{kind=link}
{kind=link}
查询主题分类方法研究*
[刘峰1  , 李煜
, 李煜2 , 吕学强2 , 李卓2 ]
, 李煜|
|


李煜: 采集清洗分析数据, 进行实验, 撰写论文; 吕学强: 论文最终版本修订; 李卓: 论文修改与审查。刘峰: 提出研究思路, 设计研究方案, 辅助实验
[Objective] Expand the queries to get the query topic. [Methods] Get the query expansion text by using the pseudo-feedback technology, extract the text features and combine them by the proposed partial matching rules and vector space compression algorithm. In the end, the query topic classification can be done by the Cosine Include Angle and SVM. [Results] The precision can reach 90.34%, the recall rate is 89.34%, the F value is 89.67% and the accuracy is 89.24%. [Limitations] Online processing efficiency is not high because of expanding the queries using the searching results. [Conclusions] The proposed method is effective in query topic classification. Using the machine learning method can get the better experimental results than the Cosine Include Angle and it is significative for improving the quality of search engine.
搜索引擎已经成为人们从互联网上获取信息的主要工具。如何使搜索引擎更好地理解用户查询意图成为提高搜索引擎结果用户满意度的一个重要方面。
查询分类意在将互联网用户提交的查询按照主题或意图分配到预先定义的类别体系中[1], 在广告推荐和查询意图分析等方面有广泛的应用前景。查询主题分类处理的对象为用户提交的查询串, 文献[2]指出查询串的平均查询长度为1.85, 具有特征稀疏、信息量不足的特点。目前广泛采用查询扩展技术来弥补查询串由于内容少而导致分类困难的缺陷。搜索引擎通过识别查询串主题类别返回与用户主题更加相关的结果。所以利用查询扩展进行查询主题分类对提高搜索引擎质量有重大帮助。
