{kind=link}
{kind=link}
社交网络话题信息传播影响簇发现谱系挖掘方法
[何建民1, 2  , 王哲
, 王哲1 ]
, 王哲|
|


作者贡献声明:
何建民: 提出研究思路, 设计研究方案, 论文最终版本修订;
王哲: 采集, 清洗和分析数据, 进行实验;
何建民, 王哲: 论文起草。
【目的】利用互联网传播媒介, 在社交网络中寻找对特定话题信息有影响的人群(影响簇), 以此作为传播中介, 为企业营销决策提供理论和方法支持。【方法】通过新浪微博API收集数据, 采用谱系挖掘方法挖掘对信息传播有影响的人群, 分析个体信息传播及其之间的交互关系来发现影响簇。【结果】获得对信息传播有高影响力的人群, 利用该人群推广企业的营销信息, 可显著提高产品引导购买率。【局限】仅考虑个体自身传播影响力的因素, 未考虑微博非常规用户行为。【结论】为企业实施网络精准营销决策支持提供理论基础和实用方法。
[Objective] The paper aims to find the user groups (influential clusters in social network) which have great influence on others in particular topics. The user groups can be employed as spread media to support the marketing decisions of enterprises.[Methods] With the data collected from Sina micro-blog, use the pedigree method to mine the influential clusters in social network, and analyze the information distribution and interaction among individuals to mine the influential clusters. [Resuls] The proposed method can find the user groups which have high influence in social network. Enterprises can utilize the user groups to distribute the marketing information and enhance the guiding rate of product sale.[Limitations] Only consider the factor which compose the influential ability of individuals, and do not take the unconventional behaviors of micro-blog users into account.[Conclusions] This paper provides the theoretical basis and practical method to support the social marketing decisions of enterprises.
影响簇是指在社交网络中有相同兴趣和偏好的人高度关注、频繁互动和积极转发某特定主题的话题并使其发挥影响力的人群。在社交网络中, 话题信息能否引起网民的关注和转发, 与网民对该话题信息的关注度、兴趣度和参与度等因素有密切关系[1, 2]。具有相同兴趣和偏好的网民, 为了吸引更多的人关注他们讨论的话题内容, 会采用聚焦眼球、频繁互动和积极推广等方法, 以增强话题信息的传播影响力。企业可借此开展营销推广活动, 通过设置营销话题, 借助高影响力的网民人群传播和放大营销信息的内容, 以实现低成本的口碑营销。
