1 引 言
科研成果评价是科研管理中的一个重要环节, 目前已经引起了社会各界的广泛关注和重视, 但是其难点也相对突出, 难以对学术成果的学术质量做出客观准确的评价, 同时这里的学术质量又是一个比较复杂的概念, 难以直接和客观地评判与测度, 特别是一些重大理论创新必须经历较长时间的检验后才能展示其历史地位与学术价值。在自然科学领域中, 曾长期把新颖性、先进性和实用性作为评价科研成果学术质量的主要指标, 并且认为新颖性是先进性与实用性的基础[1 ,2 ] , 因此学术评价机构在开展学术评价与学术成果质量判断时, 新颖性都是其中的一个重要方面, 但是在具体做法上, 包括查新服务等方法在内, 对学术成果新颖性的判断主要以定性评价为主, 仅以证明“没有发表过”作为查新的主要目的和新颖性判断依据, 评价粒度较粗且没能从量化角度进行学术成果的新颖性研究, 伴随着当前学术研究的不断深入, “从无到有”的绝对学术新颖性并不十分常见, 而在一定的检索数据集内研究主题或话题的相对新颖性成为相关研究的测度目标。基于此, 本文从学术成果的研究主题新颖性着手, 通过文本挖掘技术和方法, 对学术成果的研究主题进行抽取和计算, 构建主题新颖性测度指标, 以期为学术成果的评价提供参考。
2 相关研究
2.1 基于同行评议的主题新颖性测度方法
关于学术研究中的主题新颖性的评价方法, 在国际学术界最为通用的就是同行评议, 由于其操作简便易行、结果反馈直接, 因此其应用范围不仅仅局限在包含学术创新性或者研究主题新颖性等在内的学术评价中, 同时在项目管理各环节、人才评价与学位授予等众多方面都有广泛应用。同行评价自身是一种主观的定性评价方法, 该词作为一个术语最早出现于公元9世纪的阿拉伯医学家Al-Ruhawi所著的《医师伦理》之中并展现其评价职能[3 ] , 近代以来, 美国率先使用同行评议方法进行科研项目经费申请的评审, 此后在欧美国家的科研评价中被不断广泛采用[4 ] 。总的来说, 同行评议方法已经在学术评价过程中发挥了并依然发挥着重要的作用, 且该作用在当前的学术评价中仍具有不可替代性, 但是同时也暴露出一些问题, 如部分学者认为其基于个人认知的特性有可能会造成评价结果中出现非公正性、非客观性和非合理性等问题的可能性[5 ] 。因此为了有效地弥补这一问题, 在当前信息处理技术快速发展的大背景下, 基于数据科学和认知计算的学术评价方法的出现为同行评议过程提供了一定程度上的支撑和参考。
2.2 基于引用的主题新颖性测度方法
为了在学术研究成果评价过程中更加准确、客观和量化地测度学术研究主题的新颖性, 为同行专家在进行学术评价过程中提供参考, 众多学者开始探索和构建量化的学术研究成果主题新颖性测度方法以进一步补充和支撑定性评价, 因而也产生了一系列的研究成果, 这些成果主要分为两个方面: 基于引文和引用关系的学术成果研究主题新颖性测度方法; 基于内容分析的学术成果研究主题新颖性测度方法。
在基于引文和引用关系的学术成果主题新颖性测度方面, 其理论基础继承自引文分析方法的基本假设, 即学术影响力的重要表现形式之一就是在学术成果发表以后被其他成果引用中体现的, 这一假设在学界中产生广泛影响, 也出现包括影响因子在内的众多基于引文分析的学术影响力与创新性的评价指标, 其中沈律[6 ] 认为在科技成果创新性评价中, 科技成果的创新性与其重复率成反比, 与其被引用情况成正比, 即重复率越高其创新度越低、引用率越高其创新度越高。从另一方面来讲, 引用行为除了是对被引对象的论证之外, 在施引自身也体现其学术研究自我证实的过程, 其中参考文献对施引者在科学研究的继承性、关联性与连续性上的体现也反映了学术成果的创新性、科学性[7 ] 。但是近些年来由于学术引用的情况越来越复杂, 导致其在具体应用中偏离学术本身的情况时有出现, 因此这一评价方法的合理性问题也广受质疑和诟病[8 ,9 ] , 众多学者也在研究中都尝试对该方法进行修正和完善。Leydesdorff等[10 ] 认为学术引用应该被进一步区分为长期引用和短期引用, 其中长期引用体现论文的原创性与学术影响, 重在反映学术研究的深度; 短期引用行为则说明学术成果处于研究前沿或研究热点之中, 反映了研究主题的先进性, 也可以理解为新颖性。尚海茹等[11 ] 认为引用行为可以体现学术传播与学术传承, 在此基础上进行基于学术链的学术传承效应, 提出长期传承性引用指标F1和其所处学术链中位置的测度指标F2。鉴于基于引用的评价指标中引用动机的多样性, 吴勤[12 ] 提出引证强度的概念, 综合考虑学术成果被他引次数在该论文质量量化中的正面效应和故意自引行为所可能带来的引证强度放大的负面影响, 并在此基础上建立论文评价数学模型。但是严格来说, 基于引用关系的学术评价实际上只是学术成果在学术影响力上的表层反映或者说不完全反映, 过于重视引文的评价属性会导致其偏离学术成果的实际内容越来越远[13 ] 。
2.3 基于内容的主题新颖性测度方法
由于上述基于引文的学术创新性评价的局限性, 这一领域的研究人员开始将目光转向学术成果本身, 通过对学术成果的内容分析与挖掘构建学术成果的研究主题新颖性测度指标, 从而展示学术研究内容间的差异。沈阳[14 ] 通过对关键词的挖掘与计算, 构建基于关键词在文中出现的频率、被用户检索的频率、使用的时间跨度及用户对关键词的创新度评价指标, 以此反映学术成果的创新度。虽然关键词可以在一定程度上反映学术成果中包含的重要主题、概念、思想、模型或方法, 但是使用单个关键词仍然不足以准确刻画和反映学术成果的主题新颖性, 在此基础上, 钱玲飞、杨建林等[15 ,16 ] 研究认为学科交叉程度与其学科创新性之间有较强的正向联系, 学科交叉程度越高, 其具有较高创新度的可能性就越大, 通过构建关键词的交叉率量化研究学科的创新能力, 并在此基础上基于关键词对间的共现关系进一步研究和构建文档的主题新颖度指标。在技术创新性研究领域, 研究者通过对专利文本特征、技术术语的提取和文本特征相似度的计算, 描述专利技术文本间的差异性, 其相似度越小, 则该专利间的技术差异越大、内容越新、专利价值越高[17 ] 。刘玉琴等[18 ] 使用该方法计算专利相似度, 并在此基础上量化地研究了技术的新颖度, 构建了在相似性水平阈值α 上的技术新颖度测算指标, 并在此基础上进一步构建相似水平阈值α 上m件专利的平均技术新颖度, 用于评价某段时间内专利群体的总体价值和技术新颖性。
从当前基于内容的主题新颖性计算方法来看, 现有的主题新颖性是基于关键词共现和文本特征提取的内容相似性计算的测度方法。在实际计算过程中, 学术成果中给出的关键词几乎都是由作者提供, 由于中文词语表达的随意性, 关键词中不规范或不合理之处比较常见。为消除不规范关键词等因素对主题新颖度量化结果准确度的影响, 研究者也采用词表的方法(如基于WordNet的语义相似度计算和基于HowNet中义原层次结构的语义深度和语义密度扩展等方法)对作者给出的关键词进行规范处理和语义扩展[19 ,20 ] , 但是该方法依赖于一个较为全面的领域语义词典, 其应用范围相对较为局限。
随着计算能力的大幅提高和数据规模的急速膨胀, 在大数据环境下采用深度学习的方法进行文本特征的语义扩展和内容相似度计算已经成为可能, 其计算效果也显著提升。其中以2013年Google公司发布其深度学习算法及工具包Word2Vec[21 ] 为代表, 标志着深度学习从理论走向实际应用。在Word2Vec工具包的基础上, Le等[22 ] 开发Doc2Vec算法工具包, 将文本特征的计算从词语层面扩展到句子层面。随后国内外众多学者基于该工具进行文本相似度计算研究, 表现出良好的效果[23 ,24 ,25 ] 。因此本文将基于此方法计算文档集内文本间的语义相似度, 并在论文研究主题相似度计算的基础上, 基于主题相似性网络的拓扑结构, 采用隐马尔可夫模型(Hidden Markov Model, HMM)的相关算法计算各文档间基于相似度的系统状态转移关系, 整体考虑文档集内所有文本间的相似性强度及其关系, 在该相似度转移矩阵的基础上计算内容特征因子, 构建学术研究成果的主题新颖度测度算法。
3 基于Doc2Vec和HMM的学术成果主题新颖性测度
3.1 主题新颖性测度模型构建
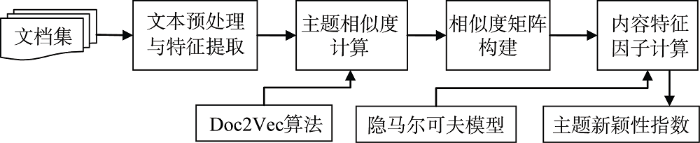
为了从整体上研究文档集内各个文档的主题新颖性, 本文采用深度学习中的Doc2Vec算法计算文档集内各个文档间的相似度关系, 并在文档相似度计算的基础上, 通过构建相似度转移矩阵并基于HMM算法计算该矩阵的特征因子, 作为反映单篇文档在文档集内与其他文档的关系指标, 并将该指标定义为文本的内容特征因子(Content Eigenfactor, Cef), 进一步基于该内容特征因子计算文档的主题新颖性。其计算模型如图1 所示。
图1 基于深度学习与隐马尔可夫模型的主题新颖性指数计算模型
该主题新颖度计算模型具体包括以下步骤:
①对文档集内的所有文本信息进行预处理, 在不改变信息位置的情况下进行文本分词并去除停用词等噪音信息。
②采用深度学习中的Doc2Vec算法计算文档集内所有文本间的语义相似度; 鉴于本文主要研究和探讨的是主题新颖性测度指标的构建, 因此, 将重点放在相似度计算之后内容特征因子计算及主题新颖性指标的函数表达上, 其中基于Doc2Vec算法的文本主题语义相似度计算采用文献[22 ]中的相关计算方法。
③根据文档的相似度计算结果, 构建并输出文档间的相似度关系矩阵A, 如公式(1)所示:
$A=\left[ \begin{align} & \begin{matrix} 0 & {{a}_{1,2}} & \cdots \ \ \ {{a}_{1,j}} \\ {{a}_{2,1}} & 0 & \cdots \ \ \ {{a}_{2,j}} \\ \cdots & \cdots & \cdots \ \ \ \cdots \\\end{matrix} \\ & {{a}_{j,1}}\ \ \ {{a}_{j,2}}\ \ \ \ \ \cdots \ \ \ \ 0 \\ \end{align} \right]$$\ \ \ \ \ \ {{a}_{i,j}}=\left\{ \begin{align} & \text{sim}({{t}_{i}},{{t}_{j}})\ \ \ i,j\in N,\ i\ne j \\ & 0\ \ \ \ \ \ \ \ \ \ \ \ \ \ i,j\in N,\ i=j \\ \end{align} \right.$ (1)
其中, $\text{sim}({{t}_{i}},{{t}_{j}})$为文档ti 和文档tj 的文本主题语义相似度。
④采用隐马尔可夫模型(HMM)的相关算法计算该相似度矩阵的内容特征因子Cef, 具体计算方法如公式(2)[26 ] 所示, 其中, M 是所有与文档Di 存在相似度关系的文档集合, weight (Dj )是边(Di , Dj )间的权重, degree (Dj )是转移矩阵中文档Dj 的度数。
$Cef({{D}_{i}})=\sum\limits_{{{D}_{j}}\in M}{\frac{weight({{D}_{j}})\times Cef({{D}_{j}})}{degree({{D}_{j}})}}$ (2)
⑤在内容特征因子计算的基础上, 构建文档D 的主题新颖性指数(Novelty of Theme, Nov), 如公式(3)所示。
$Nov(D)={{\text{e}}^{-Cef(D)}}$ (3)
其中, Cef (D )为文档D 的内容特征因子。该函数将主题新颖性测度对象从文本相似度计算和内容特征因子计算转化为文本主题新颖度测度指标与内容特征因子的单调递减函数关系, 其具体含义表现为在测试集内的文本相似度网络中, 综合考虑该成果与其他成果之间相似度数值和数量关系, 其结果表现为网络中与该节点相似的节点数量越少、相似度越低, 该节点的内容特征因子越低、其主题新颖性越高。
3.2 主题新颖性测度实证研究
为测试上述指标和方法的有效性, 本文选取国内情报学期刊中的相关学术论文进行主题新颖性测度。中国社会科学院发布的《中国人文社会科学期刊评价报告》[27 ] 显示, 《情报学报》在情报学期刊中的排名相对较高, 因此本文假定期刊评价排名与期刊质量、期刊质量与期刊论文的主题新颖性之间存在一定的相关关系。为加强对比效果且使测试样本具有横向可比性, 选取《情报学报》(简称QBXB)、《情报科学》(简称QBKX)和《情报杂志》(简称QBZZ)三本期刊上的2014年度所刊载的全部学术论文(928 篇)作为测度对象。对所选样本集内的文档进行两两相似度计算从而构建文档相似度矩阵, 在此基础上计算各个文档的内容特征因子和主题新颖性指数, 并通过计算和对比各刊刊载论文的新颖性指数的平均值, 验证本文构建的新颖性指数是否与期刊质量之间存在正相关关系。同时为了进一步加强对比效果。在计算文档相似度过程中, 分别采用Doc2Vec模型和TFIDF模型对文档相似度进行计算。此外, 为了验证基于文档相似度和内容特征因子的主题新颖性指数的有效性, 在同一文档集上, 采用文献[18 ]的技术新颖度测算方法对该文档的主题新颖度进行计算, 并与本文的算法进行对比。
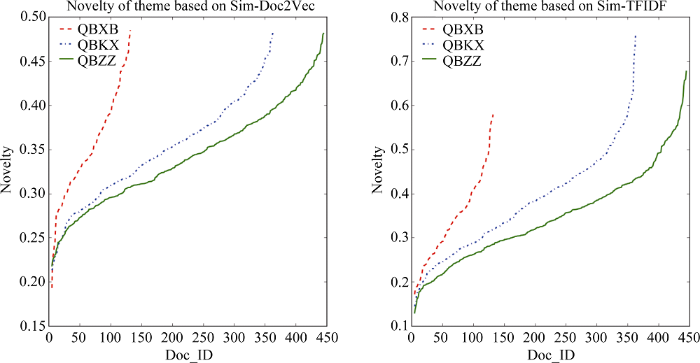
按照上述计算方法和研究思路, 分别采用两种相似度计算算法对上述三种期刊所载论文的文本内容进行相似度计算, 并在此基础上计算每篇文章的内容特征因子和主题新颖度, 其计算结果的分布如图2 所示。其中横轴表示每篇文章的ID号, 纵轴表示每篇文章所对应的主题新颖性指数。需要特别说明的是, 由于《情报学报》所刊载论文数量相对较少, 其曲线分布较为紧凑。从该结果来看, 基于Doc2Vec的主题新颖度计算方法较之基于TFIDF的计算结果更为准确可靠, 具体表现在前者计算中《情报学报》的论文总体新颖度较高, 且测试集内论文的主题新颖度最高的论文出现在《情报学报》中; 而后者计算结果中明显看出《情报学报》上所刊载论文的主题新颖度最高的论文其新颖度仍低于《情报科学》和《情报杂志》, 这一点上并不符合实际认知。
上述三种期刊中部分论文的主题新颖度计算结果如表1 所示。
3.3 结果分析与讨论
为了进一步研究期刊论文的主题新颖度水平与期刊学术质量间的关系, 笔者在基于Doc2Vec的单篇论文主题新颖度计算结果, 进一步计算出各期刊所载论文的主题新颖度的整体情况, 得出《情报学报》刊载论文的主题新颖性指数平均值为0.3532, 《情报科学》刊载论文的主题新颖性指数平均值为0.3462, 《情报杂志》刊载论文的主题新颖性指数平均值为0.3419。通过t检验统计和比较各期刊刊载论文的主题新颖性指数的差异分布及其显著性可以发现, 《情报学报》与《情报杂志》间论文主题新颖性指数存在显著性差异, 其p值为0.048<0.05, 这一结果可以从整体上说明, 期刊刊载论文的主题新颖性指数与期刊质量之间存在一定的正相关关系, 同一学科领域内, 高质量学术期刊的载文主题新颖度平均值相对较高。从每篇论文的主题新颖度的具体分布来看, 虽然重要期刊上所刊载论文的整体新颖度较高, 但是也存在两级分化现象, 例如《情报学报》上就有个别论文的主题新颖度低于0.2, 表明这些论文与较多其他主题新颖性较低的论文间的相似度较高。这也说明论文的主题新颖性只是保证学术质量与创新的前提之一, 并不具有绝对性, 重要期刊上也会刊载一些主题新颖度相对较低的论文, 因此该结果也表明研究主题的新颖度并不是决定学术质量的绝对因素。需要特别说明的是, 表1 中第4个样例(国内外网络舆情数学建模研究综述)虽为综述论文, 但该文基于不确定系统和不确定性因素的数学处理方法, 对网络舆情中不确定性因素的数学处理方法进行研究, 并对网络舆情相关研究的未来发展趋势进行展望, 视角独特且该类研究在目前的情报学领域内还较为少见, 且该综述论文在测试样本集内与其相似的论文数量较少、相似度也较低, 所以出现了较高的主题新颖性, 因此该例在样本集内的研究视角和主题获得了较高的主题新颖度, 这也进一步说明学科交叉融合能够促进学术创新和发展这一判断。综上所述, 本文构建的主题新颖性指数指标和方法不仅具有可操作性, 并且其计算结果也具有较好的可解释性。
为了进一步验证该方法的科学性和有效性, 将本文构建的主题新颖性指数与文献[18 ]的技术新颖度指数对该文档集的新颖度计算结果进行对比验证, 计算结果见表1 。通过计算两者的相关性, 可以发现, 基于本文所构建的主题新颖性测度方法所得到的结果与文献[18 ]的方法所得出的结果呈显著相关关系, 其相关系数为0.494, p值为0, 表现为0.01水平上显著相关, 以此验证本文所构建的主题新颖性计算方法的有效性。具体在采用文献[18 ]的技术主题新颖度计算过程中, 在文档相似度计算后选取其中α 的取值时发现, 若α 取值过大, 会造成与之相似的文档数n的值极小, 最终计算结果逼近或等于1, 反之若α 取值过小, 则容易造成与之相似的文档数n的值过大, 从而造成最终的新颖度指标结果极小的情况。本文对比研究时选取α =0.5作为阈值计算主题新颖度, 但是其结果也直接表现为文档主题新颖度计算结果的区分度较差, 而采用本文所构建的方法则有效地避免了这种问题。
4 结论与局限
