




1 引 言
城市地名是城市数据画像的重要标记和参照点, 也见证了城市的变迁, 蕴含着城市的文化创意。自从20世纪60年代开启城市数据画像研究以来, 城市地名就是城市画像最为重要的研究对象。最初MIT城市规划大师Lynch采用绘制认知地图方法绘制了美国波士顿、泽西城和洛杉矶三地的城市画像[1], 而城市画像构成的重要要素之一就是城市地名标识。其后一段时间内, 城市画像内容都被限定为城市观察者的所见事物, 侧重构筑城市的实体环境, 忽略公众对城市的非物质认知, 此时城市地名代表的是地理标识, 个体间认知也趋于城市地名原本的含义; 20世纪80年代后期城市画像关注到了城市系统的社会属性, 城市画像构建与分析方法也由实体层面的认知分析拓展到心理层面的认知分析, 此时城市地名代表的不再仅仅是地理标识, 更多代表了个体认知地图中的心理标识[2,3]。进入21世纪, 随着移动社交媒介平台的发展, 城市地名作为重要的标签资源被广泛应用, 成为彰显城市地理及人文特色的重要媒介[4,5], 此时城市地名并没有更深层次内涵的延伸, 但利用城市地名构建城市画像的方法却得到了极大拓展。大规模在线数据既为城市画像提供了大数据分析的途径, 也对资源保管及利用提出了挑战, 如何从这些数据资源中发掘出有意义的地名实体并建立地名实体之间的横向联系已然成为实体分析领域重要的研究命题[6]。
城市地名实体是现实世界城市地名在信息世界中的转换结果, 是从文本等语料中提取的有意义的地理名词。但在实际研究中, 地名实体识别只是地理信息分析的基础工作, 在依序识别出特定对象某段时间所处地理位置后, 还可建立不同情景下不同对象的轨迹链, 轨迹链本质上就是不同地名实体的序贯组合, 通过位置网络建模及演化分析手段可探究特定对象的移动规律, 再结合对象自身属性信息来追踪和揭示群体行为[7]。不同对象轨迹链链条之间关系的建立和延伸都反映了观测对象在进行路径选择过程中的心理活动, 但少量轨迹链无法从统计意义上判别观测对象进行路径选择时的偏好[8], 因此笔者选择从城市线路文本中抽取城市地名实体, 形成轨迹链集合, 然后以该集合为统计样本, 计算城市地名实体双向链接概率, 进而在旅游者依据地理实体提出相应路线诉求时, 可以较快为其推荐出可行的备选路线集合及其推荐指数。
2 研究现状及思路
目前国内路线推荐研究主要集中于计算机科学领域和信息资源管理领域[9], 计算机领域侧重对推荐模型[10]、推荐算法[11]、推荐方法在特定场景(尤其是移动场景)下的应用效果等[12]内容进行细化研究, 而信息资源管理领域则多从地理信息分析、旅游信息资源规划[13]、推荐系统原型设计等[14]角度进行解析。相比国内, 国外路线推荐研究起步更早, 提出了很多经典推荐算法, 国内推荐算法研究也聚焦于对这些经典算法效果和效率的改进。本文以WOS为资源库, 对计算机科学、信息与图书馆学领域的期刊论文进行关键词分析, 发现routing、efficiency、cloud computing、recommendation systems、algorithms等词出现频次较高且时间连续性较好, 国外路线推荐研究关键词时序分布如图1所示。
图1
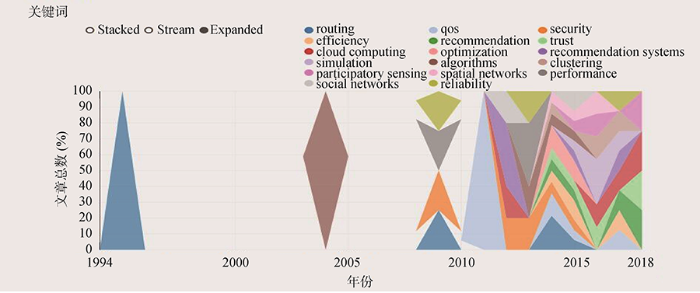
将这些词进行大致分类, 可看出国外路线推荐一方面重视融合新技术到推荐算法设计中, 如cloud computing、simulation、participatory sensing、qos、social networks、spatial networks、clustering等, 另一方面也在积极关注技术融合与结果推荐的效果, 如efficiency、optimization、reliability、security、trust、performance等。综合国内外路线推荐研究成果, 笔者发现过往研究偏重于推荐过程分析, 对用户需求表达及解析、多元化推荐策略设计关注不够, 同时匹配过程更多采用经典的推荐算法, 这些推荐算法有的是基于统计分析的推荐(如协同过滤), 有的是基于语义分析的推荐(如基于内容或知识的推荐), 两种推荐算法各有优劣, 本文试图引入模糊集合计算逻辑, 融合两类推荐算法, 设计基于城市地名实体双向链接分析的路线推荐模型, 模型框架如图2所示。
图2
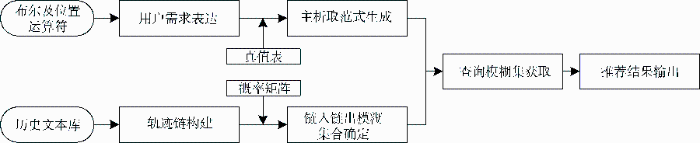
