


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于动态标签-资源网络图的信息资源推荐*
[王忠群 , 蒋胜, 修宇, 皇苏斌, 汪千松]
, 蒋胜, 修宇, 皇苏斌, 汪千松]
, 蒋胜, 修宇, 皇苏斌, 汪千松]
|
|


王忠群, ORCID: 0000-0002-5307-5706, E-mail: zqwang@ahpu.edu.cn。
[Objective] To solve the problem that recommender systems recommend outdated information resources to the target user. [Methods] This paper proposes an individual recommendation method for information resource based on dynamic tag resources network graph. Firstly, resource network graph is established to form resource semantic relationships, using common tags in two resource objects as a link pairwise. Secondly, tag network graph with time is created to describe users’ interest drifting using the links in resource network graph. Thirdly, top N information resource objects are recommended to target user from tag network graph by matching target users’ dynamic tags describing users’ interest drifting. [Results] In MovieLens data set, the experimental results show that this information recommendation method can trace and predict users’ interest drifting, and recommend accurate resource to users. Mean Absolute Error (MAE) is lower than the traditional methods by about 15%. [Limitations] The method does not involve the problem that information resources are recommended under real-time dynamic environment such as information retrieval with users’ interests drifting rapidly. [Conclusions] The proposed method can recommend more accurate information resource to users with interest drifting.
互联网带来信息量的急剧增长, 信息过载已成为人们面对的一个巨大挑战[1]。推荐技术是解决信息过载问题的一种有效方法[2]。但仍然存在诸如推荐过时、推荐精度低等问题。
个性化推荐系统主要依据个人信息、历史行为等特征构建用户的兴趣模型, 继而为目标用户进行推荐。而现实中用户的兴趣会随着时间推移而不断变化, 这种用户兴趣变化称为用户兴趣漂移[3]。例如, 读者从高中进入大学后, 对物理、大学物理再到原子物理的兴趣变化。推荐系统的推荐质量依赖于系统掌握用户兴趣的准确度, 如果推荐系统不能把握用户兴趣的变化, 就可能将过时的资源推荐给目标用户。因此, 如何依据用户兴趣偏好的变化给目标用户推荐即时感兴趣的信息资源, 已成为推荐系统研究的新问题。
信息资源推荐是根据用户的潜在需求、兴趣或行为模式, 将信息资源对象主动推荐给用户的一种个性化信息服务[4]。目前, 比较典型的推荐策略分为基于内容、协同过滤和混合推荐三种模式[4, 5]。一般来说, 用户兴趣时常会发生变化, 但一个人的兴趣往往会在一段时间内保持稳定, 如几个月, 甚至更长时间。不过, 一旦用户兴趣发生变化, 所构建推荐系统的兴趣模型也应随之调整。目前, 关于用户兴趣漂移的研究主要集中在: 兴趣漂移概念、兴趣漂移规律、兴趣跟踪、兴趣漂移模型和漂移算法等方面[3, 6]。用户的最近行为更能准确反映其当前兴趣, 故跟踪和捕获用户兴趣漂移的方法大多基于用户的最近想法[7, 10]。借助用户评价或所购项目的序列定义用户兴趣模式[7, 8, 9], 兴趣漂移处理使用时间窗口和遗忘函数, 前者滤除过时的兴趣, 后者利用遗忘函数衰减兴趣的权重[10, 11, 12], 并运用机器学习技术挖掘兴趣模式[7, 8]或者使用评价图和评价链[9]实现用户兴趣漂移的跟踪和识别。很多系统是在时间窗口和遗忘函数的基础上进行的改进[7, 8, 9, 10, 11, 12]。显然, 定义用户兴趣模式的前提是聚集目标用户的评价数据, 用户初始兴趣模式的获取与后期识别挖掘漂移的兴趣模式存在冷启动和额外工作量。跟踪目标用户兴趣漂移, 为其推荐即时感兴趣的精准资源固然重要, 但是能预测其未来下一刻的兴趣变化趋势同样重要, 而此方面的研究尚不多见。