为进一步研究和完善学术成果主题新颖性测度指标体系, 量化地测度学术成果的主题新颖性, 为学术成果评价和学科发展态势监测提供帮助和支撑, 本文构建基于深度学习的文本内容特征因子计算模型。通过计算文档集内文本间的语义相似性, 构建文档相似性矩阵, 进而计算该矩阵网络中各个文本节点间的相似性关系, 并采用隐马尔可夫模型的相关方法计算出该网络中各个节点的文本特征因子, 从而将文档集内与其他文本存在较低相似性的文档识别出来, 即构成文档的主题新颖性测度指标。
总体来说, 该方法避免了已有方法中仅仅考虑相似度阈值的高相似文档间的数量关系, 在网络图中进一步考虑了与节点间的相似度权重和与之连接的每一个节点与其他节点的相似性问题, 并从文档集内整体上考虑了主题的跨度与分布情况。从所选数据源进行实验后的实际计算结果来看, 该方法比较有效地计算出了各个文档的主题新颖度, 并且其计算结果与人们的实际认知比较相符, 这也表明本文构建的主题新颖性指数指标和方法不仅具有可操作性, 并且其计算结果也具有较好的可解释性。
通过将本文的测度方法与已有学者提出的方法进行对比验证和相关性分析, 得出本文构建的主题新颖性测度指标和计算方法所得到的结果与刘玉琴等[18 ] 的计算方法所得出的结果呈0.01水平上的显著相关关系, 相关系数为0.494, 进一步验证了该方法的科学性和有效性, 同时本文构建的方法也有效避免了其他方法中阈值依靠人工设定和其计算结果区分度不够的问题。
由于各方面条件的限制, 本文在实证研究中仅使用了学术论文中的文题和摘要文本, 未对全文信息进行深入挖掘, 这一点将在后续研究中进一步探讨。此外, 从基于该指标的学术成果主题新颖性测度的具体结果来看, 通过对不同期刊上所载论文的主题新颖度测算, 重要期刊上也会刊载一些主题新颖度相对较低的论文, 这也表明论文的主题新颖性只是保证学术质量与创新的前提之一, 而并不是其绝对因素, 因此, 在主题新颖性测度的基础上, 进一步构建能够识别学术研究创新点和重大技术突破点的相关指标和算法, 是未来需要进一步探索和研究的方向。
作者贡献声明
逯万辉: 设计研究方案, 实验验证, 论文起草;
谭宗颖: 提出研究思路, 论文修订。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据
支撑数据由作者自存储, E-mail: luwanhui@126.com。
[1] 逯万辉, 谭宗颖. sankan_data.txt. 2014年《情报学报》、《情报科学》与《情报杂志》所刊论文题目及摘要数据.
[2] 逯万辉, 谭宗颖. 新颖度计算结果. xlsx. 2014年《情报学报》、《情报科学》与《情报杂志》所刊论文主题新颖性计算结果.
参考文献
文献选项
[1]
张京辉 , 胡淑礼 , 王亚非 , 等 . 软科学成果查新研究
[J]. 软科学 , 1993 , 7 (4 ): 28 -33 .
URL
[本文引用: 1]
摘要
正 随着科学技术突飞猛进地向前发展,学科间的相互渗透和广泛发展推动了科研工作的管理科学化的进程,科技查新工作逐步完善起来。到目前为止,应用科技成果的查新和软科学研究项目的查新组成了科技成果查新工作的整体。我国软科学研究查新工作大体分为两类:一是软科学研究项目开题(立题)查新;二是软科学研究成果鉴定前的查新。前者是通过对申报课题在一段时间内的
(Zhang Jinghui Hu Shuli Wang Yafei et al .Research on the Novelty Search of Soft Science
[J]. Soft Science , 1993 , 7 (4 ): 28 -33 .)
URL
[本文引用: 1]
摘要
正 随着科学技术突飞猛进地向前发展,学科间的相互渗透和广泛发展推动了科研工作的管理科学化的进程,科技查新工作逐步完善起来。到目前为止,应用科技成果的查新和软科学研究项目的查新组成了科技成果查新工作的整体。我国软科学研究查新工作大体分为两类:一是软科学研究项目开题(立题)查新;二是软科学研究成果鉴定前的查新。前者是通过对申报课题在一段时间内的
[2]
《科技查新教程》编写组 . 科技查新教程 [M]. 北京 : 机械工业出版社 , 2001 : 325 .
[本文引用: 1]
(Writing Group of Sci-Tech Novelty Retrieval Tutorial . Sci-Tech Novelty Retrieval Tutorial [M]. Beijing : China Machine Press , 2001 : 325 .)
[本文引用: 1]
[3]
Spier R The History of the Peer-Review Process
[J]. Trends in Biotechnology , 2002 , 20 (8 ): 357 -358 .
https://doi.org/10.1016/S0167-7799(02)01985-6
URL
PMID: 12127284
[本文引用: 1]
摘要
Abstract The peer-review process is a turf battle with the ultimate prize of the knowledge, science or doctrine being published. On the one side, we have the writers and originators of ideas, on the other, we have the editors and critics. But it was not always so.
[4]
杨京 . 基于研究水平的单篇学术论文创新力评价研究
[D]. 淄博: 山东理工大学 , 2016 .
[本文引用: 1]
(Yang Jing Evaluation of Paper’s Innovation Based on the Research Level
[D]. Zibo: Shandong University of Technology , 2016 .)
[本文引用: 1]
[5]
杨锋 , 梁樑 , 苟清龙 , 等 . 同行评议制度缺陷的根源及完善机制
[J]. 科学学研究 , 2008 , 26 (3 ): 569 -572 .
URL
[本文引用: 1]
摘要
同行评议是科学评价过程中采用的最重要、最普遍的方式。现有的同行评议制度中普遍存在着非公正性、非客观性、非合理性的缺陷。本文详细描绘了现有同行评议制度的缺陷,分析了缺陷存在的根源,并创新性地提出一整套完善机制以消除这些缺陷。
(Yang Feng Liang Liang Gou Qinglong et al .Origination and Improvement for the Pitfalls of Peer Review Systems
[J]. Studies in Science of Science , 2008 , 26 (3 ): 569 -572 .)
URL
[本文引用: 1]
摘要
同行评议是科学评价过程中采用的最重要、最普遍的方式。现有的同行评议制度中普遍存在着非公正性、非客观性、非合理性的缺陷。本文详细描绘了现有同行评议制度的缺陷,分析了缺陷存在的根源,并创新性地提出一整套完善机制以消除这些缺陷。
[6]
沈律 . 科技创新的一般均衡理论——关于科技成果创新度评价的科学计量学分析
[J]. 科学学研究 , 2003 , 21 (2 ): 205 -209 .
[本文引用: 1]
(Shen Lv A General Equilibrium Theory of the Science & Technology Innovation: On Scientometrics Analysis of the Science & Technology Innovation
[J]. Studies in Science of Science , 2003 , 21 (2 ): 205 -209 .)
[本文引用: 1]
[7]
朱大明 . 参考文献的主要作用与学术论文的创新性评审
[J]. 编辑学报 , 2004 , 16 (2 ): 91 -92 .
https://doi.org/10.3969/j.issn.1001-4314.2004.02.006
URL
[本文引用: 1]
摘要
将参考文献在学术论文中的主要作用类型进行了归纳。认为分析论文文后参考文献的特征及其在论文中所起的具体作用 ,有助于从参考文献角度鉴审学术论文的创新性。
(Zhu Daming Main Roles of References and Appraisal of Innovation of Academic Papers
[J]. Acta Editologica , 2004 , 16 (2 ): 91 -92 .)
https://doi.org/10.3969/j.issn.1001-4314.2004.02.006
URL
[本文引用: 1]
摘要
将参考文献在学术论文中的主要作用类型进行了归纳。认为分析论文文后参考文献的特征及其在论文中所起的具体作用 ,有助于从参考文献角度鉴审学术论文的创新性。
[8]
祁延莉 , 窦曦骞 , 夏汇川 . SCI量化评价功能的局限性及其修正
[J]. 情报理论与实践 , 2009 , 32 (9 ): 48 -52 .
[本文引用: 1]
(Qi Yanli Dou Xiqian Xia Huichuan Limitations of SCI Quantitative Evaluation Function & Its Modifications
[J]. Information Studies: Theory & Application , 2009 , 32 (9 ): 48 -52 .
[本文引用: 1]
[9]
Seglen P O Why the Impact Factor of Journals Should Not Be Used for Evaluating Research
[J]. BMJ , 1997 , 314 (7079 ): 498 -502 .
https://doi.org/10.1136/bmj.314.7079.498
URL
PMID: 9056805
[本文引用: 1]
摘要
Abstract As part of its mission to raise the level of debate about rationing of healthcare resources, the Rationing Agenda Group commissioned six pairs of articles debating specific propositions to do with rationing. The BMJ plans to publish these at roughly fortnightly intervals over the next few weeks. The first appears below.
[10]
Leydesdorff L Bornmann L Comins J et al . Citations: Indicators of Quality? The Impact Fallacy
[J]. Frontiers in Research Metrics and Analysis , 2016 , 1: Article 1.
URL
[本文引用: 1]
摘要
We argue that citation is a composed indicator: short-term citations can be considered as currency at the research front, whereas long-term citations can contribute to the codification of knowledge claims into concept symbols. Knowledge claims at the research front are more likely to be transitory and are therefore problematic as indicators of quality. Citation impact studies focus on short-term citation, and therefore tend to measure not epistemic quality, but involvement in current discourses in which contributions are positioned by referencing. We explore this argument using three case studies: (1) citations of the journal Soziale Welt as an example of a venue that tends not to publish papers at a research front, unlike, for example, JACS; (2) Robert Merton as a concept symbol across theories of citation; and (3) the Multi-RPYS (“Multi-Referenced Publication Year Spectroscopy”) of the journals Scientometrics, Gene, and Soziale Welt. We show empirically that the measurement of “quality” in terms of citations can further be qualified: short-term citation currency at the research front can be distinguished from longer-term processes of incorporation and codification of knowledge claims into bodies of knowledge. The recently introduced Multi-RPYS can be used to distinguish between short-term and long-term impacts.
[11]
尚海茹 , 冯长根 , 孙良 . 用学术影响力评价学术论文——兼论关于学术传承效应和长期引用的两个新指标
[J]. 科学通报 , 2016 , 61 (26 ): 2853 -2860 .
[本文引用: 1]
(Shang Hairu Feng Changgen Sun Liang Evaluation of Academic Papers with Academic Influence — Proposing Two New Indicators of Academic Inheritance Effect and Long-term Citation
[J]. Chinese Science Bulletin , 2016 , 61 (26 ): 2853 -2860 .)
[本文引用: 1]
[12]
吴勤 . 基于引证强度的学术论文质量评价方法研究
[J]. 情报学报 , 2007 , 26 (4 ): 522 -526 .
https://doi.org/10.3969/j.issn.1000-0135.2007.04.007
URL
[本文引用: 1]
摘要
学术论文质量评价是科研管理中的一个重点和难点.部分学者做了一些重要的工作,但尚未形成一个比较科学、系统、通用性较强的论文质量评价体系.本文提出了引证强度概念,在考虑了学术论文所在期刊学术影响力的前提下,考虑论文被他引次数在该论文质量量化中的正面效应,同时考虑"故意自引"有可能带来的引证强度放大的负面影响.从而建立论文评价数学模型.利用已发表的14篇经济类论文对模型进行实验,将实验结果和专家评价结果进行比较,检验数学模型的相对合理性.检验结果表明两者基本吻合.
(Wu Qin Research on Quality Evaluation in the Academic Articles Based on the Intensity of Citation
[J]. Journal of the China Society for Scientific and Technical Information , 2007 , 26 (4 ): 522 -526 .)
https://doi.org/10.3969/j.issn.1000-0135.2007.04.007
URL
[本文引用: 1]
摘要
学术论文质量评价是科研管理中的一个重点和难点.部分学者做了一些重要的工作,但尚未形成一个比较科学、系统、通用性较强的论文质量评价体系.本文提出了引证强度概念,在考虑了学术论文所在期刊学术影响力的前提下,考虑论文被他引次数在该论文质量量化中的正面效应,同时考虑"故意自引"有可能带来的引证强度放大的负面影响.从而建立论文评价数学模型.利用已发表的14篇经济类论文对模型进行实验,将实验结果和专家评价结果进行比较,检验数学模型的相对合理性.检验结果表明两者基本吻合.
