{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
一种基于本体和位置感知的图书馆书籍推荐模型
[李胜, 王叶茂 ]
]
]
|
|


作者简介:李胜: 确定研究方向及研究方法, 提出论文的修订意见;王叶茂: 进行算法设计及实验分析, 撰写与修订论文。
[Objective] Improve the library recommendation service and help readers select interested books. [Methods] This paper proposes an Ontology-based and location-aware book recommendation model in library by applying Wi-Fi indoor positioning technology, which constructs user’s profile based on the books classification Ontology, and then recommends books by combining regional group profile and considering the problem of when to make a recommendation. [Results] The proposed method outperforms the existing Ontology-based hybrid recommenddation method in accuracy and correlation by 13.6% and 21.8% respectively, and shows 48.03% increase in the set diversity compared with the content-based filtering method. [Limitations] The weights of user preferences and regional group preferences in the recommendation model are not discussed. [Conclusions] This research can improve the library recommendation service and provide location-aware personalized book recommendation.
移动设备的发展为开发新的图书馆服务提供机遇, 如图书馆内资源导航、社交参与、推广等[1]。很多图书馆, 例如北卡罗莱纳州立大学的移动图书馆MobiLIB(http://www.lib.ncsu/dli/projects/librariesmobile)
为读者提供通过移动设备访问图书馆的接口。剑桥大学与开放大学的研究表明: 与利用移动设备阅读电子书籍相比, 学生对图书馆开放时间、位置地图和可访问的完整书籍目录更感兴趣[2]。因此, 图书馆以移动友好的方式提供特定的服务将成为图书馆广泛发展的趋势, 而位置感知的书籍推荐服务正是其中一种。
