胡晓雪
西安财经学院管理学院 西安 710100
Hu Xiaoxue
中图分类号: C93
通讯作者:
收稿日期: 2017-06-16
修回日期: 2017-09-16
网络出版日期: 2017-12-25
版权声明: 2017 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
展开
摘要
【目的】针对多时段动态客户细分问题, 提出一种面向契约型客户的类结构变动自适应进化聚类框架。【方法】通过构建一个动态更新相似矩阵和聚类参数的聚类环, 实现对客户细分结果的跟踪。在每个聚类时段, 首先, 以前一相邻时段的聚类结果为基础, 依据客户契约的失效信息制定类消亡的判定准则; 其次, 计算原客户在该时段的估计相似矩阵, 根据新客户数据判断类结构的变动情况并制定创建新类的准则; 最后, 在更新的相似矩阵和聚类参数上运行静态聚类算法得到该时段的聚类结果。【结果】采用某电力企业客户数据进行实验, 结果表明, 该框架在保证聚类质量的基础上通过取消聚类数目判定和聚类结果匹配两个环节, 能显著提高聚类效率。【局限】由于数据的可获得性, 尚未在其他领域或高维数据集上对算法效率进行验证。【结论】考虑类结构变动的自适应进化聚类框架不仅能有效追踪客户群的进化轨迹, 而且可以避免传统方法对聚类数目的重复判定和聚类结果的匹配问题, 适用于契约型客户的多时段动态细分。
关键词:
Abstract
[Objective] This paper proposes an adaptive evolutionary clustering framework for contracted customer segmentation with changing cluster structure, aiming to solve the multi-period dynamic customer segmentation problem. [Methods] The proposed framework could track customer segmentation results within a clustering cycle, which updated the proximity matrix and clustering parameters dynamically. For each clustering period, we eliminated expired clusters from the latest adjacent period based on the contract termination date. Then, we calculated the estimated proximity matrix for current customers. We also changed the exiting clusters’ structure according to data of new customers and developed guidelines to add new clusters. Finally, we examined the proposed algorithm with the updated proximity matrix and parameters to obtain the final clustering results of a specific period. [Results] The proposed framework could significantly improve the efficiency of clustering by excluding the process of selecting and matching clusters. [Limitations] The proposed algorithm was not examined with other datasets. [Conclusions] The proposed framework could effectively track evolutionary trajectories of customer groups and eliminate problems facing traditional methods. It could do multi-period dynamic segmentation for contracted customers.
Keywords:
客户细分是指企业在明确的战略、业务模式和特定的市场中, 根据客户的属性、行为、需求、偏好以及价值等因素对客户进行分类[1]。聚类分析作为数据挖掘的重要技术, 在客户细分领域应用广泛, 常用的聚类技术包括层次聚类、划分聚类、自组织映射神经网络、模糊聚类和粗糙聚类等[2]。
“细分结果不是一成不变的”这一现象很早就引起学者的关注, 产生这一现象的原因主要可归结为时间因素与空间因素的共同变化。以盈利为目的的企业, 其主要经营目标是在不断变化的外部环境中持续保持竞争优势。随着客户信息获取渠道的增多、数据存储和分析技术的发展, 企业已不再满足于通过客户细分发掘客户可利用的固有特征和模式, 还希望进一步了解这些特征和模式的演变趋势, 以对中、长期营销服务活动提供支持, 对客户需求的转变做出快速响应[3]。这需要细分技术具备处理变动数据和趋势发现的能力。在这一背景下, 研究支持动态客户细分的相关技术显得尤为必要。
早期研究通常采取三种策略应对细分结果的改变: 固定细分模型, 始终创建新模型和不断更新模型[4]。其中, 不断更新模型能在不改变建模思路的同时通过调整参数使模型适应数据的变化, 既能实现对以往细分结果的追溯, 又尽可能降低了建模成本和开销, 因而受到广泛推荐。目前, 学界尚未形成统一的动态客户细分建模方法, 比较典型的有: 关联、序列规则挖掘[5-6]、隐马尔科夫链模型[7]、动态聚类[8]和云模型[9]等。
在动态聚类方面, 一些学者从不同视角对“动态”的概念进行界定。Crespo等[4]和Peters等[10]从聚类对象和类结构两个维度将聚类问题划分为4类: 静态对象-静态类, 对应经典聚类问题; 静态对象-动态类, 对应增量聚类问题; 动态对象-静态类, 对应时间序列聚类问题; 以及动态对象-动态类, 即真正意义上的动态聚类。其中, 动态类泛指类结构的变动, 具体表现为类的增加、减少和移动。Perez-Suarez等从数据集的角度定义“动态”, 将只能用于处理固定静态数据集的聚类技术称为静态聚类, 反之, 则为非静态聚类[11]。非静态聚类又可划分为增量聚类和动态聚类, 前者仅能处理数据规模不断增长的数据集, 后者不仅能应对数据量的增加, 也能处理数据的减少和变更, 具备根据变动的数据集动态调整聚类参数的能力。目前, 对聚类算法的探讨多集中在经典聚类、数据流聚类[11-12]和增量聚类[4,10]领域, 关于动态聚类的研究还较少, 而进化聚类提供了一种有效的解决思路, 目的是在反映聚类对象长期漂移现象的同时对其短期扰动具有健壮性。现有进化聚类方法可分为两类: 一类通过在静态聚类代价函数的基础上增加一个时间平滑罚以防止相邻时段的聚类结果出现严重不一致[13-14], 而罚权值的选取仍是待解决的难题; 另一类统称为基于模型的方法, 包括: 半马尔科夫模型[15]、贝叶斯模型[16]、稀疏学习模型[17]等。一种建模思路是对静态聚类进行跟踪建模。Rosswog等采用一个有限冲激响应滤波器对聚类对象在各时段的特征向量进行加权求和, 用经过过滤的输出向量代替原向量参与聚类, 但该模型需固定聚类数目, 无法描述类结构的变动[18]。Xu等提出一个称为基于自适应遗忘因子的进化聚类跟踪框架(AFFECT), 对各时段观测到的聚类对象相似矩阵建模以实现对静态聚类的跟踪[19]。该框架通过求一个变动的遗忘因子避免了罚权值的确定问题, 适用范围广泛。
在解决类结构随时间变动这一问题上, AFFECT采用的聚类数目寻优和聚类结果匹配策略限制了它的可操作性。为此, 本文提出一种考虑类结构变动的AFFECT聚类框架, 通过制定类结构变动规则并添加相应的处理模块, 实现了对客户数据相似矩阵和类结构的同时迭代更新, 避免了聚类数目的重复判定和聚类结果的匹配问题。同时, 原有的AFFECT框架仅适用于层次聚类、k均值和谱聚类等硬聚类技术, 本文采用粗糙k均值算法作为静态聚类技术, 给出相应的距离函数和空间样本均值计算公式, 首次将AFFECT应用于软聚类领域。
