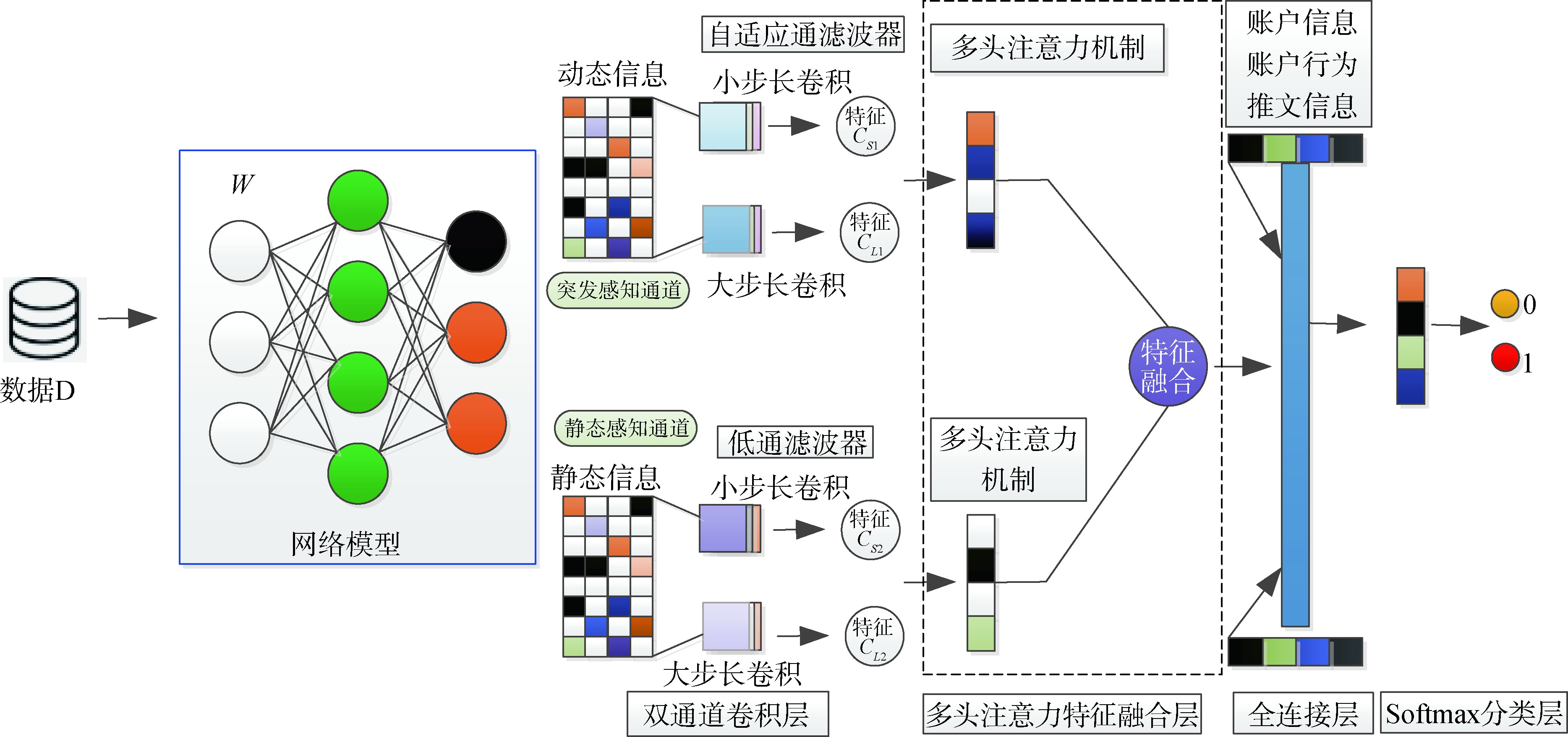
[Objective] This study proposes a deception risk identification model to address the insufficient multimodal feature representation in AI face-swapping fraud detection. [Methods] The FSFRI model captures the generation and dissemination characteristics of fraudulent information by extracting forged face video frame features, traffic description features, traffic payload features, and traffic temporal features. A feature fusion module is then employed to achieve cross-modal feature integration, followed by a risk identification module for assessing deception risks. [Results] On a simulated dataset, the FSFRI model demonstrated superior identification performance, achieving an F1 score of 0.920. It also exhibits strong robustness under low-noise conditions (noise ratio 0~0.2), with a minor F1-score decrease of 0.019 at a 0.2 noise level. [Limitations] The incorporation of multimodal features increases computational complexity, and the model’s performance under high-noise conditions requires further improvement. [Conclusions] By integrating multimodal features generated in AI face-swapping frauds, the proposed model effectively identifies deception risks. It provides valuable support and reference for intelligent prevention and control of telecom and online fraud.

