
|
|
沈志宏 , 姚畅
, 姚畅
Shen Zhihong, Yao Chang
中图分类号: TP393
通讯作者:
收稿日期: 2017-12-12
修回日期: 2018-01-7
网络出版日期: 2018-01-25
版权声明: 2018 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】分析关联大数据的概念、内涵与特征, 针对关联大数据管理的技术挑战, 探讨关联大数据管理技术的对策和解决思路。【方法】结合NoSQL数据管理技术、分布式图计算技术、大数据流水线技术等给出应对挑战的思路, 并基于此思路形成大规模图数据仓库加工系统gETL。【结果】该方法和系统在NSFC-KBMS和WDCM项目中得到了应用, 实现了大规模知识型数据和生物数据的有效管理, 满足了多元化的数据管理需求。【局限】需要结合应用的情况, 进一步完善方法与系统。【结论】通过采用NoSQL数据存储技术、分布式图计算技术、大数据流水线技术以及gETL系统, 可以很好地解决关联大数据的管理问题。
关键词:
Abstract
[Objective] This article analyzed the concept, connotation and characteristics of the big linked data, aiming to explore possible solutions for technical challenges facing its management. [Methods] We proposed a new model based on NoSQL data management, distributed graph computing and big data pipeline technologies, which designed and develop gETL, a large-scale graph data warehouse processing system. [Results] The proposed system was used in NSFC-KBMS and WDCM projects, which effectively manages large-scale knowledge-data and biological data. [Limitations] The proposed system could be improved with new applications. [Conclusions] The NoSQL data storage, distributed graph computing, and big data pipeline technologies, as well as the gETL system, help us address the challenges facing linked big data management.
Keywords:
关联数据(Linked Data)的概念由Berners-Lee于2006年提出[1], 其原理是用一种轻型的、可利用分布数据集及其自主内容格式、基于标准的知识表示与检索协议、可逐步扩展的机制实现可动态关联的知识对象网络, 并支持在此基础上的知识组织和知识发现[2]。2007年5月, W3C的关联开放数据(Linking Open Data, LOD)运动正式启动, 旨在推动将Web上的开放数据源以资源描述框架(Resource Description Framework, RDF)的方式发布, 同时生成数据源之间的RDF链接, 以供关联数据浏览器、搜索引擎以及更高级的应用程序使用。由此关联数据的理念逐渐深入到各个领域, 关联数据的应用得以蓬勃发展。
2008年, Nature出版专刊BigData[3], 分析了大量快速涌现的数据给数据分析处理带来的巨大挑战。大数据(Big Data)指传统的数据处理应用软件难以处理的庞大和复杂的数据集[4]。近年来, 数据爆炸式增长催生着大数据时代的来临。一方面, 互联网、移动互联网、物联网、车联网、GPS、生命科学、医学影像、安全监控、金融、电信等领域产生着巨大的数据; 另一方面, 随着越来越多的诸如500米口径球面射电望远镜(FAST)、中国散裂中子源(CSNS)等大科学装置的建设和重大科学实验的开展, 以及无所不在的科学传感器和传感器网络广泛应用于天空、陆地和海洋, 对自然环境进行全方位的探测、监测, 源源不断产生的科学数据将科学研究快速推进到一个前所未有的大数据时代[5]。
随着越来越多的数据以关联数据的方式发布, 关联大数据的概念为人提起。Hu等介绍了一种针对“Big Linked Data”的存储方案, 允许在保持语义特性的同时还能实现大规模数据的存储[6]。Hitzler等在讨论“关联数据、大数据与第四范式”时认为, 关联数据已经毫无争议地成为大数据版图中的一部分[7]。文献[8]也认为: 大数据和关联数据将成为未来Web基础设施一个必不可少的部分, 大量的数据将变得可用、互联和可标识。Robak等介绍了如何将大数据和关联数据的概念应用到供应链管理当中的实践[9]。刘炜等认为由于数据量越来越大, 越来越多的关联数据应用系统不得不考虑采用大数据解决方案[10]。由于大数据方案对于海量、高速发展的数据具有很好的管理能力, 因而被用来管理关联数据是一个必然的选择。这种采用大数据技术方案建立的关联数据应用, 可称之为“大”关联数据应用。
本文认为, 关联大数据(Big Linked Data)即体量很大(如: RDF资源数目达到亿级, RDF三元组数目达到十亿级)、无法采用传统的方法和系统(如: Jena、Virtuoso[11]、D2R[12]、Silk[13]等)进行管理的关联数据。