粗糙$k$均值聚类算法[20]是将粗糙集理论引入经典$k$均值聚类的一种软聚类技术, 允许获得的类相互重叠。在粗糙$k$均值聚类中, 一个类由两个分别称为下近似和上近似的区间集描述, 前者是后者的一个子集, 下近似中包含依据已有知识, 能确定划分到该类的对象, 而上近似则包含可能属于该类的所有对象。使用$\underline{A}(k)$和$\bar{A}(k)$分别表示类$k$的下近似和上近似, 粗糙$k$均值聚类遵循粗糙集的三个基本性质:
性质1: 对象v至多属于一个下近似$\underline{A}(k)$;
性质2: $v\in \underline{A}(k)\Rightarrow v\in \overline{A}(k)\ \ \ \ k\in \left\{ 1,2,\cdots ,K \right\}$;
性质3: 若$v$不属于任意一个下近似$\Leftrightarrow $$v$至少属于两个上近似。
引入下、上近似的概念后, 类$k$的中心${{\mathbf{m}}_{k}}$可由公式(1)[20]求得, 其中, $\left| \underline{k} \right|$和$\left| \overline{k} \right|$分别表示类$k$下近似和上近似中包含的对象数, ${{w}_{l}}$和${{w}_{u}}$分别代表下近似、上近似所占权重, 并满足${{w}_{l}}+{{w}_{u}}=1$。使用${{p}_{ij}}$表示对象$i$和对象j的点积, 笔者给出了任一对象i与任一类中心mk的距离公式, 如公式(2)所示。可知: 对象与类中心的相似度可通过该对象与类内相应对象的点积间接求得。
${{\mathbf{m}}_{k}}={{w}_{l}}\frac{\sum\limits_{i\in \underline{A}(k)}{{{\mathbf{x}}_{i}}}}{\left| \underline{k} \right|}+{{w}_{u}}\frac{\sum\limits_{j\in \overline{A}(k)}{{{\mathbf{x}}_{j}}}}{\left| {\bar{k}} \right|}$ (1)
${{\left\| {{\mathbf{x}}_{i}}-{{\mathbf{m}}_{k}} \right\|}^{2}}={{p}_{ii}}-2{{P}_{1}}+{{P}_{2}}+2{{P}_{3}}$ (2)
$\begin{align} & {{P}_{1}}={{w}_{l}}\frac{\sum\limits_{j\in \underline{A}(k)}{{{p}_{ij}}}}{\left| \underline{k} \right|}+{{w}_{u}}\frac{\sum\limits_{n\in \overline{A}(k)}{{{p}_{in}}}}{\left| \overline{k} \right|} \\ & {{P}_{2}}=w_{l}^{2}\frac{\sum\limits_{c,d\in \underline{A}(k)}{{{p}_{cd}}}}{{{\left| \underline{k} \right|}^{2}}}+w_{u}^{2}\frac{\sum\limits_{r,s\in \overline{A}(k)}{{{p}_{rs}}}}{{{\left| \overline{k} \right|}^{2}}} \\ & {{P}_{3}}={{w}_{l}}{{w}_{u}}\frac{\sum\limits_{z\in \underline{A}(k)}{\sum\limits_{v\in \overline{A}(k)}{{{p}_{zv}}}}}{\left| \underline{k} \right|\left| \overline{k} \right|} \\ \end{align}$
粗糙$k$均值算法需要预先指定4个参数: 聚类数目K, 下近似、上近似所占权重${{w}_{l}}$和${{w}_{u}}$, 以及决定对象在下近似或边界域间归属的阈值$\xi $。
AFFECT框架[19]将聚类对象在时段$t$观测到的相似矩阵(点积阵)${{\mathbf{P}}^{t}}$视作其真实相似矩阵${{\mathbf{\psi }}^{t}}$和一个零均值噪声矩阵${{\mathbf{N}}^{t}}$的线性组合, 如公式(3)所示。由于${{\mathbf{\psi }}^{t}}$是变动且不可观测的未知矩阵, 使用一个平滑相似矩阵${{\overline{\mathbf{P}}}^{t}}$对其进行估计。如公式(4)所示, ${{\overline{\mathbf{P}}}^{t}}$是${{\mathbf{P}}^{t}}$和以往时段获得的估计相似矩阵${{\overline{\mathbf{P}}}^{t-1}}$的线性组合, 其中权重${{\alpha }^{t}}$被称为遗忘因子, 是一个位于$[0,1)$区间内随时段$t$变动的值。
${{\mathbf{P}}^{t}}={{\mathbf{\psi }}^{t}}+{{\mathbf{N}}^{t}},\ \ t=0,1,2,\cdots $ (3)
${{\overline{\mathbf{P}}}^{t}}={{\alpha }^{t}}{{\overline{\mathbf{P}}}^{t-1}}+(1-{{\alpha }^{t}}){{\mathbf{P}}^{t}}$ (4)
AFFECT的工作原理可概括为: 采用一种方法得到任一时段$t$内遗忘因子${{\alpha }^{t}}$的最优估计值, 使得${{\mathbf{\psi }}^{t}}$和${{\overline{\mathbf{P}}}^{t}}$的均方误差最小, 通过在求得的${{\overline{\mathbf{P}}}^{t}}$上运行相应的静态聚类算法即可实现对静态聚类的跟踪。Xu等将用${{\overline{\mathbf{P}}}^{t}}$估计${{\mathbf{\psi }}^{t}}$的风险定义为一个在给定所有前期观测矩阵时, 求代价函数条件期望的过程, 如公式(5)所示, 则对${{\alpha }^{t}}$求一阶导数即得到${{\alpha }^{t}}$的最优解, 如公式(6)所示[19]。由于$\psi _{ij}^{t}$和噪声的方差$\operatorname{var}(n_{ij}^{t})$均为随时间变动的未知值, 在计算时用相应的空间样本均值$\widehat{E}[{{\mathbf{P}}^{t}}]$和方差$\widehat{\operatorname{var}}[{{\mathbf{P}}^{t}}]$代替。对于粗糙$k$均值的相似矩阵, 笔者给出其空间样本均值$\widehat{E}[{{\mathbf{P}}^{t}}]$的计算方法如公式(7)-公式(9)所示。若对象$i$和$j$同属于类$k$, $\widehat{E}[p_{ij}^{t}]$的计算见公式(7); 若$i$和$j$分属于不同的类$k$和$c$, $\widehat{E}[p_{ij}^{t}]$的计算见公式(8); 公式(9)给出任一对象$i$和自身的期望相似度。在填充相似矩阵${{\widehat{\mathbf{\psi }}}^{t}}=\widehat{E}[{{\mathbf{P}}^{t}}]$时, 若两个对象位于两个不同边界域的交集, 则相应的$\widehat{E}[p_{ij}^{t}]$用求得的两类$\widehat{E}[p_{ij}^{t}]$的均值代替。同理可计算得到相应的$\widehat{\operatorname{var}}[p_{ij}^{t}]$。