[Objective] This paper proposes a federated learning framework embedded with dual-channel attention convolution. It aims to address the challenge of cross-social-network feature extraction to meet privacy protection requirements and to identify social-bot accurately. [Methods] First, we adopted a federated learning framework to integrate datasets across social networks. Second, we embedded dual-channel attention convolution in the local model module to comprehensively extract data features. Third, we used basic convolutional and blockchain technology in the federated aggregation module to integrate parameters from each local model, enabling parameter acquisition and secure storage of optimal model parameters. [Results] Experiments conducted on the TwiBot-20 and Weibo-bot datasets showed that the proposed model achieved an accuracy of 91.63%, precision of 97.10%, recall of 97.14%, and F1-Score of 96.88%, respectively, demonstrating strong generalization capability. [Limitations] In multi-modal feature extraction, we only considered structured data, text data, and image data; video and audio data were not included. [Conclusions] The proposed model effectively addresses the poor social-bot detection performance caused by insufficient feature extraction and single-source data.
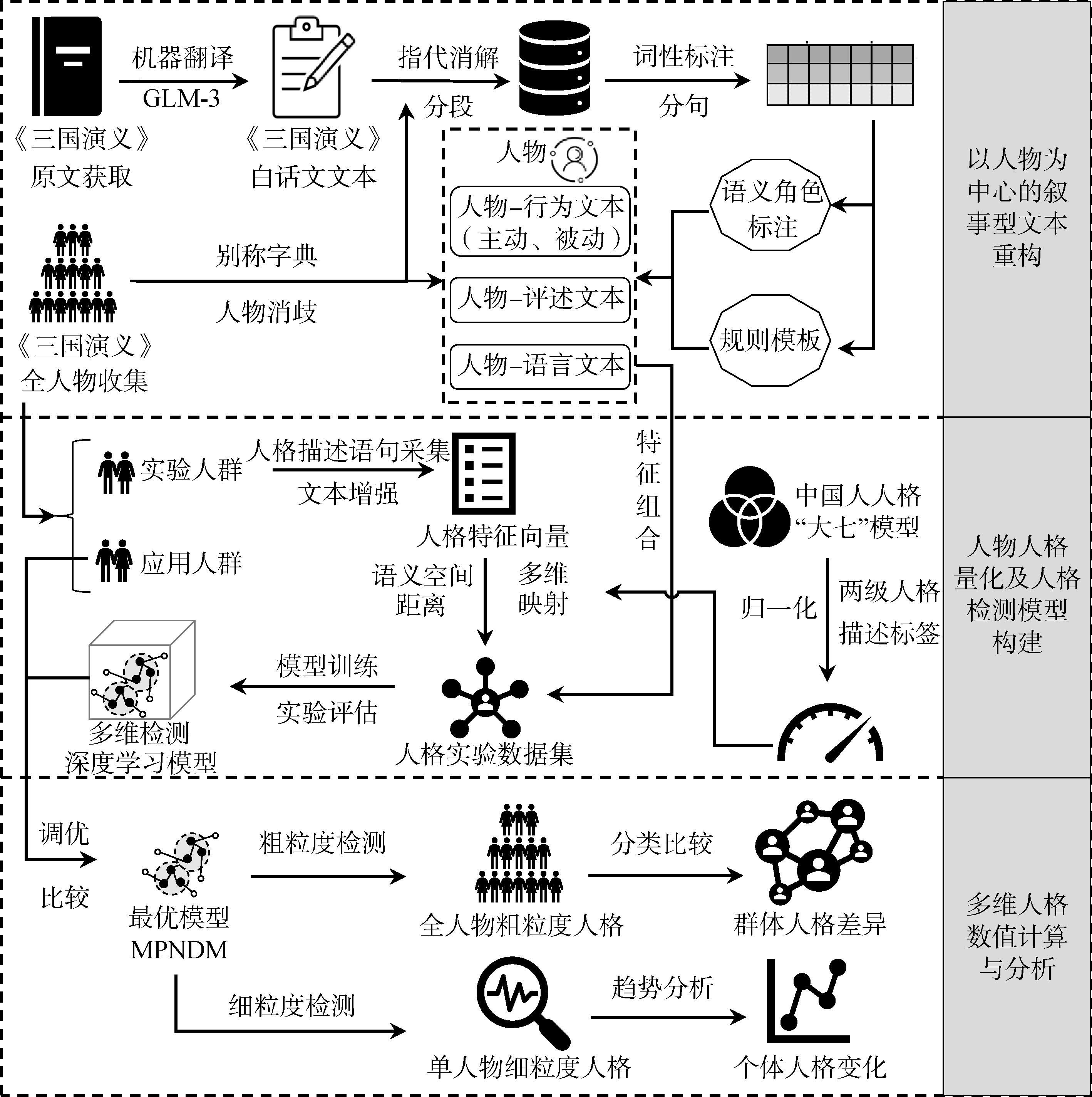
[Objective] This study presents a multidimensional personality computing framework based on narrative text reconstruction, aiming to explore the potential of digital technology in enhancing the depth and breadth of literary character analysis. [Methods] Our research process includes text reconstruction, personality quantification, model construction, and personality analysis. First, we extracted text information using technologies such as machine translation and coreference resolution. Second, we utilized a large language model (LLM) to generate personality descriptions of characters to construct a personality dataset. Third, we built a personality detection model using a deep learning framework. Finally, we conducted multidimensional personality computation and analysis. [Results] Experiments show that the proposed method achieves over 89% accuracy and 74% F1 in main character extraction, with an average Rouge-L of 73.01% for text segmentation. The personality detection model (MPNDM) outperforms baselines by reducing MSE by 29.08% and 8.72%, respectively. A case study on Romance of the Three Kingdoms demonstrates the model’s ability to capture both group and individual personality differences. [Limitations] Since theoretical models and measures of personality vary widely, introducing different theoretical models may yield different results; thus, the model’s generalization ability requires further verification and improvement. [Conclusions] The proposed framework offers a new digital humanities approach to character image appreciation in literary research.