[13]
Hirsch J E An Index to Quantify an Individual’s Scientific Research Output
[J]. Proceedings of the National Academy of Sciences of the United States of America , 2005 , 102 (46 ): 16569 -16572 .
https://doi.org/10.1073/pnas.0507655102
URL
PMID: 16275915
[本文引用: 1]
摘要
I propose the index $h$, defined as the number of papers with citation number higher or equal to $h$, as a useful index to characterize the scientific output of a researcher.Hirsch, J E
[14]
沈阳 . 一种基于关键词的创新度评价方法
[J]. 情报理论与实践 , 2007 , 30 (1 ): 125 -127 .
[本文引用: 1]
(Shen Yang An Innovative Evaluation Method Based on Keywords
[J]. Information Studies: Theory & Application , 2007 , 30 (1 ): 125 -127 .)
[本文引用: 1]
[15]
钱玲飞 , 杨建林 , 张莉 . 基于关键词分析的学科创新力比较——以情报学图书馆学为例
[J]. 情报理论与实践 , 2011 , 34 (1 ): 117 -120 .
URL
[本文引用: 1]
摘要
本文以情报学和图书馆学为例,选取情报学重要核心期刊《情报学报》和图书馆学重要核心期刊《中国图书馆学报》2000—2009年10年间论文的关键词,用定量方法深入分析这些关键词出现的规律,对情报学和图书馆学的学科创新力进行立体评价。具体包括用主关键词交叉率对学科创新潜力进行评价,用共现词生命指数对学科创新活力进行评价,用有效共现词出现率对学科创新保持力进行评价,并对评价结果进行定性分析,证明定量分析结果的客观性和合理性。
(Qian Lingfei Yang Jianlin Zhang Li Comparison of the Discipline Innovation Based on Keyword Analysis — Take the Information Science and Library Sciences as an Example
[J]. Information Studies: Theory & Application , 2011 , 34 (1 ): 117 -120 .)
URL
[本文引用: 1]
摘要
本文以情报学和图书馆学为例,选取情报学重要核心期刊《情报学报》和图书馆学重要核心期刊《中国图书馆学报》2000—2009年10年间论文的关键词,用定量方法深入分析这些关键词出现的规律,对情报学和图书馆学的学科创新力进行立体评价。具体包括用主关键词交叉率对学科创新潜力进行评价,用共现词生命指数对学科创新活力进行评价,用有效共现词出现率对学科创新保持力进行评价,并对评价结果进行定性分析,证明定量分析结果的客观性和合理性。
[16]
杨建林 , 钱玲飞 . 基于关键词对逆文档频率的主题新颖度度量方法
[J]. 情报理论与实践 , 2013 , 36 (3 ): 99 -102 .
[本文引用: 1]
(Yang Jianlin Qian Lingfei A Novel Measurement Method of the Theme Based on Inverse Document Frequency of Keywords
[J]. Information Studies: Theory & Application , 2013 , 36 (3 ): 99 -102 .)
[本文引用: 1]
[17]
Mase H Matsubayashi T Ogawa Y et al .Proposal of Two-stage Patent Retrieval Method Considering the Claim Structure
[J]. ACM Transactions on Asian Language Information Processing , 2005 , 4 (2 ): 190 -206 .
https://doi.org/10.1145/1105696.1105702
URL
[本文引用: 1]
摘要
The importance of patents is increasing in global society. In preparing a patent application, it is essential to search for related patents that may invalidate the invention. However, it is time-consuming to identify them among the millions of patents. This article proposes a patent-retrieval method that considers a claim structure for a more accurate search for invalidity. This method uses a claim text as input; it consists of two retrieval stages. In stage 1, general text analysis and retrieval methods are applied to improve recall. In stage 2, the top N documents retrieved in stage 1 are rearranged to improve precision by applying text analysis and retrieval methods using the claim structure. Our two-stage retrieval introduces five precision-oriented analysis and retrieval methods: query-term extraction from a portion of a claim text that describes the characteristics of a claim; query term-weighting without term frequency; query term-weighting with “measurement terms”; text retrieval using only claims as a target; and calculating the relevant score by “partially” adding scores in stage 2 to those in stage 1. Evaluation results using test sets of the NTCIR4 Patent Retrieval Task show that our methods are effective, though the degree of the effectiveness varies depending on the test sets.
[18]
刘玉琴 , 朱东华 , 吕琳 . 基于文本挖掘技术的产品技术成熟度预测
[J]. 计算机集成制造系统 , 2008 , 14 (3 ): 506 -510 .
https://doi.org/10.1016/j.commatsci.2008.03.016
URL
[本文引用: 7]
摘要
为使产品技术成熟度预测的应用更加有效和广泛,结合国内外研究状况,提出了基于文本挖掘技术的产品技术成熟度预测方法。该方法应用文本挖掘技术挖掘隐含于专利数据库中内在的、客观的、定量的信息,引入技术新颖度度量函数量化技术的新颖程度,评价专利质量;同时,以专利维持成本反应专利的获利情况,并结合专利数量作为预测指标,进行产品技术成熟度预测。阐述了应用该方法进行预测的具体步骤,预测了我国光通信技术的成熟度情况,实验结果显示了该方法的有效性。
(Liu Yuqin Zhu Donghua Lv Lin Technology Maturity of Product Forecasting Based on Text Mining
[J]. Computer Integrated Manufacturing Systems , 2008 , 14 (3 ): 506 -510 .)
https://doi.org/10.1016/j.commatsci.2008.03.016
URL
[本文引用: 7]
摘要
为使产品技术成熟度预测的应用更加有效和广泛,结合国内外研究状况,提出了基于文本挖掘技术的产品技术成熟度预测方法。该方法应用文本挖掘技术挖掘隐含于专利数据库中内在的、客观的、定量的信息,引入技术新颖度度量函数量化技术的新颖程度,评价专利质量;同时,以专利维持成本反应专利的获利情况,并结合专利数量作为预测指标,进行产品技术成熟度预测。阐述了应用该方法进行预测的具体步骤,预测了我国光通信技术的成熟度情况,实验结果显示了该方法的有效性。
[19]
Meng L Huang R Gu J A Review of Semantic Similarity Measures in WordNet
[J]. International Journal of Hybrid Information Technology , 2013 , 6 (1 ): 1 -12 .
URL
[本文引用: 1]
摘要
Semantic similarity has attracted great concern for a long time in artificial intelligence, psychology and cognitive science. In recent years the measures based on WordNet have shown its talents and attracted great concern. Many measures have been proposed. The paper contains a review of the state of art measures, including path based measures, information based measures, feature based measures and hybrid measures. The features, performance, advantages, disadvantages and related issues of different measures are discussed. Finally the area of future research is described..
[20]
孙润志 . 基于语义理解的文本相似度计算研究与实现
[D]. 北京: 中国科学院大学 , 2015 .
[本文引用: 1]
(Sun Runzhi Research and Implementation of Text Similarity Computing Based on Semantic Understanding
[D]. Beijing: University of Chinese Academy of Sciences , 2015 .)
[本文引用: 1]
[21]
Word2Vec [EB/OL]. [2017-12-05]..
URL
[本文引用: 1]
[22]
Le Q V Mikolov T Distributed Representations of Sentences and Documents
[OL]. arXiv Preprint, arXiv: 1405.405302 .
URL
[本文引用: 2]
摘要
Abstract: Many machine learning algorithms require the input to be represented as a fixed-length feature vector. When it comes to texts, one of the most common fixed-length features is bag-of-words. Despite their popularity, bag-of-words features have two major weaknesses: they lose the ordering of the words and they also ignore semantics of the words. For example, "powerful," "strong" and "Paris" are equally distant. In this paper, we propose Paragraph Vector, an unsupervised algorithm that learns fixed-length feature representations from variable-length pieces of texts, such as sentences, paragraphs, and documents. Our algorithm represents each document by a dense vector which is trained to predict words in the document. Its construction gives our algorithm the potential to overcome the weaknesses of bag-of-words models. Empirical results show that Paragraph Vectors outperform bag-of-words models as well as other techniques for text representations. Finally, we achieve new state-of-the-art results on several text classification and sentiment analysis tasks.
[23]
Lee S Jin X Kim W Sentiment Classification for Unlabeled Dataset Using Doc2Vec with JST
[C]// Proceedings of the 18th Annual International Conference on Electronic Commerce: E-Commerce in Smart Connected World. ACM , 2016 : 28 .
[本文引用: 1]
[24]
Maslova N Potapov V Neural Network Doc2vec in Automated Sentiment Analysis for Short Informal Texts
[A]// Lecture Notes in Computer Science[M]. Springer , 2017 : 546 -554 .
[本文引用: 1]
[25]
逯万辉 . 基于深度学习的学术期刊选题同质化测度方法研究
[J]. 情报资料工作 , 2017 , 38 (5 ): 105 -112 .
https://doi.org/10.3969/j.issn.1002-0314.2017.05.016
URL
[本文引用: 1]
摘要
文章针对当前学术期刊发展中的同质化以及研究选题的相似性问题,提出了基于深度学习的学术期刊选题同质化测度模型,分别从基于期刊整体主题分布的同质化测度和基于单篇论文相似度的期刊同质化测度两个方面展开研究,并以图书情报与档案学核心期刊为例进行了实证,结果表明两种方法都能够较好地识别出期刊间选题的相似性,且可以互为补充.
(Lu Wanhui Research on Measuring Academic Journals Topics Homogenization Based on Deep Learning
[J]. Information and Documentation Services , 2017 , 38 (5 ): 105 -112 .)
https://doi.org/10.3969/j.issn.1002-0314.2017.05.016
URL
[本文引用: 1]
摘要
文章针对当前学术期刊发展中的同质化以及研究选题的相似性问题,提出了基于深度学习的学术期刊选题同质化测度模型,分别从基于期刊整体主题分布的同质化测度和基于单篇论文相似度的期刊同质化测度两个方面展开研究,并以图书情报与档案学核心期刊为例进行了实证,结果表明两种方法都能够较好地识别出期刊间选题的相似性,且可以互为补充.
[26]
Sheldon D Manipulation of Pagerank and Collective Hidden Markov Models
[D]. Cornell University , 2010 .
[本文引用: 1]
[27]
荆林波 . 中国人文社会科学期刊评价报告 [M]. 北京 : 中国社会科学出版社 , 2015 .
[本文引用: 1]
(Jing Linbo. Evaluation Report of Chinese Humanities and Social Sciences Journals [M]. Beijing : China Social Sciences Press , 2015 .)
[本文引用: 1]
软科学成果查新研究
1
1993
... 科研成果评价是科研管理中的一个重要环节, 目前已经引起了社会各界的广泛关注和重视, 但是其难点也相对突出, 难以对学术成果的学术质量做出客观准确的评价, 同时这里的学术质量又是一个比较复杂的概念, 难以直接和客观地评判与测度, 特别是一些重大理论创新必须经历较长时间的检验后才能展示其历史地位与学术价值.在自然科学领域中, 曾长期把新颖性、先进性和实用性作为评价科研成果学术质量的主要指标, 并且认为新颖性是先进性与实用性的基础[1 ,2 ] , 因此学术评价机构在开展学术评价与学术成果质量判断时, 新颖性都是其中的一个重要方面, 但是在具体做法上, 包括查新服务等方法在内, 对学术成果新颖性的判断主要以定性评价为主, 仅以证明“没有发表过”作为查新的主要目的和新颖性判断依据, 评价粒度较粗且没能从量化角度进行学术成果的新颖性研究, 伴随着当前学术研究的不断深入, “从无到有”的绝对学术新颖性并不十分常见, 而在一定的检索数据集内研究主题或话题的相对新颖性成为相关研究的测度目标.基于此, 本文从学术成果的研究主题新颖性着手, 通过文本挖掘技术和方法, 对学术成果的研究主题进行抽取和计算, 构建主题新颖性测度指标, 以期为学术成果的评价提供参考. ...
软科学成果查新研究
1
1993
... 科研成果评价是科研管理中的一个重要环节, 目前已经引起了社会各界的广泛关注和重视, 但是其难点也相对突出, 难以对学术成果的学术质量做出客观准确的评价, 同时这里的学术质量又是一个比较复杂的概念, 难以直接和客观地评判与测度, 特别是一些重大理论创新必须经历较长时间的检验后才能展示其历史地位与学术价值.在自然科学领域中, 曾长期把新颖性、先进性和实用性作为评价科研成果学术质量的主要指标, 并且认为新颖性是先进性与实用性的基础[1 ,2 ] , 因此学术评价机构在开展学术评价与学术成果质量判断时, 新颖性都是其中的一个重要方面, 但是在具体做法上, 包括查新服务等方法在内, 对学术成果新颖性的判断主要以定性评价为主, 仅以证明“没有发表过”作为查新的主要目的和新颖性判断依据, 评价粒度较粗且没能从量化角度进行学术成果的新颖性研究, 伴随着当前学术研究的不断深入, “从无到有”的绝对学术新颖性并不十分常见, 而在一定的检索数据集内研究主题或话题的相对新颖性成为相关研究的测度目标.基于此, 本文从学术成果的研究主题新颖性着手, 通过文本挖掘技术和方法, 对学术成果的研究主题进行抽取和计算, 构建主题新颖性测度指标, 以期为学术成果的评价提供参考. ...
1
2001
... 科研成果评价是科研管理中的一个重要环节, 目前已经引起了社会各界的广泛关注和重视, 但是其难点也相对突出, 难以对学术成果的学术质量做出客观准确的评价, 同时这里的学术质量又是一个比较复杂的概念, 难以直接和客观地评判与测度, 特别是一些重大理论创新必须经历较长时间的检验后才能展示其历史地位与学术价值.在自然科学领域中, 曾长期把新颖性、先进性和实用性作为评价科研成果学术质量的主要指标, 并且认为新颖性是先进性与实用性的基础[1 ,2 ] , 因此学术评价机构在开展学术评价与学术成果质量判断时, 新颖性都是其中的一个重要方面, 但是在具体做法上, 包括查新服务等方法在内, 对学术成果新颖性的判断主要以定性评价为主, 仅以证明“没有发表过”作为查新的主要目的和新颖性判断依据, 评价粒度较粗且没能从量化角度进行学术成果的新颖性研究, 伴随着当前学术研究的不断深入, “从无到有”的绝对学术新颖性并不十分常见, 而在一定的检索数据集内研究主题或话题的相对新颖性成为相关研究的测度目标.基于此, 本文从学术成果的研究主题新颖性着手, 通过文本挖掘技术和方法, 对学术成果的研究主题进行抽取和计算, 构建主题新颖性测度指标, 以期为学术成果的评价提供参考. ...
1
2001
... 科研成果评价是科研管理中的一个重要环节, 目前已经引起了社会各界的广泛关注和重视, 但是其难点也相对突出, 难以对学术成果的学术质量做出客观准确的评价, 同时这里的学术质量又是一个比较复杂的概念, 难以直接和客观地评判与测度, 特别是一些重大理论创新必须经历较长时间的检验后才能展示其历史地位与学术价值.在自然科学领域中, 曾长期把新颖性、先进性和实用性作为评价科研成果学术质量的主要指标, 并且认为新颖性是先进性与实用性的基础[1 ,2 ] , 因此学术评价机构在开展学术评价与学术成果质量判断时, 新颖性都是其中的一个重要方面, 但是在具体做法上, 包括查新服务等方法在内, 对学术成果新颖性的判断主要以定性评价为主, 仅以证明“没有发表过”作为查新的主要目的和新颖性判断依据, 评价粒度较粗且没能从量化角度进行学术成果的新颖性研究, 伴随着当前学术研究的不断深入, “从无到有”的绝对学术新颖性并不十分常见, 而在一定的检索数据集内研究主题或话题的相对新颖性成为相关研究的测度目标.基于此, 本文从学术成果的研究主题新颖性着手, 通过文本挖掘技术和方法, 对学术成果的研究主题进行抽取和计算, 构建主题新颖性测度指标, 以期为学术成果的评价提供参考. ...
