|
|
|
| Patent Keyphrase Extraction Based on Patent Term and Layer Information |
Yu Yan1,2( ),Wang Li1,Zheng Siyu1 ),Wang Li1,Zheng Siyu1 |
1Institute of Information Management and Technology, Nanjing Tech University, Nanjing 210009, China
2College of Electronic and Computer Engineering, Southeast University Chengxian College, Nanjing 210088, China |
|
|
|
|
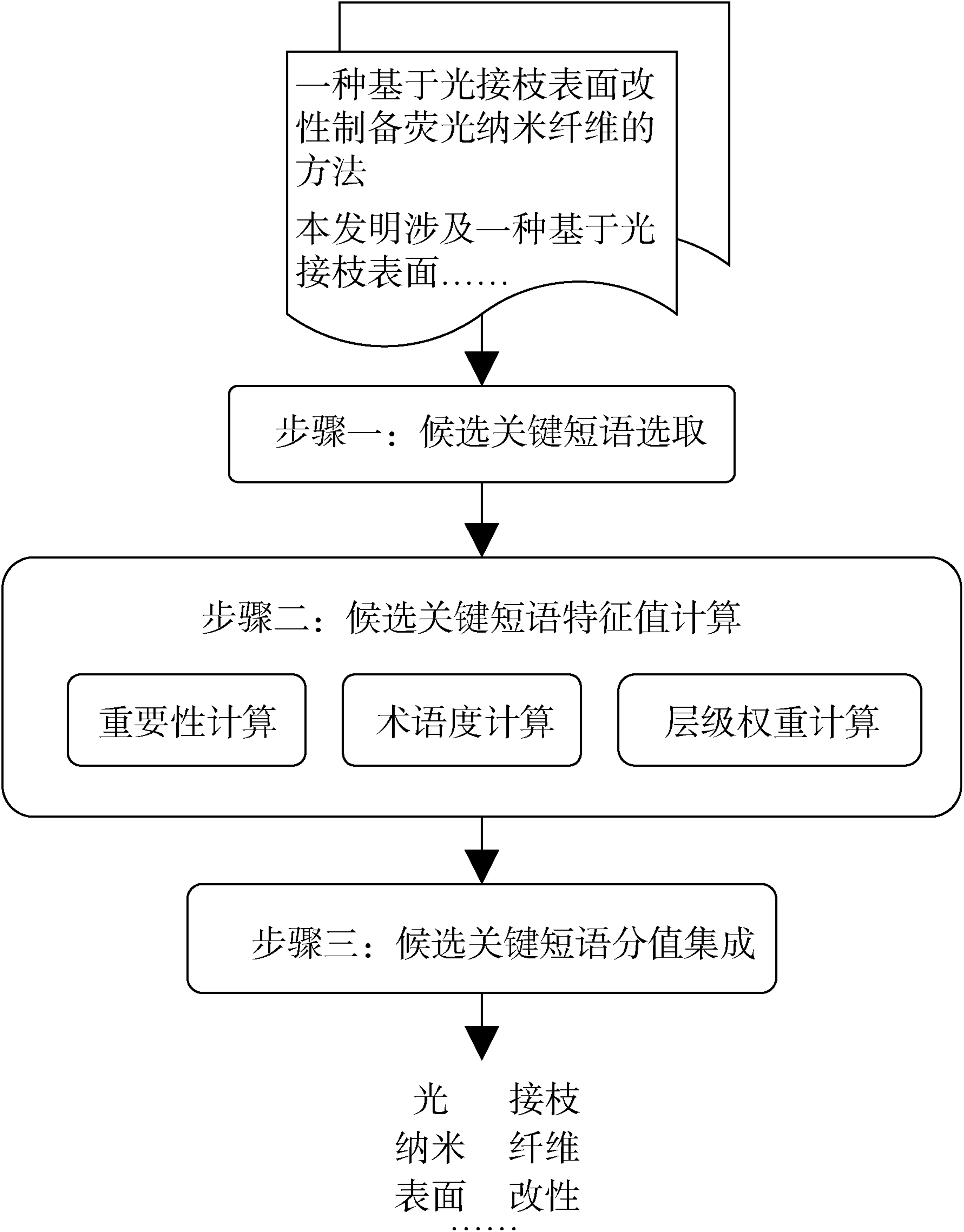
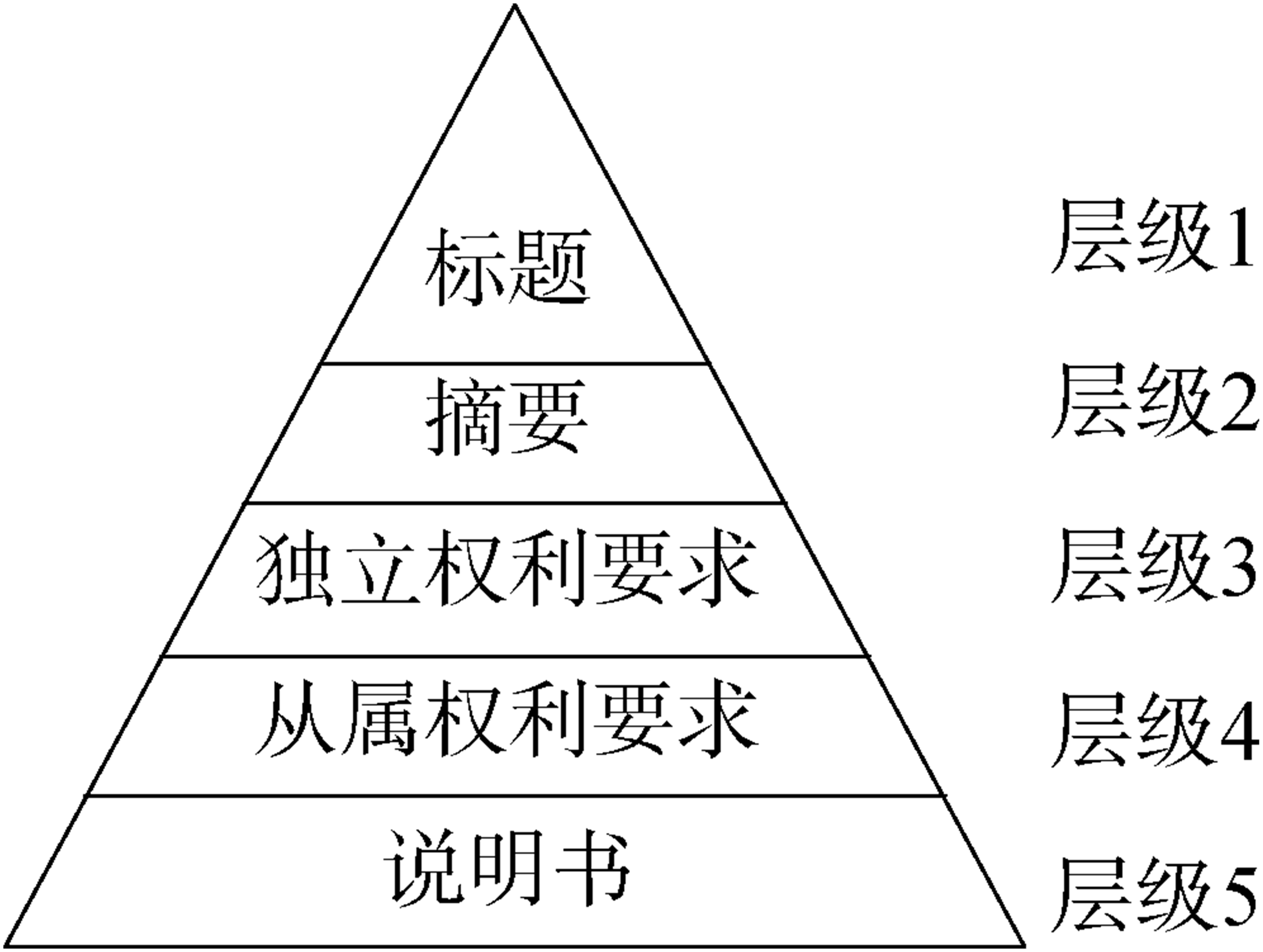
Abstract [Objective] This paper proposes a patent key phrase extraction method incorporating terminology and hierarchical information to improve the accuracy of patent key phrase extraction. It tries to improve the existing graph-based model, which tends to select long key phrases and ignores the phrases’ positional information. [Methods] Based on the traditional graph model, we constructed a new terminology degree metric to measure the terminological information of candidate key phrases. Considering the characteristics of patent documents, we divided patents into several hierarchies and used their weight metrics to measure the positional information of candidate key phrases. [Results] By incorporating terminology information, the F value of the new method improved by 7.615% (nanotechnology), 11.515% (image recognition), 9.813% (chip), and 8.839% (LCD). By incorporating the hierarchical information, the new method’s F value improved by 9.880% (nanotechnology), 6.929% (image recognition), 6.099% (chip), and 5.576% (LCD). [Limitations] The candidate key phrase selection method based on part-of-speech rules may produce more noise. [Conclusions] The proposed method effectively enhances the accuracy of patent key phrase extraction.
