{kind=link}
{kind=link}
电商用户“状态-行为”建模及其在商品信息搜索行为分析的应用*
[袁兴福, 张鹏翼 , 王军]
, 王军]
, 王军]
|
|


[Objective] This research aims to develop an approach to model and describe the user information behaviors during information seeking, product comparison, and decision-making process more systematically and precisely. [Methods] This paper proposes a user “state-behavior” model including sequential, temporal, and content features. Test data set includes the click-through log data of 4 710 users from taobao.com. The user behavior sequences are established by mapping page types and user behaviors, and then used as features to model users’ “status-behavior” at the session level. [Results] Classification using the “state-behavior” model resulted 8 user groups with significant features, including swift searchers, serendipitous browsers, promotion-driven users, personal information maintainers, weekday-active users, weekend-active users, night-active users, and irregular users. [Limitations] Adding a session layer between logs and user behavior may cause accumulation of classification errors at the session level into the behavior level. [Conclusions] The results show that this model is able to capture the behavior sequence more precisely. The classification of users may be used in guiding personalized recommendation and marketing plans for e-commerce Websites.
据中国互联网络信息中心发布的数据, 截至2014年12月, 我国网络购物用户规模达到3.61亿, 占我国网民总数的55.7%[1]。已有研究探讨利用电商平台上积累的用户数据进行推荐和预测, 如基于用户特征进行推荐[2, 3]、利用点击流数据预测购买行为等[4]。在挖掘访问日志方面, 已有研究还停留在利用页面与页面之间的跳转概率揭示用户行为[5, 6, 7], 这种定义用户行为的方法并不准确, 而且可能丢失用户在同一页面中的点击行为。另外, 直接用记录刻画用户行为未考虑会话层信息, 而会话代表用户在一定情境下执行事务的特征, 导致用户行为特点未被充分揭示。可见, 从大量电商网站用户访问日志中, 提取用户信息行为序列等会话特征, 并从中分析提炼商品信息搜索行为的模式, 依然是电商网站用户行为特征研究方面十分必要的课题。
本文从序列、时间、内容三个角度出发, 利用一批用户的浏览器日志, 在原始日志与用户行为序列之间建立会话层, 从而分离日志记录与用户行为。本研究采用“ 状态-行为” 模型对用户行为序列及用户所处的页面状态进行标记, 制定描述页面类型及用户信息行为的标记词, 并对标记词建立等级结构, 考虑电商网站URL的参数特征, 将其纳入从记录到页面类型、行为类型的映射方案, 并通过实验数据对此建模方法进行应用和验证。
用户的访问日志主要分两种, 服务器端日志与浏览器端日志[8]。服务器端日志指服务器在响应用户发送的请求时记录在磁盘上的数据, 浏览器日志是用户在发送请求时, 浏览器(或者安装在浏览器中的插件)记录在用户磁盘中(或上传到指定位置)的日志。已有研究利用客户端日志建立用户兴趣模型, 但受数据集中性的限制, 无法为多个用户建模[9]。为弥补这方面的不足, 可在被测用户浏览器上安装插件, 获取多个用户的浏览数据[10]。此方式能获取如下用户数据: 用户访问路径、用户点击行为以及更精确的页面驻留时间。此外, 使用浏览器端日志可以更准确地区分不同用户, 并且可以避免网络爬虫产生的无效流量[11]。
建模需利用其他数据源对日志数据进行扩充或描述。这些扩充的数据, 一方面从抓取的网页内容[12]中提取, 一方面来自人工对页面的标记描述[13, 14]。对页面进行处理时, 可对页面标记直接编码[5, 6], 也可对页面进行标记[4, 13, 14]。然而, 一次页面类型的标记往往和URL中的参数密不可分。尤其在电商页面中, URL往往具有繁杂的参数, 页面相同参数不同的URL指向的网页内容很可能是不同的。
由于研究人员抓取网页的时间与用户访问的时间并不一致, 抓取时网页可能已经失效或变更, 这会给研究带来一定误差; 而如果使用人工标记, 研究结论容易受到标记人员主观影响。本文尝试针对浏览器端日志, 结合网页内容与人工标记两方面的优点, 对用户的访问记录进行标记描述。
用户模型的表示方法有4类: 协同过滤模型、行为规则的模型、基于概念的用户兴趣模型与向量空间模型[15]。本文采用的向量空间模型(VSM)是最为常用的用户模型表示方法之一, 通常使用一组向量值描述用户特征, 向量的每一个维度代表用户感兴趣的一个主题。维度的提取往往与网站系统的数据特征有关: 在标签系统中, 特征维度往往由用户提供的标签表示[16]; 在检索系统中, 特征语词来自分析系统页面后所得到的关键词; 在协同过滤系统中, 可以把项目认为是描述用户特征的维度。使用VSM构建用户行为模型的困难是, 数据中并没有明确表示信息行为的词语, 所以在构建描述信息行为的维度时, 需要从数据中抽象出描述信息行为的维度。