The History of the Peer-Review Process
1
2002
... 关于学术研究中的主题新颖性的评价方法, 在国际学术界最为通用的就是同行评议, 由于其操作简便易行、结果反馈直接, 因此其应用范围不仅仅局限在包含学术创新性或者研究主题新颖性等在内的学术评价中, 同时在项目管理各环节、人才评价与学位授予等众多方面都有广泛应用.同行评价自身是一种主观的定性评价方法, 该词作为一个术语最早出现于公元9世纪的阿拉伯医学家Al-Ruhawi所著的《医师伦理》之中并展现其评价职能[3 ] , 近代以来, 美国率先使用同行评议方法进行科研项目经费申请的评审, 此后在欧美国家的科研评价中被不断广泛采用[4 ] .总的来说, 同行评议方法已经在学术评价过程中发挥了并依然发挥着重要的作用, 且该作用在当前的学术评价中仍具有不可替代性, 但是同时也暴露出一些问题, 如部分学者认为其基于个人认知的特性有可能会造成评价结果中出现非公正性、非客观性和非合理性等问题的可能性[5 ] .因此为了有效地弥补这一问题, 在当前信息处理技术快速发展的大背景下, 基于数据科学和认知计算的学术评价方法的出现为同行评议过程提供了一定程度上的支撑和参考. ...
基于研究水平的单篇学术论文创新力评价研究
1
2016
... 关于学术研究中的主题新颖性的评价方法, 在国际学术界最为通用的就是同行评议, 由于其操作简便易行、结果反馈直接, 因此其应用范围不仅仅局限在包含学术创新性或者研究主题新颖性等在内的学术评价中, 同时在项目管理各环节、人才评价与学位授予等众多方面都有广泛应用.同行评价自身是一种主观的定性评价方法, 该词作为一个术语最早出现于公元9世纪的阿拉伯医学家Al-Ruhawi所著的《医师伦理》之中并展现其评价职能[3 ] , 近代以来, 美国率先使用同行评议方法进行科研项目经费申请的评审, 此后在欧美国家的科研评价中被不断广泛采用[4 ] .总的来说, 同行评议方法已经在学术评价过程中发挥了并依然发挥着重要的作用, 且该作用在当前的学术评价中仍具有不可替代性, 但是同时也暴露出一些问题, 如部分学者认为其基于个人认知的特性有可能会造成评价结果中出现非公正性、非客观性和非合理性等问题的可能性[5 ] .因此为了有效地弥补这一问题, 在当前信息处理技术快速发展的大背景下, 基于数据科学和认知计算的学术评价方法的出现为同行评议过程提供了一定程度上的支撑和参考. ...
基于研究水平的单篇学术论文创新力评价研究
1
2016
... 关于学术研究中的主题新颖性的评价方法, 在国际学术界最为通用的就是同行评议, 由于其操作简便易行、结果反馈直接, 因此其应用范围不仅仅局限在包含学术创新性或者研究主题新颖性等在内的学术评价中, 同时在项目管理各环节、人才评价与学位授予等众多方面都有广泛应用.同行评价自身是一种主观的定性评价方法, 该词作为一个术语最早出现于公元9世纪的阿拉伯医学家Al-Ruhawi所著的《医师伦理》之中并展现其评价职能[3 ] , 近代以来, 美国率先使用同行评议方法进行科研项目经费申请的评审, 此后在欧美国家的科研评价中被不断广泛采用[4 ] .总的来说, 同行评议方法已经在学术评价过程中发挥了并依然发挥着重要的作用, 且该作用在当前的学术评价中仍具有不可替代性, 但是同时也暴露出一些问题, 如部分学者认为其基于个人认知的特性有可能会造成评价结果中出现非公正性、非客观性和非合理性等问题的可能性[5 ] .因此为了有效地弥补这一问题, 在当前信息处理技术快速发展的大背景下, 基于数据科学和认知计算的学术评价方法的出现为同行评议过程提供了一定程度上的支撑和参考. ...
同行评议制度缺陷的根源及完善机制
1
2008
... 关于学术研究中的主题新颖性的评价方法, 在国际学术界最为通用的就是同行评议, 由于其操作简便易行、结果反馈直接, 因此其应用范围不仅仅局限在包含学术创新性或者研究主题新颖性等在内的学术评价中, 同时在项目管理各环节、人才评价与学位授予等众多方面都有广泛应用.同行评价自身是一种主观的定性评价方法, 该词作为一个术语最早出现于公元9世纪的阿拉伯医学家Al-Ruhawi所著的《医师伦理》之中并展现其评价职能[3 ] , 近代以来, 美国率先使用同行评议方法进行科研项目经费申请的评审, 此后在欧美国家的科研评价中被不断广泛采用[4 ] .总的来说, 同行评议方法已经在学术评价过程中发挥了并依然发挥着重要的作用, 且该作用在当前的学术评价中仍具有不可替代性, 但是同时也暴露出一些问题, 如部分学者认为其基于个人认知的特性有可能会造成评价结果中出现非公正性、非客观性和非合理性等问题的可能性[5 ] .因此为了有效地弥补这一问题, 在当前信息处理技术快速发展的大背景下, 基于数据科学和认知计算的学术评价方法的出现为同行评议过程提供了一定程度上的支撑和参考. ...
同行评议制度缺陷的根源及完善机制
1
2008
... 关于学术研究中的主题新颖性的评价方法, 在国际学术界最为通用的就是同行评议, 由于其操作简便易行、结果反馈直接, 因此其应用范围不仅仅局限在包含学术创新性或者研究主题新颖性等在内的学术评价中, 同时在项目管理各环节、人才评价与学位授予等众多方面都有广泛应用.同行评价自身是一种主观的定性评价方法, 该词作为一个术语最早出现于公元9世纪的阿拉伯医学家Al-Ruhawi所著的《医师伦理》之中并展现其评价职能[3 ] , 近代以来, 美国率先使用同行评议方法进行科研项目经费申请的评审, 此后在欧美国家的科研评价中被不断广泛采用[4 ] .总的来说, 同行评议方法已经在学术评价过程中发挥了并依然发挥着重要的作用, 且该作用在当前的学术评价中仍具有不可替代性, 但是同时也暴露出一些问题, 如部分学者认为其基于个人认知的特性有可能会造成评价结果中出现非公正性、非客观性和非合理性等问题的可能性[5 ] .因此为了有效地弥补这一问题, 在当前信息处理技术快速发展的大背景下, 基于数据科学和认知计算的学术评价方法的出现为同行评议过程提供了一定程度上的支撑和参考. ...
科技创新的一般均衡理论——关于科技成果创新度评价的科学计量学分析
1
2003
... 在基于引文和引用关系的学术成果主题新颖性测度方面, 其理论基础继承自引文分析方法的基本假设, 即学术影响力的重要表现形式之一就是在学术成果发表以后被其他成果引用中体现的, 这一假设在学界中产生广泛影响, 也出现包括影响因子在内的众多基于引文分析的学术影响力与创新性的评价指标, 其中沈律[6 ] 认为在科技成果创新性评价中, 科技成果的创新性与其重复率成反比, 与其被引用情况成正比, 即重复率越高其创新度越低、引用率越高其创新度越高.从另一方面来讲, 引用行为除了是对被引对象的论证之外, 在施引自身也体现其学术研究自我证实的过程, 其中参考文献对施引者在科学研究的继承性、关联性与连续性上的体现也反映了学术成果的创新性、科学性[7 ] .但是近些年来由于学术引用的情况越来越复杂, 导致其在具体应用中偏离学术本身的情况时有出现, 因此这一评价方法的合理性问题也广受质疑和诟病[8 ,9 ] , 众多学者也在研究中都尝试对该方法进行修正和完善.Leydesdorff等[10 ] 认为学术引用应该被进一步区分为长期引用和短期引用, 其中长期引用体现论文的原创性与学术影响, 重在反映学术研究的深度; 短期引用行为则说明学术成果处于研究前沿或研究热点之中, 反映了研究主题的先进性, 也可以理解为新颖性.尚海茹等[11 ] 认为引用行为可以体现学术传播与学术传承, 在此基础上进行基于学术链的学术传承效应, 提出长期传承性引用指标F1和其所处学术链中位置的测度指标F2.鉴于基于引用的评价指标中引用动机的多样性, 吴勤[12 ] 提出引证强度的概念, 综合考虑学术成果被他引次数在该论文质量量化中的正面效应和故意自引行为所可能带来的引证强度放大的负面影响, 并在此基础上建立论文评价数学模型.但是严格来说, 基于引用关系的学术评价实际上只是学术成果在学术影响力上的表层反映或者说不完全反映, 过于重视引文的评价属性会导致其偏离学术成果的实际内容越来越远[13 ] . ...
科技创新的一般均衡理论——关于科技成果创新度评价的科学计量学分析
1
2003
... 在基于引文和引用关系的学术成果主题新颖性测度方面, 其理论基础继承自引文分析方法的基本假设, 即学术影响力的重要表现形式之一就是在学术成果发表以后被其他成果引用中体现的, 这一假设在学界中产生广泛影响, 也出现包括影响因子在内的众多基于引文分析的学术影响力与创新性的评价指标, 其中沈律[6 ] 认为在科技成果创新性评价中, 科技成果的创新性与其重复率成反比, 与其被引用情况成正比, 即重复率越高其创新度越低、引用率越高其创新度越高.从另一方面来讲, 引用行为除了是对被引对象的论证之外, 在施引自身也体现其学术研究自我证实的过程, 其中参考文献对施引者在科学研究的继承性、关联性与连续性上的体现也反映了学术成果的创新性、科学性[7 ] .但是近些年来由于学术引用的情况越来越复杂, 导致其在具体应用中偏离学术本身的情况时有出现, 因此这一评价方法的合理性问题也广受质疑和诟病[8 ,9 ] , 众多学者也在研究中都尝试对该方法进行修正和完善.Leydesdorff等[10 ] 认为学术引用应该被进一步区分为长期引用和短期引用, 其中长期引用体现论文的原创性与学术影响, 重在反映学术研究的深度; 短期引用行为则说明学术成果处于研究前沿或研究热点之中, 反映了研究主题的先进性, 也可以理解为新颖性.尚海茹等[11 ] 认为引用行为可以体现学术传播与学术传承, 在此基础上进行基于学术链的学术传承效应, 提出长期传承性引用指标F1和其所处学术链中位置的测度指标F2.鉴于基于引用的评价指标中引用动机的多样性, 吴勤[12 ] 提出引证强度的概念, 综合考虑学术成果被他引次数在该论文质量量化中的正面效应和故意自引行为所可能带来的引证强度放大的负面影响, 并在此基础上建立论文评价数学模型.但是严格来说, 基于引用关系的学术评价实际上只是学术成果在学术影响力上的表层反映或者说不完全反映, 过于重视引文的评价属性会导致其偏离学术成果的实际内容越来越远[13 ] . ...
参考文献的主要作用与学术论文的创新性评审
1
2004
... 在基于引文和引用关系的学术成果主题新颖性测度方面, 其理论基础继承自引文分析方法的基本假设, 即学术影响力的重要表现形式之一就是在学术成果发表以后被其他成果引用中体现的, 这一假设在学界中产生广泛影响, 也出现包括影响因子在内的众多基于引文分析的学术影响力与创新性的评价指标, 其中沈律[6 ] 认为在科技成果创新性评价中, 科技成果的创新性与其重复率成反比, 与其被引用情况成正比, 即重复率越高其创新度越低、引用率越高其创新度越高.从另一方面来讲, 引用行为除了是对被引对象的论证之外, 在施引自身也体现其学术研究自我证实的过程, 其中参考文献对施引者在科学研究的继承性、关联性与连续性上的体现也反映了学术成果的创新性、科学性[7 ] .但是近些年来由于学术引用的情况越来越复杂, 导致其在具体应用中偏离学术本身的情况时有出现, 因此这一评价方法的合理性问题也广受质疑和诟病[8 ,9 ] , 众多学者也在研究中都尝试对该方法进行修正和完善.Leydesdorff等[10 ] 认为学术引用应该被进一步区分为长期引用和短期引用, 其中长期引用体现论文的原创性与学术影响, 重在反映学术研究的深度; 短期引用行为则说明学术成果处于研究前沿或研究热点之中, 反映了研究主题的先进性, 也可以理解为新颖性.尚海茹等[11 ] 认为引用行为可以体现学术传播与学术传承, 在此基础上进行基于学术链的学术传承效应, 提出长期传承性引用指标F1和其所处学术链中位置的测度指标F2.鉴于基于引用的评价指标中引用动机的多样性, 吴勤[12 ] 提出引证强度的概念, 综合考虑学术成果被他引次数在该论文质量量化中的正面效应和故意自引行为所可能带来的引证强度放大的负面影响, 并在此基础上建立论文评价数学模型.但是严格来说, 基于引用关系的学术评价实际上只是学术成果在学术影响力上的表层反映或者说不完全反映, 过于重视引文的评价属性会导致其偏离学术成果的实际内容越来越远[13 ] . ...
参考文献的主要作用与学术论文的创新性评审
1
2004
... 在基于引文和引用关系的学术成果主题新颖性测度方面, 其理论基础继承自引文分析方法的基本假设, 即学术影响力的重要表现形式之一就是在学术成果发表以后被其他成果引用中体现的, 这一假设在学界中产生广泛影响, 也出现包括影响因子在内的众多基于引文分析的学术影响力与创新性的评价指标, 其中沈律[6 ] 认为在科技成果创新性评价中, 科技成果的创新性与其重复率成反比, 与其被引用情况成正比, 即重复率越高其创新度越低、引用率越高其创新度越高.从另一方面来讲, 引用行为除了是对被引对象的论证之外, 在施引自身也体现其学术研究自我证实的过程, 其中参考文献对施引者在科学研究的继承性、关联性与连续性上的体现也反映了学术成果的创新性、科学性[7 ] .但是近些年来由于学术引用的情况越来越复杂, 导致其在具体应用中偏离学术本身的情况时有出现, 因此这一评价方法的合理性问题也广受质疑和诟病[8 ,9 ] , 众多学者也在研究中都尝试对该方法进行修正和完善.Leydesdorff等[10 ] 认为学术引用应该被进一步区分为长期引用和短期引用, 其中长期引用体现论文的原创性与学术影响, 重在反映学术研究的深度; 短期引用行为则说明学术成果处于研究前沿或研究热点之中, 反映了研究主题的先进性, 也可以理解为新颖性.尚海茹等[11 ] 认为引用行为可以体现学术传播与学术传承, 在此基础上进行基于学术链的学术传承效应, 提出长期传承性引用指标F1和其所处学术链中位置的测度指标F2.鉴于基于引用的评价指标中引用动机的多样性, 吴勤[12 ] 提出引证强度的概念, 综合考虑学术成果被他引次数在该论文质量量化中的正面效应和故意自引行为所可能带来的引证强度放大的负面影响, 并在此基础上建立论文评价数学模型.但是严格来说, 基于引用关系的学术评价实际上只是学术成果在学术影响力上的表层反映或者说不完全反映, 过于重视引文的评价属性会导致其偏离学术成果的实际内容越来越远[13 ] . ...