查询分类大致可分为查询意图分类和查询主题分类[3]。Broder[4]按照意图将查询分为导航类、信息类和事务类, 文献[5]在此问题上进行了详细的综述。本文主要研究查询主题分类。查询主题分类, 主要指将查询映射到预定义的主题类别中[3], 主题类别包括“ 体育” 、“ 经济” 、“ 旅游” 等。
查询分类处理对象为查询串, 机器学习方法和传统的文本分类方法均可用来处理查询分类问题。但由于用户提交的查询串词汇少且有歧义, 利用传统的文本分类方法对查询串进行分类将面临严重的特征稀疏问题; 机器学习方法依赖于训练数据, 而难以获得大量有标注的查询串会导致数据稀疏问题。
解决特征稀疏问题的主要方法是通过对查询串进行查询扩展, 构建更加丰富的查询特征。Shen等[6]将查询串提交给某一搜索引擎, 用排序靠前的文本表示查询, 此方法有一定的延迟性。Broder等[7]提出在线下利用文本分类技术对搜索引擎文档分类。Shen等[8]利用查询日志, 选取与当前查询最相似的查询串进行扩展。也有学者利用外部知识如WordNet[9]或Wikipedia[10]对查询串进行扩展, 均取得了良好效果。解决数据稀疏问题可通过基于半指导学习的方法, 从查询日志等资源中扩充训练数据。Beitzel等[11]利用自然语言处理中的选择倾向性方法, 从未标注的查询日志中扩充训练数据。Hu等[10]利用少量种子从Wikipedia中获取概念类别, 从而实现查询分类。
本文利用搜索引擎伪相关反馈技术, 对查询串进行扩展, 丰富查询串特征; 使用Sogou实验室提供的分类文本语料作为分类基准文本。对扩展文本和分类文本提取特征, 定义部分匹配规则对其量化, 形成高维向量空间。观察高维向量特点并结合所提取特征, 提出空间压缩算法, 对特征进行融合, 形成压缩后的特征空间向量。分别利用向量余弦夹角和支持向量机(SVM)模型对其进行分类, 进一步验证所提方法的有效性。
查询串简短, 特征稀疏, 仅仅通过查询串本身很难准确地对其分类。因此, 利用伪相关反馈技术对查询串进行扩展, 形成扩展文本, 并对扩展文本进行分类, 将查询分类问题转换为文本分类问题。
伪相关反馈提供一种自动局部分析方法, 用户可不用参与额外的交互, 是用户行为分析和查询意图识别中常用的一种方法。用户查询串通常为关键字的组合, 仅仅通过查询串难以准确判断出查询主题。当用户向搜索引擎提交查询后, 搜索引擎返回查询结果, 包括摘要、标题和URL等。搜索结果中排序靠前的结果与查询串具有相近的主题, 则可以通过查询结果中的信息判断出用户查询串主题。
由于搜索引擎返回的文本摘要含有丰富的查询串主题信息, 可通过查询串摘要的内容判断查询串的主题。故本文将前N条搜索结果中的摘要合并成一个文档作为查询的扩展文本, 从而将对查询串的分类问题转换为对扩展文本的分类问题。