本研究采用信息检索模型的通用三元表达形式: 查询、文档及二者匹配算法。查询部分综合考虑布尔逻辑表达和位置运算符直接或间接设计表达式, 这种处理方式既考虑到查询主体的信息检索素养, 又与结构化文档对应的轨迹链形式相契合; 对文档的处理是对既往文本网络化有序化的过程, 涉及到地名实体抽取、地名实体链接概率计算、轨迹链构建等环节; 匹配算法部分引入模糊检索逻辑, 将原来的信息检索问题提升为自主学习预测模型的构建问题, 预测模型的基础训练集就是不断在扩展的轨迹链集合, 预测模型目标解是与查询相关度最高的轨迹链集合。
3 基于城市地名实体双向链接分析的路线推荐过程
基于城市地名实体双向链接分析的路线推荐研究主要包括轨迹链构建、地名实体链入和链出集合计算、基于链接分析结果的推荐策略研究三部分, 其中轨迹链构建为后续两部分提供了基础数据, 地名实体链入和链出集合计算用于测度任一轨迹链隶属于当前地名实体对应的理想集的程度, 基于链接分析结果的推荐策略则是在充分考虑用户需求的基础之上, 设计用户需求表达方式、需求与轨迹链的匹配算法和评价路线推荐效果。
3.1 轨迹链构建
轨迹链构建借鉴了事件链建模思想, 从文本中提取地名实体及其出现位置, 序贯相连就形成了轨迹链。轨迹链的最小组成单位为由相邻地名实体构建的有向三元组, 形式可以表述为$({{V}_{m}},{{V}_{n}},E)$, $Vm$表示前链, ${{V}_{n}}$表示后链, $G{{E}_{o}}\text{ AND (}G{{E}_{p}}\text{ OR NOT }G{{E}_{q}}\text{)}$表示${{V}_{m}}$指向${{V}_{n}}$的连边, $E$取值为0或1, 0表示前后链之间存在连接关系, 反之不存在连接关系。轨迹链中的最小单元允许多次重复, 此时$E$值则为重复连边累计之和。多个轨迹链中由某些相同地名实体连接, 形成地名实体的有向加权网络。但地名实体的加权网络与一般的节点加权网络还存在一定差别, 主要体现为:
(1) 地名实体的加权网络由轨迹链拓展而来, 其结构相对简单, 节点数目不多, 连通性一般; 而一般的节点加权网络结构与具体应用场景存在紧密关系, 往往较为复杂, 语义关系类型更多样, 且连通性较好;
(2) 地名实体的加权网络是对非结构化文本资源网络化组织的结果, 网络连接的基础建立在概率统计计算之上, 因此可在某种程度上用于推理及预测, 但随着历史数据的不断更新, 不同时间点推理及预测结果可能存在差别; 而一般的加权网络推理则基于事先定义好的语义规则(关系属性、公理、常识等)来实现, 因而较为稳定;
(3) 地名实体加权网络的推理服务于推荐和预测; 一般的加权网络推理则服务于知识管理[15]。不同轨迹链连接后形成的组织既可以表示为网络, 也可以描述为网络对应的邻接矩阵。为排除矩阵值绝对值计算对结果造成的影响并提升计算结果的收敛效率, 还需对矩阵进行归一化处理, 生成地名实体的概率矩阵。
3.2 地名实体链入和链出集合计算
地名实体链入和链出集合计算以3.1节生成的概率矩阵为基础数据源, 计算任意轨迹链隶属某个地名实体对应理想集的程度。该计算模式参考模糊集合计算逻辑[16], 模糊集合计算区别于简单的二值判定, 认为每个轨迹链可隶属于一个及以上地名实体对应的理想集, 也就是说每条轨迹链可与任意地名实体存在关联关系, 只是关联程度存在一定差异, 这种处理策略更符合用户进行路径选择时的心理认知, 默认初始状态下地名实体之间形成完全连通图, 随着历史轨迹链集合的不断丰富, 完全连通图中的某些路径由于不断被选择而得到强化, 有些路径则始终处于初始状态或缓慢强化的状态。
由于地名实体之间形成的网络是有向加权网络, 因此每个地名实体对应的理想集存在两个: 链入理想集和链出理想集, 对应的计算也分为链入理想集计算和链出理想集计算。前者是在${{V}_{n}}$已知的情形下, 计算某一轨迹链与${{V}_{n}}$对应理想集之间的隶属程度; 后者是在${{V}_{m}}$已知的情形下, 计算某一轨迹链与${{V}_{m}}$对应的理想集之间的隶属程度。隶属度计算方法如下: 定义与地名实体$G{{E}_{i}}$相关的链入模糊集合为$G{{S}_{i+}}$, 定义与地名实体$G{{E}_{i}}$相关的链出模糊集合为$G{{S}_{i-}}$, 对于任一轨迹链$G{{C}_{j}}$, 其隶属度值计算如公式(1)所示[17], 其中, ${{\mu }_{ij}}$表示隶属度大小,Cij表示概率矩阵中对应的数值。
