{kind=link}
{kind=link}
一种通过挖掘研讨记录来促进学生思考的在线督导系统
[李嘉1, 2, 3  , 张朋柱
, 张朋柱2 , 李欣苗4 ]
, 张朋柱|
|


为促进学生思考并提高响应速度,提出一种从历史研讨记录中挖掘相关信息的在线问答推荐方法。该方法包括建立技术词汇层次树、提取任务词汇、文本段落划分、特征抽取、主题识别过滤和计算文档得分6个步骤。通过设计两个实验来评估所提出的方法:第一个实验比较TF-IDF、TF-IDF+主题过滤以及TF-IDF+LSA+主题过滤三种推荐方法,结果表明使用TF-IDF+主题过滤的算法可以获得最好的推荐效果;第二个实验将系统用于一个学期的在线课程研讨中,现场评估结果表明,文档推荐系统可以促进学生研讨,并且有较高的感知有用性和易用性。本研究表明,中等相关程度的历史研讨记录可以被自动挖掘出来,并且向学生提供这些信息可以促进学生思考和研讨。
In order to stimulate student thinking and reduce service response time, the authors propose an online recommendation method that mines relevant information from discussion logs. The proposed method consists of six steps, namely technique term hierarchical tree building, task term extraction, document segmentation, feature extraction, topic identification, and document score calculation. Two experiments are designed to evaluate the proposed system. In the first experiment, three different document recommendation algorithms (i.e., TF-IDF, TF-IDF + topic filtering, TF-IDF + LSA + topic filtering) are compared, and the TF-IDF + topic filtering algorithm gets the best performance. In the second experiment, the proposed system is applied to one semester of online discussion, and the proposed system leads to better discussion participation as