

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于结构和编辑历史的Wikipedia信任模型*
[李慧, 相华婷 , 汤强]
, 汤强]
, 汤强]
|
|


作者简介:李慧: 提出研究思路, 论文版本修订; 李慧, 相华婷, 汤强: 设计研究方案; 相华婷: 采集数据, 起草论文; 汤强: 清洗和分析数据, 进行试验。
[Objective] Accurately calculate the credibility of the Wikipedia entry. [Methods] This paper builds a trust evaluation model which makes a comparison between the current version and their historical version by the text analysis to obtain each version of the edior’s effective edit content, and combined with the number of reference and image in the current version of the Wikipedia article. [Results] It shows that the model is able to distinguish the high trust Wikipedia article and low trust through empirical research. [Limitations] The entry level threshold by this algorithm is not very obvious to distinguish the two types of B level and C level. [Conclusions] The algorithm is simple and effective, and can understand the changing process of entry from the microscopic level, dynamically compute its trust value.
Wiki是一种多人协作的写作工具, Wiki站点可以由多人维护, 每个人都可以发表自己的意见。Wikipedia是Wiki技术应用的一个典型范例, 它是一个协作开放的百科全书, 并已快速发展为互联网上最大的参考资料查询网站, 其内容可以与大英百科全书媲美[1], 同时该网站在全球所有的网站中排名第5位[2]。但是, 由于Wiki技术的开放性, 也给Wikipedia带来了很多弊端, 越来越多低质量的词条涌现, 导致Wikipedia中词条的可信度成了一个大家质疑的问题[3]。所以, 找到一种合理的方法来评定词条的质量非常必要。
目前, 国内还未涉及对Wikipedia词条信任的评估, 但在国外已经成为一个热门的研究领域。国外对词条信任评估主要分为两部分:
(1) 认为词条的信任来源主要在于作者。Lih[4]是最早以系统方式进行Wikipedia中词条质量评估的专家, 他提出基于一个词条的总编辑数及总不同作者数的评估算法, 该算法快速可行但考虑因素较少, 比较粗糙。Zeng等[5]着重考虑了创建该词条版本的作者信誉值, 以及该版本作者所进行编辑操作后插入的文本量以及删除的文本量大小; 在另一项研究中, Zeng等[6]改进延伸了之前创建的词条信任模型, 通过对编辑作者、审查作者以及作者编辑内容存活时间的分析, 建立了一个词条片段信任模型, 来评估整个词条的质量。Hu等[7]提出三种词条质量评价模型: Basic模型认为一个词条的质量由其所有作者的权威性决定; PeerReview模型引入审查行为来衡量词条质量, 经审查阅读的内容即使其创作者的信誉较低, 只要某审查者具有高信誉, 该内容便具有高质量; ProbReview模型则是对PeerReview模型的改进, 该模型认为用户在对词条进行编辑时, 并不都是要阅读整个词条内容, 排除了用户对词条进行编辑但并没有浏览整个词条内容的例外情况。Adler等[8]通过作者信誉值(由声誉系统提供)确定每个单词的信任值, 然后对词条所有单词的信任值进行累积得到词条的信任值[9]。
(2) 认为词条信任主要来源于词条自身文本特征。Blumenstock[10]通过对词条长度测量(单词个数统计)判断一个词条是高质量的特色词条还是普通词条。Wö hner等[11]基于词条生命周期, 通过比较词条整个生命周期中持久贡献和瞬间贡献的变化情况, 判断词条的质量。Moturu等[12]通过评估影响词条内容可靠性的相关特性(如词条长度), 提出一种依靠各相关特性的经验均值, 进而对这些特性进行累积得分的评价方法。
