{kind=link}
{kind=link}
基于语义分析和相似强度的微博热点发现方法
[吴妮 , 赵捧未, 秦春秀]
, 赵捧未, 秦春秀]
, 赵捧未, 秦春秀]
|
|


作者贡献声明:
吴妮, 赵捧未, 秦春秀: 提出研究思路, 设计研究方案, 论文最终版本修订;
吴妮: 进行实验, 采集、清洗和分析数据, 起草论文。
【目的】通过改进热点发现方法, 解决传统方法存在的语义理解不足和聚类算法局限性的问题。【方法】从语义分析角度表示文本, 使用信息增益和潜在语义分析方法构建词-文档矩阵; 提出二次聚类算法方案, 实现热点发现与更新, 并使用相似强度的大小选取最优热点。【结果】该热点发现方法的查全率为91.3%, 查准率为92.9%, 较前人方法的聚类效果有所提高; 该热点发现方法也可以更新数据, 降低实验复杂度。【局限】实验数据的时间跨度较小, 使得更新热点方法的效果不太显著。【结论】本文提出的热点发现方法具有良好的准确性。
[Objective] Improve the method of hotspot detection to solve the lack of semantic understanding and the limitation of clustering algorithm in the traditional method of microblog hotspot.[Methods] This paper uses the Information Gain and the Latent Semantic Analysis as the way to construct a word-document matrix, then, the two-step clustering algorithm is put up which uses an improved K-means algorithm in hotspot detection as well as incremental clustering algorithm in hotspot refreshing. Meanwhile, similarity strength is adopted to solve the low accuracy of traditional method in which the number of hot topics is firstly determined and then the topic is detected.[Results] Compared with previous methods, the recall ratio of presented method is 91.3% and the precision ratio is 92.9%, clustering effect increased. It also can update data to reduce the complexity of the experiment.[Limitations] The experimental data has a small time span making the effect of update hotspot is not outstanding.[Conclusions] Experimental results show that the proposed method has good accuracy.
在Web2.0时代, 许多虚拟社区和社交媒体以用户为核心组织内容, 用户成为互联网信息的主要贡献者, 使得用户生成内容(User Generated Content, UGC)数量剧增、形式多样、互动性强, 微博是UGC的重要构成。微博通常是不超过140字的短文本, 具有生成快、内容分散、简短、口语化等特点, 可达到传播信息、人际交往等目的[1]。国外最受欢迎的微博是Twitter, 国内是新浪微博和腾讯微博。近年来, 微博发展迅猛, 已成为热点事件发布和推动的新阵地。如何快速有效地从微博文本中挖掘热点话题并追踪话题演变、预测话题倾向, 从而为相关监督部门提供网络舆情动态, 为商业决策提供有价值的信息, 是当前研究面临的一个热点。
目前国内外关于微博热点发现方法的研究随着微博的日益普及而增加。微博热点发现方法通常包含文档表示和热点提取两个步骤:
(1) 文档表示方面, 通过选取特征词构建词-文档矩阵。通常用词频[2]或TFIDF[3]选择特征词, 构建VSM模型、LDA模型、LSA模型或者结合VSM模型和LDA模型表示文本。由于微博短文本的特点, 这两种选择特征词的方式容易丢失语义信息, 构建的VSM模型[3, 4]的维度大, 不利于热点提取的实现; LDA模型参数的设置决定了热点个数, 不能对比选择最优热点结果[2, 3, 4, 5]; LSA模型将高维的文档矩阵投射到低维的潜在语义空间, 可以有效处理大规模的数据[6, 7, 8], 并且LSA模型构建的词-文档矩阵能有效地反映词语和文档之间的语义关系, 但奇异值大小的选取决定了语义信息的多少, 这里奇异值选择没有具体的参数设置。例如, 黄波[9]将VSM模型和LDA模型结合表示文本发现热点, 该方法合并热点的结果取决于相似度阈值的设定, 发现的热点内容相关性随数据的增大而降低, 且处理速度慢, 在大数据时代适应性稍弱。
(2) 热点提取方面, 通过使用一定的聚类技术提取微博内容中的热点话题。
①对具体事件的微博使用TDT (Topic Detection and Tracking)将分散杂乱的信息组织起来, 从而实现热点话题的提取、分类和推荐[10, 11, 12, 13, 14, 15], 该方法的数据多来源于TREC会议且针对具体事件, 不适用于海量微博内容的热点发现。
②使用K-means算法[16, 17, 18, 19], HD-K-means算法[3]、Single-Pass算法[20, 21]、改进的CURE[7]算法提取热点。该类方法计算过程简单, 评价指标单一, 聚类结果容易局部最优, 或者话题相似度阈值的设定直接影响发现结果。
③结合层次和划分聚类方法, 通过层次聚类确定聚类个数和初始聚类中心, 再使用划分聚类实现话题划分而发现热点。例如结合CURE和K-means算法[6]、凝聚层次聚类和K-means算法[7], 该类方法发现的热点结果对层次聚类的依赖性强, 结果的不确定性大。
在以上三类方法中还有一个共病: 若有新数据加入时需将全部数据重新聚类, 在数据量大的情况下, 将会影响热点发现的效率和精度。针对这些问题, 本文在文本表示方面通过信息增益筛选特征词, 保留低频词汇的语义信息, 潜在语义分析根据因子分析理论选取奇异值, 构建词-文档矩阵; 在提取热点过程中参考网站民意调查和人工分类文本结果, 确定初始聚类质心的范围, 使用二次聚类算法, 即改进的K-means算法发现初始热点, 增量聚类算法快速聚类新数据, 更新初始热点, 引入相似强度选择初始热点集合中的最优热点发现结果, 可解决确定初始聚类个数对热点发现结果准确性的影响, 且处理速度快, 在数据量大的情况下较有效。
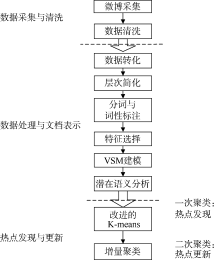
基于LSA和二次聚类算法的微博热点发现方法主要通过数据采集与清洗、数据处理与文档表示、热点发现与更新这三个步骤来发现和更新微博热点, 该热点发现过程如图1所示:
 | 图1 基于LSA和二次聚类算法的微博热点发现过程 |
使用数据采集软件进行微博数据采集, 并对采集到的微博数据进行清洗。
(1) 微博采集: 采集微博的标题、内容、转发次数、评论内容、作者和发表时间, 并以文本文档的格式保存到服务器。
(2) 数据清洗: 采集结果中相同内容仅保留一个, 清除内容中未处理的HTML标签, 去除空值、广告等噪声。
(1) 数据转化: 对清洗过的数据统一编码, 转化为GB2312格式。
(2) 层次简化: 将原始微博及其评论和转发归结为一个文本文档, 以便后续的数据分析。
(3) 中文分词与词性标注: 词语是组成文档的基本元素, 分词处理是中文文本分析的基础。通过对微博文本分词, 去停用词, 观察分析数据发现体现文本主题的词语主要是名词, 因此本文选择名词作为后续分析的数据。
(4) 特征选取: 信息增益[22](见公式(1))通过特征对分类系统的贡献大小衡量词的重要程度, 既能降低空间维度, 又能提取低频词的语义信息, 是一种有效的特征选择方法, 因此本文通过名词的信息增益大小筛选特征词。
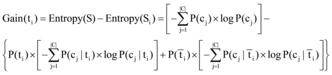
(1)
其中, P(cj)表示语料中出现属于cj的文本的概率, P(ti)表示语料中出现含有ti的文本的概率, 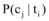
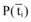
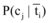
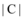
本文的微博热点话题的发现流程为: 通过计算特征词的TFIDF构建VSM, 使用LSA降低VSM的维度, 使用基于相似强度的二次聚类算法发现和更新热点话题。
