


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
面向主题的高质量评论挖掘模型研究*
[唐晓波1 , 邱鑫2  ]
]
]
|
|


帮助消费者从海量的评论集合中识别高质量评论。
方法利用LDA主题模型对消费者关注的主题进行分类, 借鉴改进的自动摘要的思想, 追踪评论主题下的高质量评论, 提出面向主题的高质量评论挖掘模型。
结果自动提炼出每个主题下的高质量评论, 其准确率、召回率和F1值分别为80.73%、64.90%和71.95%, 并通过实证研究证明该模型的有效性和优越性。【局限】仅与部分典型模型作对比, 其他模型方法还未进行验证。
结论该模型能从评论集中有效地挖掘出不同主题下的高质量评论, 从而能够更加高效地辅助消费者进行购买决策。
[Objective] In order to help consumers distinguish high quality reviews from enormous review sets.[Methods]Using LDA topic model to classify the themes and referring to the thoughts of improved automatic summarization, this paper puts forward Subject-Oriented High Quality Reviews Mining Model.[Results]The model extracts high quality reviews automatically under each topic. The results of the experiment show that its precision, recall and F1 score reach 80.73%, 64.90% and 71.95% respectively, proving the model’s effectiveness and superiority.[Limitations]Just compared the model with some typical models, but there are some other methods exist but have not been verified. [Conclusions]The model can effectively mine high quality reviews under different themes from the review sets, thus help customers in making more effective purchase decision.
在Web2.0时代, 越来越多的内容和行为是由终端用户产生和主导的。电子商务也开始衍生出一种新模式— — 社交电子商务。它借助社交媒介、网络媒介的传播途径, 通过社交互动、用户自生内容(User Generated Content, UGC)等手段辅助商品的购买和销售行为。在线评论作为UGC中的一部分, 凝聚着集体的智慧, 对消费者有着举足轻重的地位。然而, 互联网上庞大又不断增长的信息中被利用的仅占到5%-10%[1]。因此, 获取高质量信息的成本不断增高, 消费者在查阅相关评论并做出决策的过程中会消耗大量时间, 从成千上万条良莠不齐的评论中发现合适的信息成为消费者极大的困扰。
因此, 如何使消费者能够快速有效地定位到自己感兴趣的主题下有价值的评论, 从而减少消费者购买的不确定性, 提高消费者对在线评论网站的感知有用性和粘性, 这是本研究期望解决的问题。
随着互联网的广泛应用, 在线评论在消费者购买决策中发挥着越来越重要的作用, 目前关于在线评论的效用研究主要从以下方面展开:
(1)发现影响在线评论效用的因素研究。Ghose等[2]认为在线商品评论内容中的观点主观性有助于预测评论的效用。 Otterbacher[3]却认为评论的内容是评价在线商品评论效用的重要方面。李志宇[4]从评论者信誉、评论得票数、评论时效性、评论长度以及评论语义特征入手, 建立评论效用指标体系。可以看出, 对于影响在线商品评论效用的因素没有统一的看法, 影响评论效用的因素缺少理论依据。
(2)一些研究[5, 6]使用网站的人工评价结果作为参照, 即将在线评论获得的赞成票与得票总数的比值作为模型或算法的因变量来探究评论有用性的影响因素。但仅仅局限于具有有用性投票的评论, 从而忽略了大量有用却没来得及投票的评论。