基于伪相关反馈的查询主题分类模型共分为三个模块: 扩展模块、特征提取模块和分类模块, 如图1所示。扩展模块中, 通过将查询串q提交到搜索引擎, 利用搜索引擎伪相关反馈技术返回的信息, 形成扩展文本。
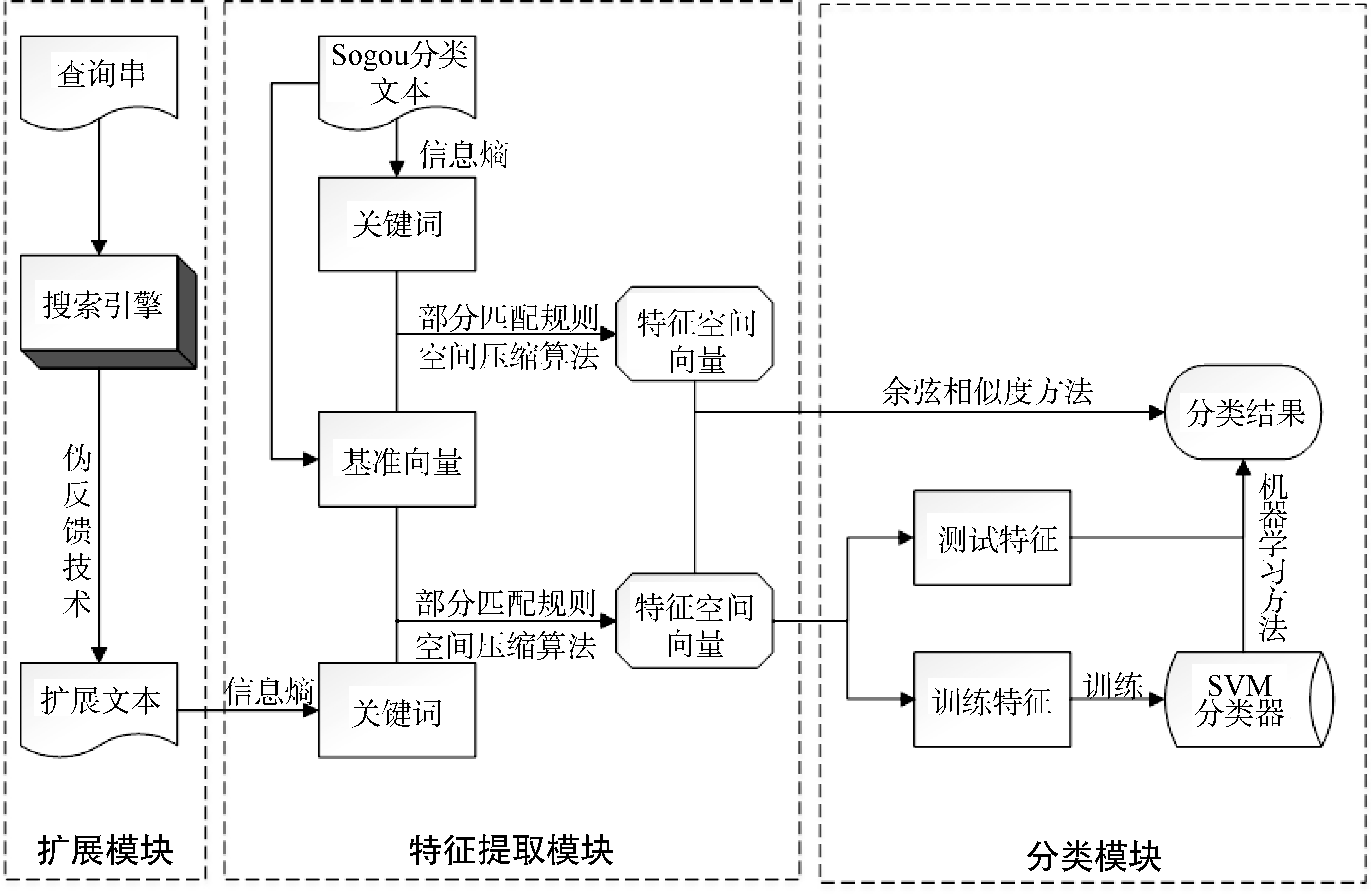 | 图1 基于伪相关反馈的查询主题分类模型 |
Sogou实验室提供了大量文本标注语料, 利用信息熵对扩展文本和每一类的分类文本提取关键词作为文本特征, 将每个分类文本的关键词组合形成基准向量。采用部分匹配规则和空间压缩算法, 形成特征空间向量。
分类模块中展示的是一个文本分类的过程。文本分类是在给定的分类体系下, 根据文本的内容自动地确定所属类别[12]。经过特征提取模块后, 得到特征空间向量, 文本分类问题可简化为向量空间中的向量运算, 通过计算向量之间的余弦距离来度量文档间的相似性。机器学习方法很早就被应用到文本分类中, 在分类效果和性能上相比传统方法均有很大的提升。其中, SVM模型相对于其他分类算法, 具有更好的分类性能[13], 被研究人员大量使用。本文分别以余弦相似度和SVM验证所提出的部分匹配规则和空间压缩方法在查询主题分类上的有效性。
对查询串q进行查询扩展得到扩展文本D(q), 将查询串分类转化为文本分类, 通过特征提取模块得到特征空间向量, 利用余弦相似度方法和机器学习方法, 得到分类结果, 从而得到查询串的主题类别。
查询串经过扩展模块、特征提取模块和分类模块后, 可得到其主题类别。特征提取模块中, 对文本进行特征选择得到关键词基准向量, 通过定义部分匹配规则提高关键词匹配成功率, 提出空间压缩算法对特征融合, 一定程度上解决特征稀疏问题, 最终形成特征向量空间。
通过伪相关反馈得到查询串q的扩展文本D(q), 查询串分类转化为文本分类。向量空间模型是一种常用的文本表示方法。但分词后的词特征项个数往往十分巨大, 因此需要进行特征选择, 即选择有代表性的、有类别区分性的词作为文本特征。
常用的特征选择算法有TFIDF、互信息、信息增益等, 本文引用文献[14]采用的信息熵理论, 计算词特征项的熵值, 熵值越大, 类别区分度越大。熵值大的词可选为文本关键词, 作为该文本一个特征。
利用信息熵分别对D(q)和分类文本进行特征选择, 并将熵值较大的关键词作为文档特征。利用中国科学院计算技术研究所分词软件ICTCLAS①对扩展文本和分类文本分词, 并进行噪声过滤、去停用词等初始化操作, 计算词信息熵, 提取熵值较大的前m个词作为文本特征, 则扩展文本和分类文本均可转化为一个m维的关键词向量 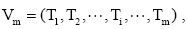 其中Ti为关键词特征, m为关键词个数且1≤ i≤ m。
其中Ti为关键词特征, m为关键词个数且1≤ i≤ m。
Sogou分类语料主题类别数为k个, 对每一类文本, 提取m个关键词, 将每一类别关键词特征有序组合, 则可形成一个m× k维的关键词基准向量Vm× k。
①http://ictclas.nlpir.org/.
