基于规则的机构名规范化研究*
[杨波 , 杨军威, 阎素兰]
, 杨军威, 阎素兰]
, 杨军威, 阎素兰]
|
|


作者简介:杨波: 提出研究思路, 算法设计, 数据处理, 论文最终版本修订; 杨军威: 部分算法设计, 数据处理; 杨波, 杨军威: 起草论文; 阎素兰: 算法评测。
[Objective] To improve the data reliability in large-scale academic assessment and the performance of word-similarity or frequency based techniques in institution name normalization. [Methods] A new rule-based algorithm aided with low-value word similarity is proposed and a series of rules and statistical methods are applied jointly to mapping multiple institution names onto one entity of institution, so as to make institution name normalized. [Results] The experimental results show that the F-value of the rule-based algorithm (55.50%) is higher than the other two strategies. [Limitations] The ability to identify institution names with low value of word similarity is not good enough. [Conclusions] The rule-based algorithm proposed performs better than the other two techniques comprehensively, while the recall value needs to be improved.
采用量化方法对急速增长的海量科研成果进行评价, 是政府和科研机构进行科研资金分配、成果转化、人才培养和制订长期科研战略的必要工作。在具体的科技评价研究以及科研管理实践中, 使用最多的评价工具就是ISI开发的数据平台— — 基本科学指标数据库(Essential Science Indicators , ESI)。ESI提供前1%的机构、国家、作者和学科等层面的排名数据, 一直以来被作为重要的参考标准之一[1]。然而通过本研究大规模的数据分析发现, ESI提供的数据在准确性方面存在较大误差。在作者分析和机构分析方面的问题尤为突出, 如作者重名现象比较严重和机构名称混乱等问题。当前大多数建立在ESI评价数据之上的文献计量学研究和科技评价管理决策, 都不同程度受到数据可靠性问题的影响。有关机构合作网络的研究证实了机构名称的歧义对机构科研评价的影响是显著存在的[2]。由于高被引论文和作者在大学排名中占有比较高的比例, 因此没有对机构名称进行统一, 将直接影响机构排名位置[3]。由于各种复杂的原因, 比如作者书写习惯、机构名翻译方法的差异、机构合并和更名、隶属关系不清和数据录入错误等问题, 导致机构统计数据的准确性受到影响。虽然机构名称的表现形式多样, 但机构名称的层次关系在总体上存在一定规律。Web of Science (WoS)中提供的已标注的结构化机构信息可以作为机构规范化的重要参考。
为了改善基于海量数据的科技评价中的数据可靠性问题, 克服相似度匹配或者频率统计方法在机构名称规范化方面存在的缺陷, 本研究提出基于松散的词面相似度的机构名称映射算法, 该算法采用规则和统计相结合的策略实现多个机构名称到一个机构实体的映射, 从而达到机构名规范化的研究目的。本研究将对基于规则的机构名规范化算法和传统方法进行对比, 通过多个量化指标评估算法的有效性。
引发机构名不规范现象的原因有很多种, 在形式上也比较多样化, 主要体现在以下5个方面: 翻译方式不同; 书写习惯不同; 机构变迁; 作者拼写或者数据加工错误; 总部和分支关系。
