

{kind=link}
{kind=link}
{kind=link}
{kind=link}
实时虚拟参考咨询服务新尝试——清华大学图书馆智能聊天机器人
引用本文
姚飞, 纪磊, 张成昱, 陈武. 实时虚拟参考咨询服务新尝试——清华大学图书馆智能聊天机器人. 现代图书情报技术, 2011, 27(4): 77-81
Yao Fei, Ji Lei, Zhang Chengyu, Chen Wu. New Attempt on Real-time Virtual Reference Service——The Smart Chat Robot of Tsinghua University Library. 现代图书情报技术, 2011, 27(4): 77-81
Permissions
Yao Fei, Ji Lei, Zhang Chengyu, Chen Wu. New Attempt on Real-time Virtual Reference Service——The Smart Chat Robot of Tsinghua University Library. 现代图书情报技术, 2011, 27(4): 77-81
Copyright©2011, 《现代图书情报技术》编辑部
《现代图书情报技术》编辑部
实时虚拟参考咨询服务新尝试——清华大学图书馆智能聊天机器人
摘要
实时虚拟参考咨询服务在图书馆服务中发挥着积极且重要的作用。清华大学图书馆基于开源软件A.L.I.C.E.开发出实时智能聊天机器人“小图”,提供参考咨询、图书搜索、自我学习等多种服务,并将其推广至社交网络,取得良好的效果。
关键词:
虚拟参考咨询; 智能聊天机器人; 自我学习; A.L.I.C.E.
中图分类号:TP311
New Attempt on Real-time Virtual Reference Service——The Smart Chat Robot of Tsinghua University Library
Abstract
Virtual reference service is playing an active and important role in library services. Based on the open source software A.L.I.C.E., Tsinghua University Library develops the real-time smart chat robot -“Xiaotu” to provide various services, including reference service, booking searching, self-learning etc, and promotes “Xiaotu” into the social networking site, and achieves good results.
Keyword:
Virtual reference service; Smart chat robot; Self-learning; A.L.I.C.E.
1 引 言
实时虚拟参考咨询服务在图书馆服务中发挥着积极且重要的作用。将人工智能运用到参考咨询中、以聊天机器人的身份提供参考咨询服务是一种新的尝试。本文以清华大学图书馆聊天机器人为例,对人工智能实时虚拟参考馆员的设计和实现进行阐述。
2 需求及技术思路
2.1 现状及需求
实时虚拟参考咨询服务以交互方式为读者提供针对性的个性化服务,方便快捷,而且用户体验好。在图书馆中使用的实时虚拟参考咨询服务系统一般有两类:
(1)图书馆专用系统,例如:国外的QuestionPoint[ 1] (又称第二代CDRS)和24/7 Reference[ 2];国内的国家科技图书文献中心(NSTL)实时咨询服务系统[ 3]以及CALIS分布式联合虚拟参考咨询系统(Calis Distributed Collaborative Virtual Reference System,CDCVRS)[ 4];
(2)商用即时通信(Instant Messaging,IM)工具,例如腾讯QQ[ 5]、微软MSN[ 6]、开源软件Meebo[ 7]等。
实时咨询系统的共同特点是必须有参考馆员值守,人工地提供咨询服务,这会带来很多问题。例如,值班咨询馆员的知识有限,可能不能针对性地回答读者问题;咨询馆员工作量增大;非咨询时间不能提供及时有效的在线咨询服务;同一位咨询馆员不可能同时现身在数量众多的社交网络上分别提供咨询服务等。
将人工智能与虚拟参考服务相结合,提供机器人虚拟参考咨询馆员,则至少可以部分地解决上述问题。基于这种考虑,清华大学图书馆设计并实现了虚拟咨询馆员“小图”[ 8]。
2.2 技术思路
在设计风格方面,考虑用户习惯,界面以MSN、QQ等聊天对话风格为首选;在知识结构方面,清华大学咨询服务开展多年,积累了大量宝贵的咨询记录,也整理出很多精选的FAQ,这些内容为“小图”的核心语料库提供了基础;在用户认证方面,用户不需要单独的账户与咨询员对话,省去用户注册的麻烦;在功能配备方面,通过各种精心设计,让用户意识不到他在与机器人聊天,而是感觉有馆员值班在线;在服务场所方面,众多社交网站发展迅速且影响巨大,希望能够将“小图”推广到这些社交网络上以发挥更大的作用。
3 聊天机器人的构建
3.1 聊天机器人的选型
在智能聊天机器人选型方面,MSN聊天机器人、XIAOI聊天机器人[ 9]和自然语言互联网计算机实体(Artificial Linguistic Internet Computer Entity,A.L.I.C.E.)[ 10]都被纳入研究对象并进行了尝试。MSN机器人要求用户登录、对含有中文的URL判断不准且会推送广告。网页版XIAOI聊天机器人虽无需登录,但是其免费版本功能有限,且服务器不稳,经常宕机。最后,选用了开源软件A.L.I.C.E.。A.L.I.C.E.于1995年由Wallace创建。