利用社交网络传播信息一般都有特定营销主题下的话题, 如何找到对推广该营销信息有贡献的高影响力人群(影响簇)是企业网络营销策划决策的关键问题。利用网络意见领袖的个人影响力推广营销信息一直是企业营销活动的选项, 涉及的研究侧重于探索意见领袖识别方法, 并未关注网民的社交互动关系对营销信息推广的影响作用及其利用价值。
在社交网络关系圈及其影响力研究上, 主要研究成果集中于社交网络社区发现[3, 4, 5, 6]、社区影响力分析[7, 8, 9]和意见领袖识别方法[10, 11, 12, 13]。社区网络发现方法主要包括: 矩阵谱分析方法[14], 由构建网络邻接矩阵分析社群谱系, 以发现有价值的社区; 层次聚类方法[15], 运用层次聚类方法, 由计算网络节点, 比较节点间的相似性, 发现目标社区; 边图求解方法[16], 通过计算网络的边和路径大小, 以发现有价值的社区; 极大团聚类方法[17], 由网络完全子图分析, 找出极大图, 以发现目标社区。社区影响力研究主要包括: 通过对微博网络的信息传播行为的分析, 提出一种WeiboRank用户传播影响力识别算法[7]; 运用灰色关联理论, 由社区网页总数、链接总数、PR值计算社区网络的影响因子和影响力[8]; 综合用户的发表内容及其之间的关系信息, 将话题传播发现、社区形成和用户影响力进行关联, 提出基于LDA的集成话题发现、社区发现和用户影响力分析模型ACT-LDA[9]。上述研究者虽提出许多网络社区发现方法, 但未考虑在社交网络中群体话题传播互动关系以及该群体对话题传播的作用。在意见领袖识别方法上, 主要包括: 指标评价法[18], 即根据意见领袖的特征, 构建指标测评体系以发现意见领袖; 社会网络结构挖掘法[19], 即根据网民社交关系, 构建网络拓扑结构以描述网民之间链接关系, 以此设计算法计算用户在网络中的重要度, 以确定意见领袖。在社交网络中, 意见领袖和影响簇的区别在于: 意见领袖是在社交网络中具有高影响力的个体, 而影响簇则是在特定话题下, 具有高影响力的个体集合, 且集合内成员个体之间信息交互频繁。意见领袖的话题影响力正受到频繁互动的群体影响力的挑战, 如何找到对话题传播具有高影响力的有重要贡献人群, 关键是研究社交网络信息传播影响簇发现谱系挖掘方法。
综上所述, 利用社交网络推广营销信息, 需要企业设定特定的营销话题, 找出对营销话题信息推广有贡献的高影响力人群(影响簇)作为话题传播的中介, 由他们级联传播话题信息可使营销推广达到事半功倍的效果。本文研究在社交网络中发现对话题信息传播有重要影响力人群的方法, 主要通过分析社交网络中有相同兴趣和爱好的个体及其之间频繁互动关系, 采用DBSCAN聚类方法[20], 构建频繁传播序列和影响簇谱系发现算法, 以此形成社交网络话题信息传播影响簇发现谱系挖掘方法, 为企业网络营销决策支持提供理论依据和实用方法。
在社交网络中, 话题信息传播关系可描述为信息传播树T, T=(N, S, L, r), 其中N为T的节点集合, 即网民个体集合; S为T的边的集合, 相连的边构成信息传播路径; L为T的话题主题集合, 表示传播的话题特定内容, 比如一篇具有特定主题的微博内容; r为T的根节点, 表示话题传播初始个体[21]。
定义1(个体影响力) : 假定任意一个网民个体 a(a∈ N)分布于某个信息传播树T, 记a的影响力为 inf a=|F(a)|, 表示在特定的话题传播树中, 所有与a有直接连接关系的节点数目, 即a是所有树节点中的分叉数累加和。
定义2(影响力平凡个体) : 假定 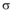
