

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
一种基于类别描述的TF-IDF特征选择方法的改进*
[徐冬冬 , 吴韶波]
, 吴韶波]
, 吴韶波]
|
|


作者简介:徐冬冬: 设计研究方案, 进行实验, 撰写论文; 吴韶波: 提出研究思路, 设计论文框架, 论文修订。
[Objective] Improve the text categorization accuracy by modifying the weighting approach in feature selection. [Methods] Introducing the inner and outer categorical information, and modifying the TF-IDF weighting, this paper proposes the TF-IDF-CD approach which based on the categorical description. Combining TF-IDF-CD with varied classifiers, such as NB and SVM, this paper conducts text categorization experiment in balanced corpus and unbalanced corpus respectively. At last, the accuracies of different weighting approaches are compared with TF-IDF-CD. [Results] The TF-IDF-CD performs well even when there are a less number of feature items. Compared to the TF-IDF, when combined with varied classifiers in different corpus, the TF-IDF-CD can greatly improve the average accuracies. The minimum increase is 14%, and the maximum up to 30%. Compared to the CTD approach, when combined with NB, SVM, and DT, the TF-IDF-CD could improve the the average accuracy of TC from 1% to 13%. But, in unbalanced corpus, when combined with KNN, the performance of the TF-IDF-CD is 2% lower than CTD. [Limitations] Combined with KNN classifier which is sensitive to the skew data, the TF-IDF-CD needs to be improved to resist the skew characteristics of unbalanced corpus. [Conclusions] Experiment resualts show that the TF-IDF-CD approach is effective.
