
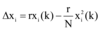
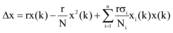
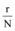
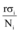
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
大数据背景下微博舆情信息交互模型研究
[兰月新 , 董希琳, 苏国强, 瞿志凯]
, 董希琳, 苏国强, 瞿志凯]
, 董希琳, 苏国强, 瞿志凯]
|
|


作者贡献声明:
董希琳, 兰月新: 提出研究思路, 设计研究方案;
兰月新: 数学建模及分析, 撰写论文及最终版本修订;
苏国强: 获取实验数据及案例分析;
瞿志凯: 资料收集、数据统计分析。
【目的】通过构建数学模型, 研究大数据背景下微博与其他网络媒体的信息交互问题。【方法】分析大数据背景下的微博舆情信息交互特征, 定义信息交互系数, 建立微博信息交互的微分方程模型。【结果】应用Matlab数值仿真以及6个网络舆情实例分析模型特征, 并验证模型, 得出构建良性信息交互机制是大数据背景下政府应对网络舆情的关键。【局限】仅从常规情形构建微博信息交互模型, 尚未考虑网络谣言等负面舆情全面爆发时的信息交互问题。【结论】研究成果有利于政府面对复杂微博舆情时做到“心中有数”, 也为进一步研究大数据背景下舆情信息交互问题提供参考。
[Objective] By building a mathematical model, this paper studies the information interaction between micro-blog and other network media under the background of big data.[Methods] Analyze the information interactive features of micro-blog public opinion, define the information interaction coefficient, and establish the differential equation model of micro-blog information interaction.[Results] Using Matlab numerical simulation and six cases of network public opinion to analyze the feature of the model and validate the model, it is concluded that to build information interaction mechanism is the key for the government to response network public opinion under the background of big data.[Limitations] The research only builds the regular model of micro-blog information interaction, not considering the situation when the negative public opinions like Internet rumors spreads rapidly and widely.[Conclusions] The results can help the government take measures when facing complex micro-blog public opinion, and also provide some references for the further research on information interaction problem of public opinion.