|
|
Received: 17 June 2020
Published: 09 August 2023
|
|
|
|
Corresponding Authors:
Yu Yan,ORCID: 0000-0002-9654-8614,E-mail: yuyanyuyan2004@126.com。
|
| [1] |
Mihalcea R, Tarau P. TextRank: Bringing Order into Texts[C]// Proceedings of the 2004 Empirical Methods in Natural Language Processing. ACL, 2004: 404-411.
|
| [2] |
Page L, Brin S, Motwani R, et al. The PageRank Citation Ranking: Bringing Order to the Web[C]// Proceedings of the 1999 International Conference of World Wide Web. 1999.
|
| [3] |
崔振新, 卢昊文. 民航安全信息中实现关键词提取的方法[J]. 交通信息与安全, 2016, 34(5): 82-86.
|
| [3] |
(Cui Zhenxin, Lu Haowen. A Method for Extraction of Keywords from Safety Information in Civil Aviation[J]. Journal of Transport Information and Safety, 2016, 34(5): 82-86.)
|
| [4] |
陈忆群, 周如旗, 朱蔚恒, 等. 挖掘专利知识实现关键词自动抽取[J]. 计算机研究与发展, 2016, 53(8): 1740-1752.
|
| [4] |
(Chen Yiqun, Zhou Ruqi, Zhu Weiheng, et al. Mining Patent Knowledge for Automatic Keyword Extraction[J]. Journal of Computer Research and Development, 2016, 53(8): 1740-1752.)
|
| [5] |
Hu J, Li S B, Yao Y, et al. Patent Keyword Extraction Algorithm Based on Distributed Representation for Patent Classification[J]. Entropy (Basel), 2018, 20(2): 104.
doi: 10.3390/e20020104
|
| [6] |
Das Gollapalli S, Li X L, Yang P. Incorporating Expert Knowledge into Keyphrase Extraction[C]// Proceedings of the 31st AAAI Conference on Artificial Intelligence. New York: ACM, 2017: 3180-3187.
|
| [7] |
Aquino G, Lanzarini L. Keyword Identification in Spanish Documents Using Neural Networks[J]. Journal of Computer Science and Technology, 2015, 15: 55-60.
|
| [8] |
Zhang Q, Wang Y, Gong Y Y, et al. Keyphrase Extraction Using Deep Recurrent Neural Networks on Twitter[C]// Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. ACL, 2016: 836-845.
|
| [9] |
成彬, 施水才, 都云程, 等. 基于融合词性的BiLSTM-CRF的期刊关键词抽取方法[J]. 数据分析与知识发现, 2021, 5(3): 101-108.
|
| [9] |
(Cheng Bin, Shi Shuicai, Du Yuncheng, et al. Keyword Extraction for Journals Based on Part-of-Speech and BiLSTM-CRF Combined Model[J]. Data Analysis and Knowledge Discovery, 2021, 5(3): 101-108.)
|
| [10] |
Wang L T, Li F. SJTULTLAB: Chunk Based Method for Keyphrase Extraction[C]// Proceedings of the 5th International Workshop on Semantic Evaluation. New York: ACM, 2010: 158-161.
