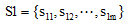
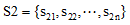
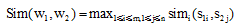 |
(2) 基于语义的短文本相似度计算
从信息论的角度讲, 文本相似度一方面与它们的共性相关, 共性越多, 相似度越高; 另一方面也与它们的区别相关, 区别越大, 相似度越低。两个文本完全相同时相似度为1, 完全不同时相似度为0。基于《知网》的短文本相似度依赖于词语相似度的计算结果。对于短文本d1和d2, 假设分词和预处理后, 短文本 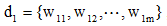
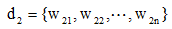
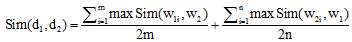 |
其中, 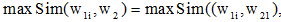
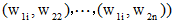
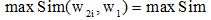
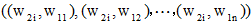
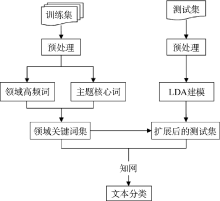
本文针对短文本特征稀疏等问题, 提出一种基于《知网》和领域关键词集扩展的短文本分类算法, 研究框架如图2所示:
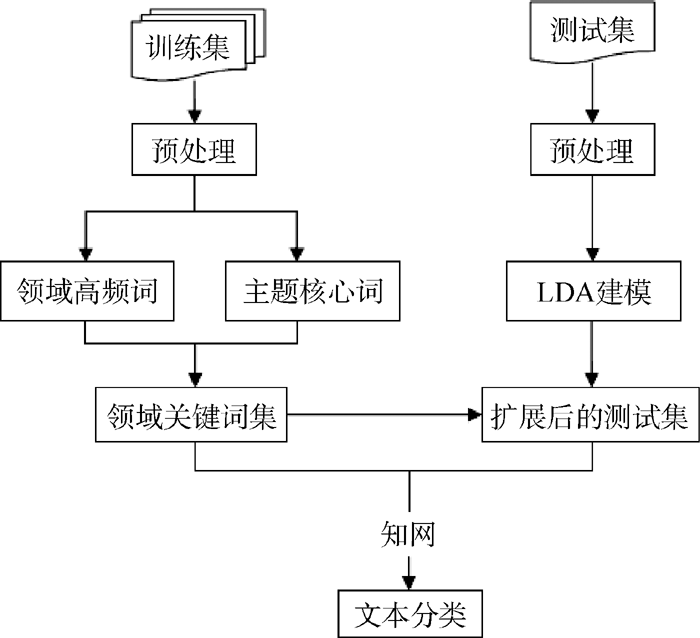 | 图2 基于《知网》和领域关词集扩展的 短文本分类研究框架 |
获得训练集各类别的领域关键词集后, 通过LDA模型对测试集文本进行扩展, 借助《知网》计算短文本语义相似度, 在此基础上进行短文本分类。具体算法如下:
(1) 预处理, 包括分词、去停用词、词性过滤;
(2) 对训练集文本进行词频统计, 提取各类别的领域高频词;
(3) 训练集建模, 抽取各主题下的核心特征词;
(4) 合并各类别的领域高频词和主题核心词, 去掉重复特征词, 得到各类别的领域关键词集;
(5) 对测试集进行LDA建模, 利用训练集中各类别的领域关键词集对测试集文本进行扩展;
(6) 计算待分类文本与各类别领域关键词集的语义相似度, 将相似度最高的类别分配给该待分类文本。