(3)利用机器学习识别在线评论的结构特征。聂卉[7]利用决策树预测模型区分高质量的评论。Liu等[8]提出一个非线性回归模型以预测有用的评论。这些方法都能较好地发现高质量的评论, 但有一些评论仅评价了商品某一方面的特征, 其他方面只字未提, 这使得消费者很难快速定位到当前商品准确的评价信息[9]。
另一方面, 主题发现的结果可以帮助用户定位一类相关评论[10, 11, 12, 13], 而关于怎样快速追踪主题下高质量评论的研究却鲜有深入。
文本摘要是为一个给定的文本自动创建压缩版本的过程, 目的是为用户提炼有用的信息。从摘要与原文的关系考虑, 可以分为抽取式文摘和生成式文摘。生成式摘要是以自然语言理解技术为基础, 对文本中的句子进行分割抽取后重新组合生成文摘, 但目前在自然语言的处理方面仍然是一个较难克服的问题。抽取式文摘是抽取文章中一组最重要的句子构成文摘, 定量地评定句子的重要度是文摘选取的关键。
据此, Erkan等[14]提出LexRank算法: 将给定的文档分成一个个句子, 计算句子之间的相似度, 将句子视作无向图G=(S, E)中的节点, 当句子间的相似度大于某一阈值时, 将这两个句子节点连接成边E。如果存在一个节点sS, 与之相连的边{E1, …, Ei}的数目i越大, 则节点对应的句子s的信息越重要。根据句子间的连接迭代计算句子所包含的信息量, 再从中选取包含信息量最多的一组句子作为文摘[15]。
LDA是一种生成概率模型。集合中的每个条目(文档)被建模成一个有限的潜在的主题集合。每个主题的特征是由条目的属性(单词)组成的概率分布。LDA通过生成概率模型, 获取语料库中词汇、文档和主题之间的关系。一篇文档的LDA生成过程如下[16]:
(1) 获取文档的长度即文档中所有单词的总数N~Poission(β );
(2) 获取文档在主题上的分布θ m~Dir(α );
(3) 从1到n遍历每一个单词wn:
①获取每一个主题的概率分布zm~Multinomial(θ m);
②获取主题与词的概率分布wn~Multinomial(Φ z)。
其中, α 和β 都是先验参数, θ 和Φ 是预估参数。采用Gibbs抽样估计θ 和Φ , 在保持其他词的主题分布不变的情况下, 预估当前词的主题概率, 通过边缘化θ 和Φ 间接求得它们的值[16]:
| | (1) |
CVK和CMK是维数分别为V× K和M× K的数量矩阵, V为词汇个数, K为主题个数, M为文档个数。
给文档中的词汇分配随机主题, 形成初始的Markov链, 根据公式(1)给它们再分配主题, 获取下一个Markov链的状态, 然后不断地迭代, 使得Markov链趋于稳定。Gibbs抽样算法为每个单词估计出θ 值和Φ 值[16]:
| | |
|---|---|
| | (2) |
这样可以得到每一个主题的概率分布和主题与单词的概率分布, 从而获得“ 主题-单词” 的概率分布矩阵和“ 文档-主题” 的概率分布矩阵。
文本摘要能准确、全面地提炼出文本主要内容, 以满足用户快速获取知识的要求。面向主题的摘要则能专注于用户的兴趣主题并提炼文本主要信息, 抽取出具体主题下的摘要文本。本文试图利用主题模型来发现潜在的主题, 实现已有评论集的主题分类, 使用户定位于自己感兴趣的主题, 利用抽取式的摘要方法追踪探测主题下的高质量评论。同样, 评论有用性投票同样能够反映评论质量。因此, 将评论主题发现的方法与自动摘要的思想和在线评论的有用性投票相结合挖掘高质量的评论, 提出了面向主题的高质量评论发现模型, 如图1所示。该模型由三部分组成, 分别是: 数据抓取模块、数据预处理模块和面向主题的高质量评论发现模块。
 | 图1 面向主题的高质量评论挖掘模型 |
八爪鱼采集器[17]是以分布式云计算平台为核心, 针对不同需求定义数据的抓取规则, 从而设计数据的采集流程, 模拟人的操作思维模式, 点击链接, 选取需要采集的数据项、循环列表和翻页等, 从所需网页获取大量的规范化数据, 实现数据自动化采集。
为保证数据的质量, 降低无关数据或噪声数据对结果的影响, 需要对抓取到元数据进行预处理。本文
主要从以下方面对数据进行整理:
(1) 剔除只包含特殊字符和数字的评论, 只保留重复评论中的一条;
(2) 利用IKAnalyzer2012开源分词类库对每条评论进行分词, 保留名词和动词;
(3) 建立停用词表剔除文本内容中的无用字词;
(4)分词后, 存在一些词频不高、但对应有多个同义词的词, 例如: “ 送货” 、“ 配送” 、“ 快递” 。为避免这类词被当作低频词滤去, 利用知网HowNet中的WordSimilarity计算词语的相似度, 合并同义词, 形成“ 评论-词语” 矩阵的集合。