在图书馆书籍推荐服务中, 基于内容过滤的方法总体上根据用户阅读历史, 构建用户偏好模型, 并据此向用户推荐书籍。因此, 用户偏好模型表征用户兴趣的准确度和对潜在兴趣的挖掘度直接决定了资源推荐的准度和广度[3]。但是, 基于向量空间的用户模型, 以词为基础来描述用户兴趣, 没有考虑到语义方面信息, 不能很好地表达用户的潜在需求。鉴于此, 本文提出一种基于本体和具有位置感知的书籍推荐模型(OB-LABRM), 以向用户提供移动环境下个性化书籍推荐。
本体[4]作为语义网(Semantic Web)的关键技术, 为实现计算机自动化处理概念以及它们之间关系提供了支持。因此, 将本体技术与个性化推荐技术相结合, 是目前很多计算机学者较为关注的一个研究方向。在图书馆个性化推荐系统中, 基于本体的推荐方法也有大量的研究。Yan等[5]和丁雪等[6]分别提出了基于本体的数字图书馆系统推荐框架和用户本体模型。汪英姿[7]利用语义手段描述图书资源和借阅者, 提出了一种基于本体的混合式图书推荐方法, 提高了推荐的命中率。唐晓玲[8]综合本体和协同过滤技术实现推荐系统, 更准确地满足了用户的需求。但是这些方法均没有考虑用户兴趣的演化, 并且提出的方法或模型也没有考虑用户位置等上下文信息, 不适于移动环境下、位置感知的书籍推荐。
位置感知的图书馆书籍推荐结合了基于位置的服务和个性化推荐技术。通过定位用户的位置, 获取用户所在区域的书籍, 并根据用户的偏好, 主动向用户提供书籍推荐。Hahn[9]在书籍定位导航的基础上, 提出了基于位置的“ 主题” 文献推荐模型, 使用户能最大可能访问纸质和电子资源。Chen[10]提出了智能移动位置感知的书籍推荐系统, 该系统将基于问题的学习和具有丰富书籍资源的图书馆环境相结合, 提高了基于问题学习效率。但这两个模型都没有考虑用户的偏好, 不能提供个性化的书籍推荐。
基于此, 在充分借鉴上述研究成果的基础上, 本文考虑用户兴趣演化, 不仅结合用户个人书籍偏好, 而且将就区域书籍而言的相似性读者群兴趣也作为参考。推荐时, 根据用户当前位置, 考虑“ 何时推荐” , 推荐位置区域的偏好书籍, 满足用户的个性化需求。
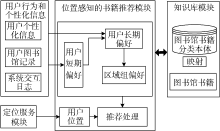
本文提出的OB-LABRM模型(Ontology-Based and Location-Aware Book Recommendation Model)主要由三部分组成: 位置定位服务模块、知识库模块、位置感知的书籍推荐模块。位置定位服务模块主要负责用户位置定位, 向推荐模块提供用户位置上下文; 知识库模块包括构建的图书馆书籍分类本体和馆藏书籍; 位置感知的书籍推荐模块是整个模型的核心, 它通过结合位置定位服务模块提供的用户位置和构建的图书馆书籍分类本体, 向用户推荐位置区域的偏好书籍。在推荐模块中, 为每一个用户构建了一个基于本体的书籍偏好模型, 包含用户的长期和短期偏好。前者的构建基于时间的遗忘模式, 后者利用用户最近的兴趣来表示。除此之外, 还构建了区域组模型, 以表达就区域书籍而言相似阅读偏好读者的共性偏好。OB-LABRM模型如图1所示:
