{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
混合拓扑因子的科研网络合作关系预测*
[伍杰华1, 2  , 朱岸青
, 朱岸青1, 3 ]
, 朱岸青|
|


伍杰华: 提出研究思路, 设计研究方案, 进行实验并起草论文; 朱岸青: 采集、清洗和分析数据,论文最终版本修订。
[Objective] The paper aims to predict the cooperation between scholars according to the academic research network’s structural information. [Methods] A novel mixture topological factor predictive model called MTF is proposed, which cooperating local feature factors and global community factors. This model firstly introduces Naïve Bayesian algorithm to calculate local factors and then uses community contribution to compute the global factors. [Results] Experimental results show that MTF method can effectively handle the task of real scientific collaboration network relationships prediction, also performs better than some of the classic and newly proposed algorithms. [Limitations] The data used in the experiments should be at a larger scale. [Conclusions] This paper proves that the proposed model can mine community information for improving prediction performance, which leads to a new path in such area.
复杂网络(Complex Network)是一种描述对象之间相互关系的图模型, 它具有自组织、自相似、吸引子、小世界、无标度中部分或全部性质, 如生命科学领域的各种网络、Internet/WWW网络、社交媒体网络, 包括流行性疾病的传播网络、科学家合作网络[1]、语言学网等。目前, 复杂网络研究正渗透到数理学科、计算机学科和工程学科等众多领域, 对复杂网络的定量与定性特征的科学理解分析已成为网络时代科学研究的主要问题。