计算差别在于当计算$G{{S}_{i+}}$时, 选择$G{{E}_{i}}$在概率矩阵中对应的列数值计算; 当计算$G{{S}_{i-}}$时, 选择$G{{E}_{i}}$在概率矩阵中对应的行数值计算。在计算中, 如果$G{{C}_{j}}$中的地名实体与$G{{E}_{i}}$有联系, 那么该轨迹链就属于与$G{{E}_{i}}$相关联的理想集。无论何时, $G{{C}_{j}}$中只要存在一个地名实体与$G{{E}_{i}}$有强联系(即概率矩阵中对应的数值为1), 那么${{\mu }_{ij}}=\text{1}$, 则可以认为$G{{E}_{i}}$对于$G{{C}_{j}}$来说是一个好的模糊索引。相反, 当$G{{C}_{j}}$中的所有地名实体都与$G{{E}_{i}}$几乎都没有联系时, 则认为$G{{E}_{i}}$对于$G{{C}_{j}}$来说不是一个好的模糊索引。模糊匹配算法及模糊索引的设计都将极大提升推荐效率和效果。
3.3 基于链接分析结果的推荐策略
基于链入和链出集合计算结果, 结合用户需求, 可有效实现路线的推荐, 目前在推荐领域应用较多的方法包括: 协同过滤、基于内容的推荐、基于知识的推荐、混合推荐等, 其中协同过滤是应用最为广泛的推荐算法[18], 但本文采用的推荐算法是融合模糊集合计算的改进协同过滤算法, 3.2节已对算法中的基础数据进行了有效组织与分类, 但如何表达用户需求并 实现需求与上述分类数据的匹配是实现路线推荐的 关键。
(1) 用户需求表达: 用户需求表达的常见方式有两种:
①用户结合自身规划, 选择部分关键地名实体作为检索标识点, 借助布尔运算符构建地名实体的逻辑表达式, 该表达式被提交到前端, 经过格式转换、模糊匹配、排序输出等流程实现备选路线的推荐, 这种需求表达方式有利于计算机处理, 但对用户端压力较大, 适合需求相对明确且具备一定信息组织与表达能力的用户。同时布尔逻辑表达无法实现地名实体间的排序, 因此必须要结合位置运算符限定地名实体之间的序贯关系, 实现更加精准的推荐结果。
②采用自然语言方式表达, 用户端压力相对较小, 但系统前端在原有处理流程的基础之上需要添加对自然语言文本地名实体识别及序贯关系判别的步骤。
两种方式面向不同场景下的用户需求表达而设计, 但其实二者的处理过程存在较多重叠部分, 布尔逻辑表达方式可以说是自然语言表达方式的子集。
(2) 模糊匹配: 在用户需求表达出来后, 还需要设计需求与轨迹链集合匹配的方式。在3.2节已经计算出轨迹链隶属于每个地名实体对应链入和链出理想集的数值, 这里接续描述后面的匹配方式。匹配的第一步需要将用户逻辑表达式进行数学转换, 采用方式为布尔逻辑运算和数学中主析取方式求解。无论哪一种方式表达的用户需求, 最终都要在前端转换为不同地名实体的布尔逻辑表达式, 该表达式通过真值表法可转换为不同地名实体形成的极小项, 但由于不同地名实体之间还存在序贯关系, 因此需要将极小项进行二次遴选, 在此假定通过地名实体识别后获取的逻辑表达式为$G{{E}_{o}}\text{ AND (}G{{E}_{p}}\text{ OR NOT }G{{E}_{q}}\text{)}$, $G{{E}_{o}}$、$G{{E}_{p}}$和$G{{E}_{q}}$代表被检索的地名实体, 为检索式中的原子, 求解该逻辑表达式的主析取范式, 该主析取范式全部由极小项通过OR连接而成, 极小项指代的是一个式子包括所有原子(含原子否定), 且原子之间AND相连的式子。求解步骤如下:
①列出检索式真值表, 每个地名实体在轨迹链中存在两种状态, 出现或不出现, 出现表示为1, 不出现表示为0, 示例中的地名实体有三个, 则共计8种排列组合形式;
②取出上述排列组合中表达式为真的记录, 析取极小项;
③所得主析取范式中的极小项中的原子是无序排列的, 此时还需要结合位置运算符对原子排序情况进行限定。
(3) 模糊结果输出: 逻辑表达式对应的模糊集合是所有与查询组件相关联的模糊集的并集, 这里的查询组件即为极小项, 其关联的模糊集即为极小项中每个地名实体对应理想集的交集, 因为每个地名实体都对应链入和链出两个理想集, 则在计算并集之前需要依照三种情况判别地名实体关联到哪一个理想集: 如果当前地名实体通过位置运算符设定了明确的位置关系, 则在前面出现的地名实体对应链出理想集, 在后面出现的地名实体对应链入理想集, 此时前后地名实体之间还可以有其他地名实体; 如果只是通过位置运算符限定两个地名实体位置邻近, 但排序没有明确要求, 则需要综合链入和链出理想集合并处理。通过上述计算和阈值设定可获取每个极小项对应的模糊集, 取模糊集的并集即可得到逻辑表达式对应的模糊集。计算模糊集中的每个轨迹链隶属于模糊集的程度, 计算方法如公式(2)所示, 与公式(1)存在较大相似性, 差别在于公式(1)计算的基础数据源为概率矩阵, 而公式(2)计算的基础数据为主析取范式和通过概率矩阵求解出来的隶属度。