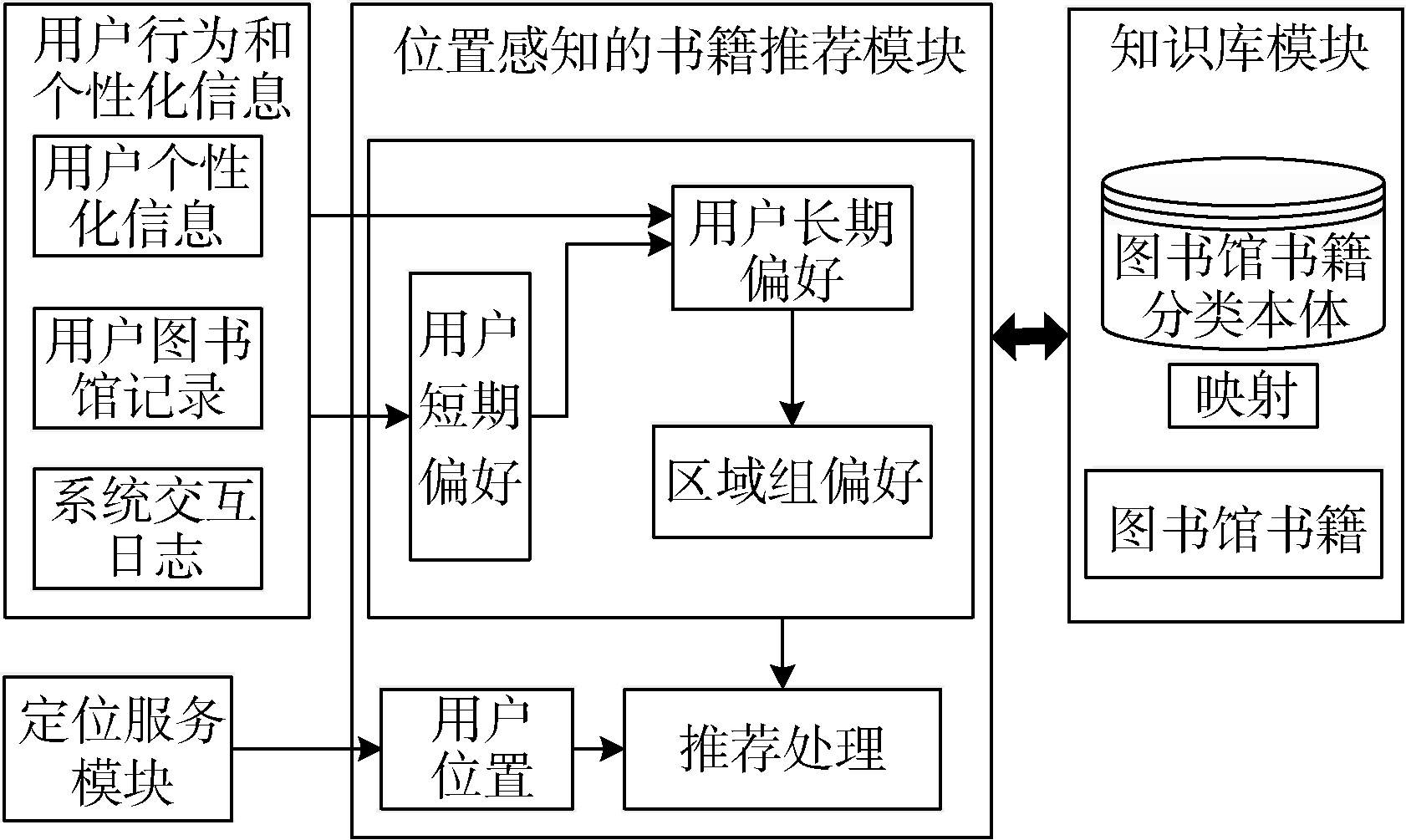 | 图1 基于本体和位置感知的书籍推荐模型 |
(1) 根据当前时间段用户的借阅记录和交互日志, 利用图书馆书籍分类本体中的概念, 表达用户的短期偏好;
(2) 用户长期偏好初始从用户个人信息中提取, 每隔T时间, 利用短期偏好进行更新;
(3) 针对划分的每个区域构建区域组模型, 每隔T时间, 对受影响区域的区域组模型进行更新;
(4) 在推荐处理时, 根据用户的位置和停留时间上下文, 系统首先对用户当前情景进行分析, 在判断用户对该区域书籍感兴趣后, 结合用户长、短期偏好和区域组偏好, 向用户推荐区域内的Top-k书籍。
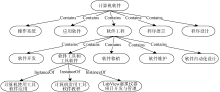
图书馆书籍分类本体通过定义类、属性、实例、关系、公理等, 抽象和概述了图书馆书籍的分类组织结构, 反映了书籍之间以及书籍类之间的关系。本文借鉴任沁[11]构建图书馆初始本体和领域本体的过程, 以《中国图书馆分类法》(中图法)和《中国分类主题词表》为依据, 结合领域专家的知识构建了图书馆书籍分类本体。构建的本体大体为一个树状结构, 本体的部分片段如图2所示:
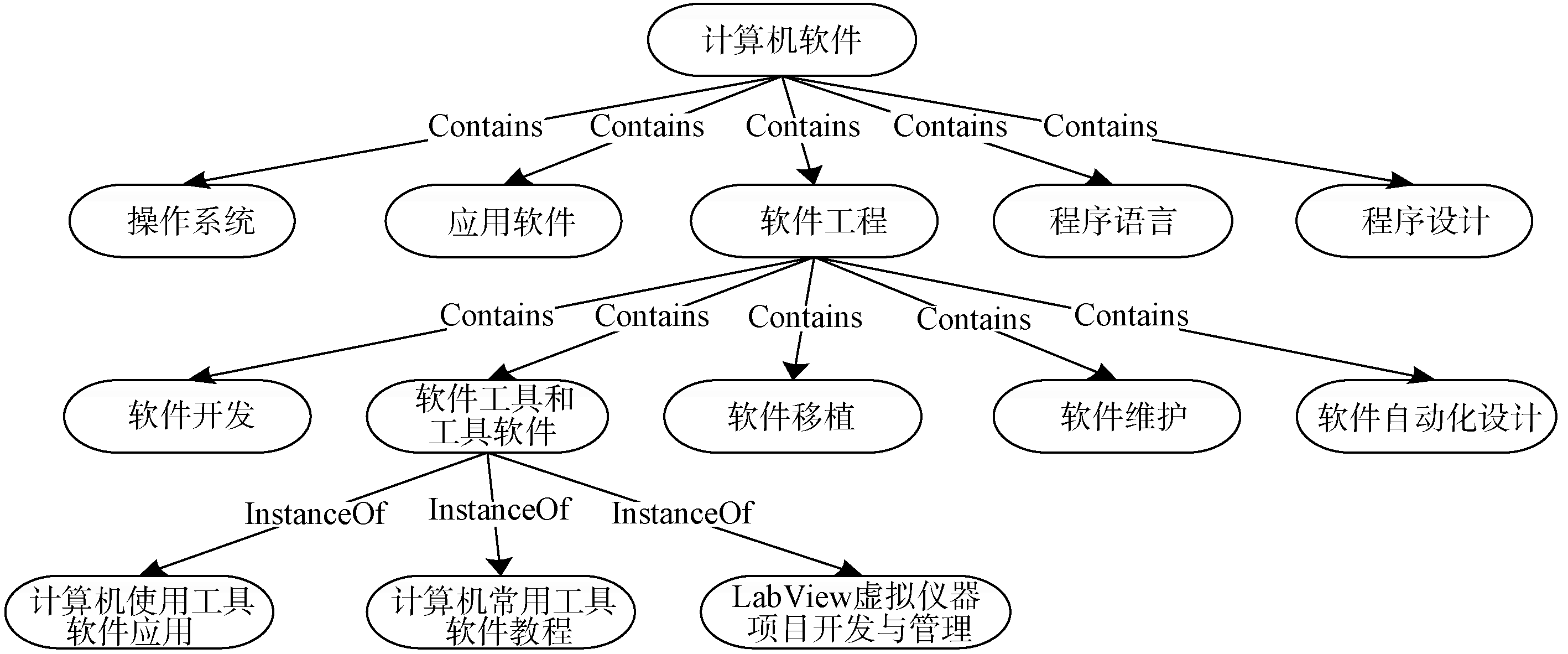 | 图2 图书馆书籍分类本体部分图 |
上述本体片段中定义了11个类(计算机软件、软件工程等)以及类之间的关系(如包含关系)。“ 计算机使用工具软件应用” 是类“ 软件工具与工具软件” 的实例。对于书籍实例, 以书籍的ISBN为实例ID, 以书籍描述或关键词为实例描述, 除此之外, 还有书籍标题、作者等信息。
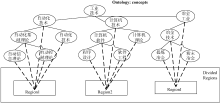
图书馆主要根据中图法进行书籍排架管理, 这种分类的组织结构使得近邻书籍存在着紧密的相关性, 即区域书籍往往都属于同一个或紧密相关的几个主题。基于此, 本文借鉴Hahn[9]基于Wi-Fi数据对图书馆书库划分区域的思想, 将藏馆书库划分为不同的区域。形式化地, 划分的区域集为: Region={region1, region2, 
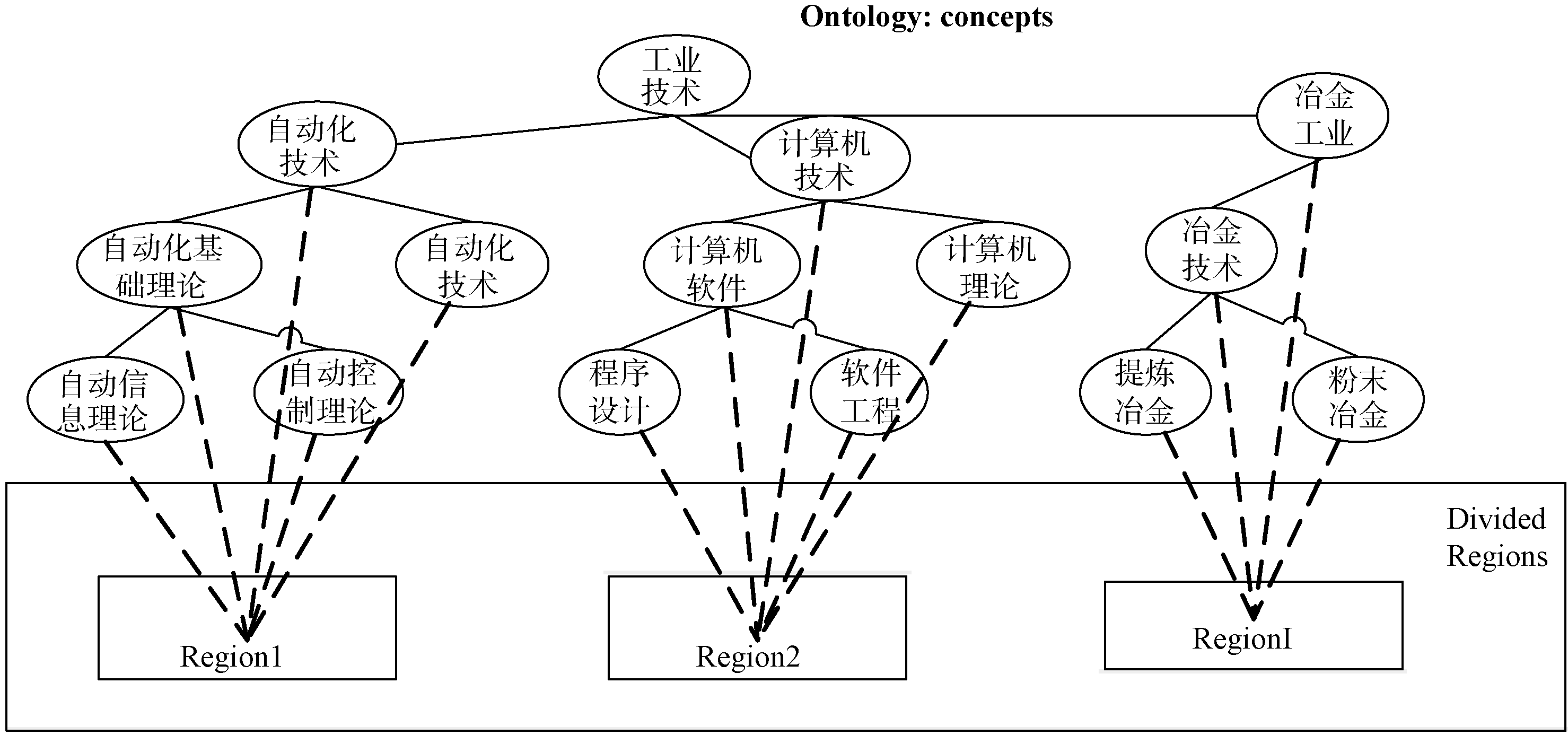 | 图3 本体概念与区域之间的映射结构 |
在划分区域以后, 将基于位置的书籍推荐问题转换为基于用户位置区域的书籍推荐问题。即当用户在区域内移动时, 本文认为先前推荐都是有效的, 只有当用户移动到另一个区域且其停留的时间超过设定的门限值时, 才重新计算推荐。
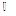
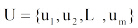
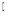
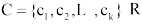
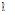

