
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
文本分类中受词性影响的特征权重计算方法*
[路永和 , 王鸿滨]
, 王鸿滨]
, 王鸿滨]
|
|


王鸿滨: 采集、分析数据, 设计研究方案, 进行实验, 论文撰写及最终版本修订。
[Objective] In order to get a higher precision, this paper is to improve the feature weighting method by introducing the effect of part of speech. [Methods] The effectiveness between introducing the part of speech into feature weighting and the classical TF-IDF is contrasted in text classification. In the approach of text classification introducing part of speech, the weights of part of speech is used for the feature weighting calculation, and using Particle Swarm Optimization to find the best weights of the part of speech. The parallel tests all use SVM classifier. [Results] The experiment results show that the improved feature weighting method performs better than the classical TF-IDF method, and the precision of text classification achieves obvious improvement in different dimensions of feature space, and the increments are between 2% and 6%. [Limitations] Because of the lack of experimental conditions, the weights ensured in the experiment is only a result close to the best weights, it is needed to expand the scale of data and increase the number of iterations so as to get better weights. [Conclusions] Introducing part of speech into text classification can get a higher precision. The influence degree of part of speech is nouns, verbs and string in decreasing order. The modified feature weighting method is not only applicable to a particular corpus, but also the general one.
随着网络技术的应用与发展, 电子文档的数量日益增加, 文本分类作为一项处理大规模文本信息的技术越来越受到人们的关注。在对文本分类技术进行研究的过程中, 如何提高分类的效率以及准确率始终是人们关注的重点。对此, 人们采用了多种途径来实现这一目的。有从方法上进行改进的, 提出了KNN、SVM等分类算法以及改进算法; 有从特征空间上进行改进的, 将粒子群优化算法(PSO)、遗传算法(GA)等引入特征选择环节; 有从特征的属性上进行改进的, 将特征在文本中所处的位置、特征的语义等特征属性对分类的贡献度加入到分类过程中。对此, 本文从特征的属性出发, 将特征的词性对分类的贡献度引入到分类过程中[1], 试图对分类的效率与准确率进行改善。
