1Institute of Scientific and Technical Information of China, Beijing 100038, China 2School of Economics, Renmin University of China, Beijing 100872, China
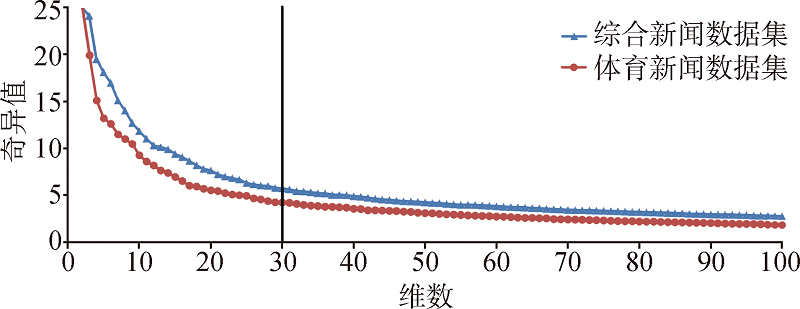
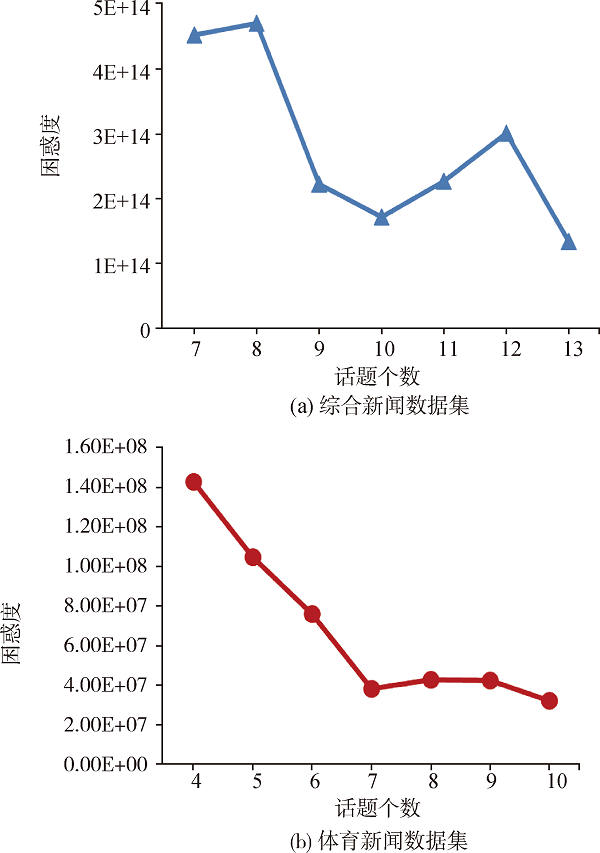
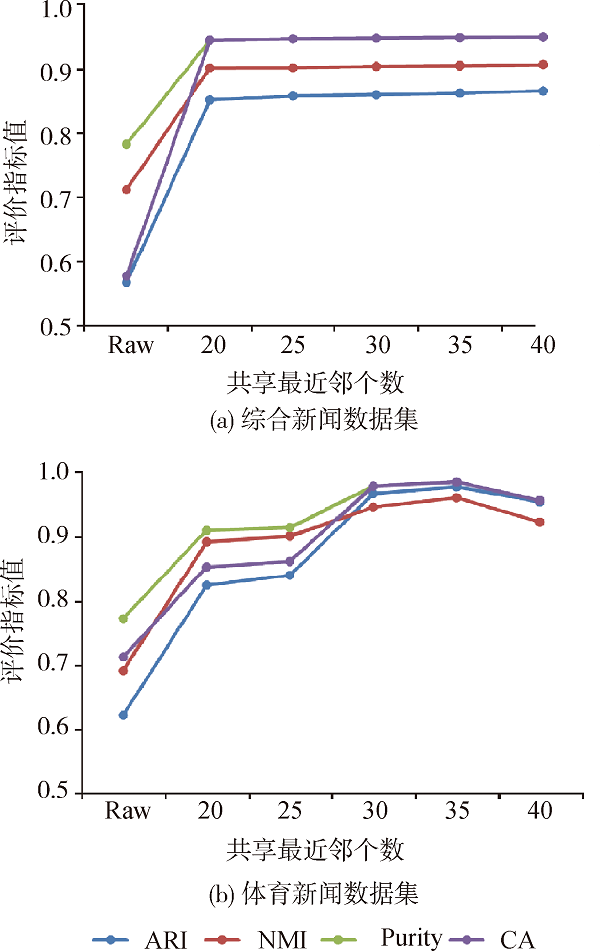
[Objective] This paper proposes a topic detection method for online news, aiming to more effectively utilize the internal structure of data. [Methods] First, we examined the association strength among online news with the number and rank of their shared nearest neighbors. Then, we constructed a graph for the shared nearest neighbors, which improved the utilization of internal structure of the data. Finally, we detected the topics of online news with dimension reduction, the decision of the optimal number of topics, Markov clustering, and automatic topic description based on closeness centrality. [Results] We examined our new model with two data sets of online news and found the ARI values were up to 0.86 and 0.97, while the ARI values of the LDA, K-means, and GMM models were all less than 0.75 and 0.90. [Limitations] We need to evaluate the performance of the proposed method with data sets from other fields and the multilingual ones. [Conclusions] The proposed method could effectively detect the topics of online news and provide new direction for the future research.
吴振峰, 兰天, 王猛猛, 浦墨, 张昱, 刘志辉, 何彦青. 基于共享最近邻和马尔科夫聚类的网络新闻话题检测方法*[J]. 数据分析与知识发现, 2022, 6(10): 103-113.
Wu Zhenfeng, Lan Tian, Wang Mengmeng, Pu Mo, Zhang Yu, Liu Zhihui, He Yanqing. Detecting Topics of Online News with Shared Nearest Neighbours and Markov Clustering. Data Analysis and Knowledge Discovery, 2022, 6(10): 103-113.