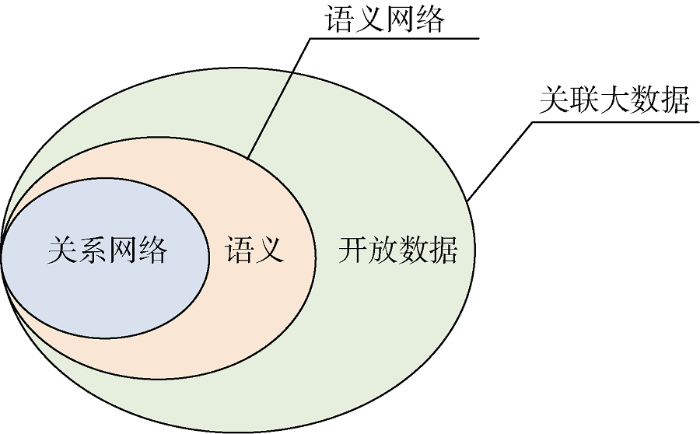
关联大数据综合了学术和工程实践的丰富内涵。本文认为关联大数据具有两个形态, 即外在的开放数据形态和内在的语义网络形态。外在的开放数据形态关注其开放可获取性, 在技术特征上一般表现由HTTP、URI和SPARQL所构成的RDF数据开放协议和服务; 内在的语义网络形态则关注关联大数据的语义网络结构, 表现为由RDF资源和RDF Link构成的庞大的关系网络。
与语义网络很相关的另一个概念即知识图谱 (Knowledge Graph), 作为当前的研究热点, 知识图谱将互联网的信息表达为更接近人类认知世界的形式, 提供一种更好地组织、管理和理解互联网海量信息的能力[14]。很多知名的知识图谱(如: DBpedia[15]、YAGO[16]、Wikidata[17]等)就采用RDF模型作为知识的表达格式。有观点认为知识图谱本质上就是语义网络[18]。
语义网络形态又可以进一步分解成两个要素, 即语义要素和关系网络要素。语义要素表现为RDF描述框架、RDF Schema、语义推理等语义规范和内容, 关系网络表现为由实体、关系构成的图(Graph)。关联大数据的概念层次如图1所示。
大数据具有显著的4V特征: 体量大(Volume)、增长速度快(Velocity)、多形态(Variety)、高价值(Value)[19,20]。关联大数据作为大数据版图中的一部分,同样表现出体量大和增长速度快的特征。随着数据内容的快速增加, 关联数据的资源(RDF Resource)和关联(RDF Link)往往达到千万级、十亿级乃至百十亿级的规模。以关联开放数据组织LOD收录的数据集为例, 2007年共收录12个开放的关联数据集; 2010年,收录203个数据集, 共3.95亿条三元组; 2012年, 收录295个数据集, 共316亿条三元组; 截至2017年2月, 数据集的数目已达到1 163个, RDF三元组达到1 494亿条[21]。再以世界微生物数据中心WDCM[22]为例, 共收集了全世界68个国家584个保藏中心的微生物资源信息, 其构建的RDF网络包括海量的物种、蛋白质、基因、酶等信息以及丰富的相关文献信息, 从而从整体的层面对生命进行理解和研究。据统计, WDCM的RDF数据三元组多达30亿条。
关联大数据也具有多形态的特征表现, 主要表现为语义Schema的多元性。从LODStats[23]收录的9 960个数据集来看, 它采用的词表多达2 593项, 命名空间33 761项 , 由此可以看出数据集中描述实体的Schema具有较大的差异性。另外, 关联大数据的汇聚数据源也呈现出多形态的特征, 如WDCM中除了主要的本体数据外, 很大一部分数据来源于关系型数据库表格、文献信息等非关系型数据和以文本形式存储的基因序列文件。
关联大数据所具有的价值性特征则主要表现为基于数据集乃至跨数据集的关联发现以及深层次关系挖掘的价值。比较经典的应用案例有, Dong等开发的Chem2Bio2RDF Dashboard系统集成了化学、生物、药物领域的关联数据, 用以发现两个实体或概念之间的路径[24]。Vidal等开发的BioNav系统能够基于本体技术有效发现药物和疾病之间的潜在关系等[25]。此外, 关联大数据所具备的关系网络形态, 导致其在实体聚类、社区发现等方面也具有较高的挖掘价值。
传统的观点[26,27]认为, 关联数据的应用包括三个方面: 关联数据的发布(Publishing Linked Data)、关联数据的互联(Interlinking Linked Data)、关联数据的消费(Consuming Linked Data)。在关联大数据的场景下, 这个观念呈现出两个方向的改变。
(1) 关联数据的互联和消费任务的内涵变得更加丰富, 互联与消费之间的界限变得模糊, 逐渐演化成关联数据的采集、加工、存储、挖掘、可视化整个过程。如: 关联数据集成处理框架LDIF[28]就为用户提供了丰富的数据采集、Schema映射、标识识别(Identity Resolution)、质量评估与数据融合等功能模块。
(2) 关联大数据的消费与发布构成循环, 消费系统通过采集开放数据, 进行加工整合又形成了新一代的语义网络, 再以开放数据的方式发布, 整个过程构成“关联数据发布-关联数据消费-关联数据发布”的循环, 关联大数据的两个形态也在反复切换, 即“外在的开放数据形态-内在的语义网络形态-外在的开放数据形态”, 如图2所示。
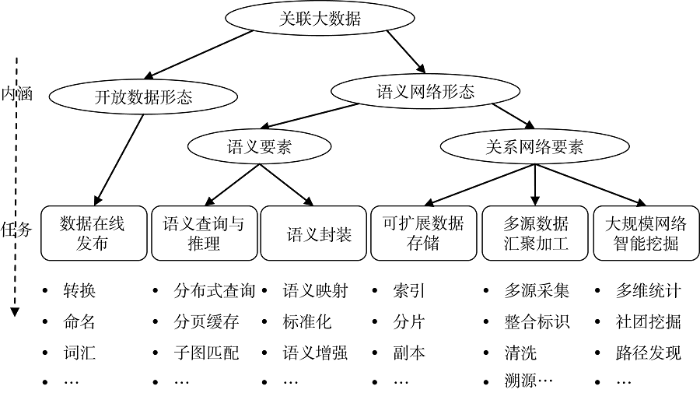
结合关联大数据的内涵分析, 关联大数据的管理任务可以分解成数据在线发布、语义查询与推理、语义封装、可扩展数据存储、多源数据汇聚加工、大规模网络智能挖掘等内容。完整的任务框架如图3所示。
传统的关联数据技术很难满足关联大数据的管理任务, 在数据存储、分析计算等多个方面都存在诸多瓶颈, 技术上主要面临的挑战包括: 来自大体量的存储管理挑战、来自迭代式多源数据汇聚加工的挑战以及来自关联大数据多元服务需求的挑战。
(1) 来自大体量的挑战
大体量带来的首要问题就是大规模RDF数据的存储问题。传统的RDF存储管理系统, 采用基于内存、文件系统和关系数据库的存储方法[29], 如: Jena TDB、3Store、RStar、Virtuoso等, 很难满足大体量的要求。近年来, 也有一些基于分布式的存储系统提出, 如: RDFPeers、4store、Bigdata、YARS2、HadoopRDF等。但这些系统针对10亿级甚至100亿级RDF三元组的存储管理, 还存在较大的差距。有观点甚至认为由于RDF数据库的存储能力问题, 目前只有少量的人还在用Triple Store(三元组数据库)和SPARQL, RDF数据库不再成为主流[30]。