well as a higher level of perceived usefulness and ease of use. The results indicate that moderated relevant discussion record can be mined automatically, and providing such information can stimulate student’s thinking and discussion.
历届学生的历史研讨记录非常珍贵,因为过去学生讨论过的问题同样可能是今天的学生会提出的问题。如果能够从历史研讨记录中挖掘出相关的信息,就能够促进学生思考,进而帮助学生解决问题。传统的在线督导工具一般局限于对学生发言和表现情况进行自动评估[ 1, 2],对研讨内容进行自动摘要[ 3, 4],对研讨主题[ 5]和研讨状态[ 6]进行自动检测等,目前还没有发现通过挖掘历史研讨记录来促进学生思考和解决问题的方法。
为了考察通过挖掘研讨记录来促进学生思考的可能性,本文研究开发了一个在线推荐系统来提供与学生所提问题相关的历史研讨信息。该系统从过去学生研讨的历史记录和课程的相关文档中寻找问题的答案或与问题有关的信息并提供给学生参考,同时设计了两个实验来评估所设计的系统。在第一个实验中评估了不同算法推荐文档的相关性,在第二个实验中将系统用于一个学期的在线课程研讨中,通过现场使用来评价学生对问答推荐系统的使用效果。本研究所使用的语料数据和实验环境来自PedaBot[ 7]在线研讨系统,在这个研讨系统内学生可以讨论与课堂内容相关的技术问题。PedaBot是一个使用英语的研讨平台,美国南加州大学的Viterbi工程学院从2004年就开始使用PedaBot系统配合本科生和研究生的操作系统课程教学,鼓励学生在课后加入PedaBot系统讨论与课程相关的问题,并将学生在PedaBot系统中的表现作为考核成绩的一部分。从使用情况上看,PedaBot主要是一个用于教学辅导的系统,学生提出自己不懂的问题或在作业中遇到的困难,其他同学和老师一起来讨论并解决这些问题。
Kim等[ 2]开发了一种自动评估教学研讨效果的工具。通过使用自然语言处理和信息检索技术这一工具可以检测到研讨主题的对话焦点,对研讨主题进行分类,并评估发言的技术深度。这些评估工具对于开发教育课程中的监管和问答技术提供了一定的基础。Lochbaum等[ 3, 4]建造了一个名为Knowledge Post的工具来辅助在线研讨中的学生和教师。除了支持面向问题的同步或异步群体研讨以外,Knowledge Post使用潜在语义分析(Latent Semantic Analysis,LSA)来监视和提高群体研讨。例如,Knowledge Post将相关发言相互关联,在一个大型的电子图书馆中寻找相关信息,对用户发言进行自动摘要。Feng等[ 5]利用单个发言和整个研讨主题(Thread)之间的关系来对研讨主题进行分类。