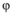
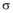
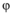
定义3(影响簇): 假定 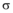
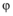
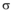
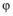
在社交网络平台上, 某个特定主题的话题信息被多人转发传播, 构成信息转发序列。研究社交网络话题信息传播中具有重要贡献的影响人群发现问题, 其实是要找频繁转发该话题的具有高影响力的人群, 即找出该话题下的影响力平凡个体, 将其归属到各自影响力的关系圈中; 在个体集合中找出能够使话题影响力投射到最大的关系圈, 从而确立其所在的影响簇。本文将此发现过程描述为谱系影响簇发现方法。为了找到对话题传播有重要影响的人群簇, 需要计算该话题传播树下的影响力平凡个体距离, 通过计算信息传播频繁序列个体之间交互次数和交互层级, 经转换得到影响力平凡个体的距离。而对不在频繁序列中的个体客户, 则通过信息传播序列的期望, 计算影响力平凡个体的距离。
在社交网络中传播特定的营销话题信息, 网民个体之间的互动和转发次数决定了网民个体之间的影响距离。个体之间直接传播信息的距离小于间接传播信息的距离。因此在计算距离时, 由个体转发信息的层级关系, 可得到个体之间信息传播的影响程度。由于传统的方法采用频繁项集找出无序的项, 因而并不能发现信息传播序列。在传播特定的话题时, 发现对话题传播有贡献价值的影响簇面临两个难题:
(1) 如何找到有序的频繁传播序列;
(2) 如何根据个体间的距离确定网民个体归属于哪个目标影响簇。
某一网民个体在社交网络平台上传播特定的主题信息, 可以被多个网民个体同时转发形成多条不同的频繁传播序列[20, 21, 22, 23]。不同的信息转发序列组成了信息传播序列集合, 由此构建序列数据库M。一个序列mi(mi∈ M), 其中序列m1=< a1a2…as> 是序列m2=< a’ 1a’ 2…a’ t> 的子序列, 记为m1m2, 如果存在整数1 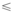
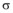
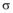
定义4(前缀): 对于序列m1=< a1a2…as> , m2= < a’ 1a’ 2…a’ t> (s 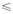
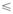
定义5(投影): 对于序列m1和m2, 如果m2是m1的子序列, 则m1关于m2的投影a’ 满足: m2是a’ 的前缀, a’ 是m1的满足上述条件的最大子序列。
定义6(后缀): 序列m1关于子序列m2=< a1a2…as-1a’ s> 的投影为m’ =< a1a2…at> (s 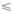
定义7(投影数据库): 假定序列mi为序列数据库M中的任意一个序列模式, 则mi的投影数据库为M中所有以mi为前缀的序列相对于mi的后缀。
定义8(投影数据库中的支持度): 序列m1为序列数据库M中的一子序列, 序列m2以m1为前缀, 则m2在m1的投影数据库中的支持度为满足 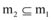