文本分类(Text Categorization, TC)是在信息化趋势下应运而生的分类技术, 作为文本资源处理的一种重要方法, TC广泛应用于数字图书馆、文本资源分类组织管理以及文本信息过滤等领域。
在文本分类技术中, 普遍使用的文本表示方式是向量空间模型(Vector Space Model, VSM)。VSM是20世纪60年代末由Salton等[1]提出的, 是当前自然语言处理中的主流模型。用向量空间模型表示文本, 要对文本进行分词, 进行特征选择和权重计算, 形成一个N维的空间向量。权重计算方法的优劣直接影响文本分类算法的整体性能。
词频-反文本频率(Term Frequency-Inverse Document Frequency, TF-IDF)是一种经典的基于VSM模型的权重计算方法, 其算法相对简单, 便于计算, 应用较为广泛。但该方法比较粗糙, 容易导致特征空间高维稀疏。基于传统的TF-IDF特征选择方法, 本文引入类别描述因子(Category Description, CD), 提出一种包含类别信息的TF-IDF-CD特征选择模型。该模型含有特征项的类内、类间频数信息, 可以提高类别贡献大的特征的权重, 降低次要特征权重。通过文本分类实验验证改进算法的分类效果。
特征权重主要利用文本的统计信息进行计算, 如词或其他文本单元的频率等, 文献[2]认为适用于表示特征的权重因子有以下三个:
(1) 词频因子, 出现在文本中的词能够在一定程度上表征该文本。
(2) 文本集频率因子, 单独的词频因子不能合理体现相关文本与非相关文本间的差异性, 引入文本集频率因子可提高特征的区分能力。
(3) 标准化因子, 使用Cosine对文本长度进行标准化。
通常将词频因子和反比文本因子相乘来提高准确率(Precision)和召回率(Recall)。表1总结了几种常用的词频和文本集频率因子以及常用的权重因子组合。
| 表1 常用的特征权重因子 |
(1) Binary计算简单, 多应用于朴素贝叶斯(Naï ve Bayesian, NB)和决策树(Decision Tree, DT)等无需利用权重数值的算法中。
(2) tf直接以特征项在文本中出现的次数为权重。
(3) log tf引入对数函数平衡对高频词的过度依赖。
(4) 受IDF启发, 文献[3]提出了反词频(Inverse Term Frequency, ITF)的概念。
四种词频因子Binary、tf、log tf、ITF皆可以单独应用于特征权重的计算, 其效果无明显差别[4]。故在词频因子方面, 本文选取较常用的tf因子进行研究。
文本集频率因子中, 1表示忽略文本集频率因子, N是文本集中的文本数, nk是包含特征项tk的文本数。一些学者将特征选择方法引入权重计算, 如卡方检验(Chi-square)、信息增益(Information Gain, IG)以及增益比(Gain Ratio, GR)等。文献[5]表明tf· χ 2、tf· ig以及tf· gr并不比tf· idf的特征权重具有更好的性能。文献[4]将tf· idf、log(tf· idf)、tf· idf_prob以及idf与tf权重计算方法进行对比, 结果显示, 前4种权重计算方法的性能并无明显差别, 故本文将tf· idf方法作为研究的重点。
TF-IDF由Jones[6]首次提出, 最早应用于信息检索领域。其计算公式如下:
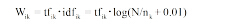 |