(2) 多源汇聚成为常态, 数据加工成为常态
在构建关联数据语义网络时, 常常需要采用开放的第三方数据源作为输入。以国家自然科学基金大数据知识管理服务平台项目(简称NSFC-KBMS)为例, 为了构建完整的成果数据库, 需要集成开放的DBLP数据源、授权访问的CSCD数据以及授权访问的Scopus数据。这些数据源具有显著的多元异构特征, 新一代的关联大数据管理系统需要支持这些多元化数据的存储需求, 并提供灵活的数据汇聚模型和工具。
关联数据的加工本质上是关联数据语义网络不断演化的过程[31], 这个过程是迭代式的、极其复杂的。在数据不断快速增加的情况下, 这种迭代式加工逐渐成为一种常态。然而, 传统的关联数据的发布加工系统往往基于“数据量小、加工频次低”的假设, 通常采用一种粗暴式的“全量批处理”方式处理RDF数据集。以SILK[32]为例, SILK允许用户制定SILK-LSL(SILK Link Specification Language)规则文件, 并藉此自动生成出不同数据集之间的实例级链接。这种模式是以指定的数据集为输入, 并批量生成一批新的关联数据。其他工具, 如: LinQuer(Linkage Query Writer)[33]、LIMES(Link Discovery Framework for Metric Spaces)[34]
和RDF-AI[35]都采取这种“全量批处理”模式。这种模式具有以下不足:
①对于大规模数据来说, 单批次计算时间过长;
②一旦有新的数据加入, 不支持增量计算, 需要重新计算;
③经常在预处理、后处理阶段进行数据迁移、数据复制等操作, 实际上在大规模数据的场景下, 这些操作的成本很高, 包括空间和时间的消耗;
④处理方法之间的组合性很差, 不同处理过程之间需要大量的数据复制。
(3) 关联大数据的多元服务需求
传统的关联数据的服务形态体现为基于Web的SPARQL查询服务, 即应用程序通过HTTP协议提交SPARQL查询请求, 从而获取到SPARQL查询结果。然而, 关联大数据在面向上层应用时, 除了基础的SPARQL查询需求以外, 还需要满足更多的服务需求。
①全文检索需求。作为大数据的一个重要特征, 非结构数据、自由文本在关联数据的数据源中还占有较大的比重, 如: 成果的标题和摘要、人员的简历等, 针对这些非结构化自由文本需要提供自由高效的全文检索;
②图分析需求。应用需要针对语义网络进行深层次的分析, 如: 最短路径计算、集中度测量(如PageRank、特征向量集中度、亲密度、关系度、HITS)等;
③可视化浏览与交互式分析需求。即针对关联数据语义网络实现可视化挖掘分析, 如: 在线挖掘两个实体之间的关联路径, 社区聚类展示等。
针对以上技术挑战, 目前已经有一些值得借鉴和采用的方法及大数据技术, 包括NoSQL数据存储技术、分布式图计算技术以及大数据流水线技术。
大规模的结构化、半结构化、非结构数据的产生引发了NoSQL运动[36]。数据库世界由最初的SQL垄断的局面转变成传统SQL、NoSQL、NewSQL分治的局面。与传统的SQL数据库不同, NoSQL数据库自发明之日起, 就具备着利于大数据存储的几个特性[37,38]: BASE原则、分布式架构、横向扩展。
人们根据数据存储模型的差异性, 常常将NoSQL数据库分成Key-Value数据库、列式数据库、文档数据库、图数据库。作为NoSQL数据库中的一个重要分支, 图数据库成为关联大数据实现存储管理的最佳选择。目前典型的图数据库有Neo4j[39]、Titan[40]、Virtuoso等。
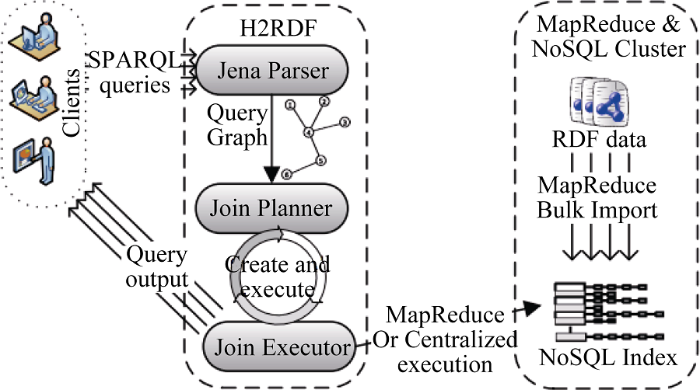
分布式图数据库可以解决大规模关联数据的存储问题[41,42]。然而, 为了应对大数据问题, 往往需要多种数据模型的混搭, 而非一种单一的图数据库模型。如: H2RDF[43]作为一个大规模RDF查询系统, 在RDF数据存储方面就采用了列式数据库HBase作为存储介质。由于RDF是采用三元组表示数据, 而HBase是面向列存储稀疏的数据库, 因此需要将RDF采用面向列的方式进行转换, 然后存储到HBase上。H2RDF的混搭架构如图4所示。
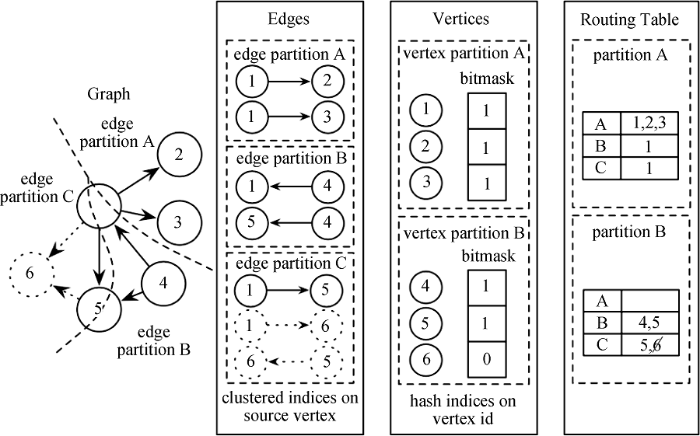
随着大数据应用的深入, 越来越多的图计算框架被提出, 包括GraphLab[44]、Giraph[45]、Spark GraphX[46]、Faunnus等。这些计算框架具有较大的异构性, 如: GraphLab框架采用Message Passing Interface (MPI)模型运行基于HDFS数据的复杂算法; Apache Giraph和Apache Hama则采用Bulk Synchronous Paralle(BSP)范式实现; Faunnus项目通过用Hadoop运行MapReduce作业的方式处理Titan数据库中图对象; Spark GraphX项目基于Spark分布式计算框架, 如图5所示。为了实现大规模图的高效计算与处理, Spark GraphX采用图的分布式或者并行处理方法, 即将图拆分成很多的子图, 然后分别对这些子图进行计算, 计算时可以分别迭代进行分阶段的计算, 即对图进行并行计算。
流水线结构(Pipeline Architecture)是计算机体系结构中的术语, 指在系统处理数据时, 每个时钟脉冲都接受下一条处理数据的指令。其中不同的部件完成不同的任务, 就像生产线流水操作一样, 而不是等一个或一批产品做完, 再接受下一批生产命令。每个工序完成以后, 立即接受下一批生产任务, 这样提高了系统处理数据的速度。大数据流水线(Pipeline)指从数据源到数据关联、数据处理及分析的一系列大数据操作[47], 如: Netflix[48]为了处理由几百个微服务系统每天产生的万亿条消息和PB级数据, 构建大数据流水线, 实现从生产者到消费平台(如 Hadoop/Elastic Search/Kafka)的大规模数据传输。