Wallace还创造了一种名为人工智能标记语言[ 11](Artificial Intelligence Markup Language,AIML)[ 11]的知识描述语言来支持A.L.I.C.E.。无数程序专家在此基础上用多种不同的编程语言补充着免费开源的AIML语言并用多种语言出版,在世界各国流传[ 12]。A.L.I.C.E.先后三次获得了罗纳奖(2000年、2001年和2004年)。A.L.I.C.E.基于模式匹配方法,加入启发式会话规则,具有学习、推理、判断、记忆以及上下文获取等功能。AIML基于XML标准的丰富标签库,可以方便地在一个AIML文档中创建和共享知识,并把多个AIML文档加载到一起,组成一个“更聪明的”机器人,目前A.L.I.C.E.系统已经存储了4万多条知识分类[ 10]。
3.2 智能聊天机器人的架构
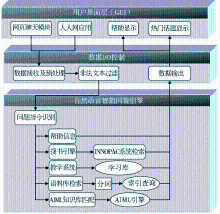
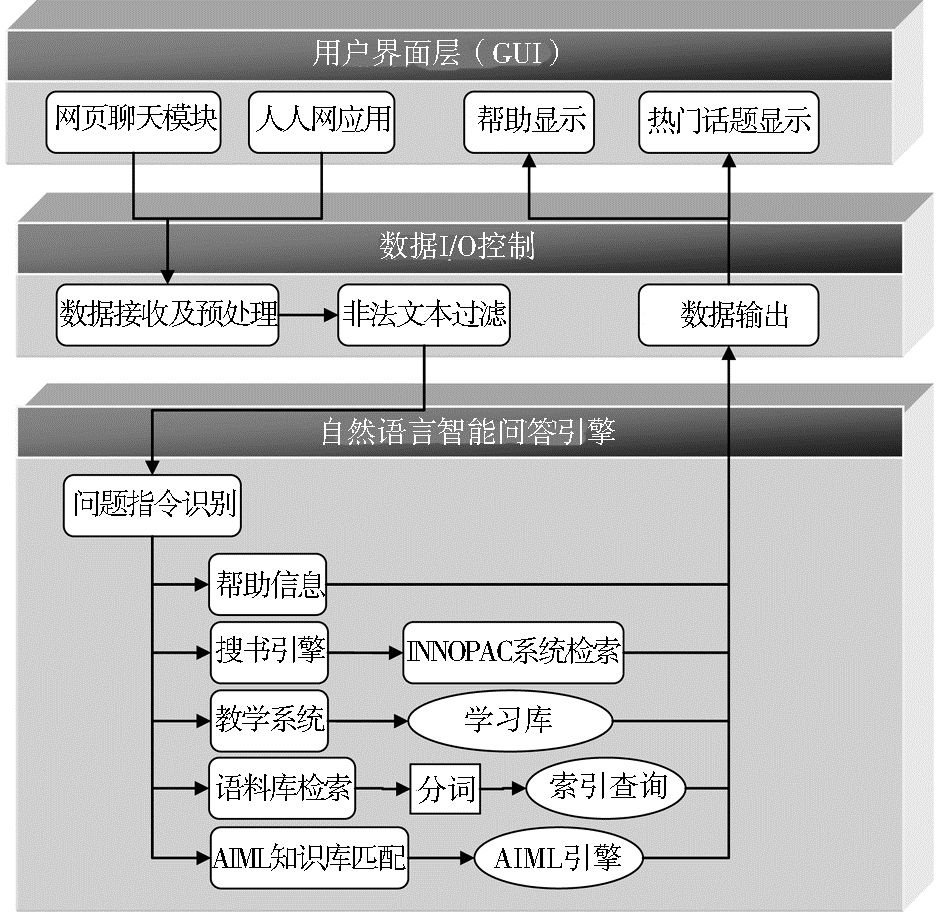
基于A.L.I.C.E.构建聊天机器人“小图”的系统架构,如图1所示:
用户可以通过访问网页、使用人人网应用等形式与“小图”进行交互,通过不同的指令,智能机器人可以为用户提供各种功能。
(1)用户界面层:主要负责与读者用户交互,用户通过对话方式在对话框中输入感兴趣的话题或者查询图书馆的书籍或相关信息。
(2)数据I/O层:主要负责数据的转发和预处理。预处理模块用于过滤停用词和非法词,同时对用户输入的文本进行分类并转发到相应的处理引擎,等待“小图”返回结果后,再将答案返回给用户。数据I/O层基于Java Servlet实现Web服务器功能,并与用户界面层之间建立了Ajax请求服务,以实现聊天应用所需的动态交互。
(3)自然语言智能问答引擎:负责具体的问答,包括帮助信息、搜书引擎、教学系统、语料库检索和AIML知识库匹配等功能模块。
3.3 关键技术实施
(1)语料库设置
语料库检索功能的实现基于搜索引擎技术[ 13]。语料库以XML格式存储,一个问答的存储格式如下:
为了适应多源语料库质量高低不同的现状,设计了语料库优先级系统。将图书馆多年以来积累的咨询记录作为第一优先级语料库,将人工动态添加的问答资料作为第二级语料库,并且将通过教学系统得到的问答知识作为第三级语料库。
(2)中文分词
中文语句每个词之间没有如英文一样的固定空格分割符,为了对其进行索引,必须先进行分词。在自然语言处理领域,中文分词是一个研究热点,一般分为三类:机械分词、基于理解的分词和基于统计的分词[ 14]。在研究了多种开源分词程序后,选择中国科学院计算技术研究所研发的汉语词法分析系统ICTCLAS[ 15]。ICTCLAS采用了层叠隐马尔科夫模型(Hierarchical Hidden Markov Model,HHMM),将汉语词法分析的所有环节都统一到一个完整的理论框架中,获得非常好的总体效果。ICTCLAS分词精度达98.45%,API不超过200KB,各种词典数据压缩后不足3MB,是当前世界上最好的汉语词法分析器之一。此外,在分词后,加入了停用词去除逻辑,去掉比如“啊”、“哎”等一些无用助词以及一些需要过滤的敏感词和不健康词。