其中, tfik指第k个特征项tk在文本i中出现的次数。
TFC[7, 8]权值算法在TF-IDF方法的基础上利用文本长度对其进行规范化处理, 公式如下:
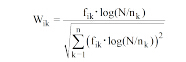 |
为弱化词频差异较大带来的影响, ITC[7, 8]权值法用词频的对数形式代替TF-IDF中的词频, 其形式如下:
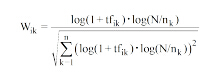 |
Basili等[9]认为IDF部分赋予特征项频率过多的倚重, 故而采用对反词频(Inverse Word Frequency, IWF)进行平方的方法来降低权重公式对特征频率的倚重。
为解决文本集偏斜带来的问题, How等[10]提出基于类别词描述(Category Term Description, CTD)的方法, 利用特征项在类别中出现的总频数替代TF, 使其更好地区分类别信息, 公式如下:
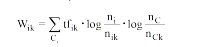 |
其中, C表示所有的类别, 并且有CiC, ni表示类别Ci中的文本数, nik表示类别Ci中包含第k个特征项的文本数, nC表示类别总数, nCk表示含有第k个特征项的类别数。
Xue等[11]叠加IG因子到TF-IDF提出TF-IDF-IG, 继而用EXP因子替代IDF因子得到了TF-EXP-IG, 算法引入特征频率的均值和方差以描述特征项在类别间的分布。Lan等[12]用相关性频率(Relevance Frequency, RF)替代IDF因子, 实验证明, 相比TF因子与其他文本集频率因子的结合, TF-RF的性能更好。周炎涛等[13]将词条信息熵因子引入TF-IDF, 计算特征项在各类之间的分布, 解决了IDF忽略特征项在文本集中分散度的问题。熊忠阳等[14]提出了TF-IDF-DI-WFDB, 通过引入特征项的无偏方差, 描述类内及类间离散度因子, 同时设计一个描述不完全分类情况的词频差异因子, 结合三者以改善IDF, 未考虑类内以及类间分布的缺陷, 此方法计算较复杂。Forman[15]将特征选择中的二元正态分隔(Bi-Normal Separation, BNS)方法引入权重计算, 用BNS替代IDF因子, 其表现优异。张保富等[16]认为特征项的类内和类间分布熵能反映出特征项的分布比例情况, 并引入类别贡献因子对TF-IDF进行改进。李学明等[17]对TF-IDF-IG进行改进, 认为特征项在类内分布熵值的大小与其所能提供的分类信息一致, 提出基于信息熵的TF-IDF-IG-E, 但未能将特征项在类间的分布信息考虑在内。雷军程等[18]将某一具体类的文本频率引入TF-IDF, 提出能够提高特征项类别区分能力的TFIDF_Ci。
为弥补TF-IDF缺乏类内信息的缺陷, Liu等[19]在TF-IDF上叠加了类别频率(Category Frequency, CF)因子, 提出TF-IDF-CF, 计算公式如下:
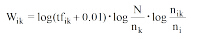 |
其中, nik是第k个特征项所属文本的类别C内包含该词的文本数, nc为类别C内拥有的总文本数。
覃世安等[20]用特征值在类间出现的概率比代替特征值在类间出现的次数比来改进IDF, 解决了文本类的数量分布不均时提取特征值效果差的问题。刘海峰等[21]基于类内分布修改TF项, 从文本频率角度体现特征项的区别能力, 该方法引入均方差修改IDF项。