$\begin{align} & R({{\alpha }^{t}})=E\left[ \left\| {{\overline{\mathbf{P}}}^{t}}-{{\mathbf{\psi }}^{t}} \right\|_{F}^{2}\left| {{\mathbf{P}}^{(t-1)}} \right. \right] \\ & \ \ \ \ \ \ \ \ \ =\sum\limits_{i=1}^{n}{\sum\limits_{j=1}^{n}{\left\{ {{(1-{{\alpha }^{t}})}^{2}}\operatorname{var}(n_{ij}^{t})+{{({{\alpha }^{t}})}^{2}}{{(\overline{p}_{ij}^{t-1}-\psi _{ij}^{t})}^{2}} \right\}}} \\ \end{align}$ (5)
${{({{\alpha }^{t}})}^{*}}=\frac{\sum\limits_{i=1}^{n}{\sum\limits_{j=1}^{n}{\operatorname{var}(n_{ij}^{t})}}}{\sum\limits_{i=1}^{n}{\sum\limits_{j=1}^{n}{\left\{ {{(\overline{p}_{ij}^{t-1}-\psi _{ij}^{t})}^{2}}+\operatorname{var}(n_{ij}^{t}) \right\}}}}$ (6)
$\widehat{E}[p_{ij}^{t}]={{w}_{l}}\frac{1}{\left| \underline{k} \right|(\left| \underline{k} \right|-1)}\sum\limits_{i\in \underline{k}}{\sum\limits_{\begin{smallmatrix} j\in \underline{k} \\ j\ne i \end{smallmatrix}}{p_{ij}^{t}}}+{{w}_{u}}\frac{1}{\left| \overline{k} \right|(\left| \overline{k} \right|-1)}\sum\limits_{i\in \overline{k}}{\sum\limits_{\begin{smallmatrix} j\in \overline{k} \\ j\ne i \end{smallmatrix}}{p_{ij}^{t}}}$ (7)
$\widehat{E}[p_{ij}^{t}]={{w}_{l}}\frac{1}{\left| \underline{k} \right|\left| \underline{c} \right|}\sum\limits_{i\in \underline{k}}{\sum\limits_{j\in \underline{c}}{p_{ij}^{t}}}+{{w}_{u}}\frac{1}{\left| \overline{k} \right|\left| \overline{c} \right|}\sum\limits_{i\in \overline{k}}{\sum\limits_{j\in \overline{c}}{p_{ij}^{t}}}$ (8)
$\widehat{E}[p_{ii}^{t}]={{w}_{l}}\frac{1}{\left| \underline{k} \right|}\sum\limits_{i\in \underline{k}}{p_{ii}^{t}}+{{w}_{u}}\frac{1}{\left| \overline{k} \right|}\sum\limits_{i\in \overline{k}}{p_{ii}^{t}}$ (9)
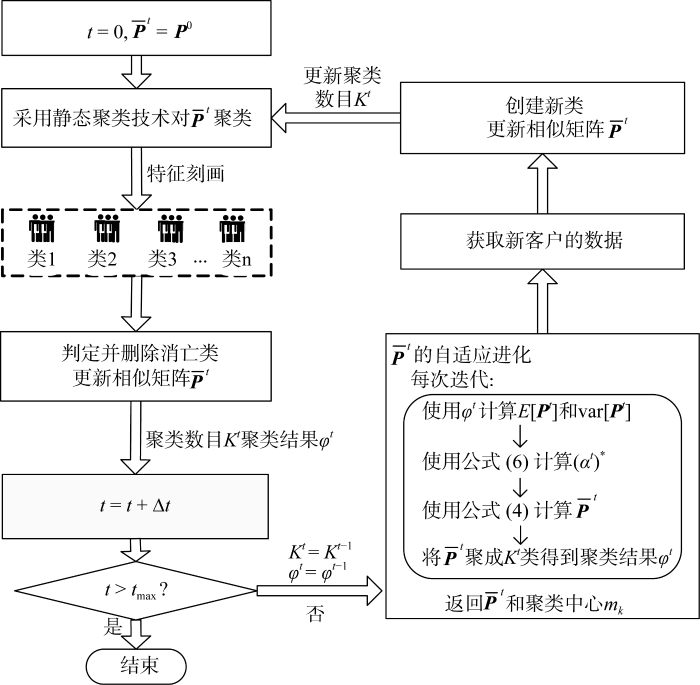
AFFECT可视作一个随时段$t$迭代寻找${{({{\widehat{\alpha }}^{t}})}^{*}}$并对求得的${{\overline{\mathbf{P}}}^{t}}$聚类的过程, 其工作过程如图1所示。在每个时段$t$, 先将$t-1$时段的聚类结果${{\varphi }^{t-1}}$赋值给${{\varphi }^{t}}$, 然后迭代求${{({{\widehat{\alpha }}^{t}})}^{*}}$, 完成迭代后返回$t$时段的最终聚类结果${{\varphi }^{t}}$并将其与$t-1$时段的聚类结果${{\varphi }^{t-1}}$进行匹配。
类结构随时间变化和相邻时段聚类结果的匹配是AFFECT需要解决的关键问题。传统的解决思路是: 用启发式算法或聚类效度指标(CVI)获取各时段的最优聚类数目${{({{k}^{*}})}^{t}}$; 在各个$t$内将对象分别聚为${{({{k}^{*}})}^{t}}$类; 对相邻时段得到的${{({{k}^{*}})}^{t}}$和${{({{k}^{*}})}^{t-1}}$进行匹配。
使用启发式算法或效度指标寻找最优聚类数目${{({{k}^{*}})}^{t}}$的过程是一个不断试错的局部或全局搜索过程, 随着样本量的增大和尝试聚类次数的增加, 获取最优解的时间开销也相应增大。另外, 目前尚没有能快速匹配相邻时段聚类结果的有效方法, 常用的做法是穷举法, 即: 对$t$时段的聚类结果, 列出所有可能的类标签排列, 若$t$时段的最终聚类数目为${{({{k}^{*}})}^{t}}$, 共有${{({{k}^{*}})}^{t}}!$种类标签排列方式; 将获得的每种类标签序列与$t-1$时段聚类结果的类标签序列进行匹配。当${{({{k}^{*}})}^{t}}$较大时, 该方法的时间成本非常高, 这将大大降低AFFECT的可操作性。
基于上述分析, 本文提出一个考虑类结构变动的自适应进化聚类框架: 首先, 利用客户先验信息制定类结构的变动规则, 用于判定类的消亡和产生; 在此基础上, 在客户相似矩阵自适应进化过程中分别添加一个删除消亡类和创建新类的模块, 实现聚类数目${{({{k}^{*}})}^{t}}$和相似矩阵的同时更新; 最后, 在新的相似矩阵和聚类参数上运行静态聚类算法。其基本架构如图2所示, 主要由类消亡的判断模块, ${{\overline{\mathbf{P}}}^{t}}$的自适应进化模块和创建新类模块三部分组成。图2表明: 考虑类结构变动的自适应进化聚类在每个聚类时段形成一个聚类环, 通过添加类消亡和类创建的判断模块, 避免了各时段聚类数目的重复选取和聚类结果的匹配。
类结构在不同细分时段变动主要包括两个方面: 类消亡导致的聚类数目减少和出现新客户群引起的聚类数目增加。本文仅探讨契约型客户的类结构变动, 这类客户通过与企业订立规范合约建立中长期、稳定的交易关系, 变更契约需向企业提出申请, 客户的转移成本较高, 流失行为可预测[21]。类结构的变动主要受客户流失和新客户进入的影响。
(1) 类的消亡
识别和处理消亡类对企业的中长期营销决策具有重要意义, 对于契约型客户, 企业掌握客户契约生效和失效的关键信息, 这些信息可作为判定消亡类的辅助先验信息。笔者提出类消亡的判定公式, 如公式(10)和公式(11)所示。若用${{\left| \underline{k} \right|}^{t}}$和$M_{\underline{k}}^{t}$分别表示在第$t$个聚类时段类$k$下近似包含的对象数和下近似中契约失效的对象数, 当公式(10)和公式(11)同时成立时, 则判定类$k$为消亡类。
$\frac{M_{\underline{k}}^{t+1}}{{{\left| \underline{k} \right|}^{t}}}\ge \gamma \ $ (10)
${{\left| \underline{k} \right|}^{t}}-M_{\underline{k}}^{t+1}\ \min \left( {{\left| \underline{k} \right|}^{t}} \right)$ (11)