[Objective] To enable early detection of rumors, this study investigates rumor detection models and methods based on text content. [Methods] A Chinese health rumor detection model using multi-scale graph neural networks enhanced by large language models is proposed. First, a text graph is constructed for each individual document to capture latent information in the sentence. Second, entity information is extracted from the text through prompt engineering to enhance knowledge representation. Finally, a multi-scale graph neural network with feature decomposition is employed to perform rumor detection. [Results] The proposed model achieves macro F1 scores of 95.21% and 87.39% on the CHECKED and LTCR datasets, respectively, outperforming existing baseline models. [Limitations] The proposed model relies solely on textual input and dose not incorporate multimodal data such as images or videos. [Conclusions] Utilizing large language models for knowledge enhancement not only facilitates efficient and accurate entity extraction but also enrich sentence semantic representations. The integration of multi-scale graph neural networks with feature decomposition enable effective capture of hierarchical features without compromising computational stability. Constructing individual text graph per document enhances flexibility and adaptability in downstream applications. By combining these components, the overall performance of the model is significantly improved.

[Objective] The systematic utilization of policy documents is hindered by fragmented policy information, heterogeneous structural expressions, and the difficulties in capturing both explicit and implicit knowledge hinder. This study aims to address these challenges and strengthen top-level design and improve the efficient integration and sharing of policy information, by developing a generalizable construction method for policy knowledge graphs that can be adapted to domain-specific needs. [Methods] Drawing on a deconstructionist perspective, multiple theoretical frameworks are aligned to clarify the positioning of policy elements and to establish a multidimensional representation model as the schema layer. Fine-grained extraction techniques—integrating web retrieval, index matching, full-text parsing, entity recognition, and text classification—are designed to populate the data layer. Knowledge storage and visualization are implemented using the Neo4j graph database to generate the final knowledge graph. [Results] The proposed approach yields a universal ontology comprising 11 entity types, 14 relationship types, and 13 attribute types. Extraction standards for 29 fundamental elements and acquisition strategies for 9 domain-specific characteristic elements are defined. A set of efficient extraction methods and a dynamic visualization mechanism are developed. The feasibility and applicability of the method are demonstrated using 258 research integrity policies. [Limitations] As the construction process is primarily top-down, it may overlook innovative features embedded in grassroots policies, suggesting the need for future bottom-up enhancements to better capture emerging elements. [Conclusions] By integrating both general policy features and domain-specific characteristics, the proposed method supports comprehensive extraction of explicit and implicit policy knowledge, reveals deeper policy associations, meets diverse information needs across different fields, and strengthens cross-domain policy analysis and information integration.