|
| [11] |
Noh H, Jo Y, Lee S. Keyword Selection and Processing Strategy for Applying Text Mining to Patent Analysis[J]. Expert Systems with Applications, 2015, 42(9): 4348-4360.
doi: 10.1016/j.eswa.2015.01.050
|
| [12] |
刘峰, 吴瑞红, 徐川, 等. 专利文献中关键词抽取方法的改进[J]. 情报杂志, 2014, 33(12): 36-40.
|
| [12] |
(Liu Feng, Wu Ruihong, Xu Chuan, et al. Keyword Extraction of Patent Document: An Improved Approach[J]. Journal of Intelligence, 2014, 33(12): 36-40.)
|
| [13] |
黄磊, 伍雁鹏, 朱群峰. 关键词自动提取方法的研究与改进[J]. 计算机科学, 2014, 41(6): 204-207.
doi: 10.11896/j.issn.1002-137X.2014.06.040
|
| [13] |
(Huang Lei, Wu Yanpeng, Zhu Qunfeng. Research and Improvement of TFIDF Text Feature Weighting Method[J]. Computer Science, 2014, 41(6): 204-207.)
doi: 10.11896/j.issn.1002-137X.2014.06.040
|
| [14] |
张瑾. 基于改进TF-IDF算法的情报关键词提取方法[J]. 情报杂志, 2014, 33(4): 153-155.
|
| [14] |
(Zhang Jin. A Method of Intelligence Key Words Extraction Based on Improved TF-IDF[J]. Journal of Intelligence, 2014, 33(4): 153-155.)
|
| [15] |
牛萍, 黄德根. TF-IDF与规则相结合的中文关键词自动抽取研究[J]. 小型微型计算机系统, 2016, 37(4): 711-715.
|
| [15] |
(Niu Ping, Huang Degen. TF-IDF and Rules Based Automatic Extraction of Chinese Keywords[J]. Journal of Chinese Computer Systems, 2016, 37(4): 711-715.)
|
| [16] |
Joung J, Kim K. Monitoring Emerging Technologies for Technology Planning Using Technical Keyword Based Analysis from Patent Data[J]. Technological Forecasting and Social Change, 2017, 114: 281-292.
doi: 10.1016/j.techfore.2016.08.020
|
| [17] |
Nguyen K L, Shin B J, Yoo S J. Hot Topic Detection and Technology Trend Tracking for Patents Utilizing Term Frequency and Proportional Document Frequency and Semantic Information[C]// Proceedings of the 2016 International Conference on Big Data and Smart Computing. IEEE, 2016: 223-230.
|
| [18] |
Hofmann T. Probabilistic Latent Semantic Indexing[C]// Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, 1999: 50-57.
|
| [19] |
Blei D M, Ng A Y, Jordan M I, et al. Latent Dirichlet Allocation[J]. Journal of Machine Learning Research, 2003, 3(1): 993-1022.
|
| [20] |
Song Y Q, Pan S M, Liu S X, et al. Topic and Keyword Re-Ranking for LDA-Based Topic Modeling[C]// Proceedings of the 18th ACM Conference on Information and Knowledge Management. New York: ACM, 2009: 1757-1760.
|
| [21] |
Wei H, Gao G, Su X. LDA-Based Word Image Representation for Keyword Spotting on Historical Mongolia Documents[C]// Proceedings of the 23rd International Conference on Neural Information Processing. Springer, 2016: 432-441.
|
| [22] |
顾益军, 夏天. 融合LDA与TextRank的关键词抽取研究[J]. 现代图书情报技术, 2014(7/8): 41-47.
|
| [22] |
(Gu Yijun, Xia Tian. Study on Keyword Extraction with LDA and TextRank Combination[J]. New Technology of Library and Information Service, 2014(7/8): 41-47.)
|
| [23] |
刘啸剑, 谢飞, 吴信东. 基于图和LDA主题模型的关键词抽取算法[J]. 情报学报, 2016, 35(6): 664-672.
|
| [23] |
(Liu Xiaojian, Xie Fei, Wu Xindong. Graph Based Keyphrase Extraction Using LDA Topic Model[J]. Journal of the China Society for Scientific and Technical Information, 2016, 35(6): 664-672.)
