江思伟 , 陈梅婕
, 陈梅婕
Jiang Siwei, Chen Meijie
中图分类号: TP393
通讯作者:
收稿日期: 2017-09-22
修回日期: 2017-10-13
网络出版日期: 2017-12-25
版权声明: 2017 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】解决混合含有连续数值与标签特征量数据集的规则挖掘问题。【方法】提出数据集中特征维度间的互解释表示方法——自解释归约模型, 模型通过最大化新设计的自解释归约目标实现对连续数值数据的自适应划分建模。【结果】针对标准数据集、模拟规则挖掘问题、以及实际问题的实验分析表明, 本文方法具有显见的可行性及可用性, 是对现有数据建模与关联规则挖掘方法的有效扩展。【局限】计算效率一般, 还不能适应较大规模数据集的高速处理要求。【结论】技术方法上弥补了现有相关方法在解决混合特征数据建模问题时的局限性, 通过理论与实验分析证明新方法具有较强的创新性及实用性。
关键词:
Abstract
[Objective] This paper aims to mine the data with continuous numeric and label features. [Methods] We proposed a self-explainable reduction model to represent the data. The proposed model used the new reduction objective to create adaptive discrete division for continuous data dimension. [Results] We examined the new model with standard datasets and found it had better performance than the existing ones. [Limitations] The computational efficiency of the proposed method was not very impressive, which cannot meet the demand of large-scale data mining. [Conclusions] The proposed model is innovative and practical to model the mixed feature data.
Keywords:
数据挖掘是从原始数据中发现有价值的语义规则的基础手段, 关联规则挖掘是其中最具代表性的技术, 最早由Agrawal等[1]对市场购物篮分析时提出, 通过寻找交易数据库中频繁购买模式发现不同商品之间的销售相关性。关联规则挖掘重点关注数据库中不同数据内容间存在的强相关性, 以挖掘事物之间的关系, 在商业决策、医疗诊断等领域有着重要的应用价值。
数据库中的数据往往存在两种不同属性类型: 数值型, 如温湿度、重量、电压等; 分类标签型, 如性别、物品类别、商家等。目前的关联规则挖掘算法主要适用于离散化的数值数据和分类标签数据, 而对于连续型数值数据, 则必须预先进行离散化处理, 否则无法正常工作[2]。
连续数值数据的离散化质量直接关系到数据挖掘的准确性, 其实质是在最小化信息丢失的情况下, 将连续量值域划分成数目有限的区间, 每个区间用一个数值量表示[3-4]。在无监督模式下, 连续量的离散化处理是较为困难的, 也缺乏有效的结果性能衡量标准。而传统的基于聚类划分的方法并不能很好地直接处理此类问题, 在一些实际应用问题中, 简单的经验划分方法仍是常用的手段。
本文从数据建模的思想角度出发, 结合贝叶斯网络[5]技术, 期望数据划分后的离散集能最大程度地保留原始数据集中不同特征属性之间的相关关系, 提出基于贝叶斯网络的自解释归约模型, 适应混合数据的建模表示及关联规则挖掘需求。