与传统的媒体相比, 用户角色的变化, 用户关系的形成, 使得Web 2.0发展的社会媒体对推荐系统提出了新要求[6], 并为提高推荐质量提供了潜能[13]。社交网络中的信任关系和社会标签系统扩充了用户和信息资源的语义范围, 可显著提高推荐的可靠性和精度。文献[14]使用用户社交关系提取用户相关性以提升预测精度。文献[15]提出一种基于用户偏好自动分类的社会媒体数据共享和推荐方法。文献[16]研究了社会化标注对推荐质量的影响, 但有关工作并未考虑标签的时间属性, 而时间属性是人社交行为的本质特征。作为用户标注行为结果且具有时间属性的社会化标签能够体现用户的个性化动态偏好信息。
针对跟踪并预测用户兴趣的漂移, 提高推荐资源的精准性, 本文提出一种网络信息资源的推荐方法。该方法以两两资源对拥有共同标签作为连边建立资源网络图, 形成资源语义链, 再由作为资源语义链的资源网络图中的连边投影构建具有时间属性的标签网络图以刻画用户对资源的兴趣漂移, 继而匹配目标用户感兴趣资源的标签与标签网络图中的标签, 预测目标用户可能的兴趣漂移方向, 以实现向目标用户推荐精准的信息资源。
用户、资源和标签组成了社会化标签( 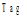
一个资源往往被标注多个标签, 资源的标签集合定义为: 

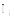
同样, 一个标签可以被标注于多个资源。对于标签集合 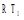
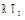
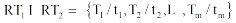
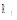
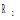
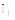

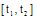

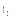
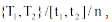
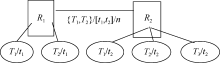
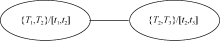
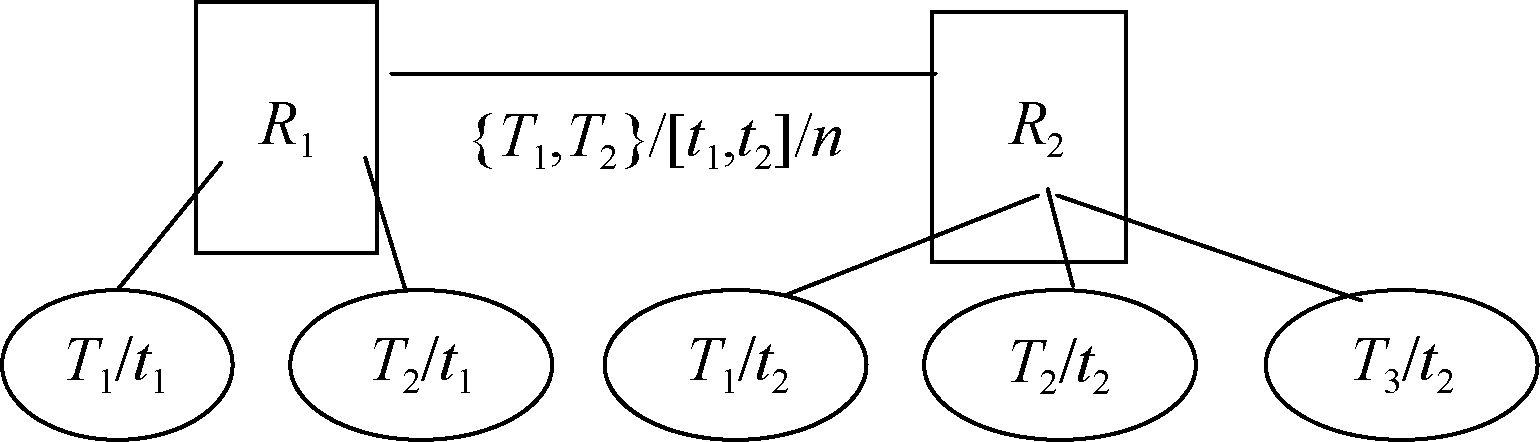 | 图1 资源R1与资源R2标签集合的交集 |
从用户标注行为的角度分析, 语义链体现了用户兴趣的漂移。重要的是, 当资源R1和R2是由不同用户标注的资源时, 则资源语义链为预测用户兴趣漂移的方向提供了使能。
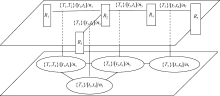