(1) 选取特征权重。目前文本表示主要采用向量空间模型, 其主要思想是将文本用特征词和权重构成的向量表示。将每个文本用数据处理中选取的特征词表示, 计算各个文本的TFIDF值(见公式(2))获得特征词的权重, 将单个文本用向量表示, 从而构建向量空间模型[23]。
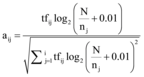 |
其中, tfij表示第j个文档中第i个词出现的频度, N为文本集的总文本数, nj为含有词条j的文本个数。矩阵 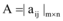
(2) 潜在语义分析。从语义的角度处理词-文档的共现矩阵, 通过对大量文本集的统计分析自动提取词语的上下文使用含义, 其核心技术是奇异值分解(Singular Value Decomposition, SVD)[24]。
对于任意一个秩为r矩阵 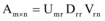
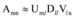 |
其中, Uml由Umr的前l列组成, 是矩阵A近似到l维空间的特征词向量, Dll由Drr的前l列组成, 是矩阵A近似到l维空间的文档向量。
(3) 热点发现与更新。本文使用二次聚类算法实现热点话题发现和更新, 即改进的K-means算法发现微博热点和增量聚类算法更新热点。
算法思想: 将经数据采集与清洗的微博数据集按时间段划分为part_1和part_2两部分, 经数据处理后在part_1中选取初始聚类值区间, 即确定热点发现结果个数的区间(k, k+x), 计算part_1中任意两个对象之间的距离, 选择相互距离最远的前k个点作为初始聚类中心, 使用K-means算法聚类; part_2数据使用增量聚类算法聚类, 返回聚类结果和质心, 完成首次二次聚类。循环二次聚类算法, 直至k=k+x 时算法结束。
设数据集 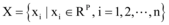
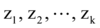
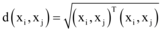
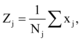
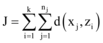
热点发现(步骤①-步骤⑧)与更新算法(步骤⑨-步骤⑪ ):
输入: 聚类个数k以及包含n个数据对象的数据集;
输出: 分别满足目标函数值最小的x+1个聚类结果。
令k取值范围为[k, k+x];
①计算任意两个数据对象间的距离 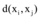
②令Z1, Z2为满足 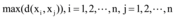
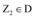
③令Z3为满足 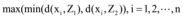
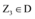
④令Z4为满足 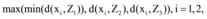
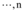
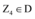
⑤令Zk为满足 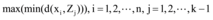
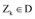
⑥从这k个聚类簇中心出发, 循环步骤⑦到步骤⑧直到目标函数J不再变化:
⑦根据每个聚类簇的均值, 计算每个对象与这些中心对象的距离, 并且根据最小距离重新对相应对象进行划分;
⑧重新计算每个簇的质心为 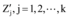
⑨令 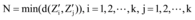
⑩分别计算每个新数据与 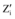
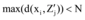
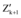
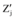
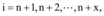