关联规则作为数据挖掘的重要组成部分, 已被应用于工程改进[6]、健康信息分析[7]、文本主题挖掘[8]、图书推荐[9]等领域。Agrawal等[10]提出基于先验知识的 Apriori算法, 利用支持度的单调性, 逐步约简候选集的生成, 但需要多次扫描数据库, 算法效率不高。Han等[11]提出FP-Growth算法, 该算法只需扫描两次数据库即可将数据压缩入FP-Tree数据结构, 可通过不断生成条件子树, 直接生成频繁项集, 算法性能高效。但不断生成条件子树时会耗费大量时间, 当数据量较大时, FP-Tree无法一次放入内存。Zaki[12]提出基于垂直数据格式的Eclat算法, 以将水平数据格式转换成垂直数据格式求交集的方式挖掘频繁项集。
对大规模数据进行数据挖掘, 即使仅含几百个事务项的数据集, 不采取任何措施约束搜索空间, 或是提高搜索效率, 仍然难以计算。Qian等[13]构建一种吉布斯采样诱发式的随机搜索框架, 在项目集合空间内进行随机采样关联规则, 并在采样生成的减少的事务数据集中进行规则挖掘。Sheng等[14]结合先验算法和概率图模型, 提出一种基于状态参数变化的数据驱动型关联规则挖掘方法, 克服每当搜索到频繁项时, 所有的数据项都要经过周期性扫描的缺点。Li等[15]定义因果规则(Causal Rules, CRs)的概念, 用于大规模数据挖掘, 并基于关联规则的挖掘结果, 利用回溯队列的思想检测CRs。Song等[16]提出基于交叉验证的可预测集体类关联规则挖掘的方法, 在交叉验证步骤中测量每个候选规则的预测精度。
上述方法为基于标签属性的关联规则挖掘, 而在基于数值属性的关联规则挖掘研究中, Agbehadji等[17]结合遗传算法与蚁群算法, 提出狼式搜索算法, 但其搜索得到的规则的准确性不高。Jorge等[18]利用支持度和置信度设定数值区间条件, 进行规则挖掘, 但需要给定数值属性确定的区间数。Rastogi等[19]提出基于分类属性与数值属性挖掘最优规则的算法, 然而, 随着特征属性量的增加, 搜索的时间会大幅度增加。综上, 现有关联规则挖掘算法的研究主要侧重于约简频繁项集的搜索空间和提高搜索效率, 而针对含有连续数值特征的数据挖掘问题则还没有直接的研究成果。
本文考虑在规则挖掘的同时对连续数值属性进行无监督离散化。现有的无监督离散化方法主要有: 核密度估计(Kernel Density Estimation, KDE)[20]方法使用无参数的密度评估器自动寻找合适的子区间以适应数据要求; 基于树的密度估计(Tree-based Density Estimation, TDE)[21]使用对数似然函数作为打分函数选择区间的离散划分。这两种方法仅从一个属性特征量考虑, 易造成属性特征之间关联信息的丢失。Shanmugapriya等[22]提出结合等宽离散化(Equal Width, EQW)与等频离散化(Equal Frequency, EQF)的方法, 但需要类分布信息的指导, 否则离散结果随机性较大, 结果往往难以达到预想的要求。
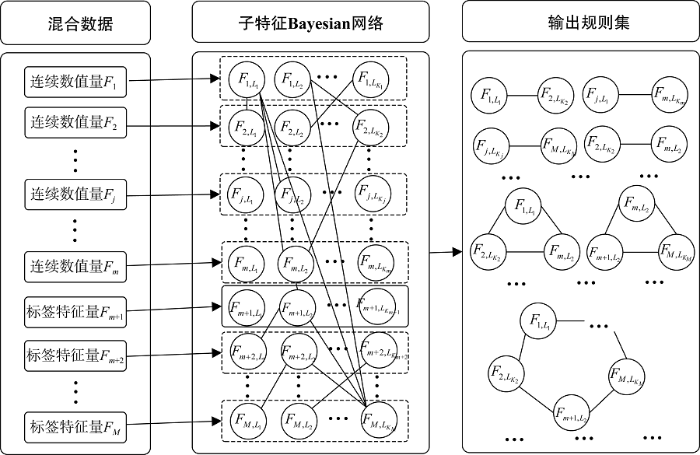
本文利用贝叶斯概率图[5]建模工具, 并通过考查关联规则挖掘的内涵需求, 即筛选出不同数据特征维间存在的某些特征量的关联规则, 以不同数据特征维间的耦合关系作为数据约简建模表示的立足点, 引入如图1所示的自解释归约数据表示模型结构。
图1中输入数据为含有连续数值量和标签特征量的混合型数据集, 其中${{F}_{1}},{{F}_{2}},\cdots {{F}_{m}}$表示连续数值特征量, ${{F}_{m+1}}\text{,}{{F}_{m+2}}\text{,}\cdots {{F}_{M}}$表示标签特征量。基于新设计的自解释归约目标, 考虑将连续特征量在模型中自适应动态划分为${{K}_{j}}$个区间$\{{{F}_{j,1}},{{F}_{j,2}},\cdots {{F}_{j,{{K}_{j}}}}\}$, 然后与标签特征量的标签子集共同形成子特征Bayesian网络, 最后通过后处理技术输出结果规则集。