其中, ${{\mu }_{q\text{, }j}}$表示用户查询式对应模糊集中的每条轨迹链隶属于模糊集的程度, $c{{c}_{n}}$表示主析取范式的组成单元极小项, $q$代表主析取范式对应的逻辑表达式, $j$表达模糊集中的任意轨迹链。按照${{\mu }_{q\text{,}j}}$的数值大小排序输出即可得到推荐结果, 而每天线路的推荐指数可与原始隶属度数值一致, 也可与进行归一化处理后的隶属度数值一致。
4 实证分析
中国香港是旅行者理想的目的地, 同时伴随着文化产业的输出, 中国香港众多地名早已成为其城市文化的重要标识, 因此选取赴港旅游文本作为数据, 共计801篇。
(1) 对采集到的线路文本进行地名实体识别, 地名实体排序按照实际旅行者参观的先后顺序, 与文本对应, 共得到801组地名实体序列。
(2) 将801组地名实体序列进行数据存储方式转换, 定义三个字段: 地名实体名、地名实体编号和轨迹链编号。地名实体名对应每组序列中的实际名字, 地名实体编号对应地名实体在当前轨迹链中的位置, 最先出现的即为1, 以此类推, 轨迹链编号表示地名实体序列的编号, 形式如表1所示, 转换后的记录数为 4 410条, 存储到MySQL数据库中。
(3) 步骤(2)只是揭示了轨迹链编号与地名实体编号之间的关联形式, 以表1中轨迹链编号字段为连接点, 借助数据查询中的自身连接操作, 并限定地名实体编号之差为1, 可得到地名实体轨迹链的基本组成单元, 即链入地名实体名、链出地名实体名、轨迹链编号, 此时轨迹链编号表示链入和链出地名实体之间存在序贯关系, 但连接权重未知。
(4) 以链入和链出地名实体名为分组变量, 以轨迹链编号为计数统计字段, 可获取链入和链出地名实体名之间的有向连接次数, 生成地名实体之间的有向加权网络, 该网络共包括32个地名实体, 630条连边, 联系权重越大线条越粗, 网络结构如图3所示。
图3
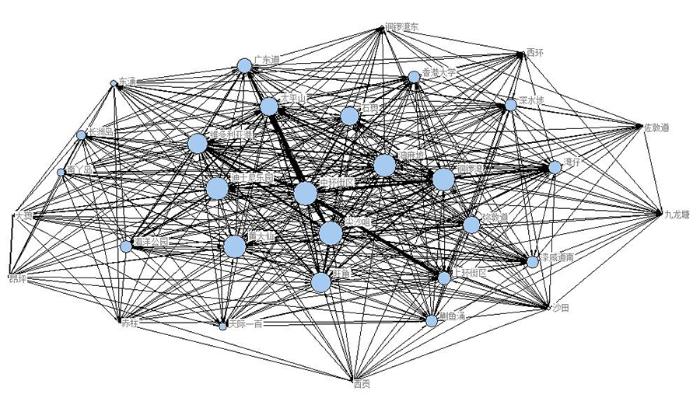
(5) 有向加权网络有其对应的邻接矩阵, 经过最大最小值归一化方式转换, 可得到邻接矩阵对应的概率矩阵, 概率矩阵数值代表行地名实体链入列地名实体的概率大小。
(6) 基于地名实体间的概率计算值, 按照模糊集合计算逻辑, 利用Python计算历史轨迹链隶属于任意地名实体链入和链出集合的程度大小, 计算流程如图4所示。
图4
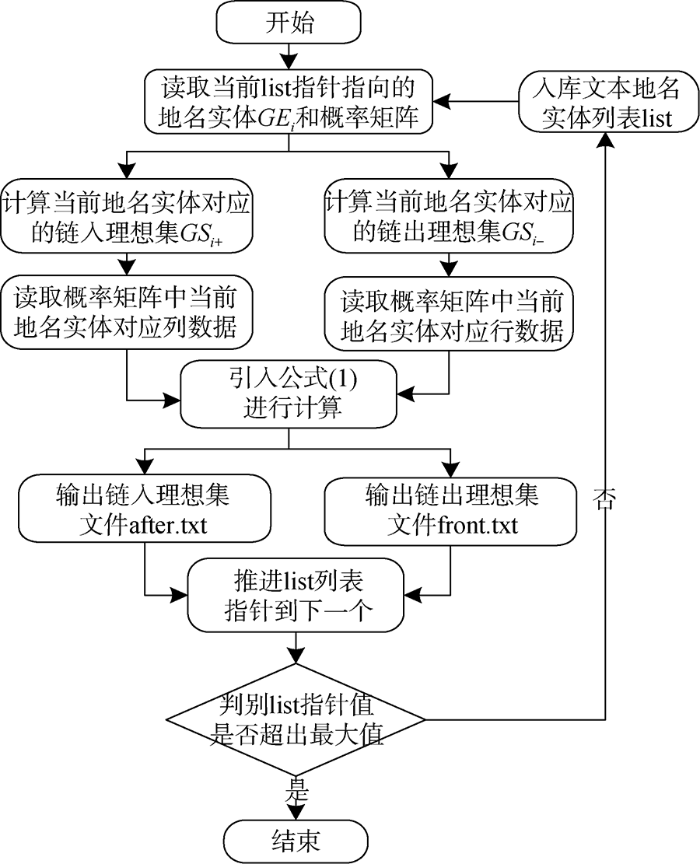
经过两次计算, 共输出两个文件: after.txt和front.txt, 通过循环遍历, 每个计算文件包括32×801条记录, 32表示地名实体的数目, 801代表轨迹链的数目, 二者两两组配, 共计获得25 632条记录, 包含隶属度为0的记录。随着历史文档不断增多, 计算及存储的工作量也会不断变大, 此时可根据实际需求设定阈值, 筛除隶属度低于阈值的记录, 这样在一次查询事务中, 地名实体所对应链入和链出理想集的规模就可根据实际情况进行调整。记录样式如表2所示。
(7) 采用自然语言或预定义好的逻辑运算符表达自身查询需求, 借鉴Web of Science平台提供的布尔逻辑运算符和位置限定运算符。布尔逻辑运算符优先级顺序为NOT、AND、OR, 位置限定运算符优先级顺序为WITH/n、NEAR/n(注意WITH/n为自定义的位置运算符, n表示地名实体之间可以间隔其他地名实体的数目), 总体上位置运算符的优先级高于布尔逻辑运算符, 通过括号可以改变现有的优先级顺序。随机选择三个地名实体沙田、旺角和湾仔, 如果组配需求为: 沙田 OR 旺角 AND 湾仔, 将找到包含地名实体沙田的轨迹链或同时包含旺角和湾仔的轨迹链。但如果组配需求为: (沙田OR旺角) AND 湾仔, 将找到同时包含沙田和湾仔的轨迹链, 或者同时包含旺角和湾仔的轨迹链。无论哪一种表达方式都对二者参观顺序没有直接要求, 此时这三个地名实体不需要区分链入理想集和链出理想集, 统一合并为理想集, 任意轨迹链隶属于这三个地名实体对应理想集的程度为链入和链出值的均值。以“沙田 OR 旺角 AND 湾仔”为例, 采用真值表法计算其对应的主析取范式为(1,0,0)∨ (1,0,1)∨(1,1,0)∨(1,1,1)∨(0,1,1), 依次计算每个极小项对应的模糊集(设定阈值为0.5), 计算结果如表3所示。
表3 极小项对应模糊集计算结果(不考虑地名实体参观顺序)
| 极小项 | 地名实体对应轨迹链集合 | 极小项对应模糊集 | |