研究发现, 目前对Wikipedia词条信任评估算法的研究在考虑词条信任影响因素方面并不全面, 如Lucassen等[13]发现词条中参考文献与图片的数量和词条文本的大小一样, 对词条信任同样起着举足轻重的作用; Rowley等[14]也同样阐述了参考文献数和图片数对词条信任影响占有很重要的作用。但是目前的研究都没有给出具体的算法。因此, 本文在总结前人研究基础上构建了一个新的词条信任评价模型, 该模型主要考虑词条当前版本参考文献数、图片数, 参与词条编辑的作者信誉值情况及其编辑的有效文本大小。结果表明, 该模型能够很好地区分高质量词条和低质量词条。
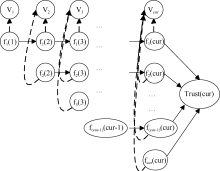
Wikipedia中一个词条会经历多个版本的更迭, 随着版本的不断变化, 文本大小、参考文献数量、图像数量、参与编辑人数等都会跟随着变动, 而且以前所编辑的内容也会随着版本的更迭而产生变化, 如图1[6]所示:
 | 图1 Wikipedia中词条版本演化过程 |
图1中V表示词条版本, fi(j)表示创建词条第i个版本的作者所编辑的内容到第j个版本最终保留的内容, Trust(cur)表示词条当前版本的信任值。
在浏览Wikipedia词条内容时, 呈现给用户的总是每个词条的最新版本, 而用户从这个最新版本并不能看出该词条从最初版本到目前的版本都经历了怎样的发展过程, 而且用户也无法知道最终版本的词条中有多少词条内容是可信的。所以本文将探讨如何来定量评价一个词条版本的信任情况。
(1) 参考文献数和图片数。Lucassen等[13]发现对于词条而言, 参考文献数和图片数越多, 词条的可信度越高。这与Wikipedia中已有的词条等级划分标准对高等级词条的要求一致。所以参考文献数和图片数越多, 词条质量越高。
(2) 插入作者的信誉值和其插入的有效文本大小。目前许多研究[5, 7, 8, 12, 13]已经表明, 信誉值越高的用户, 其插入的文本内容质量越高, 进而其插入的有效文本越大, 对词条质量影响的比例就越大。
(3) 有效文本插入的时间先后。用户对词条修改时会浏览当前词条内容, 赞同的内容保留下来, 而对其认为有问题的内容才会做出修改[7]。这样先插入的有效文本比后插入的有效文本经历更多的审查用户, 继而拥有更高的权威性, 对词条质量的影响更大。
基于以上三个因素的分析, 对于词条当前版本的信任值计算, 本文提出以下的信任评价公式:
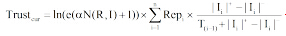
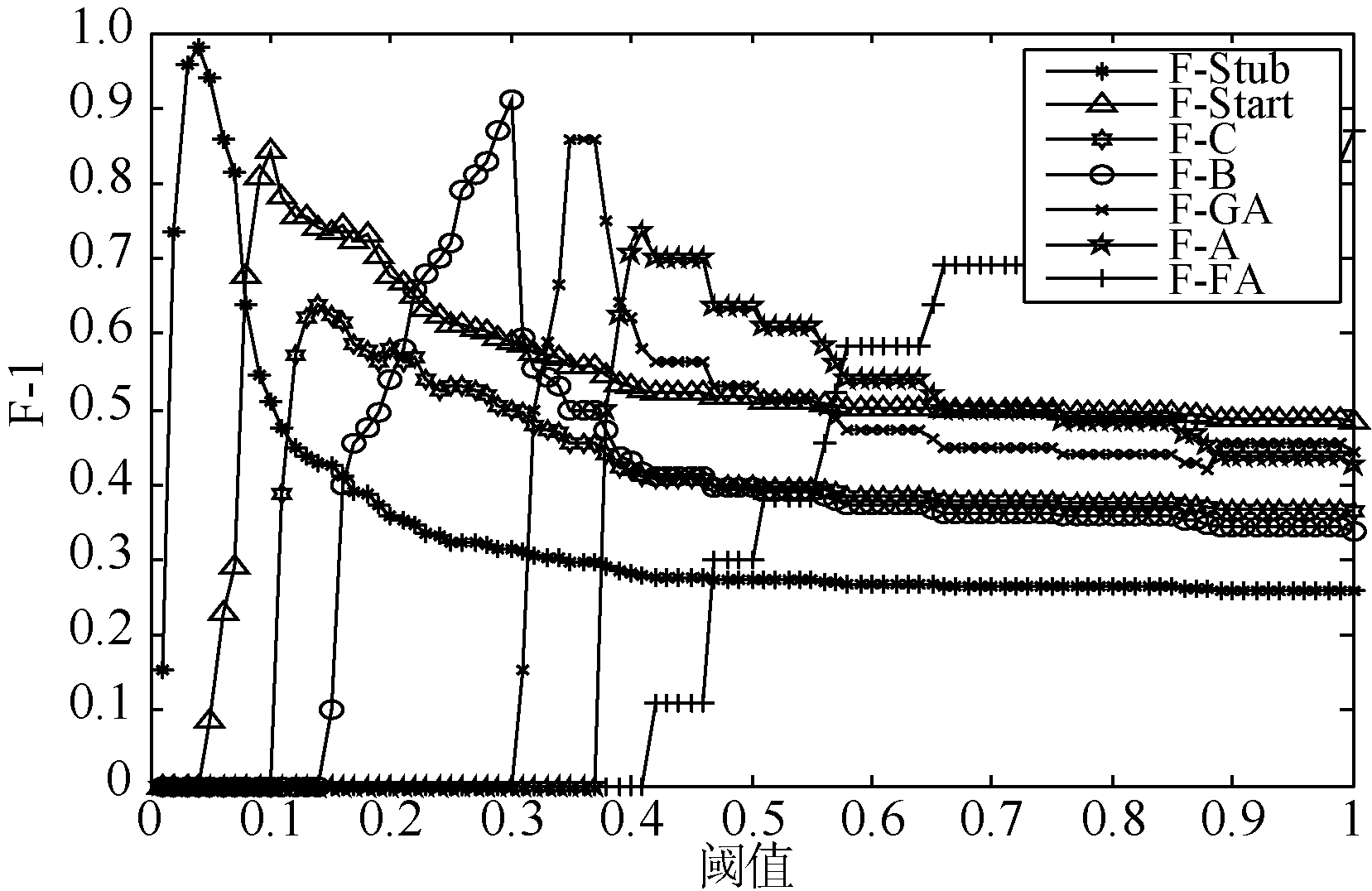
其中, 
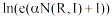
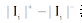
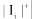