不同的原因导致不同的错误表现形式, 因此在机构名规范化的过程中, 需要采用不同的技术手段识别和归并这些数据。
国内从文本检索的角度对机构名消歧已经有很多尝试, 比如利用社交网络平台Twitter信息的机构名聚类研究[4], 利用百度百科词条的命名实体识别等[5]。但用于科技评价的机构名规范化方法还比较少。从科技评价的对象和评价方法方面分析, 被评价实体可能是作者、期刊、机构或者国家等。虽然也存在期刊更名或者国家名称译名不统一等情况, 但作者名和机构名的情况更为复杂, 数据噪音问题更为突出, 并且相互关联。与作者名规范化所不同的是, 基于科学文献的作者姓名识别可以参考的信息很多, 比如篇名、摘要、关键词、期刊名、合作作者、地址和电子邮件地址等[5, 6], 而可供机构名识别的直接信息非常有限。机构名规范化的关键问题是解决机构名称和机构实体之间的对应关系。这种关系主要分为两种情况: 一个机构名对应多个机构实体; 多个机构名对应一个机构实体。
一般情况下, 第二种情况更为普遍, 对评价结果的影响也更严重, 因此也是本文的重点研究内容。
采用基于科技文献的机构名规范化的策略主要分为两种, 一种是基于机构注册列表的机构映射, 另一种是以机构名称文本相似度为依据的机构名称聚类。
(1) 在前者的相关研究方面, Abramo 等在针对意大利大学评价的研究中采用一个人员-机构目录, 该目录包含意大利大学系统中每个研究者所属学科领域、大学、学院以及职称信息[7]。
(2) 机构名称中的关键词一定程度上体现了机构的性质和类别, 因此有些研究者采用以文本为基础的相似度比较策略进行机构名规范化。Morillo等利用机构名中抽取的关键词对西班牙的研究机构进行类别标注[8]。Jiang等采用一种基于规范化表达距离(Normalized Compression Distance)的机构名称聚类方法, 试验结果表明该方法比较有效地实现了针对同一机构不同名称的聚类[9]。Onodera等在进行作者识别研究中, 对所有在机构名称中出现的词的频率进行统计, 并赋予不同的权重, 根据两个机构地址中共同出现的词的权重之和衡量它们的相似程度[10]。French等提出利用字符串的编辑距离进行聚类的方法, 并且以文献作者的机构地址为对象进行实验, 结果证明基于编辑距离的技术能有效地实现对机构地址的聚类[11]。机构名映射是作者识别的一个重要环节, 目前大多数作者识别的研究中或多或少会涉及到机构名的规范化问题。其中最常见的方法是基于机构名称字符串中共同出现的单词数量判断两个字符串所代表的机构是否对应于同一机构实体[12, 13]。
经过科研管理部门人工加工和维护机构列表虽然在权威性和准确性方面有一定优势, 但实际上很难获得和维护一个包含全世界各个国家科研机构名称的完整的、格式统一的信息列表。在面对海量信息的机构评价中, 基于登记制度的机构列表的应用范围和使用效果将受到很大的限制。基于词面相似度比较的方法为自动化的机构名称映射提供了新的途径, 其有效性已经得到证明, 但这种方法也存在一定局限性。通过大量的机构字符串分析可以发现, 很多机构名称的词相似度很高, 或者编辑距离很小, 实际上并不对应于同一个机构实体, 而相似度低或者编辑距离大的机构名称却很可能对应于同一个机构实体。因此通过单一的词相似度或者编辑距离判断两个机构名字符串是否对应于一个机构实体的方法是不可靠的。
在数据加工过程中, WoS文献记录中的地址字段被分成若干部分, 主要以“ 主机构名, 部门名称, 地址, 邮编, 地区或者国家” 的形式出现。对同一个机构实体, 之所以存在多个与之对应的机构名称, 主要原因有: 翻译方式的不同、书写习惯不同、机构变迁、拼写或者标引错误, 以及总部和分支隶属关系问题。对WoS中导出的大量文献记录中的地址字段进行分析, 可以发现在同一个作者名的文献集合中, 如果两个主机构名称具备一定相似度, 并且其下属机构名称或者邮编相同, 则这两个机构很可能对应于同一个机构实体。比如对于作者Diao, KF存在以下两个不同的机构地址:
①Linyi Normal Univ, Dept Math, Linyi 276005, Shandong, Peoples R China.
②Linyi Univ, Sch Sci, Linyi 276005, Shandong, Peoples R China.