[Objective] This paper proposes a knowledge graph completion model integrating temporal information with dynamic graph structure evolution (PaTKGC). It aims to accurately capture interactions between entities over time and to examine the continuous formation patterns reflected in the evolution of local graph structures and global dynamic representations. [Methods] The PaTKGC model first vectorizes the temporal knowledge graph. Then, it aggregates neighborhood information to capture local structural evolution features. Next, the model uses attention mechanisms to compute dynamic correlations across facts at different time points, enabling it to learn temporal evolution patterns. Finally, the model fuses local and global features to complete the knowledge graph. [Results] Extensive experiments on public datasets showed that the proposed model achieved performance comparable to state-of-the-art approaches. It improves Hits@1 and Hits@3 by 0.9 and 1.1 percentage points, respectively. Ablation studies confirm the effectiveness of the model’s improvements for temporal knowledge graph completion tasks. [Limitations] Current knowledge graph completion models rely heavily on datasets with specific formats and high quality; preprocessing costs are high, and performance can degrade under poor data conditions. [Conclusions] The proposed model, which integrates temporal information and dynamic graph evolution, enhances temporal understanding and reasoning through representation enhancement and attention mechanisms.

[Objective] This study addresses the limitations of traditional bibliometric tools, which are unsuitable for fine-grained content analysis of literature and incapable of constructing systematic frameworks of research questions and research methods. [Methods] We constructed an ontology to capture the distinctive features of research questions and methodologies in the literature. Then, we identified graph triples by leveraging both local and global contextual information of input sequences. We also utilized the general intelligence of large language models (LLMs) to enhance the accuracy of triple extraction. Finally, we proposed a method for converting natural language into graph query statements, enabling natural language-based knowledge graph querying. [Results] The proposed method improved the F1 score of entity classification and relation extraction by 9.18 and 8.07 percentage points, respectively. The constructed “Problems and Methods” knowledge graph effectively supports popular research and literature association analysis. With the support of LLMs, it enables high-quality graph-based question answering. [Limitations] The ontology design of the knowledge graph remains incomplete and cannot fully support comprehensive literature content analysis. In addition, triplet extraction using the GPT-4o LLM has relatively low efficiency, limiting its applicability for large-scale graph construction. [Conclusions] The proposed knowledge graph can effectively assist scholars in analyzing the current state of research and literature associations from the perspective of problems and methods. Large language models play an important role in the construction and application of academic graphs.

[Objective] This study aims to address two key challenges in multi-task travel time prediction: the limited flexibility in modeling the ripple effects of road segments, and the reduced learning capability of models under limited labeled data. To this end, we propose a travel time prediction method based on spatio-temporal graph structure learning and route feature enhancement. [Methods] First,we employed a dynamic adaptive mechanism to initialize the spatial structure at each time slice. We then constructed an encoder-only learning module to capture spatio-temporal dependencies among road segments across the entire network. This process enabled the generation of a high-quality spatio-temporal graph that effectively captured ripple effects, along with the corresponding feature representations. Subsequently, we enhanced the expressiveness of route features using the learned representations. We then applied a multi-head attention mechanism to capture implicit spatio-temporal contextual dependencies along the route. Finally, we introduced a hierarchical task-specific training strategy to improve the accuracy of travel time prediction. [Results] Experiments conducted on the Shenzhen dataset demonstrated that the proposed method outperformed all baseline models across multiple evaluation metrics. Compared with the best-performing baseline, it achieved a 1.23% and 5.07% reduction in MAE and RMSE, respectively. Additionally, it lowered MAPE by 0.61 percentage points. [Limitations] Due to the high computational complexity of spatio-temporal graph neural networks, the proposed method is currently suitable only for small- to medium-scale road network scenarios. [Conclusions] Spatio-temporal graph structure learning enables flexible modeling of the ripple effects of road segments and facilitates the generation of expressive spatio-temporal representations. These representations enhance route-level feature learning and support the capture of implicit contextual spatio-temporal dependencies. By integrating a task-specific training module, the proposed method improves both the generalization capability and the robustness of travel time prediction.