当前, 互联网进入大数据时代。据CNNIC发布的《第34次中国互联网络发展状况统计报告》[1], 截至2014年6月, 我国网民规模达6.32亿, 互联网普及率为46.9%, 其中我国手机网民规模达5.27亿。随着3G/4G技术、智能手机和无线网络的发展普及, 用户行为的移动化使微博成为中国网民使用的主流应用, 庞大的用户规模进一步巩固了其网络舆情传播中心的地位。据统计, 中国网民每天发布和转发微博信息达2.5亿条[2], 海量舆情数据使微博成为舆情的放大器, 大数据背景下微博舆情信息传播问题成为网络舆情研究热点。
目前, 国内外已有很多关于微博舆情信息传播的研究, 主要包括4个方面:
(1) 基于复杂网络理论研究微博信息传播规律, 如Wu等[3]根据微博中用户发表、浏览、回复和转发博文的基本行为, 将微博的信息交流分成信息发布、接收、加工、传播4个阶段, 提出竞争窗口模型描述微博信息的动态传播; 郑蕾等[4]结合微博信息传播规则和微博网络的拓扑结构, 通过构建微博网络信息传播模型, 在新浪微博拓扑子网中模拟信息流向; Xiong等[5]将Twitter用户按照对信息的接受程度划分为4种类型, 并提出SCIR模型探讨模型仿真过程中随着传播速率改变的整个模型网络的动态变化; 田占伟等[6]利用复杂网络理论方法, 构建微博信息传播网络进行基于度、路径统计指标的分析, 得出网络具有集群性、小世界、高度中心化等特征;
(2) 基于统计分析方法研究微博传播规律, 如田盼等[7]使用自组织特征映射神经网络对样本进行聚类分析, 通过数据分组处理方法拟合各类曲线发展趋势; 张赛等[8]以新浪微博为代表对社交网络信息传播进行较大规模的测量、统计和分析, 提出一种三角和算法用于探测用户粉丝数阈值;
(3) 通过建立微分方程模型研究微博信息传播规律, 如兰月新[9]在研究突发事件微博舆情影响趋势的基础上, 建立微分方程模型研究微博舆情扩散规律并基于新浪微博数据进行实证分析; Wang等[10]提出没有关注转发者的微博用户也会有可能转发微博信息及转发者会多次地转发相同的信息, 并以SIS模型研究这两种转发行为来描述信息参与者的动态变化;
(4) 定性研究微博信息传播规律并辅之以案例分析, 如付宏等[11]以“ 三亚宰客门” 事件为案例, 剖析微博传播对该事件形成的作用机理、描绘微博传播作用下该舆情事件的演进模式及微博传播影响力分析; 赵蓉英等[12]从流行三要素理论出发, 以新浪微博为例, 对影响微博信息传播的要素进行实证分析; 张玥等[13]结合信息采纳模型和媒介丰富度理论, 从信源特征和信息形式视角出发研究微博舆情传播的影响路径、影响因子并进行实例研究。
然而, 大数据背景下, 网络媒体之间都存在信息交互现象, 例如大部分网络新闻可以被网民共享到微博、论坛、社交网站等, 这就导致微博舆情信息除了自身原创和转发信息外, 还存在大量的交互信息。以上大多是研究微博内部信息传播规律, 而忽视了微博与外部空间(新闻网站、论坛、社交网站等网络媒体)的信息交互问题。本文构建数学模型研究微博舆情信息交互问题, 以期为后续微博研究提供参考。
