{kind=link}
汉语组块分析在产品特征提取中的应用研究
[杜思奇1  , 李红莲
, 李红莲1 , 吕学强2 ]
, 李红莲|
|


作者贡献声明:吕学强: 提出研究命题; 杜思奇: 提出研究思路, 设计研究方案, 分析数据, 起草论文; 李红莲: 论文修订。
目的 解决用户评论文本中的产品特征提取问题, 尤其是名词性短语的识别问题。方法 利用汉语组块分析进行产品特征提取, 根据Apriori产生频繁项集以及TF-IDF阈值对候选产品特征进行过滤, 得到产品特征集合, 从而实现对用户评论中产品特征的自动提取。结果 为验证该方法的有效性, 以汽车评论文本为例, 从中提取汽车类产品的特征, 平均召回率达到76.89%, 平均准确率达到84.03%。【局限】该方法的召回率较低, 存在名词块识别错误的问题。结论 实验结果表明引入汉语组块分析可以准确识别名词性短语, 提高产品特征提取的准确率。
[Objective] This paper aims at the problem of product feature extraction, especially the noun phrase identification.[Methods] Chinese Chunk Parsing is used to extract the feature, and frequent sets are generated by Apriori. Then the candidate product features are filtered according to the rules of the minimum support, frequent nouns and TF-IDF. At last, the final product feature sets are obtained.[Results] In order to verify the effectiveness of the method, the car reviews are used in this paper, the average recall rate reaches 76.89%, the average precision rate reaches 84.03%. [Limitations] The recall rate is low and there is noun phrase identification error in the test.[Conclusions] Experiment results show that the method can extract product feature from Chinese reviews with good effects.
近年来, 互联网技术和电子商务的不断发展给企业的业务流程和消费者的购买行为带来了深刻的影响[1]。如何挖掘出用户在线评论中的有用信息成为电子商务领域关心的问题。