该研究使用一个Rocchio式的分类器对研讨进行分类,这样不需要对数据进行标记。他们描述了一种新的Classify-by-dominance的策略来对研讨主题分类,并且证明在有噪音存在时比标准的Classify-as-a-whole方法可以减少16.8%的错误率。 Kim等[ 6]进行了一个利用言语行为的扩展研究,提出了一种根据言语行为模式对学生发言分类的方法,并展示如何使用这些言语行为模式来评估参与者的作用并识别那些可能包含混淆和未回答问题的主题。
总体来说,自动在线督导系统目前处在一个相对发展较快的进程中,新的工具和应用层出不穷。但是还没有发现一个通过挖掘历史研讨信息来促进学生思考,进而帮助学生解决问题的工具。前人研究的推荐系统多用于电子商务的购物推荐、网络浏览的网页推荐等领域,专门针对E-learning环境,以在线督导为目的的推荐系统还比较少见。由于在线学习环境有很多其他环境所不具备的特点(如有自己的教材、课程体系、学习内容相对固定等),以其他环境为背景研究得到的推荐方法不一定适用于在线督导。因此本文专门针对E-learning环境的特征,研究服务于在线督导的文档推荐方法和推荐系统。
本文提出的在线推荐系统框架如图1所示:
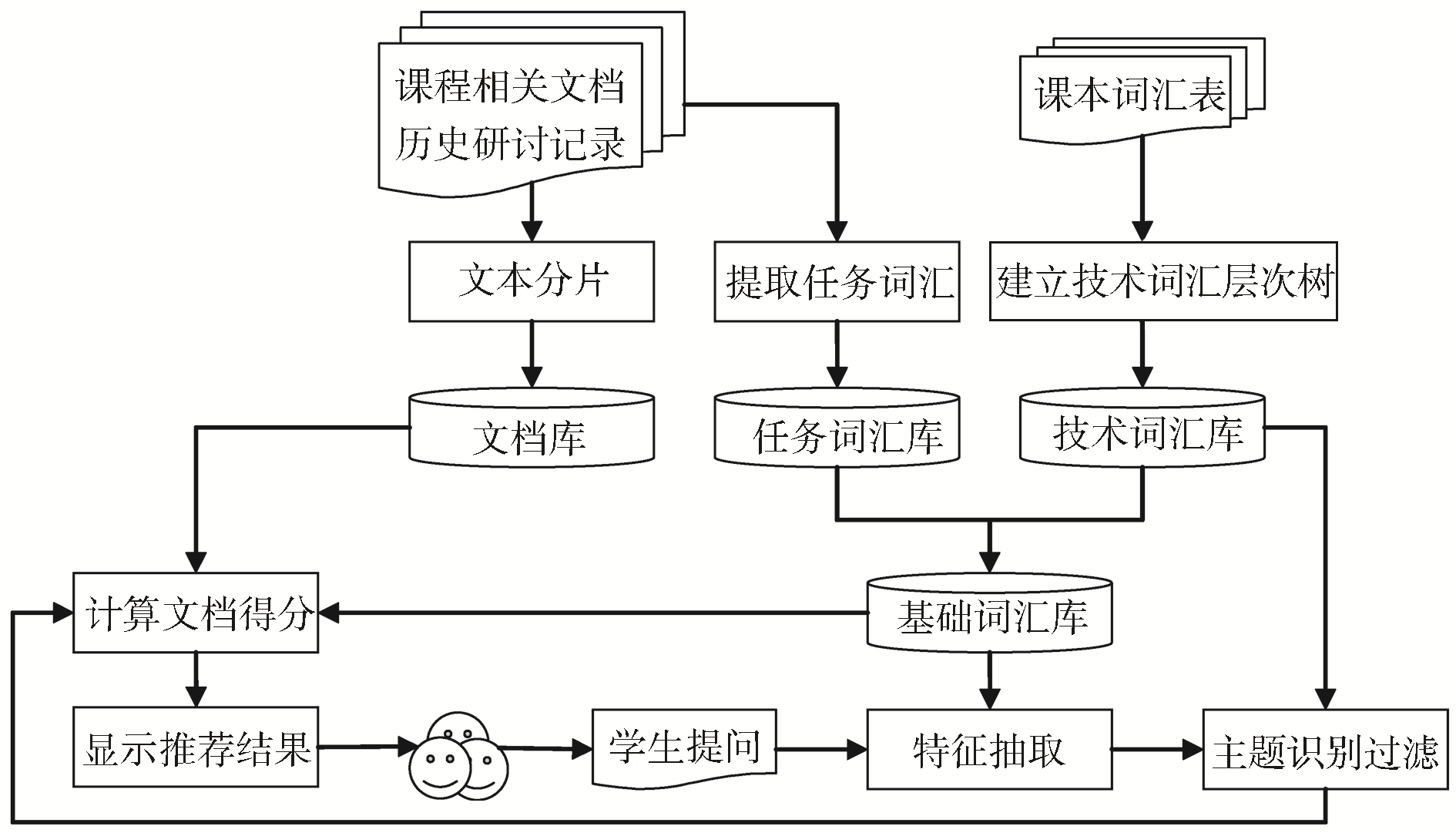 | 图1 在线推荐系统结构 |
当学生提出一个新问题时,系统试图从知识库中寻找问题的答案或相关信息并提供给学生参考。回答学生提问的知识来源于以下三个方面:历届学生研讨的历史记录、课程相关文档和课本词汇表。学生的提问经过特征抽取后被表示成向量的形式。经过主题识别,一个问题被分类到一个预定的主题,文档库中所有不属于该主题的文档被过滤掉,没有资格被选为推荐信息展示给用户。然后计算文档库中的每一个同主题文档与当前问题的相似程度,相似度最高的文档被显示给参与研讨的学生。
由于教科书一般都有目录和词汇表,因此本文通过处理教科书的目录和词汇表来自动建立与研讨课程有关的技术词汇层次树。教科书的目录包含全书的主要章节,而词汇表则包含一系列的词汇以及每个词在教科书中出现的位置(页码)。通过扫描和自动处理教科书的目录和词汇表,可以把词汇表中出现的词汇归类到各个教科书的章节。如果把教科书的章节目录看作是不同的主题,那么就建立了一棵关于教科书内容的技术词汇层次树。这一处理过程如图2所示。
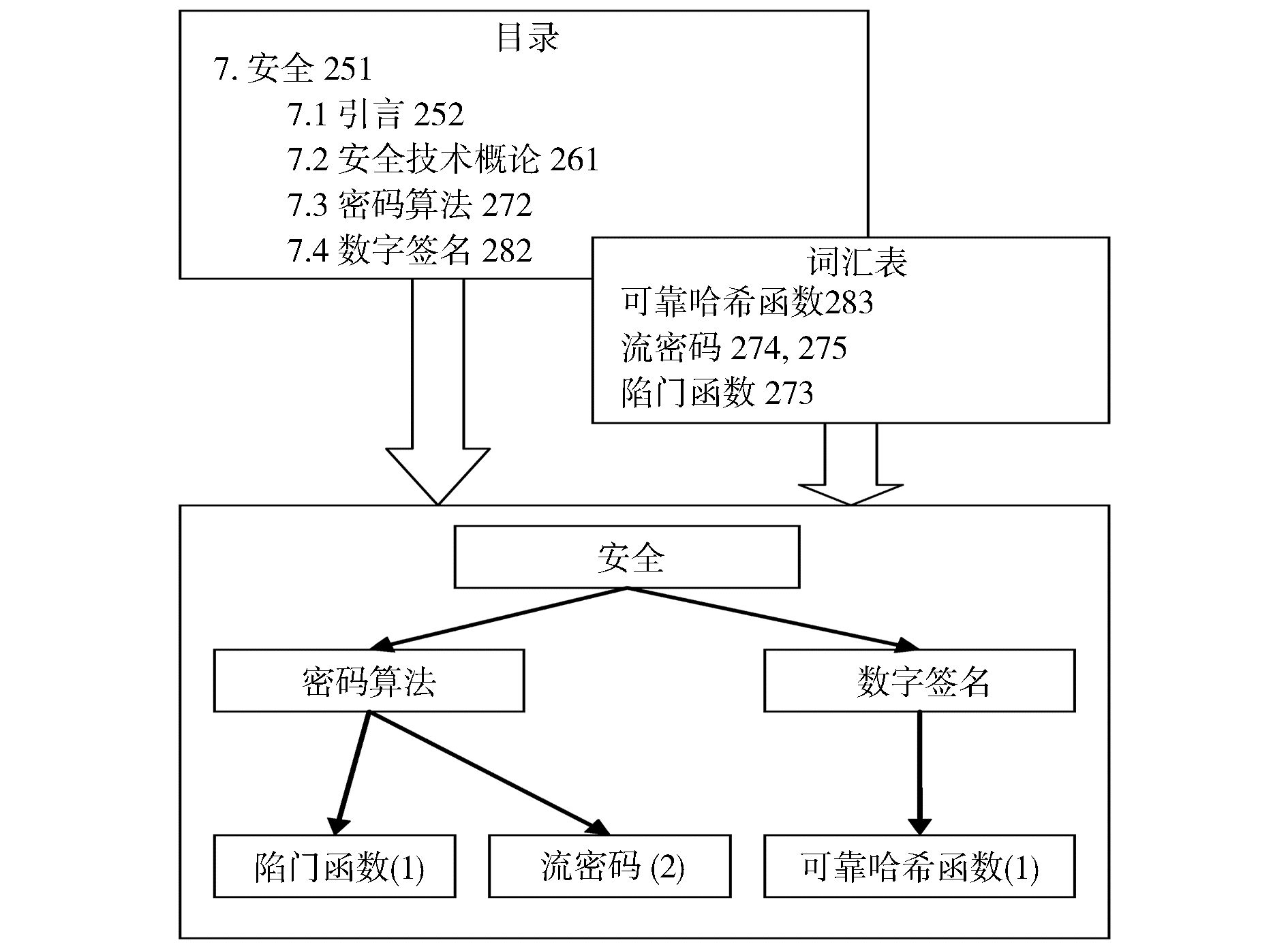 | 图2 从目录和词汇表生成技术词汇层次树的方法示例 |
图2中第一个方框里是目录,第二个方框里是词汇表,第三个方框里是生成的词汇层次树。目录显示了两级的章节标记以及每一级章节标题的页码。词汇表中每一行是一个词条,还包括这个词出现过的页面。将目录和词汇表联合起来看,就可以知道词汇表中的一个词条出现在哪一个章节。例如“可靠哈希函数”应该属于7.4节“数字签名”,因为“可靠哈希函数”出现在283页,而7.4节“数字签名”覆盖了282页到288页的内容。综合目录和词汇表就可以得到技术词汇层次树(如图2最下方的方框所示),括号里的数字表示该词出现的次数。