实验语料来自复旦大学中文语料库[17]、Sogou文本分类语料库[18]和微博语料库[19]。对于两种公开语料库, 分别从复旦大学中文语料库的期刊文章和Sogou新闻中抽取标题作为实验数据, 文本平均长度约为20个字, 复旦大学中文语料库包括艺术、计算机、经济、环境、历史、航空、体育7个类, 共4 708篇文本, 其中, 训练集2 979篇, 测试集1 729篇; Sogou文本分类语料库包括计算机、经济、教育、旅游、军事、体育、医学7个类, 共3 005篇, 其中训练集1 977篇, 测试集1 028篇; 微博语料取自NLPIR微博内容语料库, 包含旅游、体育、军事、科技、政治5个类别, 随机抽2 335篇作为实验, 其中训练集1 427篇, 测试集908篇。各类别文本分布如表1所示, 所有实验的语料数据均为随机抽取, 重复实验10次, 取其均值为最终结果。
| 表1 实验语料各类别文本分布 |
为验证本文提出的基于《知网》和LDA领域关键词集扩展的短文本分类算法的有效性, 在传统的查准率P、查全率R和F1值三种指标的基础上使用宏平均F1测度值Macro_F1和微平均F1测度值Micro_F1对分类性能进行评价[20]。
本文训练集领域高频词获取中类别比重weight阈值为0.8, 主题核心词阈值M为20, 测试集文本扩展主题概率阈值C2为0.5, 关键词数抽取阈值N为5。
复旦语料训练集中各类别抽取的领域关键词集中的部分关键词如表2所示。从表2可以看出, 本文方法获得的领域关键词能有效地表示某一类别, 并区分其他类别。通过提取各类别中类别指示意义较强、类别区分能力较好的特征词, 有效解决了噪声影响, 提高文本分类效果。
| 表2 复旦语料训练集各类别中关键词集示例 |
为验证本文方法的有效性和优越性, 进行如下两个实验: 比较本文方法与领域关键词集分别只包含领域高频词和主题核心词的方法; 比较本文方法与传统VSM和LDA模型结合SVM算法的分类方法。
(1) 实验一
采用传统VSM作为文本表示, 结合SVM分类算法, 作为对比实验; 还利用LDA建模对文本降维, 构造潜在语义矩阵, 分类算法选择SVM, 也作为对比实验。三组实验结果如表3和图3-图5所示:
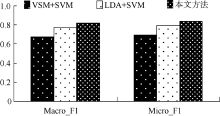
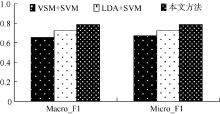
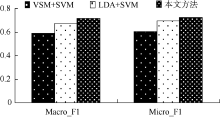
| 表3 三种不同分类方法在三个语料库上的分类性能比较 |
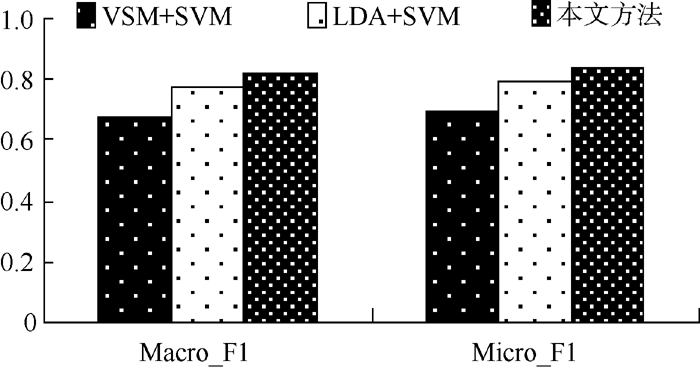 | 图3 不同分类方法在复旦语料上的分类性能比较 |
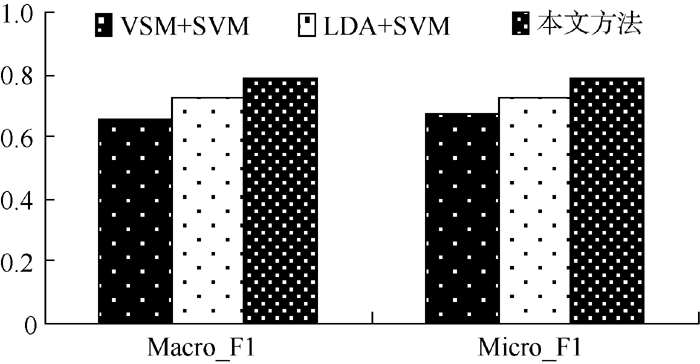 | 图4 不同分类方法在Sogou语料上的分类性能比较 |
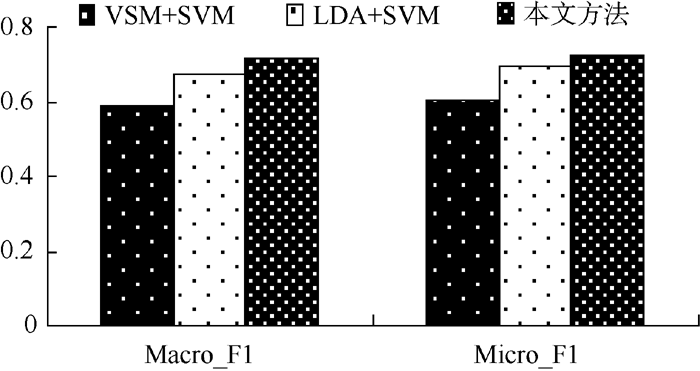 | 图5 不同分类方法在微博语料上的分类性能比较 |
