
{kind=link}
{kind=link}
文献关键词链接标引方法研究
[许德山1 , 李辉2 , 张运良1  ]
]
]
|
|


作者贡献声明:许德山: 提出研究思路, 设计研究方案, 编写服务接口和标注程序, 论文起草及最终版本修订; 李辉: 实验数据的采集、清洗、标注, 实验结果分析;张运良: 领域词系统内容组织、词典到本体格式的转换。
目的 以本体管理与服务平台为基础, 利用三元组获取和自然语言处理技术实现中文科技文献的自动标引。方法 通过Web Services接口将本体知识库和词汇资源集成到标注模块中, 利用词典匹配和分词组合方法分别获取文献中的领域词和未登录词, 并与本体知识库中的三元组建立链接, 形成领域概念关系网络。结果 通过语料测试, 系统能以86篇/秒的较快速度进行文献标引和词汇链接, 并达到65%的全面率和69%的准确率。【局限】词典加载后未做索引, 匹配计算耗时过多, 空格、断行等噪声数据对文本的分词处理和词性判断产生影响。结论 数据清洗流程和关键词筛选算法改善后, 可以进一步提高标引效率, 为深度挖掘文本提供支撑。
[Objective] Build an auto-indexing system by triple acquirement and NLP for Chinese scientific and technical literatures based on Ontology management and service platform.[Methods] Merging Ontology knowledge bases and vocabularies by Web services, the system can identify the terms and unlisted words through matching vocabulary and words combination, as well as link them with the triples in the knowledge bases for building a conceptual relational network.[Results] This system can process 86 articles per second with recall rate of 65% and precision rate of 69%. [Limitations] It takes a lot of time to match terms because no index is built. The performance of Chinese word segmentation and POS tagging are influenced by the noise data such as spaces, line break, and so on.[Conclusions] Data cleaning process and algorithm optimization of keywords selecting need continuous study for supporting the deep mining and enhancing the efficiency of the system.
关键词是表达文献主题意义的最小单位, 是实现文献检索和主题定位的基础。关键词的标引工作已成为文献加工流程中的重要环节, 自动摘要、自动分类以及知识发现等应用, 都必须在关键词提取的基础上进行。文献关键词标引通常采用人工方式从主题词表中选择词汇进行标引, 这种方式能够较为精确地反映文献的主题内容。国外的一些机构、组织和高校开展了广泛的研究工作, 并开发了一些实用的标注工具, 如英国开放大学研制的Magpie[1]、德国卡尔斯鲁厄大学开发的CREAM[2]以及由W3C研究开发 Annotea[3]等系统为人工标引提供了方便, 但其自动化程度不高, 只能辅助标引人员完成一些标签的选择。人工标引系统受标引人员自身领域知识结构的影响较大, 面对领域广泛的海量网络文本, 人工标引系统无法满足应用需求。随着学科的细化和研究的深入, 新产生的科技文献越来越多, 依靠传统的标注方法仅能以篇章为单位进行文献检索, 使得用户从文献中获取所需的信息越来越困难。近年来, 语义网和数据链接技术的蓬勃发展为文献关键词标注研究带来新的思路, 陆续开发了自动、半自动的语义标注工具, 如Ontotext研究室开发的Semantic Platform[4]系统、IBM公司开发的SemTag[5]系统以及AKT项目成果Armadillo[6]系统, 采用本体和机器学习完成领域文本的自动标注。此外, 英国谢菲尔德大学开发的GATE[7], 德国卡尔斯鲁厄大学开发的Text2Onto[8]等工具集合了词汇发现、关系挖掘、本体构建以及语义标注等功能, 为英文关键词提取和标引提供了技术手段, 在英文文本的深度挖掘和内容分析领域得到广泛应用。