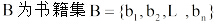
用户兴趣分为长期兴趣和短期兴趣, 长期兴趣广泛且相对稳定, 短期兴趣范围狭窄却变化迅速。因此, 用户偏好建模应能反映长、短期兴趣特征。借鉴 Li 等[12]的处理方法, 对给定用户u的历史记录H, 基于统一的时间段T将其分成多个区段, 即 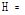
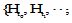

(1) 用户短期偏好
用户短期偏好主要来源于用户借阅记录和用户与系统的交互日志。根据构建本体O中叶子概念和书籍之间的“ 类-实例” 关系, 通过用户借阅记录和交互日志中的书籍名称, 可以直接获得用户偏好的概念集。形式化地, 用户短期偏好标记为: 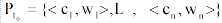
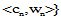
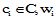
概念权重的计算, 本文主要考虑用户借阅行为和点击查看行为对概念权重的影响, 提出的计算公式为:
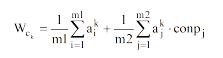 |
其中, 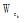

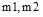
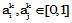


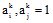
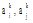

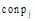
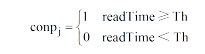 |
其中, 
概念之间的语义相似性利用Ganesan等[14]提出的公式计算:
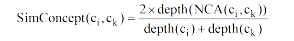 |
其中, 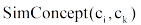