什么是大数据? 大数据的主要特性是什么? 这些问题至今还没有准确、统一的定义。通常认为, 大数据具有“ 4V” 特性, 即规模性(Volume)、多样性(Variety)、高速性(Velocity)和价值性(Value)[14], 而在微博舆情研究领域充分体现了这些特性:
(1) 规模性: 据统计, 中国网民每天发布和转发微博信息达2.5亿条[2], 如果加上评论及其他微博功能产生的信息, 堪称海量数据;
(2) 多样性: 微博舆情信息多样, 包括内部原创、转发信息, 外部共享信息, 以及网民对这些信息的评论, 尤其是外部共享信息来源多样, 包括新闻网站、论坛、社交网站等;
(3) 高速性: 随着移动宽带互联网的普及, 突发事件信息近乎于“ 同步直播” 在微博上, 导致政府应对突发事件舆情由原来的黄金24小时变为黄金4小时, 甚至1小时[15];
(4) 价值性: 微博舆情信息中含有社情民意, 甚至蕴藏极具价值的情报(例如天价烟、微笑门等舆情事件), 微博舆情研究无论是学术层面还是政府需求层面都成为研究重点。
信息交互, 即发出和接收信息的过程。随着互联网技术的升级, 微博、新闻网站、论坛、社交网站等媒体之间大多存在信息交互, 如某条新浪新闻可以通过共享功能将信息共享至新浪微博、人人网、百度贴吧等。大数据背景下, 微博舆情信息交互特征如下:
(1) 信息交互“ 多对一” 模式
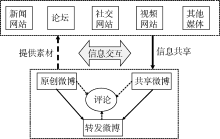
突发事件发生后, 国内绝大部分新闻网站、论坛、社交网站、视频网站及其他媒体发布的信息均存在共享功能将信息快速共享至微博, 或者通过复制信息文字将其共享至微博。与此同时, 网民通过微博发布信息后, 网络编辑可以以此为素材发布网络新闻、论坛主帖等, 如图1所示:
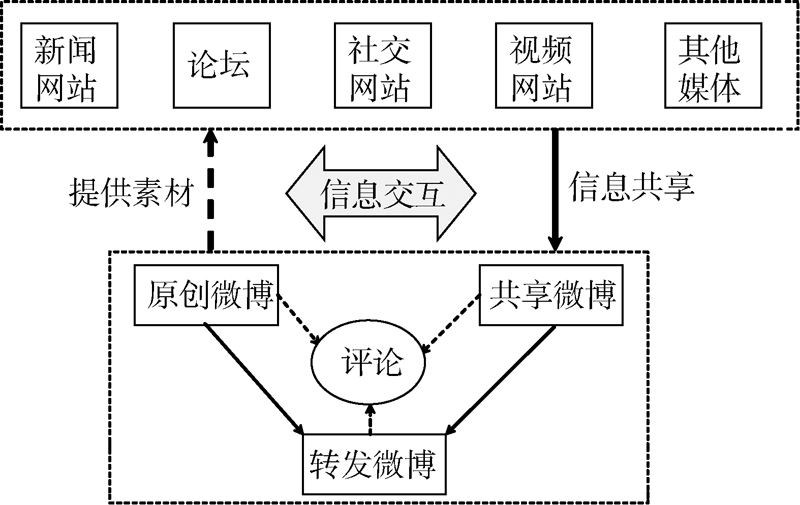 | 图1 信息交互“ 多对一” 交互模式 |
(2) 信息交互同步性
随着移动宽带互联网的普及, 突发事件网络舆情主要通过手机网络进行传播, 这使得微博舆情信息与新闻网站、论坛、社交网站、视频网站及其他媒体的信息交互几乎是同步进行, 尤其是手机网络新闻的共享功能, 可以及时将网络新闻信息共享为微博信息。
以浙江余姚市台风灾害网络舆情[16]为例(图2数据来源为人民网舆情监测室数据库), 容易看出网络新闻和微博数据曲线变化趋势相近。设微博信息量和网络新闻信息量对应的连续函数分别为x(t)和x1(t), 应用Matlab分别将x(t)和x1(t)、x1(t-1)、x1(t+1)进行回归分析得到:
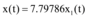
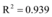
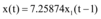
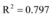
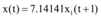
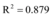
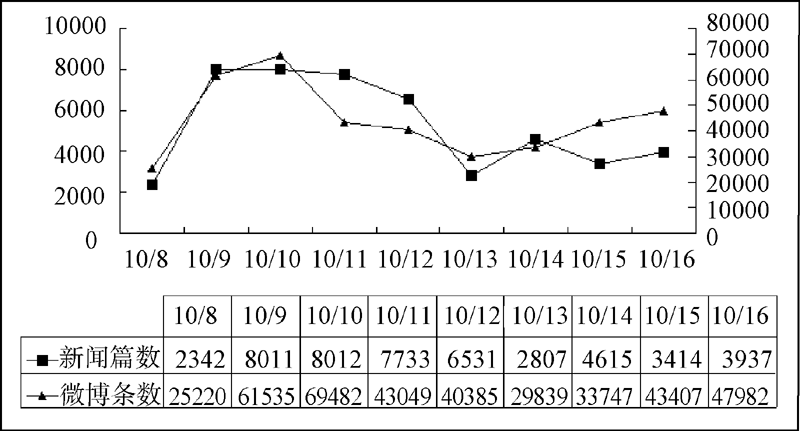 | 图2 2013年浙江余姚市台风灾害网络舆情数据 |
不难发现x(t)和x1(t)满足拟合程度更高, 两者之间延迟或提前信息交互的数量较少, 所以, 微博和新闻网站的信息交互可以假设为同时进行的。
综合以上两点, 大数据背景下微博舆情信息交互包括两个方面: 信息共享和提供素材, 前者可以直接转化为微博信息量(作用相当于原创微博), 后者则扩充了新闻网站、论坛等媒体的信息空间。本文将以此作为假设条件, 构建大数据背景下微博舆情信息交互的数学模型。