利用标签系统可在用户、标签以及信息资源等集合间形成相应的关联网络图。以相同标签作为连边形成资源的语义链, 反映资源间的关联情况, 刻画资源间的语义逻辑性。同样, 借助资源的语义链, 标签间的链接可以体现用户兴趣在一个时间段里的漂移和未来可能漂移的方向。为此, 依据标签系统, 提出两层结构的标签-资源网络图, 以描述资源间的逻辑语义以及用户间的兴趣漂移情况, 如图2所示, 其中顶层是资源网络图, 矩形框表示资源(为了使图清晰, 省略了标签部分); 底层是标签网络图, 根据对顶层资源网络图中的连边进行投影构建, 即资源网络图中连边映射为标签网络图中结点, 资源网络图中两条连边中间的结点映射为标签网络图中的相应的连边。如果用户集合为一个用户, 所投影构建的标签网络图则刻画了该用户的兴趣漂移。如果用户集合为多个用户, 则标签结点的邻居可作为目标用户的兴趣可能漂移的方向。
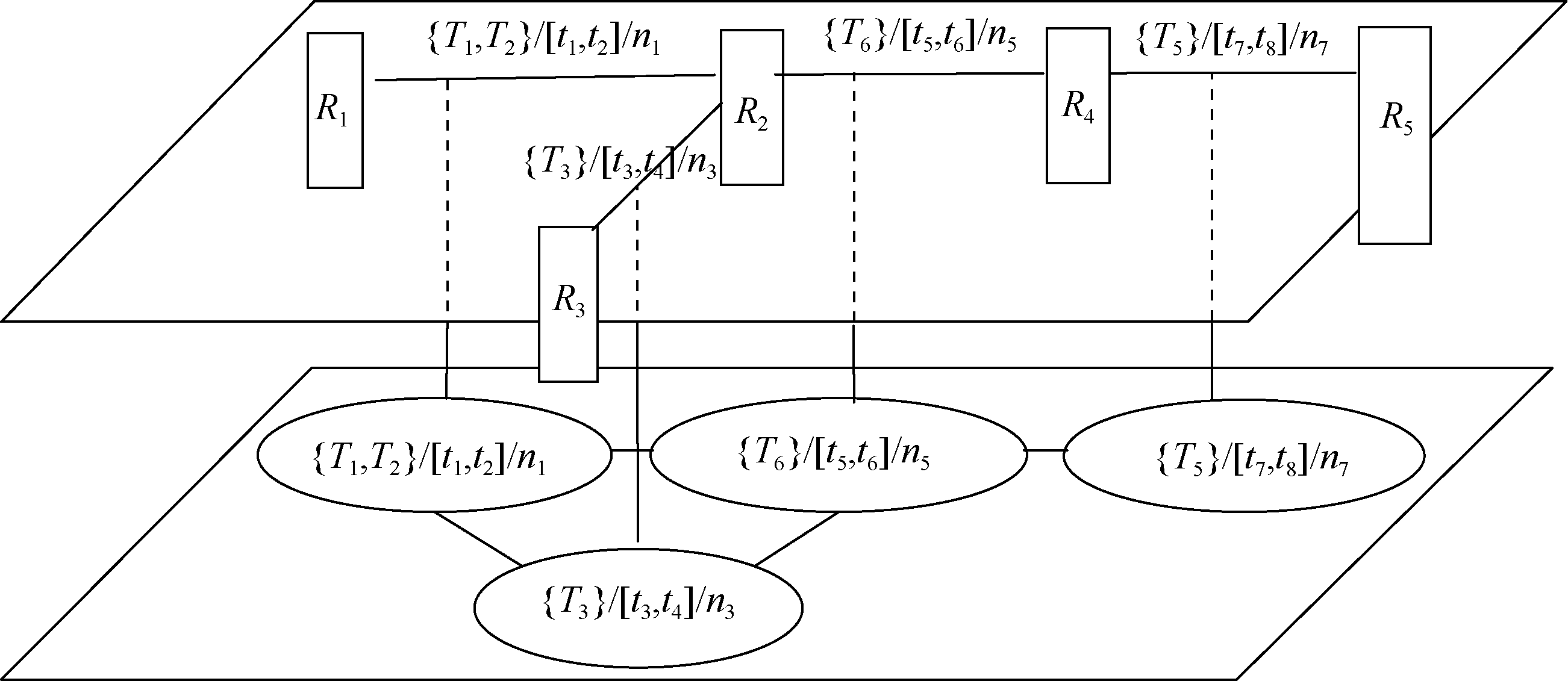 | 图2 标签-资源网络图 |
资源网络图构建过程如下:
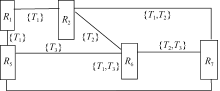
(1) 以用户集合所标注的资源为结点, 对两两资源的标签集合取交集运算, 如果结果为空, 则不建立连边; 如结果不为空, 则在这两个资源间用连边连接起来, 在连边旁标注交集结果以及相应的时间窗口。
(2) 当不同用户对相同资源进行相同标注时, 在资源网络图中记录该资源被标注的次数和标注的时间点, 即标注次数加1, 时间窗口向前扩大、不变或者向后扩大; 当不同用户对相同资源进行不同标注时, 把不同标签增加到该资源标签集合中, 同时考虑标注的时间窗口, 即标注次数加1, 时间窗口向前扩大、不变或者向后扩大。

 | 图3 资源网络图的构建 |
如果用户集合为一个用户, 依据时间窗口可认为资源网络图描述了该用户使用资源的历史记录。如用户集合为多个不同用户, 则可以实现目标用户感兴趣资源的预测推荐。
事实上, 由于网络资源的不断更新, 以及用户偏好的不断变化, 用户对资源的选择存在时间效应。一般来讲, 用户对最近选择的资源往往比较感兴趣。在标签系统中则体现为用户最新标注的资源是其当前最感兴趣的资源。因此, 通过用户最新标注的标签可准确检索到符合其需要的资源, 或者通过预测目标用户漂移的兴趣为其推荐更为精准的资源。
假设一读者阅读了如下书籍:
(1) 高中物理教材, 其标签={高中, 物理, 教材} /2012.7.2;
(2) 大学物理教材, 其标签={本科, 物理, 教材} /2013.1.1;
(3)光学教材, 其标签={本科, 光学, 物理} /2013.8.1。
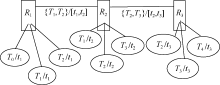
从该读者所阅读的上述书籍, 能够刻画该读者的阅读兴趣或者偏好的漂移, 如图4所示, 其中, 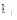






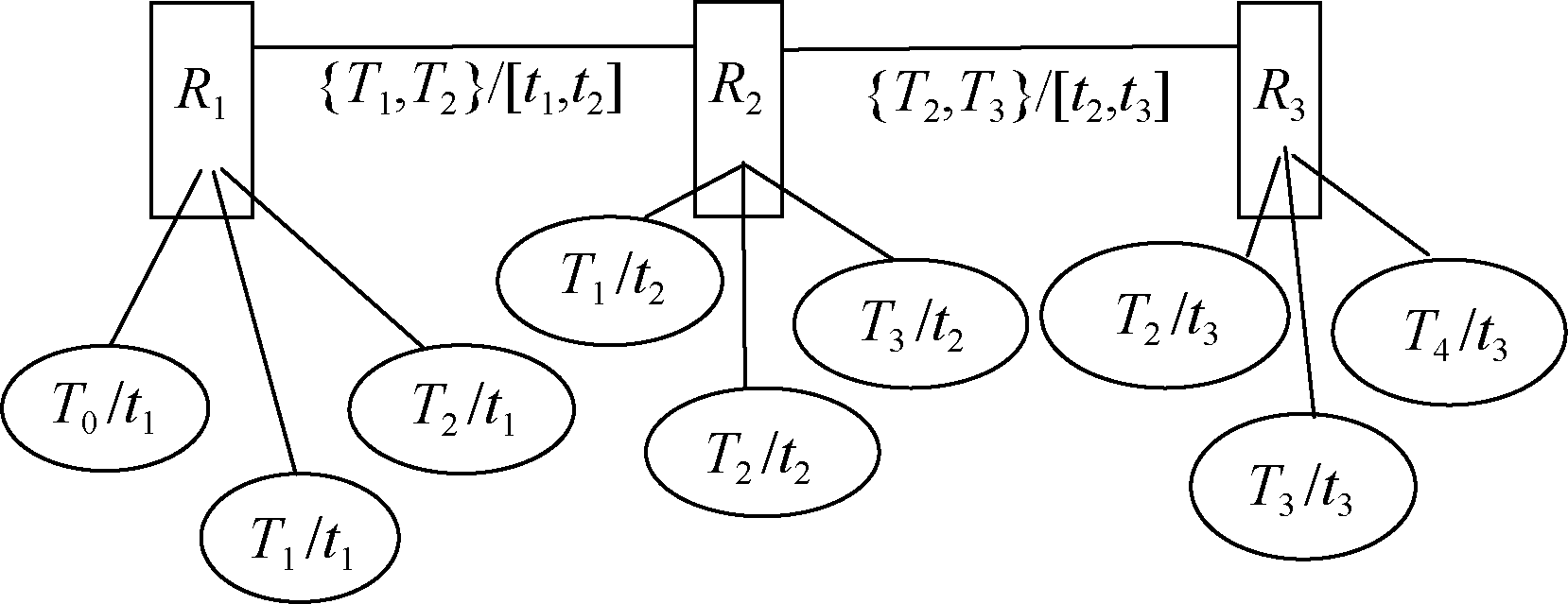 | 图4 基于标签的资源网络图 |
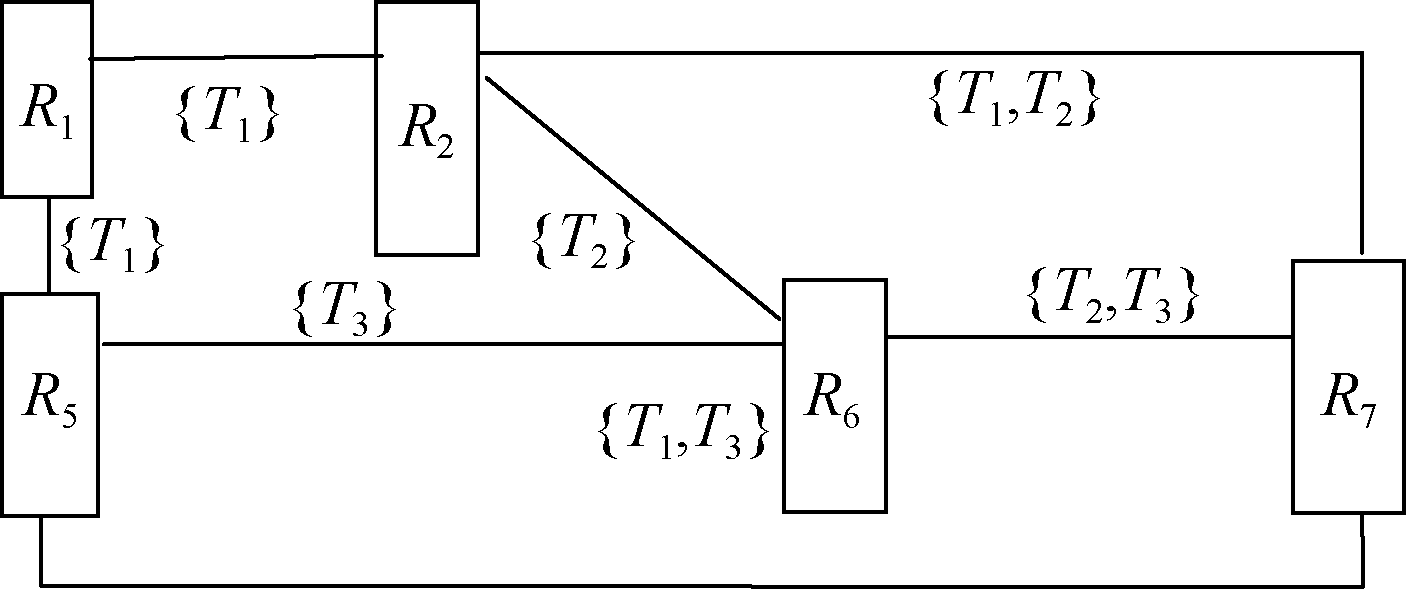