|
| [24] |
马力, 焦李成, 白琳, 等. 基于小世界模型的复合关键词提取方法研究[J]. 中文信息学报, 2009, 23(3): 121-128.
|
| [24] |
(Ma Li, Jiao Licheng, Bai Lin, et al. Research on a Compound Keywords Detection Method Based on Small World Model[J]. Journal of Chinese Information Processing, 2009, 23(3): 121-128.)
|
| [25] |
左晓飞, 刘怀亮, 范云杰, 等. 基于概念语义场的文本聚类算法研究[J]. 情报杂志, 2012, 31(5): 180-184.
|
| [25] |
(Zuo Xiaofei, Liu Huailiang, Fan Yunjie, et al. Research of Text Clustering Algorithm Based on Conceptual Semantic Field[J]. Journal of Intelligence, 2012, 31(5): 180-184.)
|
| [26] |
Boudin F. A Comparison of Centrality Measures for Graph-Based Keyphrase Extraction[C]// Proceedings of the IJCNLP 2013 Workshop on Natural Language Processing for Social Media. ACL, 2013: 834-838.
|
| [27] |
李航, 唐超兰, 杨贤, 等. 融合多特征的TextRank关键词抽取方法[J]. 情报杂志, 2017, 36(8): 183-187.
|
| [27] |
(Li Hang, Tang Chaolan, Yang Xian, et al. TextRank Keyword Extraction Based on Multi Feature Fusion[J]. Journal of Intelligence, 2017, 36(8): 183-187.)
|
| [28] |
Florescu C, Caragea C. PositionRank: An Unsupervised Approach to Keyphrase Extraction from Scholarly Documents[C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. 2017: 1105-1115.
|
| [29] |
刘竹辰, 陈浩, 于艳华, 等. 词位置分布加权TextRank的关键词提取[J]. 数据分析与知识发现, 2018, 2(9): 74-79.
|
| [29] |
(Liu Zhuchen, Chen Hao, Yu Yanhua, et al. Extracting Keywords with TextRank and Weighted Word Positions[J]. Data Analysis and Knowledge Discovery, 2018, 2(9): 74-79.)
|
| [30] |
夏天. 词向量聚类加权TextRank的关键词抽取[J]. 数据分析与知识发现, 2017, 1(2): 28-34.
|
| [30] |
(Xia Tian. Extracting Keywords with Modified TextRank Model[J]. Data Analysis and Knowledge Discovery, 2017, 1(2): 28-34.)
|
| [31] |
宁建飞, 刘降珍. 融合Word2Vec与TextRank的关键词抽取研究[J]. 现代图书情报技术, 2016(6): 20-27.
|
| [31] |
(Ning Jianfei, Liu Jiangzhen. Using Word2Vec with Text Rank to Extract Keywords[J]. New Technology of Library and Information Service, 2016(6): 20-27.)
|
| [32] |
Wang R, Liu W, McDonald C. Using Word Embeddings to Enhance Keyword Identification for Scientific Publications[C]// Proceedings of the 26th Australasian Database Conference on Databases Theory and Applications. ACM, 2015: 257-268.
|
| [33] |
Li D C, Li S J, Li W J, et al. A Semi-Supervised Key Phrase Extraction Approach: Learning from Title Phrases Through a Document Semantic Network[C]// Proceedings of the ACL 2010 Conference Short Papers. New York: ACM, 2010: 296-300.
|
| [34] |
Li D C, Li S J. Hypergraph-Based Inductive Learning for Generating Implicit Key Phrases[C]// Proceedings of the 20th International Conference Companion on World Wide Web. New York: ACM, 2011: 77-78.
|
| [35] |
Lynn H M, Choi C, Choi J, et al. The Method of Semi-Supervised Automatic Keyword Extraction for Web Documents Using Transition Probability Distribution Generator[C]// Proceedings of the 2016 International Conference on Research in Adaptive and Convergent Systems. New York: ACM, 2016: 1-6.