地址1和地址2中的主机构名分别为“ Linyi Normal Univ” 和“ Linyi Univ” , “ Dept Math” 和“ Sch Sci” 为其下属学院。除了国家和省份字段外, 两个地址的邮编都是“ Linyi 276005” , 因此可以初步判断Linyi Normal Univ和Linyi Univ对应于同一个机构实体。
上述样例中体现的规律为机构名规范化操作提供了线索。因此笔者将以此为研究假设, 在借鉴传统基于简单或者加权词面相似度方法和邮编匹配方法的基础上, 提出基于规则和编辑距离结合的机构名规范化算法。该算法建立在WoS的结构化英文题录数据基础上, 因此可以独立于不同的原文语种, 有效地实现机构名的识别和聚类。
机构名规范化的过程本质上是对机构名进行聚类。对数据样例分析可以发现, 无论何种原因产生的机构名称的多样化问题, 在很大概率上这些机构名称之间满足一定的词面相似度。比如“ Univ Colorado” 和“ Univ Colorado Denver” , 后者是前者的一个校区。利用词面相似度进行机构名称聚类的缺陷是, 很多机构名称即便比较相似, 但也可能不指向同一个机构实体, 如“ Univ Seoul” 和“ Seoul Natl Univ” 。因此, 单纯依靠主机构名的词面相似度的聚类方法并不可靠, 需要通过其他信息进行二次匹配。大多数机构地址中包含了邮编信息, 因此可以作为二次匹配的依据。由于各个国家的邮编格式存在很大差异, 有的是纯粹数字, 有的是数字和字母结合, 因此本研究将利用模糊匹配算法识别机构地址中出现的连续数字字段作为邮编, 而不是只提取其中的数字部分, 比如“ Linyi 276005” 。
Onodera等在作者识别研究中, 将作者机构地址之间的加权相似度作为作者相似度判断的第一步过滤条件。在该研究中没有涉及到对该方法的有效性测试, 因此本研究将参考Onodera等的词权重分配方案, 利用改进的相似度计算方法实现机构名的规范化。算法按照一个词在机构地址中出现的频率分配权重, 具体词权重分配方案[10]如表1所示。根据TF-IDF的原则以及对大量机构名分析结果显示, 在机构名中一个词出现的频率越高(同一地址中一个词出现多次则多次计数), 它对机构实体的区分能力越弱, 权重也就越低。
| 表1 词权重 |
为了提高机构名识别的准确性, 本研究也采用先匹配国家名称的做法。如果两个地址的国家字段相同, 才进入相似度计算过程, 否则给两者之间的相似度直接赋值为0。Onodera等将相似度定义为两个地址之间除了国家字段外, 出现的相同词的权重之和[10], 这种计算方法没有考虑词长问题, 地址越长越容易获得高的权重值。本研究将利用两个地址中出现不同词的数量, 对权重之和进行平均, 获得由所有地址组成的相似度矩阵。
基于规则的机构名规范化方法建立的前提是机构地址中存在上下级的结构化关系。如果一个机构名和另外一个机构名满足松散的相似度(词面相似度或者编辑距离), 并且这两个机构名对应的下级机构或者上级机构名相同, 则它们很可能对应于同一个机构实体。根据机构规范化操作的步骤, 本研究设计了规则和编辑距离相结合的机构名规范化算法, 其分为三个部分(算法的详细描述参见文献[14]):
(1) 建立作者-机构名称对应表。从原始数据中抽取作者名和对应的机构名, 形成的对应表中每个作者对应于一个或者多个机构地址。由于WoS原始数据中提供的作者全名信息在很多情况下仍然是作者名简写, 因此这里抽取作者简写作为作者名。虽然可能会加重作者重名问题, 但数据稳定性可以得到保障, 并且作者识别不是本研究的目标。如果多个同名作者对应的机构名称有重叠则合并作者机构(即视为一个作者)。
(2) 基于作者块的机构名聚类。本研究采用作者识别中的以作者块为单位进行机构名识别操作的策略[6], 即将作者-机构名称对应表中的作者按照名称进行分块, 在块内部再进行机构名称比对。虽然不能认为同一个作者块中的多个机构名称一定对应于同一个机构实体, 但相似机构名很可能存在其中。根据机构名规范化的特点, 针对一个特定的作者块, 本研究提出以下规则和算法组合(N1和N2分别表示当前集合内任意两个机构名):
规则1: 如果N1和N2包含的词完全相同, 只是顺序不同, 则加入集合C; 如果N1和N2词长相等, 但包含的词不完全相同, 如果Sim(N1, N2)> 0.6, 则加入集合C, 公式如下。