当模型在语料库中学习时, 每个文档的主题分布可以表示成一个向量, 通过计算文档之间的距离来获取文档间的相似度[18]。也就是说, 相似的文档就会有相似的主题分布, 在其向量空间中距离就会很近。因此它们可以提供分类的基础以及定义两个文档之间的距离。
将每条评论当作一个文档, 则在对应的LDA模型的“ 评论-主题” 矩阵中, 每条评论的主题分布可以表示成一个向量 , 其中 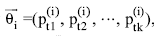
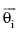

输入: n个句子的数组S[n], 余弦相似度阈值F
输出: 存储LexRankScore值的数组L[n]
a.定义变量。
Array CosineMatrix[n][n]; //评论的处理余弦相似度的矩阵
Array Degree[n]; //用于存储无向图中度的数组
Array L[n]; //用于存储评论集中LexRankScore的值
b. 计算每个顶点和周围顶点连接的总和, 每有一个顶点相连, 值就加1。
for i=0 to n do
for j=0 to n do
CosineMatrix[i][j] = idf-modified-cosine(S[i], S[j]);
if CosineMatrix[i][j] > t then
CosineMatrix[i][j] = 1;
Degree[i] + +;
end
else
CosineMatrix[i][j] = 0;
end
end
end
c.利用节点的度的大计算评论的重要程度, 用值L表示。
for i=0 to n do
for j=0 to n do
CosineMatrix[i][j] = CosineMatrix[i][j]=Degree[i];
end
end
L = PowerMethod(CosineMatrix, n, ∈ );
return L;
L越大即LexRankScore值越大, 说明该评论与很多其他评论相似, 其在所属主题的评论集中具有越大的重要性。所以此条评论就是比较重要的, 具有较高的质量。
依靠自动摘要的LexRankScore值单方面衡量主题下评论的质量是不够的。在对传统的自动摘要算法进行改进时, 需要将句子位置、指示性短语等相关信息纳入到权重计算中。句子的权重qi的计算公式[15]为:
qi=LexRankScore+PositionScore+InforScore (3)
PositionScore表示句子位置的加分; InforScore表示指示性短语所在的句子的加分。
因此, 本文借鉴自动摘要算法改进的思路, 在LexRank算法的基础上, 融入消费者评论有用性的投票和主题相关性, 改进评论权重计算过程。
(1) 评论的有用性投票
Mudambi等[19]将在线评论有用性定义为在线评论在消费者决策过程中的感知价值, 即消费者对其他互联网用户提交的评论对自己购买决策是否有帮助的一种主观感知。因此, 评论有用性投票同样能反映评论质量。评论的有用性等于有用投票数占投票总数的比值, 范围在0到1之间, 如: n个人中有m个人认为该评论有用则评论的有用性为m/n。考虑到当总投票数不同时, 评论有用性度量的效果也不同, 如: “ 1个人中有1个人投有用票” 与“ 10个人中有10个人投有用票” 的解释效果会不一样, 因此在本研究中引入投票总数作为控制变量, 同时使用等级划分来度量评论的有用性[5], 将其划分为4个等级(1=非常没用、2=比较没用、3=比较有用、4=非常有用)。当投票总数在5以上(包括5): 有用性投票比例大于或等于50%时, 评论有用性定为“ 非常有用” ; 有用性投票比例小于50%时, 评论有用性定为“ 非常没用” 。当投票总数在 5 以下: 评论有用性投票占比大于或等于50%时, 评论有用性定为“ 比较有用” ; 当有用性投票占比小于50%时, 评论有用性定为“ 比较没用” 。
根据不同的等级将评论赋予不同的权重, 将有用性等级与原有用性投票即m/n作加权处理, 分别对“ 1=非常没用、2=比较没用、3=比较有用、4=非常有用” 赋权值为a、b、c、d, 可以得到新评论投票有用性的值。将评论的加权有用性投票映射到对应主题的评论下, 记为UsefulScore。
| | (4) |
其中, degree表示有用性等级。
(2) 评论的主题相关度
当Gibbs抽样使参数达到稳定时, 在LDA模型获得的评论-主题矩阵中, 存在不同主题所占比重的不同, 使用评论集合包含的所有评论中主题混合成分权重的和计算评论集合中主题的重要性[20], 为方便直观地对评论主题重要程度进行比较, 将其在所有主题上进行归一化[11]处理:
| | (5) |
其中, N为文档的个数, K为主题的个数。P(zi)表示主题zi的权值,
Titov等[13]指出: 某一主题下的评论与主题越相关, 对该主题的价值越大, 因此与某一主题越相关的评论在该主题下的质量越高。选取阈值F, 筛选出每个主题下主题相关度大于F的评论作为该主题下质量较高的评论, 其相关度记为TopicScore, 因此在每个主题下评论相关度大于F的评论都有与之对应的TopicScore。
综上所述, 每个主题下的每条评论都对应有三个值: LexRankScore、TopicScore、UsefulScore, 每个值都在一定程度上反映了评论的重要程度, 决定了评论的质量。由此, 可以获得面向主题的高质量评论描述公式:
W=α LexRankScore+β TopicScore+γ UsefulScore (6)
其中, α 、β 、γ 是LexRankScore、TopicScore、UsefulScore三个衡量值的权值, α +β +γ =1。
亚马逊网站的重要特色之一就是商品评论, 因此, 本文将其作为数据源, 在2014年11月8日利用八爪鱼采集器[17]共采集1 508条有关手机“ HUAWEI华为荣耀3X畅玩版G750-T01 TD-SCDMA/GSM” 的评论, 自动抽取评论的文本内容和相关元数据, 包括各条评论的有用性投票(有用投票数/总投票数)、评论内容。并利用4.3节的方法对数据进行处理。为获得公式(4)中可信的权重值a、b、c、d, 利用调查法中多人打分的方式, 对“ 1=非常没用、2=比较没用、3=比较有用、4=非常有用” 4个等级按照重要性进行打分, 计算占比作为权重, 获得a、b、c、d的权值分别为1/4、1/2、5/4、3/2。通过其获得每条评论的UsefulScore。
根据4.2节的方法获得分词结果后, 使用Java语言实现LDA概率模型。通过文献[21], 在Gibbs抽样时, 设置参数α =0.5、β =0.1和主题数K=6, 循环迭代抽样的次数设为100次。经过LDA聚类获取主题-词矩阵和评论-主题矩阵。其中LDA主题模型聚类(部分)结果如图2所示:
 | 图2 LDA主题模型聚类(部分)结果 |
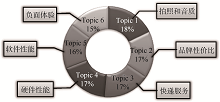
由图2不难判断出, Topic 1与手机拍照和音质相关; Topic 2与华为品牌及性价比相关; Topic 3与手机的快递服务相关; Topic 4与手机的硬件相关; Topic 5与手机软件相关; Topic 6与负面消息相关。
LDA聚类的评论-主题概率分布矩阵(部分)如表1所示。ID表示评论的编号, 文章展现的是ID≤ 8的评论的概率分布。
| 表1 评论-主题概率分布矩阵(部分) |
利用评论集合包含的所有评论中主题混合成分权重的加和来衡量不同的主题在整个评论集中的重要程度, 由公式(5)可以分别获得6个主题的重要程度, 如图3所示。其中Topic 1到Topic 6的重要程度的计算值分别为18%、17%、17%、17%、16%、15%。
在每个主题下对应有每个评论的主题概率, 如表1所示。对主题下的评论进行筛选, 经过多次试验验证, 选取主题概率大于0.33的评论作为主题下的评论, 筛选结果如表2所示。
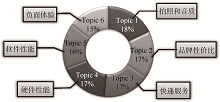 | 图3 主题重要程度分布 |
| 表2 各主题下评论数 |
利用LexRank算法计算同一主题下每条评论与其他评论的相似度, 获得每条评论的LexRankScore值, 并抽取每条评论对应主题下的主题概率值TopicScore和消费者有用性投票的加权值UsefulScore。利用公式(6), 通过每条评论的LexRankScore、TopicScore、UsefulScore三个衡量评论质量的属性, 计算出每个主题下每条评论的得分。
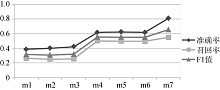
为确定适合模型的α 、β 、γ 参数, 实验中采用常用的准确率(P)、召回率(R)和F1指标进行考察, 准确率为文本分类模型的准确性评估指数, 召回率是对模型查全程度的评价, 而F1则是对准确率和召回率的综合考虑。公式[22]如下:
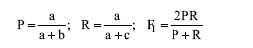 |
其中, a表示模型推送给用户且用户满意的数目, b表示模型推送给用户但是用户不满意的数目, c表示用户满意但是模型没有推送的数目。
