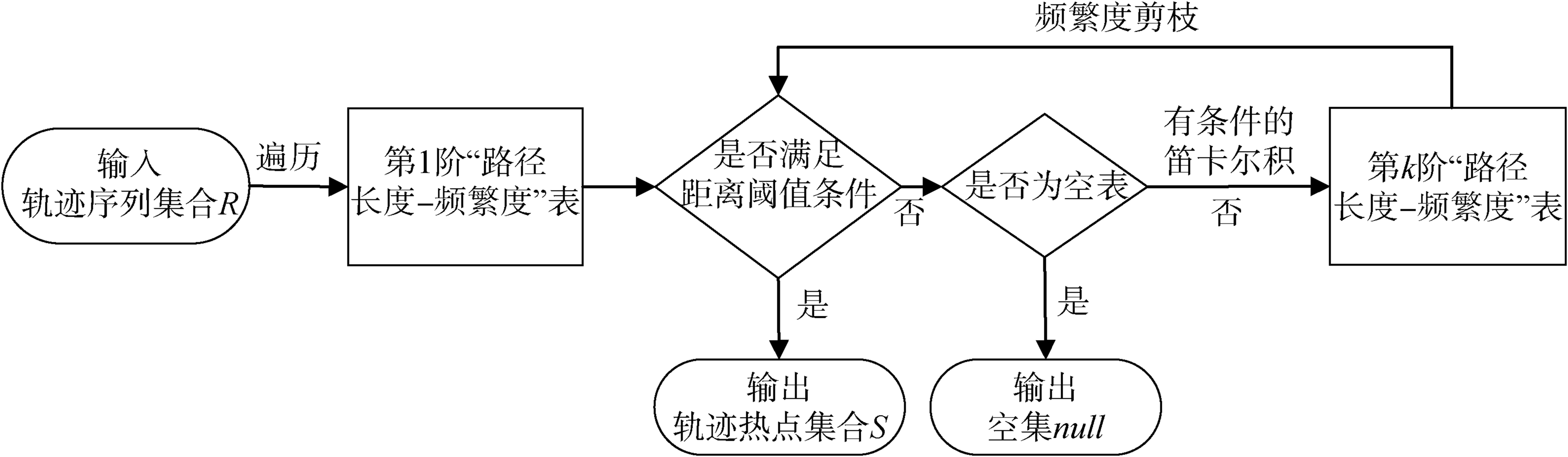
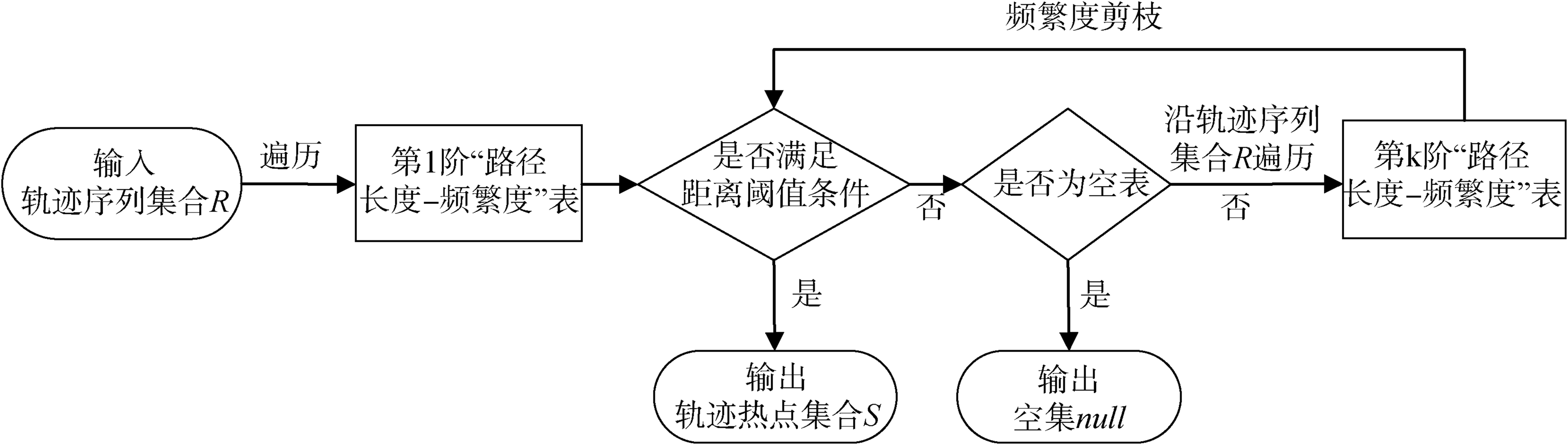
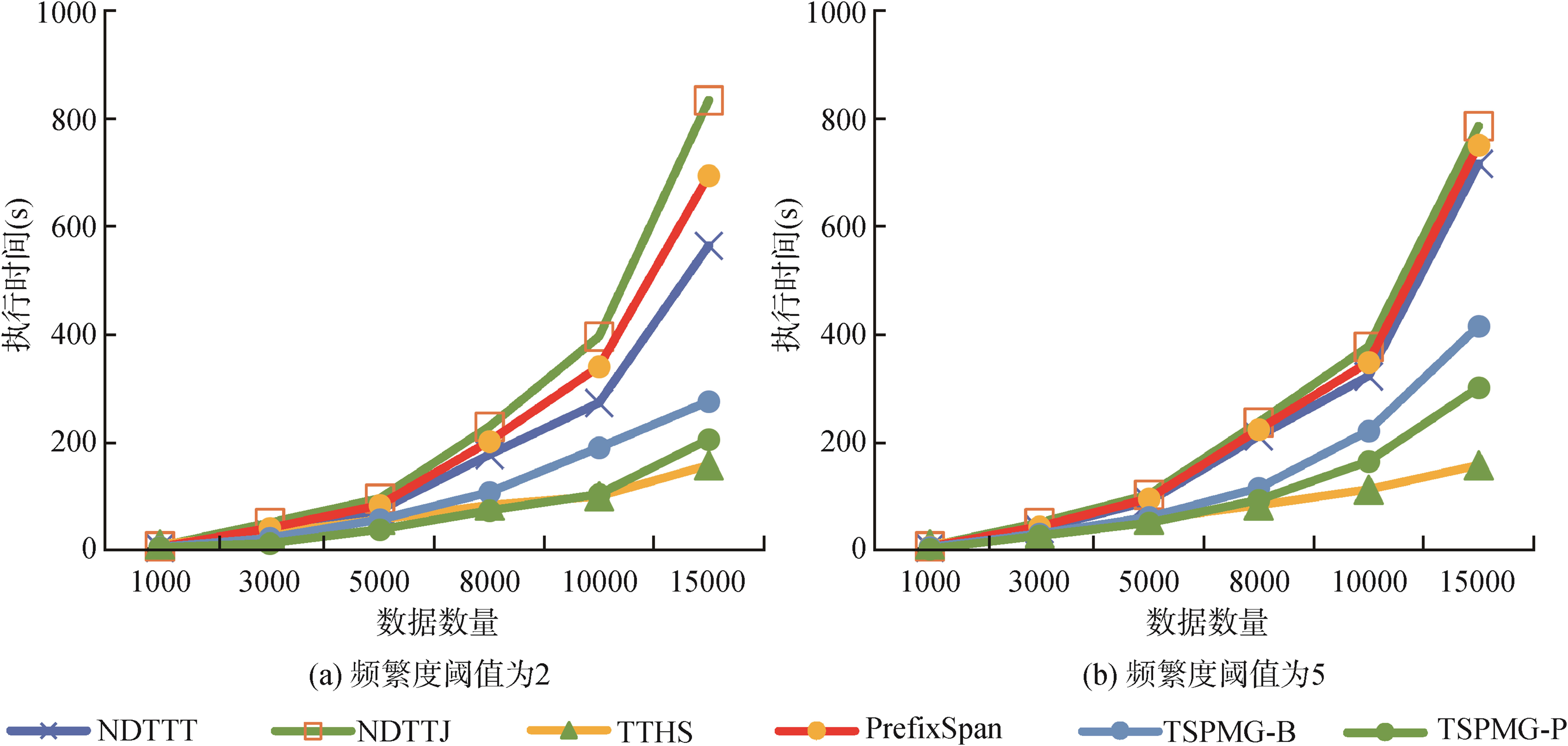
[Objective] This paper proposes multiple Trajectory Traversal Hotspots Mining algorithms based on different trajectory characteristics like N-Degree Trajectory Table Join, N-Degree Trajectory Table Traversal, and graph databases. These algorithms will help us reduce the time and space complexity of trajectory hotspots mining, [Methods] If the trajectory data does not form a complete graph structure, we will use the N-Degree Trajectory Table Join algorithm or N-Degree Trajectory Table Traversal algorithm to iterate the path table multiple times. Based on the distribution density of the trajectory data, the algorithms help us obtain the hotspots. If the trajectory data forms a graph structure, the Trajectory Traversal Hotspots Search algorithm will perform traversal search and pruning optimization to obtain the trajectory hotspots. [Results] We conducted experiments with the ChoroChronos open-source dataset. Regarding time complexity, the running time of the Trajectory Traversal Hotspots Search algorithm was reduced by 25% compared with the best comparison algorithm. Regarding space complexity, the N-Degree Trajectory Table Join algorithm and N-Degree Trajectory Table Traversal algorithm consume 67% less memory space than the best comparison algorithm. [Limitations] We still need to fully utilize the temporal features in the trajectory sequences and should conduct experiments on a more comprehensive dataset. [Conclusions] Compared with other trajectory hotspots mining algorithms, the proposed one effectively reduces the space and time complexity.