在研讨中经常使用的与学生任务相关的词汇称为任务词汇。将语料中所有出现频率超过5次的词列举出来,然后让熟悉语料的标注者手工选择任务词汇。通过手工挑选,一共得到了1 587个任务词汇。出现频率最高的前20个任务词汇按照所属的类别如表1所示:
| 表1 出现频率最高的20个任务词汇 |
历届学生研讨的历史记录和课程相关文档一般都比较长,讲述的内容也可能不局限于某一主题。例如,一个有3页的文档中可能只有一段话对解决当前学生的问题有帮助。如果直接将整篇文档提供给学生,则可能会降低帮助学生解决问题的效率,通常造成学生信息过载。解决这一问题的方法就是对文本进行段落划分,只向学生提供与问题相关的文本段落。
本研究采用TextTiling方法[ 8]对文本进行段落划分。TextTiling方法认为相邻的若干句子表达同一个子主题,这些表达同一子主题的句子中相邻两句的相似度都比较高,而子主题有转折的两个相邻句子的相似度相对会有大幅度下降,TextTiling方法将表达同一个子主题的句子划分为同一段落。在实际操作时,使用的是用C++实现的一个TextTiling软件包Douglas Beeferman,其源代码可以从http://people.ischool.berkeley.edu/~hearst/tiling/beeferman_tiling.tar.gz下载。
本研究将技术词汇和任务词汇合并到一起,组成基础词汇库。根据向量空间模型,用这个基础词汇库来表示学生提出的问题。一个学生的提问发言将被表示成向量形式,如下:
Mi=(Mi1,Mi2,…,MiN)(1)
其中,N是所有技术词汇和任务词汇数量的总和,Mij的值是学生的提问发言中第j个词出现的次数。如果学生的提问发言中第j个词没有出现,则Mij=0。在对教科书目录和词汇表的分析中得到2 233个技术词汇,同时让标注者手工选取了1 587个任务词汇,因此这里N=3 820。
根据教学内容的不同,学生的发言和相关的教学文档可以分成若干不同的主题。例如,有的学生提问是关于加密算法的,有的问题则是关于数字签名的。为了进一步提高推荐文档的相关性,首先需要过滤掉和当前提问主题无关的文档。
本文采用Rocchio-Style算法来实现对文档的主题识别。Rocchio-Style算法被广泛应用于信息检索领域的主题检测和跟踪[ 9, 10, 11]。Rocchio-Style算法为每一个类别(或主题)产生一个Profile Vector,这个Profile Vector是由训练集中正例和反例的加权平均产生。当训练集较小时,Rocchio-Style算法尤为有效。