|---|---|---|---|
| $\phi $(1,0,0) | 沙田 | A=$\phi $ | $\phi $ |
| 旺角 | U-B | ||
| 湾仔 | U-C | ||
| (1,0,1) | 沙田 | A=$\phi $ | $\phi $ |
| 旺角 | U-B | ||
| 湾仔 | C={2,3,8,19,26,34,39,72,121,136,199,272,406,504,575,635} | ||
| (1,1,0) | 沙田 | A=$\phi $ | $\phi $ |
| 旺角 | B={8,26,34,39,73,88,136,199,205,216,272,349,375,406,635,640,789} | ||
| 湾仔 | U-C | ||
| (1,1,1) | 沙田 | A=$\phi $ | $\phi $ |
| 旺角 | B={8,26,34,39,73,88,136,199,205,216,272,349,375,406,635,640,789} | ||
| 湾仔 | C={2,3,8,19,26,34,39,72,121,136,199,272,406,504,575,635} | ||
| (0,1,1) | 沙田 | U | {8,26,34,39,136,199,272,406,635}. |
| 旺角 | B={8,26,34,39,73,88,136,199,205,216,272,349,375,406,635,640,789} | ||
| 湾仔 | C={2,3,8,19,26,34,39,72,121,136,199,272,406,504,575,635} | ||
(注: U代表隶属度≥0.5的轨迹链集合, A代表沙田对应的理想集, B代表旺角对应的理想集, C代表湾仔对应的理想集, -表示差集运算符号。)
表4 不考虑地名实体参观顺序的线路推荐结果
| 轨迹链编号 | 隶属度 | 轨迹链编号 | 隶属度 |
|---|---|---|---|
| 8 | 0.332 | 199 | 0.300 |
| 26 | 0.301 | 272 | 0.282 |
| 34 | 0.314 | 406 | 0.277 |
| 39 | 0.258 | 635 | 0.278 |
| 136 | 0.311 |
表5 极小项对应模糊集计算结果(考虑地名实体参观顺序)
| 极小项 | 地名实体对应轨迹链集合 | 极小项对应模糊集 | |
|---|---|---|---|
| (1,0,0) | 沙田 | A=$\phi $ | $\phi $ |
| 旺角 | U-B | ||
| 湾仔 | U-C | ||
| (1,0,1) | 沙田 | A=$\phi $ | $\phi $ |
| 旺角 | U-B | ||
| 湾仔 | C={8,26,88,199} | ||
| (1,1,0) | 沙田 | A=$\phi $ | $\phi $ |
| 旺角 | B={3,8,26,34,39,73,88,136,199,205,245,272,375,406,475,495,620,635,638,717} | ||
| 湾仔 | U-C | ||
| (1,1,1) | 沙田 | A=$\phi $ | $\phi $ |
| 旺角 | B={3,8,26,34,39,73,88,136,199,205,245,272,375,406,475,495,620,635,638,717} | ||
| 湾仔 | C={8,26,88,199} | ||
| (0,1,1) | 沙田 | U | {8,26,88,199}. |
| 旺角 | B={3,8,26,34,39,73,88,136,199,205,245,272,375,406,475,495,620,635,638,717} | ||
| 湾仔 | C={8,26,88,199} | ||
(注: U代表隶属度≥0.5的轨迹链集合, A代表沙田对应的理想集, B代表旺角对应的链出理想集, C代表湾仔对应的链入理想集, -表示差集运算符号。)
从表6结果可以看出, 添加位置限制符后, 线路推荐结果相较之前明显减少, 但两者推荐结果存在较