|
| [36] |
Frantzi K, Ananiadou S, Mima H. Automatic Recognition of Multi-Word Terms: The C-Value/NC-Value Method[J]. International Journal on Digital Libraries, 2000, 3(2): 115-130.
doi: 10.1007/s007999900023
|
| [37] |
Muralikumar J, Seelan S A, Vijayakumar N, et al. A Statistical Approach for Modeling Inter-Document Semantic Relationships in Digital Libraries[J]. Journal of Intelligent Information Systems, 2017, 48(3): 477-498.
doi: 10.1007/s10844-016-0423-6
|
| [38] |
Le T, Jeong D H. NLP-Based Approach to Semantic Classification of Heterogeneous Transportation Asset Data Terminology[J]. Journal of Computing in Civil Engineering, 2017, 31(6): Article No. 04017057.
|
| [39] |
Yan E J, Williams J, Chen Z. Understanding Disciplinary Vocabularies Using a Full-Text Enabled Domain-Independent Term Extraction Approach[J]. PLoS One, 2017, 12(11): Article No. e0187762.
|
| [40] |
Thanawala P, Pareek J. MwTExt: Automatic Extraction of Multi-Word Terms to Generate Compound Concepts within Ontology[J]. International Journal of Information Technology, 2018, 10(3): 303-311.
doi: 10.1007/s41870-018-0111-6
|
| [41] |
Bagheri A, Nadi S. Sentiment Miner: A Novel Unsupervised Framework for Aspect Detection from Customer Reviews[J]. International Journal of Computational Linguistics Research, 2018, 9(2): 120-130.
doi: 10.6025/jcl/2018/9/2/120-130
|
| [42] |
Haque R, Penkale S, Way A. TermFinder: Log-Likelihood Comparison and Phrase-Based Statistical Machine Translation Models for Bilingual Terminology Extraction[J]. Language Resources and Evaluation, 2018, 52(2): 365-400.
doi: 10.1007/s10579-018-9412-4
|
| [43] |
Li Z, Tong X, Zhang Y. Constructing the Phrase Dictionary and Visualizing Consumer Behaviors in the Food Industry Based on Online Reviews During the COVID-19 Pandemic[J]. CONVERTER, 2021: 624-632.
|
| [44] |
Lahiri S, Mihalcea R, Lai P H. Keyword Extraction from Emails[J]. Natural Language Engineering, 2017, 23(2): 295-317.
doi: 10.1017/S1351324916000231
|
| [45] |
王志宏, 过弋. 基于词句重要性的中文专利关键词自动抽取研究[J]. 情报理论与实践, 2018, 41(9): 123-129.
doi: 10.16353/j.cnki.1000-7490.2018.09.021
|
| [45] |
(Wang Zhihong, Guo Yi. Automatic Keywords Extraction from Chinese Patents Based on Sentence Importance Ranking[J]. Information Studies: Theory & Application, 2018, 41(9): 123-129.)
doi: 10.16353/j.cnki.1000-7490.2018.09.021
|
| [46] |
Carletta J. Assessing Agreement on Classification Tasks: The Kappa Statistic[J]. Computational Linguistics, 1996, 22(2): 249-254.
|
| [47] |
陆伟, 程齐凯. 一种基于加权网络和句子窗口方案的信息检索模型[J]. 情报学报, 2013, 32(8): 797-804.
|
| [47] |
(Lu Wei, Cheng Qikai. An Information Retrieval Model Based on Weighted Graph and Sentence[J]. Journal of the China Society for Scientific and Technical Information, 2013, 32(8): 797-804.)
|
| [48] |
柳林青, 余瀚, 费宁, 等. 一种基于TextRank的单文本关键字提取算法[J]. 计算机应用研究, 2018, 35(3): 705-710.
|
| [48] |
(Liu Linqing, Yu Han, Fei Ning, et al. Key-Word Extracting Algorithm from Single Text Based on TextRank[J]. Application Research of Computers, 2018, 35(3): 705-710.)
|
| [49] |
Wan X, Xiao J. CollabRank: Towards a Collaborative Approach to Single-Document Keyphrase Extraction[C]// Proceedings of the 22nd International Conference on Computational Linguistics. 2008: 969-976.
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|