(Zeng Qingtian, Dai Mingdi, Li Chao, et al. Discovering Important Locations with User Representation and Trace Data[J]. Data Analysis and Knowledge Discovery, 2019, 3(6): 75-82.)
(Lu Yanling, Wei Jingshan, Zhao Yumeng, et al. Research on Cluster Analysis of Spatio-Temporal Trajectory Data for Extracting Hot Spots[J]. Mathematics in Practice and Theory, 2021, 51(13): 129-138.)
[3]
Li H H, Liu J X, Wu K F, et al. Spatio-Temporal Vessel Trajectory Clustering Based on Data Mapping and Density[J]. IEEE Access, 2018, 6: 58939-58954.
doi: 10.1109/ACCESS.2018.2866364
(Wang Kan, Mei Kejin, Zhu Jiahui, et al. Hotspots Extraction Based on Spatial-Temporal Trajectory Data[J]. Journal of University of Electronic Science and Technology of China, 2019, 48(6): 925-930.)
[5]
Gariel M, Srivastava A N, Feron E. Trajectory Clustering and an Application to Airspace Monitoring[J]. IEEE Transactions on Intelligent Transportation Systems, 2011, 12(4): 1511-1524.
doi: 10.1109/TITS.2011.2160628
[6]
Yuan G, Sun P H, Zhao J, et al. A Review of Moving Object Trajectory Clustering Algorithms[J]. Artificial Intelligence Review, 2017, 47(1): 123-144.
doi: 10.1007/s10462-016-9477-7
(Mou Naixia, Xu Yujing, Zhang Hengcai, et al. A Review of the Mobile Trajectory Clustering Methods[J]. Bulletin of Surveying and Mapping, 2018(1): 1-7.)
doi: 10.13474/j.cnki.11-2246.2018.0001
(Gao Qiang, Zhang Fengli, Wang Ruijin, et al. Trajectory Big Data: A Review of Key Technologies in Data Processing[J]. China Industrial Economics, 2017, 28(4): 959-992.)
[9]
Pei J, Han J W, Mortazavi-Asl B, et al. PrefixSpan: Mining Sequential Patterns Efficiently by Prefix-Projected Pattern Growth[C]// Proceedings of the 17th International Conference on Data Engineering. IEEE, 2002: 215-224.
(Lu Feng, Zhang Weiwei. Research on the Characters of Four Sequential Patterns Mining Algorithms[J]. Journal of Wuhan University of Technology, 2006, 28(2): 57-60.)
doi: 10.1007/s11595-013-0640-6
(Hu Zisong, Wang Lizhen, Vanha Tran, et al. Mining Spatial Prevalent Co-Location Patterns Based on Graph Databases[J]. Journal of Frontiers of Computer Science & Technology, 2022, 16(4): 806-821.)
doi: 10.3778/j.issn.1673-9418.2010015
[12]
Zheng K, Zheng Y, Yuan N J, et al. Online Discovery of Gathering Patterns over Trajectories[J]. IEEE Transactions on Knowledge and Data Engineering, 2014, 26(8): 1974-1988.
doi: 10.1109/TKDE.2013.160
[13]
Zhao P X, Qin K, Ye X Y, et al. A Trajectory Clustering Approach Based on Decision Graph and Data Field for Detecting Hotspots[J]. International Journal of Geographical Information Science, 2017, 31(6): 1101-1127.