产品特征是潜藏在用户评论中的产品性能的描述性信息, 通过产品特征, 可以使用户和生产商迅速了解产品的主要特点, 例如汽车类产品的产品特征包括: 油耗、内饰、做工、颜色、性价比等。提取评论中产品特征的方法主要分为人工定义和自动提取两种。人工定义依靠人工找出评论中出现的产品特征, 建立产品特征集合。姚天昉等[2]利用本体构建汽车类产品的概念图, 并对汽车类产品的特征进行提取。娄德成等[3]利用特征词表提取汽车类产品的特征及评论。Shi等[4]利用人工定义的层次概念模型对中文评论文本进行研究。虽然人工定义的方法相对简单, 但是需要耗费一定的人力; 另外, 这种方法的可移植性较差。因此更倾向于使用自动提取的方法。自动提取依靠自然语言处理提取名词性成分。Hu等[5]利用关联规则实现产品特征提取。Popescu等[6]改进了Hu等[5]的方法, 并利用MPI算法过滤停用词。伍星等[7]利用弱监督学习算法对数码相机提取产品特征。李实等[8]结合汉语中名词性短语的表达特点实现数码类产品的特征提取。
从句法分析角度, 产品特征不仅可以由名词描述, 还可以通过名词性短语描述, 这些名词性成分共同构成产品特征。仅仅依靠词法分析很难准确识别评论文本中的名词性成分, 需要依靠句法分析进一步研究。
在总结现有的产品特征提取方法的基础上, 本文引入汉语组块分析, 利用汉语组块分析识别名词性成分, 利用Apriori算法产生频繁项集, 利用TF-IDF方法过滤停用词, 从而实现评论文本中产品特征的提取。为了验证该方法的有效性, 以汽车类产品评论为例, 进行产品特征提取, 提取流程如图 1所示。
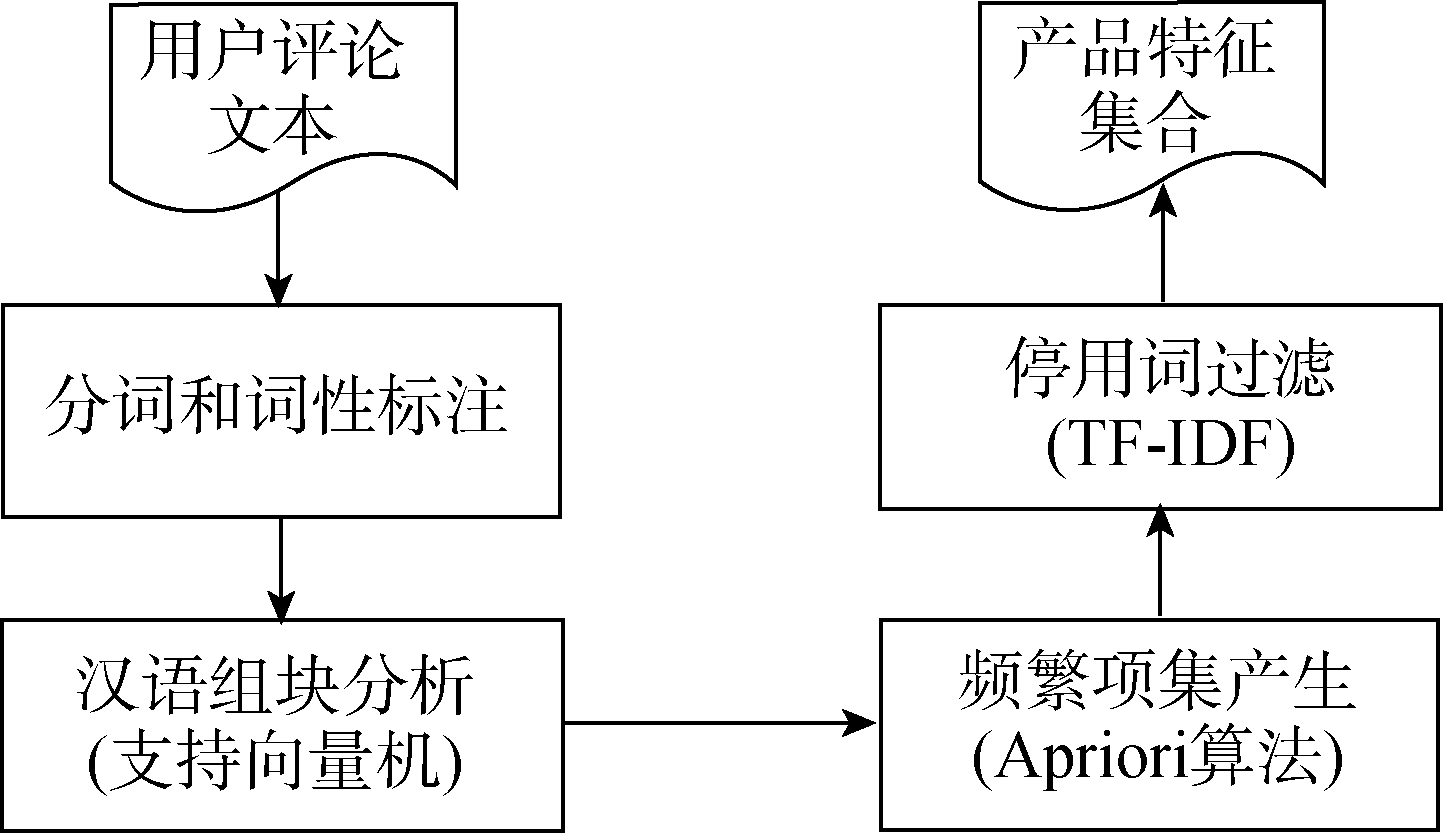 | 图1 基于汉语组块分析的产品特征提取流程 |
组块分析是一种句法分析。它既可以作为自然语言处理系统中分析句法功能的子任务, 也可以作为词法分析过渡到句法分析的一座桥梁[9]。汉语组块分析针对经过预处理的词语序列, 分析后主要产生两部分信息— — 词界块: 将相同成分的词语序列划分在同一个块中, 形成连续的词界块序列; 块成分标记: 为每一个汉语块赋予一个块成分标记。可见, 进行汉语组块分析首先要确定汉语块标记。本文主要采用的汉语块标记如表1所示:
| 表1 汉语组块成分标记集 |
其中, 名词块描述的是评论文本中的名词性成分信息, 本文依靠汉语组块分析识别名词性成分。
目前应用于汉语组块分析的机器学习算法主要有隐马尔科夫模型、基于记忆的机器学习、基于转换的机器学习、最大熵[10]等。本文利用台湾大学资讯工程系提供的LibSVM工具箱(http://www.csie.ntu.edu.tw/~cjiin/libsvm/.)进行汉语组块分析。
汉语文本组块, 实际上就是输出一组汉语块序列。例如, 对于评论文本“ 空间足够大, 空间利用率比较高!” , 利用中国科学院计算技术研究所分词软件ICTCLAS(http://ictclas.nlpir.org/.)处理该评论文本, 输出结果为“ 空间/n 足够/v 大/a , /w 空间/n 利用率/n 比较/d 高/a !/w” 。再对经过上述预处理的评论文本做汉语组块分析, 输出结果为“ 空间/n [ap 足够/v 大/a] , /w [np 空间/n 利用率/n] [ap 比较/d 高/a] !/w” 。其中, “ 空间” 和“ 利用率” 两个名词在句子中构成名词性描述信息, 因此这两个名词进行组块就形成名词块“ [np 空间/n 利用率/n]” 。
支持向量机作为一种有监督的机器学习算法, 必须由使用者提供一系列特征作为分类依据。将评论文本上下文不同位置出现的词(w)、词性(t)以及组块类别标记(c)作为组合特征训练支持向量机模型。这样分类模型x就可以由12个特征表示, 如下所示:

其中, i为当前位置, i-1为前一个位置, i+1为后一个位置。
为解决数据集不均衡的问题, 本文采用一对一分类方法。另外, 选择多项式核函数(Polynomial Kernel Function)使分类器在高维空间具有更好的泛化能力。
经过汉语组块分析后, 每一条评论文本可以形成类似“ 空间/n [ap 足够/v 大/a] , /w [np 空间/n 利用率/n] [ap 比较/d 高/a] !/w” 的汉语块序列。根据汉语组块分析的特点, 能够描述产品特征的主要有如下两类名词性信息:
(1) 名词块: 通过汉语组块可以将某一名词以及其附属修饰信息嵌入到同一个汉语块中, 例如: [np 空间/n 利用率/n]。
(2) 自由名词、动名词: 这类信息指在汉语块外的名词以及动名词, 这些名词性信息同样具有描述产品特征的功能, 例如: 小句序列“ 空间/n [ap 足够/v 大/a]” 中的名词“ 空间” 。
基于以上分析, 本文要对经过组块分析后文本中出现的名词块和自由名词、动名词进行提取。通过这样的方法, 可以对评论文本进行初始化处理, 再从初始化集合中找出用户评论的对象, 并进行停用词过滤。
计算机无法自动识别某一个名词性信息是否为产品特征, 但是基于“ 评价对象会在评论文本中重复出现” 的假设, 通过Apriori算法寻找构成频繁项集的产品特征是合适的。在文献[5]的基础上, 本文结合支持度计数对初始化集合进行剪枝, 从而寻找频繁项集。
项集和支持度计数是Apriori算法的重要参数。由于本文所使用的语料是评论文本, 因此项集X可以定义为: 经过汉语组块分析后得到的初始化集合。事务集合T定义为: 从网络上下载的用户评论集合。其中一条用户评论可以计为 ti(1≤ i≤ n), 因此T={t1, t2, · · · , ti, · · · , tn} 。项集的一个重要属性是支持度计数, 支持度计数可以表示为[5]:
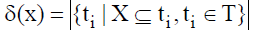
支持度用来衡量给定项集的频繁程度, 因此可以用支持度删除频繁程度较低的项集。支持度可以用如下公式计算:

其中, X和Y是互不相交的项集, 即X∩ Y=φ , N为用户评论的词条个数。通过设定最小支持度(Minimum Support, Min_Support), 在事务集合中搜索项集, 其中满足最小支持度的项集称为频繁项集。
利用Apriori算法在上一步生成的初始化集合中搜索频繁项集作为候选的商品特征集合。本文采用的最小支持度阈值为[1%, 5%], 并利用这个阈值过滤非频繁项集。通过Apriori算法得到频繁项集, 并将其作为候选的产品特征。由于频繁项集中还包含许多的非产品信息, 因此还需要对该集合进行停用词过滤, 才能得出最后的产品特征集合。
停用词在产品特征提取中指候选产品特征集合中的非产品特征的名词。通过观察候选产品特征集合, 这些停用词主要有以下三类: 商品品牌名称, 例如: “ 众泰” 、“ 别克” 、“ 雪佛兰” 等; 口语化名词, 例如: “ 车子” 、“ 这款车” 、“ 这辆车” 等; 人称名词, 例如“ 朋友” 、“ 同事” 、“ 老公” 等。