公式(10)是类消亡需满足的主要条件, 其中$\gamma $为根据具体的细分任务人为指定的类消亡阈值, 且有$0\gamma \le 1$。$\gamma $越小, 类被判定为消亡类的条件越宽松, 少量客户终止契约就会导致类的消亡, 反之, $\gamma $越大, 类消亡的条件越严格。在实际应用中, 为避免客户群被轻易删除, $\gamma $不应设置得过小。公式(10)表明: 对任一下近似$\underline{A}(k)$, 当下一个聚类时段$t+1$内契约失效的客户数占该下近似客户总数的比率达到阈值$\gamma $时, 类$k$在聚类时段$t+1$被判定为消亡类。这是由于契约失效的客户在时段$t+1$内将不再产生新数据, 从而导致类规模显著缩小。在细分实践中, 客户数据集通常是不平衡的, 这意味着, 即使满足公式(10), 一个规模较大的类在去除契约失效的客户后, 类规模也可能远大于另一个规模较小的类。引入公式(11)作为约束条件, 保证了大客户群不会被轻易删除。
任一类$k$被判定为消亡类后, 需对其执行删除操作。删除消亡类的步骤如下:
①对于客户$v\in \underline{A}{{(k)}^{t}}$且$v$在时段$t+1$内契约失效, 删除${{\overline{\mathbf{P}}}^{t}}$中$v$对应的行和列;
②对于客户$v\in \underline{A}{{(k)}^{t}}$且$v$在时段$t+1$内契约仍生效, 将$v$视为$t+1$时段进入的新客户, 删除${{\overline{\mathbf{P}}}^{t}}$中$v$对应的行和列;
③对于客户$v\in \overline{A}{{(k)}^{t}}-\underline{A}{{(k)}^{t}}$, 判断$v$是否同时属于两个以上的$\overline{A}{{(c)}^{t}}-\underline{A}{{(c)}^{t}},c\ne k$, 如果是, 满足粗糙集的性质3, 不作任何操作, 否则表明$v$仅属于一个$\overline{A}{{(c)}^{t}}-\underline{A}{{(c)}^{t}},c\ne k$, 不满足粗糙集的基本性质, 为此, 将$v$添加到$\underline{A}{{(c)}^{t}}$以使性质1成立。
④删除$\underline{A}{{(k)}^{t}}$和$\overline{A}{{(k)}^{t}}$, 更新聚类数目${{K}^{t}}={{K}^{t}}-1$。
(2) 创建新类
随着聚类时段的推移, 大量契约生效, 新客户的进入为新客户群的产生提供了机会。当已有类结构不能对这些新客户的特征进行准确描述时, 有必要创建新类以及时反映类结构的变化。早期研究表明[4,10]: 准则1可作为创建新类的一个必要条件。
准则1: 存在许多远离当前聚类中心${{\mathbf{m}}_{k}},$ $k=1,2,\cdots ,{{K}^{t}}$的新对象。
为使准则1可操作, 需量化地定义“许多”和“远离”。文献[4,10]认为: 当客户$v$与任一当前聚类中心${{\mathbf{m}}_{k}}$的距离满足公式(12)时, 该客户“远离”当前类, 使用已有客户群不能准确刻画其特征。
${{d}_{vk}}>\frac{1}{2}\min \left\{ d({{\mathbf{m}}_{k}},{{\mathbf{m}}_{c}}) \right\}\ \forall k,c\in \left\{ 1,2,\cdots ,{{K}^{t}} \right\},k\ne c$
(12)
设满足公式(12)的新客户数为$F$, 文献[10]认为: 当公式(13)成立时, $F$达到“许多”。公式(13)中的$f$为根据具体细分任务设置的乘法调节算子, $f>0$。$f$越大, 创建新类的条件越严格, 反之, $f$越小, 越容易创建新类。实际操作中, $f$的设置与具体细分任务、已有各客户群规模、可接受的最小客户群规模等因素密切相关。一般情况下, 为控制营销成本, 新客户群的规模不应小于已有的最小客户群规模, 设置一个较大的$f$能防止产生过小的类。
$F>f\frac{{{\underline{M}}^{t}}}{{{K}^{t}}}=f\frac{\sum\nolimits_{k=1}^{{{K}^{t}}}{{{\left| \underline{k} \right|}^{t}}}}{{{K}^{t}}}$ (13)
准则1成立后, 还需确定要创建的新类个数。本文以聚类效度评价指标值作为选择聚类数目的依据, 即在预设的多个聚类数目下对新客户进行预聚类, 选择效度指标最优值对应的聚类数目为最终创建的新类个数。采用的效度评价指标为$OS$指标[22], $OS$值越小代表聚类质量越好。生成新类个数的算法描述如下:
算法1 基于$OS$指标确定新添加聚类数的算法
输入: 聚类数目的范围$K_{\min }^{t}$和$K_{\max }^{t}$, 满足公式(12)的新客户数据集${{X}^{t}}$;
输出: 需要创建的新类个数$K_{new}^{t}$, 类中心${{\mathbf{m}}_{k}},k=1,2,\cdots ,K_{new}^{t}$;
Begin
使用粗糙$k$均值算法将${{X}^{t}}$聚为$K_{\min }^{t}$类
计算$OS(K_{\min }^{t})$
初始化$K_{new}^{t}=K_{\min }^{t}$, $O{{S}_{\min }}=OS(K_{\min }^{t})$
for $K=K_{\min }^{t}+1$to$K_{\max }^{t}$do
使用粗糙$k$均值算法将${{X}^{t}}$聚为$K$类
计算$OS(K)$
if $OS(K)<O{{S}_{\min }}$then
$O{{S}_{\min }}=OS(K)$
$K_{new}^{t}=K$
end if
end for
使用粗糙$k$均值算法将${{X}^{t}}$聚为$K_{new}^{t}$类
更新聚类总数${{K}^{t}}={{K}^{t}}+K_{new}^{t}$
end Begin
完成新类判定和创建后, 还需同时更新相似矩阵${{\overline{\mathbf{P}}}^{t}}$, 由于新客户在$t$时段才产生数据, 并不影响前t-1个时段的聚类结果, 因此, 只需在原客户的${{\overline{\mathbf{P}}}^{t}}$中插入新客户行和列对应的点积向量即完成了${{\overline{\mathbf{P}}}^{t}}$的更新。
为了对所提出的自适应进化聚类框架进行说明并验证其有效性, 本文采用电力客户数据进行实验。电力客户是典型的契约型客户, 客户使用电能前需与供电企业签订供电合同。供电企业可通过客户ID跟踪其用电行为。
实验采用国家电网陕西省电力公司某下属供电局营销信息系统中存储的工业企业客户数据为数据源。该数据库包含客户基本信息和客户用电记录两个数据表, 共使用31个属性描述工业企业客户的基本信息和客户从2007年至2009年连续三年每月的用电记录。将每个月作为一个聚类时段, 以客户ID为主键, 共抽取并筛选2008年8月-10月240条客户用电记录组成基础实验样本。为直观地展现所提框架的工作流程, 仅在月用电量和低谷用电率两个属性上对客户进行交叉细分, 这两个属性能粗略反映客户的用电规模和用电习惯。采用最大-最小规范化线性变换对月用电量数据进行归一化处理以消除不同量纲对聚类结果的影响。
参照已有研究的经验[10]并咨询电力业务专家意见后将粗糙$k$均值算法中的下近似、上近似权重${{w}_{l}}$和${{w}_{u}}$分别设置为0.7和0.3。为便于展示类消亡的过程, 将类消亡的阈值$\gamma $设为0.5, 这是一个较宽松的阈值, 规定超过50%的类成员终止用电合同时, 就能判定该类消亡。为控制聚类数目并保证每一个新产生的客户群规模不会过小, 将创建新类步骤中的乘法算子$f$设置为一个严格的阈值0.8。依据尽可能减少不确定性的原则并咨询业务专家意见后, 将初始聚类时段内所需的数据集粗糙度指定为0.2, 采用遗传算法确定阈值$\xi $, 遗传算法的相关参数设置为: 变量个数为1, 种群规模40, 编码方式为20位的二进制编码, 算法采用随机遍历抽样的选择算子, 单点交叉和二元变异算子, 复制后代中交叉部分占比0.9, 终止条件为30代。使用遗传算法求得的最优阈值$\xi $为1.2531。早期研究认为, ${{\overline{\mathbf{P}}}^{t}}$自适应进化模块中的迭代次数超过3次, 才能保证聚类结果收敛到一个稳定解[19], 而过多的迭代次数又会导致算法效率的降低, 因此, 将该迭代次数设置为5次。