本文主要研究一种经典的复杂网络模型— — 科研网络中合作关系预测的问题[2]。科研网络主要描述科研人员之间合作关系或者论文之间的引用关系, 在该类网络中, 每个科研人员作为网络中的一个节点, 如果两个科研人员之间共同发表过一篇科研论文, 这两个节点之间就存在关系, 即形成一条连边, 那么大量科研人员之间的关系形成了一个结构复杂的网络, 即科研合作网络。深入研究挖掘科研网络的动态变化有助于理解其演化结构和隐含信息[3], 为科研合作提供帮助, 对合作关系预测便是其中一个主要的研究方向, 它通过学习科研合作者的属性及其相互间合作关系, 预测两个科研人员未来合作的可能性, 其在关系推荐[4]、科研工作者重要性度量(重要有影响力节点发现)[5]等多个方面具有重要的应用价值。
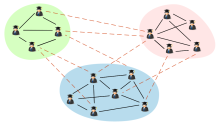
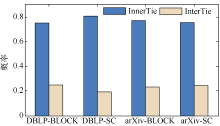
目前, 合作关系预测主要通过图论和网络理论中的链接预测算法实现, 其思想是通过已知的网络结构信息预测未来节点之间产生连边的可能性, 其作为数据挖掘和复杂网络分析的主要研究方向已经有工作正在开展, 其中一类主流的算法是通过无监督模型计算两节点之间的相似度。相似度表示两个节点之间(或称节点对)结构属性的相似性及产生连边的可能性, 假设相似性越大, 它们之间存在连边的可能性就越大。Liben-Nowell等[6]总结了基于网络拓扑结构的相似性定义方法, 将这些指标分为基于节点和基于路径两类, 并分析了若干指标对的相互作用、网络中链接预测的效果。Lü 等[7]将经典的相似度算法分为局部相似度和全局相似度两类, 通过详细的实验进行比较和总结。Tang等[8]提出一种跨域的合作关系推荐算法, 该算法引入一种多领域的主题特征模型(Cross-domain Topic Learning, CTL)进行关系推荐, 取得了较好的效果。Sun等[9, 10]采用元路径模型(Meta-Path Model)概念对DBLP合作网络预测问题进行建模, 并把问题推广到异构信息网络中(Heterogeneous Information Networks)中。综上所述, 该领域的大量工作取得了一定的成果, 但是其中的不少算法均忽视了科研合作网络的隐含结构信息, 并不能反映其拓扑特性的多样性, 较为突出的一点在于模型缺乏挖掘科研合作者中“ 群” 的特点, 即具备相同领域或者相同研究方向的合作者可能会产生许多合作关系, 这构成了复杂网络中的经典结构: 社区[11]。社区相当于子网络, 整个网络是由若干个具备“ 社区” 或“ 群组” 结构的子网络构成, 如图1所示, 科研网络图中每个颜色区域代表社区, 可以看出社区内部的节点间链接相对非常紧密, 社区间的链接比较稀疏, 即社区内部关系(InnerTie)比社区间关系(InterTie)多, 其比率的图形表示如图2所示。
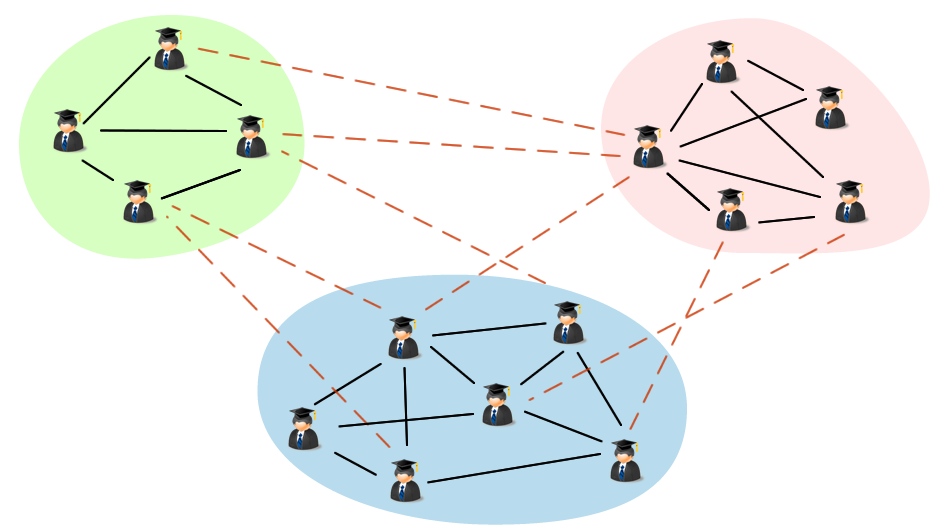 | 图1 科研网络简图 |
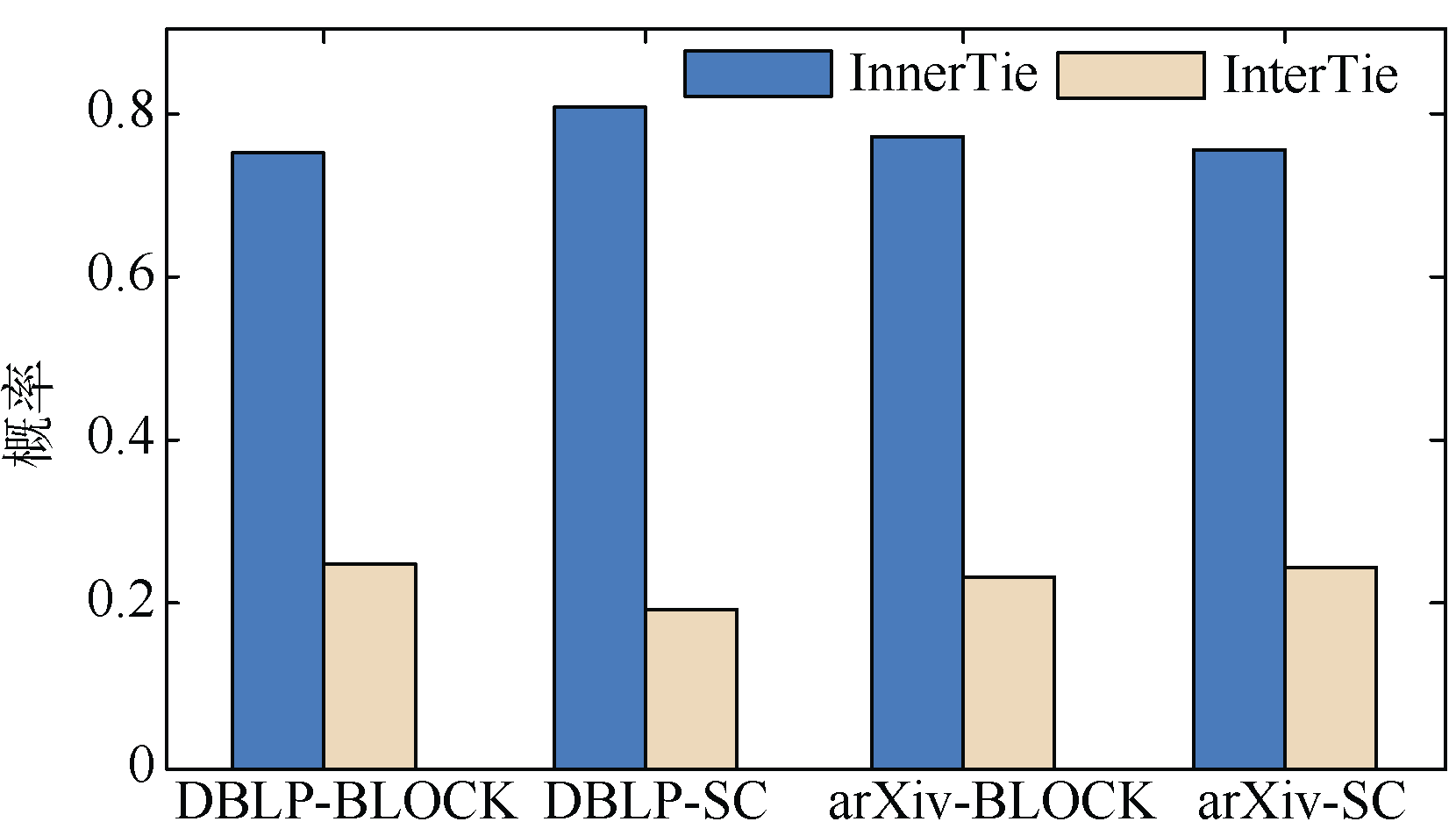 | 图2 社区内外关系比率 |