如前所述, χ 2、IG、GR、IDF方法与TF结合, 其性能无明显差异。本文选取计算简单且较为常用的IDF方法进行研究。公式(5)对IDF修正后, 计算简单, 且性能良好, 本文将实验与其进行对比。在TF因子上, 除文献[10]和文献[21]外, 其他研究都基于类别分布修改IDF或引入类别分布因子来改善特征项的区分性能, 鲜有考虑到改进TF项的类别区分能力。而文献[21]计算较复杂, 故将重点讨论文献[10]的CTD方法, 并与其进行对比。
TF-IDF权重存在明显缺陷, 主要为以下两方面:
(1) 集中性。若特征项在某类中频繁出现, 而在其他类中较少出现, 则该词具有较好的类别区分性, 应赋予较高权重; 相反, 权重应较低。TF-IDF并不能体现这一点。
(2) 均匀性。能够代表一类的特征项应较均匀地分布在该类的大多数文本中。特征项对某一个文本的表现力并不能完全体现其对该类别的区分能力, 传统TF-IDF没有考虑这一点, 进而可能产生与理论相矛盾的结果。
以下例子很好地说明了TF-IDF的缺陷所带来的问题。如表2所示, 有两个类别Ci(i=1, 2), 每类各有三个文本dij(第i类的第j个文本, j=1, 2, 3), 每个文本考虑三个特征项tk(k=1, 2, 3)。
| 表2 特征项在文本中的频数 |
从表2中可以看出, 特征项t1全部集中出现在C1类中, 在C2类中没有出现。从集中性角度考虑, t1对于C1具有较强分类能力, 其在C1类中权重值应较高。观察C2类, 特征项t3在每个文本都有分布, 从均匀性角度考虑, t3比t2对C2的分类能力强, 故t3在C2中权重值应较高。
利用公式(1)的TF-IDF对表2中的特征项进行权重计算, 其结果如表3所示:
| 表3 特征项的TF-IDF权重 |
对于C1类, 特征项t1的权重值小于t2; C2类中, 特征项t3的权重值小于t2, 这与之前的分析相矛盾。究其原因, 是由于文本集中包含特征项t1、t2的文本数目相差不大时, TF-IDF忽略了集中性, 从而导致权重值完全倚重于词频; 特征项t2、t3在C2类中的分布差异性较大时, TF-IDF忽略了均匀性, 从而产生误差很大的结果。
TF-IDF将文本集作为整体来考虑, 其IDF部分并没有考虑特征项的类间分布信息。从之前的分析可知, 类间信息的重要性不言而喻。
类频率(C1ass Frequency, CF)指出现特征项的文本所属类别的个数。通常认为在大多数类中出现的特征项对于类别的区分能力很弱, 其分类作用不大, 应该通过特征选择将其从特征空间中去除; 而只在少数类中出现的特征项类别辨识能力最强。参考IDF, 引入逆类频率(Inverse Class Frequency, ICF)表示特征项的类别辨识能力。其表达式如下所示:
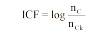 |
其中, nC表示文本类别总数, nCk表示包含第k个特征项的类别数目。当特征项只出现在一个类别中时, 其ICF达到最大值lognC。特征项出现的类别数越多, nCk越大, 其ICF越小, 即其类别区分能力越弱。
IDF是从文本频数角度反映含有特征项tk的文本频数与总文本数目之比, 体现在信息论上反映的是特征项的文本表现能力的熵值这一信息。ICF是从类别频数角度反映含有特征项tk的类别频数与总类别数目之比, 体现在信息论上反映的是特征项的类别表现能力的熵值这一信息。ICF的加入, 使权重计算公式可以充分利用特征项在类别之间的分布信息。