根据建立的技术词汇本体,所有文本被分成6个主题。每一个主题包含教科书中的一个或多个章节,对应技术词汇层次树中的一个或多个子树。本文通过计算一个新文档向量和主题向量之间的夹角余弦来决定一个新文档所属的类别。利用Rocchio-Style分类器,事先将文档库中的所有文档片段分类到6个主题中。每当有学生提问发言时,也用同一分类器将发言分类到6个主题中的一个。当系统为这一提问推荐相关文档时,只会考虑与问题属于同一主题的文档,其他类别的文档在这一步骤中会被过滤掉。
为了从许多潜在文档中挑选最佳文档推荐给学生,需要计算每一个文档对于当前问题的得分。计算文档得分的目的在于给这些文档排序,从而将得分最高的文档推荐给学生。计算学生提问发言和文档库中每一个文档的得分可以有很多种方法,这里使用信息检索中最常用的TF-IDF法[ 12, 13, 14]和潜在语义分析法[ 15, 16]。
(1)TF-IDF
TF(Term Frequency)对文档中出现次数很多的词汇赋予较高的得分,对于那些出现次数很少的词汇则赋予较低的得分。IDF(Inverted Document Frequency)对整个语料中经常出现的词汇赋予较低的得分,对整个语料中很少出现的词汇则赋予较高的得分。较高的TF-IDF值意味着这个词在给定文档中有较高的出现频率,并且这个词在整个语料中有较低的出现频率。在本研究中将TF标准化来度量词ti在文档dj中的重要程度。
(2)潜在语义分析
潜在语义分析是把高维的向量空间模型(VSM)表示中的文档映射到低维的潜在语义空间中。这个映射是通过对项/文档矩阵的奇异值分解(SVD)来实现的。潜在语义分析把这个矩阵转化成词与某些概念之间的关系,以及这些概念与文档之间的关系,这样词和文档就通过概念间接联系起来。Term-Document矩阵降维需要进行奇异值分解,本文采用传统的大矩阵方法(Lanczos方法)来完成。
(3)计算文档得分
将文档用向量表示后,用夹角余旋[ 17]来计算学生问题Q与文档库中文档Di的相似度。基于夹角余旋的相似度计算方法如下:
sim(Q,Di)=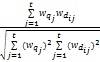
其中, 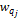
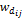
本文设计了一个实验研究和一个实地研究来进行系统评估。第一个实验研究比较了三种不同推荐算法所推荐文档的相关性,第二个实地研究将系统用于一个学期的在线课堂,来评估系统在真实环境中刺激学生思考和研讨的效果以及用户的主观评价。
实验的目是评价不同算法推荐文档的相关性,对算法设定了三种不同的参数:
(1)主题分类过滤。主题分类过滤将文档库中的所有文档以及学生提问进行主题分类,只有与问题属于同一主题的文档才有可能被推荐给学生。
(2)用TF-IDF的方法将文档转换为向量。
(3)用LSA的方法将文档转换为向量。
根据这三种参数的不同组合,产生了三种不同的推荐算法:
(1)仅使用TF-IDF。