大重合度, 如两次推荐结果都包括轨迹链8、26和199; 也存在一定差异, 如88号轨迹链在第一次推荐结果中并未出现, 出现这种情况主要在于用于匹配计算的理想集及隶属度发生一定变化: 在历史轨迹链集合中, 88轨迹链隶属于湾仔对应链出理想集的程度为0.485, 隶属于湾仔对应链入理想集的程度为0.512, 隶属于湾仔对应综合理想集的程度为0.498, 在阈值设置为0.5的情形下就出现了上述差异。在实际推荐系统中, 第二次推荐可以在第一次推荐结果的基础上进行检索, 这样可以最大程度消除推荐结果集上的差异。
步骤(8)和步骤(9)通过设置是否考虑地名实体参观顺序来进行对照实验, 引入测试推荐效果的准确率(Precision)和召回率(Recall)作为评价指标, 准确率表示推荐结果中相关记录所占比例; 召回率表示推荐结果中相关记录占所有相关记录的比例。同时, 融合模糊逻辑的线路推荐算法与以往推荐算法也存在较大 差异, 因此选择基于TF-IDF计算的传统推荐方法作为第二组对照实验。三类方法的性能表现结果如表 7所示。

由表7可知, 本文所提考虑地名实体参观次序的推荐方法具有最高的准确率, 但在召回率指标表现上无优势; 不考虑地名实体参观次序的推荐方法两方面性能表现居中; 基于TF-IDF计算的传统推荐方法具有较高召回率和较低的准确率。三类方法的两类指标存在明显的反向关系。在现实推荐系统中, 结合用户需求可融合多种推荐方法, 为其提供更为丰富的推荐策略。
入库记录是概率矩阵生成计算的数据源。随着入库记录规模的增大, 本文所提方法中的概率矩阵规模也会不断变大, 但最终会稳定下来。为验证入库记录规模对推荐结果的影响, 以现有入库记录801为最大值, 分别选取入库记录为200和500时进行推荐效果测试, 测试过程及控制条件参见步骤(9), 测试结果如表8所示。
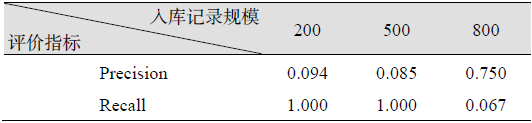
由表8可知, 随着入库记录规模的增加, 推荐结果的准确率在不断提升, 但召回率在不断下降, 两类指标也存在明显的反向关系, 二者乘积总体保持稳定。概率矩阵是地名实体大规模有向链接分析的加权结果, 是反映公众认知的有效视图, 随着概率矩阵规模趋于稳定, 轨迹链链条之间的概率更接近统计水平, 稳定性也越强, 推荐结果数量虽然在不断下降, 但结果的准确性却在上升。
5 结 语
城市地名实体是城市数据画像的重要参考点, 其发展经历了从实体认知到心理认知进化的过程。围绕特征场景或个体形成的轨迹链对于发掘个体移动规律和行为具有重要参考价值, 尤其是在线路推荐领域。结合WOS计量可知, 目前线路推荐研究主要聚焦在推荐算法和推荐效果两个层面, 综合以往研究, 本文提出融合模糊检索逻辑的线路推荐算法, 基于既往线路文本生成地名实体链接的概率矩阵, 以概率矩阵为模糊计算基础数据源, 测度每个轨迹链隶属于32个地名实体链入和链出理想集的程度; 设计用户查询需求表达的方式及基于真值表的转换策略; 最后阐述了查询式对应主析取范式与地名实体对应理想集的匹配过程, 并进行模拟实证分析。该推荐算法以不断增多的历史线路文本为输入参数, 以地名实体链接网络为基准数据源, 且随着网络规模扩展、节点连接稳定性的增强而不断进化, 能够实现较好的推荐效果。本文的不足在于从线路文本中抽取轨迹链的过程中没有考虑到线路发布者的属性信息, 比如性别、收入、年龄等, 以及这些因素对公众路线认知造成的影响, 未来将依据这些属性数据对用户及其关联的地名实体进行分层, 以进一步考察与判别属性数据对最终推荐结果的影响。
作者贡献声明:
叶光辉: 提出研究思路, 论文撰写及修订;
杨金庆: 数据采集、处理及分析。
利益冲突声明:
所有作者声明不存在利益冲突关系。
支撑数据:
支撑数据由作者自存储, E-mail: 3879-4081@163.com。
[1] 叶光辉.数据源.xlsx. 地名实体次序数据源.
[2] 叶光辉.链入-链出.txt. 链入链出计算结果.
[3] 叶光辉.推荐实验.xlsx. 考虑地名实体次序的计算数据
[4] 叶光辉.对照1.xlsx. tf-idf计算数据.
[5] 叶光辉.对照2.xlsx. 不考虑地名实体次序的计算数据.
[6] 叶光辉. 200&500推荐.xlsx. 不同入库记录规模推荐结果数据.
[7] 叶光辉. 数据源. ##h和数据源.##d. 地名实体连接可视化 数据.
[8] 叶光辉.savedres.txt. 相关研究题录数据.
参考文献
Measuring Image of a City: A Qualitative Approach with Case Example
[J].DOI:10.1057/palgrave.pb.5990058 URL [本文引用: 1]
Modeling a City’s Image: The Case of Granada
[J].