依据图4, 可抽象映射得到该读者的兴趣漂移图, 如图5所示。从{“ 教材” , “ 物理” } /[2012.7.2, 2013.1.1]漂移到{“ 物理” , “ 本科” }/[2013.1.1, 2013.8.1]。
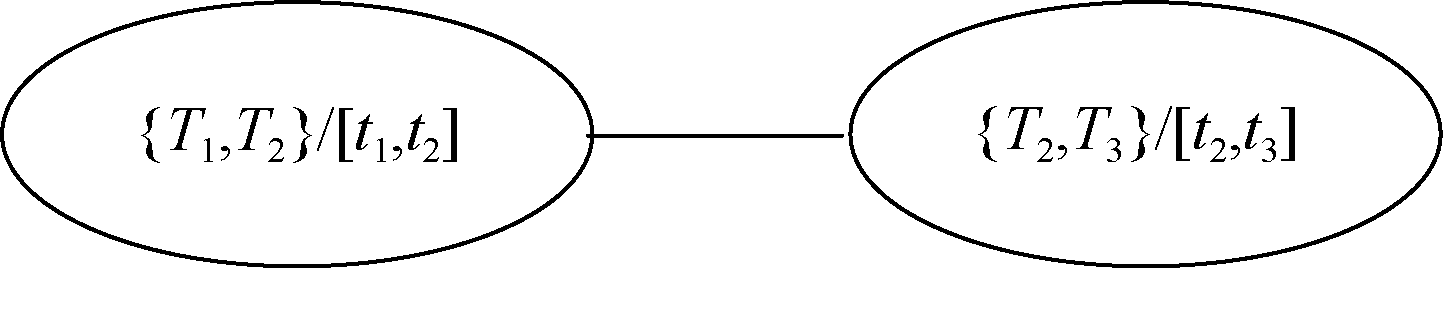 | 图5 用户兴趣的标签网络图 |
借助动态标签-资源网络图不仅可跟踪用户兴趣的漂移, 还可预测目标用户兴趣可能的漂移趋势; 反之, 依据对用户兴趣漂移的预测可以推断出用户可能感兴趣的资源。
在实际构建标签-资源网络图时, 选择构建该图的时间窗口存在两种策略:
(1) 对某个时间段 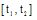
(2) 考虑资源标签标注的时间约束, 对在时间窗口 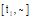
对于第一种构建策略, 可根据需要, 自由推荐某时间段内用户感兴趣的资源。第二种策略构建标签-资源网络图可推荐最近而非过时的资源给目标用户, 从而可满足跟踪或者预测用户兴趣漂移的需要。这是本文研究的对象。
依据标签-资源网络图中底层的标签网络图, 采取深度搜索策略匹配目标用户的当前兴趣标签, 获得兴趣标签结点后再依据顶层的资源网络图反过来推导对应的资源结点, 实现给目标用户推荐信息资源。
用户集合的标签网络图为无向图, 定义为一个二元组: G=< V, E> , 其中V是结点集合, 结点 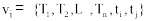
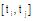
引入结点 
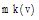
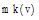
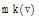
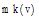
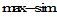
资源推荐算法描述如下:
输入: 目标用户当前兴趣标签向量, 用户集合的标签网络图(每个结点为一标签向量)和相应的资源网络图;
输出: 推荐结果, 产生推荐资源集合。
推荐步骤如下:
①设置 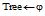

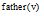
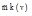
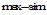
②从任何一个图G的分支开始, 任意选择一个 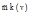
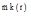