(2)使用TF-IDF+主题过滤。
(3)使用TF-IDF+LSA+主题过滤。其中LSA取两种不同的维度:一种是k=75,另一种是k=300。与TF-IDF的方法一起,这三种方法各自独立为文档排序。最终决定文档次序的是三种排序的平均值。
本文从一个E-learning系统中随机抽取了30个主题,系统根据这些主题的第一个发言自动产生3个推荐文档。聘请两位评估者用1-4(1表示完全不相关,2表示相关程度低,3表示相关程度中等,4表示相关程度高)4个等级来评价系统推荐文档的相关性。两位评估者间的信度的Kappa值是0.767。表2显示了系统推荐的3个文档与当前问题的相关性。将评价者给出的1-4级评分转化为0-1之间的数字(0表示完全不相关,1/3表示相关程度低,2/3表示相关程度中等,1表示相关程度高)。
| 表2 不同算法推荐文档的性能对比 |
可以看出,在3种算法中,TF-IDF+主题过滤(平均相关性=0.57)比仅仅使用TF-IDF(平均相关性=0.55)推荐文档的相关性更高,说明通过加入主题过滤具有一定过滤噪音的作用。引入了LSA后推荐文档的相关性反而比较差(平均相关性=0.43),可能是因为目前使用LSA没能有效反映概念的相关性,尤其是领域词汇的相关性。表2同时还显示了最佳文档的MRR(Mean Reciprocal Rank)。MRR越大,说明相关性最大的文档越有可能出现在推荐结果的靠前位置,有利于用户以最小的力气发现最相关的文档。从实验结果可以看出,TF-IDF + 主题过滤(MRR=0.67)比单纯的TF-IDF方法(MRR=0.65)在MRR指标上有一定的提升,而TF-IDF+ LSA (k=75) + LSA (k=300) + 主题过滤的方法(MRR=0.57)则要差很多。
综上所述,本文认为TF-IDF方法比LSA方法更适合在E-learning这样的高噪音环境中推荐相关文档。同时,实验结果表明用TF-IDF+ 主题过滤算法可以获得最好的推荐性能,因此本文在真实系统中采用TF-IDF + 主题过滤的方法来检索文档。
本研究将在线推荐系统集成到PedaBot系统中并用于某大学高年级的操作系统课程的教学讨论,使用的一些基本情况如表3所示:
| 表3 集成推荐功能的E-learning系统使用情况统计 |
可以看到,大部分学生都是男性。在一个15周的学期中,问答推荐系统这一功能在第4周被引入到系统中。刚开始的时候,为了对比有问答推荐系统和没有问答推荐系统的主题的不同效果,只为一半的主题提供自动推荐功能,而另一半的主题不提供自动推荐的功能。但是后来发现这一功能很少被学生使用,大部分学生都没有注意到有这个新增的功能。所以到后期,所有的主题都提供自动推荐的功能。除去管理和幽默讨论区的主题,在所有的301个研讨主题中问答推荐系统为其中的127个主题推荐了相关文档。只能通过一个学生是否查看过推荐详细内容来判断这个学生是否使用过问答推荐系统。