在自解释归约数据表示模型结构中, 子特征Bayesian网络的构建需要同时考虑网络节点的自适应生成, 以及对观测数据的最优解释刻画。子特征Bayesian网络节点由连续数值量的子划分节点与标签特征量的标签节点构成, 其中连续数值属性的节点需要自适应获取, 则考虑在目标函数中引入聚类策略项; 同时为了使网络节点间的概率连接关系能最大化地对原始数据关系进行解释刻画, 考虑在目标函数中使特征属性间的相关信息损失最小化。综合地, 在自解释归约数据表示模型中, 引入如公式(1)所示的模型目标。
$\underset{{{c}_{jk}}}{\mathop{\arg \max }}\,{{J}_{\text{SRM}}}\text{=}\sum\limits_{i=1}^{N}{\sum\limits_{j=1}^{M}{\sum\limits_{k=1}^{{{K}_{j}}}{{{p}_{ijk}}{{e}^{-\frac{{{({{x}_{ij}}-{{c}_{jk}})}^{2}}}{{{\sigma }^{2}}}}}}}}$ (1)
其中, 加和项中的右乘项对应自适应划分的聚类目标最小化要求, 加和项中的左乘项对应相关信息损失最小化的目标要求; $N$为数据集中数据项个数, $M$为数据特征维数, ${{K}_{j}}$为特征维$j$的划分类别数, ${{c}_{jk}}$为特征维$j$上的第$k$个划分类的均值, ${{x}_{ij}}$表示第$i$个数据项的第$j$维数值, $\sigma $为尺度因子。特别地, ${{p}_{ijk}}$表示在自解释贝叶斯网络中, 由${{x}_{ij\sim }}$能推断出${{x}_{ij}}\in {{V}_{jk}}$的概率, 其中${{x}_{ij\sim }}$表示${{x}_{i}}$中去除第$j$维所构成的数据特征, ${{V}_{jk}}$表示数据维$j$上的第$k$个划分类。
连续数值特征量在表示模型中迭代地自适应动态划分, 当公式(1)目标达到最优解时, 子特征Bayesian网络的自解释性平衡最优。针对上述模型目标, 本文考虑在实际中对${{K}_{j}}$可预设一个上限值。${{p}_{ijk}}$的计算考虑每个特征维选择一个对应的最大可能关联依赖特征, 由于互信息熵[23]能够从事件之间发生的概率角度表示相互关联性, 因此, 考虑将互信息熵作为最优依赖项选择的评判指标。
为避免连续数值特征量之间关联信息的丢失, 使得连续数值特征量能自适应动态划分, 本文引入Dirichlet Process求解模型目标。Dirichlet Process是一种随机过程, 应用于非参数贝叶斯模型中, Ferguson[24]在1973年对其定义。Dirichlet Process有良好的聚类性质, 能够自动确定聚类数目, 并生成聚类中心的分布参数。为实现Dirichlet Process的采样, 需要对Dirichlet Process进行构造, 一般有Stick-breaking构造, Polyaurn Scheme构造以及Chinese Restaurant Process(CRP) [25]构造。本文采用CRP进行构造, 在自解释归约模型中, 计算连续数值特征量${{F}_{j}}$下各元素属于不同${{V}_{jk}}$划分类时目标函数值, 如公式(2)所示。
$\begin{align} & {{J}_{\text{SRM}}}\text{(}{{x}_{ij}}\in {{V}_{jk}}\text{)=}\sum\limits_{i=1}^{N}{\sum\limits_{j=1}^{M}{\sum\limits_{k=1}^{{{K}_{j}}}{{{p}_{ijk}}{{e}^{-\frac{{{({{x}_{ij}}-{{c}_{jk}})}^{2}}}{{{\sigma }^{2}}}}}}}} \\ & \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ k\in \{1,2,\cdots {{K}_{j}}\} \\ \end{align}$ (2)