SCI量化评价功能的局限性及其修正
1
2009
... 在基于引文和引用关系的学术成果主题新颖性测度方面, 其理论基础继承自引文分析方法的基本假设, 即学术影响力的重要表现形式之一就是在学术成果发表以后被其他成果引用中体现的, 这一假设在学界中产生广泛影响, 也出现包括影响因子在内的众多基于引文分析的学术影响力与创新性的评价指标, 其中沈律[6 ] 认为在科技成果创新性评价中, 科技成果的创新性与其重复率成反比, 与其被引用情况成正比, 即重复率越高其创新度越低、引用率越高其创新度越高.从另一方面来讲, 引用行为除了是对被引对象的论证之外, 在施引自身也体现其学术研究自我证实的过程, 其中参考文献对施引者在科学研究的继承性、关联性与连续性上的体现也反映了学术成果的创新性、科学性[7 ] .但是近些年来由于学术引用的情况越来越复杂, 导致其在具体应用中偏离学术本身的情况时有出现, 因此这一评价方法的合理性问题也广受质疑和诟病[8 ,9 ] , 众多学者也在研究中都尝试对该方法进行修正和完善.Leydesdorff等[10 ] 认为学术引用应该被进一步区分为长期引用和短期引用, 其中长期引用体现论文的原创性与学术影响, 重在反映学术研究的深度; 短期引用行为则说明学术成果处于研究前沿或研究热点之中, 反映了研究主题的先进性, 也可以理解为新颖性.尚海茹等[11 ] 认为引用行为可以体现学术传播与学术传承, 在此基础上进行基于学术链的学术传承效应, 提出长期传承性引用指标F1和其所处学术链中位置的测度指标F2.鉴于基于引用的评价指标中引用动机的多样性, 吴勤[12 ] 提出引证强度的概念, 综合考虑学术成果被他引次数在该论文质量量化中的正面效应和故意自引行为所可能带来的引证强度放大的负面影响, 并在此基础上建立论文评价数学模型.但是严格来说, 基于引用关系的学术评价实际上只是学术成果在学术影响力上的表层反映或者说不完全反映, 过于重视引文的评价属性会导致其偏离学术成果的实际内容越来越远[13 ] . ...
SCI量化评价功能的局限性及其修正
1
2009
... 在基于引文和引用关系的学术成果主题新颖性测度方面, 其理论基础继承自引文分析方法的基本假设, 即学术影响力的重要表现形式之一就是在学术成果发表以后被其他成果引用中体现的, 这一假设在学界中产生广泛影响, 也出现包括影响因子在内的众多基于引文分析的学术影响力与创新性的评价指标, 其中沈律[6 ] 认为在科技成果创新性评价中, 科技成果的创新性与其重复率成反比, 与其被引用情况成正比, 即重复率越高其创新度越低、引用率越高其创新度越高.从另一方面来讲, 引用行为除了是对被引对象的论证之外, 在施引自身也体现其学术研究自我证实的过程, 其中参考文献对施引者在科学研究的继承性、关联性与连续性上的体现也反映了学术成果的创新性、科学性[7 ] .但是近些年来由于学术引用的情况越来越复杂, 导致其在具体应用中偏离学术本身的情况时有出现, 因此这一评价方法的合理性问题也广受质疑和诟病[8 ,9 ] , 众多学者也在研究中都尝试对该方法进行修正和完善.Leydesdorff等[10 ] 认为学术引用应该被进一步区分为长期引用和短期引用, 其中长期引用体现论文的原创性与学术影响, 重在反映学术研究的深度; 短期引用行为则说明学术成果处于研究前沿或研究热点之中, 反映了研究主题的先进性, 也可以理解为新颖性.尚海茹等[11 ] 认为引用行为可以体现学术传播与学术传承, 在此基础上进行基于学术链的学术传承效应, 提出长期传承性引用指标F1和其所处学术链中位置的测度指标F2.鉴于基于引用的评价指标中引用动机的多样性, 吴勤[12 ] 提出引证强度的概念, 综合考虑学术成果被他引次数在该论文质量量化中的正面效应和故意自引行为所可能带来的引证强度放大的负面影响, 并在此基础上建立论文评价数学模型.但是严格来说, 基于引用关系的学术评价实际上只是学术成果在学术影响力上的表层反映或者说不完全反映, 过于重视引文的评价属性会导致其偏离学术成果的实际内容越来越远[13 ] . ...
Why the Impact Factor of Journals Should Not Be Used for Evaluating Research
1
1997
... 在基于引文和引用关系的学术成果主题新颖性测度方面, 其理论基础继承自引文分析方法的基本假设, 即学术影响力的重要表现形式之一就是在学术成果发表以后被其他成果引用中体现的, 这一假设在学界中产生广泛影响, 也出现包括影响因子在内的众多基于引文分析的学术影响力与创新性的评价指标, 其中沈律[6 ] 认为在科技成果创新性评价中, 科技成果的创新性与其重复率成反比, 与其被引用情况成正比, 即重复率越高其创新度越低、引用率越高其创新度越高.从另一方面来讲, 引用行为除了是对被引对象的论证之外, 在施引自身也体现其学术研究自我证实的过程, 其中参考文献对施引者在科学研究的继承性、关联性与连续性上的体现也反映了学术成果的创新性、科学性[7 ] .但是近些年来由于学术引用的情况越来越复杂, 导致其在具体应用中偏离学术本身的情况时有出现, 因此这一评价方法的合理性问题也广受质疑和诟病[8 ,9 ] , 众多学者也在研究中都尝试对该方法进行修正和完善.Leydesdorff等[10 ] 认为学术引用应该被进一步区分为长期引用和短期引用, 其中长期引用体现论文的原创性与学术影响, 重在反映学术研究的深度; 短期引用行为则说明学术成果处于研究前沿或研究热点之中, 反映了研究主题的先进性, 也可以理解为新颖性.尚海茹等[11 ] 认为引用行为可以体现学术传播与学术传承, 在此基础上进行基于学术链的学术传承效应, 提出长期传承性引用指标F1和其所处学术链中位置的测度指标F2.鉴于基于引用的评价指标中引用动机的多样性, 吴勤[12 ] 提出引证强度的概念, 综合考虑学术成果被他引次数在该论文质量量化中的正面效应和故意自引行为所可能带来的引证强度放大的负面影响, 并在此基础上建立论文评价数学模型.但是严格来说, 基于引用关系的学术评价实际上只是学术成果在学术影响力上的表层反映或者说不完全反映, 过于重视引文的评价属性会导致其偏离学术成果的实际内容越来越远[13 ] . ...
Citations: Indicators of Quality? The Impact Fallacy
1
2016
... 在基于引文和引用关系的学术成果主题新颖性测度方面, 其理论基础继承自引文分析方法的基本假设, 即学术影响力的重要表现形式之一就是在学术成果发表以后被其他成果引用中体现的, 这一假设在学界中产生广泛影响, 也出现包括影响因子在内的众多基于引文分析的学术影响力与创新性的评价指标, 其中沈律[6 ] 认为在科技成果创新性评价中, 科技成果的创新性与其重复率成反比, 与其被引用情况成正比, 即重复率越高其创新度越低、引用率越高其创新度越高.从另一方面来讲, 引用行为除了是对被引对象的论证之外, 在施引自身也体现其学术研究自我证实的过程, 其中参考文献对施引者在科学研究的继承性、关联性与连续性上的体现也反映了学术成果的创新性、科学性[7 ] .但是近些年来由于学术引用的情况越来越复杂, 导致其在具体应用中偏离学术本身的情况时有出现, 因此这一评价方法的合理性问题也广受质疑和诟病[8 ,9 ] , 众多学者也在研究中都尝试对该方法进行修正和完善.Leydesdorff等[10 ] 认为学术引用应该被进一步区分为长期引用和短期引用, 其中长期引用体现论文的原创性与学术影响, 重在反映学术研究的深度; 短期引用行为则说明学术成果处于研究前沿或研究热点之中, 反映了研究主题的先进性, 也可以理解为新颖性.尚海茹等[11 ] 认为引用行为可以体现学术传播与学术传承, 在此基础上进行基于学术链的学术传承效应, 提出长期传承性引用指标F1和其所处学术链中位置的测度指标F2.鉴于基于引用的评价指标中引用动机的多样性, 吴勤[12 ] 提出引证强度的概念, 综合考虑学术成果被他引次数在该论文质量量化中的正面效应和故意自引行为所可能带来的引证强度放大的负面影响, 并在此基础上建立论文评价数学模型.但是严格来说, 基于引用关系的学术评价实际上只是学术成果在学术影响力上的表层反映或者说不完全反映, 过于重视引文的评价属性会导致其偏离学术成果的实际内容越来越远[13 ] . ...
用学术影响力评价学术论文——兼论关于学术传承效应和长期引用的两个新指标
1
2016
... 在基于引文和引用关系的学术成果主题新颖性测度方面, 其理论基础继承自引文分析方法的基本假设, 即学术影响力的重要表现形式之一就是在学术成果发表以后被其他成果引用中体现的, 这一假设在学界中产生广泛影响, 也出现包括影响因子在内的众多基于引文分析的学术影响力与创新性的评价指标, 其中沈律[6 ] 认为在科技成果创新性评价中, 科技成果的创新性与其重复率成反比, 与其被引用情况成正比, 即重复率越高其创新度越低、引用率越高其创新度越高.从另一方面来讲, 引用行为除了是对被引对象的论证之外, 在施引自身也体现其学术研究自我证实的过程, 其中参考文献对施引者在科学研究的继承性、关联性与连续性上的体现也反映了学术成果的创新性、科学性[7 ] .但是近些年来由于学术引用的情况越来越复杂, 导致其在具体应用中偏离学术本身的情况时有出现, 因此这一评价方法的合理性问题也广受质疑和诟病[8 ,9 ] , 众多学者也在研究中都尝试对该方法进行修正和完善.Leydesdorff等[10 ] 认为学术引用应该被进一步区分为长期引用和短期引用, 其中长期引用体现论文的原创性与学术影响, 重在反映学术研究的深度; 短期引用行为则说明学术成果处于研究前沿或研究热点之中, 反映了研究主题的先进性, 也可以理解为新颖性.尚海茹等[11 ] 认为引用行为可以体现学术传播与学术传承, 在此基础上进行基于学术链的学术传承效应, 提出长期传承性引用指标F1和其所处学术链中位置的测度指标F2.鉴于基于引用的评价指标中引用动机的多样性, 吴勤[12 ] 提出引证强度的概念, 综合考虑学术成果被他引次数在该论文质量量化中的正面效应和故意自引行为所可能带来的引证强度放大的负面影响, 并在此基础上建立论文评价数学模型.但是严格来说, 基于引用关系的学术评价实际上只是学术成果在学术影响力上的表层反映或者说不完全反映, 过于重视引文的评价属性会导致其偏离学术成果的实际内容越来越远[13 ] . ...
用学术影响力评价学术论文——兼论关于学术传承效应和长期引用的两个新指标
1
2016
... 在基于引文和引用关系的学术成果主题新颖性测度方面, 其理论基础继承自引文分析方法的基本假设, 即学术影响力的重要表现形式之一就是在学术成果发表以后被其他成果引用中体现的, 这一假设在学界中产生广泛影响, 也出现包括影响因子在内的众多基于引文分析的学术影响力与创新性的评价指标, 其中沈律[6 ] 认为在科技成果创新性评价中, 科技成果的创新性与其重复率成反比, 与其被引用情况成正比, 即重复率越高其创新度越低、引用率越高其创新度越高.从另一方面来讲, 引用行为除了是对被引对象的论证之外, 在施引自身也体现其学术研究自我证实的过程, 其中参考文献对施引者在科学研究的继承性、关联性与连续性上的体现也反映了学术成果的创新性、科学性[7 ] .但是近些年来由于学术引用的情况越来越复杂, 导致其在具体应用中偏离学术本身的情况时有出现, 因此这一评价方法的合理性问题也广受质疑和诟病[8 ,9 ] , 众多学者也在研究中都尝试对该方法进行修正和完善.Leydesdorff等[10 ] 认为学术引用应该被进一步区分为长期引用和短期引用, 其中长期引用体现论文的原创性与学术影响, 重在反映学术研究的深度; 短期引用行为则说明学术成果处于研究前沿或研究热点之中, 反映了研究主题的先进性, 也可以理解为新颖性.尚海茹等[11 ] 认为引用行为可以体现学术传播与学术传承, 在此基础上进行基于学术链的学术传承效应, 提出长期传承性引用指标F1和其所处学术链中位置的测度指标F2.鉴于基于引用的评价指标中引用动机的多样性, 吴勤[12 ] 提出引证强度的概念, 综合考虑学术成果被他引次数在该论文质量量化中的正面效应和故意自引行为所可能带来的引证强度放大的负面影响, 并在此基础上建立论文评价数学模型.但是严格来说, 基于引用关系的学术评价实际上只是学术成果在学术影响力上的表层反映或者说不完全反映, 过于重视引文的评价属性会导致其偏离学术成果的实际内容越来越远[13 ] . ...
基于引证强度的学术论文质量评价方法研究
1
2007
... 在基于引文和引用关系的学术成果主题新颖性测度方面, 其理论基础继承自引文分析方法的基本假设, 即学术影响力的重要表现形式之一就是在学术成果发表以后被其他成果引用中体现的, 这一假设在学界中产生广泛影响, 也出现包括影响因子在内的众多基于引文分析的学术影响力与创新性的评价指标, 其中沈律[6 ] 认为在科技成果创新性评价中, 科技成果的创新性与其重复率成反比, 与其被引用情况成正比, 即重复率越高其创新度越低、引用率越高其创新度越高.从另一方面来讲, 引用行为除了是对被引对象的论证之外, 在施引自身也体现其学术研究自我证实的过程, 其中参考文献对施引者在科学研究的继承性、关联性与连续性上的体现也反映了学术成果的创新性、科学性[7 ] .但是近些年来由于学术引用的情况越来越复杂, 导致其在具体应用中偏离学术本身的情况时有出现, 因此这一评价方法的合理性问题也广受质疑和诟病[8 ,9 ] , 众多学者也在研究中都尝试对该方法进行修正和完善.Leydesdorff等[10 ] 认为学术引用应该被进一步区分为长期引用和短期引用, 其中长期引用体现论文的原创性与学术影响, 重在反映学术研究的深度; 短期引用行为则说明学术成果处于研究前沿或研究热点之中, 反映了研究主题的先进性, 也可以理解为新颖性.尚海茹等[11 ] 认为引用行为可以体现学术传播与学术传承, 在此基础上进行基于学术链的学术传承效应, 提出长期传承性引用指标F1和其所处学术链中位置的测度指标F2.鉴于基于引用的评价指标中引用动机的多样性, 吴勤[12 ] 提出引证强度的概念, 综合考虑学术成果被他引次数在该论文质量量化中的正面效应和故意自引行为所可能带来的引证强度放大的负面影响, 并在此基础上建立论文评价数学模型.但是严格来说, 基于引用关系的学术评价实际上只是学术成果在学术影响力上的表层反映或者说不完全反映, 过于重视引文的评价属性会导致其偏离学术成果的实际内容越来越远[13 ] . ...