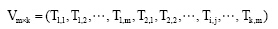 (1)
(1)
其中, Ti, j表示第i个类别中的第j个关键词, 并且1≤ i≤ k, 1≤ j≤ m。
通过对文本进行特征选择可以得到关键词向量Vm和关键词基准向量Vm× k, 将扩展文本的关键词向量和分类文本的关键词向量分别与关键词基准向量进行匹配, 可将关键词向量进行量化。
针对每一类分类文本, 将抽取到的关键词分别与关键词基准向量Vm× k进行匹配, 匹配成功记为1, 不成功记为0, 则每一个类别下的分类文本可以量化为由0、1组成的一个m× k维的向量V_ti (1≤ i≤ k)。
设qQ (Q为查询串集), D(q)为扩展文本, 提取n (n≤ m)个关键词, 形成n维向量Vkey, 以关键词向量Vm× k为基准, 将n个关键词分别与关键词向量依次匹配, 匹配成功记为1, 不成功记为0, 则查询串q的扩展文本D(q)也可量化为由0、1组成的一个m× k维向量Vq。
观察关键词向量中的关键词特征, 发现如下现象:
(1) 关键词向量中有很多短关键词串是关键词基准向量中某些长关键词串的子串;
(2) 关键词基准向量中也有很多短关键词串是关键词向量中某些长关键词串的子串。这些关键词含有相同的含义, 但若采用完全匹配规则, 即词串的每一个字必须对应相同, 则这些关键词不会匹配成功。故本文采用部分匹配规则, 定义如下:
∀ Ti, jVm× k, TiVkey, tiVq;
规则1: Ti, j contain Ti|| Ti contain Ti, j→ ti=1;
规则2: Ti, j not_contianTi & Ti not_contain Ti, j→ ti=0。
即当关键词向量和关键词基准向量中的词串进行匹配时, 词串的每一个字不必对应相同, 只需一个词串是另一个词串的子串, 即可认为这两个词串部分匹配成功, 否则部分匹配失败。比如“ 汽车产业” 为关键词基准向量Vm× k中一个关键词, “ 汽车” 为关键词向量Vkey中一个关键词, 按照上述匹配规则1, 则t=1。
通过特征选择, 形成一个m× k维的关键词基准向量Vm× k, 以Vm× k为基准, 每一类别的分类文本和查询串q的扩展文本D(q)通过部分匹配规则后均可量化为一个由0、1组成的m× k维向量V_ti和Vq。但是V_ti和Vq均为高维向量, 含有大量的0, 特征稀疏。通过向量空间压缩技术可在一定程度上解决特征稀疏问题, 同时分类的时间性能也会得到提高。
由公式(1)可知, 关键词向量Vm× k是由k个主题类别、每个主题类别含m个关键词组成的向量。对于任一主题类别i, 其中的m个关键词 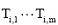 是这一主题类别中的m个特征, 均能体现出这个类别的特性, 故可将这m个特征视为一个整体, 既可强化这m个特征在该类别中的作用, 又凸显出该类别特性。基于这一特点, 本文提出向量空间压缩算法, 具体分为三步:
是这一主题类别中的m个特征, 均能体现出这个类别的特性, 故可将这m个特征视为一个整体, 既可强化这m个特征在该类别中的作用, 又凸显出该类别特性。基于这一特点, 本文提出向量空间压缩算法, 具体分为三步:
(1) 利用4.1节特征选择方法分别得到分类文本和查询串q的扩展文本的关键词向量Vm和Vkey, 并得到关键词基准向量Vm× k;