在训练过程中元素属于新的划分类${{x}_{ij}}\in {{V}_{j,{{K}_{j}}\text{+}1}}$, 目标函数值如公式(3)所示。
${{J}_{\text{SRM}}}\text{(}{{x}_{ij}}\in {{V}_{j,{{K}_{j}}\text{+}1}}\text{)=}\sum\limits_{i=1}^{N}{\sum\limits_{j=1}^{M}{\sum\limits_{k=1}^{{{K}_{j}}\text{+}1}{{{p}_{ijk}}{{e}^{-\frac{{{({{x}_{ij}}-{{c}_{jk}})}^{2}}}{{{\sigma }^{2}}}}}}}}$ (3)
当${{J}_{\text{SRM}}}\text{(}{{x}_{ij}}\in {{V}_{j,{{K}_{j}}\text{+}1}}\text{)}>{{J}_{\text{SRM}}}\text{(}{{x}_{ij}}\in {{V}_{jk}}\text{)},k=1,2,\cdots {{K}_{j}}$时, 则产生新区间, 该连续数值特征量${{F}_{j}}$区间数目${{K}_{j}}$增1。若连续数值特征量${{F}_{j}}$划分区间${{F}_{j,{{L}_{k}}}}$内没有元素, 则删除此区间, 并刷新该特征量下所有划分区间标号, 总区间数目${{K}_{j}}$减1。
算法中, 有连续数值特征${{F}_{1}},{{F}_{2}},\cdots {{F}_{j-1}},{{F}_{j+1}},\cdots {{F}_{m}}$和标签特征${{F}_{m\text{+}1}},{{F}_{m+2}},\cdots {{F}_{M}}$可作为连续数值特征${{F}_{j}}$的候选关联依赖特征, 考虑计算${{F}_{j}}$与其候选关联依赖特征的互信息熵, 并比较选取最大互信息熵值对应的特征为${{F}_{j}}$的最大关联依赖特征, 据此可计算获得相应的${{p}_{ijk}}$值。
对整个模型进行反复迭代, 自解释归约模型目标值${{J}_{\text{SRM}}}$的值变化小于某一个阈值(本文设为${{10}^{-5}}$)时迭代结束, 从而得到相应的子特征Bayesian网络。网络中的节点表示连续数值特征量划分的子特征或是标签特征量的标签, 节点之间的有向边表示子特征或标签间的关联规则支持度, 无向边表示关联规则间的置信度。进一步, 可根据需要提取子特征Bayesian网络中的重要关联规则, 产生数据挖掘所期望的关联规则结果。混合特征数据的自解释归约建模算法如下。
输入: 混合数据集$D\text{= }\!\!\{\!\!\text{ }{{F}_{1}},{{F}_{2}},\cdots {{F}_{m}},{{F}_{m+1}}\text{,}$${{F}_{m+2}}\text{,}\cdots {{F}_{M}}\text{ }\!\!\}\!\!\text{ }$, 其中${{F}_{1}},{{F}_{2}},\cdots {{F}_{m}}$为连续数值特征量, ${{F}_{m+1}}\text{,}{{F}_{m+2}}\text{,}\cdots {{F}_{M}}$为标签特征量
②计算公式(2)连续数值特征量中各特征量${{F}_{j}}$中的元素在不同已有划分类的目标函数${{J}_{\text{SRM}}}\text{(}{{x}_{ij}}\in {{V}_{jk}}\text{)}$的值;
③计算公式(3)连续数值特征量中各特征量${{F}_{j}}$下元素产生新划分区间时的目标函数${{J}_{\text{SRM}}}\text{(}{{x}_{ij}}\in {{V}_{j,{{K}_{j}}\text{+}1}}\text{)}$的值; .
④比较公式(2)与公式(3)的值, 当公式(3)值大于公式(2)值时, 连续数值特征量${{F}_{j}}$产生新划分区间, 当划分区间内没有元素时, 删除此区间, 更新连续数值特征量${{F}_{j}}$下各元素的所属类别;