要对电子文档进行自动分类, 就要先对文本进行形式化的表示。目前的文本形式化表示模型主要有布尔模型(Boolean Model)[2]、概率模型(Probabilistic Model)[3]、向量空间模型(Vector Space Model, VSM)[4]等。而向量空间模型由于将文本表示成实数域上的多维向量, 使得其他领域的各种面向多维向量的建模方法和计算方法都能更好地应用到文本分类当中, 大大提高了电子文档自动分类的可操作性和可计算性[5]。
作为形式化表达电子文本的向量, 向量的每一维代表一个特征, 因此, 这些向量也被称为文本的特征向量。而在文本的特征向量中, 向量各维度的取值表示相应特征的权重, 而对这些权重如何取值就是文本分类过程中的权重计算环节。对此, 传统的方法是采用TF-IDF方法进行计算。
TF是词频, 一般写为tf(t, d), 表示特征t在文本d中出现的频率。
IDF是逆文档频率, 是特征在文本空间中分布情况的量化, 常用的计算方法是 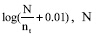 表示文本空间中文本的数量, nt表示出现过特征t的文本数量[6]。
表示文本空间中文本的数量, nt表示出现过特征t的文本数量[6]。
TF-IDF是综合特征的TF与IDF这两个属性而得出的一种计算方法, 表示一个特征在文本空间中的相关属性的衡量, 具体计算方法为[7]:
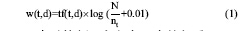
其中, W(t,d)表示特征t在文本d中的权重。
在实际应用过程中, 一般会对其进行归一化处理, 处理后的权重计算方法为[7]:
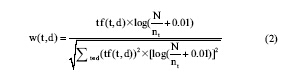
粒子群优化(Particle Swarm Optimization, PSO)算法是由Kennedy等[9]于1995年提出的, 其基本概念源于对鸟群捕食行为的研究, PSO是一种基于迭代的算法, 也是一种基于群智能随机搜索的算法。PSO算法中, 每个优化问题的解都是搜索空间中的一只鸟, 称之为“ 粒子” , 算法的过程就是一群“ 粒子” 在搜索空间中搜索最优解、不断向最优解靠近的过程。在搜索空间中, 每个粒子的位置和速度都以随机的方式进行初始化, 而后粒子就朝着全局最优(用gbest表示其位置)和个体最优(用pbest表示其位置)的方向靠近。所有粒子在每个位置都有一个由被优化函数决定的适应度值, 每个粒子还有一个速度决定其飞行的方向和距离。
在粒子群算法中, 如果粒子i的信息用D维向量表示, 则其位置表示为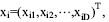 , 速度表示为
, 速度表示为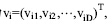 , 它们的更新方程分别为:
, 它们的更新方程分别为:

其中, t表示当前迭代次数;
对速度更新方程加入惯性权重
一般取
当前对于将词性的贡献度引入到文本分类方法的研究大多数只着眼于词性预处理环节— — 词性过滤, 也就是本文所提出的引入词性的文本分类方法的第一部分, 即在文本的预处理阶段根据词性对特征进行筛选, 而没有进一步将筛选过后剩余的词性对分类的不同贡献引入到特征选择环节中进行研究。通过已有研究可以了解到, 在文本分类中, 对分类结果贡献较大的词性有名词、动词、形容词等, 但显而易见的是不同词性的词对于文本内容的反映程度是不同的, 也就是说词性对于特征的权重应当是有影响的。
不同词性的特征对分类的贡献度是不同的。这一点可从两个方面进行讨论:
(1) 不同词性的不同特征对分类的贡献度是不同的。名词是描述人、事物、地点或抽象的词语, 动词是描述各类动作的词语。在大多数情况下, 描述人、事物、地点的词对比描述动作的词来说, 明显对文本内容的反映程度更好。例如“ 足球” 这个名词和“ 踢” 这个动词, “ 足球” 一般情况下出现在体育类别的文本中, 而“ 踢” 则可以出现在体育类“ 踢足球” 、经济类“ 房价VS地价, 谁踢了开发商的屁股” 等, 明显“ 足球” 对分类的贡献度更大。但也有特殊的情况, 例如“ 书” 这个名词能出现在很多类别中, “ 点射” 、“ 射击” 这些动词大多会出现在军事类、射击类、游戏类的文本中, 这些动词对分类的贡献度明显又比“ 书” 这类区分度较小的名词对分类的贡献度更大。对此, 笔者对不同词性进行不同程度的加权来调整特征的权重, 以期得出更合理的文本特征向量表达式。