浏览路径能够在一定程度上反映用户浏览行为特征。文献[5]根据用户的浏览路径(包括页面停留时间)计算用户之间的相似性。但此方法仅适用于网站页面类型较少的情况, 如果页面较多或者包含较多的动态页面, 会使构造矩阵过于稀疏, 导致用户聚类不准确。有研究依据用户访问路径创建页面序列, 使用关联规则挖掘页面跳转规律[6]; 或将用户访问的页面分类, 计算用户在这些页面之间跳转的概率以描述用户信息行为[7]。由于访问日志中只记录用户访问的页面, 没有标识出用户信息行为, 使得用户的行为序列信息没有被充分挖掘。
本文将用户会话抽象成页面状态与用户行为不断交替的过程, 用页面状态(Page State)与用户行为(User Action)刻画用户访问网站时的一系列记录。页面状态包含页面内容与页面类型, 停留时间是页面状态的一个属性, 状态是静态的, 并通过行为来切换, 由此形成一个状态行为交替的序列。用户行为是对用户在网页上的各种操作进行的归纳, 比如, 当用户点击筛选的链接时, 可认为用户发生了对列表的筛选行为。“ 状态-行为” 模型能够充分地表示用户的商品搜索会话特征, 本文重点研究用户商品信息搜索行为, 故提取用户的商品信息搜索行为序列进行分析。
实现用户“ 状态-行为” 模型的基础是对页面、行为进行标记, 标记页面类型时需要考虑URL参数。以淘宝网站中的结果列表页①(http://list.taobao.com/itemlist/default.htm. )为例, 参数中包含q字段的URL②(②http://list.taobao.com/itemlist/default.htm?q=iphone.)是用户检索产生的, 不包含的是用户浏览类目产生的。用户对两种页面存在不同的认知, 故需从参数上区分这两类页面, 比如分为检索结果列表页与浏览结果列表页。
用户行为导致新的网页序列, 网页内容的差异能够最准确地反映用户行为。然而在获取用户行为时, 直接对比两个URL指向的网页内容是困难的, 因此本研究根据URL的差异确认用户行为。例如: 会话中如下两条连续的访问日志记录中的URL字段值为:
http://s.taobao.com/search?q=iphone.
http://s.taobao.com/search?end_price=1000& start_price=10& q=iphone.
后者比前者增加了参数“ end_price=1000& start_ price=10” , 这是由于用户产生了筛选行为。针对日志中高频的页面, 分析这些页面的参数变化所反映的用户行为, 据此制定映射规则。
描述页面类型与行为类型的前提是创建语词标记体系, 为保留标记细节可使标记语词具有层级性。创建页面类型标记体系使用自下而上不断聚集的方式, 创建行为类型标记体系使用自顶向下逐步细化的方式。具体可参照实验部分的相关描述。