因此, 社区内部产生合作关系的数目或者概率可能会相对较高。详细地说, 对于两个身处同一社区合作紧密的科研人员, 他们处于同一社区的共邻节点(即共同的科研合作者)数量较多, 则他们很有可能会在以后产生合作关系, 那么如何针对这一突破点进行模型构建和预测显得十分必要。
本文提出一种新的挖掘社会网络社区拓扑属性并将局部拓扑因子(简称局部因子)和全局拓扑因子(简称全局因子)混合集成进行建模预测科研合作关系的算法— — 混合拓扑因子模型(Mixture Topological Factor, MTF)。
定义科研网络的无向图模型G=(V, E, R), V和 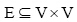 分别为模型中节点(也可称为合作者)和链接(也可称为合作关系)的集合, L定义为网络中的关系集合, 节点u, vV中形成的链接e(u, v)E被认为是L上定义的一个关系, 其映射函数为: ϕ : V× V× L→ E。其中e(u, v)为节点对, 为节点对的共邻节点集合, 简写记为CN(u, v)。划分G的社区集合:
分别为模型中节点(也可称为合作者)和链接(也可称为合作关系)的集合, L定义为网络中的关系集合, 节点u, vV中形成的链接e(u, v)E被认为是L上定义的一个关系, 其映射函数为: ϕ : V× V× L→ E。其中e(u, v)为节点对, 为节点对的共邻节点集合, 简写记为CN(u, v)。划分G的社区集合: 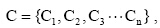 , 每一个Ci都有其包含的节点和链接。划分结果中不存在社区重叠的节点, 同时任意的节点只属于一个社区, 链接则是连接同一个社区内的节点和不同社区之间的节点。
, 每一个Ci都有其包含的节点和链接。划分结果中不存在社区重叠的节点, 同时任意的节点只属于一个社区, 链接则是连接同一个社区内的节点和不同社区之间的节点。
给定一个社会网络G , 在G中随机移除一定比例的边, 把E分为训练集ES和预测集EP, 即原网络G变为GS=(V, ES)和GP=(V, EP)。本文将GS作为源网络, 即训练网络, 将GP作为预测网络, 采用无监督模型对所有候选集中的关系对计算其发生关系的可能性并进行排序, 也就是计算下列到实数集合R的映射:
Q(GS, GP, C)→ R
预测关系存在或者不存在这一问题其实是一个基于机器学习的二分类或者聚类问题, 那么关系所代表的特征因子的选择和获取便显得尤其重要, 文献[6]总结了大部分的拓扑特征因子, 并将其分为局部因子和全局因子两类, 但是目前这一领域尚无完善的算法框架集成这两类因子, 因此, 本文拟对此问题建模, 并采用乘法进行集成, 如公式(1)所示:
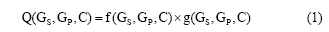
其中, f(GS, GP, C)是局部因子, g(GS, GP, C)是全局因子, 为了更好地度量差异化因子对合作关系的贡献, 笔者对公式(1)进行对数运算并赋予参数λ :