由于中文和英文在句子结构和词汇使用上的差异性, 这些标注工具无法直接用于中文关键词的标注。为此, 国内科研人员在分析英文系统的基础上开展了中文关键词标注研究。马颖华等[9]提出以“ 汉字” 为基本处理单位, 利用不同汉字的共现频率筛选文本主题词。耿焕同等[10]以词频统计为基础, 利用词共现形成的主题信息以及不同主题间的连接特征对词汇进行标注, 提取一些频率适中但对主题贡献较大的词表达作者的写作意图。索红光等[11]将文本中的词汇组成词汇链, 结合词频、区域特征等抽取关键词。随着研究的不断深入, 一些高效的机器学习算法和模型也被引入到文本关键词的抽取和标注工作中。李素建等[12]利用最大熵模型实现了关键词自动标引系统, 赵鹏等[13]借鉴复杂网络构建文章语言网络, 通过分析中文语言网络的“ 小世界” 特征, 将网络中具有较大关联度和聚集系数的词汇抽取出来, 作为文献关键词。这些早期的研究大多采用机器统计学习和自然语言处理两种主流技术, 实现思路较为单一。近期的研究实践中, 研究者更倾向将知识组织方法与传统技术相结合, 充分利用各种技术的优势。例如段宇锋等[14, 15]实现的植物学领域概念语义标注系统, 利用自主学习规则与先导词相结合的算法提取领域关键词。罗军等[16]将机器学习算法融入到领域知识框架中, 通过学习知识库中的相关模式, 采用Bootstrapping算法提取文本关键词。米杨等[17]将多个本体进行整合, 通过顶层本体的控制完成医学文献的标注。这些系统都在不同程度上使用了人工建立的本体, 其内部结构较为简单, 由于缺少大量的实例填充, 词汇间的知识关联难以建立, 主要用于展示标注内容的上下位关系。为了实现中文关键词的语义标注和知识链接, 向用户提供资源服务, 本文尝试将本体服务平台内部丰富的概念关系和领域词典集成到标引模块中, 通过概念匹配和分词组合方法将文本中的关键词与知识库中的三元组建立链接, 形成领域概念关系网络, 为文献内容的深度分析和知识抽取提供底层支撑。
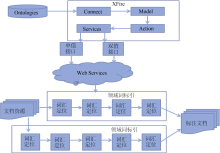
本文实现的科技文献关键词标引和链接系统主要由领域知识资源组织和关键词识别两个模块组成。文献关键词的标引和链接离不开知识库和领域词典的支持, 为了实现领域知识的关联和组织, 笔者开发了本体管理与服务平台, 该平台集本体管理、发布、检索和服务于一体, 旨在为已创建的各种本体资源提供一套规范化的管理方式, 并通过统一的服务接口供外部用户使用[18]。通过使用管理平台提供的服务功能, 关键词标引模块根据标引类型获取所需的词汇和语义资源, 从而实现文献关键词的标引和链接。整个标引系统的体系结构如图1所示:
 | 图1 关键词标引和链接系统的工作流程 |
本体管理平台中注册了“ 新能源汽车” 、“ 新一代工业生物技术” 、“ 智能材料与结构技术” 、“ 重大自然灾害监测与防御” 以及“ 新能源” 等多个领域本体, 每个文件大约含有5万个领域概念。由于单个本体提供的关联信息有限, 管理平台通过分析概念的结构和形式信息, 将多个本体中相同或相似的概念建立语义链接。管理平台除了提供本体信息的注册和检索功能外, 还设计了Web Services接口方便用户进行二次开发和嵌入式调用。关键词识别模块利用本体管理平台提供的词汇资源识别文献中的领域词, 再通过分词处理和词性组配技术实现未登录词的标引。
本体知识库中概念、属性、关系、约束条件构成了领域知识框架, 虽然这些元素的语义特征并不相同, 但其内部的知识结构都可以转化为关系三元组和属性三元组。关系三元组描述了各种概念间的语义联系, 属性三元组则用来对概念具有的个性特征进行说明。知识框架经大量的实例填充后, 实例概念间通过“ 主语-关系-宾语” 三元组和“ 主语-属性-取值” 三元组产生联系, 形成彼此相连的知识网络。这些相互关联的三元组构成了本体知识库中的最小知识单元, 是进行语义推理、关系发现和相似度计算的基本单位。由于标引的领域词汇来源于本体知识库, 知识库中的概念又通过三元组产生各种关联, 因此文献内容经过标引处理后, 这些领域概念便与科技文献中的关键词建立链接, 从而形成具有语义关系的文献概念网络, 可以为文献主题内容的深度挖掘提供支撑。