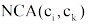


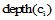

(2) 用户长期偏好的构建与更新
人的长期兴趣是由个体倾向性引起的, 与个人的背景、学历等因素相关[15]。因此, 从用户个人信息中提取的偏好可以认为是相对稳定的长期兴趣。此处主要考虑用户专业的核心课程。参照Cantador等[16]将社交标签分类到本体类中的方法, 本文基于课程名与本体类之间的形态学匹配, 通过计算编辑距离, 选择与课程名最相似的本体概念, 生成初始的用户长期偏好模型P。
考虑到用户偏好模型的稀疏性[17], 在更新长期偏好之前, 会对用户短期偏好 
形式化地, 本文将与概念 

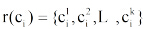
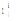
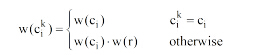 |
其中, 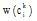
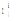
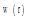
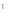
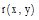
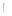
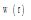
对用户短期偏好 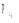
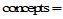
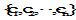
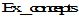
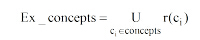 |
获得扩展的用户短期偏好后, 用户长期偏好采用Kang等[18]提出的方法进行更新。
根据区域内书籍的紧密相关性, 在同一个区域内有借阅记录的用户可以看成是就区域书籍而言有相似阅读兴趣的用户。通过合并这些用户对区域书籍的长期偏好, 构建区域组模型以改善推荐的多样性。
具体地, 根据本体概念 

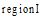
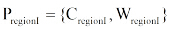
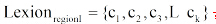
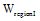
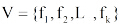
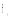

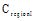
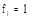
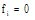
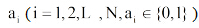
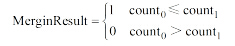 |
其中, 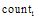

对每个概念特征, 都利用公式(6)进行合并, 剔除合并结果为0的概念后, 对选择的每个概念特征, 其权重的计算公式为[19]:
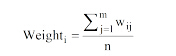 |
其中, 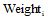

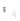

区域组模型是根据用户长期偏好构建的。在更新长期用户偏好后, 对受影响区域的区域组模型也需要进行更新。同样地, 本文将区域组模型的更新周期也设为T。即每隔时间段T, 根据借阅记录和交互日志, 寻找受影响的区域并对这些区域的区域组模型进行重现构建。
本文提出的基于用户偏好和区域组偏好的混合推荐模型
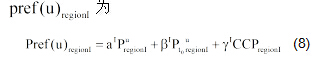
其中, 
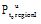

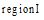
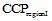
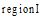
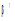
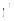
对候选书籍的评估, 本文根据获取的Top-k叶子概念集, 选择每个概念下权值最高的书籍进行推荐。但是, 如果直接利用公式(8), 获取的Top-k概念中很可能包含非叶子概念, 且概念之间还可能存在包含关系。因此, 在计算概念排名之前, 需要对非叶子概念进行处理。算法1描述了Top-k 叶子概念的选择过程。
算法1 Top-k叶子概念的选择输入: 用户 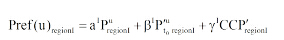
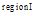
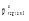
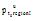
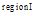
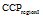
输出: 用户 
①利用程序HandleNonLeafConcepts (Profile p)对 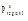
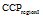
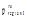
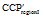

在获得用户Top-k偏好概念集后, 考虑书籍流行性和出版时间最近这两个指标, 选择推荐的Top-k书籍。提出的书籍权重计算公式如下:
 |
其中, 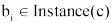
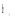
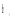
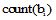
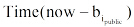
移动环境下, 基于位置的图书馆书籍主动推荐必须考虑“ 何时推荐” 问题。本文采用情景分析的方法, 对推荐处理的触发机制进行研究。
按照Woerndl 等[20]提出的方法, 本文将一次推荐分成两个阶段: 第一阶段确定当前的情景是否能确保推荐; 第二阶段进行推荐处理。只有当阶段一情景满足特定的条件时, 推荐处理才能被初始化。具体地, 对第一阶段的情景主要考虑用户位置和停留时间。在确定用户位置 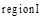

(1) 实验场景与数据集
实验是在本校图书馆内进行, 图书馆内覆盖的大量Wi-Fi访问点为用户位置定位提供了有利条件。用户位置定位方法采用改进的Average-KNN Classifier, 该方法在两米区域范围内定位用户位置的准确率高达76%[10], 这足以在实现基于位置的书籍推荐时定位用户位置。实验场地为图书馆的综合阅览室(二)。该阅览室分布了中图法分类中“ A、B、D、J、N、O、R、S、T、Z” 类书籍, 其中A、B、D、TP3类占主要部分。阅览室中划分的区域及区域书籍所属中图类如表1所示:
| 表1 区域与区域内书籍所属中图类 |
对于实验的参与者, 笔者随机从“ 计算机专业” 和“ 哲学院” 各选择50名学生, 进行为期7个月(从2013年6月1日到2013年12月31日)的实验。整个实验期间, 当他们在图书馆内查询书籍时, 被要求利用手机上安装推荐客户端获取推荐。用户的系统交互日志通过记录用户点击、查看的书籍获取, 其他的数据样本(用户借阅记录、个人信息和书籍信息)直接从图书馆系统数据中提取。
(2) 参数设置
参考Vallet等[21]在案例分析中设定的权重值, 对用户短期偏好进行语义扩展时, 不同语义关系 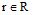
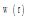
| 表2 概念之间的权重设置 |
| 表3 其他参数设置 |
为了验证模型推荐书籍的多样性, 利用Zhang等[22]描述的集合多样性, 对结合区域组偏好方法(LS- Group)、基于内容过滤的方法(Content-based)和基于内容的协同过滤方法(User-based CF)的推荐结果进行比较。书籍的集合多样性定义为在推荐列表中所有书籍之间的平均非相似性。具体地, 给定书籍集合N, N的平均非相似性 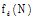
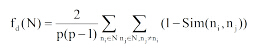 |
其中, |N|=p, Sim(ni, nj)标记为书籍实例 