do {
match( 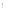
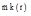
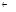
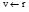
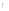
③如果结点 



④对无向边定向为从 

转到步骤③;
⑤如果 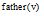
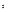

do {v 
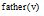
转到步骤③, 否则转到步骤⑥;
⑥对于图G中每个结点 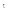
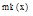
否则转到步骤②;
⑦停止。
子过程match (r, user)的算法描述如下:
①如果结点 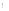
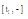
②sim( 
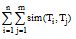
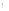
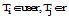
③ 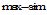
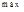
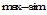
④退出。
本节进行跟踪和预测目标用户兴趣漂移及其推荐精度的验证。实验采用MovieLens站点①提供的10M公开数据集, 该数据集包括2006年-2008年间71 567个用户对65 133部电影的评级信息以及用户的标签信息。数据集中, 用户对观看过的电影资源进行评价并标注标签。数据集中的标签由用户自由添加, 电影的类型表示该电影属于何种题材, 如: Action, Thriller等。时间信息用时间戳表示, 时间戳越小, 所标注时间越早。由于标签集中用户所标注标签过于繁杂, 实验中基于MovieLens数据集构建出一个新数据集。新数据集将MovieLens数据集中电影的类型作为用户对该电影标注的标签信息, 同时将用户标注标签时间作为观看电影的时间。MovieLens数据集中最近时间为2008年12月。