从原始访问日志中分离出用户会话, 标记会话中出现的页面类型与行为类型, 通过程序补充抽取网站中的相关数据(比如用户访问的商品信息, 检索词语等), 统计页面访问时刻与持续时间, 以完善页面状态, 最终形成包含数据的“ 状态-行为” 模型。从使用“ 状态-行为” 模型描述的会话中, 抽取出三个方面刻画用户行为: 序列模式、时间偏好、内容复杂度, 形式化为描述用户的STC模型: {Sequence, Time, Content}。具体而言:
S: 序列模式(Sequence), 即用户访问页面的序列特征。这种特征是多方面的, 可能体现在不同页面之间的先后关系, 也可能体现在访问序列的起始与终止页面。为了统一表达这些行为特征, 使用SQL Server序列分析和聚类分析模型对用户的行为序列进行聚类, 不同的类代表了不同的序列模式。
T: 时间偏好(Time), 用户的访问行为在时间上的特征。具体包括:
(1) 页面停留时间, 即用户在不同类型页面上的停留时间;
(2) 会话日, 即用户访问行为在工作日与休息日上的分布;
(3) 会话时间段, 即用户访问行为在一天的不同时间段上的分布。
C: 内容复杂度(Content), 一次会话中用户访问的商品种类。内容复杂度可通过访问的商品数与类目数来近似。
以此模型为框架, 分析用户的会话行为序列特征、时间特征与内容特征。在分析结果基础上, 归纳描述用户的向量空间并对用户进行聚类。
实验原始数据集来自某互联网市场调查机构通过浏览器插件收集的用户在2013年5月的浏览器访问日志, 包括4 710位用户在淘宝网的1 433 807条日志记录。在此基础上, 通过爬虫程序, 抓取用户访问的原始网页, 并利用淘宝开放的API①, 获取用户访问的商品描述信息共320 566条。用户访问日志、原始网页和商品描述信息三个部分共同构成本文的实验数据。数据表中重要的字段如表1和表2所示:
| 表1 浏览器日志字段及含义 |
| 表2 商品表字段及含义 |
电商网站业务的拓展造成了页面的繁杂, 对淘宝这样庞大的网站更是如此。对于从中得到的某一具体页面, 一般可以从内容维度、结构维度、功能维度三个方面分析, 运用卡片分类方法不断地向上聚集调整, 构成一个涵盖站点页面的层级标记体系。
将页面类型分成三级共75个类, 其中可供分析理解的一级类为: 淘宝门户页, 结果列表页, 交易页面, 检索主页, 会员活动页, 个人资料页面, 对象详情页; 不利于分析的一级类为: 验证性过渡页面, 无效页面, 未知类型。在构建行为类型标记体系时, 本研究使用自上而下的方法, 确立需要分析的主要行为类型, 再逐步细化。
将用户行为分成三级共56个类, 其中可供分析理解的一级类为: 用户登录行为, 个人资料管理行为, 浏览行为, 列表处理行为, 交易行为, 检索行为; 不利于分析的用户行为包括: 获取页面成分, 系统执行跳转, 未知行为。
将页面按照出现的频次排序, 频次最高的前120个页面已经涉及了86.35%的日志记录, 再多的选择会增加制定规则的难度, 因此仅选择频次前120的页面, 统计出这些页面的高频参数, 针对页面参数的不同, 映射到不同的类型。将不在前120个页面的13.65%的URL统一标记成未知页面或者未知行为。