(He Min, Du Pan, Zhang Jin, et al. Microblog Bursty Topic Detection Method Based on Momentum Model[J]. Journal of Computer Research and Development, 2015, 52(5): 1022-1028.)
[2]
Papadimitriou C H, Raghavan P, Tamaki H, et al. Latent Semantic Indexing: A Probabilistic Analysis[J]. Journal of Computer and System Sciences, 2000, 61(2): 217-235.
doi: 10.1006/jcss.2000.1711
[3]
Blei D M, Ng A Y, Jordan M I. Latent Dirichlet Allocation[J]. The Journal of Machine Learning Research, 2003, 3: 993-1022.
[4]
Teh Y W, Jordan M I, Beal M J, et al. Sharing Clusters among Related Groups: Hierarchical Dirichlet Processes[C]// Proceedings of the 17th International Conference on Neural Information Processing Systems. 2004: 1385-1392.
[5]
Li W, McCallum A. Pachinko Allocation: DAG-Structured Mixture Models of Topic Correlations[C]// Proceedings of the 23rd International Conference on Machine Learning. 2006: 577-584.
(Liu Hongbing, Li Wenkun, Zhang Yangsen. Microblog Topic Detection Based on LDA Model and Multi-level Clustering[J]. Computer Technology and Development, 2016, 26(6): 25-30.)
(Li Zhenpeng, Huang Shuai. Analysing on Network Public Opinion Based on LDA Topic Model[J]. Journal of Systems Science and Mathematical Sciences, 2020, 40(3): 434-447.)
doi: 10.12341/jssms13829
[8]
Lancichinetti A, Sirer M I, Wang J X, et al. High-Reproducibility and High-Accuracy Method for Automated Topic Classification[J]. Physical Review X, 2015, 5: 011007.
doi: 10.1103/PhysRevX.5.011007
[9]
Li S D, Lv X Q, Wang T, et al. The Key Technology of Topic Detection Based on K-Means[C]// Proceedings of 2010 International Conference on Future Information Technology and Management Engineering. 2010: 387-390.