采用平均绝对误差(Mean Absolute Error, MAE)作为评测指标。 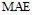
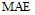
假设预测用户评价集为
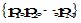
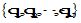
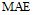
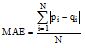
其中, 
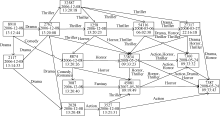
图6为一典型的用户观看电影资源网络图。其中的结点表示该用户观看的电影ID及观看该电影的时间。边表示用户观看电影资源之间标签的关联性, 即表示不同资源具有共同的标签。可以看出, 用户观看的影片随着时间推移渐渐变化, 资源网络图表达了用户观看影片的变化情况, 即从2006年观看Drama或Comedy (图6左上角)类型影片变化到最近观看Horror、Thriller、Action和Drama类型影片(图6右下角)。
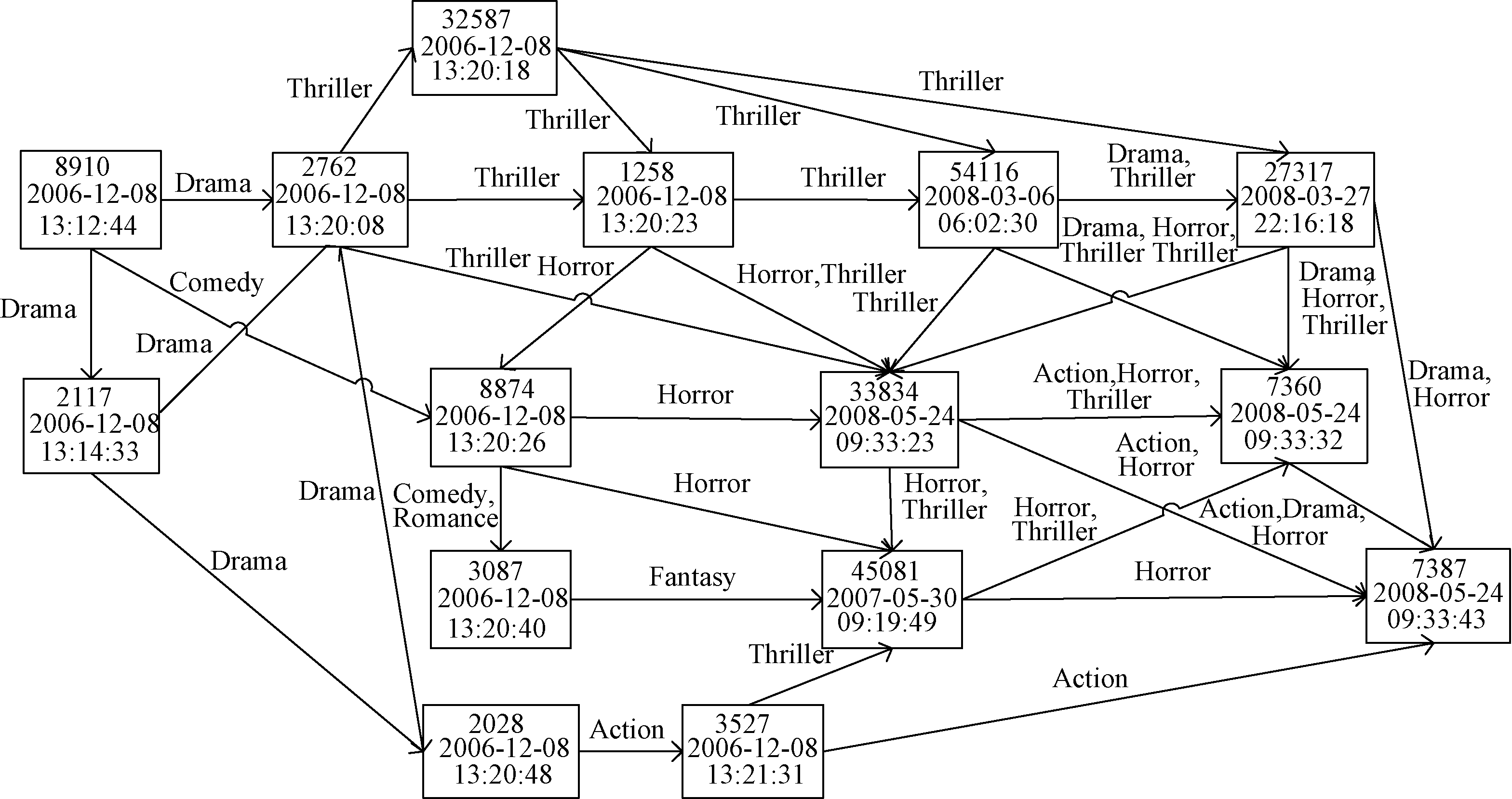 | 图6 用户观看电影的资源网络图 |
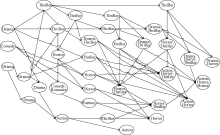
由资源网络图可投影映射出标签网络图, 图7为该用户观看电影的标签网络图, 该图更加具体地表现了用户兴趣漂移变化的方向。在图6和图7中, 2006年该用户兴趣标签为Drama, Comedy, Thriller 等, 随着时间变化, 用户兴趣发生相应的漂移。在2008年时, 该用户兴趣标签变化为Drama、Horror, Action、Drama、Horror, Action、Horror, Horror、Thriller等。由此, 知道用户观看的影片含有Horror 情节, 其兴趣中增加了Horror 和Action成分。
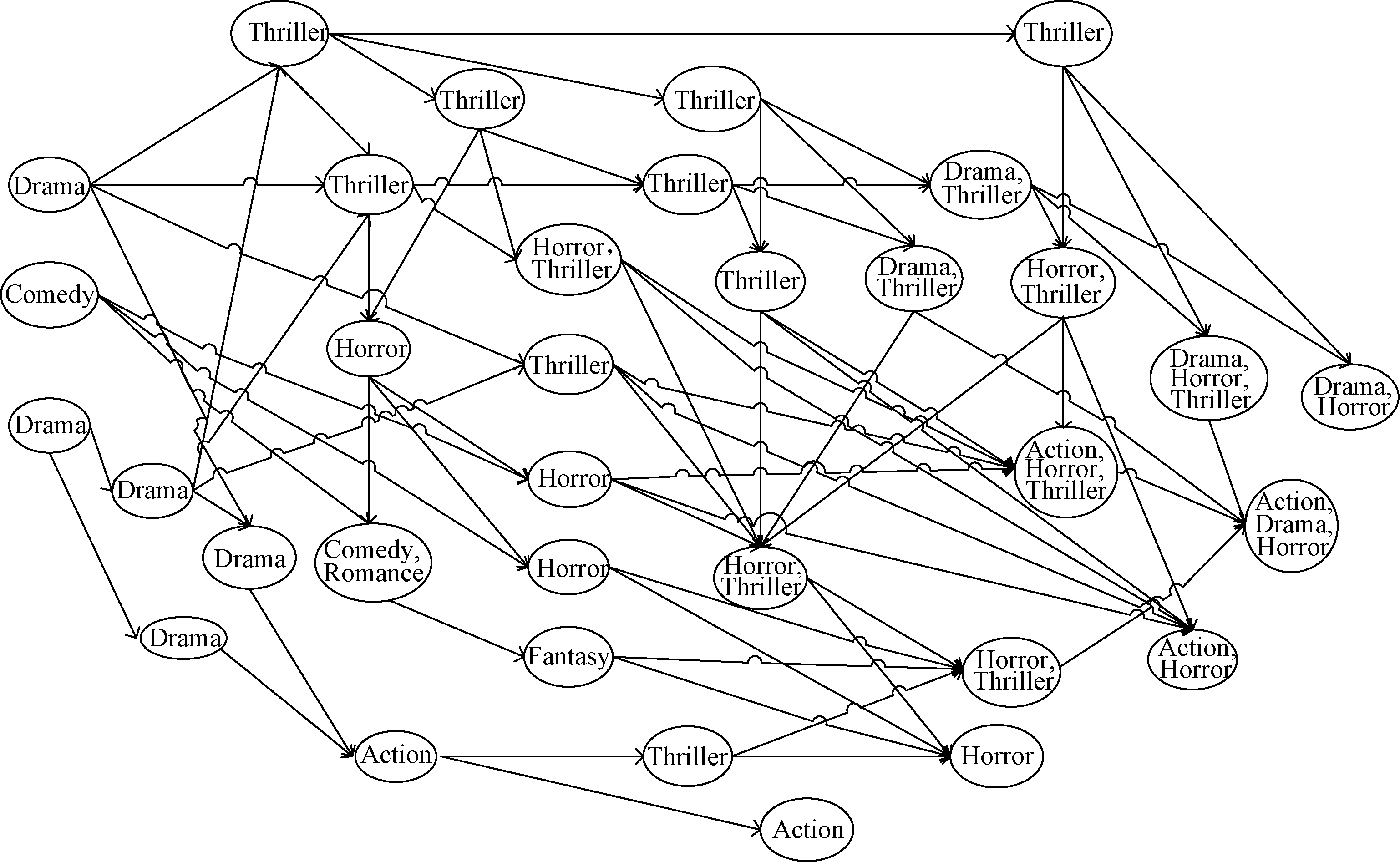 | 图7 用户观看电影的标签网络图 |
为了验证本文方法的推荐结果更为即时有效, 将其与基于社会化标签、基于用户背景信息的两种协同过滤推荐算法进行比较。在实验中, 结合用户对电影的评分数据集, 输入待推荐用户ID, 通过本文方法返回推荐的标签集合及相应的标注时间, 实验结果如图8-图10所示。其中用户ID为117, 12是依据标签网络图, 采用深度搜索策略得出的一个相似用户集。
 | 图8 基于本文方法的推荐结果 |
 | 图9 基于社会化标签的协同过滤推荐结果 |
 | 图10 基于用户背景信息的协同过滤推荐结果 |