由此得到, 频繁传播序列求解算法如下:
(1) 扫描序列数据库M, 生成所有长度为1的序列模式, 即序列元素个数为1;
(2) 根据长度为1的序列模式, 生成相应的投影数据库;
(3) 在相应投影数据库中重复上述步骤, 直到不能产生长度为1的序列模式为止;
(4) 分别对不同的投影数据库重复上述过程, 直到不产生新的长度为1的序列模式为止。
该算法在对数据库投影时, 无需考虑全部的可能频繁子序列, 只是根据频繁前缀构造投影数据库。因为频繁子序列是可以通过增长频繁前缀被发现的, 从而使得投影数据库逐步缩减, 该算法代价主要在构造投影数据库上, 其效率远高于需经多次扫描数据库的Apriori算法。可见, 在序列模式数量庞大时, 可以采用并行序列模式探索发现, 即将数量庞大的序列模式分成若干个数量较小的序列模式, 并重复上述步骤以发现频繁模式, 在结果汇总中再次采用上述方法找到频繁传播序列。
新浪微博的转发序列数据库M部分如表1所示:
| 表1 微博转发序列数据库 |
设置影响力个体阈值 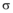
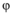
(1) 扫描M一次, 找出所有长度为1的序列模式。它们为< a1> : (6, 7); < a2> : (4, 4); < a3> : (9, 8); < a4> : (7, 8); < a5> : (7, 7); < a6> : (5, 5); < a7> : (9, 9); < a8> : (6, 4); < a9> : (6, 5); < a10> : (6, 6); < a11> : (7, 7); < a12> : (4, 2); < a13> : (5, 5); < a14> : (1, 1); < a15> : (3, 4); < a16> : (2, 2); < a17> : (4, 5); < a18> : (3, 4); < a19> (6, 5) ; < a20> : (6, 6)。其中, 符号“ < 模式> : (计数1, 计数2)” 中计数1表示用户在信息传播树中出现的次数。由于a14, a16出现次数低于3, 所以删除a14, a16。计数2表示用户在某个话题下的影响力, 由于a12小于4, 所以再删除项a12。结果如表2所示:
| 表2 去除低于阈值的微博转发序列 |
(2) 找出前缀分别为a1, a2, a3, a4, a5, a6, a7, a8, a9, a10, a11, a12, a13, a14, a15, a16, a17, a18, a19, a20的后缀。a1的后缀如表3所示:
| 表3 个体a1的后缀序列 |
(3) a1的后缀中还有其他的项, 所以在各个后缀中递归地将后缀变为前缀。那么前缀为< a1a2> : 0的序列出现0次, 低于阈值3, 停止迭代; < a1a3> : 2的序列出现了2次, 低于阈值3, 停止迭代; < a1a4> : 3的后缀是a5a6a13a19a9a10a4a18a8a20a11, a5a20a6a1a3a13a15a7a17a8和a13a10a8; 剩下的能出现3次的只有< a1a4a13a8> : 3, 停止迭代; < a1a5> : 3的后缀是a6a13a19a9a10a4a18a8a20a11, a20a6a1a3a13a15a7a17a8和a6, 明显能出现3次的序列只有< a1a5a6> : 3, 停止迭代; < a1a7> : 3的后缀是a17a8, a17a6a9a5a6和a17a9a4a13a10a8, 能出现3次的序列只有< a1a7a17> : 3, 停止迭代。在这里需要注意, 频繁序列的子集一定是频繁的, 所以当< a1a4a13a8> 是频繁的时候, < a1a13> 也一定是频繁的, 所以不需要再找< a1a13> 的后缀, 并且频繁序列以发现的最大序列为标准, 所有子集序列都不需要标出。所以以a1为前缀的频繁序列模式为< a1a4a13a8> 、< a1a5a6> 、< a1a7a17> 、< a1a9> 。类似的可以找出其他各项有前缀的频繁序列模式, 如表4所示:
| 表4 个体的频繁序列模式集合 |
在找出频繁转发序列后, 为了将找出的个体归属到不同的影响簇中, 还要计算个体之间的距离。个体之间关系越密切, 则他们之间的距离越小。计算规则如下:
(1) 直接转发的距离应小于间接转发的距离, 间接转发的层级越多, 则个体之间的距离越大;
(2) 转发的次数越多, 表明其关系越密切, 则距离越小;
(3) 在寻找个体频繁转发序列时, 可忽略其他非频繁的序列关系, 以其频繁转发序列关系计算距离。
规定直接转发的个体间距离为1; 经n次转发的个体距离为n+1; 个体转发了n次, 则在原有的距离上乘以1/n。据此计算得个体间距离, 如下所示:
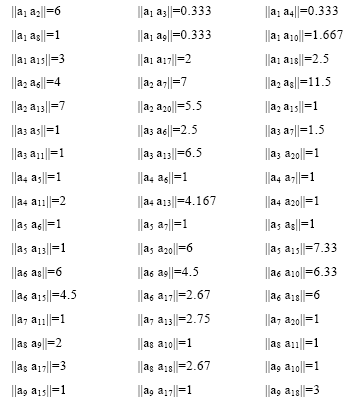
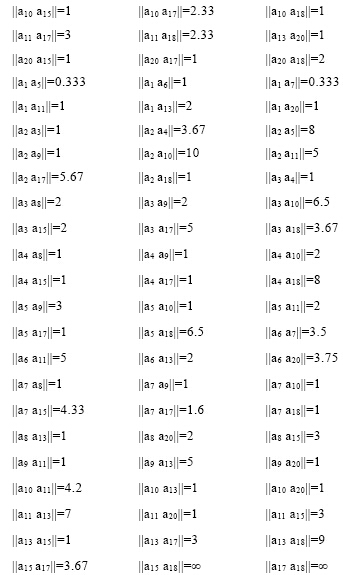
在求得个体之间的距离以后, 再采用DBSCAN聚类算法[24] , 快速识别任意形状的簇。该聚类算法是一种基于高密度联通区域的密度聚类方法, 其伪代码算法描述如下:
输入: D, 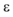
D: 一个包含n个对象的数据集;
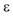
MinPts: 领域密度阈值。
输出: 簇的集合
算法过程:
标记所有对象为unvisited;
Do
随机选择一个unvisited对象p;
标记p为visited;
If p的 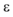
创建一个新簇C, 并把p添加到C中;
令N为p的 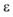
For N中的每个点p°
If p° 是unvisted
将p° 标记为visited;
If p° 的 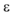
If p° 还不是任意簇的成员, 把p° 添加到C中;
End For
输出C; //C为影响簇
Else将p标记为噪声;
Until直到扫描到没有unvisited标记对象为止。
在上述算法中, 假定阈值 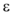
以新浪微博平台及其数据作为实验环境, 实验分为两段进行, 2013年11月12日至12月12日为第一阶段, 2014年3月10日至4月10日为第二阶段, 实验周期两个月。实验设计选择了两个营销主题的话题内容, 一是与“ 户外产品” 营销话题相关的3 000条博文和对应的2 000个微博客户, 每个用户平均发表与其主题相关的博文1.5个; 另一个是与“ 母婴产品” 营销话题相关的博文3 000条和对应的2 100个微博客户, 每个客户平均发表与营销主题相关的博文约1.4个。测试数据选取在“ 户外产品” 和“ 母婴产品” 主题的话题下的各5组最新的且不包含在前期所取的数据中已被影响簇内的个体客户转发了的产品推广博文和相应的博文转发序列, 即该主题的话题下博文实际对个体产生影响作用的数目。其中博文转发序列通过新浪微博API提供的repost_timeline方法获取。
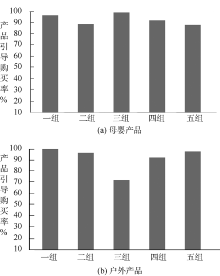