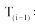
通过公式(1)可以计算出Wikipedia中每一个词条其不同版本各自对应的信任值大小, 并且保证词条版本的每一次变更都能反映在其信任值的变化上; 同时也表明词条信任值的变化是一个动态的过程, 随着作者每一次的编辑, 都会产生内容、图片或参考文献的变化, 从而对词条产生动态的影响。
Wikipedia中被人工操纵后的词条被分为7个等级, 具体等级说明如表1所示:
| 表1 Wikipedia词条等级划分准则[13] |
本文从英文版Wikipedia中随机挑选5个类(Health and fitness、Computing、Religion、Chinese_ history、Mathematics), 并分别收集这5个类中标记有等级的词条(收集每个词条从创立之初到当前版本的所有版本内容进行研究), 具体数据情况如表2所示:
| 表2 数据收集分布 |
将Health and fitness的数据作为训练集, Computing、Religion、Chinese_history、Mathematics 共4个类的数据作为测试集。
(1) 用户信誉值预处理
目前Wikipedia中支持的作者类型有4类: 管理员、注册用户、匿名用户和封禁用户。管理员和封禁用户是Wikipedia中已确定的分别代表高信誉和低信誉的两类用户。Javanmardi等[15, 16]曾对Wikipedia中用户贡献做了实证研究, 结果表明, 注册用户相比匿名用户进行了更多的编辑。基于此, 本文分别赋予这4类作者不同的初始信任值: 0.95、0.7、0.6和0.05。
(2) 词条编辑历史记录预处理
本文对于词条编辑历史数据的处理首先是滤掉由机器人所创建的词条修改版本, 随后, 从余下的词条的每个版本内容中统计出各版本的参考文献数和图片数, 并抽取出相应的作者名和去掉标点符号、停用词、语法标记后的词条正文。接着采用文本分析法让最新版本的词条正文按照先后顺序依次与最初版本、第二版本等各个版本的词条正文进行单词比较, 以获取各版本作者实际插入的有效文本量, 即一个最新版本词条的所有单词也都找到了其插入作者。选择单个的词进行信任值分析, 而并不执行编辑操作后句子的语义分析, 这样算法具有的优点是简单, 并且适合大多数语言。
利用Java编程, 统计出Health and fitness类中每个词条每个版本的实际总文本量、参考文献数、图片数、作者信誉值及其插入的有效文本量, 各等级之间词条信任相关因素的曲线分布如图2所示, 数据经过归一化处理, 处理方式是用词条某因素的值比上所有词条该因素值的平均值。