基于引证强度的学术论文质量评价方法研究
1
2007
... 在基于引文和引用关系的学术成果主题新颖性测度方面, 其理论基础继承自引文分析方法的基本假设, 即学术影响力的重要表现形式之一就是在学术成果发表以后被其他成果引用中体现的, 这一假设在学界中产生广泛影响, 也出现包括影响因子在内的众多基于引文分析的学术影响力与创新性的评价指标, 其中沈律[6 ] 认为在科技成果创新性评价中, 科技成果的创新性与其重复率成反比, 与其被引用情况成正比, 即重复率越高其创新度越低、引用率越高其创新度越高.从另一方面来讲, 引用行为除了是对被引对象的论证之外, 在施引自身也体现其学术研究自我证实的过程, 其中参考文献对施引者在科学研究的继承性、关联性与连续性上的体现也反映了学术成果的创新性、科学性[7 ] .但是近些年来由于学术引用的情况越来越复杂, 导致其在具体应用中偏离学术本身的情况时有出现, 因此这一评价方法的合理性问题也广受质疑和诟病[8 ,9 ] , 众多学者也在研究中都尝试对该方法进行修正和完善.Leydesdorff等[10 ] 认为学术引用应该被进一步区分为长期引用和短期引用, 其中长期引用体现论文的原创性与学术影响, 重在反映学术研究的深度; 短期引用行为则说明学术成果处于研究前沿或研究热点之中, 反映了研究主题的先进性, 也可以理解为新颖性.尚海茹等[11 ] 认为引用行为可以体现学术传播与学术传承, 在此基础上进行基于学术链的学术传承效应, 提出长期传承性引用指标F1和其所处学术链中位置的测度指标F2.鉴于基于引用的评价指标中引用动机的多样性, 吴勤[12 ] 提出引证强度的概念, 综合考虑学术成果被他引次数在该论文质量量化中的正面效应和故意自引行为所可能带来的引证强度放大的负面影响, 并在此基础上建立论文评价数学模型.但是严格来说, 基于引用关系的学术评价实际上只是学术成果在学术影响力上的表层反映或者说不完全反映, 过于重视引文的评价属性会导致其偏离学术成果的实际内容越来越远[13 ] . ...
An Index to Quantify an Individual’s Scientific Research Output
1
2005
... 在基于引文和引用关系的学术成果主题新颖性测度方面, 其理论基础继承自引文分析方法的基本假设, 即学术影响力的重要表现形式之一就是在学术成果发表以后被其他成果引用中体现的, 这一假设在学界中产生广泛影响, 也出现包括影响因子在内的众多基于引文分析的学术影响力与创新性的评价指标, 其中沈律[6 ] 认为在科技成果创新性评价中, 科技成果的创新性与其重复率成反比, 与其被引用情况成正比, 即重复率越高其创新度越低、引用率越高其创新度越高.从另一方面来讲, 引用行为除了是对被引对象的论证之外, 在施引自身也体现其学术研究自我证实的过程, 其中参考文献对施引者在科学研究的继承性、关联性与连续性上的体现也反映了学术成果的创新性、科学性[7 ] .但是近些年来由于学术引用的情况越来越复杂, 导致其在具体应用中偏离学术本身的情况时有出现, 因此这一评价方法的合理性问题也广受质疑和诟病[8 ,9 ] , 众多学者也在研究中都尝试对该方法进行修正和完善.Leydesdorff等[10 ] 认为学术引用应该被进一步区分为长期引用和短期引用, 其中长期引用体现论文的原创性与学术影响, 重在反映学术研究的深度; 短期引用行为则说明学术成果处于研究前沿或研究热点之中, 反映了研究主题的先进性, 也可以理解为新颖性.尚海茹等[11 ] 认为引用行为可以体现学术传播与学术传承, 在此基础上进行基于学术链的学术传承效应, 提出长期传承性引用指标F1和其所处学术链中位置的测度指标F2.鉴于基于引用的评价指标中引用动机的多样性, 吴勤[12 ] 提出引证强度的概念, 综合考虑学术成果被他引次数在该论文质量量化中的正面效应和故意自引行为所可能带来的引证强度放大的负面影响, 并在此基础上建立论文评价数学模型.但是严格来说, 基于引用关系的学术评价实际上只是学术成果在学术影响力上的表层反映或者说不完全反映, 过于重视引文的评价属性会导致其偏离学术成果的实际内容越来越远[13 ] . ...
一种基于关键词的创新度评价方法
1
2007
... 由于上述基于引文的学术创新性评价的局限性, 这一领域的研究人员开始将目光转向学术成果本身, 通过对学术成果的内容分析与挖掘构建学术成果的研究主题新颖性测度指标, 从而展示学术研究内容间的差异.沈阳[14 ] 通过对关键词的挖掘与计算, 构建基于关键词在文中出现的频率、被用户检索的频率、使用的时间跨度及用户对关键词的创新度评价指标, 以此反映学术成果的创新度.虽然关键词可以在一定程度上反映学术成果中包含的重要主题、概念、思想、模型或方法, 但是使用单个关键词仍然不足以准确刻画和反映学术成果的主题新颖性, 在此基础上, 钱玲飞、杨建林等[15 ,16 ] 研究认为学科交叉程度与其学科创新性之间有较强的正向联系, 学科交叉程度越高, 其具有较高创新度的可能性就越大, 通过构建关键词的交叉率量化研究学科的创新能力, 并在此基础上基于关键词对间的共现关系进一步研究和构建文档的主题新颖度指标.在技术创新性研究领域, 研究者通过对专利文本特征、技术术语的提取和文本特征相似度的计算, 描述专利技术文本间的差异性, 其相似度越小, 则该专利间的技术差异越大、内容越新、专利价值越高[17 ] .刘玉琴等[18 ] 使用该方法计算专利相似度, 并在此基础上量化地研究了技术的新颖度, 构建了在相似性水平阈值α 上的技术新颖度测算指标, 并在此基础上进一步构建相似水平阈值α 上m件专利的平均技术新颖度, 用于评价某段时间内专利群体的总体价值和技术新颖性. ...
一种基于关键词的创新度评价方法
1
2007
... 由于上述基于引文的学术创新性评价的局限性, 这一领域的研究人员开始将目光转向学术成果本身, 通过对学术成果的内容分析与挖掘构建学术成果的研究主题新颖性测度指标, 从而展示学术研究内容间的差异.沈阳[14 ] 通过对关键词的挖掘与计算, 构建基于关键词在文中出现的频率、被用户检索的频率、使用的时间跨度及用户对关键词的创新度评价指标, 以此反映学术成果的创新度.虽然关键词可以在一定程度上反映学术成果中包含的重要主题、概念、思想、模型或方法, 但是使用单个关键词仍然不足以准确刻画和反映学术成果的主题新颖性, 在此基础上, 钱玲飞、杨建林等[15 ,16 ] 研究认为学科交叉程度与其学科创新性之间有较强的正向联系, 学科交叉程度越高, 其具有较高创新度的可能性就越大, 通过构建关键词的交叉率量化研究学科的创新能力, 并在此基础上基于关键词对间的共现关系进一步研究和构建文档的主题新颖度指标.在技术创新性研究领域, 研究者通过对专利文本特征、技术术语的提取和文本特征相似度的计算, 描述专利技术文本间的差异性, 其相似度越小, 则该专利间的技术差异越大、内容越新、专利价值越高[17 ] .刘玉琴等[18 ] 使用该方法计算专利相似度, 并在此基础上量化地研究了技术的新颖度, 构建了在相似性水平阈值α 上的技术新颖度测算指标, 并在此基础上进一步构建相似水平阈值α 上m件专利的平均技术新颖度, 用于评价某段时间内专利群体的总体价值和技术新颖性. ...
基于关键词分析的学科创新力比较——以情报学图书馆学为例
1
2011
... 由于上述基于引文的学术创新性评价的局限性, 这一领域的研究人员开始将目光转向学术成果本身, 通过对学术成果的内容分析与挖掘构建学术成果的研究主题新颖性测度指标, 从而展示学术研究内容间的差异.沈阳[14 ] 通过对关键词的挖掘与计算, 构建基于关键词在文中出现的频率、被用户检索的频率、使用的时间跨度及用户对关键词的创新度评价指标, 以此反映学术成果的创新度.虽然关键词可以在一定程度上反映学术成果中包含的重要主题、概念、思想、模型或方法, 但是使用单个关键词仍然不足以准确刻画和反映学术成果的主题新颖性, 在此基础上, 钱玲飞、杨建林等[15 ,16 ] 研究认为学科交叉程度与其学科创新性之间有较强的正向联系, 学科交叉程度越高, 其具有较高创新度的可能性就越大, 通过构建关键词的交叉率量化研究学科的创新能力, 并在此基础上基于关键词对间的共现关系进一步研究和构建文档的主题新颖度指标.在技术创新性研究领域, 研究者通过对专利文本特征、技术术语的提取和文本特征相似度的计算, 描述专利技术文本间的差异性, 其相似度越小, 则该专利间的技术差异越大、内容越新、专利价值越高[17 ] .刘玉琴等[18 ] 使用该方法计算专利相似度, 并在此基础上量化地研究了技术的新颖度, 构建了在相似性水平阈值α 上的技术新颖度测算指标, 并在此基础上进一步构建相似水平阈值α 上m件专利的平均技术新颖度, 用于评价某段时间内专利群体的总体价值和技术新颖性. ...
基于关键词分析的学科创新力比较——以情报学图书馆学为例
1
2011
... 由于上述基于引文的学术创新性评价的局限性, 这一领域的研究人员开始将目光转向学术成果本身, 通过对学术成果的内容分析与挖掘构建学术成果的研究主题新颖性测度指标, 从而展示学术研究内容间的差异.沈阳[14 ] 通过对关键词的挖掘与计算, 构建基于关键词在文中出现的频率、被用户检索的频率、使用的时间跨度及用户对关键词的创新度评价指标, 以此反映学术成果的创新度.虽然关键词可以在一定程度上反映学术成果中包含的重要主题、概念、思想、模型或方法, 但是使用单个关键词仍然不足以准确刻画和反映学术成果的主题新颖性, 在此基础上, 钱玲飞、杨建林等[15 ,16 ] 研究认为学科交叉程度与其学科创新性之间有较强的正向联系, 学科交叉程度越高, 其具有较高创新度的可能性就越大, 通过构建关键词的交叉率量化研究学科的创新能力, 并在此基础上基于关键词对间的共现关系进一步研究和构建文档的主题新颖度指标.在技术创新性研究领域, 研究者通过对专利文本特征、技术术语的提取和文本特征相似度的计算, 描述专利技术文本间的差异性, 其相似度越小, 则该专利间的技术差异越大、内容越新、专利价值越高[17 ] .刘玉琴等[18 ] 使用该方法计算专利相似度, 并在此基础上量化地研究了技术的新颖度, 构建了在相似性水平阈值α 上的技术新颖度测算指标, 并在此基础上进一步构建相似水平阈值α 上m件专利的平均技术新颖度, 用于评价某段时间内专利群体的总体价值和技术新颖性. ...
基于关键词对逆文档频率的主题新颖度度量方法
1
2013
... 由于上述基于引文的学术创新性评价的局限性, 这一领域的研究人员开始将目光转向学术成果本身, 通过对学术成果的内容分析与挖掘构建学术成果的研究主题新颖性测度指标, 从而展示学术研究内容间的差异.沈阳[14 ] 通过对关键词的挖掘与计算, 构建基于关键词在文中出现的频率、被用户检索的频率、使用的时间跨度及用户对关键词的创新度评价指标, 以此反映学术成果的创新度.虽然关键词可以在一定程度上反映学术成果中包含的重要主题、概念、思想、模型或方法, 但是使用单个关键词仍然不足以准确刻画和反映学术成果的主题新颖性, 在此基础上, 钱玲飞、杨建林等[15 ,16 ] 研究认为学科交叉程度与其学科创新性之间有较强的正向联系, 学科交叉程度越高, 其具有较高创新度的可能性就越大, 通过构建关键词的交叉率量化研究学科的创新能力, 并在此基础上基于关键词对间的共现关系进一步研究和构建文档的主题新颖度指标.在技术创新性研究领域, 研究者通过对专利文本特征、技术术语的提取和文本特征相似度的计算, 描述专利技术文本间的差异性, 其相似度越小, 则该专利间的技术差异越大、内容越新、专利价值越高[17 ] .刘玉琴等[18 ] 使用该方法计算专利相似度, 并在此基础上量化地研究了技术的新颖度, 构建了在相似性水平阈值α 上的技术新颖度测算指标, 并在此基础上进一步构建相似水平阈值α 上m件专利的平均技术新颖度, 用于评价某段时间内专利群体的总体价值和技术新颖性. ...
基于关键词对逆文档频率的主题新颖度度量方法
1
2013
... 由于上述基于引文的学术创新性评价的局限性, 这一领域的研究人员开始将目光转向学术成果本身, 通过对学术成果的内容分析与挖掘构建学术成果的研究主题新颖性测度指标, 从而展示学术研究内容间的差异.沈阳[14 ] 通过对关键词的挖掘与计算, 构建基于关键词在文中出现的频率、被用户检索的频率、使用的时间跨度及用户对关键词的创新度评价指标, 以此反映学术成果的创新度.虽然关键词可以在一定程度上反映学术成果中包含的重要主题、概念、思想、模型或方法, 但是使用单个关键词仍然不足以准确刻画和反映学术成果的主题新颖性, 在此基础上, 钱玲飞、杨建林等[15 ,16 ] 研究认为学科交叉程度与其学科创新性之间有较强的正向联系, 学科交叉程度越高, 其具有较高创新度的可能性就越大, 通过构建关键词的交叉率量化研究学科的创新能力, 并在此基础上基于关键词对间的共现关系进一步研究和构建文档的主题新颖度指标.在技术创新性研究领域, 研究者通过对专利文本特征、技术术语的提取和文本特征相似度的计算, 描述专利技术文本间的差异性, 其相似度越小, 则该专利间的技术差异越大、内容越新、专利价值越高[17 ] .刘玉琴等[18 ] 使用该方法计算专利相似度, 并在此基础上量化地研究了技术的新颖度, 构建了在相似性水平阈值α 上的技术新颖度测算指标, 并在此基础上进一步构建相似水平阈值α 上m件专利的平均技术新颖度, 用于评价某段时间内专利群体的总体价值和技术新颖性. ...
Proposal of Two-stage Patent Retrieval Method Considering the Claim Structure
1
2005
... 由于上述基于引文的学术创新性评价的局限性, 这一领域的研究人员开始将目光转向学术成果本身, 通过对学术成果的内容分析与挖掘构建学术成果的研究主题新颖性测度指标, 从而展示学术研究内容间的差异.沈阳[14 ] 通过对关键词的挖掘与计算, 构建基于关键词在文中出现的频率、被用户检索的频率、使用的时间跨度及用户对关键词的创新度评价指标, 以此反映学术成果的创新度.虽然关键词可以在一定程度上反映学术成果中包含的重要主题、概念、思想、模型或方法, 但是使用单个关键词仍然不足以准确刻画和反映学术成果的主题新颖性, 在此基础上, 钱玲飞、杨建林等[15 ,16 ] 研究认为学科交叉程度与其学科创新性之间有较强的正向联系, 学科交叉程度越高, 其具有较高创新度的可能性就越大, 通过构建关键词的交叉率量化研究学科的创新能力, 并在此基础上基于关键词对间的共现关系进一步研究和构建文档的主题新颖度指标.在技术创新性研究领域, 研究者通过对专利文本特征、技术术语的提取和文本特征相似度的计算, 描述专利技术文本间的差异性, 其相似度越小, 则该专利间的技术差异越大、内容越新、专利价值越高[17 ] .刘玉琴等[18 ] 使用该方法计算专利相似度, 并在此基础上量化地研究了技术的新颖度, 构建了在相似性水平阈值α 上的技术新颖度测算指标, 并在此基础上进一步构建相似水平阈值α 上m件专利的平均技术新颖度, 用于评价某段时间内专利群体的总体价值和技术新颖性. ...