实验结果表明, 基于VSM的分类算法对短文本分类效果并不理想。由于短文本描述信息弱, 基于概率主题模型的分类算法准确率也未能达到满意的效果。与LDA模型结合SVM分类算法相比, 本文提出的分类算法在Macro_F1和Micro_F1均有所提高, 具体如表4所示:
| 表4 本文方法分类性能在LDA基础上的提高情况 |
(2) 实验二
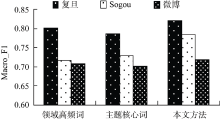
比较本文方法与只采用领域高频词和主题核心词进行特征扩展的方法, 实验结果如表5和图6-图7所示:
| 表5 三种不同特征扩展方法在三个语料库上的分类性能比较 |
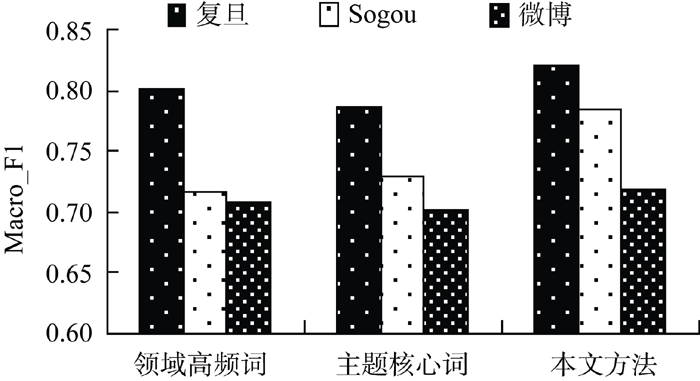 | 图6 不同特征扩展方法在各语料上的 Macro_F1比较 |
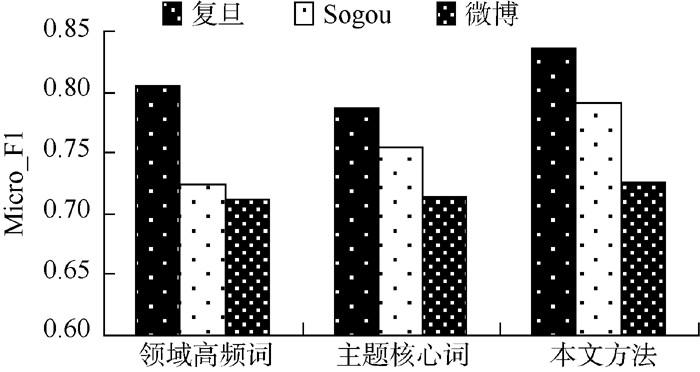 | 图7 不同特征扩展方法在各语料上的 Micro_F1比较 |
实验结果表明, 在复旦语料上, 基于领域高频词扩展的分类结果高于基于主题核心词扩展的方法; 在Sogou语料上, 基于主题核心词扩展的方法分类性能优于基于领域高频词扩展的方法; 在微博语料上, 二者分类效果相当。本文方法优于领域关键词集, 分别只包含领域高频词和主题核心词的方法。
综合以上实验可以得出, 利用领域关键词集对短文本隐含信息进行挖掘和补充, 能有效提高短文本的分类效果; 结合领域高频词和主题核心词的特征扩展方法分类性能优于仅使用领域高频词或主题核心词进行特征扩展的方法。
本文提出一种基于《知网》和领域关键词集的短文本分类算法, 该算法结合不同特征粒度提取训练集各类别的关键词, 在较细粒度的特征词上, 通过特征词词频统计获得训练集各类别的领域高频词; 在较粗粒度的隐含主题上, 采用概率主题模型提取各类别的主题核心词。合并领域高频词和主题核心词, 删除重复特征词, 形成领域关键词集, 利用该领域关键词集, 结合概率主题模型扩展测试集文本特征, 借助《知网》计算文本语义相似度, 并在此基础上预测待分类文本的类别。本文方法通过对测试集文本进行特征扩展, 在保持短文本原有语义的前提下, 更加丰富了文本内容。实验结果表明, 本文方法取得了较好的分类效果。但也存在一些不足, 由于《知网》词典只包含6万多个词汇, 短文本中存在很多《知网》未收录的特征词, 无法利用《知网》计算相似度, 影响分类效果。因此, 下一步工作是利用《知网》结合其他算法(如匹配算法), 提高短文本语义相似度计算的准确性与分类效果。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|