(Li Lirong. Research on Internet Public Opinion Topic Detection Based on Text Clustering Algorithm[J]. Journal of Shanxi Police College, 2021, 29(1): 69-72.)
[11]
Dai X Y, Chen Q C, Wang X L, et al. Online Topic Detection and Tracking of Financial News Based on Hierarchical Clustering[C]// Proceedings of 2010 International Conference on Machine Learning and Cybernetics. 2010: 3341-3346.
[12]
Liu B, Niu D, Lai K F, et al. Growing Story Forest Online from Massive Breaking News[C]// Proceedings of the 2017 ACM Conference on Information and Knowledge Management. 2017: 777-785.
(Yang Lianlian, Yang Zhiyin, Yang Chaofeng. Research on the Hotspots of Microbiology and Botany Based on the Co-Word Analysis[J]. Technology Intelligence Engineering, 2016, 2(4): 96-103.)
(Xiao Xianglong, Li Xin, Gao Han, et al. Research on Scientific Gaps Recognition Based on Keywords Co-occurrence[J]. Technology Intelligence Engineering, 2018, 4(6): 37-50.)
[15]
Brohée S, van Helden J. Evaluation of Clustering Algorithms for Protein-Protein Interaction Networks[J]. BMC Bioinformatics, 2006, 7: 488.
pmid: 17087821
[16]
Liu Z C, Lin G S, Yang S, et al. Learning Markov Clustering Networks for Scene Text Detection[C]// Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2018: 6936-6944.
[17]
Wang C H, Zhang M, Ma S P, et al. Automatic Online News Issue Construction in Web Environment[C]// Proceedings of the 17th International Conference on World Wide Web, Beijing, China. 2008: 457-466.
[18]
White H D. Bag of Works Retrieval: TF*IDF Weighting of Co-cited Works[J]. International Journal on Digital Libraries, 2018, 19(2-3): 139-149.
doi: 10.1007/s00799-017-0217-7
[19]
Satija R, Farrell J A, Gennert D, et al. Spatial Reconstruction of Single-Cell Gene Expression Data[J]. Nature Biotechnology, 2015, 33(5): 495-502.
doi: 10.1038/nbt.3192
pmid: 25867923
[20]
Krzanowski W J, Lai Y T. A Criterion for Determining the Number of Groups in a Data Set Using Sum-of-Squares Clustering[J]. Biometrics, 1988, 44(1): 23-34.
doi: 10.2307/2531893
[21]
Golbeck J.Network Structure and Measures[A]// Analyzing the Social Web[M]. Amsterdam: Elsevier, 2013: 25-44.
[22]
van der Maaten L, Hinton G. Visualizing Data Using t-SNE[J]. Journal of Machine Learning Research, 2008, 9: 2579-2605.
[23]
Hubert L, Arabie P. Comparing Partitions[J]. Journal of Classification, 1985, 2(1): 193-218.
doi: 10.1007/BF01908075
[24]
Strehl A, Ghosh J. Cluster Ensembles-A Knowledge Reuse Framework for Combining Partitions[J]. The Journal of Machine Learning Research, 2002, 3(3): 583-617.
[25]
Meilă M, Heckerman D. An Experimental Comparison of Model-Based Clustering Methods[J]. Machine Learning, 2001, 42(1-2): 9-29.
doi: 10.1023/A:1007648401407
[26]
Tian K, Zhou S G, Guan J H. DeepCluster: A General Clustering Framework Based on Deep Learning[C]// Proceedings of Joint European Conference on Machine Learning and Knowledge Discovery in Databases. 2017: 809-825.
[27]
Kuhn H W. The Hungarian Method for the Assignment Problem[J]. Naval Research Logistics Quarterly, 1955, 2(1-2): 83-97.
doi: 10.1002/nav.3800020109
(Guan Peng, Wang Yuefen. Identifying Optimal Topic Numbers from Sci-Tech Information with LDA Model[J]. New Technology of Library and Information Service, 2016(9): 42-50.)