[14]
Yang Y F, Cui Z, Wu J, et al. Trajectory Analysis Using Spectral Clustering and Sequene Pattern Mining[J]. Journal of Computational Information Systems, 2012, 8(6):2637-2645.
[15]
Khetarpaul S, Chauhan R, Gupta S K, et al. Mining GPS Data to Determine Interesting Locations[C]// Proceedings of the 8th International Workshop on Information Integration on the Web: In Conjunction with WWW 2011. New York: ACM, 2011: 1-6.
[16]
Li F, Shi W Z, Zhang H. A Two-Phase Clustering Approach for Urban Hotspot Detection with Spatiotemporal and Network Constraints[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2021, 14: 3695-3705.
doi: 10.1109/JSTARS.2021.3068308
[17]
Koperski K, Han J W. Discovery of Spatial Association Rules in Geographic Information Databases[C]// Proceedings of the 4th International Symposium on Advances in Spatial Databases. New York: ACM, 1995: 47-66.
[18]
Agrawal R, Srikant R. Mining Sequential Patterns[C]// Proceedings of the 11th International Conference on Data Engineering. IEEE, 2002: 3-14.
[19]
Bao X G, Wang L Z. A Clique-Based Approach for Co-Location Pattern Mining[J]. Information Sciences, 2019, 490: 244-264.
doi: 10.1016/j.ins.2019.03.072
[20]
Wang X X, Lei L, Wang L Z, et al. Spatial Co-Location Pattern Discovery Incorporating Fuzzy Theory[J]. IEEE Transactions on Fuzzy Systems, 2022, 30(6): 2055-2072.
doi: 10.1109/TFUZZ.2021.3074074
[21]
Lei M T, Zhang X, Chu L Y, et al. Finding Route Hotspots in Large Labeled Networks[J]. IEEE Transactions on Knowledge and Data Engineering, 2021, 33(6): 2479-2492.
doi: 10.1109/TKDE.2019.2956924
[22]
Lei M T, Chu L Y, Wang Z F, et al. Mining Top-K Sequential Patterns in Transaction Database Graphs[J]. World Wide Web, 2020, 23(1): 103-130.
doi: 10.1007/s11280-019-00686-w
[23]
Yoo J S, Boulware D, Kimmey D. A Parallel Spatial Co-Location Mining Algorithm Based on MapReduce[C]// Proceedings of the IEEE International Congress on Big Data. IEEE, 2014: 25-31.
[24]
Refaye E M, Hegazy O. Parallel Co-Location Pattern Mining Discovery Constraint Neighborhood Approach[J]. International Journal of Applied Engineering Research, 2016, 11(1): 586-591.
[25]
Shekhar S, Huang Y. Discovering Spatial Co-Location Patterns: A Summary of Results[C]// Proceedings of the 7th International Symposium on Spatial and Temporal Databases. 2001: 236-256.
[26]
Huang Y, Shekhar S, Xiong H. Discovering Colocation Patterns from Spatial Data Sets: A General Approach[J]. IEEE Transactions on Knowledge and Data Engineering, 2004, 16(12): 1472-1485.
doi: 10.1109/TKDE.2004.90
(Li Xudong, Cheng Feng. Computing Classical Trajectories Using Density-Peak Based Clustering[J]. Journal of China Academy of Electronics and Information Technology, 2019, 14(9): 967-972.)
(Wu Di, Du Yunyan, Yi Jiawei, et al. Density-Based Spatiotemporal Clustering Analysis of Trajectories[J]. Journal of Geo-Information Science, 2015, 17(10): 1162-1171.)
doi: 10.3724/SP.J.1047.2015.01162
(Shen Zhihong, Zhao Zihao, Wang Haibo. Big Data Technology Stack Shifting: From SQL Centric to Graph Centric[J]. Data Analysis and Knowledge Discovery, 2020, 4(7): 50-65.)
[31]
Lake P, Crowther P. Concise Guide to Databases[M]. London: Springer, 2013.
Pelekis N. Trucks Revised[EB/OL]. (2012-06-14). [2022-03-24]. https://ChoroChronos.datastories.org/?q=node/10.
[34]
Zhidchenko T V, Seredina M N, Udintsova N M, et al. Design of Energy-Loaded Systems Using the Neo4j Graph Database[J]. IOP Conference Series: Earth and Environmental Science, 2021, 659(1): 012108.
doi: 10.1088/1755-1315/659/1/012108