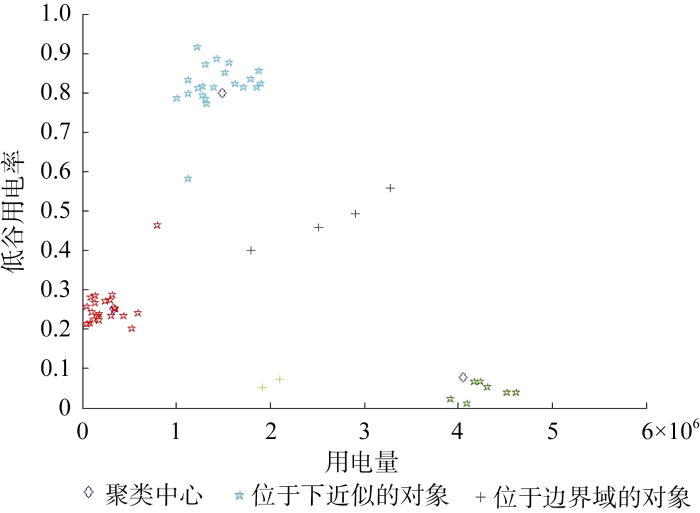
图3-图5描述了使用本文框架对电力客户进行动态细分的流程。可知: 在初始聚类时段, 根据月用电量的大小和低谷用电率的高低, 客户被有效地分为三类, 其中一类为: 用电量大而低谷用电率小于10%的客户, 将该类客户命名为消耗型高价值客户(类1)。同理, 可将另两类客户分别命名为普通低价值客户(类2)和节约型低价值客户(类3)。有6位客户属于边界域, 无法确定其归属。
第二个聚类时段的工作过程如图4所示。由于超过一半的客户选择终止供电合同, 致使消耗型高价值客户群消亡; 与第一时段相比, 普通低价值客户群向低谷用电更少的方向进化。同时, 该时段供电合同生效的34个新客户均远离已有的类中心, 为此, 创建两个新类以准确描述这些客户的用电特征, 并将其分别命名为普通高价值客户(类4)与节约型高价值客户(类5)。
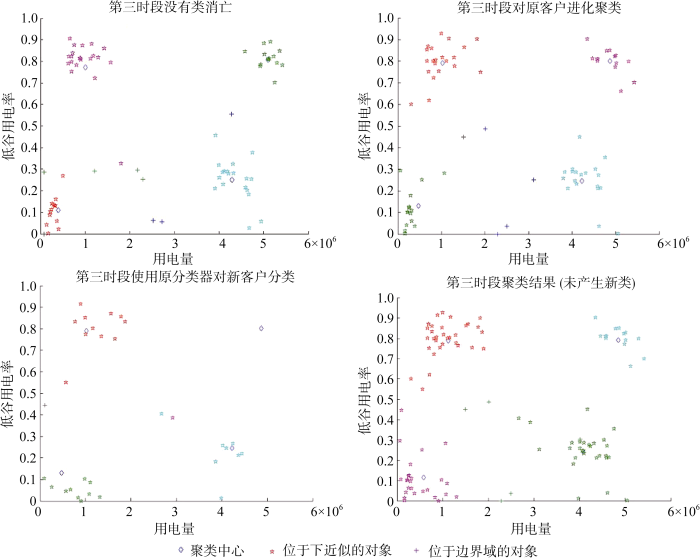
第三个时段的细分过程如图5所示。可知: 虽然普通低价值客户群中有一些成员终止了供电合同, 但尚未满足类消亡的条件, 因此, 该类得以保留; 已有客户群的用电特征在该时段保持稳定, 未发生显著进化。该时段内虽然产生了许多新客户的用电数据, 但这些客户大部分位于已有类中心附近, 仅有两名客户的用电特征不能用已有客户群解释, 不满足创建新类的条件, 因此, 类结构在该时段保持不变。
电力客户各时段的细分结果如表1所示。其中, 粗糙度为客户数据集的整体粗糙度。供电企业可通过类个数和类编号的变动跟踪类结构随时间发生的变化, 从而掌握不同时段的客户构成情况。而类规模和粗糙度的变动分别反映出各客户群随时间的演进趋势和客户数据集不确定性的改变。遗忘因子${{\alpha }^{t}}$用于衡量相邻聚类时段观测到的客户数据差异, 一个小的${{\alpha }^{t}}$表明该时段获取到的客户数据符合客户以往的数据特征, 数据可信度高; 反之, 一个大的${{\alpha }^{t}}$则意味着该时段观测到的数据和以往数据存在显著差异, 这种差异可能由噪声数据引起, 也可能源于客户特征和行为模式的突然转变。
表1 电力客户各时段细分结果
| 时段 | 类数 | 类编号 | 类规模 | 粗糙度 (%) | αt | |
|---|---|---|---|---|---|---|
| 下近似 | 上近似 | |||||
| 1 | 3 | 类1 | 7 | 12 | 19.67 | / |
| 类2 | 21 | 24 | ||||
| 类3 | 21 | 25 | ||||
| 2 | 4 | 类2 | 21 | 27 | 16.67 | 0.66 |
| 类3 | 21 | 25 | ||||
| 类4 | 19 | 23 | ||||
| 类5 | 14 | 15 | ||||
| 3 | 4 | 类2 | 26 | 31 | 12.28 | 0.41 |
| 类3 | 32 | 35 | ||||
| 类4 | 28 | 33 | ||||
| 类5 | 14 | 15 | ||||
跟踪细分结果随时间的改变对企业开展营销工作具有重要意义。一方面, 企业可通过类结构的变动及时识别营销机遇, 例如, 第二时段产生的类5, 是具有高价值和合理用电潜力的优质客户群, 及时识别该类客户, 有助于企业提供进一步的增值服务并推广新的有序用电业务。另一方面, 类规模的扩大和缩小能直观反映客户的增加和流失。对于企业想要发展的优质客户, 类规模的扩大说明企业的营销工作取得成效, 类规模的缩小则表明存在客户流失现象; 反之, 对于企业想要抑制的劣质客户, 类规模的缩小意味着企业的客户构成向良好方向发展, 是企业乐于见到的情况。在本例中, 普通高价值客户群类4的规模在时段3显著增长, 若细分目标是督促用户合理用电, 供电企业可对该类客户实施峰谷电价并进行有序用电宣传。另外, 粗糙度和${{\alpha }^{t}}$的改变可作为调整营销策略或重建细分模型的依据。粗糙度变大表明越来越多的客户分类不明确, 要确定这些客户的归属需投入额外成本。而一个接近1的${{\alpha }^{t}}$表明客户数据出现显著波动, 已有细分模型可能不适用于跟踪后续的细分结果, 需重建分类器。
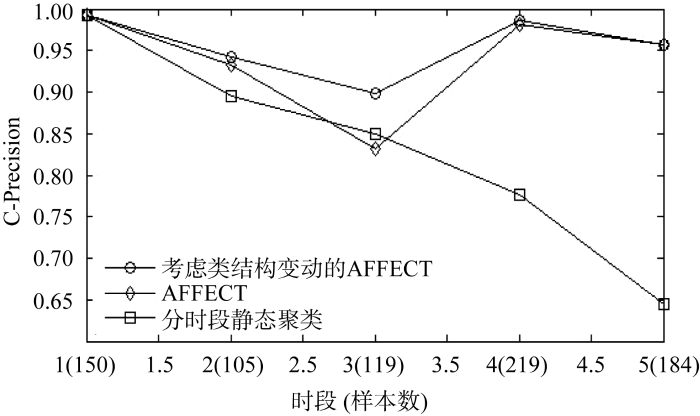
为测试本文方法的性能, 设计了对比实验, 将其和传统AFFECT及常用的在各时段分别施行静态聚类的方法进行比较。从该供电局连续5个月的客户用电记录中, 共抽取777条记录作为实验样本。每条记录由4个属性描述, 分别为: 月用电量, 用电增长率, 运行容量和电压等级, 还包括一个不参与聚类、用于评价聚类性能的类别标签。类别标签由业务专家在参考历史细分结果的基础上根据数据特征人为指定。实验中的静态聚类技术仍采用粗糙$k$均值算法, 综合类别标签和多次预聚类的结果将参数${{w}_{l}}$、${{w}_{u}}$和$\xi $分别指定为: 0.8、0.2和1.2。同5.1节, 阈值$\gamma $和乘法算子f 仍设为0.5和0.8。${{\overline{\mathbf{P}}}^{t}}$自适应进化的迭代次数设置为5。采用传统AFFECT时, 在区间[2,5]内使用$OS$指标确定合适的聚类数目${{K}^{t}}$, 为克服随机选取初始聚类中心对指标值的影响, 每个${{K}^{t}}$计算5次$OS$并用其均值作为最终值。各时段分别运行静态聚类时, 预先指定正确的聚类数目, 分别为: 3、2、2、4和3。每种方法实验10次, 在得到各时段聚类结果的基础上, 用类别标签计算10次实验得到的C-Precision指标[23]均值以评价聚类精度, 指标值越大, 表明聚类质量越好。图6给出三种方法在5个时段的聚类精度结果。
从图6可以看出, 本文方法和传统的AFFECT在聚类精度上总体优于常用的分时段静态聚类, 这是由于分时段聚类结果对噪声数据非常敏感, 当噪声较大时, 相邻时段的聚类结果存在显著差异, 无法进行匹配, 而自适应进化聚类通过调整当前时段观测数据的权重, 尽可能地避免了噪声对聚类结果的影响。本文方法和传统AFFECT聚类精度大致相当, 在创建新类时, 由于本文方法采用先对原客户数据聚类, 再引入新客户数据的预聚类策略, 获得的原客户类中心和新类中心作为正式聚类时的初始类中心, 指导粗糙$k$均值算法的收敛过程, 一定程度上克服了随机选取初始类中心对聚类结果的影响。与传统AFFECT相比, 获得的聚类结果更稳定。
由于实验设定的聚类数目${{K}^{t}}$较小, 各时段聚类结果容易匹配, 若将匹配结果的时间忽略不计, 则本文方法和传统AFFECT在各时段的聚类效率对比结果如图7所示。可以看出, 两种方法所需时间随样本量的增大而增加, 且本文方法的时间效率明显高于传统AFFECT。这是由于后者在每个时段都需将数据聚成不同的${{K}^{t}}$以寻找最优聚类个数, 随着样本量的增大, 这一过程将极为耗时, 而本文方法只在产生新类时需要判定聚类数目, 且只需在新客户数据集上进行判定, 从而在保持聚类精度的同时能有效缩短运行时间, 具有更好的可操作性。
针对传统自适应进化聚类在处理类结构变动客户细分问题时存在的局限性, 本文提出一种考虑类结构变动的面向契约型客户细分的自适应进化聚类方法。以客户契约的生效和失效作为先验信息制定类结构变动的判定准则并在传统进化聚类框架基础上添加相应的类结构变动处理模块, 指导聚类参数随时间的改变, 从而在保证聚类质量的同时降低计算开销。另外, 本文方法在判定和处理类结构变动时均基于客户契约提供的先验信息及聚类算法生成的个体类标签, 独立于具体的聚类技术, 因此, 所提出的框架保留了传统自适应进化聚类的优点, 能灵活扩充到除粗糙$k$均值以外的任一采用成对距离度量对象相似性的硬聚类或软聚类技术中。
在未来研究中, 一方面会搜集更多的数据集尤其是高维数据集进一步验证本文算法的有效性; 另一方面, 本文算法在客户细分领域的动态挖掘和趋势发现能力尚需更多实证研究进行检验。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: nolanspring@163.com。
[1] 胡晓雪. powerCustomerData3.xls. 用于5.1节实验的电力客户数据.