DOI:10.1016/j.cities.2007.01.010
URL
[本文引用: 1]

In both strategic city planning and city marketing, a fundamental starting point is to evaluate the image of the city itself. Knowing a city’s image is a key element in the diagnosis, which should serve as the basis of city planning. The concept of city image is multidimensional; it is not limited solely to one urbanistic aspect but, rather, includes other dimensions. This study identifies those dimensions that may have implications for the forming of city image. After validating the measurement scales, a causal model applied to the city of Granada is obtained that helps to understand the forming of its image. The interpretation and conclusions drawn from the model complement the diagnosis and suggest actions to be carried out to improve a city’s image.
C-IMAGE: City Cognitive Mapping Through Geo-Tagged Photos
[J].DOI:10.7326/0003-4819-81-6-817 URL PMID:4611299 [本文引用: 1]
基于微博数据的北京市热点区域意象感知
[J].
DOI:10.18306/dlkxjz.2017.09.006
URL
[本文引用: 1]
“城市意象”研究对城市文化感知、城市管理与规划、旅游资源开发等具有重要意义。近年来,随着智能移动终端和社交媒体的普及,产生了大量城市内包含有文本和地理位置等信息的社交媒体数据,涉及城市的各个区域,为开展城市意象的综合感知研究提供了新的途径。本文以2016年北京市带位置签到的新浪微博数据为例,在空间聚类发现热点区域的基础上,采用词频—逆文件频率(TF-IDF)与文档主题生成模型LDA两类典型的文本分析的方法,挖掘城市不同热点区域的主题,以感知北京市不同热点区域的社会文化功能和人群行为,并在此基础上通过对热点区域高频主题词进行共词聚类分析,深度挖掘北京市的总体意象。研究表明,运用文本挖掘及地理大数据分析的城市意象研究方法,能及时感知人群在城市不同场所的活动、态度、偏好,从而揭示城市的社会文化及功能特征,是对刻画城市物质形态的城市意象五要素模型的重要补充。此外,以北京市热点区域为例的实证研究结果对现实中的城市特色传承与空间品质塑造等有一定的启发意义。
Image Perception of Beijing’s Regional Hotspots Based on Microblog Data
[J].
DOI:10.18306/dlkxjz.2017.09.006
URL
[本文引用: 1]
“城市意象”研究对城市文化感知、城市管理与规划、旅游资源开发等具有重要意义。近年来,随着智能移动终端和社交媒体的普及,产生了大量城市内包含有文本和地理位置等信息的社交媒体数据,涉及城市的各个区域,为开展城市意象的综合感知研究提供了新的途径。本文以2016年北京市带位置签到的新浪微博数据为例,在空间聚类发现热点区域的基础上,采用词频—逆文件频率(TF-IDF)与文档主题生成模型LDA两类典型的文本分析的方法,挖掘城市不同热点区域的主题,以感知北京市不同热点区域的社会文化功能和人群行为,并在此基础上通过对热点区域高频主题词进行共词聚类分析,深度挖掘北京市的总体意象。研究表明,运用文本挖掘及地理大数据分析的城市意象研究方法,能及时感知人群在城市不同场所的活动、态度、偏好,从而揭示城市的社会文化及功能特征,是对刻画城市物质形态的城市意象五要素模型的重要补充。此外,以北京市热点区域为例的实证研究结果对现实中的城市特色传承与空间品质塑造等有一定的启发意义。
Trajectory Data Mining: An Overview
[J].
DOI:10.1002/eji.201646347
URL
PMID:27682842
[本文引用: 1]
Recent developments in single-cell transcriptomics have opened new opportunities for studying dynamic processes in immunology in a high throughput and unbiased manner. Starting from a mixture of cells in different stages of a developmental process, unsupervised trajectory inference algorithms aim to automatically reconstruct the underlying developmental path that cells are following. In this review, we break down the strategies used by this novel class of methods, and organize their components into a common framework, highlighting several practical advantages and disadvantages of the individual methods. We also give an overview of new insights these methods have already provided regarding the wiring and gene regulation of cell differentiation. As the trajectory inference field is still in its infancy, we propose several future developments that will ultimately lead to a global and data-driven way of studying immune cell differentiation.
Urban Computing: Concepts, Methodologies, Applications
[J].
Combining Tag Correlation and User Social Relation for Microblog Recommendation
[J].
Toward the Next Generation of Recommender Systems: A Survey of the State-of-the-Art and Possible Extensions
[J].
DOI:10.1109/TVCG.2018.2864814
URL
PMID:30130212
[本文引用: 1]
The emerging prosperity of cryptocurrencies, such as Bitcoin, has come into the spotlight during the past few years. Cryptocurrency exchanges, which act as the gateway to this world, now play a dominant role in the circulation of Bitcoin. Thus, delving into the analysis of the transaction patterns of exchanges can shed light on the evolution and trends in the Bitcoin market, and participants can gain hints for identifying credible exchanges as well. Not only Bitcoin practitioners but also researchers in the financial domains are interested in the business intelligence behind the curtain. However, the task of multiple exchanges exploration and comparisons has been limited owing to the lack of efficient tools. Previous methods of visualizing Bitcoin data have mainly concentrated on tracking suspicious transaction logs, but it is cumbersome to analyze exchanges and their relationships with existing tools and methods. In this paper, we present BitExTract, an interactive visual analytics system, which, to the best of our knowledge, is the first attempt to explore the evolutionary transaction patterns of Bitcoin exchanges from two perspectives, namely, exchange versus exchange and exchange versus client. In particular, BitExTract summarizes the evolution of the Bitcoin market by observing the transactions between exchanges over time via a massive sequence view. A node-link diagram with ego-centered views depicts the trading network of exchanges and their temporal transaction distribution. Moreover, BitExTract embeds multiple parallel bars on a timeline to examine and compare the evolution patterns of transactions between different exchanges. Three case studies with novel insights demonstrate the effectiveness and usability of our system.