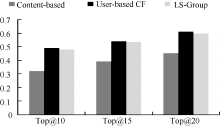
评估时, 对每个用户选择最近4次时间范围的阅读记录作为评估的标准(根据设置的T值, 每次时间范围为15天), 在此时间范围之前的历史记录则用于用户偏好模型和区域组模型的构建。通过每个方法向用户推荐了Top@k (k=10, 15, 20)的书籍, 并统计4次时间范围的平均集合多样性。结果如图4所示:
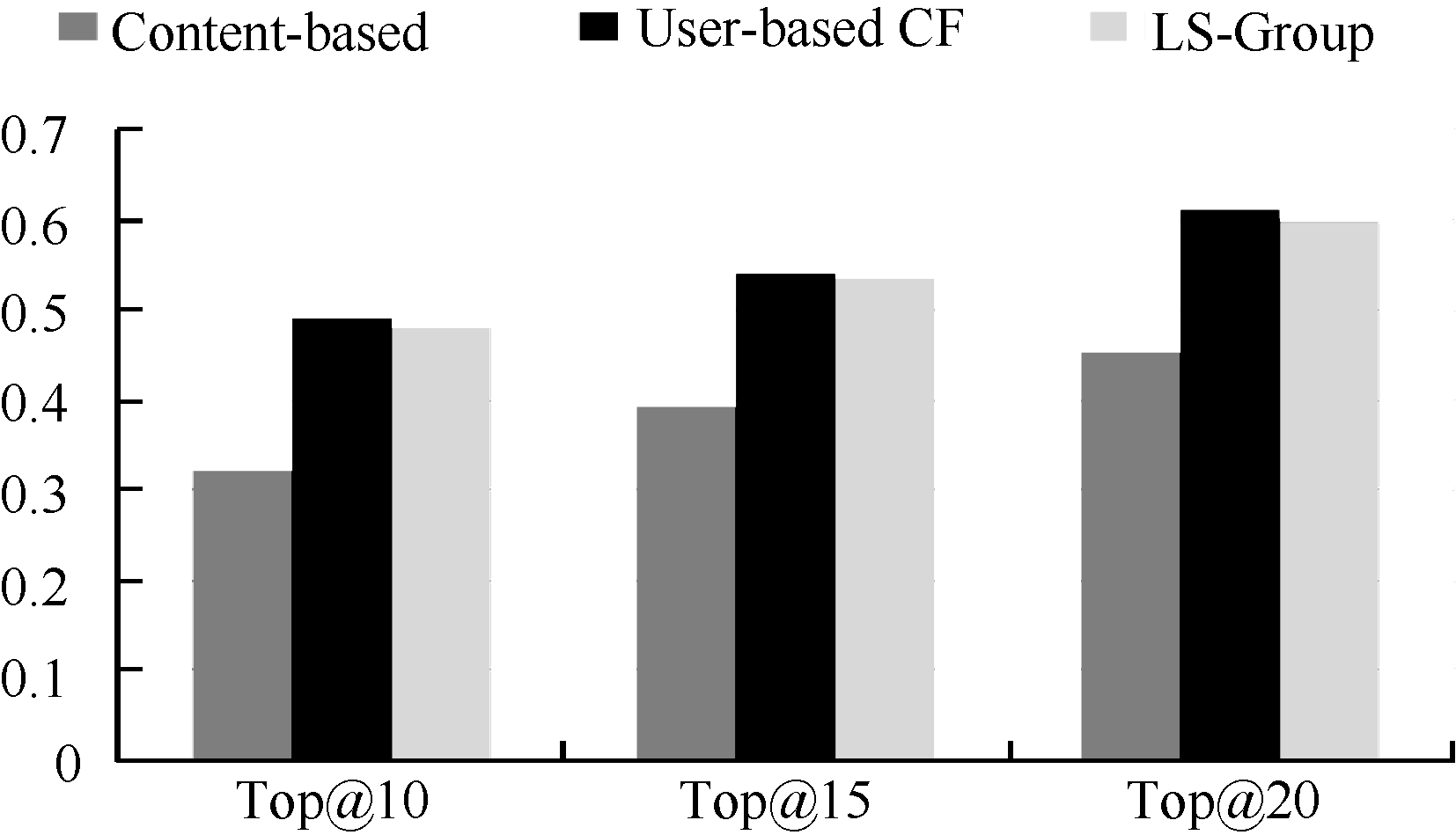 | 图4 推荐书籍的多样性 |
正如图4所描述的, LS-Group方法和User-based CF方法均比Content-based方法表现更好。其中, LS-Group方法平均提高了48.03%, User-based CF方法平均提高了49.38%。说明User-based CF方法和本文提出的LS-Group方法均可提高推荐的多样性。但与User-based CF方法相比, LS-Group方法推荐结果的集合多样性较低。产生这种结果的一种可能原因是公式(9)中各权重系数取值均相等, 在未来, 为进一步改善推荐效果, 笔者将对权重系数的取值进行讨论。
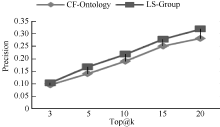