突发事件发生后, 假设微博舆情信息量是关于时间的连续函数, 记x(t), 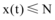
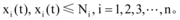
假设包括微博舆情信息在内的n+1个媒体舆情信息量均满足:
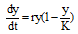
其中, y为信息量, K为网络信息上限, x> 0为最大增长率(定值, 由突发事件性质决定)。
网民通过网络媒体的共享功能或直接复制文字的方式, 将信息共享至微博, 引发其他网民转发此类微博, 这个过程相当于为微博注入了新的活力, 通过共享网络媒体信息直接促使微博信息量大幅提升。假设第i个媒体共享至微博的信息量比例为 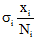
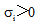
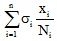
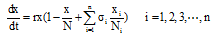
爆料和提供线索等形式的微博可以为网络媒体提供素材, 促使包含该素材的新的网络新闻、帖子等产生, 这个过程提升了网络媒体的“ 创作空间” , 必然提升网络媒体的信息量上限。不妨设爆料等微博使第i个媒体信息量上限由Ni提升为kiNi, 其中 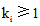
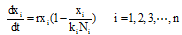
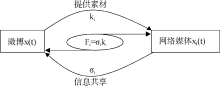
大数据背景下微博舆情信息交互是双向的过程, 如图3所示, 由此定义交互系数如下:
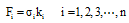
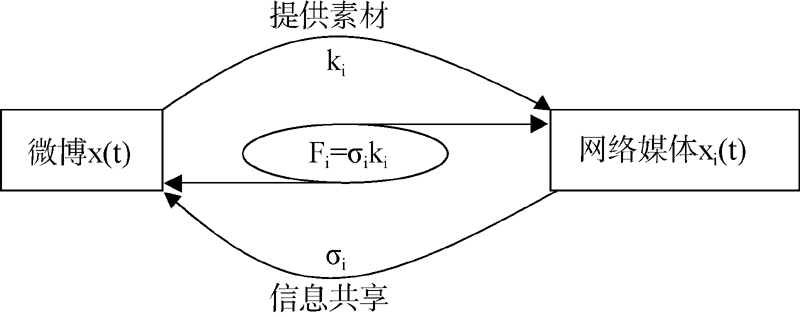 | 图3 微博信息交互过程量化 |
交互系数描述微博和第i个网络媒体的信息交互程度, Fi值越大, 信息交互程度越高。
综上所述, 得到大数据背景下微博舆情信息交互模型如下:
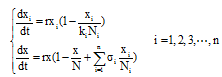
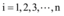
其中, x(t)初值为x(0), xi(t)初值为xi(0)。容易得出, 当 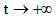
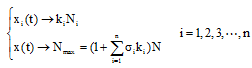
模型包括n+1个微分方程, 通过求解方程可以得到模型的解如下。
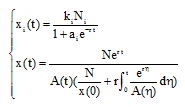
其中, 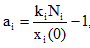
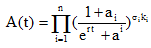
在数值仿真时, 本文仅考虑新闻网站、论坛、社交网站与微博的信息交互问题, 其对应函数分别为x1(t), x2(t), x3(t)。一般情况下, 微博发文信息量最大, 其次是社交网站、论坛和新闻网站, 而对某个突发事件来说r是固定的, 即信息增长率只与事件性质相关。所以本文针对某个突发事件设定如表1所示的参数, 用以研究微博与其他三个网络媒体的信息交互程度。
| 表1 模型参数初始值 |