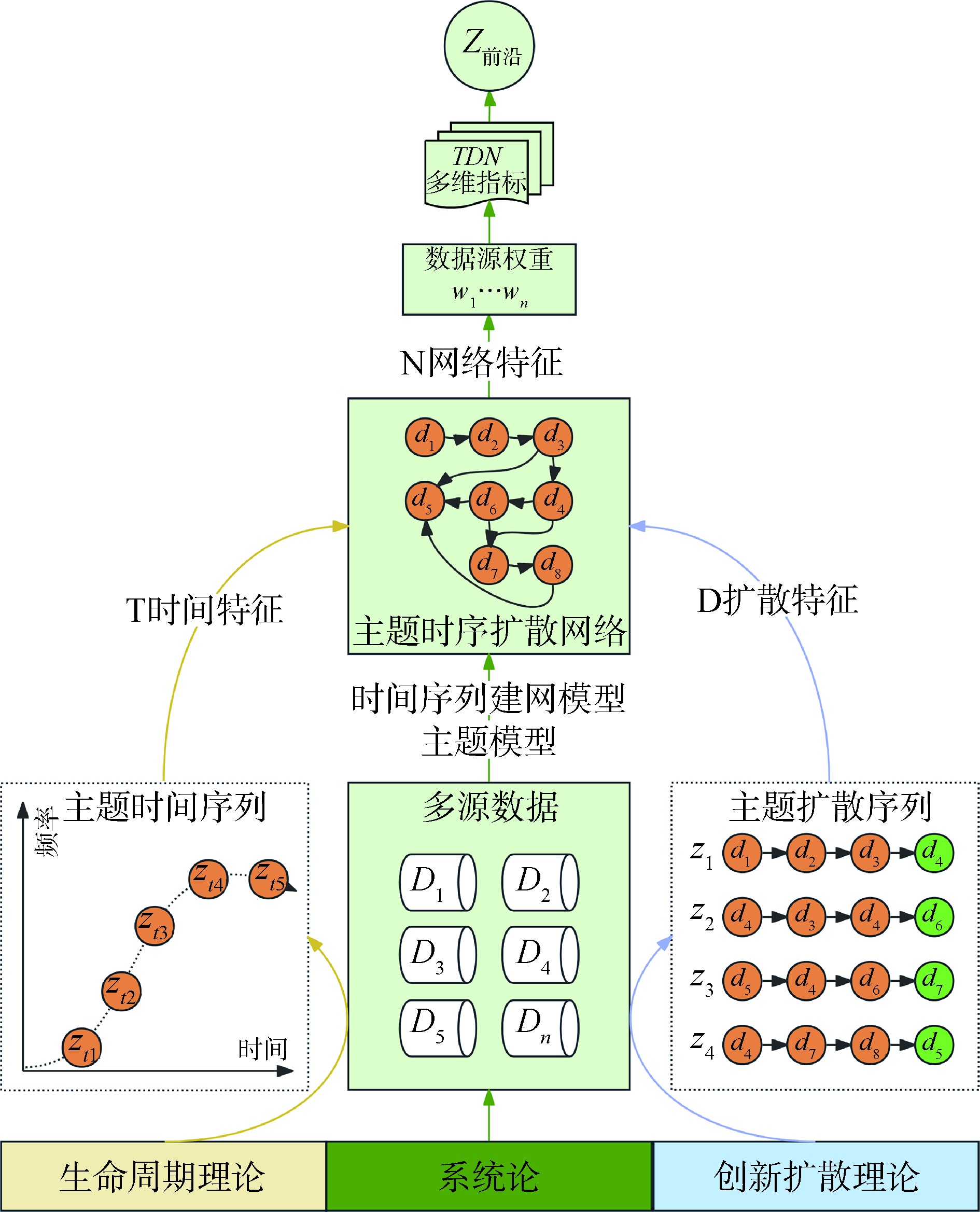
[Objective] To improve the accuracy and foresight of research frontier detection, this study proposes a method that dynamically measures the weights of multi-source data. [Methods] We constructed a topic temporal diffusion network across multi-source data using a Parametric Natural Visibility Graph algorithm. Then, we derived the data-source weight from the out-degree centrality of network nodes. Finally, we used a topic novelty-density-intensity index system with a three-dimensional mapping to distinguish frontier topics. [Results] We conducted an empirical analysis in the field of artificial intelligence, which yielded dynamic data-source weights: strategic planning (0.301), scientific reports (0.234), funded projects (0.124), patents (0.122), conference papers (0.113), and journal papers (0.105). Additionally, eight emerging and three growing research frontier topics were identified. [Limitations] Threshold determination relies on expert judgment, and the method’s cross-disciplinary applicability requires further validation. [Conclusions] The proposed method mitigates expert bias in assigning data-source weights, effectively detects domain frontiers, and introduces a novel “topic temporal diffusion” perspective for frontier analysis.