(2) 在关键词基准向量Vm× k的k个主题类别中, 将每个主题类别的m个关键词视为一个整体。以Vm× k为基准, 用Vkey中的关键词依次与Vm× k中每个主题类别中的关键词按照规则1和规则2进行匹配。设successi, j (1≤ i≤ k, 1≤ j≤ n, n为Vkey中关键词个数, k为主题数)表示第j个关键词是否与第i个主题内的关键词匹配成功, 匹配成功记为1, 否则记为0, Counteri (1≤ i≤ k, k为主题类别数)表示Vkey中关键词与Vm× k中第i个主题类别的m个关键词匹配成功的次数, 则 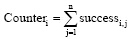 。量化后未经压缩的m× k维向量Vq就可以压缩为一个k维向量
。量化后未经压缩的m× k维向量Vq就可以压缩为一个k维向量 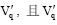 可表示为:
可表示为:
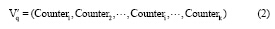
(3) 将分类文本得到的关键词向量Vm按照步骤(2), 经过压缩算法后, m× k维向量V_ti压缩为一个k维向量 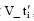 , 且
, 且 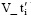 可表示为:
可表示为:
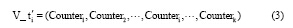
扩展文本的关键词向量中的n个关键词根据信息熵权重进行排序, 排序靠前的关键词更能体现出该查询串的特征。因此按照关键词的等级赋予每个关键词一定大小的权重, 排序靠前的关键词权重较大, 排序靠后的关键词权重较小。本文采用5等级权重, 权重等级与权重对应关系如表1所示。
| 表1 权重等级与权重关系 |
结合权重, 查询串q的扩展文本D(q)所形成的关键词向量中, Counteri变为 Counter'i:
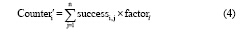
其中, factorl(1≤ l≤ 5)为第l个等级的权重, 则进行空间压缩得到k维向量 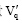 , 且
, 且 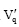 表示为:
表示为:

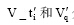 分别为训练文本和扩展文本采用部分匹配规则, 通过空间压缩和等级权重技术并量化得到压缩后的k维向量。利用余弦相似度算法和SVM对其分类, 得到查询串主题分类。
分别为训练文本和扩展文本采用部分匹配规则, 通过空间压缩和等级权重技术并量化得到压缩后的k维向量。利用余弦相似度算法和SVM对其分类, 得到查询串主题分类。
(1) 实验数据
本文主题类别体系采用Sogou实验室的主题类别体系①, 将查询串分为10个主题类别: 财经、IT、健康、体育、旅游、教育、招聘、文化、军事和汽车。从每个类别选择2 000篇文档作为分类文本。采用2012版Sogou搜索日志, 采样并标注2 233个查询作为测试查询串, 每一个查询串只标注一个主题类别。每个类别的分类文本样本数和查询串个数如表2所示:
| 表2 主题分类样本数及测试查询串数 |
实验中设置m值为100, n值为50, k值为10, 参考文献[1], 取N=80, 即爬取搜索引擎前N条搜索结果中的摘要。利用SVM进行分类时, 将每一类查询串分为5份, 每一类中选取其中4份作为训练语料, 总数为1 782个; 1份作为测试语料, 总数为451个。每个主题类别训练和测试查询串个数如表3所示:
| 表3 训练和测试查询串个数 |
(2) 评价指标
针对某一主题类别i, 采用文本分类中正确率、召回率和F值对分类结果进行评价, 分别记作Pi、Ri和Fi, 定义如下:
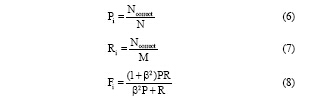
其中, Ncorrect表示被正确分为主题类别i的查询串数量, N表示被分为主题类别i的查询串数量; M表示测试集中属于主题类别i的查询串数量; β 为正确率和召回率的相对权重, 本文取β =1。
宏平均经常用来对分类的整体性能进行评价, 是每一个类别性能指标的算术平均值。上述三个指标的宏平均分别记作P、R、F。整体正确率A也是衡量全部主题类别分类性能的整体评价指标, 定义分别如下:
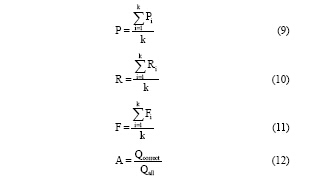
其中, k为主题类别数, Qcorrect表示被正确分类的查询串个数, Qall表示所有查询串的个数。
(3) 实验设计
在主题分类实验中, 共设计了两组实验: 利用余弦夹角分类和利用SVM分类。每一组实验中均有4小组实验, 分别对比将查询串扩展后形成的特征向量空间, 采用部分匹配原则、空间压缩技术和赋予权重后查询分类的实验效果, 共8小组实验。
在验证了本文查询主题分类方法有效性后, 对比采用相同措施、不同分类方法的时间性能, 并对分类方法时间性能差异进行分析。
本实验将对比查询串扩展后形成的特征向量空间, 采用部分匹配原则和空间压缩以及对关键词赋予权重后查询分类的实验效果, 并分别利用余弦夹角和支持向量机模型进行分类, 以验证方法的有效性, 实验结果如表4所示:
| 表4 查询串主题分类实验结果 |
分析比较采用余弦夹角作为分类器, 分别使用部分匹配、空间压缩和赋予权重后的实验效果, 以实验1为Baseline, 对比这4组实验, 可以看出: 由实验1到实验4, 正确率、召回率、F值和整体正确率逐步提升。其中实验4的4个评价指标相比Baseline有最大的提升, F值达到84.78%。
(1) 对比实验1和实验2: 实验1中采用完全匹配的规则, 实验2在实验1的基础上, 采用部分匹配的规则。实验2的各个指标均比实验1有明显提升, 其中整体正确率约提升6.36%。部分匹配规则对实验结果有明显影响, 主要有以下两个原因:
①利用粗粒度分词, 每个类别训练文本采用2 000篇搜狗分类语料, 在提取关键词过程中会出现大量长词串, 比如“ 车载导航仪” 、“ 汽车制造商” 、“ 搜狐汽车频道” 等。扩展文本中的短词串, 比如“ 汽车” 、“ 导航仪” 等, 根据部分匹配规则可以匹配成功, 反之亦可;
②训练文本为新闻语料, 人们在写此类文章时所用的词汇与摘要所用的词汇会有区别, 利用部分匹配规则可以在一定程度上缓解这种差异。
(2) 对比实验2和实验3: 实验3进行了空间压缩, 将原先的1 000维特征空间压缩至10维。实验正确率、召回率、F值和整体正确率均得到明显提升。利用空间压缩, 实质为将扩展文本中每类的50个特征进行融合, 不仅能使特征向量空间中0的个数减少, 即特征更加明显, 更能反映查询串歧义性的特点, 在计算相似度过程中, 也使得结果更加准确。
(3) 对比实验3和实验4: 实验4在实验3的基础上, 把关键词按照等级赋予权重, 按照顺序, 每10个关键词一个等级, 共5个等级, 权重由1依次降到0.2。观察表4, 关键词权重对查询串分类结果有一定的影响, 各个指标均提高了约0.5%。由于查询串具有歧义性, 提取得到的关键词在各个类别上都有可能得到匹配, 按照关键词赋予权重则可以部分抵消由于查询串歧义性而带来的分类错误。