scikit-learn[49]和GraphLab等框架也采用流水线的概念构建系统。Spark Mllib[50]同样提供机器学习流水线机制, 将机器学习的过程抽象成“数据注入-数据清洗-特征抽取-模型训练-模型验证-模型选择-模型部署”的过程。
Apache NiFi[51]是一个成熟的开源大数据流水线项目, 基于其工作流式的编程理念, 提供了强大的、可靠的、高度可配置的流水线定义和执行功能。然而, 由于Apache NiFi采用专有的分布式计算框架和应用容器机制, 导致很难实现与Hadoop、Spark等大数据框架的无缝集成。另外, NiFi基于Flow File的溯源机制, 在处理大数据时往往具有极差的性能。
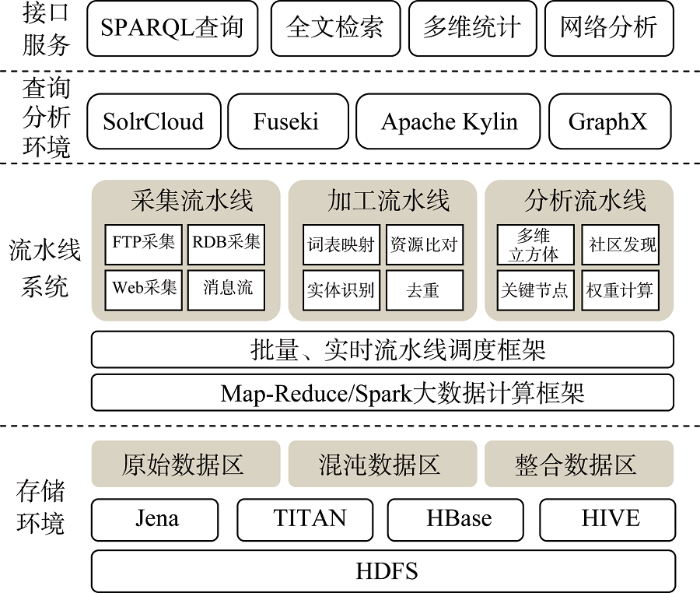
针对关联大数据管理的典型任务及流程, 基于对其面临的有关挑战及技术对策的分析, 笔者构建了面向大规模图数据仓库的ETL(Extract-Transform-Load)加工系统gETL。考虑到图数据模型比RDF模型具有更大的适用性, gETL采用图模型作为基础模型, 实现了大规模图数据的流程化存储、加工、挖掘管理, 同时针对关联数据的语义特性和开放特性提供相应的发布和转换的功能。图6为gETL的总体架构, 主要包括: 由Jena、TITAN、HBase、HIVE[52]等构成的存储环境; 流水线系统; 由Solr、Kylin、GraphX等构成的查询分析环境; SPARQL查询、全文检索、多维统计以及网络分析挖掘等的接口服务。
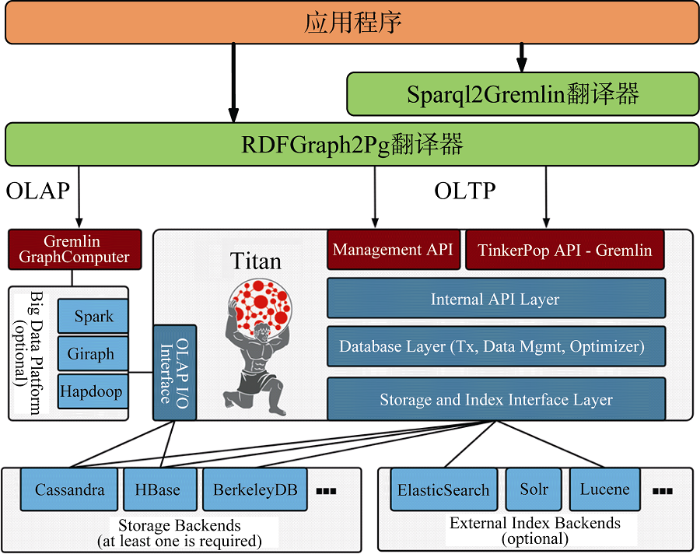
为了管理平台中超大规模的属性数据及关系数据, gETL采用大规模分布式图数据库TITAN。TITAN支持横向扩展, 可容纳数千亿个顶点和边, 并支持事务, 可以支撑上千并发用户和计算复杂图形遍历。TITAN更大的优势在于, 其数据存储支持Cassandra、HBase、BerkeleyDB, 索引存储支持ElasticSearch、Solr、Lucene。gETL所采用的RDF存储系统架构如图7所示。
其中, TITAN作为分布式存储、查询引擎, 底层数据存储采用HBase。面向关联数据的开放数据和语义特性, gETL提供RDFGraph2Pg翻译器和Sparql2 Gremlin翻译器。其中, RDFGraph2Pg翻译器基于Jena RDF I/O API完成, 主要实现RDF图到属性图的映射, 即接受RDF Graph(RDF资源、属性、RDF link)作为输入, 将其转换成属性图(节点、边、标签), 存储到TITAN中。在读取时, 从TITAN中加载到属性图信息, 结合RDF Schema将其转换成RDF Graph。Sparql2Gremlin翻译器基于Jena ARQ完成, 主要实现SPARQL查询语句到TITAN支持的Gremlin语句。Gremlin[53]是Apache TinkerPop 框架下的图遍历语言, 采用一种函数式数据流语言规范, 用户可以使用简洁的方式表述复杂的属性图的遍历或查询。Sparql2Gremlin翻译器针对Gremlin的查询结果进行解析, 将其封装成SPARQL查询结果返回。
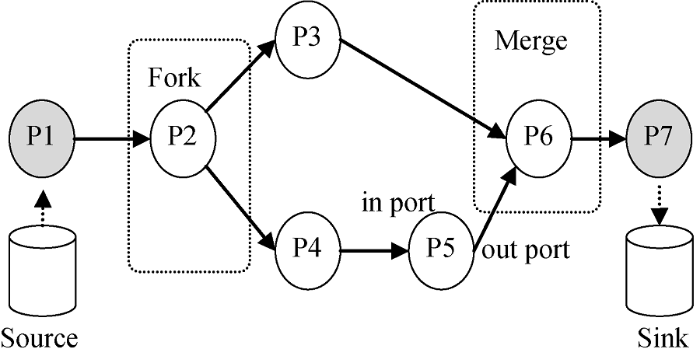
作为gETL的核心部分, 流水线系统基于统一的流水线软件表达模型, 实现图数据的采集、存储、查询和分析等过程。一条流水线(pipeline)用以描述一个相对独立的过程, 如: FTP数据采集流水线、实体识别流水线等。如图8所示, 流水线由多个节点组成, 每个节点被称为处理器(processor), 处理器之间存在数据传输。每个处理器可具有多个输入端口(in ports)和多个输出端口(out ports)。其中, 具有一个输入和一个输出的处理器被称为转换器(transform), 具有多个输入的处理器形成合流(merge)的效果, 具有多个输出的处理器形成分流(fork)的操作。
与大数据采集框架Apache Flume[54]类似, gETL引入Source和Sink的概念。有一类处理器没有输入只有输出, 它从指定的源(Source, 如: 关系型数据库、TCP输入流等)读取数据; 另一类处理器没有输出只有输入, 它将数据写到指定的槽(Sink, 如: 关系型数据库、消息系统、控制台输出等)中。
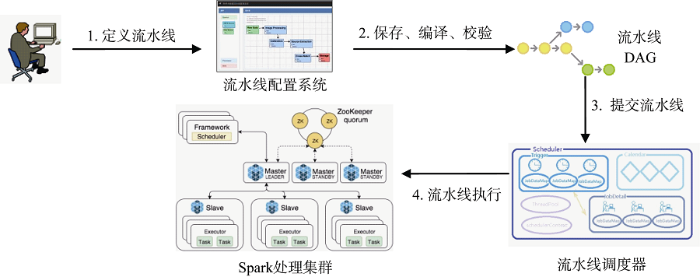
在流水线系统中, 流水线被抽象成多个处理器节点构成的有向无环图。流水线申请系统接收到流水线任务后, 校验无误后将它编译成一个有向无环图, 并将其封装成任务(job)提交给流水线任务调度系统。流水线调度系统根据调度要求(定时、实时、重复执行等), 在合适的时机执行该任务。该流程如图9所示。
在数据处理的过程中, 有一些针对RDF资源的处理任务, 包括: Schema映射、资源比对、实体识别、去重、属性IRI(Internationalized Resource Identifiers)化等。
(1) Schema映射。Schema映射用以实现两个异构RDF资源之间的转换。如: 可以将科学数据库项目中关于一个联系人的信息csdb:Contact映射成一个人员信息foaf:Person和一个机构信息vcard:Organisation。