TF-IDF将特征项作为个体来考虑, 而单个文本中的特征项信息并不能完整体现该类别的全部信息。特征项在某类中是否呈高值分布、分布是否均匀都关系到该特征项的权重计算是否合理。
由于TF仅能体现特征项的文本表现力, 文献[10]用特征项在Ci类中的总频数替代TF频数, 以提高其类别表现能力。然而该方法并未考虑特征项在其他类别中的总频数。因此, 引入特征项的类别比率(Category Ratio, CR)因子, 如公式(7)所示:
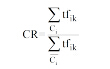 |
其中, 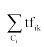
若特征项只是以较大频数分布在类内的少数几个文本, 并不代表该词具有良好的区分能力, IDF作为平衡因子可以保证分布在较多文本中的特征项的权重较高, 二者结合可保证特征项在类内分布的均匀性。
结合公式(6)和公式(7), TF-IDF改进为基于类别描述(Categorical Description, CD)的权重计算公式TF-IDF-CD, 如公式(8)所示:
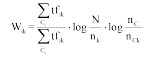 |
下面对传统TF-IDF、CTD、TF-IDF-CF以及本文提出的TF-IDF-CD进行对比, 因TFC与ITC均为TF-IDF的变形, 故仅讨论TF-IDF。
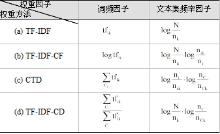
 | 表4 不同权重方法的权重因子对比 |
在词频因子方面, (a)和(b)均采用单个文本中的词频来表示, 而(c)和(d)均采用类别中的词频总数。二者分别从个体角度和整体角度体现特征项的类别表现能力。从理论上讲, 后者可提供更丰富的类别信息。(c)和(d)的不同之处在于(c)只考虑了特征项的类内总频数, 而(d)还包含了特征项在所属类别外部的频数信息, 这样结合类内和类间分布的差异性, 比单一描述类内信息能更完整地体现特征项的类别辨识能力。
在文本集频率因子方面, (a)和(b)均从文本角度保证特征项只出现在少数文本中, 而(c)和(d)的第一项是从文本角度描述特征项的文本频率, 第二项是从类别角度描述特征项的类别比率, 其类别表现能力更强。二者的不同之处为(c)仅对特征项类内信息进行描述, 不包含特征项在其他类别中的类外信息, 而(d)二者兼顾。
可见, (d)在对词频因子和文本集频率因子的计算上都是从特征项的类内及类间信息两方面入手, 兼顾集中性和均匀性。在传统TF-IDF的基础上, 修改词频因子为CR因子, 该因子含有特征项的类内文本分布信息, 在文本集频率因子部分加入包含类间分布信息的ICF因子, 这种基于类别描述的改进, 充分利用了特征项与文本在类内的统一与类间的差异, 包含更丰富的类别描述信息, 弥补了传统模型在理论上的不足。
根据改进后的权重计算公式TF-IDF-CD, 对表3进行重新计算, 其结果如表5所示:
| 表5 特征项的TF-IDF-CD权重 |
可见, 在C1类中, TF-IDF-CD提高了t1权重, 降低了分布较分散的t3的权重; 同时, 在C2类中, t3的权重得到突出, t2的权重得到抑制。TF-IDF-CD在此例中有效提高了各特征项的类别区分能力。