(1) 网络媒体对微博共享程度分析— — 直接影响
突发事件发生后, 网民通过微博爆料或发现线索, 新闻网站、论坛和社交网站等几乎同时接受微博信息, 但新闻网站的信息审查要比论坛、社交网站复杂。所以同等条件下, 微博爆料或提供的线索信息对论坛和社交网站的推动会更大。本文选取微博为新闻网站、论坛和社交网站提供素材后的推动系数分别为1.2、1.3和1.4, 则新闻网站、论坛、社交网站的上限分别为1 200、2 600、4 200。
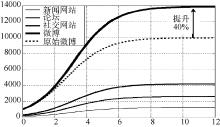
①取新闻网站、论坛和社交网站为微博共享信息的共享指数分别为 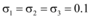
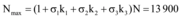
通过图4容易看出, 取相对较低的共享指数时, 三个网络媒体仍明显地推动微博舆情快速传播, 且从数值上明显看出微博信息上限提升接近40%。
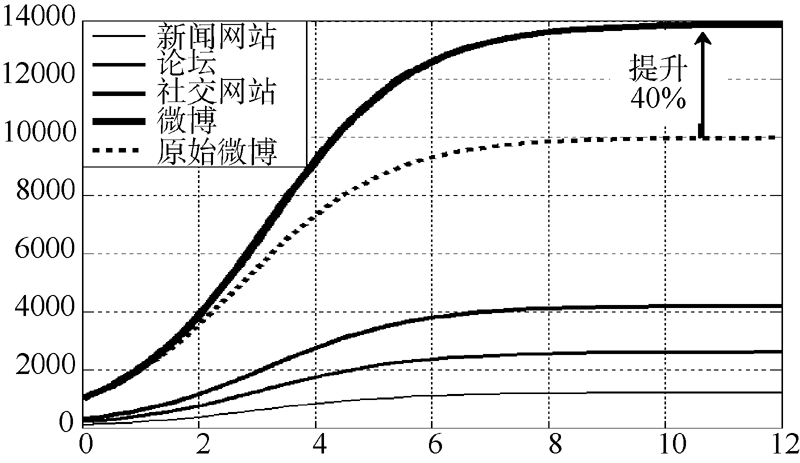 | 图4 低共享指数模型解的图像 |
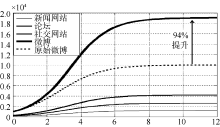
②适当提升共享系数后, 取新闻网站、论坛和社交网站为微博共享信息的共享指数分别为 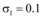
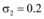
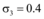
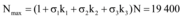
通过图5容易看出, 提升共享指数后, 三个网络媒体极大地推动微博舆情快速传播, 且微博信息上限提升接近94%。
 | 图5 提升共享指数后模型解的图像 |
通过以上两点可以看出, 在突发事件发生后, 随着网络媒体对微博共享程度的提升, 微博信息数量猛增, 而网络媒体自身数量也会适当提升, 但与微博差距较大。以2012年4个热点突发事件为例, 数据[17, 18]如表2所示, 微博舆情信息数量分别是网络新闻、论坛、社交网站的63倍、14倍和4倍, 其中新浪微博成为极其重要的网络舆情传播媒介。
| 表2 4个热点突发事件网络舆情数据(条) |
(2) 微博对网络媒体提供素材程度分析— — 间接影响
微博对网络媒体提供素材主要体现在网民爆料和提供线索上, 例如陕西杨达才事件, 正是因为“ @
JadeCong” 、孙多菲等网友在微博爆料[19], 其他网络媒体迅速跟进, 才产生“ 微笑门” 、“ 名表门” 网络舆情, 整个过程成为网络反腐的典型案例。本文定义提升系数ki研究微博对网络媒体提供素材(即不同提升系数条件下)后, 新闻网站、论坛和社交网站舆情信息变化规律。当ki=1时, 微博没有对网络媒体提供素材, 即网络媒体网络舆情传播的自然状态; 当ki> 1时, 微博为网络媒体提供素材, 且提供素材质量越高, ki值越大。
令 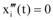
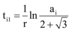
其中, 
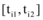
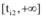
因本文参数取值(见表1)的初值均为上限值的10%, 所以, 对于相同提升系数ki, 新闻网站、论坛和社交网站对应的ai值相等。假设新闻网站、论坛和社交网站为微博共享信息的共享系数分别为 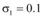