映射完成之后, 对用户行为类型进行统计, 频率最高的用户行为是浏览(31%)、其次是个人资料管理(14%)、交易(12%)、筛选(11%)等, 关键词检索仅占3%; 有关用户行为类型的结果详见文献[17]。列表筛选的对象, 既可以是关键词检索结果列表, 也可以是按照一定条件筛选的浏览结果列表。
(1) 会话行为序列特征
会话的行为特征包括会话长度、会话起始行为、频繁行为、典型的行为序列模式等。本文使用 Markov模型表示会话中的行为序列, 通过计算序列片段后不同行为出现的概率来描述会话特征, 再利用EM (Expectation Maximization)聚类方法对其进行聚类。使用SQL Server Data Tools中聚类工具实现上述算法, 从类间距离、结果的可解释性两个方面评价聚类效果, 最终确定聚类个数为6。会话行为序列各分类的特点在文献[17]中另有着重论述, 在此归纳各类会话平均记录数、起始行为以及典型行为序列示例如表3所示:
| 表3 会话序列特征 |
(2) 会话时间特征
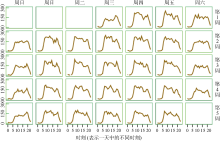
会话中不只有页面类型、用户行为类型, 还包含与页面类型相对应的停留时间与会话起止时间。图1显示了一个月内全部会话随时间的规律性分布。
图1中的每个小图的横坐标表示一天中24小时, 纵坐标表示不同时刻的会话量。可以看出会话个数随日期呈现比较明显的周期性规律, 工作日(周一至周五)会话量相对稳定, 休息日(周六和周日)会话量较低, 周六的会话量大于周日, 并且用户在工作日与休息日产生的会话随时间分布也不同。一天当中, 早晨、中午以及午饭之后的一段时间, 访问流量最高, 下午访问流量降低, 晚上的时候再次达到流量峰值, 20点之后流量基本就开始下降。在不同时刻的会话量差异实际反映了用户在不同时刻对访问电商网站的不同需求程度。
(3) 内容特征
在每一个会话中, 如果记录中包含商品详情页, 分析该页面获得商品ID, 并通过淘宝API提取商品详细信息及所属分类。为了能够考察一次会话中类目的涉及范围, 本研究将商品分类映射到顶级类目中, 并统计会话平均涉及的商品数量和类目数量。
从图2可以看出, 不涉及任何商品详情的会话占51.71%, 涉及一个商品详情的会话占15.92%, 涉及两个商品的占8.356%, 涉及三个商品的占5.025%, 而超过三个以上商品的会话总共占比18.989%。就类目数量而言, 大部分会话不涉及任何商品类目或仅涉及一个类目(87.78%), 但也存在一定比例的会话同时涉及多个类(涉及两个类的占6.966%, 涉及三个类的占2.659%), 表明一次商品检索行为中存在多购物任务的情况。
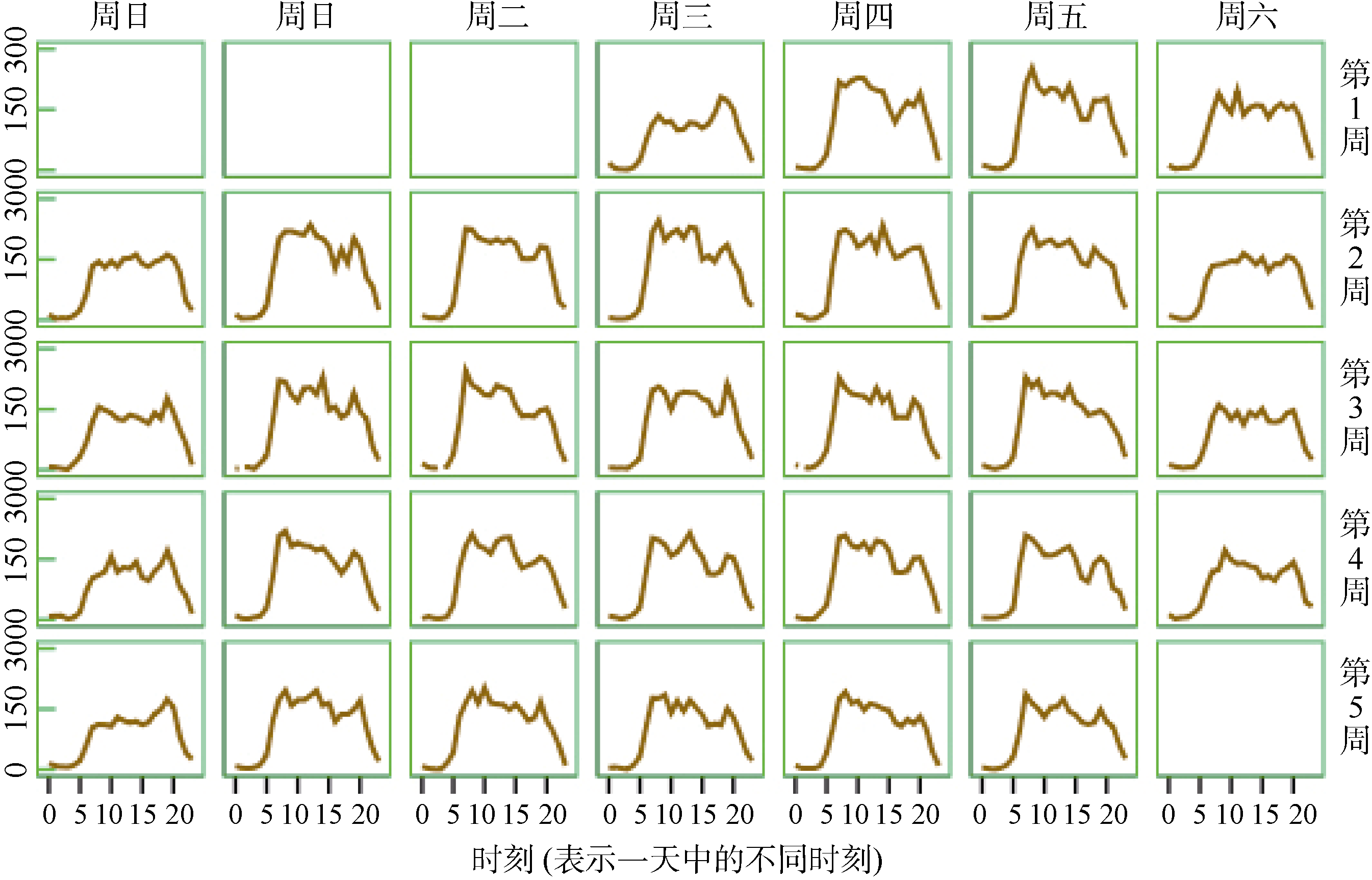 | 图1 会话个数随日期-时刻分布 |
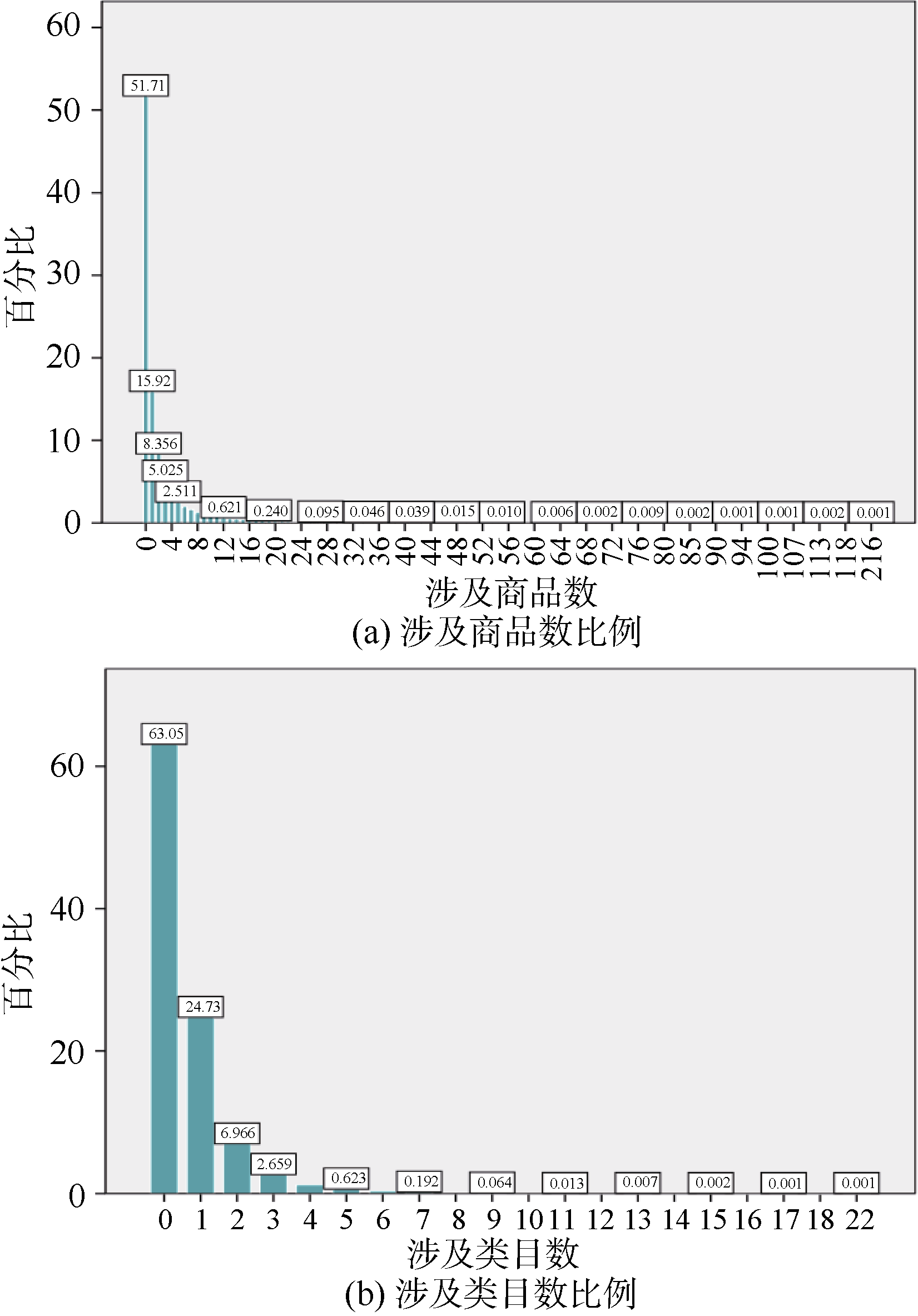 | 图2 会话涉及商品和类目数比例 |