基于文本挖掘技术的产品技术成熟度预测
7
2008
... 由于上述基于引文的学术创新性评价的局限性, 这一领域的研究人员开始将目光转向学术成果本身, 通过对学术成果的内容分析与挖掘构建学术成果的研究主题新颖性测度指标, 从而展示学术研究内容间的差异.沈阳[14 ] 通过对关键词的挖掘与计算, 构建基于关键词在文中出现的频率、被用户检索的频率、使用的时间跨度及用户对关键词的创新度评价指标, 以此反映学术成果的创新度.虽然关键词可以在一定程度上反映学术成果中包含的重要主题、概念、思想、模型或方法, 但是使用单个关键词仍然不足以准确刻画和反映学术成果的主题新颖性, 在此基础上, 钱玲飞、杨建林等[15 ,16 ] 研究认为学科交叉程度与其学科创新性之间有较强的正向联系, 学科交叉程度越高, 其具有较高创新度的可能性就越大, 通过构建关键词的交叉率量化研究学科的创新能力, 并在此基础上基于关键词对间的共现关系进一步研究和构建文档的主题新颖度指标.在技术创新性研究领域, 研究者通过对专利文本特征、技术术语的提取和文本特征相似度的计算, 描述专利技术文本间的差异性, 其相似度越小, 则该专利间的技术差异越大、内容越新、专利价值越高[17 ] .刘玉琴等[18 ] 使用该方法计算专利相似度, 并在此基础上量化地研究了技术的新颖度, 构建了在相似性水平阈值α 上的技术新颖度测算指标, 并在此基础上进一步构建相似水平阈值α 上m件专利的平均技术新颖度, 用于评价某段时间内专利群体的总体价值和技术新颖性. ...
... 为测试上述指标和方法的有效性, 本文选取国内情报学期刊中的相关学术论文进行主题新颖性测度.中国社会科学院发布的《中国人文社会科学期刊评价报告》[27 ] 显示, 《情报学报》在情报学期刊中的排名相对较高, 因此本文假定期刊评价排名与期刊质量、期刊质量与期刊论文的主题新颖性之间存在一定的相关关系.为加强对比效果且使测试样本具有横向可比性, 选取《情报学报》(简称QBXB)、《情报科学》(简称QBKX)和《情报杂志》(简称QBZZ)三本期刊上的2014年度所刊载的全部学术论文(928 篇)作为测度对象.对所选样本集内的文档进行两两相似度计算从而构建文档相似度矩阵, 在此基础上计算各个文档的内容特征因子和主题新颖性指数, 并通过计算和对比各刊刊载论文的新颖性指数的平均值, 验证本文构建的新颖性指数是否与期刊质量之间存在正相关关系.同时为了进一步加强对比效果.在计算文档相似度过程中, 分别采用Doc2Vec模型和TFIDF模型对文档相似度进行计算.此外, 为了验证基于文档相似度和内容特征因子的主题新颖性指数的有效性, 在同一文档集上, 采用文献[18 ]的技术新颖度测算方法对该文档的主题新颖度进行计算, 并与本文的算法进行对比. ...
... 基于Doc2Vec的主题新颖度计算结果
ID 文章题目 文章来源 主题新颖度 文献[18 ](α=0.5) 1 我国综合性文献数据库大学生用户心智模型结构测量实证研究 情报学报 0.4848 1 2 生态产业集群内知识转移影响因素的分析 情报科学 0.4836 0.6065 3 论中国公安情报学学科专业发展及研究框架 情报杂志 0.4812 0.3019 4 国内外网络舆情数学建模研究综述 情报杂志 0.4801 0.6065 5 数字鸿沟分析视角下的电子政务在线服务测评——基于北京市的实证研究 情报科学 0.4779 0.6065 6 知识网络的知识完备性测度方法研究 情报学报 0.4775 0.3679 7 欧美国家公共信息资源定价策略的发展演变分析 情报学报 0.4755 0.1353 8 基于仿生学视角的科技型新创企业知识转化影响因素研究 情报科学 0.4748 0.6065 9 应用“h2指数”评价高校档案馆学术能力的效果研究——以我国高校排名 情报科学 0.4741 0.6065 10 复杂项目危机预警网格系统设计与实现 情报杂志 0.4723 0.4978
3.3 结果分析与讨论 为了进一步研究期刊论文的主题新颖度水平与期刊学术质量间的关系, 笔者在基于Doc2Vec的单篇论文主题新颖度计算结果, 进一步计算出各期刊所载论文的主题新颖度的整体情况, 得出《情报学报》刊载论文的主题新颖性指数平均值为0.3532, 《情报科学》刊载论文的主题新颖性指数平均值为0.3462, 《情报杂志》刊载论文的主题新颖性指数平均值为0.3419.通过t检验统计和比较各期刊刊载论文的主题新颖性指数的差异分布及其显著性可以发现, 《情报学报》与《情报杂志》间论文主题新颖性指数存在显著性差异, 其p值为0.048<0.05, 这一结果可以从整体上说明, 期刊刊载论文的主题新颖性指数与期刊质量之间存在一定的正相关关系, 同一学科领域内, 高质量学术期刊的载文主题新颖度平均值相对较高.从每篇论文的主题新颖度的具体分布来看, 虽然重要期刊上所刊载论文的整体新颖度较高, 但是也存在两级分化现象, 例如《情报学报》上就有个别论文的主题新颖度低于0.2, 表明这些论文与较多其他主题新颖性较低的论文间的相似度较高.这也说明论文的主题新颖性只是保证学术质量与创新的前提之一, 并不具有绝对性, 重要期刊上也会刊载一些主题新颖度相对较低的论文, 因此该结果也表明研究主题的新颖度并不是决定学术质量的绝对因素.需要特别说明的是, 表1 中第4个样例(国内外网络舆情数学建模研究综述)虽为综述论文, 但该文基于不确定系统和不确定性因素的数学处理方法, 对网络舆情中不确定性因素的数学处理方法进行研究, 并对网络舆情相关研究的未来发展趋势进行展望, 视角独特且该类研究在目前的情报学领域内还较为少见, 且该综述论文在测试样本集内与其相似的论文数量较少、相似度也较低, 所以出现了较高的主题新颖性, 因此该例在样本集内的研究视角和主题获得了较高的主题新颖度, 这也进一步说明学科交叉融合能够促进学术创新和发展这一判断.综上所述, 本文构建的主题新颖性指数指标和方法不仅具有可操作性, 并且其计算结果也具有较好的可解释性. ...
... 为了进一步验证该方法的科学性和有效性, 将本文构建的主题新颖性指数与文献[18 ]的技术新颖度指数对该文档集的新颖度计算结果进行对比验证, 计算结果见表1 .通过计算两者的相关性, 可以发现, 基于本文所构建的主题新颖性测度方法所得到的结果与文献[18 ]的方法所得出的结果呈显著相关关系, 其相关系数为0.494, p值为0, 表现为0.01水平上显著相关, 以此验证本文所构建的主题新颖性计算方法的有效性.具体在采用文献[18 ]的技术主题新颖度计算过程中, 在文档相似度计算后选取其中α 的取值时发现, 若α 取值过大, 会造成与之相似的文档数n的值极小, 最终计算结果逼近或等于1, 反之若α 取值过小, 则容易造成与之相似的文档数n的值过大, 从而造成最终的新颖度指标结果极小的情况.本文对比研究时选取α =0.5作为阈值计算主题新颖度, 但是其结果也直接表现为文档主题新颖度计算结果的区分度较差, 而采用本文所构建的方法则有效地避免了这种问题. ...
... .通过计算两者的相关性, 可以发现, 基于本文所构建的主题新颖性测度方法所得到的结果与文献[18 ]的方法所得出的结果呈显著相关关系, 其相关系数为0.494, p值为0, 表现为0.01水平上显著相关, 以此验证本文所构建的主题新颖性计算方法的有效性.具体在采用文献[18 ]的技术主题新颖度计算过程中, 在文档相似度计算后选取其中α 的取值时发现, 若α 取值过大, 会造成与之相似的文档数n的值极小, 最终计算结果逼近或等于1, 反之若α 取值过小, 则容易造成与之相似的文档数n的值过大, 从而造成最终的新颖度指标结果极小的情况.本文对比研究时选取α =0.5作为阈值计算主题新颖度, 但是其结果也直接表现为文档主题新颖度计算结果的区分度较差, 而采用本文所构建的方法则有效地避免了这种问题. ...
... ]的方法所得出的结果呈显著相关关系, 其相关系数为0.494, p值为0, 表现为0.01水平上显著相关, 以此验证本文所构建的主题新颖性计算方法的有效性.具体在采用文献[18 ]的技术主题新颖度计算过程中, 在文档相似度计算后选取其中α 的取值时发现, 若α 取值过大, 会造成与之相似的文档数n的值极小, 最终计算结果逼近或等于1, 反之若α 取值过小, 则容易造成与之相似的文档数n的值过大, 从而造成最终的新颖度指标结果极小的情况.本文对比研究时选取α =0.5作为阈值计算主题新颖度, 但是其结果也直接表现为文档主题新颖度计算结果的区分度较差, 而采用本文所构建的方法则有效地避免了这种问题. ...
... 通过将本文的测度方法与已有学者提出的方法进行对比验证和相关性分析, 得出本文构建的主题新颖性测度指标和计算方法所得到的结果与刘玉琴等[18 ] 的计算方法所得出的结果呈0.01水平上的显著相关关系, 相关系数为0.494, 进一步验证了该方法的科学性和有效性, 同时本文构建的方法也有效避免了其他方法中阈值依靠人工设定和其计算结果区分度不够的问题. ...
基于文本挖掘技术的产品技术成熟度预测
7
2008
... 由于上述基于引文的学术创新性评价的局限性, 这一领域的研究人员开始将目光转向学术成果本身, 通过对学术成果的内容分析与挖掘构建学术成果的研究主题新颖性测度指标, 从而展示学术研究内容间的差异.沈阳[14 ] 通过对关键词的挖掘与计算, 构建基于关键词在文中出现的频率、被用户检索的频率、使用的时间跨度及用户对关键词的创新度评价指标, 以此反映学术成果的创新度.虽然关键词可以在一定程度上反映学术成果中包含的重要主题、概念、思想、模型或方法, 但是使用单个关键词仍然不足以准确刻画和反映学术成果的主题新颖性, 在此基础上, 钱玲飞、杨建林等[15 ,16 ] 研究认为学科交叉程度与其学科创新性之间有较强的正向联系, 学科交叉程度越高, 其具有较高创新度的可能性就越大, 通过构建关键词的交叉率量化研究学科的创新能力, 并在此基础上基于关键词对间的共现关系进一步研究和构建文档的主题新颖度指标.在技术创新性研究领域, 研究者通过对专利文本特征、技术术语的提取和文本特征相似度的计算, 描述专利技术文本间的差异性, 其相似度越小, 则该专利间的技术差异越大、内容越新、专利价值越高[17 ] .刘玉琴等[18 ] 使用该方法计算专利相似度, 并在此基础上量化地研究了技术的新颖度, 构建了在相似性水平阈值α 上的技术新颖度测算指标, 并在此基础上进一步构建相似水平阈值α 上m件专利的平均技术新颖度, 用于评价某段时间内专利群体的总体价值和技术新颖性. ...
... 为测试上述指标和方法的有效性, 本文选取国内情报学期刊中的相关学术论文进行主题新颖性测度.中国社会科学院发布的《中国人文社会科学期刊评价报告》[27 ] 显示, 《情报学报》在情报学期刊中的排名相对较高, 因此本文假定期刊评价排名与期刊质量、期刊质量与期刊论文的主题新颖性之间存在一定的相关关系.为加强对比效果且使测试样本具有横向可比性, 选取《情报学报》(简称QBXB)、《情报科学》(简称QBKX)和《情报杂志》(简称QBZZ)三本期刊上的2014年度所刊载的全部学术论文(928 篇)作为测度对象.对所选样本集内的文档进行两两相似度计算从而构建文档相似度矩阵, 在此基础上计算各个文档的内容特征因子和主题新颖性指数, 并通过计算和对比各刊刊载论文的新颖性指数的平均值, 验证本文构建的新颖性指数是否与期刊质量之间存在正相关关系.同时为了进一步加强对比效果.在计算文档相似度过程中, 分别采用Doc2Vec模型和TFIDF模型对文档相似度进行计算.此外, 为了验证基于文档相似度和内容特征因子的主题新颖性指数的有效性, 在同一文档集上, 采用文献[18 ]的技术新颖度测算方法对该文档的主题新颖度进行计算, 并与本文的算法进行对比. ...
... 基于Doc2Vec的主题新颖度计算结果
ID 文章题目 文章来源 主题新颖度 文献[18 ](α=0.5) 1 我国综合性文献数据库大学生用户心智模型结构测量实证研究 情报学报 0.4848 1 2 生态产业集群内知识转移影响因素的分析 情报科学 0.4836 0.6065 3 论中国公安情报学学科专业发展及研究框架 情报杂志 0.4812 0.3019 4 国内外网络舆情数学建模研究综述 情报杂志 0.4801 0.6065 5 数字鸿沟分析视角下的电子政务在线服务测评——基于北京市的实证研究 情报科学 0.4779 0.6065 6 知识网络的知识完备性测度方法研究 情报学报 0.4775 0.3679 7 欧美国家公共信息资源定价策略的发展演变分析 情报学报 0.4755 0.1353 8 基于仿生学视角的科技型新创企业知识转化影响因素研究 情报科学 0.4748 0.6065 9 应用“h2指数”评价高校档案馆学术能力的效果研究——以我国高校排名 情报科学 0.4741 0.6065 10 复杂项目危机预警网格系统设计与实现 情报杂志 0.4723 0.4978
3.3 结果分析与讨论 为了进一步研究期刊论文的主题新颖度水平与期刊学术质量间的关系, 笔者在基于Doc2Vec的单篇论文主题新颖度计算结果, 进一步计算出各期刊所载论文的主题新颖度的整体情况, 得出《情报学报》刊载论文的主题新颖性指数平均值为0.3532, 《情报科学》刊载论文的主题新颖性指数平均值为0.3462, 《情报杂志》刊载论文的主题新颖性指数平均值为0.3419.通过t检验统计和比较各期刊刊载论文的主题新颖性指数的差异分布及其显著性可以发现, 《情报学报》与《情报杂志》间论文主题新颖性指数存在显著性差异, 其p值为0.048<0.05, 这一结果可以从整体上说明, 期刊刊载论文的主题新颖性指数与期刊质量之间存在一定的正相关关系, 同一学科领域内, 高质量学术期刊的载文主题新颖度平均值相对较高.从每篇论文的主题新颖度的具体分布来看, 虽然重要期刊上所刊载论文的整体新颖度较高, 但是也存在两级分化现象, 例如《情报学报》上就有个别论文的主题新颖度低于0.2, 表明这些论文与较多其他主题新颖性较低的论文间的相似度较高.这也说明论文的主题新颖性只是保证学术质量与创新的前提之一, 并不具有绝对性, 重要期刊上也会刊载一些主题新颖度相对较低的论文, 因此该结果也表明研究主题的新颖度并不是决定学术质量的绝对因素.需要特别说明的是, 表1 中第4个样例(国内外网络舆情数学建模研究综述)虽为综述论文, 但该文基于不确定系统和不确定性因素的数学处理方法, 对网络舆情中不确定性因素的数学处理方法进行研究, 并对网络舆情相关研究的未来发展趋势进行展望, 视角独特且该类研究在目前的情报学领域内还较为少见, 且该综述论文在测试样本集内与其相似的论文数量较少、相似度也较低, 所以出现了较高的主题新颖性, 因此该例在样本集内的研究视角和主题获得了较高的主题新颖度, 这也进一步说明学科交叉融合能够促进学术创新和发展这一判断.综上所述, 本文构建的主题新颖性指数指标和方法不仅具有可操作性, 并且其计算结果也具有较好的可解释性. ...