本体管理平台充当服务提供者, 其内部操作方法通过Xfire服务代理发布为Web Services接口。整个服务处理流程由Action、Model、Connect和Services模块组成, 其中Action模块负责检索流程的控制和转发; Model模块负责后台数据封装和检索模型的生成; Connect模块负责知识库的初始化和连接等操作; Services模块负责将用户输入的各项检索条件映射为SPARQL表达式, 并将检索结果进行重组形成关系模型。Services模块由两个内部接口以及一个服务接口组成。由于用户使用SPARQL语句的查询习惯、构造字段不尽相同, 内部接口又分别提供单值查询接口和双值查询接口。单值查询接口封装“ findAllProperty” 、“ findAllRelation” 、“ findAllClass” 和“ findAllIndividuals” 4种功能, 双值查询接口封装“ findSubjectAndPredicate” 和“ findPredicateAndObject” 功能。Web服务接口功能的详细情况如表1所示:
| 表1 Web服务接口的功能 |
前端服务接口生成“ select ?x where {?x ?p ?y}” 类型的查询语句时, Action模块将检索需求转向单值服务接口并根据检索条件选择相应的功能调用。本体管理平台使用Sesame本地知识库存储三元组, 在检索匹配前Connect模块会完成Sesame知识库的连接操作; Model模块将这些知识三元组读入内存形成完整的概念网络模型; 将检索表达式导入Model模块中完成需求匹配。如果前端服务接口生成“ select ?x ?p where {?x ?p ?y}” 或“ select ?p ?y where{?x ?p ?y}” 形式的表达式, Action模块将调用双值服务接口, 并在Connect、Model等模块的协助下完成需求匹配。
用户在进行服务调用和二次开发时, 只需和本体管理平台的外部Services接口进行交互, 关键词标引系统在实现文本标注和词汇关系展示时嵌入了Services接口提供的各种功能。
标注模块旨在利用领域词典和术语识别技术将体现文档主题的概念单元抽取出来, 为信息检索、知识导航以及知识进化等模块提供支持。文本词汇标注分为领域词识别和未登录词识别两个子模块。
领域词的识别离不开外部词典的支持, 利用本体管理平台提供的Web Services功能可以辅助完成这一工作。本体文件的内容描述通常与一个特定的领域有关, 其内部的概念节点和关系构建了领域知识框架。一个新的本体文件添加后, 知识库将以本体URL为命名空间生成存储文件, 同时将概念类、类间关系和属性等结构信息以三元组的形式存储到领域知识库中。当启动标注功能后, 系统利用Web服务接口获取注册本体中的所有概念词汇, 形成领域词典dictionaryList, 利用领域词典完成领域词汇的标注。领域词匹配的步骤如下:
(1) 词汇定位: 遍历词典dictionaryList, 查找词汇在文本中的开始位置, 将其位置信息存入termList列表中并标记为“ DomainTerm” 类型。
(2) 文本截取: 以“ 词汇开始位置+词汇长度” 为起点, 截取剩余文本作为匹配文本。再次遍历词典, 完成词汇的匹配和位置计算, 直到词典中所有的词汇遍历完毕。
(3) 词条筛选: 遍历termList列表, 如果有词汇的起始位置处于另一个更长的词汇之内, 则去除较短词汇在termList列表中的信息, 保留较长词汇的信息。
(4) 语义关联: 通过Web Services接口访问本体管理平台, 将本体三元组中的相关概念与领域词汇建立关联, 并将所有标注信息保存到数据库中。
(5) 词条标记: 查找数据库, 获取词汇的起始位置, 将位置信息传到前台页面并高亮显示。
由于领域词典的收词范围受选词标准和时效性影响很大, 其收词通常无法全面覆盖和反映整个领域的最新动向, 这些未登录词需要通过关键词识别算法进行筛选。关键词识别模块主要负责词性标记、词汇筛选、词汇组配、同句判断、位置判断等操作, 其主要运行流程和功能如表2所示:
| 表2 未登录词的识别方法 |