(3)索引建立
建立索引是聊天机器人的语料库搜索核心技术之一,目的是加快响应用户的输入。使用了搜索引擎技术中最常用的倒排索引技术,它是“单词”到“文档”的一个映射。由于问答系统中的查询都是输入一段自然语言文本进行搜索,经过中文分词都转化为一系列关键词。利用倒排索引,可以通过关键词找到包含它们的文档集合,然后将其中的每一个文档与查询进行相似度匹配,从而返回与用户查询最相关的答案。
(4)相似度匹配
基于向量空间模型,使用权重计算方法和余弦相似度来判断查询语句和语料库中的一条记录的相似性。在向量空间模型中,用D(Document)表示文本,其泛指机器语言可读的记录;用特征项T(Term)表示出现在文本D中且能够代表该文本内容的基本语言单位,其主要是由词或者短语构成,文本可以用特征项集表示为D(T1,T2,…,Tn),其中Tk是特征项,1≤k≤n,n是文本中的单词数。对含有n个特征项的文本而言,通常会给每个特征项赋予一定的权重表示其重要程度。即D=D(T1,ω1;T2,ω2;…;Tn,ωn),简记为D=D(ω1,ω2,…,ωn),其被称为文本D的向量表示,ω表示权重。具体而言,通过TF-IDF计算特征向量。词频TFi,j表示文本j中包含单词i的频率,逆文档频率IDFi表示总记录数和出现某个单词i的记录数之比的对数,进而在文档j中单词i的TF-IDF权重ωji为TFi, j×IDFi。
在向量空间模型中,查询语句(文本Di)和语料库中的记录(文本Dj)之间的内容相似度用余弦模型表示,具体公式[ 16]为:
Similarity (query,doc) = cosine (Di,Dj) =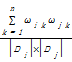
其中,ωik、ωjk分别表示文档i和j中单词k的TF-IDF权重。
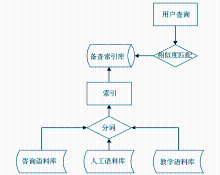
各级语料库中的文本经过中文分词后,建立相应的索引。在后台接收到用户输入后,可以在索引中的记录进行相似度匹配,最终输出最优结果。语料库检索模块的整体流程,如图2所示。
 | 图2 语料库检索模块的处理流程(5)搜书引擎搜书引擎依赖于清华大学图书馆INNOPAC系统[ 17]。在接收到读者的搜书命令(比如“book 围城”)后,搜书引擎使用“围城”作为关键字访问INNOPAC系统,抓取前10条结果并将这些结果的相关信息(例如书名、作者、出版社等)返回给用户,同时给出相应的链接,用户可以通过链接直接访问INNOPAC系统以做进一步的了解。 |
(6)教学系统
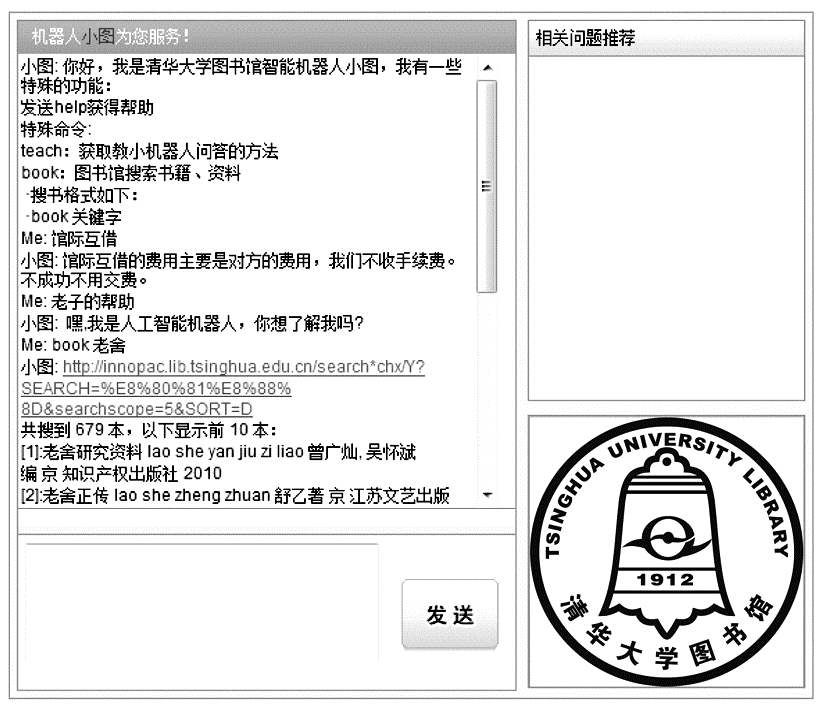
“小图”的教学系统是以一种问答的形式建立的。用户通过输入形如“Q:问题 A:答案”的句式即可进行教学。对于用户赋予的这部分问答知识,教学系统负责将其整合到一个教学语料库中,便于以后与读者交互时提取使用。
(7)推理机制