实验1: 在数据集合中按照算法步骤找出在“ 户外产品” 和“ 母婴产品” 主题的话题下的影响簇, 分别计算这两个话题下的影响力大小; 利用测试数据中相关转发数, 计算产品的引导购买率。影响簇内的一条个体营销博文被别人转发, 可认为该营销博文成功地影响了另一个人, 即转发或点击该博文的个体会被成功引导到产品购买页面, 藉此方法可计算产品的引导购买率。产品的引导购买率=影响簇内部个体发布的营销博文实际影响到的个体数目/影响簇实际的影响力× 100%。实验结果如图1所示:
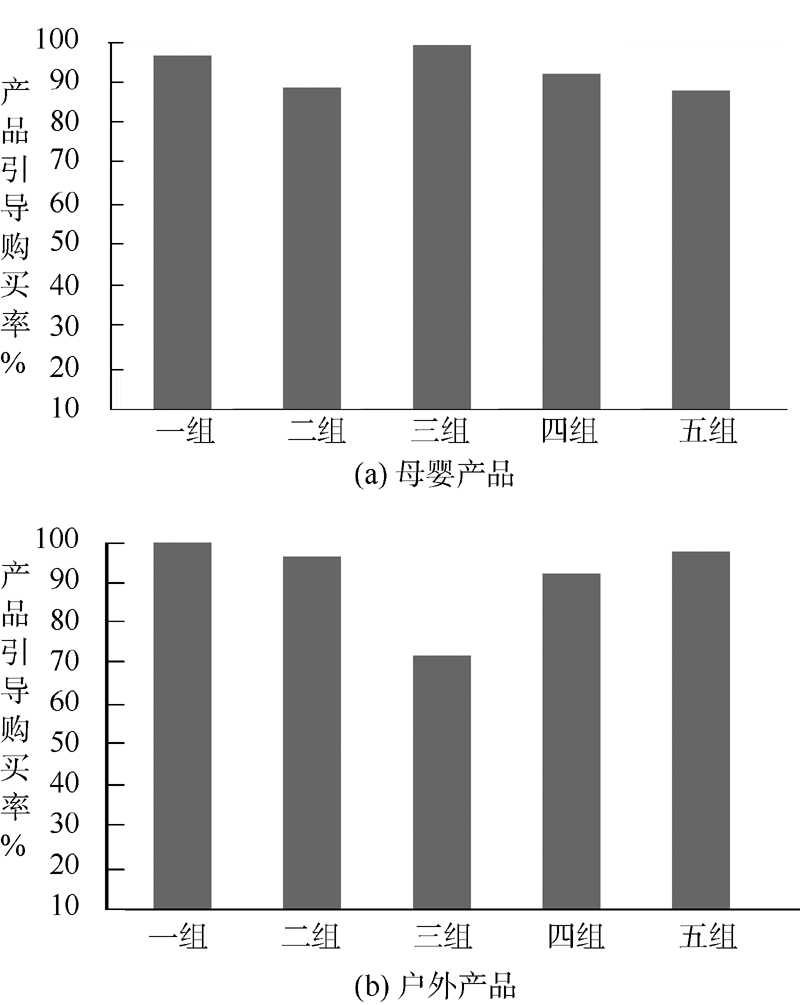 | 图1 分组实验的产品引导购买率对比 |
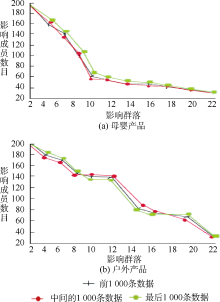
实验2: 在每个话题各取3 000条博文, 随机分成三等份, 测试数据在不同情况下算法对噪声数据的敏感性, 以确定算法效果对数据质量的影响。结果如图2所示:
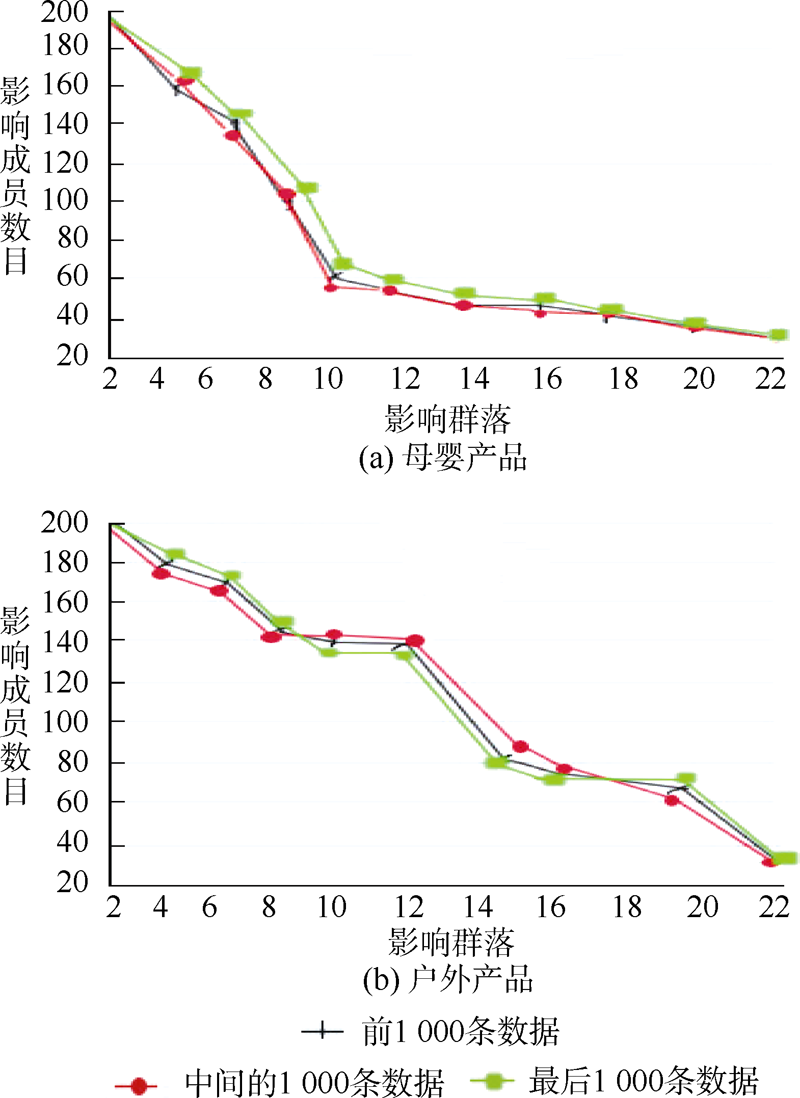 | 图2 不同数据质量下的影响群落数对比 |
实验1的结果表明: 在“ 户外产品” 和“ 母婴产品” 营销主题的话题下, 5组实验数据计算的产品引导购买率均在90%左右, 只有一组实验例外。即找出的影响簇在“ 户外产品” 和“ 母婴产品” 营销主题的话题下具有高影响力。实验2的结果表明: 每个营销主题的话题下的数据计算获得的影响成员数目和影响群落数目基本一致, 表明该算法对数据的噪音不敏感, 即算法在数据质量不一致的情况下仍然具有高精确度。
在实验过程中, 参数的选择会对实验结果产生重要影响, 其中 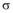
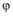
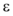
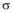
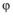
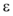
在互联网上, 利用社交网络中有价值的活跃客户人群传播企业营销推广主题信息是网络营销决策支持的重要技术。本文以社交网络特定话题信息传播为目的, 探索社交网络参与话题传播的网民频繁互动关系, 以及发现对话题信息传播有高影响力作用人群的方法, 以此为企业开展网络精准营销决策提供理论支持和实用方法。
研究发现, 在社交网络平台上的客户个体之间有频繁的信息互动关系, 这种关系对传播特定营销话题信息具有重要的影响。企业可利用这群有重要传播影响力的客户作为营销信息传播中介, 以口碑营销方式对营销受众对象实施精准营销, 可为企业获得事半功倍的营销效率和效益。主要方法是采用基于频繁序列聚类方法, 通过寻找对传播营销话题信息有高影响力的贡献人群, 形成基于营销话题传播的频繁传播序列影响簇发现谱系挖掘方法。该方法计算有序的频繁传播序列和社交网络中成员个体之间的距离, 找出对营销主题的话题传播有贡献的高影响力人群, 以此作为向目标受众人群推广营销信息的影响簇, 并以新浪微博数据进行实验, 经过数据采集、分析和处理验证算法的合理有效性。该方法可为企业营销策划决策支持提供理论依据和实用方法。
由于研究中仅考虑个体影响力自身的传播因素, 未包括作用于个体影响力的其他因素, 也未考虑博文主题内容和文本情感倾向性因素, 同时微博中存在一些非正常用户行为会干扰实验结果, 这些都需在后续研究中综合考虑, 以完整体现网民个体在社交网络中话题信息传播中的影响力综合因素。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|