为使得实验更客观, 采用多人判断法, 取平均准确率、平均召回率和平均F1。将三个参数的取值情况用m向量矩阵表示m={m1, m2, …}, 其中mi=(α i, β i, γ i)。图4显示了部分典型参数下模型P、R、F1值的比较结果, m1=(1, 0, 0), m2=(0, 1, 0), m3=(0, 0, 1), m4=(1/2, 1/2, 0), m5=(1/2, 0, 1/2), m6=(0, 1/2, 1/2), m7=(1/3, 1/3, 1/3)。
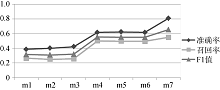 | 图4 实验参数选取 |
通过多次验证, 当α 、β 、γ 取值为1/3、1/3、1/3时, 效果最好。最后, 将每个主题下的评论按照得分排序, 考虑到篇幅原因, 选取每个主题排名前三的高质量评论, 结果如图5所示:
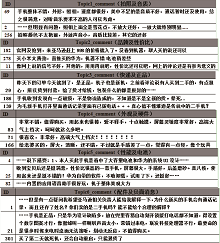 | 图5 Topic 1-Topic 6的高质量评论 |
综上所述, 各个主题Topic 1到Topic 6的重要程度的计算值分别为18%、17%、17%、17%、16%、15%。Topic 1是与手机拍照和音质相关, 通过其高质量评论可以判断在音质和拍照方面效果不太令人满意; Topic 2是与华为品牌及性价比相关, 通过其高质量评论可以帮助消费者判断出该商品的品牌和性价比具有较高的认可度; 同样, 通过Topic 3可以判断消费者对手机的快递服务持肯定态度, Topic 4可以判断出消费者对该款手机的硬件有较高的评价; Topic 5是与手机软件相关, 消费者对其评价好坏参半; Topic 6是与负面消息相关, 可以帮助消费者从另一视角了解商品, 同时对商家改进自身产品有很好的借鉴作用。这样, 消费者在阅读较少评论的同时, 能从各个方面了解商品的大致情况并通过不同主题的重要程度了解商品评论的侧重点, 从而节省消费者在购买决策过程中耗费的时间和精力成本, 对消费者做出购买决策具有较好的指导作用。
为客观验证模型的有效性, 从与原始网站排序对比和现有高质量评论挖掘方法对比两个方面进行比较分析。
(1) 与原始网站排序的对比
与原始网站排序的对比是从评论体验方面调查消费者是否可以更方便快速地定位到所需信息以及评论内容是否能够更有效地帮助消费者做出购买决策。
设计调查问卷将图3、图5及原评论链接通过社交平台发送给网络购物用户, 一共发放300份电子问卷, 有效回收 220 份问卷。与原评论排序作对比进行统计打分(非常满意为5分, 满意为4分, 一般满意为3分, 不满意为2分, 非常不满意为1分), 统计3分以上(不含3分)人数的占比, 结果如表3所示:
| 表3 问卷统计结果 |
调查问卷的统计结果显示, 在评论体验方面, 与原始网站排序相比, 有90.90%的人认为模型可以更快速地定位到关注点, 有95.45%的人认为该模型可以更有效地帮助做出购买决策。因此, 可以得知经过模型挖掘出的评论内容更能满足消费者的需求, 并对消费者做出网络购物决策的参考价值更大。
(2) 与现有高质量评论挖掘方法对比
同样采取多人判断法, 将本文模型与现有的两种高质量评论挖掘方法, 即基于决策树的预测模型[7]和非线性回归模型[8]方法进行性能比较, 结果如表4所示:
| 表4 模型性能对比 |
由表4可知, 本文模型的准确率高于其他两个模型, 召回率稍低于非线性回归模型, 但从F1值可以得出, 本文模型获取高质量评论的效果更好, 具有一定的优越性。
本文提出面向主题的高质量评论挖掘模型, 采用潜在语义分析的文本挖掘方法发现评论中形成的兴趣主题, 运用改进的自动摘要思想, 并将现有的有用性投票与其他权重指标相结合, 进一步自动提炼出每个主题下的高质量评论。
为客观验证模型的有效性和优越性, 从与原始网站排序对比和现有高质量评论挖掘方法对比两个方面进行比较分析。通过发放问卷的形式, 对模型结果进行客观网络调查。90%以上的消费者认为, 和原始评论相比, 经过模型挖掘出的评论内容能使消费者快速找到自己的关注点, 获得较高质量的评论信息, 对消费者的辅助决策效用更高。另外, 与现有高质量评论挖掘方法相比, 在综合考虑准确率和召回率时, 本模型在准确率更高的前提下, 更具优势。
但是, 本文仅与部分典型模型作对比, 因此未来研究中尝试将本文模型结果与多种典型模型方法的结果作对比, 进一步检验其准确性和优越性。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|