(2) 资源比对。资源比对用以计算两个RDF资源之间的相似度。如: 在文献数据库中, 会出现两个同名作者, 为了确定他们的身份, 需要考虑其他的属性(如: 所在的工作单位)计算两条RDF资源的图形相似度。
(3) 实体识别。实体识别是根据一个RDF资源的属性, 通过与规范记录(Authority Record)比对, 获取到该资源的规范名称(URI)。与资源比对不同, 实体识别往往需要借助于规范库, 如根据人名规范库确定“鲁迅”和“周树人”是同一个作者。
(4) 去重。根据RDF资源比对结果, 将两个被认为同指的资源进行合并。
(5) 属性IRI化。属性IRI化实现将RDF资源的属性替换成IRI, 如: 将值为一段文本的dc:subject, 更换成一个指向某个分类条目的IRI。模式映射法(根据学科分类代码创建IRI)是一种简单实用的属性IRI化的方法。较复杂的属性IRI化方法往往还涉及资源比对等多种操作的参与。
除SPARQL查询服务外, gETL还针对其他服务要求实现了全文索引流水线, 以及一系列多维统计流水线、网络分析挖掘流水线。
(1) 全文索引流水线。基于分布式搜索系统SolrCloud, 建立针对文本字段(如: 人物姓名、成果标题)的全文索引, 从而满足高效的全文检索要求。SolrCloud是基于Solr和Zookeeper的分布式搜索方案, 由多台服务器共同响应索引或搜索请求。
(2) 多维统计流水线。实现面向事实数据的多维度(如: 年度、地区、单位等)统计。为了满足高性能查询统计的需求, 采用Apache Kylin作为统计引擎。Apache Kylin[55]是由eBay开源的一个大数据OLAP框架, 在Hadoop上提供标准的、友好的SQL接口, 以及交互式的多维分析能力。
(3) 网络分析挖掘流水线。基于Spark GraphX, 通过集成第三方图分析挖掘算法库, 实现常见的网络分析功能, 包括: 中心度计算、关键节点发现、社区发现、节点聚类等。
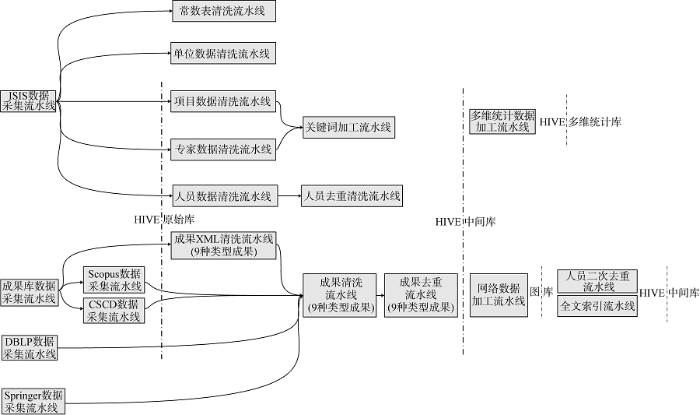
关联大数据在NSFC-KBMS项目中得到了有效的应用, gETL帮助建立起庞大的项目、人员、单位和成果等海量信息的大数据仓库, 存储规模可支持到十亿级关系。同时, NSFC-KBMS基于gETL建立丰富的大数据采集加工流水线, 管理任务涉及到业务数据采集、成果库采集、项目数据清洗、人员数据清洗、单位数据清洗、成果数据清洗、关系清洗、多维统计、全文索引等过程, 流水线达12类93条, 涉及处理器972个。图10简单展示出流水线的种类。
NSFC-KBMS同时基于gETL建立针对申请项目事实表、获批项目事实表、人员成果事实表、项目成果事实表、获批项目参与人员事实表、获批项目参与单位事实表、人员维度表、单位维度表的多维统计流水线。从基金项目类型、项目金额、项目起止时间、人员学历、年龄、研究领域等124个维度建立一个大数据仓库, 并实现针对项目资助情况、结题项目成果产出、获资助科研人员、获资助科研单位的多维统计, 其中维度组合可达31 393种。得益于Kylin的高性能, 统计服务达到亚秒级响应水平。
NSFC-KBMS还基于gETL建立了多条网络挖掘流水线, 一方面通过寻找专家之间关系、专家和待评审项目之间潜在的关联路径, 以期为基金项目的评审给出宝贵的参考意见; 另一方面通过发现科研人员或科研机构的合作网络, 寻找合作网络间的关键节点, 从而对关键专家、关键项目进行预测。
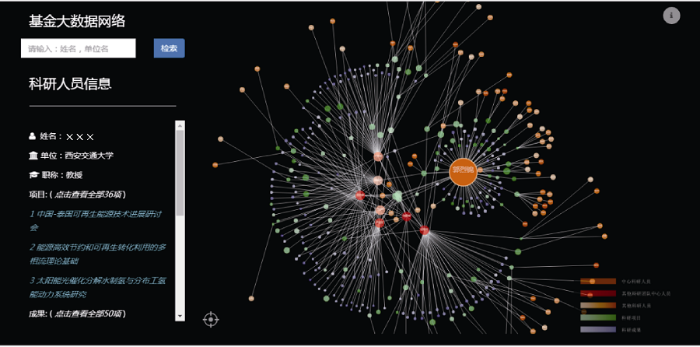
NSFC-KBMS最终面向公众提供一个基于大数据网络的服务门户, 提供直观的科研社区展示、实体属性与关联展示的功能, 运行效果如图11所示。
gETL还成功地应用到WDCM项目中, 目前已帮助WDCM实现了30亿RDF三元组的管理, 提供基于SPARQL查询的Web服务应用。测试表明, 对于大部分查询, gETL的RDF查询能达到秒级响应[56]。下一步将继续利用gETL的流水线系统, 实现对WDCM原有离散式的数据采集、汇聚、加工流程的统一管理。
关联大数据即体量很大、无法采用传统的管理系统(如: Jena、Virtuoso、D2R、Silk等)进行管理的关联数据。关联大数据具有开放数据和语义网络两个显著的形态, 其中语义网络同时包含语义要素和关系网络要素。关联大数据管理的任务涉及到数据存储、数据发布、数据汇聚加工以及数据挖掘统计等多个方面。面向这些任务, 关联大数据的管理技术需要应对多个方面的挑战: 来自大体量的存储管理挑战、来自迭代式数据汇聚加工的处理挑战以及来自关联大数据的多元服务需求的服务挑战。
针对以上挑战, 业界有一些值得借鉴和采用的方法和大数据技术, 包括NoSQL数据存储技术、分布式图计算技术以及大数据流水线技术。基于该思路, 本文介绍了大规模图数据加工系统gETL。gETL由存储环境、流水线系统、查询分析环境以及接口服务组成, gETL目前成功应用在NSFC-KBMS和WDCM项目中, 已实现10亿以上规模的生物数据和基金数据的管理与多元数据服务。
gETL还处于研发阶段, 下一步的研发计划包括: 深化应用, 结合项目的需求完善流水线的框架, 并扩充加工流水线算法库; 进一步扩充网络分析和挖掘的流水线; 完善流水线系统的容错性和错误恢复机制; 进一步提高开放性, 增加对计算框架Flink[57]、Storm[58]、Apache Beam[59]等的支持。
沈志宏: 提出论文总体思路, 确定论文总体写作框架, 撰写论文;
姚畅: 参与论文总体思路讨论, 重点完成NSFC-KBMS项目背景、需求、应用方案与效果的撰写;
侯艳飞: 提出论文修改意见, 重点参与文章第1节和第4节内容的调整和改进;
吴林寰: 参与论文总体思路讨论, 重点完成WDCM项目背景、需求、应用方案与效果的撰写;
李跃鹏: 参与论文总体思路讨论, 完成参考文献的校核与修改。