... 为了进一步验证该方法的科学性和有效性, 将本文构建的主题新颖性指数与文献[18 ]的技术新颖度指数对该文档集的新颖度计算结果进行对比验证, 计算结果见表1 .通过计算两者的相关性, 可以发现, 基于本文所构建的主题新颖性测度方法所得到的结果与文献[18 ]的方法所得出的结果呈显著相关关系, 其相关系数为0.494, p值为0, 表现为0.01水平上显著相关, 以此验证本文所构建的主题新颖性计算方法的有效性.具体在采用文献[18 ]的技术主题新颖度计算过程中, 在文档相似度计算后选取其中α 的取值时发现, 若α 取值过大, 会造成与之相似的文档数n的值极小, 最终计算结果逼近或等于1, 反之若α 取值过小, 则容易造成与之相似的文档数n的值过大, 从而造成最终的新颖度指标结果极小的情况.本文对比研究时选取α =0.5作为阈值计算主题新颖度, 但是其结果也直接表现为文档主题新颖度计算结果的区分度较差, 而采用本文所构建的方法则有效地避免了这种问题. ...
... .通过计算两者的相关性, 可以发现, 基于本文所构建的主题新颖性测度方法所得到的结果与文献[18 ]的方法所得出的结果呈显著相关关系, 其相关系数为0.494, p值为0, 表现为0.01水平上显著相关, 以此验证本文所构建的主题新颖性计算方法的有效性.具体在采用文献[18 ]的技术主题新颖度计算过程中, 在文档相似度计算后选取其中α 的取值时发现, 若α 取值过大, 会造成与之相似的文档数n的值极小, 最终计算结果逼近或等于1, 反之若α 取值过小, 则容易造成与之相似的文档数n的值过大, 从而造成最终的新颖度指标结果极小的情况.本文对比研究时选取α =0.5作为阈值计算主题新颖度, 但是其结果也直接表现为文档主题新颖度计算结果的区分度较差, 而采用本文所构建的方法则有效地避免了这种问题. ...
... ]的方法所得出的结果呈显著相关关系, 其相关系数为0.494, p值为0, 表现为0.01水平上显著相关, 以此验证本文所构建的主题新颖性计算方法的有效性.具体在采用文献[18 ]的技术主题新颖度计算过程中, 在文档相似度计算后选取其中α 的取值时发现, 若α 取值过大, 会造成与之相似的文档数n的值极小, 最终计算结果逼近或等于1, 反之若α 取值过小, 则容易造成与之相似的文档数n的值过大, 从而造成最终的新颖度指标结果极小的情况.本文对比研究时选取α =0.5作为阈值计算主题新颖度, 但是其结果也直接表现为文档主题新颖度计算结果的区分度较差, 而采用本文所构建的方法则有效地避免了这种问题. ...
... 通过将本文的测度方法与已有学者提出的方法进行对比验证和相关性分析, 得出本文构建的主题新颖性测度指标和计算方法所得到的结果与刘玉琴等[18 ] 的计算方法所得出的结果呈0.01水平上的显著相关关系, 相关系数为0.494, 进一步验证了该方法的科学性和有效性, 同时本文构建的方法也有效避免了其他方法中阈值依靠人工设定和其计算结果区分度不够的问题. ...
A Review of Semantic Similarity Measures in WordNet
1
2013
... 从当前基于内容的主题新颖性计算方法来看, 现有的主题新颖性是基于关键词共现和文本特征提取的内容相似性计算的测度方法.在实际计算过程中, 学术成果中给出的关键词几乎都是由作者提供, 由于中文词语表达的随意性, 关键词中不规范或不合理之处比较常见.为消除不规范关键词等因素对主题新颖度量化结果准确度的影响, 研究者也采用词表的方法(如基于WordNet的语义相似度计算和基于HowNet中义原层次结构的语义深度和语义密度扩展等方法)对作者给出的关键词进行规范处理和语义扩展[19 ,20 ] , 但是该方法依赖于一个较为全面的领域语义词典, 其应用范围相对较为局限. ...
基于语义理解的文本相似度计算研究与实现
1
2015
... 从当前基于内容的主题新颖性计算方法来看, 现有的主题新颖性是基于关键词共现和文本特征提取的内容相似性计算的测度方法.在实际计算过程中, 学术成果中给出的关键词几乎都是由作者提供, 由于中文词语表达的随意性, 关键词中不规范或不合理之处比较常见.为消除不规范关键词等因素对主题新颖度量化结果准确度的影响, 研究者也采用词表的方法(如基于WordNet的语义相似度计算和基于HowNet中义原层次结构的语义深度和语义密度扩展等方法)对作者给出的关键词进行规范处理和语义扩展[19 ,20 ] , 但是该方法依赖于一个较为全面的领域语义词典, 其应用范围相对较为局限. ...
基于语义理解的文本相似度计算研究与实现
1
2015
... 从当前基于内容的主题新颖性计算方法来看, 现有的主题新颖性是基于关键词共现和文本特征提取的内容相似性计算的测度方法.在实际计算过程中, 学术成果中给出的关键词几乎都是由作者提供, 由于中文词语表达的随意性, 关键词中不规范或不合理之处比较常见.为消除不规范关键词等因素对主题新颖度量化结果准确度的影响, 研究者也采用词表的方法(如基于WordNet的语义相似度计算和基于HowNet中义原层次结构的语义深度和语义密度扩展等方法)对作者给出的关键词进行规范处理和语义扩展[19 ,20 ] , 但是该方法依赖于一个较为全面的领域语义词典, 其应用范围相对较为局限. ...
1
... 随着计算能力的大幅提高和数据规模的急速膨胀, 在大数据环境下采用深度学习的方法进行文本特征的语义扩展和内容相似度计算已经成为可能, 其计算效果也显著提升.其中以2013年Google公司发布其深度学习算法及工具包Word2Vec[21 ] 为代表, 标志着深度学习从理论走向实际应用.在Word2Vec工具包的基础上, Le等[22 ] 开发Doc2Vec算法工具包, 将文本特征的计算从词语层面扩展到句子层面.随后国内外众多学者基于该工具进行文本相似度计算研究, 表现出良好的效果[23 ,24 ,25 ] .因此本文将基于此方法计算文档集内文本间的语义相似度, 并在论文研究主题相似度计算的基础上, 基于主题相似性网络的拓扑结构, 采用隐马尔可夫模型(Hidden Markov Model, HMM)的相关算法计算各文档间基于相似度的系统状态转移关系, 整体考虑文档集内所有文本间的相似性强度及其关系, 在该相似度转移矩阵的基础上计算内容特征因子, 构建学术研究成果的主题新颖度测度算法. ...
Distributed Representations of Sentences and Documents
2
... 随着计算能力的大幅提高和数据规模的急速膨胀, 在大数据环境下采用深度学习的方法进行文本特征的语义扩展和内容相似度计算已经成为可能, 其计算效果也显著提升.其中以2013年Google公司发布其深度学习算法及工具包Word2Vec[21 ] 为代表, 标志着深度学习从理论走向实际应用.在Word2Vec工具包的基础上, Le等[22 ] 开发Doc2Vec算法工具包, 将文本特征的计算从词语层面扩展到句子层面.随后国内外众多学者基于该工具进行文本相似度计算研究, 表现出良好的效果[23 ,24 ,25 ] .因此本文将基于此方法计算文档集内文本间的语义相似度, 并在论文研究主题相似度计算的基础上, 基于主题相似性网络的拓扑结构, 采用隐马尔可夫模型(Hidden Markov Model, HMM)的相关算法计算各文档间基于相似度的系统状态转移关系, 整体考虑文档集内所有文本间的相似性强度及其关系, 在该相似度转移矩阵的基础上计算内容特征因子, 构建学术研究成果的主题新颖度测度算法. ...
... ②采用深度学习中的Doc2Vec算法计算文档集内所有文本间的语义相似度; 鉴于本文主要研究和探讨的是主题新颖性测度指标的构建, 因此, 将重点放在相似度计算之后内容特征因子计算及主题新颖性指标的函数表达上, 其中基于Doc2Vec算法的文本主题语义相似度计算采用文献[22 ]中的相关计算方法. ...
Sentiment Classification for Unlabeled Dataset Using Doc2Vec with JST
1
2016
... 随着计算能力的大幅提高和数据规模的急速膨胀, 在大数据环境下采用深度学习的方法进行文本特征的语义扩展和内容相似度计算已经成为可能, 其计算效果也显著提升.其中以2013年Google公司发布其深度学习算法及工具包Word2Vec[21 ] 为代表, 标志着深度学习从理论走向实际应用.在Word2Vec工具包的基础上, Le等[22 ] 开发Doc2Vec算法工具包, 将文本特征的计算从词语层面扩展到句子层面.随后国内外众多学者基于该工具进行文本相似度计算研究, 表现出良好的效果[23 ,24 ,25 ] .因此本文将基于此方法计算文档集内文本间的语义相似度, 并在论文研究主题相似度计算的基础上, 基于主题相似性网络的拓扑结构, 采用隐马尔可夫模型(Hidden Markov Model, HMM)的相关算法计算各文档间基于相似度的系统状态转移关系, 整体考虑文档集内所有文本间的相似性强度及其关系, 在该相似度转移矩阵的基础上计算内容特征因子, 构建学术研究成果的主题新颖度测度算法. ...
Neural Network Doc2vec in Automated Sentiment Analysis for Short Informal Texts
1
2017
... 随着计算能力的大幅提高和数据规模的急速膨胀, 在大数据环境下采用深度学习的方法进行文本特征的语义扩展和内容相似度计算已经成为可能, 其计算效果也显著提升.其中以2013年Google公司发布其深度学习算法及工具包Word2Vec[21 ] 为代表, 标志着深度学习从理论走向实际应用.在Word2Vec工具包的基础上, Le等[22 ] 开发Doc2Vec算法工具包, 将文本特征的计算从词语层面扩展到句子层面.随后国内外众多学者基于该工具进行文本相似度计算研究, 表现出良好的效果[23 ,24 ,25 ] .因此本文将基于此方法计算文档集内文本间的语义相似度, 并在论文研究主题相似度计算的基础上, 基于主题相似性网络的拓扑结构, 采用隐马尔可夫模型(Hidden Markov Model, HMM)的相关算法计算各文档间基于相似度的系统状态转移关系, 整体考虑文档集内所有文本间的相似性强度及其关系, 在该相似度转移矩阵的基础上计算内容特征因子, 构建学术研究成果的主题新颖度测度算法. ...
基于深度学习的学术期刊选题同质化测度方法研究
1
2017
... 随着计算能力的大幅提高和数据规模的急速膨胀, 在大数据环境下采用深度学习的方法进行文本特征的语义扩展和内容相似度计算已经成为可能, 其计算效果也显著提升.其中以2013年Google公司发布其深度学习算法及工具包Word2Vec[21 ] 为代表, 标志着深度学习从理论走向实际应用.在Word2Vec工具包的基础上, Le等[22 ] 开发Doc2Vec算法工具包, 将文本特征的计算从词语层面扩展到句子层面.随后国内外众多学者基于该工具进行文本相似度计算研究, 表现出良好的效果[23 ,24 ,25 ] .因此本文将基于此方法计算文档集内文本间的语义相似度, 并在论文研究主题相似度计算的基础上, 基于主题相似性网络的拓扑结构, 采用隐马尔可夫模型(Hidden Markov Model, HMM)的相关算法计算各文档间基于相似度的系统状态转移关系, 整体考虑文档集内所有文本间的相似性强度及其关系, 在该相似度转移矩阵的基础上计算内容特征因子, 构建学术研究成果的主题新颖度测度算法. ...
基于深度学习的学术期刊选题同质化测度方法研究
1
2017
... 随着计算能力的大幅提高和数据规模的急速膨胀, 在大数据环境下采用深度学习的方法进行文本特征的语义扩展和内容相似度计算已经成为可能, 其计算效果也显著提升.其中以2013年Google公司发布其深度学习算法及工具包Word2Vec[21 ] 为代表, 标志着深度学习从理论走向实际应用.在Word2Vec工具包的基础上, Le等[22 ] 开发Doc2Vec算法工具包, 将文本特征的计算从词语层面扩展到句子层面.随后国内外众多学者基于该工具进行文本相似度计算研究, 表现出良好的效果[23 ,24 ,25 ] .因此本文将基于此方法计算文档集内文本间的语义相似度, 并在论文研究主题相似度计算的基础上, 基于主题相似性网络的拓扑结构, 采用隐马尔可夫模型(Hidden Markov Model, HMM)的相关算法计算各文档间基于相似度的系统状态转移关系, 整体考虑文档集内所有文本间的相似性强度及其关系, 在该相似度转移矩阵的基础上计算内容特征因子, 构建学术研究成果的主题新颖度测度算法. ...
Manipulation of Pagerank and Collective Hidden Markov Models
1
2010
... ④采用隐马尔可夫模型(HMM)的相关算法计算该相似度矩阵的内容特征因子Cef, 具体计算方法如公式(2)[26 ] 所示, 其中, M 是所有与文档Di 存在相似度关系的文档集合, weight (Dj )是边(Di , Dj )间的权重, degree (Dj )是转移矩阵中文档Dj 的度数. ...
1
2015
... 为测试上述指标和方法的有效性, 本文选取国内情报学期刊中的相关学术论文进行主题新颖性测度.中国社会科学院发布的《中国人文社会科学期刊评价报告》[27 ] 显示, 《情报学报》在情报学期刊中的排名相对较高, 因此本文假定期刊评价排名与期刊质量、期刊质量与期刊论文的主题新颖性之间存在一定的相关关系.为加强对比效果且使测试样本具有横向可比性, 选取《情报学报》(简称QBXB)、《情报科学》(简称QBKX)和《情报杂志》(简称QBZZ)三本期刊上的2014年度所刊载的全部学术论文(928 篇)作为测度对象.对所选样本集内的文档进行两两相似度计算从而构建文档相似度矩阵, 在此基础上计算各个文档的内容特征因子和主题新颖性指数, 并通过计算和对比各刊刊载论文的新颖性指数的平均值, 验证本文构建的新颖性指数是否与期刊质量之间存在正相关关系.同时为了进一步加强对比效果.在计算文档相似度过程中, 分别采用Doc2Vec模型和TFIDF模型对文档相似度进行计算.此外, 为了验证基于文档相似度和内容特征因子的主题新颖性指数的有效性, 在同一文档集上, 采用文献[18 ]的技术新颖度测算方法对该文档的主题新颖度进行计算, 并与本文的算法进行对比. ...
1
2015
... 为测试上述指标和方法的有效性, 本文选取国内情报学期刊中的相关学术论文进行主题新颖性测度.中国社会科学院发布的《中国人文社会科学期刊评价报告》[27 ] 显示, 《情报学报》在情报学期刊中的排名相对较高, 因此本文假定期刊评价排名与期刊质量、期刊质量与期刊论文的主题新颖性之间存在一定的相关关系.为加强对比效果且使测试样本具有横向可比性, 选取《情报学报》(简称QBXB)、《情报科学》(简称QBKX)和《情报杂志》(简称QBZZ)三本期刊上的2014年度所刊载的全部学术论文(928 篇)作为测度对象.对所选样本集内的文档进行两两相似度计算从而构建文档相似度矩阵, 在此基础上计算各个文档的内容特征因子和主题新颖性指数, 并通过计算和对比各刊刊载论文的新颖性指数的平均值, 验证本文构建的新颖性指数是否与期刊质量之间存在正相关关系.同时为了进一步加强对比效果.在计算文档相似度过程中, 分别采用Doc2Vec模型和TFIDF模型对文档相似度进行计算.此外, 为了验证基于文档相似度和内容特征因子的主题新颖性指数的有效性, 在同一文档集上, 采用文献[18 ]的技术新颖度测算方法对该文档的主题新颖度进行计算, 并与本文的算法进行对比. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}