(2) 同一个特征作为不同词性出现时对分类的贡献度是不同的。一个词在文本中出现时很可能是作为多种词性出现的, 例如在“ 小明是个热爱学习的好学生” 、“ 我们要积极学习党的十八大思想” 这两个句子中, “ 学习” 分别作为名词和动词出现, 但是根据人们的认知, 也可以知道当“ 学习” 作为名词出现时比作为动词出现时对文本内容的反映程度更高, 也就是说对分类的贡献度更高, 因为“ 学习” 作为名词出现时, 一般是出现在与教育相关的文本中, 而作为动词出现时, 可以出现在各种类别的文本中, 如“ 学习修车” 、“ 学习炒股票” 、“ 学习玩游戏” 等。所以, 也应当对特征作为不同词性出现时进行不同程度的加权, 得出该特征的一个词性加权总值。
综上所述, 在对特征进行词性加权时, 要解决的主要问题是: 不同词性应当赋予一个怎样的权重, 以及不同词性的权重分别是多少才是最优、最合理的。为了解决这一问题, 本文将采用粒子群算法进行迭代, 寻找一个尽量靠近最优、最合理的权重配比方案。
词性过滤是将文本集的分词结果进行预处理, 只筛选出需要的名词、动词、形容词、量词、字符串等词性的特征, 过滤掉对文本分类结果无意义或容易造成负面影响的数词、副词、介词等词性的特征, 形成原始特征集, 达到初步降维的目的。
2005年, 李彦平等[11]就提出了基于词性的特征预处理方法, 其提出的特征降维的方式包括词性过滤, 在文本预处理环节中过滤掉副词、形容词、叹词等对分类结果没有贡献或者贡献很小的词性, 只保留对分类结果贡献较大的名词、动词、缩略词等词性, 这一方法很好地降低了文本空间的特征维度, 大大提高了后续的分类效率。此后, 胡燕等[12]在特征提取环节中, 先进行词性过滤, 提取出名词、动词作为一级特征, 然后采用TF-IDF计算出各个词的权值并且进行排序, 选择排名前K位的词作为特征组成表示文本的特征向量, 这一流程成为后续研究者基于词性的特征提取方法的基本流程。随后, 李英[13]对基于词性的特征预处理方法进一步研究, 分别采用名词、名词加动词两种组合方式对特征进行筛选, 用TF-IDF提取排名前1 000的特征进行分类, 并对分类结果进行分析, 结果表明, 使用词性过滤对文本进行预处理, 能够大幅度缩减特征空间的维度, 并且对分类结果产生的影响较小。郑伟等[14]也对词性过滤的效果进行实验, 进一步加入“ 名词+动词+形容词” 的组合方式对特征进行筛选, 并研究出在不同大小的特征维度的最优词性组合方式, 如在500-2 000维, 选用“ 名词+动词+形容词” 的组合方式会使分类效果最佳。
通过3.1节的分析可以知道不同词性对文本内容的反映程度不同, 对此, 本文对不同词性的词语进行不同的加权, 得出一种结合词性的权重计算方法, 如公式(7)所示:
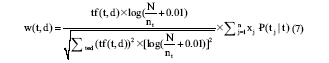
其中, xj表示第j种词性的词性权重, 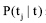 表示在特征t出现时作为第j种词性出现的概率, 如
表示在特征t出现时作为第j种词性出现的概率, 如 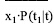 中, 如果x1为名词的词性权重, 则相应的
中, 如果x1为名词的词性权重, 则相应的 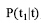 为特征t出现时作为名词出现的概率; n表示特征出现的词性类别数。整个改进部分
为特征t出现时作为名词出现的概率; n表示特征出现的词性类别数。整个改进部分 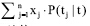 表示特征t在特征选择环节的词性加权总值。
表示特征t在特征选择环节的词性加权总值。