⑤重复步骤②-步骤④, 当${{J}_{\text{SRM}}}$的值变化小于阈值${{10}^{-5}}$时结束迭代;
⑥对子特征Bayesian网络进行后处理分析, 输出结果规则集。
以UCI标准数据集分类问题为实验对象, 分析SRM的自适应划分能力。依据混合型特征数据集选用需要, 实验中选用的UCI数据集如表1所示。
表1 本文实验用UCI数据集
| 数据集名称 | 连续量 属性数 | 标签量 属性数 | 数据类数 | 实例数 |
|---|---|---|---|---|
| glass | 9 | 0 | 9 | 214 |
| wine-quality white | 11 | 0 | 11 | 4 897 |
| wine-quality red | 11 | 0 | 11 | 1 599 |
| dermatology | 1 | 33 | 34 | 366 |
| ionosphere | 32 | 2 | 34 | 351 |
| adult | 5 | 9 | 14 | 32 562 |
实验中首先考虑采用SRM对数据集中的连续量特征维进行划分建模, 自适应得到各自维的多个划分区间, 然后结合NaïveBayes分类算法对处理后的数据集进行分类学习及预测评判。实验中, ${{K}_{j}}$上限的设为10, 同时以K-means和FCM离散化方法作为对比方法, 它们的划分类别数每轮设为与SRM方法求得的划分类别数相同。实验中采用5折交叉验证的方法, 重复20次得到分类精度的均值及均方差, 具体的实验对比结果如表2所示。
表2 不同方法的分类精度结果
| 数据集 | NaïveBayes | 本文方法+NaïveBayes | K-means+NaïveBayes | FCM+NaïveBayes |
|---|---|---|---|---|
| glass | 49.53 % | 59.14±4.60% | 61.92±4.12% | 62.43±3.75% |
| wine-quality white | 61.55% | 67.97±3.31% | 66.14±2.99% | 65.87±3.32% |
| wine-quality red | 55.35% | 54.00±2.03% | 58.16±0.98% | 58.38±0.95% |
| dermatology | 96.99% | 96.94±0.11% | 96.83±0.18% | 96.78±0.11% |
| ionosphere | 82.62 % | 86.85±1.70% | 84.63±1.70% | 84.47±1.63% |
| adult | 88.69% | 92.47±0.82% | 89.78±0.63 % | 91.34±0.80% |
实验结果表明, 使用SRM建模划分之后再采用NaïveBayes方法进行分类预测, 整体上获得了更好的分类精度。且对比来看, 在各特征维的划分类别数相同情况下, SRM的划分中心结果整体上也与K-means、FCM方法所求得的结果性能相当。综合表明, SRM对数据集中的连续量特征维进行离散化建模分析是有效且可行的。
通过模拟实验方法分析集成SRM的数据挖掘算法性能, 设计引入含有4个维度特征$\{a,b,c,d\}$的模拟数据集, 其中2个维度为连续数值量属性, 2个维度为标签特征量属性。标签特征量属性a预设有两个类, 每类的概率同等为0.5, 标签特征量属性b预设有三个类, 概率分别为0.3, 0.4, 0.3。连续量属性c预设含有N(1,1)和N(3,1)两种高斯分布, 连续量属性d预设含有N(0,1)、N(3,1)、N(6,1)三种高斯分布。
实验中考虑设置不同复杂度的关联规则, 并选用条件熵值与自信息熵值的和衡量规则复杂度。假设存在X, Y两种属性, 在Y条件下X的条件熵为$H(X\left| Y \right.)=-\sum\limits_{x\in X,y\in Y}{P(x,y)\log P(x\left| y \right.)}$, 则规则复杂度值定义如公式(4)所示。