所有作者声明不存在利益冲突关系。
| [1] |
|
| [2] |
关联数据及其应用现状综述 [J].Linked Data and Its Applications: An Overview [J]. |
| [3] |
https://doi.org/10.1038/455001a URL [本文引用: 1] |
| [4] |
|
| [5] |
科学大数据管理: 概念、技术与系统 [J].Scientific Big Data Management: Concepts, Technologies and System [J]. |
| [6] |
Towards Big Linked Data: A Large-scale, Distributed Semantic Data Storage [C]// |
| [7] |
the 4th Paradigm [J]. |
| [8] |
Big Data & Linked Data [EB/OL]. [ |
| [9] |
Applying Big Data and Linked Data Concepts in Supply Chains Management [C]// |
| [10] |
大数据与关联数据: 正在到来的数据技术革命 [J].
当前越来越多的关联数据开始寻求突破关系数据库固有的局限,采用非关系型数据库(NoSQL)处理"大规模"的RDF数据。越来越多的大数据应用引入语义技术,通过语义链接,给大数据系统带来开放性和互操作性,并能提供基于"知识"的分析。通过介绍上述背景,区分"大"关联数据和"关联的"大数据两类不同的应用,对目前采用大数据技术发布关联数据的方法和路径进行梳理,同时对大数据领域应用关联数据技术的进展也做出介绍和点评,展望这两类数据技术在图情领域的发展前景。
Big Data and Linked Data: The Emerging Data Technology for the Future of Librarianship [J].
当前越来越多的关联数据开始寻求突破关系数据库固有的局限,采用非关系型数据库(NoSQL)处理"大规模"的RDF数据。越来越多的大数据应用引入语义技术,通过语义链接,给大数据系统带来开放性和互操作性,并能提供基于"知识"的分析。通过介绍上述背景,区分"大"关联数据和"关联的"大数据两类不同的应用,对目前采用大数据技术发布关联数据的方法和路径进行梳理,同时对大数据领域应用关联数据技术的进展也做出介绍和点评,展望这两类数据技术在图情领域的发展前景。
|
| [11] |
Virtuoso: RDF Support in a Native RDBMS[A]//Semantic Web Information Management [M]. |
| [12] |
D2R Server-Publishing Relational Databases on the Semantic Web [C]// |
| [13] |
Silk - A Link Discovery Framework for the Web of Data [C]// |
| [14] |
知识图谱研究综述 [J].Overview of Knowledge Graph [J]. |
| [15] |
DBpedia: A Nucleus for a Web of Open Data[A]// The Semantic Web [M]. |
| [16] |
YAGO: A Large Ontology from Wikipedia and Wordnet [J].https://doi.org/10.1016/j.websem.2008.06.001 URL [本文引用: 1] 摘要
This article presents YAGO, a large ontology with high coverage and precision. YAGO has been automatically derived from Wikipedia and WordNet. It comprises entities and relations, and currently contains more than 1.7 million entities and 15 million facts. These include the taxonomic Is-A hierarchy as well as semantic relations between entities. The facts for YAGO have been extracted from the category system and the infoboxes of Wikipedia and have been combined with taxonomic relations from WordNet. Type checking techniques help us keep YAGO’s precision at 95%—as proven by an extensive evaluation study. YAGO is based on a clean logical model with a decidable consistency. Furthermore, it allows representing n-ary relations in a natural way while maintaining compatibility with RDFS. A powerful query model facilitates access to YAGO’s data.