聊天机器人智能方面的一大体现是:当不能在已有语料库中找到适当答案的时候,能够依靠推理机制从AIML知识库中给出经推理的答案。基于AIML格式的知识库拥有强大的、可扩展的和丰富的推理语法功能,A.L.I.C.E.系统工作流程[ 18]如图3所示:
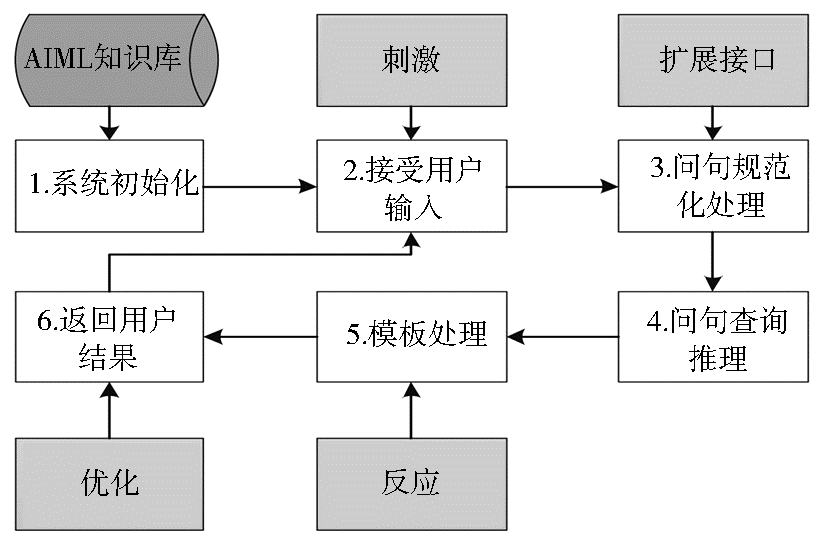 | 图3 A.L.I.C.E.内部推理机制[ 18] |
4 结 语
4.1 应用效果
“小图”一经推出就引起强烈反响,每日最高用户超过千人。仅在人人网上就吸引了1 000多人的关注,并迅速成为网络各大论坛的焦点,引来诸如扬子晚报等多家媒体的报道[ 21]。很多人都不禁感叹“真的是机器人吗,它什么问题都能回答!”,一时吸引了无数的眼球,使得更多的人关注于清华大学图书馆。
“小图”受欢迎的原因主要是以下两个方面:
(1)由于AIML的推理机制,它能够回答几乎所有的问题,并且使用大量网络流行的俏皮语言,使得读者体验到“逗闷子”的乐趣;
(2)它有自我学习功能,读者能够对“小图”进行训练,教它学习原先不会的问题,并且即时生效,这样做的好处是使用户有一种参与的成就感,也使得“小图”的知识库不断丰富,能够有针对性地回答越来越多的问题,因而变得越来越强大。
4.2 问题与思考
在使用过程中,也存在不少问题。在技术方面,虽然英文、法文等外文AIML 知识库已经初具规模,可以在A.L.I.C.E.网站下载[ 22],但是目前尚未发现大规模的AIML中文知识库,原因是多方面的:
(1)A.L.I.C.E.的最初设计针对西方文字的特点,处理过程中没有考虑汉语分词等技术障碍;
(2)汉语与印欧语系的语言差别很大,语序比较自由,虚词运用较多,大量可有可无的句子成分对于AIML的编写非常不利;
(3)单凭个人的力量很难短时间建立,借助互联网的力量也许是一条比较可行的途径。
目前“小图”已经积累了6 000多条中文AIML知识库,大部分是通过教学系统获得并加以人工整理,但这仍难以实现严格意义上的“智能”的需要。在用户对象方面,由于针对匿名用户提供服务,一些素质不高的用户会训练一些不文明、不良或低俗用语,严重影响了服务的严肃性,这已经通过添加屏蔽词表和审核机制得到部分解决。在使用用途方面,用户使用最多的还是“逗闷子”和教学训练,真正用来咨询问题和查询图书的很少。当然这也是预料之中的事情,用户行为具有一个引导过程,需通过更多的方法逐步将读者引导到图书馆相关的事务中来。
4.3 改 进
鉴于以上问题,需要进一步挖掘“小图”在虚拟参考咨询方面的作用,包括推广图书馆的服务、对用户进行引导、建立用户个性化服务、提供智能推荐书籍及相关信息等功能。另外,作为以上功能的基础,如何更加有效地获取和建立语料库、AIML知识库,如何更加准确快速地组织和检索知识,如何对AIML进行合理扩充以增强它的知识表达能力,例如中文分词、同义词处理、中文句式变换,都需要进一步深入的研究。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|