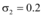
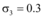
| 表3 网络媒体舆情信息传播重要指标 |
不难发现, 当微博对网络媒体提供素材时, 系数ki增大, 导致ti1增大, 则网络媒体的舆情潜伏期 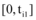
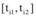
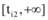
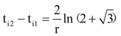
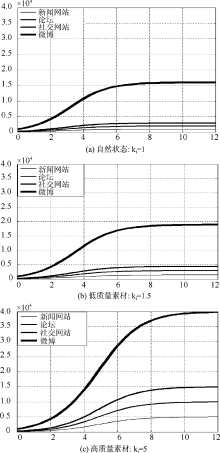
通过Matlab绘制自然状态(ki=1)、低质量素材(ki=15)和高质量素材(ki=5)三种情况下新闻网站、论坛和社交网站舆情信息量变化情况, 如图6所示:
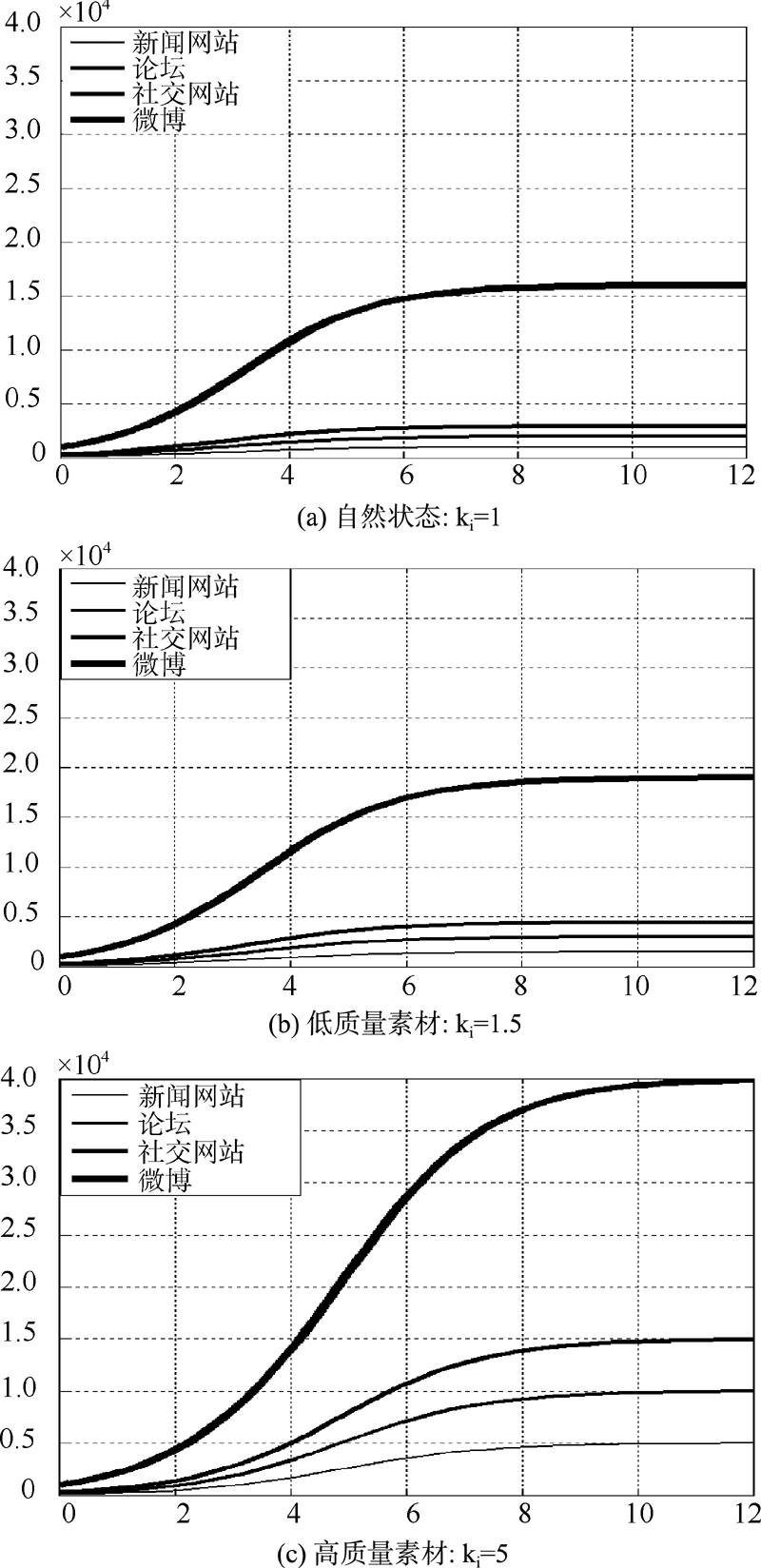 | 图6 三种状态网络媒体信息传播图像 |
不难发现, 微博提供高质量新闻素材后, 推动新闻网站、论坛和社交网站等媒体信息量迅速增大, 与此同时, 新闻网站、论坛和社交网站等媒体又通过信息共享和转发推动微博信息迅速传播。所以, 微博和新闻网站、论坛和社交网站等媒体之间的信息交互是相互促进, 相互提升的, 但微博信息量提升得更快、更大。
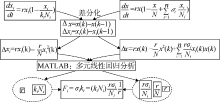
交互系数是描述微博和其他网络媒体信息交互程度的重要指标, 如何估计交互系数Fi成为模型分析的重点。突发事件发生后, 网络舆情监测软件可以及时获取网络媒体上突发事件舆情信息的统计数据, 如图2所示。通过这些数据可以估计部分模型的参数, 进而得出交互系数Fi。本文在微分方程差分化(向后差分)基础上进行多元线性回归来估计模型参数, 如图7所示:
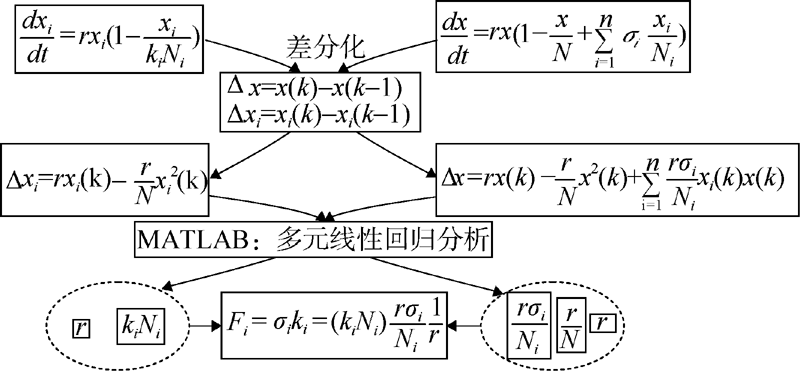 | 图7 交互系数估计方法 |
大数据背景下微博舆情信息交互模型如下:
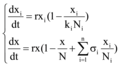
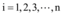
对应的差分方程如下。
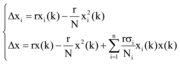
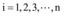
其中, 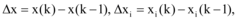
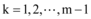
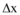
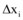
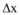
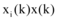
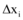
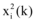
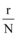
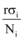