 | 图2 各等级之间词条信任相关因素的曲线分布 |
由图2发现对于参考文献数和图片数, 等级之间明显由高到低存在递减的趋势, 这符合本文模型构建时的假设。而作者信誉平均值却是先递减再升高的趋势。这可能是因为FA、A、GA这样代表高质量的词条处于成熟阶段, 关注的人比较多, 这其中包括一定数量的管理员, 编辑次数会减少且绝大多数是作者进行的小编辑; B和C等级的词条, 由于正处于发展阶段, 词条内容很不稳定, 编辑次数处于较高的水平, 而且都是一些大的编辑, 其中可能有一些捣乱者的介入导致作者的总体平均值下降; 而对于Start和Stub等级的词条, 正处于知识产生阶段, 往往是由一些该领域的专家来进行词条的框架或草稿提纲创立的[17]。
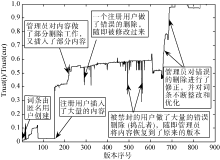
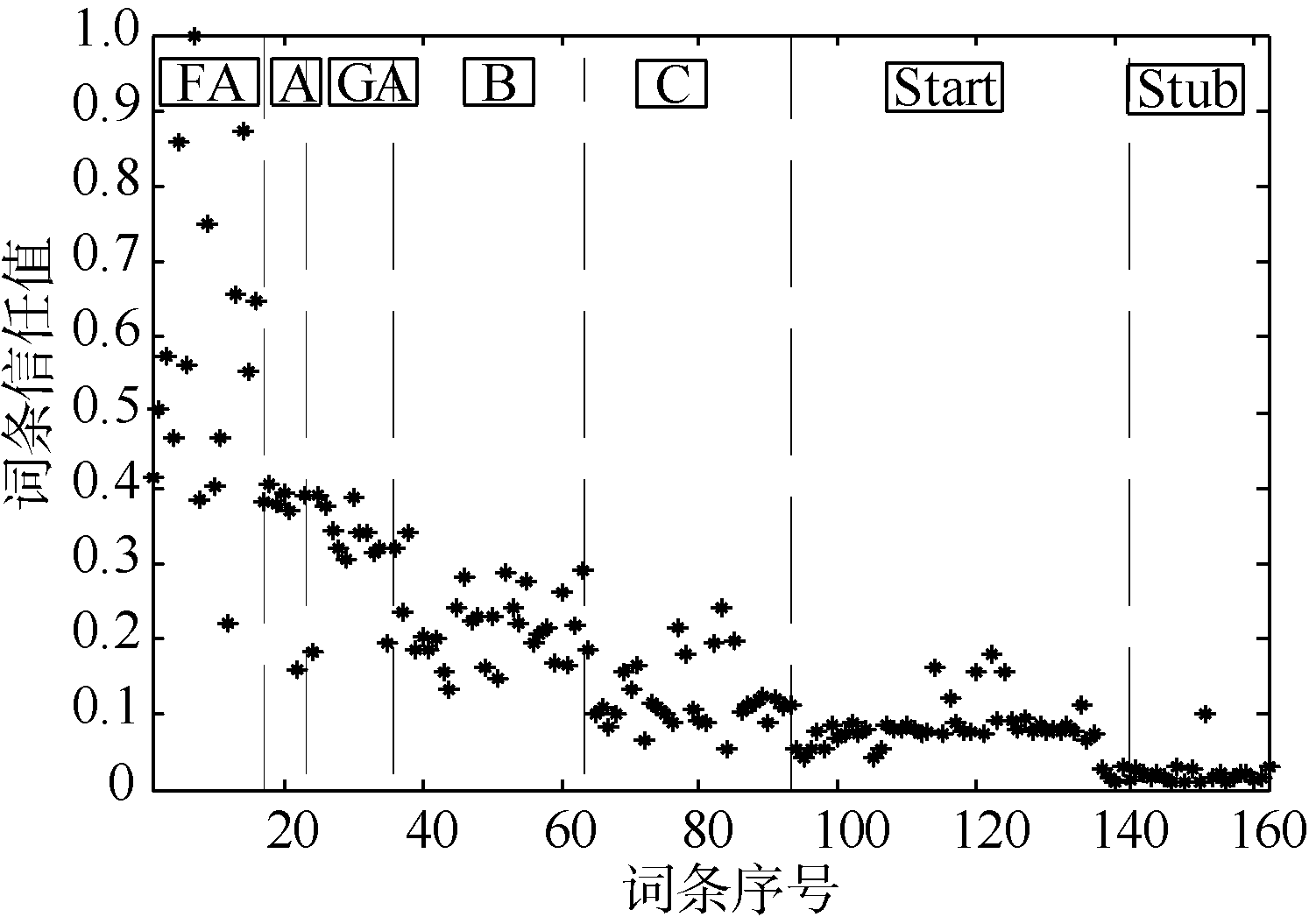
使用Matlab编程(对于控制参数α 本文取0.5), 求得这162个词条的信任值, 信任值经过归一化处理, 处理方式是用每个词条经过计算得出的信任值比上信任值最大的词条信任值, 如图3所示。可见, 采用本文模型计算出的词条信任值和Wikipedia本身的词条等级分类有较高的吻合度, 整体趋势是随着等级由高到低, 词条信任值也逐渐减少。但是个别上存在着差别, 这可能就是主观评价和客观量化评价的区别体现。Wikipedia中, 词条的等级是人们依据已有的词条评价体系在词条的Talk页面对该词条内容进行主观讨论后人工评价得到的, 有一定的说服力, 但是有很大的主观色彩, 而本文给出的词条信任值评价模型能够很好地区分词条间的差异, 而且词条信任值的计算依据词条的版本演化逐步累积得到, 更能从微观层面了解词条的变化过程, 如图4[5]所示, 展示了这162个词条中, 词条名为Frank Macfarlane Burnet的信任值随版本变化情况, 共经历了858个版本的更迭。
 | 图3 词条信任值分布 |
 | 图4 Frank Macfarlane Burnet的信任值 随版本变化示例 |
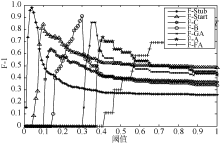
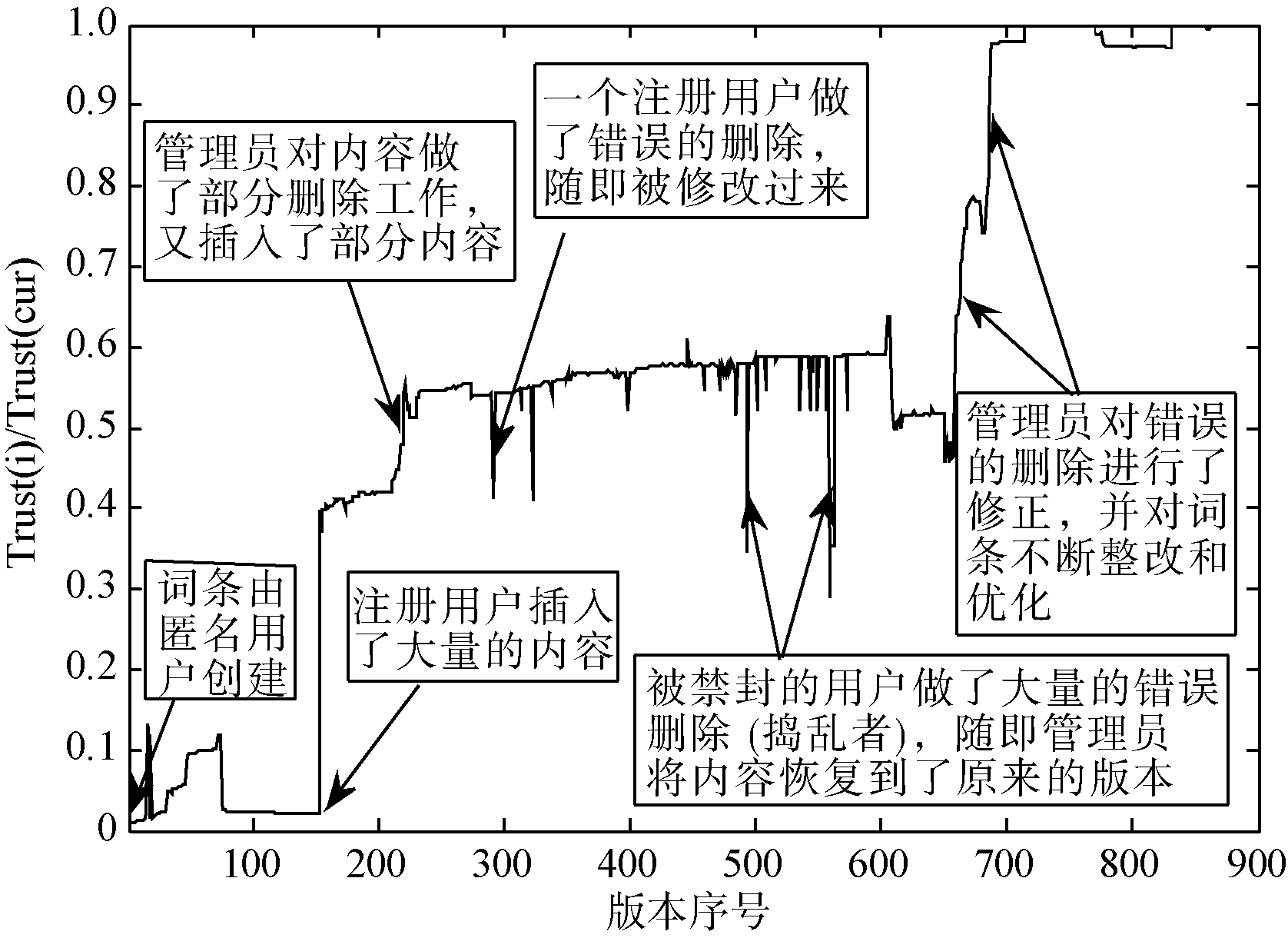