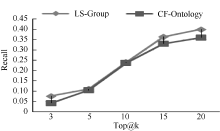
为了验证提出方法的推荐准确性, 本文将提出的方法(LS-Group)与现有综合协同过滤技术和本体的推荐方法[8](标记为CF-Ontology)进行比较。实验设置和5.2节相似, 对推荐的Top@k (k=3, 5, 10, 15, 20)书籍的精度和相关度进行比较。评估指标采用广泛使用的准确率(Precision)和召回率(Recall)。
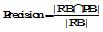 |
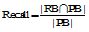 |
其中, 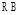
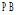
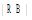
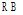
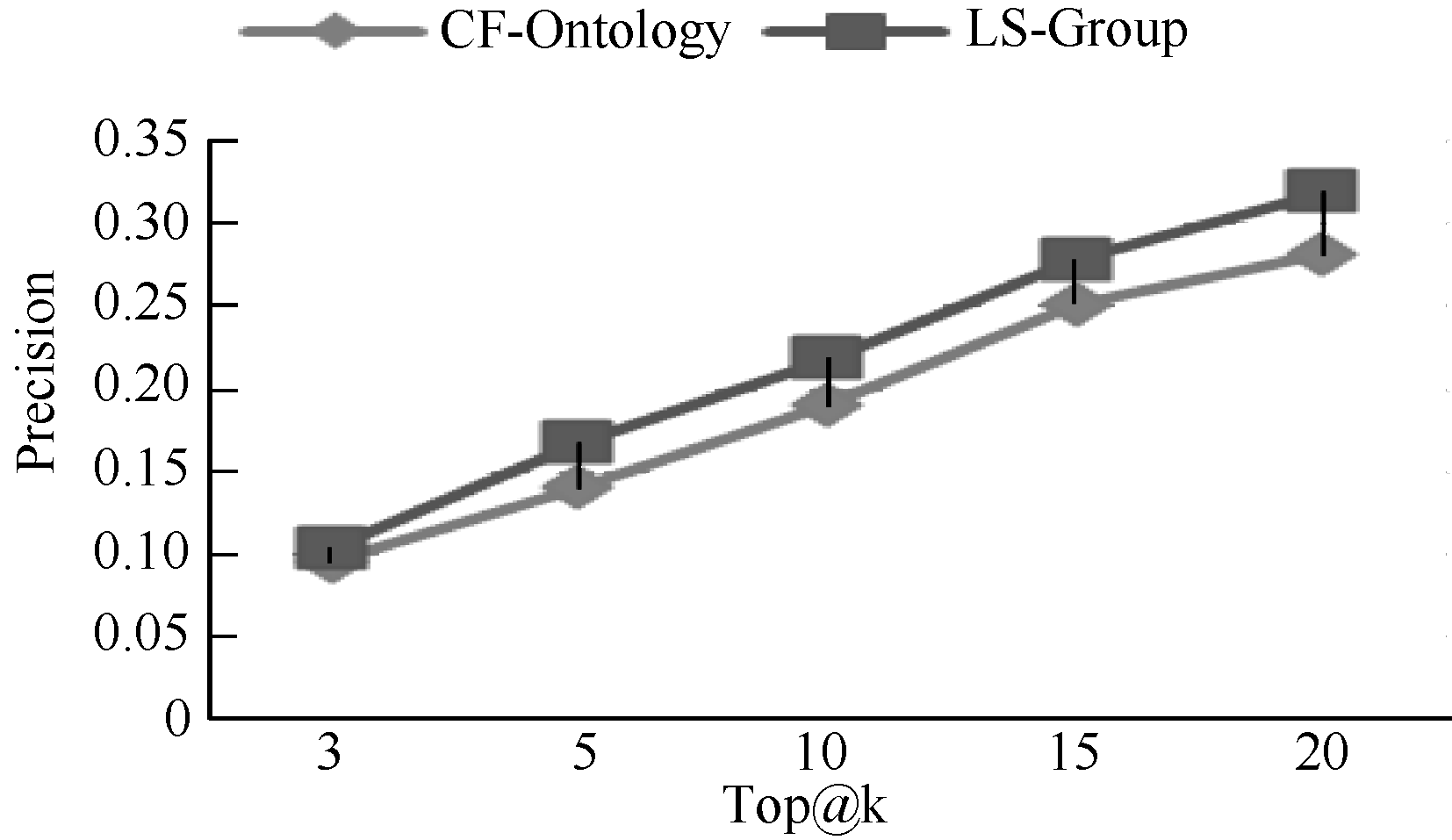 | 图5 Precision指标比较 |
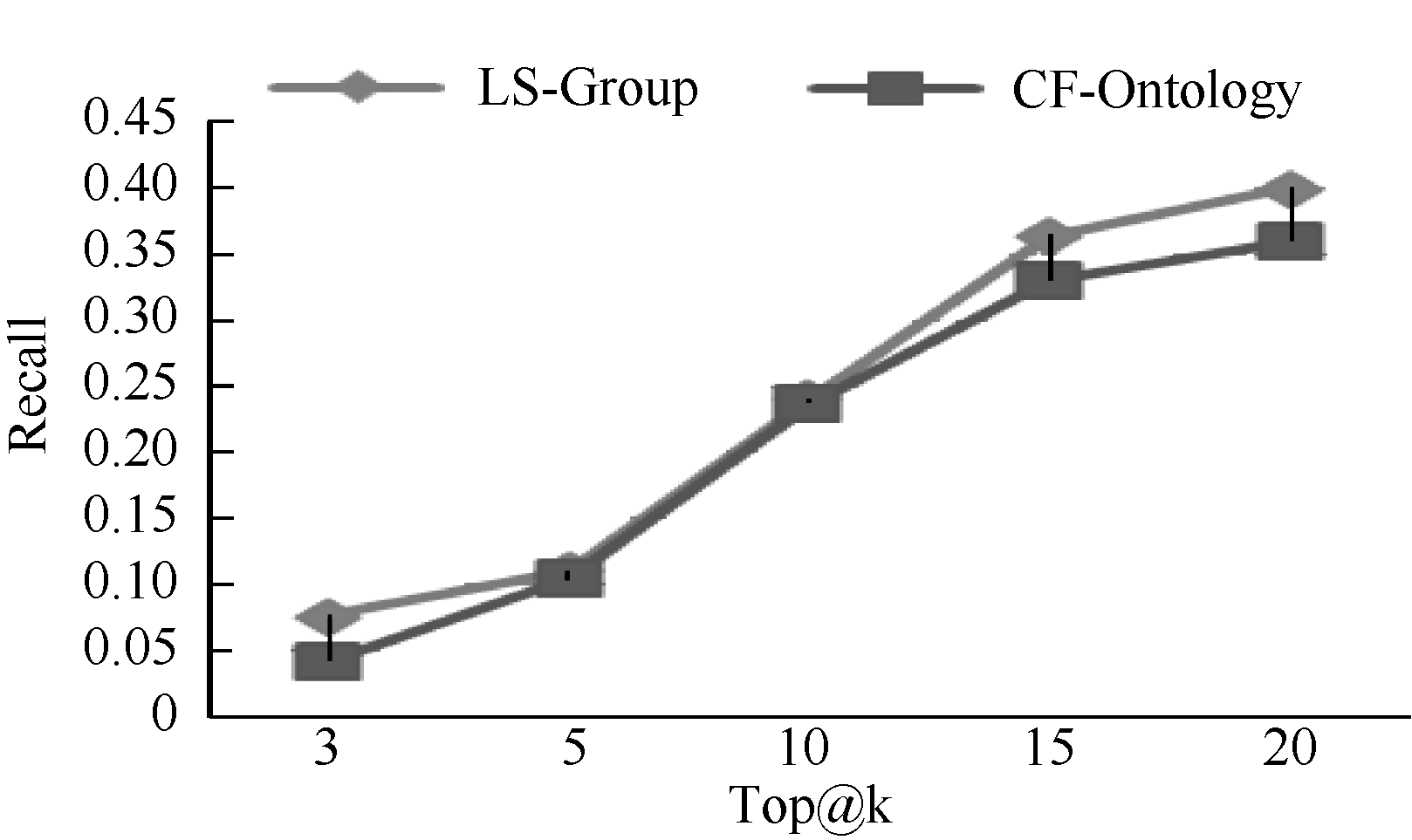 | 图6 Recall指标比较 |