为了得到最终的产品特征集合, 需要利用相应的过滤算法过滤掉这些名词。TF-IDF(Term Frequency- Inverse Document Frequency)是在资源勘探领域常用的加权技术, 常用于文本特征权重计算[11]以及文本分类[12]等任务中。本文结合停用词的特点利用TF-IDF过滤频繁项集中的停用词, 从而保留重要的产品特征。
TF-IDF的计算方法[11]如下:

其中, ni, j是某个检索词在文档dj中出现的次数, 而 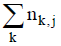
通过观察非产品特征及其TF-IDF值, 发现绝大多数的非产品特征的TF-IDF值在0.003以上, 因此本文以0.003作为过滤阈值, 对候选产品特征集合进行过滤后可以得到最终的产品特征集合。
汽车之家网站①(①http//www.autohome.com.cn/.)是互联网汽车销售平台, 为汽车消费者提供专业的购车服务信息。本文采用汽车之家网站提供的汽车类产品评论语料, 分别对4款车型进行实验, 包括众泰T600(SUV)、别克GL8(商务车)、通用雪佛兰-赛欧(小型轿车)以及长安欧诺(微面)。其中每款汽车的评论语料包含400条评论。
通过人工标注的方法得到上述4款汽车的产品特征集合, 以众泰T600为例, 产品特征集合如表2所示。
| 表2 众泰T600的产品特征 |
本文采用准确率(P)和查全率(R)评价实验效果。与文献[8]结果进行对比, 如表 3所示:
| 表3 对比实验结果1 |
通过表3可知, 在本文获取的评论文本上进行实验, 本文方法和文献[8]的召回率相接近; 但是由于本文采用机器学习的方法识别名词性信息, 所以在准确率上明显高于文献[8]。
通过第一组对比实验可知, 利用统计的机器学习算法处理语言信息是可行的; 由于评论文本中语言风格的多变, 仅仅依靠语言规则识别名词成分很难达到较高的准确率。由于文献[5]和文献[6]的方法在产品特征提取领域具有一定代表性, 因此本文再与其进行对比实验, 结果如表4所示:
| 表4 对比实验结果2 |
第二组对比实验中, 本文方法的平均召回率略低于文献[5]的方法, 平均准确率优于文献[5]和文献[6]。因此, 本文方法可以在保证一定召回率的情况下得到较高的准确率。文献[5]通过计算名词之间的距离判断能否构成名词性成分, 并通过无监督的机器学习算法寻找频繁项集, 利用停用词词表过滤停用词; 文献[6]在文献[5]的基础上改进了过滤停用词的方法, 利用MPI过滤停用词。本文利用组块分析识别名词性成分, 通过TF-IDF过滤停用词。实验结果表明, 依靠组块分析可以充分考虑句子的上下文信息, 有利于识别名词性成分。因此本文所使用的方法在平均准确率上优于经典文献所采用的基于词法分析的方法。
实验结果表明, 汉语组块分析有利于产品特征的提取。由于本文采用的评论语料来自不同车型, 从结果中可以挖掘属于它们各自的私有特征, 例如: 疝气大灯(众泰T600)、中外合资(通用雪佛兰-赛欧)、商务性(别克GL8)、能拉人能拉货(长安欧诺)。
本文引入汉语组块分析, 结合支持向量机、Apriori算法获取频繁项集、TF-IDF停用词过滤进行产品特征识别。实验结果表明, 本文方法的准确率较高, 同时召回率也保持了较高的水平, 说明本文方法是有效的。今后, 将结合汉语组块分析的产品特征对评论文本中的情感倾向性以及评论文本中情感标签的提取进行相关研究。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|