最知名的英文标准文本集是根据经济新闻报道归类的路透社集(Reuterrs-21578)[22], 其他常用的标准文本集包括收集大约20 000篇新闻文本的20个新闻组文本集(20 Newsgroups)[23]、来自医药信息数据库MEDLINE10的医学文摘文本集(Ohsumed)[24]以及加州大学欧文分校创建的机器学习文本集(UCI Repository)[25]等; 常用的中文标准文本集有搜狗文本集[26]、中国科学院TanCorp文本集[27]、复旦大学文本集[28]等。除以上标准文本集之外, 还有用于垃圾邮件测试与网页数据测试的专用文本集。
相比之下, 国外文本集规模大、较规范、使用者多, 国内在文本集建设方面还有待加强, 特别是有影响的文本集不多。本文主要面向新闻文本的分类, 故采用Reuters-21578和20 Newsgroups两种基准文本集。
(1) Reuters-21578是最重要的基准文本集, 按照MogApte划分方式, 包括9 603篇训练文本和3 299篇测试文本, 分别有118个和93个类别[22]。该文本集采用多标签分类, 另外该文本集的文本存在数据偏斜, 数目最大的earn类中含有2 877篇文本, 而castor-oil类中只有1篇, 本文在剔除文本数小于10的类别后, 随机选择其中20个类进行实验。
(2) 20 Newsgroups是均衡文本集, 文本均匀分布在20类中, 每类包含1 000篇文本。其中, 有些类非常相近, 例如分别表示PC与MAC硬件信息的comp.sys.ibm.pc.hardware类与comp.sys.mac.hardware类; 而有些类几乎完全无关, 如分别表示销售信息与基督教的misc.forsale类与soc.religion.christian类[23]。
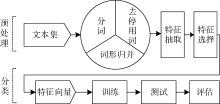
文本分类实验由文本预处理、文本分类、分类质量评估三步组成, 如图1所示:
 | 图1 文本分类实验流程 |
具体实验步骤如下:
(1) 在文本预处理阶段, 通过分词、去停用词、词形归并, 构建符合VSM模型需求的特征项集合。
(2) 特征抽取和特征选择。利用权重计算, 将能够表示文本特征的信息项通过VSM表示为空间向量形式。经过特征抽取的文本特征集一般较为庞大, 通过特征选择进一步降低其维度。实际操作中, 这两步通常在同一过程中进行。在权重计算方面, 本文将改进的TF-IDF-CD算法与几种较常用的权重计算方法进行对比。特征选择时, 将特征项按其权重大小降序排列, 取前m项构成特征向量空间, 其中特征项个数m与文本总长度n的比值依情况而定。
(3) 选择适当的分类方法, 完成训练过程。根据文本集的特点, 选择适当的分类方法, 在训练集上对其进行训练。本文采用综合性能较为优异的NB、K近邻(K-Nearest Neighbor, KNN)、支持向量机(Support Vector Machine, SVM)等方法。
(4) 利用训练好的分类方法对测试集进行分类。本文采用十折交叉验证来划分训练集与测试集。对于每种权重方法, 分别进行10次十折交叉验证, 并取均值。
(5) 对分类结果使用分类指标, 评估分类方法的性能。对于二元分类问题, 常用的评估指标有正确率(Precision)、召回率(Recall)、均衡点(BEP)、F测度值(Fβ , 常用F1)和精确度(Accuracy)等。其计算方法如表6所示, A为属于某个类别且被分类至该类别的文本数, B为不属于某个类别却被分类至该类别的文本数, C为属于某个类别却没有被分类至该类别下的文本数, D为不属于某个类别且没有被分类至该类别下的文本数。