[2] 胡晓雪. powerCustomerContrastData.xls. 用于5.3节对比实验的电力客户数据.
[3] 胡晓雪. roughKmeans.m. 粗糙k均值算法程序.
[4] 胡晓雪. deleteCluster.m. 判断并删除消亡类程序.
[5] 胡晓雪. pT.m. ${{\overline{\mathbf{P}}}^{t}}$自适应进化程序.
[6] 胡晓雪. createCluster.m. 创建新类程序.
[7] 胡晓雪. aFFECT.m. 传统AFFECT程序.
[8] 胡晓雪. geneticYu.m. 使用遗传算法确定阈值ξ程序.
| [1] |
|
| [2] |
Soft Computing Applications in Customer Segmentation: State-of-art Review and Critique [J].https://doi.org/10.1016/j.eswa.2013.05.052 URL [本文引用: 1] 摘要
Segmentation has been taken immense attention and has extensively been used in strategic marketing. Vast majority of the research in this area focuses on the usage or development of different techniques. By means of the internet and database technologies, huge amount of data about markets and customers has now become available to be exploited and this enables researchers and practitioners to make use of sophisticated data analysis techniques apart from the traditional multivariate statistical tools. These sophisticated techniques are a family of either data mining or machine learning research. Recent research shows a tendency towards the usage of them into different business and marketing problems, particularly in segmentation. Soft computing, as a family of data mining techniques, has been recently started to be exploited in the area of segmentation and it stands out as a potential area that may be able to shape the future of segmentation research. In this article, the current applications of soft computing techniques in segmentation problem are reviewed based on certain critical factors including the ones related to the segmentation effectiveness that every segmentation study should take into account. The critical analysis of 42 empirical studies reveals that the usage of soft computing in segmentation problem is still in its early stages and the ability of these studies to generate knowledge may not be sufficient. Given these findings, it can be suggested that there is more to dig for in order to obtain more managerially interpretable and acceptable results in further studies. Also, recommendations are made for other potentials of soft computing in segmentation research.
|
| [3] |
Dynamic Clustering with Soft Computing [J].https://doi.org/10.1002/widm.1050 URL [本文引用: 1] 摘要
Clustering methods are one of the most popular approaches to data mining. They have been successfully used in virtually any field covering domains such as economics, marketing, bioinformatics, engineering, and many others. The classic cluster algorithms require static data structures. However, there is an increasing need to address changing data patterns. On the one hand, this need is generated by the rapidly growing amount of data that is collected by modern information systems and that has led to an increasing interest in data mining as its whole again. On the other hand, modern economies and markets do not deal with stable settings any longer but are facing the challenge to adapt to constantly changing environments. These include seasonal changes but also long-term trends that structurally change whole economies, wipe out companies that cannot adapt to these trends, and create opportunities for entrepreneurs who establish large multinational corporations virtually out of nothing in just one decade or two. Hence, it is essential for almost any organization to address these changes. Obviously, players that have information on changes first possibly obtain a strategic advantage over their competitors. This has motivated an increasing number of researchers to enrich and extend classic static clustering algorithms by dynamic derivatives. In the past decades, very promising approaches have been suggested; some selected ones will be introduced in this review. 2012 Wiley Periodicals, Inc.
|
| [4] |
A Methodology for Dynamic Data Mining Based on Fuzzy Clustering [J].https://doi.org/10.1016/j.fss.2004.03.028 URL [本文引用: 4] 摘要
Dynamic data mining is increasingly attracting attention from the respective research community. On the other hand, users of installed data mining systems are also interested in the related techniques and will be even more since most of these installations will need to be updated in the future. For each data mining technique used, we need different methodologies for dynamic data mining. In this paper, we present a methodology for dynamic data mining based on fuzzy clustering. Using the implementation of the proposed system we show its benefits in two application areas: customer segmentation and traffic management.
|
| [5] |
基于客户行为的4S店客户细分及其变化挖掘 [J].https://doi.org/10.13587/j.cnki.jieem.2015.04.003 URL [本文引用: 1] 摘要
本文针对汽车售后维修服务业的特点,基于CRISP-DM模型提出了一种适合于4S店的客户细分方法与客户群变化挖掘方法.首先,根据汽车售后维修交易记录的特点,建立了基于客户行为的客户细分指标体系,接着运用自组织映射神经网络对客户进行聚类,通过对聚类结果进行分析与识别得到客户细分结果.其次,在客户细分结果的基础上,分别从客户群和客户个体两个角度对客户随时间变化情况进行了分析,提出了客户群在群数量及群属性上随时间变化的分析方法和客户个体的分群演变分析方法.最后,将本文方法在实际数据上进行了数值实验,实验结果表明了本文方法的可行性和有效性.
Customer Segmentation and Change Mining Based on Customer Behavior for 4S Shop [J].https://doi.org/10.13587/j.cnki.jieem.2015.04.003 URL [本文引用: 1] 摘要
本文针对汽车售后维修服务业的特点,基于CRISP-DM模型提出了一种适合于4S店的客户细分方法与客户群变化挖掘方法.首先,根据汽车售后维修交易记录的特点,建立了基于客户行为的客户细分指标体系,接着运用自组织映射神经网络对客户进行聚类,通过对聚类结果进行分析与识别得到客户细分结果.其次,在客户细分结果的基础上,分别从客户群和客户个体两个角度对客户随时间变化情况进行了分析,提出了客户群在群数量及群属性上随时间变化的分析方法和客户个体的分群演变分析方法.最后,将本文方法在实际数据上进行了数值实验,实验结果表明了本文方法的可行性和有效性.