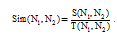
其中, S(N1, N2)表示N1和N2共同的词的数量, T(N1, N2)表示出现在N1和N2中不同的词数。
规则2: 如果N1和N2词长不相等, 但S(N1, N2)≥ 2, 则将N1和N2组合加入候选集合C。
规则3: 如果N1和N2其中一个是另外一个的子串或者缩写形式, 则将N1和N2组合加入集合C。
规则4: 如果N1和N2之间的编辑距离小于0.2, 则将N1和N2组合加入集合C。
规则5: 当前作者块的论文地址中, 任意分别包含集合C中的机构名称N1和N2的两个地址对应的国家名称相同, 则保留集合C中的N1和N2组合, 否则删除。
规则6: 参考规则5的结果, 如果包含N1的地址和N2的地址Address1和Address2的切分长度不同(以逗号切分)或者切分长度相同但小于等于3, 并且N1和N2对应的子机构名相同(即地址的第二个部分), 则加入集合D。
规则7: 参考规则5的结果, 如果Address1和Address2的切分长度相同并且大于3, 则比较它们中间部分(除主机构名、国家名称和省份)是否相同, 如果有任意一个部分相同, 则将N1和N2组成加入集合D。
(3) 基于频率的机构名称映射。以上的多条规则的筛选后, 产生的集合D中保存的是已经识别出来的可能相似的机构名称对。为了提高准确率, 本研究采用的方法是将频率超过指定阈值的机构名称对进行级联, 从而形成一个个集合, 每个集合包含一个特定机构实体的不同形式的若干名称。频率阈值可以根据实际的应用要求进行指定。如果指定比较高的阈值, 获得的机构名称映射往往是比较常见的针对某一个特定机构的多对一现象; 反之如果设定比较低的阈值, 则能发现很多因作者本人或者数据加工错误导致的偶发性机构名多对一现象, 但准确率会下降。
为了对本研究提出的基于规则和编辑距离的机构名规范化方法进行详细评测, 将对上述三种方法进行平行测试, 并通过多个指标的测试结果全面评估其有效性。
为了使得本研究的数据在后续的评价实践中和ESI的排名数据形成对比, 采用的数据收集策略是, 以ESI的学科划分为参考, 从WoS中导出文献题录信息, 对每个学科进行三种机构名规范化策略的独立测试。为了充分评估各种策略在不同学科的适用性, 以数学、计算机、心理学和经济与商业4个学科发表于2008年-2011年的文献元数据为测试数据集。
在采用基于主机构名和邮编的机构名规范化实验中, 计算两个机构名的相似度(余弦函数)。如果相似度为1, 则直接视为同一机构; 如果相似度大于阈值(根据测试, 这里设定0.7), 则进入下一步邮编匹配。对主机构名是缩写(词长为1)的情况, 直接采用邮编进行匹配, 而不进行相似度计算。所有通过邮编匹配成功的机构名称对将被视为对应同一机构。
在基于加权的地址相似度计算中, 从上述4个学科的数据集中分别抽取不同的词并且统计频率, 根据频率形成词权重表, 形成的权重分布频率如表2所示。形成地址相似度矩阵后, 将主机构名相同的地址相似度设为0, 将每个地址对应的其他地址按照相似度降序排列, 相似度最高的地址对应的主机构名则视为和当前主机构名表示同一个机构实体。
| 表2 权重分布表 |
基于规则的机构名聚类中, 需要进行作者-机构表的建立、机构名聚类和频率过滤三个步骤。
为了验证基于规则的机构名规范方法的有效性, 将以信息检索中最经典的两个指标检准率和检全率对上述提到的三种策略在不同学科的表现进行测试。邀请了两组评测人员分别参与到两个指标的评测中, 并且为了确保评测结论的可靠性, 每个小组由两名评测人员构成。每个评测小组的指标结果由两名评测人员的数据汇总获得。评测过程中参考机构名称出现的论文题名、全文、Wiki和机构网站等信息, 判断机构名识别结果的正确性。
基于主机构相似度和邮编的方法(简称PB), 以及加权相似度算法(简称SB)在原始数据集上运行所产生的结果数量非常庞大, 给检准率的判定带来困难, 并且使得检全率难以获得。因此, 为了减轻评测负担, 除了基于规则的算法(简称RB)的检准率评测外, 其他两种方法的检准率评测和所有检全率评测均在随机抽样的数据集上进行。剔除作者-机构对应表中所有发表论文超过一篇的作者, 从中随机抽取30个作者名, 由这些作者署名的文章组成抽样数据集。各个学科的数据量为: 数学291篇, 计算机科学444篇、心理学380篇, 经济与商业194篇。