|
| [17] |
Wikidata: A Free Collaborative Knowledgebase [J].https://doi.org/10.1145/2629489 URL [本文引用: 1] 摘要
ABSTRACT Wikidata allows every user to extend and edit the stored information, even without creating an account. A form based interface makes editing easy. Wikidata's goal is to allow data to be used both in Wikipedia and in external applications. Data is exported through Web services in several formats, including JavaScript Object Notation, or JSON, and Resource Description Framework, or RDF. Data is published under legal terms that allow the widest possible reuse. The value of Wikipedia's data has long been obvious, with many efforts to use it. The Wikidata approach is to crowdsource data acquisition, allowing a global community to edit the data. This extends the traditional wiki approach of allowing users to edit a website. In March 2013, Wikimedia introduced Lua as a scripting language for automatically creating and enriching parts of articles. Lua scripts can access Wikidata, allowing Wikipedia editors to retrieve, process, and display data. Many other features were introduced in 2013, and development is planned to continue for the foreseeable future.
|
| [18] |
知识图谱的应用 [EB/OL]. [2017-10-02]. Application of Knowledge Graph [EB/ OL]. [ |
| [19] |
The ‘Four Vs’ of Big Data. Implementing Information Infrastructure Symposium [EB/OL]. [2012-10- 02]. . |
| [20] |
What is Big Data? [EB/OL]. [ |
| [21] |
Linking Open Data Cloud Diagram [EB/OL]. [ |
| [22] |
World Data Centre for Microorganisms: An Information Infrastructure to Explore and Utilize Preserved Microbial Strains Worldwide [J].https://doi.org/10.1093/nar/gkw903 URL PMID: 5210620 [本文引用: 1] 摘要
Abstract The World Data Centre for Microorganisms (WDCM) was established 50 years ago as the data center of the World Federation for Culture Collections (WFCC)-Microbial Resource Center (MIRCEN). WDCM aims to provide integrated information services using big data technology for microbial resource centers and microbiologists all over the world. Here, we provide an overview of WDCM including all of its integrated services. Culture Collections Information Worldwide (CCINFO) provides metadata information on 708 culture collections from 72 countries and regions. Global Catalogue of Microorganism (GCM) gathers strain catalogue information and provides a data retrieval, analysis, and visualization system of microbial resources. Currently, GCM includes >368 000 strains from 103 culture collections in 43 countries and regions. Analyzer of Bioresource Citation (ABC) is a data mining tool extracting strain related publications, patents, nucleotide sequences and genome information from public data sources to form a knowledge base. Reference Strain Catalogue (RSC) maintains a database of strains listed in International Standards Organization (ISO) and other international or regional standards. RSC allocates a unique identifier to strains recommended for use in diagnosis and quality control, and hence serves as a valuable cross-platform reference. WDCM provides free access to all these services at www.wdcm.org. The Author(s) 2016. Published by Oxford University Press on behalf of Nucleic Acids Research.
|
| [23] |
Lodstats - An Extensible Framework for High-performance Dataset Analytics[A]// Knowledge Engineering and Knowledge Management [M]. |
| [24] |
Chem2Bio2RDF Dashboard: Ranking Semantic Associations in Systems Chemical Biology Space [C]// |
| [25] |
BioNav: An Ontology-Based Framework to Discover Semantic Links in the Cloud of Linked Data[A]// The Semantic Web: Research and Applications [M]. |
| [26] |
Linked Data Applications [R/OL]. Digital Enterprise Research Institute(DERI), 2009. . |
| [27] |
关联数据的消费技术及实现 [J].https://doi.org/10.3969/j.issn.1002-1027.2013.03.004 URL [本文引用: 1] 摘要
从关联数据技术实现的角度看,发布和消费是构建关联数据平台和实施关联数据应用应该考虑到的两个重要方面。关联数据的消费技术涉及到数据的访问、获取、发现、查询、交换、传输、处理和利用。而消费的方式和效果取决于关联数据源所提供的消费接口。通过梳理和总结关联数据消费技术的各个方面,调研DBPedia、Freebase、VIAF等大型的关联数据集和〈sameAs.org〉、SWSE、Sindice、Swoogle、Falcons等流行的语义搜索引擎所提供的数据消费接口,总结目前关联数据消费接口的类型以及相应的使用方式,分析其适用范围、优缺点等,以期为关联数据发布方和消费方提供技术参考。
Technologies and Implementation of Consuming Linked Data [J].https://doi.org/10.3969/j.issn.1002-1027.2013.03.004 URL [本文引用: 1] 摘要
从关联数据技术实现的角度看,发布和消费是构建关联数据平台和实施关联数据应用应该考虑到的两个重要方面。关联数据的消费技术涉及到数据的访问、获取、发现、查询、交换、传输、处理和利用。而消费的方式和效果取决于关联数据源所提供的消费接口。通过梳理和总结关联数据消费技术的各个方面,调研DBPedia、Freebase、VIAF等大型的关联数据集和〈sameAs.org〉、SWSE、Sindice、Swoogle、Falcons等流行的语义搜索引擎所提供的数据消费接口,总结目前关联数据消费接口的类型以及相应的使用方式,分析其适用范围、优缺点等,以期为关联数据发布方和消费方提供技术参考。
|
| [28] |
Beyond Data Integration [J].https://doi.org/10.1016/j.drudis.2008.01.008 URL [本文引用: 1] |
| [29] |
大规模的RDF数据存储技术综述 [J].https://doi.org/10.3969/j.issn.2095-347X.2013.01.002 URL [本文引用: 1] 摘要
随着互联网上数据大规模的增长以及语义网的发展,如何存储大规模RDF成为了当前普遍关注的问题。本文对语义网中大规模RDF存储系统的研究现状与进展进行了分析,分别介绍了在RDF存储系统中的存储组织和查询优化以及现有的一些大规模RDF存储系统解决方案,重在对大规模的RDF数据存储技术研究的主流方法和前沿进展进行分析,最后对大规模RDF存储系统存在的一些问题进行了讨论并展望了未来的发展方向。
Overview of the Storage Technology for Large-scale RDF Data [J].https://doi.org/10.3969/j.issn.2095-347X.2013.01.002 URL [本文引用: 1] 摘要
随着互联网上数据大规模的增长以及语义网的发展,如何存储大规模RDF成为了当前普遍关注的问题。本文对语义网中大规模RDF存储系统的研究现状与进展进行了分析,分别介绍了在RDF存储系统中的存储组织和查询优化以及现有的一些大规模RDF存储系统解决方案,重在对大规模的RDF数据存储技术研究的主流方法和前沿进展进行分析,最后对大规模RDF存储系统存在的一些问题进行了讨论并展望了未来的发展方向。
|
| [30] |
|
| [31] |
面向LOD的关联发现过程的定位、目标与复杂性分析 [J].https://doi.org/10.3969/j.issn.1001-8867.2013.06.009 URL [本文引用: 1] 摘要
本文以关联数据应用过程中的关联发现过程为研究对象,分析了面向关联开放数据(LOD)的关 联发现过程的定位、目标与复杂性.本文认为,关联发现过程处于关联数据应用过程三阶段(数据发布、数据互联与数据消费)中的第二阶段.关联发现过程的整体 目标是构建多类资源之间的关联数据网络,该过程的本质就是关联数据网络不断演变的过程.关联发现的过程具有多任务、多路径、多步骤等复杂性特征.目前流行 的关联发现框架还存在缺乏对整个网络演变过程的支持、任务类型单一、缺乏流水线机制等不足.因此,关联发现技术的研究急需新的面向整个关联数据网络的、支 持完整演变过程的、支持多任务集成的理论、方法与框架.图5.表1.参考文献17.