|
| [6] |
Mining the Dominant Patterns of Customer Shifts Between Segments by Using Top-k and Distinguishing Sequential Rules [J].https://doi.org/10.1108/MD-09-2014-0551 URL [本文引用: 1] 摘要
Purpose – The purpose of this paper is to detect different behavioral groups and the dominant patterns of customer shifts between segments of different values over time. Design/methodology/approach – A new hybrid methodology is presented based on clustering techniques and mining top- k and distinguishing sequential rules. This methodology is implemented on the data of 14,772 subscribers of a mobile phone operator in Tehran, the capital of Iran. The main data include the call detail records and event detail records data that was acquired from the IT department of this operator. Findings – Seven different behavioral groups of customer shifts were identified. These groups and the corresponding top- k rules represent the dominant patterns of customer behavior. The results also explain the relation of customer switching behavior and segment instability, which is an open problem. Practical implications – The findings can be helpful to improve marketing strategies and decision making and for prediction purposes. The obtained rules are relatively easy to interpret and use; this can strengthen the practicality of results. Originality/value – A new hybrid methodology is proposed that systematically extracts the dominant patterns of customer shifts. This paper also offers a new definition and framework for discovering distinguishing sequential rules. Comparing with Markov chain models, this study captures the customer switching behavior in different levels of value through interpretable sequential rules. This is the first study that uses sequential and distinguishing rules in this domain.
|
| [7] |
Caputuring the Evolution of Customer-Firm Relationships: How Customers Become More (or Less) Valuable Over Time [J].https://doi.org/10.1016/j.jretai.2013.04.001 URL [本文引用: 1] 摘要
Few studies have examined the influence of marketing activities while accounting for customer dynamics over time. The authors contribute to this growing literature by extending the hurdle model to capture customer dynamics using a hidden Markov chain. We find our dynamic model performs better than static and latent class models. Our results suggest the customer base can be segmented into four segments: Deal-prone, Dependable, Active, and Event-driven. Each segment reacts differentially to marketing activities. Although catalogs influence both purchase incidence and the number of orders, this marketing activity has the largest impact on purchase incidence across all four segments. In contrast, retail promotions are more likely to influence the number of orders a customer will make for all of the segments except for the Deal-prone segment. For this segment, retail promotions have the strongest impact on purchase incidence.
|
| [8] |
Dynamic Clustering Segmentation Applied to Load Profiles of Energy Consumption from Spanish Customers [J].https://doi.org/10.1016/j.ijepes.2013.09.022 URL [本文引用: 1] 摘要
The following article describes the work of dynamic segmentation of daily load profiles throughout years 2008 and 2009, of a representative sample of Spanish residential customers. The technique applied is classification of the energy consumption time series of load profiles by means of dynamic clustering algorithms. The techniques used and analysis performed prove adequate as a fast tool to classify clients according to their energy consumption patterns, as well as to evaluate their overall energy consumption trends at a glance. The segmentation of the energy consumption load profiles is performed, and the results are analyzed and discussed.
|
| [9] |
客户关系管理中的动态客户细分方法研究 [J].https://doi.org/10.3321/j.issn:1007-9807.2006.02.006 URL [本文引用: 1] 摘要
在分析客户行为的随机性和非确定性的基础上,指出现有的确定性客户细分方法不能很好地适应客户细分问题的这些特点.为此,提出基于云模型的动态客户细分模型,该模型将客户细分过程表示为一个C过程与一个P过程,并将描述非确定关系的云模型理论引入到客尸细分的P过程中,从而实现了客户细分的动态性,提高了模型对客户行为描述的客观性.文章采用来自UCI的合成数据及来自银行的实际客户数据进行了数据实验,实验结果表明了该方法的有效性.
Research on Dynamic Customer Segmentation in Customer Relationship Management [J].https://doi.org/10.3321/j.issn:1007-9807.2006.02.006 URL [本文引用: 1] 摘要
在分析客户行为的随机性和非确定性的基础上,指出现有的确定性客户细分方法不能很好地适应客户细分问题的这些特点.为此,提出基于云模型的动态客户细分模型,该模型将客户细分过程表示为一个C过程与一个P过程,并将描述非确定关系的云模型理论引入到客尸细分的P过程中,从而实现了客户细分的动态性,提高了模型对客户行为描述的客观性.文章采用来自UCI的合成数据及来自银行的实际客户数据进行了数据实验,实验结果表明了该方法的有效性.
|
| [10] |
Dynamic Rough Clustering and Its Applications [J].https://doi.org/10.1016/j.asoc.2012.05.015 URL Magsci [本文引用: 4] 摘要
Dynamic data mining has gained increasing attention in the last decade. It addresses changing data structures which can be observed in many real-life applications, e.g. buying behavior of customers. As opposed to classical, i.e. static data mining where the challenge is to discover pattern inherent in given data sets, in dynamic data mining the challenge is to understand and in some cases even predict how such pattern will change over time. Since changes in general lead to uncertainty, the appropriate approaches for uncertainty modeling are needed in order to capture, model, and predict the respective phenomena considered in dynamic environments. As a consequence, the combination of dynamic data mining and soft computing is a very promising research area. The proposed algorithm consists of a dynamic clustering cycle when the data set will be refreshed from time to time. Within this cycle criteria check if the newly arrived data have structurally changed in comparison to the data already analyzed. If yes, appropriate actions are triggered, in particular an update of the initial settings of the cluster algorithm. As we will show, rough clustering offers strong tools to detect such changing data structures. To evaluate the proposed dynamic rough clustering algorithm it has been applied to synthetic as well as to real-world data sets where it provides new insights regarding the underlying dynamic phenomena.
|
| [11] |
A Dynamic Clustering Algorithm for Building Overlapping Clusters [J].https://doi.org/10.3233/IDA-2012-0520 URL [本文引用: 2] 摘要
ABSTRACT Clustering is a Data Mining technique which has been widely used in many practical applications. In some of these applications like, medical diagnosis, categorization of digital libraries, topic detection and others, the objects could belong to more than one cluster. However, most of the clustering algorithms generate disjoint clusters. Moreover, processing additions, deletions and modifications of objects in the clustering built so far, without having to rebuild the clustering from the beginning is an issue that has been little studied. In this paper, we introduce DCS, a clustering algorithm which includes a new graph-cover strategy for building a set of clusters that could overlap, and a strategy for dynamically updating the clustering, managing multiple additions and/or deletions of objects. The experimental evaluation conducted over different collections demonstrates the good performance of the proposed algorithm.
|
| [12] |
An Algorithm Based on Density and Compactness for Dynamic Overlapping Clustering [J].https://doi.org/10.1016/j.patcog.2013.03.022 URL [本文引用: 1] 摘要
61A new dynamic overlapping clustering algorithm, called DClustR, is proposed.61DClustR introduces a new graph-covering strategy and a new filtering strategy.61DClustR solves limitations of the state-of-the-art algorithms.61DClustR outperforms state-of-the-art algorithms in several collections.61DClustR has a better quality-efficiency trade off than state-of-the-art algorithms.
|
| [13] |
Evolutionary Spectral Clustering by Incorporating Temporal Smoothness [C]// |
| [14] |
Community Detection Using Kernel Spectral Clustering with Memory [J].https://doi.org/10.1088/1742-6596/410/1/012100 URL [本文引用: 1] 摘要
This work is related to the problem of community detection in dynamic scenarios, which for instance arises in the segmentation of moving objects, clustering of telephone traffic data, time-series micro-array data etc. A desirable feature of a clustering model which has to capture the evolution of communities over time is the temporal smoothness between clusters in successive time-steps. In this way the model is able to track the long-term trend and in the same time it smooths out short-term variation due to noise. We use the Kernel Spectral Clustering with Memory effect (MKSC) which allows to predict cluster memberships of new nodes via out-of-sample extension and has a proper model selection scheme. It is based on a constrained optimization formulation typical of Least Squares Support Vector Machines (LS-SVM), where the objective function is designed to explicitly incorporate temporal smoothness as a valid prior knowledge. The latter, in fact, allows the model to cluster the current data well and to be consistent with the recent history. Here we propose a generalization of the MKSC model with an arbitrary memory, not only one time-step in the past. The experiments conducted on toy problems confirm our expectations: the more memory we add to the model, the smoother over time are the clustering results. We also compare with the Evolutionary Spectral Clustering (ESC) algorithm which is a state-of-the art method, and we obtain comparable or better results.