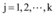
⑪ 新加入的数据集循环步骤⑩直到结束。
本实验旨在对构建的基于LSA和二次聚类算法的微博热点发现方法的性能进行评价。
在信息检索领域, 查全率和查准率是广泛使用的评价标准。查全率(Recall Ratio)指检索系统在一次作业时检索出相关文献的能力, 是检出相关文献量与系统数据库中相关文献总量的比值。查准率(Precision Ratio)指检索系统在一次作业时拒绝不相关文献的能力, 是检出的相关文献量与检出文献总量的比值。本文参考4个网站对两会民众关注热点调查结果, 通过10位实验助理对获取的微博数据集进行浏览分类, 综合10个分类结果作为人工划分微博热点集合, 使用查全率和查准率评价基于相似强度的二次聚类算法。
在此基础上笔者提出针对最终热点发现结果的查全率R和查准率P, 公式如下所示:
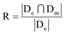 |
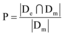 |
其中, De表示人工划分微博热点的集合, Dm表示使用本文的自动化方法获得的热点集合。
(1) 实验准备
实验使用PC内存为2GB, 服务器内存为128GB, 操作系统均为Win7。通过LocoySpider(火车头数据采集平台)注册账号, 以两会为关键词获得2014年3月3日0: 00-3月5日24: 00的5 875条微博, 经过数据采集与清洗最终得到5 010条微博。对文本进行分词处理(使用汉语词法分析系统ICTCLAS①(①http://ictclas.nlpir.org/.)), 选取名词作为处理对象, 获得42 015个名词, 取信息增益值较大的前30%的词汇即12 605个作为微博的特征词, 构建向量空间模型A为12 605× 5 010矩阵。其中信息增益值较大的名词词频如表1所示:
| 表1 特征向量词频 |
(2) 参数选择
①奇异值l的选择
LSA通过SVD将词语和文档映射到潜在语义空间, 奇异值l的选取很重要, 如果l值选取过大, 降维的效果不显著, 反而使计算量更大; 如果l值选取过小, 不能充分发挥LSA分辨词和文档的作用, 并且丢失部分语义信息。在具体实验中通过调整l值来平衡奇异值分解的效率和准确率, 在此通过因子分析理论确定潜在语义分析的奇异值l。根据因子分析理论, 给定θ , 使l满足贡献率不等式[25], 如公式(6)所示:
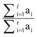 |
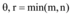
θ 为包含原始信息的阈值, 取值在0.4-1之间, 贡献率不等式是衡量l维子空间表示原始空间的程度, l一般取值在300-1 000之间。为了获得更多语义信息, 本文在奇异值分解时选取l=1 000构建词-文档矩阵。
②聚类k值的选择
查找新华网、人民网、新浪网和中国网调查的两会民众关注热点, 如表2所示, 热点数量新浪网最少为6个, 将以上4个网站提供的热点综合、去重, 最终得到20多个热点话题。将获取的微博数据集进行人工浏览分类, 综合10位实验助理的分类结果, 共获得23个类别, 如表3所示。通过以上分析, 笔者认为该数据集的热点话题个数应在6至23之间, 因此执行二次聚类算法时, 初始条件k=6, 终止条件k=23。
| 表2 网络两会民众关注热点调查表 |
| 表3 人工分类话题综合与二次聚类算法发现结果对比 |
③相似强度Q的选择
通过基于相似强度的二次聚类算法获得初始微博热点集合, 选取相似强度(Similarity Strength)最大的聚类结果为最终热点发现结果。相似强度是语义对等覆盖网的社区结构的评价指标[26], 用于衡量社区划分的优劣。在此基础上, 笔者引用相似强度的概念, 并改进计算公式使其适用于对热点发现的评价。单个热点话题的相似强度通过计算每个数据与所处类质心的相似度来描述, 全部热点话题的相似强度的计算公式如下所示。
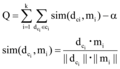 |
其中, 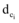
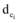
(3) 实验设计