(1) 检准率指标。在检准率评测中, 所有以上下级隶属关系出现的机构名称对都将被视为识别正确。由于基于加权相似度算法产生的是相似度矩阵, 因此在评测中选取每个学科所有地址两两之间相似度最高的20组进行正确性判断, 如果截断处有多个相同相似度的地址则顺延。为每个地址选取与之最为相似的三个地址, 如果其中一个为正确, 则视为识别正确的主机构名称对。基于规则的算法采用灵活的频率控制策略, 本实验在检准率评测中采用的频率阈值为2。三种算法运行获得的4个学科的检准率数据如表3所示:
| 表3 检准率评测结果 |
从评测结果来看, 加权相似度算法在其中两个学科的检准率最高, 基于规则的算法相对比较均衡和稳定。从后者的评测结果可以发现, 由于科研活动的特点和学术规范要求不同, 在软科学领域, 基于规则的算法的准确率要低于硬科学。
(2) 检全率指标。由评测人员手工识别测试集中出现的所有机构名称对应情况, 并建立对应表, 再对上述三种方法的运行结果进行判定。对基于加权相似度算法的检全率判定策略同上, 而对基于规则的算法采用了频率为1和2的两个级别的评测(分别用RRB1 和RRB2表示)。最终的评测结果如表4所示。
| 表4 检全率评测结果 |
通过检全率评测数据可以发现, 所有方法的检全率都远低于检准率。这说明在机构名规范化过程中, 已经识别出的机构名准确率比较高, 而对出现频率比较低的机构名规范化效果还不够理想。相比之下, 本研究提出的基于规则的规范化方法在检全率方面最优。和检准率类似的情况是, 硬科学领域的检全率总体上要高于软科学的检全率。
(3) 综合指标。为了综合评价三种策略的有效性, 表5提供了以F值度量的综合指标(其中FPB采用了基于RRB2的评测数据)。
| 表5 综合评价指标(F值) |
从事心理学研究的机构涉及大学、医院、研究所等, 因此在机构名的形式上比较复杂, 从而导致了整体的机构识别效果不够理想。基于邮编的匹配方法在多个机构共用相同邮编的情况下, 会出现识别错误; 而基于词加权的方法没有考虑到机构的层级关系, 并且在相似性判断方面不够灵活。总体上, 本研究提出的基于规则的组合算法在算法设计上对上述问题进行了改善, 并且实验数据表明该算法要优于其他两种。
即便基于规则的组合算法在大数据集的测试中表现良好, 但仍然存在不能自动识别的机构关系。上述三种方法的入口是机构名的词面相似, 而在某些情况下, 两个不相似的机构名称也可能对应到一个机构实体。此外, 在美国、法国等国家的大学和大学系统混合存在, 对大学系统内部各个大学之间的隶属关系判断失误, 也是导致机构名规范化结果不准确的原因之一。
在以往涉及机构名称规范化或者相似性判断的研究中, 对机构名规范化进行独立测试的研究比较少。Jiang等的研究显示采用规范化表达距离的机构名称聚类方法的平均准确率为83%[9], 但该方法采用的测试文献集来自于同一个机构, 机构名称的表现形式相对单一, 因此其有效性还有待验证。通过主机构名词面相似度和邮编匹配结合的方法, 识别效果有待改善。本研究对Onodera等采用的基于加权地址相似度计算的方法进行评测[10], 可以发现, 虽然该算法在识别个别人工难以发现的机构名对应案例时, 有比较好的效果, 但整体表现不够稳定。本研究采用的基于规则和松散相似度结合的方法, 既保留了相似度匹配的优点, 又可以充分利用机构之间的隶属关系, 帮助识别多个机构名称对应一个机构实体的现象。实验结果表明, 该方法在各个学科频率阈值为1和2两个层次的检准率评测中表现稳定, 在4个学科的平均F值达到55.50%, 综合表现要好于其他两种方案。在检全率方面不够理想的主要原因是, 基于规则的方法在阈值控制方面有一定的要求。因此小样本集合上的实验会对评测结果有一定的影响, 在实践中可以通过大的统计样本改善算法的运行效果。
虽然基于规则的机构名规范方法整体上要优于其他两种方法, 发现了大多数常见的机构名多对一现象, 但另外两种方法在发现有些文献频率比较低的机构名称对时, 有比较好的效果, 这一点从检准率评测数据中可以发现。在后续的研究中, 可以尝试将这三种方法相互结合, 以改善低文献频率的机构名规范化效果, 从而使科技评价中的数据统计更加精确, 评价结论更加可靠。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|