可以发现提出的LS-Group方法在Precision、Recall上都比CF-Ontology方法相对较高, 提高的均值分别为13.56%和21.79%。得出这样的结果是显然的, CF-Ontology方法基于用户的整体偏好趋势, 并不能保证最近邻居的偏好对目标用户确定有效, 特别在目标用户偏好和近邻用户偏好不充分交叠时。LS-Group方法基于用户当前位置, 仅仅考虑用户期望关注的某些兴趣, 所拓展的推荐是用户需求相关的。因此, LS-Group方法在推荐准确度上能更好地满足用户的需求。
本文提出一个基于本体和具有位置感知的图书馆书籍推荐模型, 该模型基于从个人信息、借阅记录、交互日志中学习的用户长、短期偏好和从区域组模型中获取的相似用户共性偏好向用户提供特定位置区域的书籍推荐。该推荐模型可以帮助提高图书馆的推荐服务, 不仅考虑了用户的个性化需求、区域组偏好的结合, 也有效地拓展了推荐。实验结果表明, 该模型能提高推荐的准确性和多样性。但仍然存在一些不足, 例如并未对公式(9)中各参数取值进行讨论。此外, 笔者未来会考虑将各种电子资源融合到推荐系统中, 以进一步提高推荐质量, 满足用户的书籍需求。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|