对于词性权重的取值, 本文采用粒子群优化算法完成。设计粒子的位置代表各个词性的词性权重, 则粒子的维数为所划分的词性的种类数。在本文的实验中, 将经过词性过滤后的特征的词性分为5种: 名词、动词、形容词、量词、字符串。因此粒子的向量表达式为
本文引入词性权重对权重计算方法进行改进, 目标是提高文本分类的准确率。因此, 在实验中以文本分类的准确率来衡量词性权重配比的优劣, 以此指导粒子向分类准确率更高的词性权重配比空间进行搜索。所以, 将粒子群算法的适应度函数设计为文本分类的准确率, 得到的适应度函数如公式(8)所示:

输入: 训练文本集, 测试文本集, 粒子群粒子总数n, 最大迭代次数T
输出: 基于当前文本集的最优权重配比, 分类准确率
(1) 使用中国科学院计算技术研究所ICTCLAS 2013分词器[15]对训练文本集进行分词处理;
(2) 进行词性过滤操作, 筛选出分词结果中的名词、动词、形容词作为特征, 构成原始特征集;
(3) 使用IG算法进行特征选择, 选择出排名靠前的一定数量的特征组成特征空间;
(4) 用随机函数在区间(0, 1]内为每个粒子每个维度
(5) 进行下一次计算, 在本次实验中, 取
(6) 对每个粒子, 若当前位置的适应度值大于个体最优解的适应度, 则将当前位置作为个体最优解, 若个体最优解的适应度值大于全局最优解适应度, 则将个体最优解作为全局最优解;
(7) 计算迭代次数, 若达到最大迭代次数, 程序结束, 将当前的全局最优解作为最终解, 并进行输出, 作为基于当前文本集的最优权重配比, 并取对应的适应度值作为分类准确率; 若未达到最大迭代次数, 则返回步骤(5)。
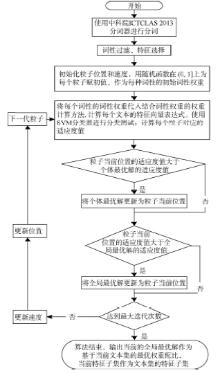
算法流程如图1所示。
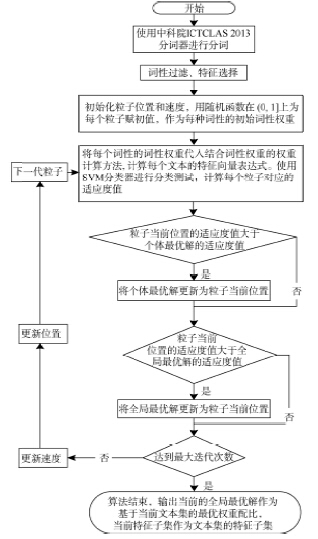 | 图1 结合词性的权重计算方法 |
为了说明引入词性对文本的贡献有助于提高文本分类的准确率, 本文采用控制变量法进行对比实验, 在其他流程不改变的情况下, 分别对权重计算方法是否引入词性权重进行实验。选择传统的TF-IDF方法作为对比实验的权重计算方法, 计算每个文档的特征向量表达式, 对文本进行分类, 计算分类准确率; 将词性权重引入到权重计算方法中, 得出结合词性的权重计算方法, 用结合词性的权重计算方法计算文本的特征向量表达式, 再对文本进行分类, 计算分类准确率。在结合词性的权重计算方法中, 为了确定一个最优的词性权重系数配比, 采用粒子群优化算法进行迭
代, 设置粒子群总数为50, 最大迭代次数为20, 将分类准确率作为粒子的适应度进行迭代计算。实验环境为Windows7操作系统, 2GB内存, 利用Java语言编写程序, 集成开发环境为Eclipse。
为了更好地进行实验对比, 本文的文本分类流程除权重计算环节外均是一致的, 整个流程如下:
(1) 文本预处理, 对文本进行分词处理, 并进行词性过滤, 根据中国科学院计算技术研究所分词器提供的“ ICTPOS汉语词性标记集” [15], 选择其中的名词、动词、形容词、量词、字符串组成原始特征集;
(2) 特征选择, 利用IG算法进行特征选择, 得出文本特征空间;
(3) 权重计算, 为本实验的关键环节, 采用前述方法进行;
(4) 文本分类, 采用SVM算法进行文本分类, 并计算分类的准确率。
此外, 为了更好地说明算法的适用性, 本文采用两个数据集分别进行实验: 用网上抓取的2 100篇文档作为实验数据集进行实验, 此为实验一; 选取复旦大学语料集中的2 100篇文档构成实验数据集进行实验, 此为实验二。
使用爬虫工具从新浪网上抓取10 000余篇文档进行人工筛选并分类, 选取其中语料较为丰富的7个类别, 分别为娱乐、财经、游戏、职场、军事、体育、神秘学, 每个类别随机选择300篇文档构成实验语料集, 共2 100篇文档。每个类别随机选取200篇作为训练文本, 构成训练文本集, 共1 400篇; 剩余的文本构成测试文本集, 每个类别100篇, 共700篇。具体实验数据如表1所示:
| 表1 基于抓取语料的两种权重计算方法 分类准确率比较1 |
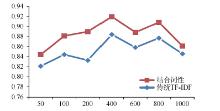
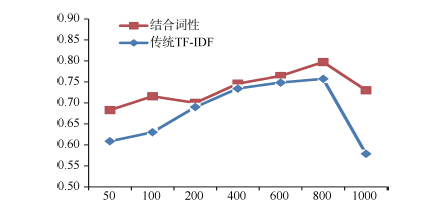
绘制成折线图如图2所示:
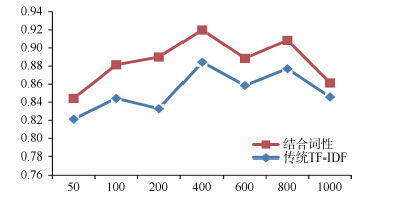 | 图2 两种权重计算方法准确率走势图1 |
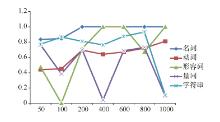
在实验一中, 采用结合词性的权重计算方法取得上述准确率时, 各词性的词性权重的取值绘成折线图如图3所示:
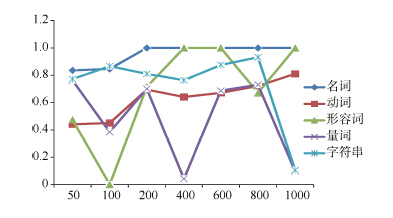 | 图3 各词性在不同维度的权重取值1 |
与表1相对应, 图2中的横坐标为特征维数, 即特征选择后特征空间所含特征的数量; 纵坐标为分类准确率, 即正确地分到相应类目中的文本数量占总文本数量的比重。从图2可以很直观地看出, 使用结合词性权重的TF-IDF方法进行权重计算比使用传统的TF-IDF方法分类准确率更高。从表1的数据可以看出, 结合词性的TF-IDF方法准确率比传统的TF-IDF方法高2-6个百分点。因此, 结合词性的TF-IDF权重计算方法较好地提高了文本分类的准确率。同时也证明不同词性对文本分类的贡献度是不同的, 即词性对分类的准确率是有影响的。尤其当特征维数在100-800时, 使用结合词性的TF-IDF方法进行权重计算, 分类准确率都保持在80%以上, 达到了较好的分类效果。
利用复旦大学李荣陆[16]提供的语料库中的一部分, 选取其中语料较为丰富的7个类别, 分别是农业、艺术、计算机、经济、环境、政治以及体育, 每个类别随机选择300篇文档构成实验语料集, 共2 100篇文档。其中, 每个类别随机选择200篇作为训练文本, 构成训练文本集, 共1 400篇; 剩余的每个类别的100篇文本作为测试文本, 构成测试文本集, 实验过程如前所述, 具体实验数据如表2所示:
| 表2 基于复旦大学语料的两种权重计算方法 分类准确率比较2 |
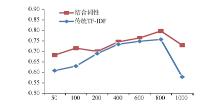
绘制成折线图如图4所示:
 | 图4 两种权重计算方法准确率走势图2 |
在实验二中, 采用结合词性的权重计算方法取得上述准确率时, 各词性的词性权重的取值绘成折线图如图5所示:
 | 图5 各词性在不同维度的权重取值2 |
与表2相对应, 图4中的横坐标为特征维数, 即特征选择后特征空间所含特征的数量; 纵坐标为分类准确率, 即正确地分到相应类目中的文本数量占总文本数量的比重。从图4可以很直观地看出, 使用结合词性权重的TF-IDF方法进行权重计算比使用传统的TF-IDF方法分类准确率更高。从表2的数据可以看出, 结合词性的TF-IDF方法准确率比传统的TF-IDF方法最高高出约15个百分点, 由此可见, 实验二也说明词性对分类的准确率是有影响的。
实验一和实验二的结果都显示出结合词性的权重计算方法分类效果优于传统的TF-IDF方法, 表明词性对文本分类的准确率是有影响的。而两个实验都获得了较为理想的效果, 说明结合词性的权重计算方法并不只适用于某个特定的语料集, 而是可以适用不同的语料集。
由于实验条件的不足, 在使用粒子群算法寻找最优权重配比时得出的结果仅是接近最优解的配比, 因此在各个维度的实验中, 权重配比没有呈现出完整的一般性规律。但是从实验结果图3及图5来看, 在各组实验当中, 名词的权重均是保持最高的状态, 与3.1节的预测一致。其次是字符串的权重, 稳定在一个较高的水平, 这一点或许与各领域具有其专有的词组、术语相关。动词的权重也较稳定, 但是相对于名词和字符串来说, 保持在一个较低的水平, 也符合3.1节的推测。而形容词及量词的权重波动较大, 需要通过进一步实验确定其具体的权重取值。
本文将词性权重引入到文本分类当中, 通过实验验证了词性对分类结果是有影响的。而本文采用的引入词性权重改进权重计算方法的方式只是一种初步的尝试, 希望以后通过进一步的研究能找到更有效、更合理的结合词性的权重计算方法。此外, 也将进一步尝试将词性对分类结果的影响引入到文本分类的其他环节, 如将词性权重引入到特征选择环节中, 以期选择出一个更优的特征空间, 从而改善分类效果。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| 17 |
|
| 18 |
|
| 19 |
|
| 20 |
|
| 21 |
|
| 22 |
|
| 23 |
|