词性标注是文本处理的首要任务, 经过处理后输入的文本被拆分为由单个词汇和符号组成的字符串集合。由于分词软件大多采用通用词典, 许多词汇的切分粒度比较小, 而科技文献中使用的领域词汇专指性强, 长度较长, 因此需要将分词后的文本按词性搭配规则进行组合, 形成具有领域特点的较长关键词。利用词汇的搭配和构成规则, 能够将文章中大量专指度较强的候选词汇抽取出来。通过分析可以发现: 领域关键词通常由名词、形容词、副词、介词等搭配而成, 另外还有少量的关键词由动词和其他词汇构成。文档处理过程中利用了一些具有特殊意义的标点符号, 如“ , ” 、“ .” 、“ ?” 、“ !” 等对句子进行分割, 以确保词汇序列的组合范围不会跨越两个不同的句子。文本经过分词和组合后, 形成以向量形式存储的词汇列表, 每个词汇向量含有该词汇的词性、文档编号、位置等信息。初步筛选的词汇列表含有部分领域词汇, 需再次与词典进行匹配, 去除领域词汇后将剩余词汇标记为“ NewTerm” 类型的未登录词, 并将所有标注信息保存到数据库中。
为了测试系统的运行效果, 笔者对64 121篇新能源汽车领域的文献进行标注处理。标注结果在页面中以不同的颜色进行显示, 领域词为绿色, 未登录词为蓝色。标注效果如图2所示:
 | 图2 关键词标注效果示例 |
绿色的领域词汇通过超链接与本体三元组关联, 用户点击领域概念后, 系统在注册的领域本体中进行查找, 将命中的本体文件返回给用户, 用户确认概念所属领域后, 系统通过Web Services接口向本体库发送检索需求获取语义三元组, 并以输入概念为核心生成关系模型。两个概念间的明确联系可以直接利用三元组进行表示, 输入词和词间关系分别映射为节点和关系弧, 并以该输入词汇为中心元素向外辐射, 形成关系网络。当点击选中的外围节点时, 处理程序会以当前节点作为中心探测与之相连的各种关系, 通过环形的布局算法将树图转换为圆环结构, 其中根节点为中心节点, 关系节点分布在外围的圆环上。图形化界面中的词汇关系以不同的颜色进行分类, 颜色相同的词之间的关系属于同一大类。整个文档集合在服务器上完成标引测试, 服务器的基本配置为: CPU为AMD Athlon™ II× 2 B26 Processor 3.20GHz, 4GB内存, 32位Windows7系统。标引系统的运行情况如表3所示:
| 表3 标引效率 |
标注系统平均每秒可处理86篇文献, 通过监测程序发现, 整个标引过程中领域词的匹配计算耗时较多。系统从本体管理平台获取2万余条领域词汇, 由于标引过程中64 121篇领域文献需要依次与词典中的每个词汇进行匹配, 同时计算词汇的位置信息, 导致部分文献的标注时间较长。
标注模块还提供了主题词推荐功能, 根据词汇的篇章位置对标注词汇赋予不同的权重, 出现在标题中的词汇给予较大的主题词权重, 其他在正文中出现的词汇按位置重要度以及是否来自词表等指标进行综合计算, 所有词汇按权重大小排序后作为候选词, 并根据用户提供的筛选数量返回页面。为了检验系统的标注性能, 笔者从语料库中选取50篇文献分别进行机器标注和人工标注, 并通过全面率、准确率以及F调和平均值分析标注效果, 详细信息如表4所示:
| 表4 标注性能 |
通过对50篇文献中的关键词进行处理, 标注系统筛选出250条关键词, 人工方式筛选出381条关键词。以人工标注的词汇作为基准, 经对比分析可知: 标注系统具有65%的全面率和69%的准确率, 其综合性能在66%左右。
关键词标注和关联是文献加工流程中的重要环节, 也是进行文本内容深度分析和挖掘的基础工作。本文利用本体管理平台提供的服务功能, 实现科技文献领域词和未登录词的自动标引。采用Web Services为系统开发带来了便利, 通过访问服务接口, 标引系统不但可以使用本体管理平台提供的词典资源还可以与本体知识库中的三元组建立语义链接, 将文本关键词的各种联系和属性描述进行展示, 方便用户了解整个领域的知识结构。
语料库中文献的来源复杂多样, 大量的领域文献由PDF和HTML格式转化而来, 文本中存在一定的断句、空格、分行以及特殊符号, 这些噪声数据对文本的分词处理和词性判断产生影响, 后期将考虑对加载到内存中的领域词典和三元组列表构建索引, 并采用功能更强的PDF和Web文本抽取工具完成语料库的清洗, 通过改善词典和三元组的匹配效率以及文本抽取质量, 提高标引系统的准确率和运行速度。另外, 在分析和统计机器标注效果时, 受主观认识和知识结构个体差异的影响, 很难给出一个绝对词汇筛选标准。另外, 虽然科技文献由大量的领域词汇组成, 但仅在词汇层面上进行无序的离散排列无法表示出文献论述的主旨, 需要从句子层面对概念进行组织, 通过概念间的语义组合形成语义块, 从更宏观的层面把握文献主题。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|