图4展示了词条名为Frank Macfarlane Burnet的信任值随着版本变化的过程, 对一些典型的操作进行了标注, 该模型对词条信任的检测是一个动态过程, 对不同作者以及不同的操作都有不同的反应。但是本文的终极目的是根据词条的信任值对词条进行自动分类, 分类结果就像Wikipedia原有的等级分类一样。依据Wikipedia本身的词条等级分类, 采用F-measure作为评价指标, 进而找出等级之间的最优阈值, 如图5所示:
 | 图5 词条F-measure值分布 |
从图5看到对于每一个类别的F值都是一个先上升后下降的过程, 对于每一个最高点可以认为是两类词条的最优划分阈值, 从低到高分别是0.04、0.1、0.14、0.30、0.37、0.41, 具体的数据分析结果如表3所示:
| 表3 阈值划分结果 |
在以上的实验中使用Health and fitness中收集的词条数据作为训练集对词条的等级进行划分。为了验证划分的准确性, 以其他4个类的数据作为测试集合对结果进行验证, 如表4所示。可以看到, 利用3.3节训练集所得出的阈值, 在其他4个类等级划分所对应的F值同样很高, 除了B和C之间的F值低于80%以外, 其他类之间几乎都高于80%。这也说明了该模型的可靠性与准确性。
| 表4 模型验证结果 |
目前有关Wikipedia词条信任的研究成果在考虑词条信任的影响因素方面并不全面, 而且多数算法使用的信任因素比较单一, 如文献[4, 7, 9-10], 而影响因素考虑较全面的算法如文献[12]因为要计算词条所有信任因素的平均值, 具体实现会很复杂。相比之下, 本文构建的词条信任算法更精确且简单易操作。
在之前研究者提出的方法基础上, 本文综合考虑了当前版本参考文献数、图片数、词条发展变化过程中参与作者的信誉情况及其编辑的有效文本大小, 构建了一个词条信任评价模型。并利用英文Wikipedia中Health and fitness类中的7个等级共162个词条作为训练集, 实验分析表明本文构建的词条信任评价模型能够很好地区分高质量的词条和低质量的词条, 然后利用计算得出的词条信任值对该训练集各等级的词条进行R、P、F-measure值的计算, 利用F-measure值找出词条7个等级之间的最优阈值, 最后为了评估模型分级的结果, 利用其他4个类的数据作为测试集进行进一步的验证, 在此阈值分级下, 除了对等级B和C区分得不是很明显, 其他等级之间都呈现出较好的效果。
未来进一步的研究工作包括: 继续调查研究其他影响词条信任值的因素, 并将其引入到模型计算中; 构建用户信任模型, 依据用户在Wikipedia中的编辑情况, 对参与词条编辑的作者给予精确的信誉值。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|