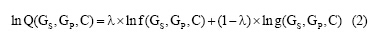
局部节点因子f(GS, GP, C)是关系预测领域算法的重要特征, 如节点因子或者共邻节点因子等, 在本文中主要采用共邻节点因子(或称节点对因子), 其中共邻节点因子衍伸出许多经典的预测算法, 例如共邻节点数目(Common Neighbors)、共邻节点度的对数反比和(Adamic-Adar, AA)、共邻节点度的反比和(Resource Allocation, RA)等。但是许多因子的实现均是单个共邻节点属性的叠加, 无法定义每个共邻节点的角色与贡献, 故笔者引入Liu等[12]提出的基于朴素贝叶斯模型(Local Bayesian Naï ve, LNB)的预测算法进行局部因子的计算。朴素贝叶斯分类器是一种应用基于独立假设的贝叶斯定理的简单概率分类器, 为了更精确地描述这种潜在的概率模型为独立特征模型, 给定特征因子 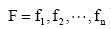 下某个分类L的概率可表示为条件概率P(L|F)[13]:
下某个分类L的概率可表示为条件概率P(L|F)[13]:
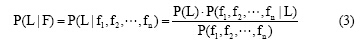
假设所有属性均为独立, 则:
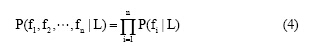
那么, 公式(3)可变为:
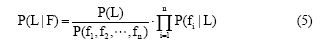
结合公式(5)和科研网络的合作关系e(u, v)预测, 笔者定义特征因子  是共邻节点对(为节点u, v和其共邻节点CN(u, v)所组成的关系集合), e(u, v)= 1/0为存在或者不存在的链接关系的概率, 即将P(L|F)看成给定一组共邻节点属性下的关系产生的条件概率, 其概率形式为:
是共邻节点对(为节点u, v和其共邻节点CN(u, v)所组成的关系集合), e(u, v)= 1/0为存在或者不存在的链接关系的概率, 即将P(L|F)看成给定一组共邻节点属性下的关系产生的条件概率, 其概率形式为:
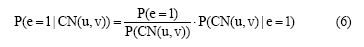
同理, 可得到在e(u, v)=0时, 即不存在合作关系的条件概率。
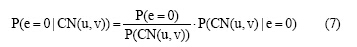
由于CN(u, v)是集合, 直接计算P(CN(u, v)|e=1)或者P(CN(u, v)|e=0)较难, 同时由于预测节点对节点u, v和共邻节点倾向于产生三角关系, 根据朴素贝叶斯公式, 可以对公式(6)和公式(7)进行变形, 分别得到关系e(u, v)=1或者e(u, v)=0的条件概率如下:
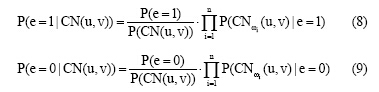
其中, ω i是给定节点对的共邻节点, 由于P(CN(u, v))也不易求得, 因此将公式(8)和公式(9)的比率[12]定义为其相似度, 即局部因子为:
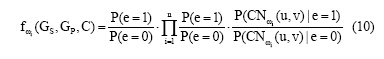