描述用户行为可以有很多维度, 比如在一定时期内用户产生的会话数, 用户会话平均涉及的商品数与类目数, 在特定页面上的停留时间, 不同日期的会话比例, 不同会话序列模式的比例等。维度越丰富, 描述的用户就更具体; 维度之间越独立, 向量空间就越精炼。以上文得到的序列模式、时间偏好、内容复杂度统摄所有维度, 构建描述用户行为的向量空间, 共得到24个特征向量维度。本研究使用K-means聚类算法对用户进行聚类。考虑到K-means聚类算法的特性, 将以上各个维度数据归一化, 分别设置聚类中心数为4-12, 迭代次数间接反映了子类凝聚的难易度, 子类是否容易解释可反映分类的合理性, 各类整体的均衡可揭示分类的可用性。综合这几点因素选择聚类结果, 最终确定聚类个数为8, 经过41次迭代聚类趋于稳定, 最终聚类中心如表4所示。
对于每一个维度, 用深灰色标记8类中的最大值, 浅灰色标记出最小值, 以直观显示类的特征。通过对各类的维度特征分析, 本研究依次将8类用户描述为: 行动迅捷的搜索者、晚上会话产生者、休息日会话产生者、个人资料管理爱好者、工作日会话产生者、营销信息依赖者、信息浏览漫步者、非常规时间访问者。鉴于文章篇幅, 此处仅以分类1用户为例加以分析。此类用户检索型会话占比较高(77.10%), 其他类会话(特别是卖家管理会话和资料管理会话)占比都很低。
| 表4 用户行为模型聚类结果 |
这类用户在会员活动页、交易页面、登录页面停留的时间都很短。由于这类用户比较依赖检索并且在多种页面上停留的时间并不多, 因此可针对此类用户的商品信息搜索行为特点制定导购和推荐机制, 例如推荐信息最好不要放在页面上, 而在检索框中优化较为适合。
本文利用浏览器日志, 分析电商网站用户的商品搜索行为特征, 建立“ 状态-行为” 交替的会话模型, 以在会话层面上聚集用户访问过程中的相关信息, 统计分析发现, 会话的访问时间、页面的停留时间、涉及商品数、涉及类目数等因素皆可间接反映用户商品搜索行为特征。本研究创建具有等级结构的页面类型标记语词75个, 用户行为标记语词56个, 根据URL特征以及URL之间的差异标记页面类型与行为类型, 进而抽取“ 状态-行为” 模型中的页面类型序列与用户商品信息搜索行为序列。将序列聚类算法作用于商品信息搜索行为序列上, 以对会话聚类, 得到6类会话, 并将会话特征作为用户聚类的输入, 得到8类用户。与纯粹使用页面类型描述的会话聚类结果相比[14], 本研究的聚类结果可表现出会话中的高频模式, 并且可以区分不同类型用户的商品信息搜索习惯。利用上述商品信息搜索会话模式, 结合时间、页面特征, 可以对用户进行聚类, 有助于指导网站的推荐策略, 或对营销方案的制定提供支持。
本文的局限性在于用会话的聚类结果描述用户行为模式中的序列特征, 误差可能会叠加, 聚类结果受到标记体系合理性、映射规则合理性、序列聚类算法及参数选择三方面的影响, 用户特征可能因此出现偏差, 页面类型与行为类型体系的合理性尚需验证。本文行为模型也可扩展到服务器端日志, 需要对日志进行筛选, 除去爬虫产生的流量。本文提出的会话模型并没有充分填充状态中的页面内容域, 在进行大规模多维度的分析时, 可在会话建立阶段就对状态中的页面内容域进行填充。模型通过类型等级结构保留了用户行为不同层次的信息, 可在不同粒度上尝试以获取最佳效果。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|