[Objective] This study aims to clarify research within a domain and identify methodological innovation paths to reveal key directions and evolutionary trends. [Methods] We proposed a methodological knowledge representation model, and used the SciBERT-BiLSTM-CRF model to extract question and method knowledge from full-text papers. Then, we constructed domain questions and methodological innovation networks based on co-occurrence relationships. Finally, we applied community detection and global network search to identify question-oriented innovation paths. [Results] We identified five subdomains in computational linguistics: information extraction, text classification, machine translation, text generation, and semantic analysis—each corresponding to distinct methodological innovation paths. The overall evolution follows two stages: statistical methods and deep learning. [Limitations] Synonym merging in entity extraction needs refinement, and the dataset lacks recent publications. [Conclusions] The proposed method effectively identifies research questions and reveals related methodological innovation paths.

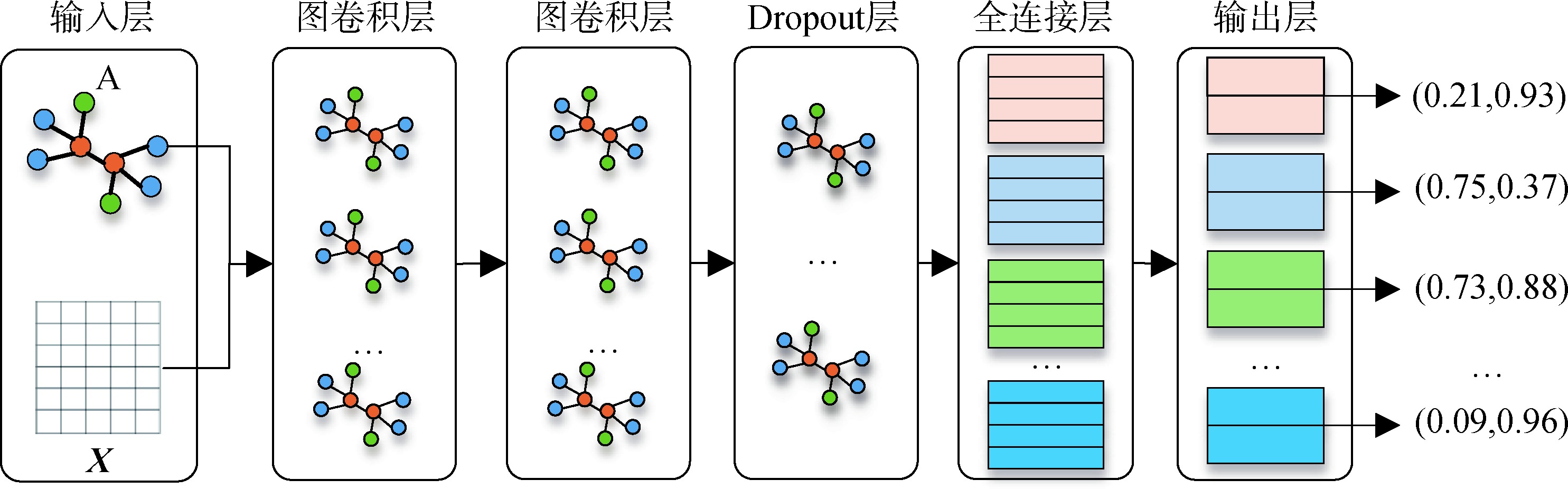
[Objective] This study aims to identify interdisciplinary literature within the dataset, thereby providing vital support for precise navigation and effective resource integration in the field of interdisciplinary research. [Methods] We proposed a method for identifying interdisciplinary literature that used graph neural networks. Specifically, we selected representative literature to train a multi-label classification model based on graph neural networks, which then employed for the identification of interdisciplinary literature. [Results] Under the condition where only 5% of the literature was labeled as representative samples, the proposed method achieved a maximum Area Under the Curve (AUC) value of 0.843 for identifying interdisciplinary literature across the entire dataset. [Limitations] The current method is limited to identifying interdisciplinary literature resulting from the integration of knowledge from two non-interdisciplinary disciplines. It remains incapable of tackling the challenge of identifying multi-disciplinary interdisciplinary literature. Additionally, the effectiveness of the method in identifying interdisciplinary literature at larger disciplinary granularity levels and on large-scale datasets requires further examination. [Conclusions] In comparison with traditional methods for identifying interdisciplinary literature that rely on text classification, the proposed method demonstrates superior performance and provides an effective solution to the issue of the scarcity of labeled training datasets.