同时可以看到,女生对研讨的参与度低于男生。然而,在所有的研讨参与者中,女生查看研讨详细内容的比率要比男生高(78%对67%)。表3还显示了平均每人查看推荐详细内容的次数和平均相关性评价。在使用问答推荐系统的7个女生中,平均每人只查看了大约3次系统推荐的详细内容。因此如何让女生更积极地使用问答推荐系统是未来需要研究的一个问题。学生仍然用1-4的等级对推荐文档的相关性进行评价,其中1代表完全不相关,4代表高度相关。学生对推荐文档给出的评价的平均值(2.6)与实验评估类似,即可以认为系统可以推荐具有中等相关性的文档给用户。
笔者对比了有推荐文档的主题和没有推荐文档的主题,如表4所示:
| 表4 有推荐文档的主题和没有推荐文档的主题包含的发言数量比较 |
可以看到,有推荐文档的主题包含的发言数量比没有推荐文档的主题要更多,这对于女生尤为明显。这说明推荐文档可以促进学生研讨,因为外部推荐的信息为学生提供了更多的线索和材料,可供学生进一步思考。从对等学习的角度上说,这种促进作用是非常有益的,因为这意味着学生可以在系统的帮助下对所学内容进行更深刻的思考和理解。
最后在学期结束的时候向每一位学生发放了问卷调查,所有使用过问答推荐系统的学生被要求用1-4(完全没有、很少的、有点、很强)的度量来评价系统的趣味性、有用性和易用性。其中有用性和易用性是信息技术采纳模型中经常使用的两个指标,被认为是用户使用系统的两个重要前置变量[ 18, 19, 20]。用户对系统的趣味性、有用性和易用性都给出了较高的评价,如表5所示:
| 表5 用户对文档推荐系统的主观评估 |
学期结束时笔者还与部分学生进行了访谈,让他们谈谈喜欢或不喜欢这项功能的原因,以及可能的改进方法。有学生说推荐系统提供了一个发现过去相关研讨信息的一站式功能,可以帮助他们很容易地获得过去的相关讨论,用户不再需要选择关键词并输入这些关键字来查询。同时很多学生承认从过去的研讨中直接获得了问题的答案或帮助他们进一步思考。但是也有学生认为系统推荐的有些文档相关性较差,会严重影响用户在未来继续使用这一功能(查看推荐的文档)的可能性。
研究开发有效的自动化在线督导工具,一直是E-learning领域的学者和实践者的目标。本文从一个全新的角度,通过挖掘历史研讨记录来促进学生思考和解决问题,从而达到自动督导的目的。通过实验研究和实地研究证明,中等相关程度的历史研讨记录可以通过算法以一种自动化的方式被挖掘出来,向学生提供这些文档可以有效促进学生思考和研讨。这为将来进一步研究以促进学生思考和研讨为目的的推荐系统提供了理论依据,同时本文所提的算法也为未来同类算法改进研究提供了一个参考。
当然,本文所提方法还有很多可以改进的地方,如考虑更多的推荐算法以及这些算法的组合与改进、考虑更多的信息源(如直接考虑Web上的信息)等,笔者在后续研究中将会考虑这些问题。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|