本文引入的社区划分算法有:
(1) Block Model划分算法(BLOCK)。Newman[14]在模块度矩阵的基础上, 结合谱分析的思想, 提出了一种新的算法, 目的是为了让社区内部拥有尽可能多的边数。此目的可通过最大化实际网络中社区内部的边数和网络在随机相连的情况下社区内部的边数的差值来实现。
(2) SpectralClust划分算法(SC)。谱聚类[15](Spectral Clustering, SC)是一种基于图论的聚类方法, 将带权无向图划分为两个或两个以上的最优子图, 使子图内部尽量相似, 而子图间距离尽量较远, 以达到常见的聚类的目的。主要思想是通过对邻接矩阵形成的拉普拉斯矩阵或标准矩阵的特征值、特征向量的分析, 挖掘网络中的社团结构。
由于社区内部节点间联系紧密而社区间节点联系较为稀疏, 如果社区划分时较多的链接被分到社区内部, 那么这样的划分显然是符合原理的, 一般用模块度(Modularity)的定义来衡量网络能否有效划分为社区度量, 后续的实验也会给出模块度对合作关系预测的性能影响, 即社区划分算法好坏对合作关系预测存在一定影响。首先给出基于社区的节点属性定义,  和|N|分别是Ck社区内所有节点数目和网络总节点数目。用Din_ω 表示共邻节点ω 与其所在社区Ck其他邻接节点之间出入度,
和|N|分别是Ck社区内所有节点数目和网络总节点数目。用Din_ω 表示共邻节点ω 与其所在社区Ck其他邻接节点之间出入度, 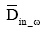 表示社区Ck所有节点出入度的均值,
表示社区Ck所有节点出入度的均值, 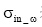 表示标准差, 则共邻节点ω 在社区Ck内部的链接度kin_ω 为:
表示标准差, 则共邻节点ω 在社区Ck内部的链接度kin_ω 为:
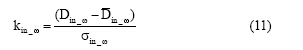
由于图1和图2均给出了科研网络社区内外链接关系密度差异较大, 故采用共邻节点社区链接度度量节点的贡献有助于进一步划分社区划分对不同共邻节点的影响。此外, 由于社区的规模和其拓扑属性也会对共邻节点有影响, 还需要定义社区参与系数刻画该节点与其他社区共邻节点的链接情况并差分化处理不同社区对不同节点的贡献, 那么共邻节点ω 的参与系数 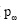 定义为:
定义为:
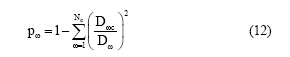
其中, Dic描述ω 与社区Ck中节点的链接数, Dic描述ω 的总链接数, Nc是社区的数目。所以, 共邻节点的贡献定义为社区内的影响和社区外的影响的比率:
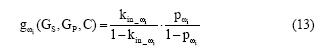
其中, 分子和分母分别表示共邻节点受社区内部属性和外部属性的影响, 分子越大, 贡献越大, 符合文献[7]提出的合作关系预测准确度受社区内部节点的影响相对较大这一原理。模型中算法的整体流程如下所示:
Algorithm Process:
Input: G=(V, E, R)
Output: Precision & & AUC
Initialize
for t = 1, …, T do //进行T次训练
G is divided into GS and GP
for m = 1, …, n do //Computing Precision
Qe(u, v)fe(u, v)(GS, GP, C)× ge(u, v)(GS, GP, C)
End for
Ranking Train(GS); //对训练集运算获取排序列表
Precision, AUC Ranking.Predict(GP); //排序后获取精确度及计算AUC
End for
为了更好地验证算法的性能, 实验采用了两个真实的科研合作网络数据集:
(1) DBLP[16]: DBLP是计算机领域内对研究成果以作者为核心的一个计算机类英文文献的集成数据库系统, 实验抽取其中一个子集— — 数据库领域的科研合作关系网络。
(2) arXiv[16]: arXiv是一个收集物理学、数学、计算机科学与生物学论文预印本的网站, 该数据集反映了这些论文作者的合作关系。实验抽取凝聚态物质领域(Cond-mat) 从1995 年到1999年的文献。
其科研合作网络结构属性如表1所示:
| 表1 科研合作网络结构属性 |
实验基于Complex Networks Package for Matlab和Link Prediction Package, 采用Matlab语言进行开发。在实验评价上分别采用以下三类标准:
(1) 预测精确度采用10-folder交叉验证方法进行, 交叉重复验证10次, 每次选择一个子集作为测试集, 并将10次的平均交叉验证Precision作为评价指标, Precision是指预测命中数目PrTop-N和Top-N个预测值的比率:
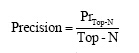
(2) 随机从GP和GN(不存在的关系集合)中抽取两个关系n次, 分别计算两个关系在模型中的相似度, 如果有nh次前者的相似度比后者大, ne次相等[7], 那么:
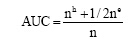
(3) 受试者工作特征曲线 (Receiver Operating Characteristic Curve, ROC)是显示链接预测模型识别结果真正率和假正率之间折中的一种图形化方法。
(1) 结果简介
从整体上验证MTF算法的性能, 对于两种社区划分算法BLOCK和SC, 为了更加直观地说明不同社区划分方法对因子混合的影响, 分别采用两种算法对其进行建模并称为MTF-BLOCK和MTF-SC。各模型效果评价如表2所示, 其中采用90%训练集, 10%预测集, λ =0.5, 取运行10次的平均结果, 黑体为较优值, 其中Prec@100和Prec@500分别是Top-N为100和500的准确度。
| 表2 各模型效果评价 |