实验一: 用以评价本文给出的微博热点发现方法的查全率和查准率。使用内存为2GB的PC将数据集分为part_1和part_2两部分, part_1包含从3月3日0: 00-3月5日12: 00的4 000条微博, part_2包含3月5日13: 00-24: 00的1 010条微博。part_1和part_2分别进行数据处理后, part_1使用本文的方法发现热点话题, part_2使用增量聚类算法更新part_1的聚类结果。分别计算k取值为6至23时的初始热点结果集, 根据相似强度获取最优热点发现结果。
实验二: 对比分析增量算法的效果。实验数据集分为对比项和实验项。对比项选取实验一的结果, 实验项的数据集为经过与对比项相同数据预处理的未分组的5 010条微博, 聚类算法仅使用改进的K-means算法, k值同样选取6至23, 通过计算相似强度Q值确定最优发现结果。根据实验结果, 对比分析两种方法的耗时、发现的热点个数, 说明增量聚类算法的效果。
(1) 实验一
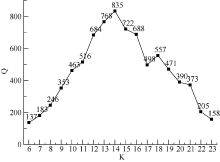
实验一热点发现结果如图2所示, 当k=14时, 相似强度Q=835为最大值, 说明此时获得的聚类结果中, 各个簇内相似度的总和是最大的, 本文认为此时是最优话题发现结果。选取k=14时各聚类结果簇中TFIDF值较大的前15个词作为该热点的特征描述词, 由于篇幅原因, 仅显示具有代表性的前5-8个词, 如表4所示:
 | 图2 相似强度K-Q值 |
| 表4 聚类实验发现的热点及部分特征词 |
由图2可知在微博数据集一定的情况下, k取不同数值时, 获得的微博热点的相似强度具有差异性, 且热点发现的准确程度呈抛物线趋势。
表4显示了热点的部分特征词, 每个热点话题的特征词具有较强的相关性, 而不同热点的特征词之间的关联就不大。这初步表明, 本文给出的方法能将相关的微博聚集在一起。
表3中人工分类热点话题De为23个, 自动化方法发现热点14个。对比分析发现, 使用本文自动化方法发现的热点比人工分类较为概括, 比如热点“ 户籍改革、高考公平” 对应人工分类中的“ 户籍改革、生源地” 和“ 教育、高考、就近入学” 两类, “ 官员作风、财产公开” 对应人工分类的“ 官员财产公开” 和“ 党风廉政” 两类, “ 医疗、二胎” 对应人工分类中的“ 药品安全” 、“ 医疗、保险、南京护士” 和“ 二胎” 三类。因此, 将人工分类与自动化方法发现的热点对应, 结果如表3所示, 那么使用本文的自动化方法获得的热点集合Dm应为21个, 则查全率R为91.3% (21/23)。
表4中自动化方法获得的第12个热点的特征词为“ 金融、互联网、经济、政府、工作” , 在人工分类时将“ 金融、互联网、经济” 和“ 政府工作报告” 分为第14、21类。查找自动化方法第12类聚类结果发现包含有政府工作报告的内容, 可见算法执行中将政府工作报告相关数据划分到了“ 金融、互联网、经济” 这一类, 可见自动化方法获得的第12个热点的效果不准确, 则本文自动化方法热点发现结果的查准率P为92.9% (13/14)。
马雯雯[7]对比分析K-means聚类和混合聚类(凝聚层次聚类和K-means聚类)的查准率, 三次实验的最大查准率分别为75.08%和81.56%。本文方法的查全率和查准率都在91%以上, 说明本文提出的热点发现方法效果不错。
(2) 实验二
实验二结果如表5所示:
| 表5 实验二结果对比 |
由于部分微博文档中出现的特征词多, 潜在语义分析降维之后的矩阵维度仍然很大, Eclipse软件实现中提示PC内存不够, 这说明改进的K-means聚类算法受限于数据量, 在大数据时代是一个挑战, 而本文的二次聚类算法可以解决数据维度高这个难点。
热点发现结果方面, 实验项数据集发现热点13个, 对比项数据集发现热点14个, 说明增量聚类算法可以用来更新热点, 当有新数据加入时, 避免了全部数据一起聚类, 相同实验环境下速度提高了20%, 降低了时间复杂度。如果在数据量大的情况下, 实验对比效果将会比较显著。
通常微博内容短小, 信息分散, 本文使用信息增益和潜在语义分析表示文本, 以降低词-文档矩阵的维度、消除噪声。为解决现有聚类算法未能评价选取多次聚类结果最优值的问题, 根据网站信息和人工热点分类确定聚类范围, 采用二次聚类算法发现与更新微博热点。改进的K-means算法降低了初始点选取对聚类结果波动性的影响, 增量聚类算法快速聚类新数据, 使用相似强度评价选取一定时间内的最优热点发现, 并证明具有较高的准确性。有待于进一步研究的工作包括: 目前仅使用微博文本数据发现热点话题, 如何使用语义分析挖掘用户在热点话题中的情感, 丰富热点话题的内容描述, 形成微博导航条推荐给用户, 为用户快速加入热点提供有力帮助; 进一步研究实验数据对二次聚类算法的影响程度。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|