基于内容相似度的运动路线推荐
[J].运动管理类移动应用经常需要从大量运动轨迹中为用户搜索出适合的运动路线,为此,提出了基于内容相似度的运动路线推荐方法。利用Geohash编码快速搜索用户邻域范围内的所有待推荐路线,计算用户已有运动路线与待推荐路线之间的路线相似度和运动模式相似度,对两种相似度进行加权求和处理作为待推荐路线的相似度,将相似度较大的若干运动路线推荐给用户。还针对推荐存在的冷启动问题给出了解决方案。通过实验,对两种相似度的权值进行调优,实验结果显示该方法可提高推荐效率,实际推荐效果良好。
Content-Based Approach to Exercise Route Recommendation
[J].运动管理类移动应用经常需要从大量运动轨迹中为用户搜索出适合的运动路线,为此,提出了基于内容相似度的运动路线推荐方法。利用Geohash编码快速搜索用户邻域范围内的所有待推荐路线,计算用户已有运动路线与待推荐路线之间的路线相似度和运动模式相似度,对两种相似度进行加权求和处理作为待推荐路线的相似度,将相似度较大的若干运动路线推荐给用户。还针对推荐存在的冷启动问题给出了解决方案。通过实验,对两种相似度的权值进行调优,实验结果显示该方法可提高推荐效率,实际推荐效果良好。
基于互联网信息的多约束多目标旅游路线推荐
[J].针对新游客在陌生城市如何规划旅游路线的问题,研究基于景点评分机制以及用户多约束的旅游路线推荐问题。首先提取景点的开放时间、门票与GPS坐标等及旅游网站上对于景点的评价信息等;然后提出一种基于多约束的k贪心算法,可以为游客推荐较好的旅游线路,并有效消除了推荐系统对先验知识的依赖。以驴评网上北京著名景点的信息作为数据集,实现并评估了推荐算法。实验结果表明,该方法能够为用户提供准确合理的路线规划。
Multi-Constraint and Multi-Objective Trip Recommendation Based on Internet Information
[J].针对新游客在陌生城市如何规划旅游路线的问题,研究基于景点评分机制以及用户多约束的旅游路线推荐问题。首先提取景点的开放时间、门票与GPS坐标等及旅游网站上对于景点的评价信息等;然后提出一种基于多约束的k贪心算法,可以为游客推荐较好的旅游线路,并有效消除了推荐系统对先验知识的依赖。以驴评网上北京著名景点的信息作为数据集,实现并评估了推荐算法。实验结果表明,该方法能够为用户提供准确合理的路线规划。
Coteries轨迹模式挖掘及个性化旅游路线推荐
[J].
Mining Coteries Trajectory Patterns for Recommending Personalized Travel Routes
[J].
Tracking the Evolution of a Destination’s Image by Text-Mining Online Reviews - The Case of Macau
[J].DOI:10.1016/j.tmp.2017.03.009 URL [本文引用: 1]
在线旅游行程规划系统关键技术研究与实现
[D].
Key Technology Research and Implementation of Online Travel Trip Planning System
[D].
网络视角下的应急情报体系“智慧”建设主题探讨
[J].
Probe into the Subject of “Wisdom” Construction of Emergency Information System Under the Perspective of Network
[J].
Fuzzy Sets
[J].
DOI:10.1007/s11356-019-07265-6
URL
PMID:31838682
[本文引用: 1]
With the significant economic shift, water pollution treatment has gradually become a key problem which needs to be deeply investigated for the sustainable development of China. In the face of specific water pollution incidents, multiple alternatives are often required to work together in order to achieve better results. However, due to the limitation of resources, alternatives must be ranked to realize the effective allocation of resources, which means the more highly ranked ones should possess more disposable resources. Furthermore, the water pollution treatment process is a multi-stage and multi-objective process. In each stage, decision-makers may have different emphasis and thus have different preferences for the treatment alternatives. How to effectively aggregate decision-makers' preferences in different stages into an overall preference so as to form a ranking of treatment alternatives under global constraints has turned into a problem worthy of discussion. Under such background, this paper proposes a multi-stage gray group decision-making method, where decision-makers use Group-G1 to rank and weight the criteria, and in this way, the weights of decision-makers and criteria in each stage could be determined. Considering the difference and deficiency of the cognitive level of decision-makers, this paper adopts the form of hesitant fuzzy linguistic term sets (HFITS) to express the evaluation information of decision-makers. And then, gray incidence analysis is selected to rank the alternatives. After ranking the alternatives in each stage, the multi-stage rankings will be aggregated into an overall ranking and the resource allocation is made according to the priorities of the alternatives. Finally, an example of water pollution treatment alternatives ranking based on a cyanobacterial bloom in Taihu Lake, China, is given to illustrate the proposed approach.
A Fuzzy Document Retrieval System Using the Keyword Connection Matrix and a Learning Method
[J].DOI:10.1016/0165-0114(91)90210-H URL [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}