从表2可以看出, 对于Precision(+1%– +6%)和AUC(+3%– +15%)指标, 两种MTF算法均优于其他经典的算法(CN, LHN, AA, RA)和新近提出的算法(Superpose Random Walk, SRW)。尤其对于MTF-SC, 其精度有最明显的提高, 这是由于该社区划分方法能够进一步区分社区内外的紧密程度。
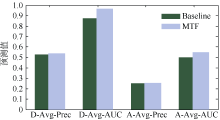
此外, 为了更加直观地说明混合因子集成对预测结果的影响, 本文对基于混合拓扑的社区算法(MTF- BLOCK和MTF-SC)和基于局部或者全局因子的Baseline算法(CN, LHN, AA, RA, SRW)进行横向比较, 各算法的平均性能如图3所示, 可以清晰看出MTF的整体性能比Baseline要优异。
 | 图3 各算法的平均性能 |
(2) 模型的可扩展性分析
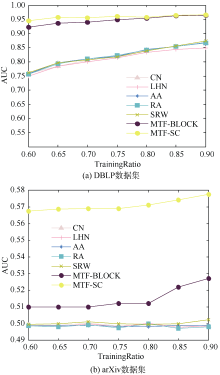
算法的性能可能会受训练集和测试集规模的影响而不稳定。实验把训练集GS占集合G的比率记为β , 建立分类效果和β 的函数关系, 训练集变化下的算法性能分析如图4所示, 可以看出, 对于两个真实数据集, 随着β 的增加, 各曲线均成正比增长, 这符合原来的预测, 证明特征及MFT模型具备可扩展性, 性能稳定。
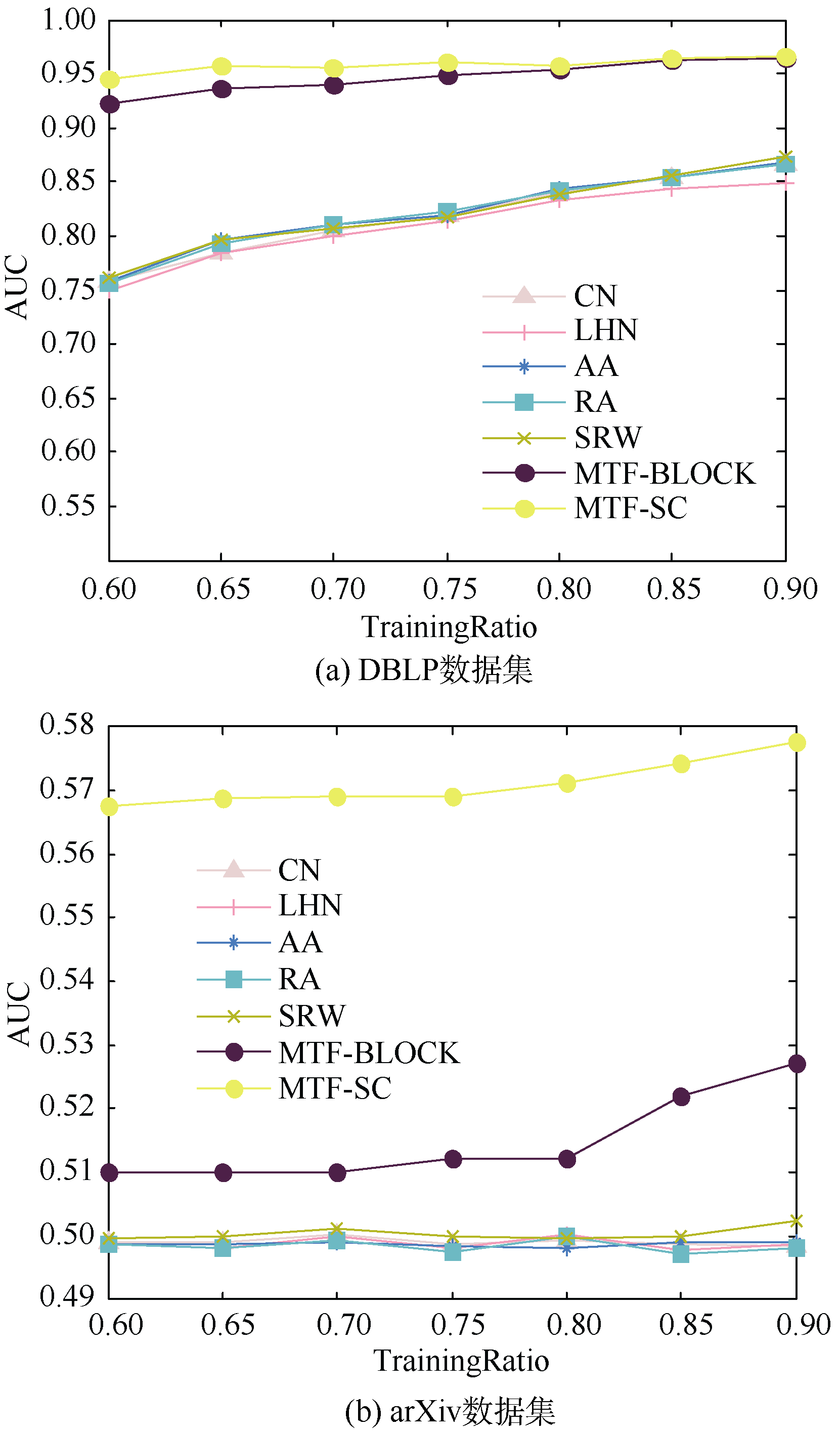 | 图4 训练集变化下的算法性能分析 |
(3) 案例细化分析
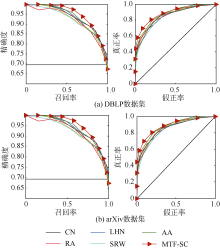
为了更好地从细节上验证算法的有效性, 引入ROC曲线和Precision-Recall曲线对结果进行分析(由于MTF-SC最优, 只选择该算法进行比较), 不同实验数据集的ROC曲线如图5所示, 可以明显看出, 两个结果都表现出相似的规律: 两种曲线无论从坐标始点到终点均在最外部三角曲线, 说明MTF-SC每一个子集均优于其他算法。
 | 图5 各算法在两数据集中的ROC曲线 |
(4) 局部因子和全局因子的贡献分析
两个数据集在λ 变化时的差异效果如表3所示。可以对比表2, 无论λ 变化如何, 其效果一直优于其他算法; 从黑体部分也可以看出, λ =0.6时效果较优, 这是由于其加强了社区全局因子的影响。
| 表3 以λ 作为参数的MTF算法的效果评价 (以AUC作为标准) |
MTF方法与以往的研究工作相比, 主要贡献包括如下两个方面:
(1) 提出新颖的基于科研社区结构属性的全局因子算法;
(2) 集成局部因子和全局因子, 并研究两者对于科研合作关系预测的贡献。
实验结果显示, MTF可以更大程度地挖掘科研合作网络的属性结构信息, 有效地避免了局部因子的局限性问题。未来仍需要对MTF方法作进一步优化:要建立一个更加归一化的模型对所有因子进行度量; 将考虑关系的权重或者异构特征, 将算法扩展到有权重的有向网络或者异构网络中。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|