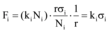
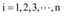
为使模型研究贴近微博舆情信息交互实际情况, 本文选取真实数据验证模型, 仅研究新闻网站和微博之间的信息交互问题, 所以信息交互模型简化为:
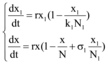
为减少网络衍生舆情对信息交互的影响, 本文选取事件发生后一周之内(7天)的舆情统计数据, 且只有一次高点舆情(舆情高潮)进行研究, 6个实例网络舆情数据来源于人民网舆情监测室的案例库[21], 如表4所示:
| 表4 网络新闻和微博舆情数据 |
按照图7计算交互系数的思路, 通过Matlab编程计算参数如表5所示。容易看出可决系数较高, 回归分析拟合程度较好。两次回归分析所得的r基本一致, 符合对于同一事件信息增长率r一致的模型假设。通过表5参数得出6个事件对应的微博舆情信息交互程度, 其中广西贺江水污染事件信息交互程度最高。
| 表5 模型参数估计表 |
相对于其他几个事件, 广西官方积极发布贺江水污染事件信息, 且信息公开及时、持续、透明, 为微博和网络媒体的信息交互提供了便利, 主要表现在以下两个方面:
(1) 政府部门公布的消息成为媒体的信源, 网络媒体以此为素材发布网络新闻, 与此同时, 网民将这些信息及时共享至微博, 信息共享程度较高, 共享系数 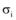
(2) 政务微博和官员微博积极发布事件调查进展情况、新闻发布会、市长公开道歉书、相关责任人予以停职等信息, 而这些微博信息又被网络媒体广泛采用, 进而导致促进系数ki较大。例如, 《今日肇庆》对外宣传网及肇庆市政务微博连续发布贺江水污染事件的三次通稿被央视新闻频道、新华、新浪网等超过100家媒体、门户网站发布了主题报道、网帖共计900多条, 微博转发6 520条[23]; @美丽肇庆(中共肇庆市委宣传部官方微博)和@陈永博(广东省肇庆市公安局新闻发言人办公室主任)在微博上积极传播污染处理的相关信息, 告知网友贺江污染物主体已在广西被拦住。
通过建模和实例分析可以得出如下结论: 如果微博与其他网络媒体之间的信息交互以政府信息为主, 且交互程度较高, 则网络舆情必将良性发展, 政府应对网络舆情效果较好, 例如广西贺江水污染事件等; 如果微博与其他网络媒体之间的信息交互以网民信息为主, 甚至小道消息和网络谣言等成为信息交互内容的话, 则政府应对网络舆情较为被动, 应对效果极差, 例如延安城管暴力执法事件等。所以, 构建良性信息交互机制是大数据背景下政府应对网络舆情的关键。
随着移动宽带互联网的普及, 微博舆情研究充分展现大数据特征, 研究微博舆情信息与其他网络媒体之间信息交互问题, 逐渐成为政府应对网络舆情的关键。本文在研究大数据背景下微博舆情信息交互特征的基础上, 定义共享系数、促进系数和信息交互系数等关键指标, 构建微分方程模型研究微博舆情信息与其他网络媒体的信息交互问题, 通过Matlab进行数值仿真研究模型特性, 以网络舆情实例验证模型并重点分析广西贺江水污染事件的信息交互问题, 得出构建良性信息交互机制是大数据背景下政府应对网络舆情关键的一般性结论, 以期为后续微博研究提供参考。然而, 大数据背景下微博舆情信息交互问题正处于探索阶段, 本文仅研究微博舆情信息交互的一般性模型, 对于含有衍生舆情甚至网络谣言的多次高点舆情尚有待进一步研究。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|