图8(a)为基于本文方法得出用户ID为117的推荐结果, 从图6和图7中可得出该用户的兴趣漂移情况, 对照推荐的结果可看出, 本文方法的推荐结果与该用户兴趣漂移的方向一致, 且推荐的也是最近时间的资源。同时, 预测推荐了含有Horror 情节的Crime和Action类型的影片“ Crime|Horror|Thriller” 和“ Action |Horror|Sci-Fi|Thriller” , 由于Horror 情节在Crime或者Action类型的影片都可出现。而在图9、图10中, 基于社会化标签和基于用户背景信息两种推荐方法所推荐的可能是过时资源, 并且没有跟踪用户兴趣的变化, 对用户兴趣漂移预测不够, 表现为只能推荐含有Horror 情节的Crime或者Action类型中的一部影片, 不能同时推荐两类电影。再者, 图10(a)的结果都为Action类型, 可能与用户背景有关, 因为某些Action类型影片恰巧含有Horror 情节。
由图8(b)可知, 基于本文方法得出用户ID为12的推荐结果, 其第二个推荐结果2007年12月到第五个推荐结果2008年12月的影片由“ Action|Adventure| Drama” 漂移到“ Action|Horror|Sci-Fi|Thriller” 类型, 与用户兴趣向Horror漂移相一致。而对图9(b)用户ID为12来说, 基于社会化标签的推荐方法推荐了Action类型影片, 但未表现用户兴趣向Horror成分漂移的趋势; 对图10(b)用户ID为12来说, 基于用户背景信息的推荐方法所推荐Action类型影片虽表现出用户兴趣向Horror漂移趋势, 但所推荐的是过时的资源。
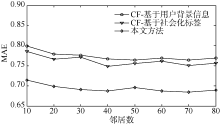
为了评价推荐精度, 用本文提出的方法与基于社会化标签、基于用户背景信息两种协同过滤算法进行比较。如图11所示, 在相同的最近邻取值下, 分别计算出三种推荐算法的MAE变化曲线, 本文算法的MAE值变化曲线明显小于基于社会化标签、基于用户背景信息两种协同过滤算法, 且随着最近邻居的增加, 本文方法的MAE值渐趋平稳, 而其他两种算法的 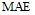
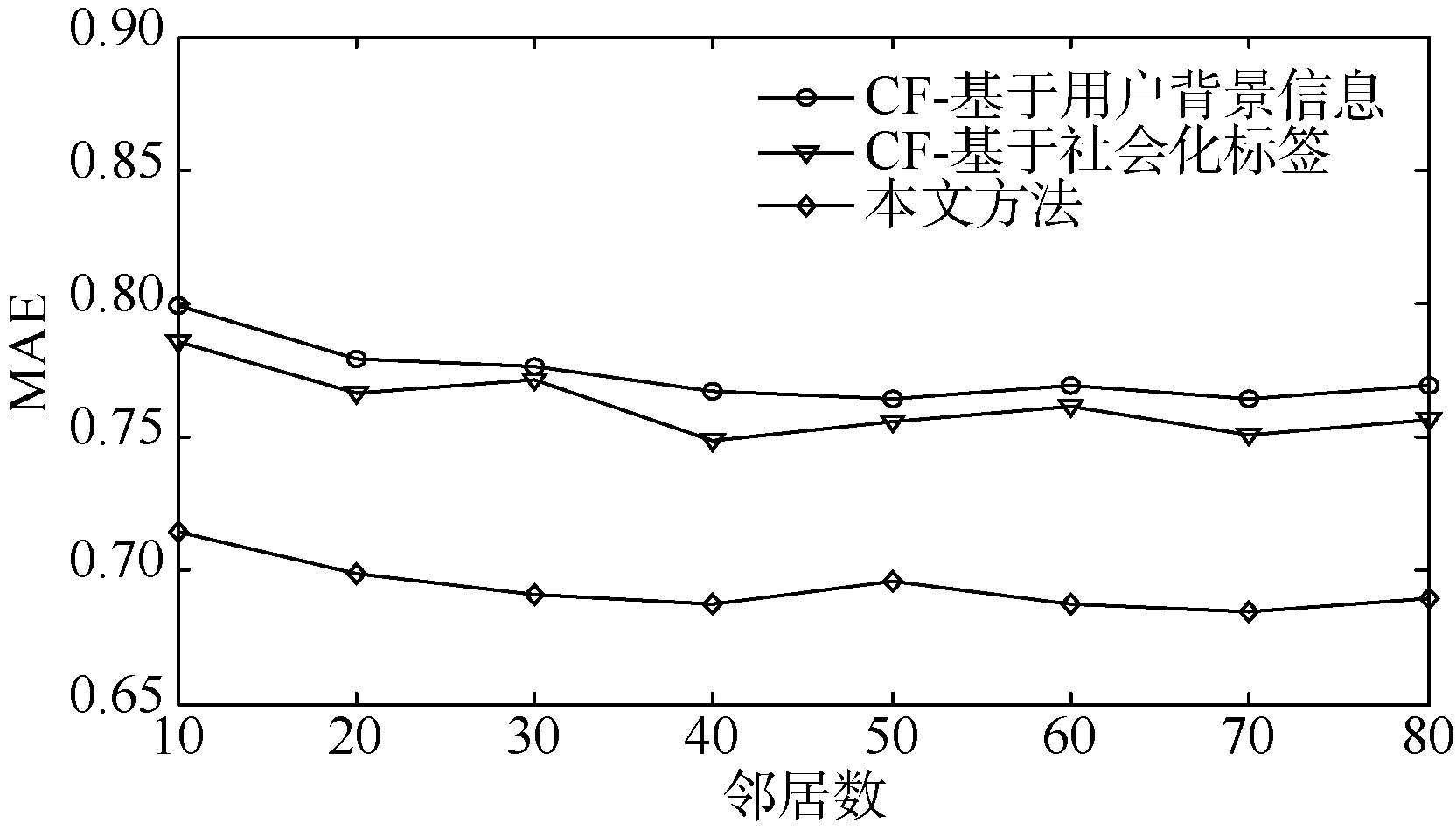 | 图11 推荐算法的MAE比较结果 |
综上所述, 本文方法能有效地跟踪和预测用户兴趣漂移, 体现推荐的时间有效性, 实现向目标用户推荐更加准确即时的信息资源。
人们对社会标签标注时间的变化体现了其社会行为的动态性。考虑标签的时间属性, 本文提出一种基于动态标签-资源网络图的信息资源推荐方法, 匹配并预测目标用户的兴趣漂移标签, 为目标用户推荐即时准确的信息资源, 同时证实了该方法的可行性和有效性。本文暂未考虑用户兴趣变化更为频繁的实时动态环境, 如信息检索中用户所使用的关键词, 未来将考虑如何跟踪和预测实时动态环境下的用户兴趣漂移以精准推荐资源的问题, 并且在实际信息共享平台上对所提出的方法进行验证。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|