[Objective] This study explores the thematic structure and evolution of multimodal user-generated content to enhance the aggregation and utilization of co-created knowledge. [Methods] Combining textual semantics and image features of multimodal user-generated content, we adopted a “model-driven and knowledge-enhanced” paradigm to achieve knowledge aggregation and topic mining. First, we integrated the BERT, Doc2Vec, ResNet, and K-BERT models to capture deep vector representations of text and image data for knowledge enhancement. Second, we constructed a distance matrix to depict the intrinsic correlations among multimodal contents. Finally, we employed the spectral clustering and DTM models to analyze the dynamic evolution of knowledge topics. [Results] Experiments on data from an online community show that the multimodal model integrating “long and short texts + image + external knowledge” significantly improves the knowledge aggregation performance, with a CH index of 62.25, outperforming other model combinations. This approach more effectively clarifies the evolution process of knowledge topics. [Limitations] Our study primarily focuses on the fusion of text and image data, lacking exploration of rich media content such as audio and video. [Conclusions] The proposed framework enhances topic identification and evolution analysis for multimodal user-generated content, thereby improving co-created knowledge management and utilization.

[Objective] To address the challenges of efficiently fusing multi-modal information and inadequate modeling of correlations among emotion labels, this study proposes a multi-modal multi-label sentiment analysis method tailored for social media. [Methods] We constructed a model that integrates both modality-specific features and cross-modal shared features. Then, we utilized a cross-modal bridge connection mechanism to facilitate multi-modal fusion. Finally, we introduced a multi-head self-attention mechanism for multi-label prediction to capture the co-occurrence relationships among different emotion labels. [Results] Experiments on the CMU-MOSEI dataset demonstrated that the proposed model outperformed baseline models under various parameters and comparative settings. The ablation study validated the effectiveness of each module. Compared to the single-modality approaches using text, video, or audio alone, the proposed method improved accuracy by 11.4, 19.9, and 26.8 percentage points, respectively, indicating effective multi-modal fusion. [Limitations] In terms of system performance, the current approach cannot fully capture subtle emotional nuances. Furthermore, our dataset does not cover all possible emotional expressions and cultural contexts, highlighting the need for more diverse data. [Conclusions] The proposed model achieves effective modality fusion, yielding promising results in sentiment analysis.

[Objective] This study proposes a conversational question answering (Q&A) system to address the challenge of natural language queries in bibliographic search systems, which are difficult to accurately map to structured database queries. [Methods] The system employs the Model Context Protocol to achieve seamless integration between the Large Language Model and the external database. To address the issue that exemplar -driven Text-to-SQL generation is susceptible to noise and domain discrepancies, we designed a contrastive learning-based exemplar selection strategy. By fine-tuning the text embedding model to focus more on the syntactic structure and retrieval intent of the query, the quality of similarity ranking is enhanced. We conducted experiments on a constructed bibliographic search semantic parsing dataset to comparatively verify system performance under zero-shot and few-shot conditions. [Results] Compared to the zero-shot setting, the DeepSeek-V3 model achieved an 18.5% increase in SQL execution accuracy in the 5-shot setting, demonstrating the effectiveness of the exemplar selection strategy for the domain-specific Text-to-SQL tasks. [Limitations] Due to the limited coverage of the experimental dataset, the system’s adaptability to cross-domain queries still requires further enhancement. [Conclusions] This research demonstrates the effectiveness of combining large language models with contrastive-learning exemplar selection strategies in intelligent bibliographic search, offering insights for building conversational QA systems in other vertical domains.