Insights into Link Discovery Process for Linked Open Data: Positioning, Goals and Complexity [J].https://doi.org/10.3969/j.issn.1001-8867.2013.06.009 URL [本文引用: 1] 摘要
本文以关联数据应用过程中的关联发现过程为研究对象,分析了面向关联开放数据(LOD)的关 联发现过程的定位、目标与复杂性.本文认为,关联发现过程处于关联数据应用过程三阶段(数据发布、数据互联与数据消费)中的第二阶段.关联发现过程的整体 目标是构建多类资源之间的关联数据网络,该过程的本质就是关联数据网络不断演变的过程.关联发现的过程具有多任务、多路径、多步骤等复杂性特征.目前流行 的关联发现框架还存在缺乏对整个网络演变过程的支持、任务类型单一、缺乏流水线机制等不足.因此,关联发现技术的研究急需新的面向整个关联数据网络的、支 持完整演变过程的、支持多任务集成的理论、方法与框架.图5.表1.参考文献17.
|
| [32] |
A Declarative Framework for Semantic Link Discovery over Relational Data [C] // |
| [33] |
LIMES: A Time-efficient Approach for Large-scale Link Discovery on the Web of Data [C]// |
| [34] |
|
| [35] |
RDF-AI: An Architecture for RDF Datasets Matching, Fusion and Interlink [C]// |
| [36] |
Scalable SQL and NoSQL Data Stores [J]. |
| [37] |
The NoSQL Principles and Basic Application of Cassandra Model [C]// |
| [38] |
CAP Twelve Years Later: How the "Rules" Have Changed [J].https://doi.org/10.1109/MC.2012.37 URL [本文引用: 1] 摘要
The CAP theorem asserts that any networked shared-data system can have only two of three desirable properties. However, by explicitly handling partitions, designers can optimize consistency and availability, thereby achieving some trade-off of all three. The featured Web extra is a podcast from Software Engineering Radio, in which the host interviews Dwight Merriman about the emerging NoSQL movement, the three types of nonrelational data stores, Brewer's CAP theorem, and much more.
|
| [39] |
A Programmatic Introduction to Neo4j [C]// |
| [40] |
An Empirical Comparison of Graph Databases [C]// |
| [41] |
Choosing Between Graph Databases and RDF Engines for Consuming and Mining Linked Data [C]// |
| [42] |
Querying Wikidata: Comparing SPARQL, Relational and Graph Databases [C]// |
| [43] |
H2RDF: Adaptive Query Processing on RDF Data in the Cloud [C]// |
| [44] |
Distributed GraphLab: A Framework for Machine Learning and Data Mining in the Cloud [J].https://doi.org/10.14778/2212351 URL [本文引用: 1] |
| [45] |
Giraph: Large-scale Graph Processing Infrastructure on Hadoop [C]// |
| [46] |
Graphx: A Resilient Distributed Graph System on Spark [C]// |
| [47] |
Data Pipelines and How to Construct Them[A]// Pro Hadoop Data Analytics [M]. |
| [48] |
Building a Network Highway for Big Data: Architecture and Challenges [J].https://doi.org/10.1109/MNET.2014.6863125 URL [本文引用: 1] 摘要
Big data, with their promise to discover valuable insights for better decision making, have recently attracted significant interest from both academia and industry. Voluminous data are generated from a variety of users and devices, and are to be stored and processed in powerful data centers. As such, there is a strong demand for building an unimpeded network infrastructure to gather geologically distributed and rapidly generated data, and move them to data centers for effective knowledge discovery. The express network should also be seamlessly extended to interconnect multiple data centers as well as interconnect the server nodes within a data center. In this article, we take a close look at the unique challenges in building such a network infrastructure for big data. Our study covers each and every segment in this network highway: the access networks that connect data sources, the Internet backbone that bridges them to remote data centers, as well as the dedicated network among data centers and within a data center. We also present two case studies of real-world big data applications that are empowered by networking, highlighting interesting and promising future research directions.
|
| [49] |
Scikit-learn: Machine learning in Python [J]. |
| [50] |
Mllib: Machine Learning in Apache Spark [J].
Abstract: Apache Spark is a popular open-source platform for large-scale data processing that is well-suited for iterative machine learning tasks. In this paper we present MLlib, Spark's open-source distributed machine learning library. MLlib provides efficient functionality for a wide range of learning settings and includes several underlying statistical, optimization, and linear algebra primitives. Shipped with Spark, MLlib supports several languages and provides a high-level API that leverages Spark's rich ecosystem to simplify the development of end-to-end machine learning pipelines. MLlib has experienced a rapid growth due to its vibrant open-source community of over 140 contributors, and includes extensive documentation to support further growth and to let users quickly get up to speed.
|
| [51] |
An Easy to Use, Powerful, and Reliable System to Process and Distribute Data [EB/OL]. [ |
| [52] |
Hive-A Petabyte Scale Data Warehouse Using Hadoop [C]// |
| [53] |
|
| [54] |
Easier: Reining Real-time Big Data Processing in Cloud [C]// |
| [55] |
Online Analytical Processing on Hadoop Using Apache Kylin [EB/OL]. [2016- 12-02]. |
| [56] |
A Resilient Index Graph for Querying Large Biological Scientific Data [C]// |
| [57] |
Apache Flink: Stream and Batch Processing in a Single Engine [J].
Apache flink : Stream and batch processing in a single engine
|
| [58] |
|
| [59] |
|

| 版权所有 © 2015 《数据分析与知识发现》编辑部 地址:北京市海淀区中关村北四环西路33号 邮编:100190 电话/传真:(010)82626611-6626,82624938 E-mail:jishu@mail.las.ac.cn |
/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}