由于正确率、召回率与Fβ 都是针对某一类别进行评价, 因此, 对于多元分类问题, 为了评价算法在整个文本集上的性能, 通常对单个分类方法的分类指标进行宏平均或微平均。其计算方法如表7所示, 其中β 为调整参数, 实际中常取β 为1得到F1。宏平均是每一个类的性能指标的算术平均值, 容易受小类影响; 微平均是每一个实例(文本)的性能指标的算术平均, 容易受大类的影响。考虑到文本集的每个类中文本数目有可能相差非常大, 因此, 本实验采用精确度作为评估指标。
 | 表6 分类结果的评估指标-1 |
 | 表7 分类结果的评估指标-2 |
为了验证改进的特征选择方法的性能, 将TF-IDF-CD与TF-IDF、TF-IDF-CF和CTD权重计算方法进行对比。
任选取某一类, 如C0类, 比较在不同权重计算方法下该类的特征项, 在此, 仅比较差异特征项(只存在于目标权重方法, 未在其他权重方法下产生的特征项), 如表8所示:
| 表8 不同权重方法下的特征词表 |
其中, TF-IDF产生的特征项与其他方法的差异最大(在本文未列出的其他类别中其差异也最大)。可以看出, TF-IDF方法产生的特征项中包含大量无特殊意义的数字, 究其原因, 主要如文献[9]中所述, IDF过于倚重特征频率。相比之下, TF-IDF-CF与其他方法的特征项差异稍小。重点比较CTD与TF-IDF-CD的特征项。
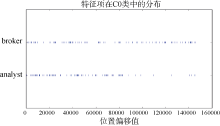
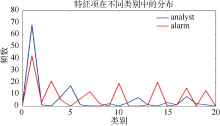
观察表8的特征项表, CTD及TF-IDF-CD滤除了一部分TF-IDF中不适合作为特征项的数字及单词, 这主要归功于二者都引入类内信息, 提高了类别贡献大的特征权重, 一定程度滤除了均匀性较差的次要特征。另外TF-IDF-CD还引入了特征项在类外的频数信息, 用以保证其集中性。分别以CTD和TF-IDF-CD特征列表中的broker和analyst特征项为例, 比较它们在类内分布的均匀程度, 如图2所示, 二者在C0内的大多数文本都有分布; 比较二者在各类中的频数分布, 如图3所示, 特征项analyst的分布主要集中在代表C0类的主瓣中, 在旁瓣中虽有分布, 但瓣数较少且其值较小。特征项broker频数的最大值也位于主瓣, 但其在旁瓣中也分布较多且频数相对较高。结合图2和图3, 可以判断出analyst比broker更适合被选作特征项。
 | 图2 特征项在C0类中的分布 |
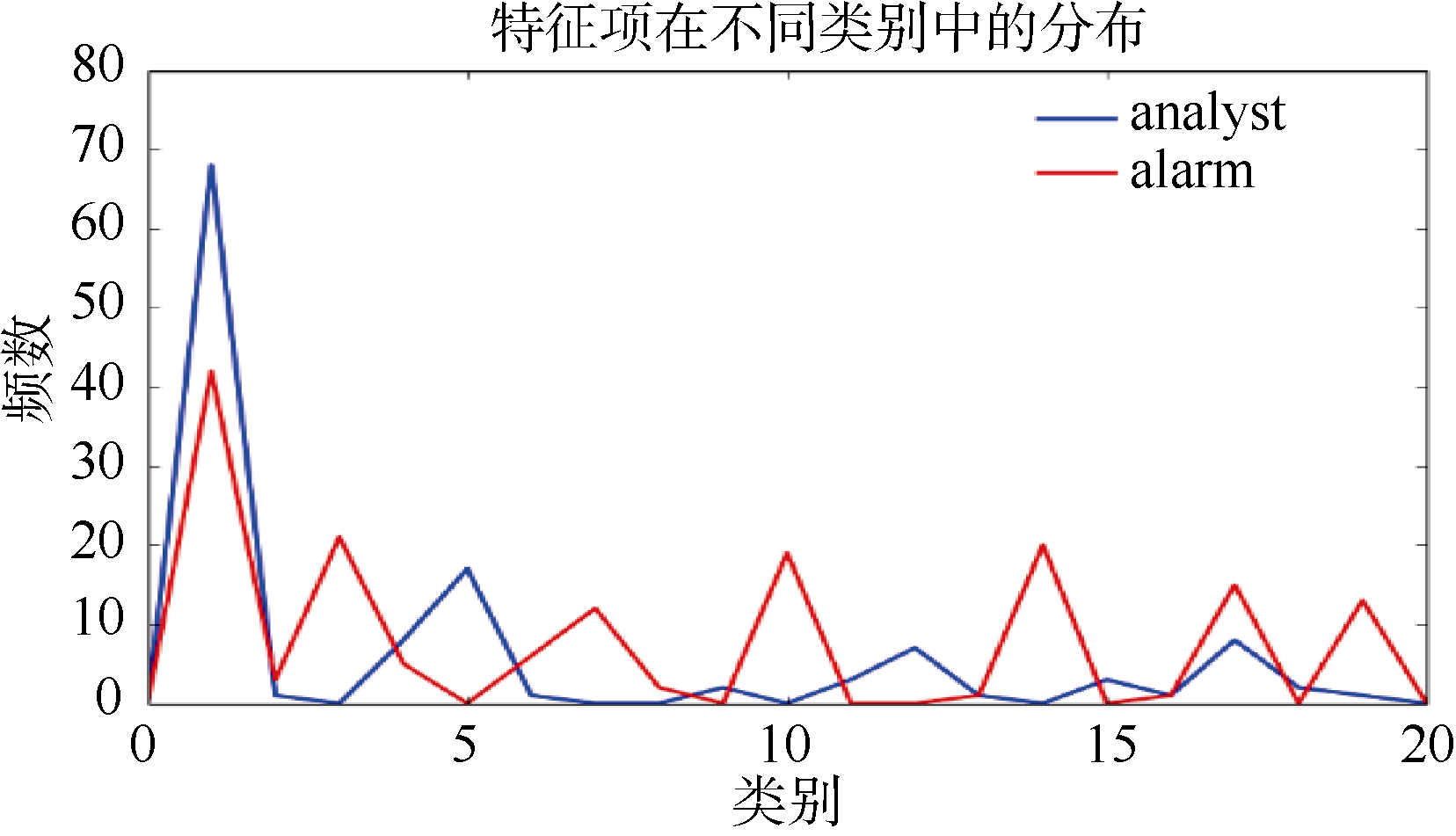 | 图3 特征项在不同类别中的分布 |
从表8可以看出, TD-IDF-CD权重计算方法确实做了如3.3节所分析的选择。TF-IDF-CD在词频因子上兼顾了类内和类外的频数分布, 通过文本集频率因子的修正, 赋予analyst和broker较合理的权重, 继而将broker从其特征空间滤除; 而CTD在词频因子部分对类内总频数有过高的倚重, 与文本集频率因子的叠加甚至加大了权重的误差。
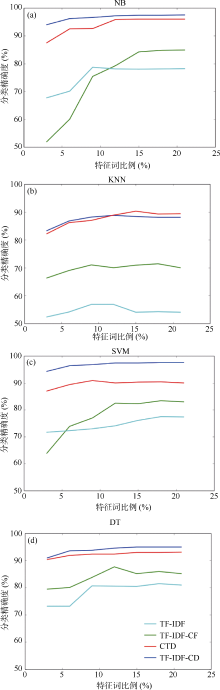
将4种权重方法依次与NB、KNN、SVM、DT分类方法叠加, 如图4所示, 其横坐标表示特征项所占文本长度的比例, 纵坐标表示各个类下的平均分类精度。
 | 图4 不同权重方法与不同分类方法叠加的 文本分类实验结果 |
从图4可以看出:
(1) TF-IDF-CD权重计算方法具有优异的特征选择性能。如图4(a)所示, 在采用SVM分类方法时其性能最好, 平均分类精度较其他三种权重方法中表现最好的CTD方法亦高出约8%; 如图4(b)和4(c)所示, 在NB和DT分类方法下, 其分类精度也比CTD方法高出约3%。如图4(d)所示, 在采用KNN分类方法时也取得了较好的结果, 但总体比CTD算法低约2%。
(2) TF-IDF-CD权重计算方法性能稳定。在4种分类方法下, 随着特征维数的逐渐增大, TF-IDF-CD的性能平稳, 并没有出现较大波动。而且只需较少特征项, 便可达到较好的分类效果。
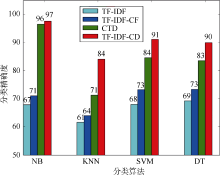
由图2可知, 当特征项占文本长度10%时, TF-IDF- CD的性能已较好且基本稳定。因此, 在20 Newsgroups文本集上, 实验的特征项取10%。TF-IDF、TF-IDF-CF、CTD和TF-IDF-CD分别与NB、KNN、SVM、DT分类方法结合进行对比实验, 如图5所示, 其横轴表示不同分类方法, 纵轴表示平均分类精度。
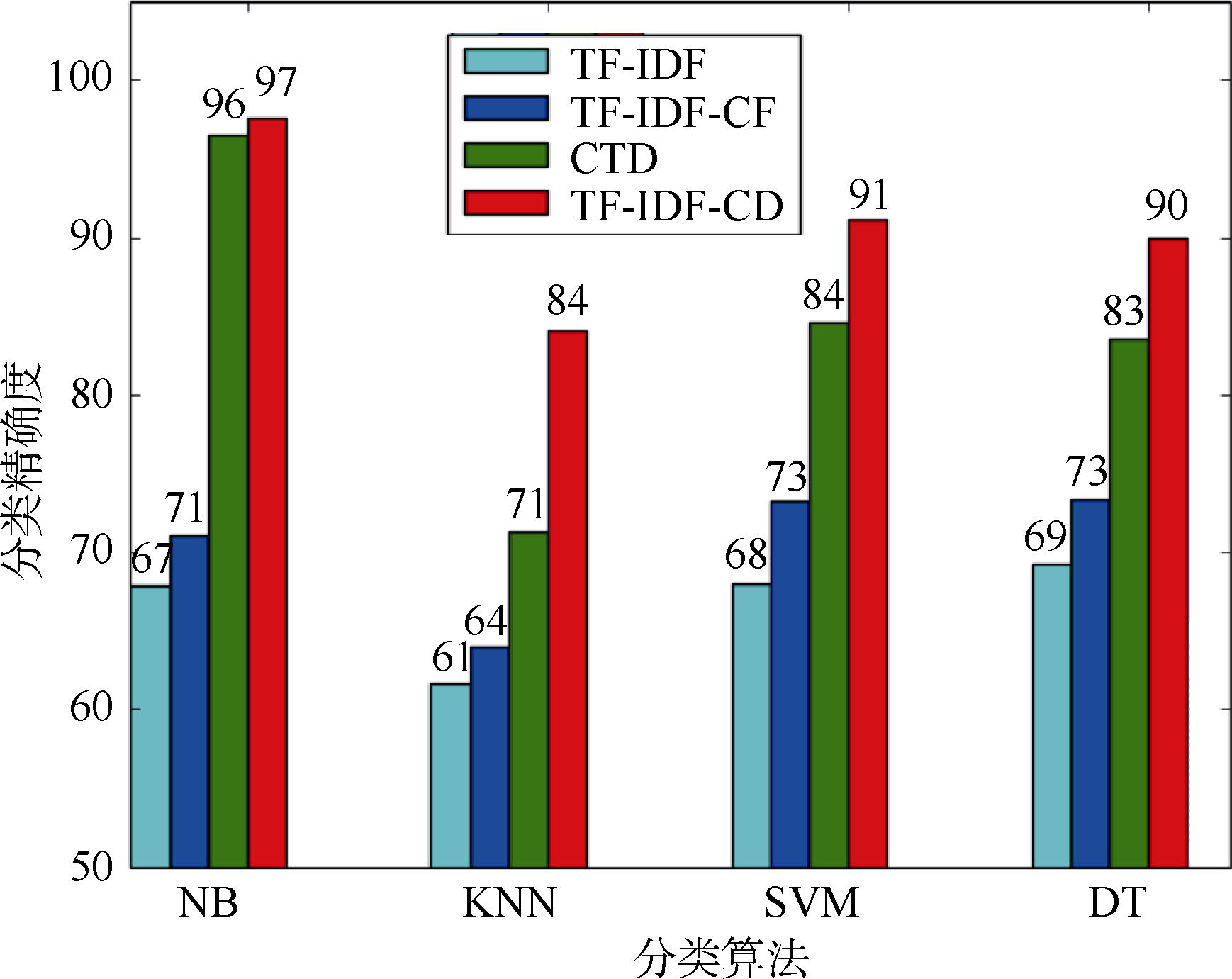 | 图5 不同分类方法在20 Newsgroups下的 分类实验结果 |
如图5所示, TF-IDF-CD在4种分类方法下较其他权重方法都具有更好的性能, 尤其是在KNN分类方法下, 其分类精度比CTD高出13%。对比在文本集Reuters-21578上, TF-IDF-CD与KNN结合其分类精度较CTD低约2%, 分析其原因, 主要是因为Reuters- 21578文本集数据偏斜, 且KNN算法本身易受样本不均衡的影响, 当输入一个小容量类的样本时, 该样本的K个邻居中大容量类的样本占多数, 导致误分类。同时, CTD算法为弥补数据偏斜的缺陷, 在词频因子上对类内词频高度倚重, 故其在Reuters-21578上的性能更好; 而在NB、SVM、DT分类方法下, 也正由于CTD对类内词频的过度依赖, 导致其性能不如TF-IDF-CD。
本文以特征项的权重计算为研究对象, 总结了现有的方法, 对TF-IDF做了详尽的研究。从类内和类间信息两方面着手, 在词频因子部分引入包含特征项类内信息的CR因子, 在文本集频率因子部分引入包含类间分布信息的ICF因子, 从词频、文本频率、类别比率三个角度来计算特征项的权重, 包含丰富的类别信息, 弥补了传统模型的不足。
分别对常用的基于TF-IDF、TF-IDF-CF、CTD的特征选择和基于TF-IDF-CD的特征选择进行文本分类实验, 证实了改进的有效性。实验结果表明:
(1) 在均衡文本集下, TF-IDF-CD方法包含的丰富类别信息, 使权重计算更合理, 性能更稳定, 且只需较少特征项便有较好性能。
(2) 在非均衡文本集下, TF-IDF-CD与NB、SVM、DT三种分类方法的结合效果较理想, 与KNN结合时, 相比CTD算法, TF-IDF-CD受数据偏斜的影响较大。正因为TF-IDF-CD在类别描述上需要丰富的类别信息, 因此对于数据偏斜文本集, TF-IDF-CD从小类集合中获取的类别信息相对较少, 虽然能在一定程度上改善数据偏斜带来的类别表现能力缺陷, 但是与对数据偏斜较敏感的KNN算法相比, 其性能较差。因此, 下一步应当考虑特征项词形、在文本中位置信息等, 在现有的基础上提出更有效的方法。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|