分析比较采用SVM模型作为分类器, 分别使用部分匹配、空间压缩和赋予权重后的实验效果。并比较在相同条件下使用余弦夹角和使用SVM模型的实验效果。
(1) 由实验5到实验8, 实验评价指标均呈现明显提升的趋势。其中实验5未采用部分匹配、空间压缩和赋予权重技术, 实验效果最差, 而实验8采用部分匹配、空间压缩和赋予权重技术后, 整体实验效果最好, 正确率达到90.34%, F值达到89.67%。这与使用余弦夹角算法时有相同的趋势, 证实了部分匹配规则和空间压缩算法的有效性。
(2) 对比表4中实验1至实验3和实验5至实验7, 仅仅使用部分匹配和空间压缩技术时, 利用余弦夹角所得的实验效果要好于使用SVM所得的实验效果。但对比实验5和实验8, 当部分匹配、空间压缩和赋予权重技术结合起来使用时, SVM模型能取得比余弦夹角更好的实验效果。主要是因为通过部分匹配、空间压缩并对关键词赋予权重后, 能使各个类别的特征更加明显, 类别间的区分度也更大, 利用机器学习方法能达到更好的效果。
(3) 使用空间压缩算法将高维向量降至低维, 对分类的时间性能有很大的提升, 如表5所示:
| 表5 空间压缩算法时间性能比较结果 |
由表5可以看出, 当使用空间压缩算法时, 时间性能有明显的提升: 利用余弦夹角分类时间性能提升约9倍, 利用SVM分类时间性能提升约4倍。使用SVM模型进行分类的时间性能明显优于使用余弦夹角算法, 体现出机器学习方法的优势。
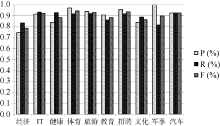
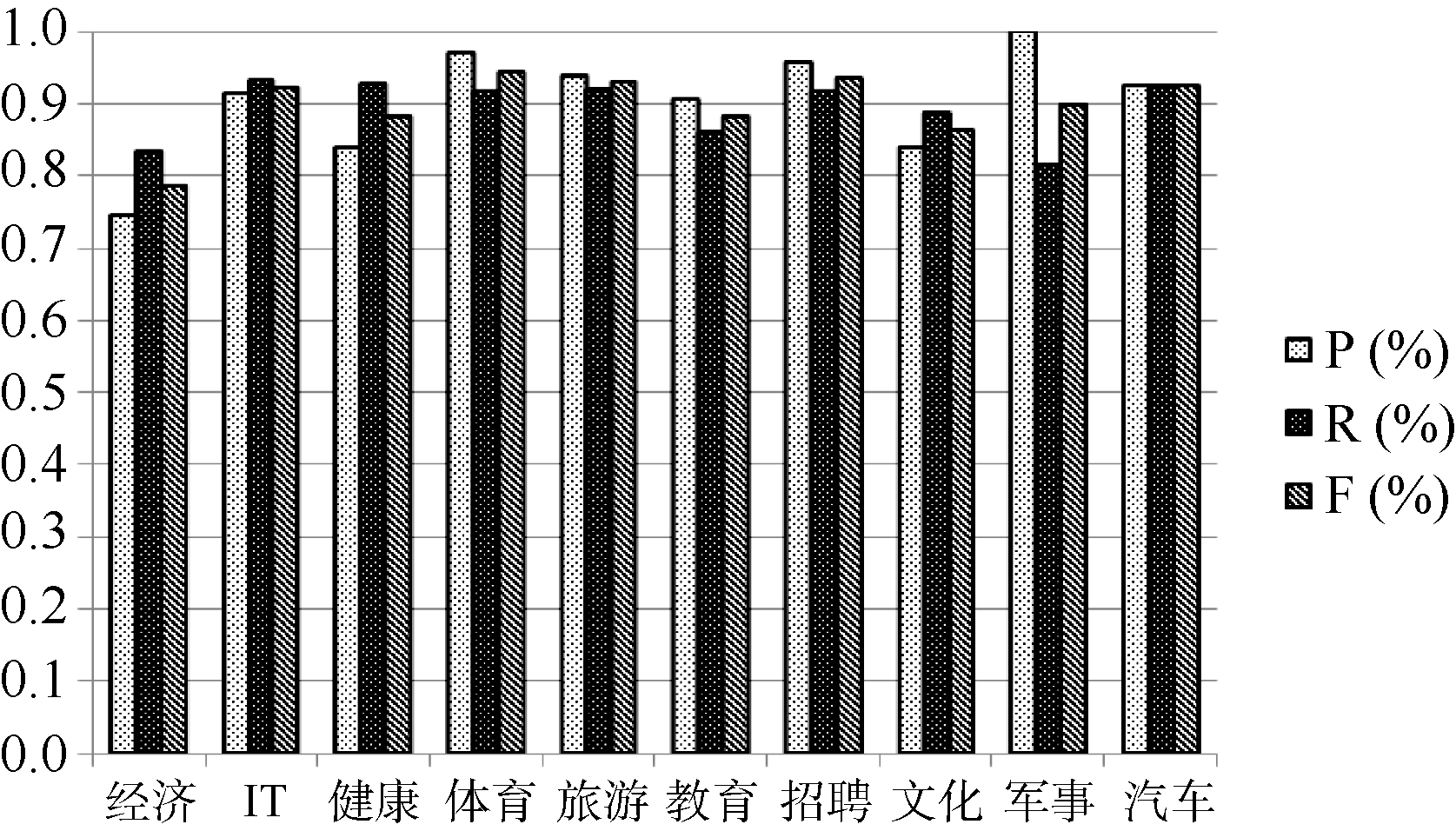
利用SVM算法进行查询串主题分类在各个主题类别上的P、R和F值的实验结果, 如图2所示:
 | 图2 SVM在不同主题上的实验结果 |
分析图2可以发现:
(1) 对于旅游、体育、汽车等几个主题类别, 实验均取得了较好的正确率、召回率和F值。因为这些主题类查询串具有明显的类别倾向, 歧义性较小。与之相反的是经济、教育、文化等几个主题类别未能取得较好的实验结果。
(2) 经济类查询串在10个类别中整体效果最差, 主要是由于很多经济类包含“ 银行” 、“ 住房公积金” 等关键词, 比如“ 住房公积金管理条例” 、“ 招商银行网点” 则被分为文化类。而且很多经济类查询串包含多个主题, 比如“ 恒大” , 可以指“ 恒大集团” , 也可以指“ 恒大足球俱乐部” , 实验中则被分为体育类。
(3) 10个类别中总体分类效果较好, 没有出现严重类别偏置。这主要是由于对文本进行了特征选择, 并且对特征进行了融合。
针对查询串信息量不足、难以对其直接分类的问题, 本文结合伪相关反馈技术, 获取搜索引擎返回结果的摘要信息, 对查询串进行扩展, 从而将查询串分类问题转化为文本分类问题。在进行文本分类过程中, 定义部分匹配规则并提出一种空间压缩算法, 对文本向量空间进行优化, 利用余弦夹角和机器学习算法SVM进行分类, 得到查询串的主题类别。实验结果表明该方法能有效地进行查询主题分类, 并能在一定程度上避免分类过程中类别偏置的问题。
根据搜索引擎返回结果进行查询扩展, 由于需要对文本摘要进行爬取, 并对文本进行特征提取, 故在线处理效率不高。可以利用搜索引擎海量的日志信息对查询串进行扩展, 这将是后续工作需要解决的问题。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|