|
| [15] |
Milling Naturally Smooth Evolution of Clusters from Dynamic Data [C]// |
| [16] |
Generative Models for Evolutionary Clustering [J].https://doi.org/10.1145/2297456.2297459 URL [本文引用: 1] 摘要
This article studies evolutionary clustering, a recently emerged hot topic with many important applications, noticeably in dynamic social network analysis. In this article, based on the recent literature on nonparametric Bayesian models, we have developed two generative models: DPChain and HDP-HTM. DPChain is derived from the Dirichlet process mixture (DPM) model, with an exponential decaying component along with the time. HDP-HTM combines the hierarchical dirichlet process (HDP) with a hierarchical transition matrix (HTM) based on the proposed Infinite hierarchical Markov state model (iHMS). Both models substantially advance the literature on evolutionary clustering, in the sense that not only do they both perform better than those in the existing literature, but more importantly, they are capable of automatically learning the cluster numbers and explicitly addressing the corresponding issues. Extensive evaluations have demonstrated the effectiveness and the promise of these two solutions compared to the state-of-the-art literature.
|
| [17] |
Sparsity Learning Formulations for Mining Time-varying Data [J].https://doi.org/10.1109/TKDE.2014.2373411 URL [本文引用: 1] 摘要
Traditional clustering and feature selection methods consider the data matrix as static. However, the data matrices evolve smoothly over time in many applications. A simple approach to learn from these time-evolving data matrices is to analyze them separately. Such strategy ignores the time-dependent nature of the underlying data. In this paper, we propose two formulations for evolutionary co-clustering and feature selection based on the fused Lasso regularization. The evolutionary co-clustering formulation is able to identify smoothly varying hidden block structures embedded into the matrices along the temporal dimension. Our formulation is very flexible and allows for imposing smoothness constraints over only one dimension of the data matrices. The evolutionary feature selection formulation can uncover shared features in clustering from time-evolving data matrices. We show that the optimization problems involved are non-convex, non-smooth and non-separable. To compute the solutions efficiently, we develop a two-step procedure that optimizes the objective function iteratively. We evaluate the proposed formulations using the Allen Developing Mouse Brain Atlas data. Results show that our formulations consistently outperform prior methods.
|
| [18] |
Detecting and Tracking Spatio-temporal Clusters with Adaptive History Filtering [C]// |
| [19] |
Adaptive Evolutionary Clustering [J].https://doi.org/10.1007/s10618-012-0302-x Magsci [本文引用: 5] 摘要
In many practical applications of clustering, the objects to be clustered evolve over time, and a clustering result is desired at each time step. In such applications, evolutionary clustering typically outperforms traditional static clustering by producing clustering results that reflect long-term trends while being robust to short-term variations. Several evolutionary clustering algorithms have recently been proposed, often by adding a temporal smoothness penalty to the cost function of a static clustering method. In this paper, we introduce a different approach to evolutionary clustering by accurately tracking the time-varying proximities between objects followed by static clustering. We present an evolutionary clustering framework that adaptively estimates the optimal smoothing parameter using shrinkage estimation, a statistical approach that improves a na < ve estimate using additional information. The proposed framework can be used to extend a variety of static clustering algorithms, including hierarchical, k-means, and spectral clustering, into evolutionary clustering algorithms. Experiments on synthetic and real data sets indicate that the proposed framework outperforms static clustering and existing evolutionary clustering algorithms in many scenarios.
|
| [20] |
Some Refinements of Rough k-means Clustering [J].https://doi.org/10.1016/j.patcog.2006.02.002 URL [本文引用: 2] 摘要
Summary: {\it P. Lingras}, {\it R. Yan} and {\it C. West} [Lect. Notes Comput. Sci. 2639, 13063137 (2003; Zbl 1026.68637)] proposed a rough cluster algorithm and successfully applied it to web mining. In this paper we analyze their algorithm with respect to its objective function, numerical stability, the stability of the clusters and others. Based on this analysis a refined rough cluster algorithm is presented. The refined algorithm is applied to synthetic, forest and microarray gene expression data.
|
| [21] |
基于客户行为的交易关系与客户风险研究 [J].
客户关系作为一种企业资产具有不确定性。这种不确定性导致客户风险客观存在性,并且威胁企业发展,其有效管理成为企业燃眉之急。根据企业与客户的交易契约约束力的强弱程度,将客户关系划分为三种类型:契约型、半契约型和非契约型,并分析其客户行为特征;基于客户关系管理的三个阶段,构建由客户获取风险、客户维系风险和客户关系终止风险构成的客户风险体系,阐述其定义、产生和后果;从而基于“交易关系类型~交易关系约束力~客户行为一客户风险”的主线探索三种交易关系与三个客户风险的关系特征。
Study of Transactional Relationship and Customer Risk Based on Customer Behavior [J].
客户关系作为一种企业资产具有不确定性。这种不确定性导致客户风险客观存在性,并且威胁企业发展,其有效管理成为企业燃眉之急。根据企业与客户的交易契约约束力的强弱程度,将客户关系划分为三种类型:契约型、半契约型和非契约型,并分析其客户行为特征;基于客户关系管理的三个阶段,构建由客户获取风险、客户维系风险和客户关系终止风险构成的客户风险体系,阐述其定义、产生和后果;从而基于“交易关系类型~交易关系约束力~客户行为一客户风险”的主线探索三种交易关系与三个客户风险的关系特征。
|
| [22] |
Validity Index for Clusters of Different Sizes and Densities [J].https://doi.org/10.1016/j.patrec.2010.08.007 URL Magsci [本文引用: 1] 摘要
Cluster validity indices are used to validate results of clustering and to find a set of clusters that best fits natural partitions for given data set. Most of the previous validity indices have been considerably dependent on the number of data objects in clusters, on cluster centroids and on average values. They have a tendency to ignore small clusters and clusters with low density. Two cluster validity indices are proposed for efficient validation of partitions containing clusters that widely differ in sizes and densities. The first proposed index exploits a compactness measure and a separation measure, and the second index is based an overlap measure and a separation measure. The compactness and the overlap measures are calculated from few data objects of a cluster while the separation measure uses all data objects. The compactness measure is calculated only from data objects of a cluster that are far enough away from the cluster centroids, while the overlap measure is calculated from data objects that are enough near to one or more other clusters. A good partition is expected to have low degree of overlap and a larger separation distance and compactness. The maximum value of the ratio of compactness to separation and the minimum value of the ratio of overlap to separation indicate the optimal partition. Testing of both proposed indices on some artificial and three well-known real data sets showed the effectiveness and reliability of the proposed indices.
|
| [23] |
基于选择性聚类集成的客户细分 [J].https://doi.org/10.13196/j.cims.2015.06.030 URL [本文引用: 1] 摘要
针对数据密集型企业的客户细分问题,提出一种基于选择性聚类集成的客户细分框架。在聚类集体生成阶段,根据数据来源和业务需求构建统一的客户视图,将客户特征划分为若干子集后再分别对客户对象聚类,通过评价函数选择高质量的个体标记向量生成聚类集体;在聚类集成阶段,构建记录簇标记所覆盖的相同对象个数的重叠矩阵,利用重叠矩阵计算各簇权值,最后选择最具代表性的簇参与集成。通过某企业客户细分的实证研究表明,该框架可以有效识别出不同价值和消费行为习惯的客户群,为企业制定产品营销方案提供依据。
Customer Segmentation Based on Selective Clustering Ensemble [J].https://doi.org/10.13196/j.cims.2015.06.030 URL [本文引用: 1] 摘要
针对数据密集型企业的客户细分问题,提出一种基于选择性聚类集成的客户细分框架。在聚类集体生成阶段,根据数据来源和业务需求构建统一的客户视图,将客户特征划分为若干子集后再分别对客户对象聚类,通过评价函数选择高质量的个体标记向量生成聚类集体;在聚类集成阶段,构建记录簇标记所覆盖的相同对象个数的重叠矩阵,利用重叠矩阵计算各簇权值,最后选择最具代表性的簇参与集成。通过某企业客户细分的实证研究表明,该框架可以有效识别出不同价值和消费行为习惯的客户群,为企业制定产品营销方案提供依据。
|

/
| 〈 |
|
〉 |





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}