${{H}_{f}}=-\left( \sum{{{P}_{x}}\log ({{P}_{x}})+\sum{P(x,y)\log (P(x\left| y \right.))}} \right)$ (4)
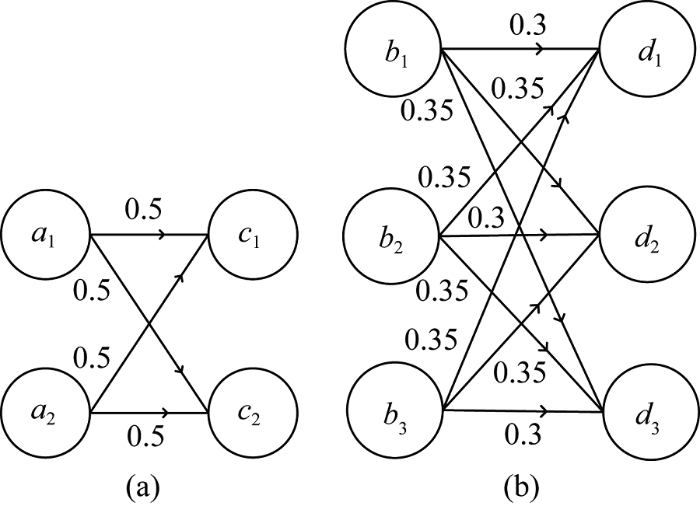
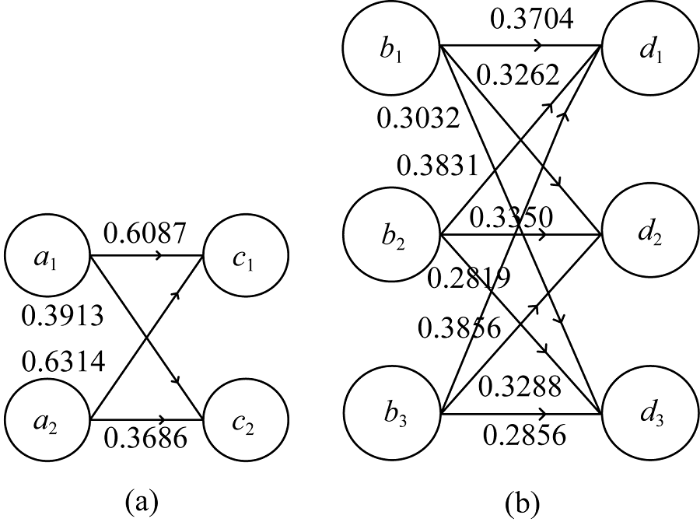
规则复杂度值越高, 定义的潜在规则越复杂。实验设计了5个不同难度等级的规则集, 模拟规则集的复杂度情况如表3所示。模拟规则4的关联规则如图2所示。
表3 模拟规则集的复杂度
| 规则集 | 规则复杂度值 |
|---|---|
| 1 | 9.5996±0.0074 |
| 2 | 16.2276±0.0158 |
| 3 | 20.8350±0.0140 |
| 4 | 29.9389±0.0211 |
| 5 | 29.6517±0.0445 |
采用交叉熵值$H(p,q)=-\sum\limits_{x}{p(x)\log (q(x))}$作为衡量规则挖掘性能指标, 其中$p$为真实分布, $q$为逼近分布。在此, $p$设为模拟规则产生的数据分布, $q$设为算法得到的数据分布。进一步定义相差度$\gamma \text{=}\frac{\left| H(p,q)-H(p,p) \right|}{H(p,p)}$表示算法所得的数据分布与模拟规则产生的数据分布的差异大小, 相差度越小, 差异越小, 挖掘出的规则越理想, 反之亦然。当$p=q$时, $\gamma \text{=}0$, 挖掘出的规则最接近理想结果。实验中, 连续量属性$c$、$d$的${{K}_{j}}$上限值设为5。
模拟规则4所产生数据集的典型挖掘结果如图3所示。可以看出, 连续量属性$c$自适应划分出的类别数目为2, 连续量属性$d$自适应划分出的类别数目为3, 与模拟规则连续属性的分布的数目一致。此时, 挖掘出的规则与模拟规则较为接近, 类别之间的关系值也很相近。对每个模拟规则进行20次实验的量化统计结果如表4所示。
表4 模拟数据挖掘实验结果
| 设定规 则序号 | 本文算法结果 (交叉熵) | 理想结果 (交叉熵) | 相差度$\gamma $ |
|---|---|---|---|
| 1 | 0.2184±0.0710 | 0.1774±1.1532e-04 | 0.2309±0.4006 |
| 2 | 0.3947±0.0880 | 0.2640±2.1624e-04 | 0.4996±0.3260 |
| 3 | 0.2840±0.0743 | 0.2689±1.6490e-04 | 0.2617±0.1062 |
| 4 | 0.3309±0.0514 | 0.3554±1.9549e-04 | 0.1528±0.0940 |
| 5 | 0.2871±0.0325 | 0.3542±3.2526e-04 | 0.1929±0.0845 |
由于连续量属性$c$由标签量属性$a$根据模拟规则产生, 连续属性$d$则由标签量属性$b$根据模拟规则产生, 设定的规则越简单, 随机因素对挖掘连续属性的分布数目和分布情况影响越大。从实验结果看, 在模拟规则比较简单的设定规则1与2的情况下, 挖掘出的规则和理想规则差距相对较大, 但挖掘出的规则仍能表明与理想规则有一定的相似性。在较为复杂的设定规则3-5的情况下, 挖掘出的规则与理想规则相似性更高。从性能结果来看, 最终的结果刻画了不同维度特征之间概率相关性, SRM很好地实现了对混合有连续量和标签量数据集的关联规则挖掘。
以江南大学数字媒体学院2016年下半学年部分学生的一卡通消费记录数据为研究对象, 挖掘分析学生消费行为的某些潜藏规律。采集的数据集含有学生996人, 跨度时间为140天, 总记录条数为411 914条, 每条记录含有4个特征量, 分别为学生编号、消费时间、消费地点、消费金额。从学生的消费行为出发, 研究中对原始数据进一步提取语义化特征, 分别为次平均消费金额${{F}_{1}}$, 早上在食堂消费的平均时间${{F}_{2}}$, 早上在食堂消费的时间方差${{F}_{3}}$, 早上在食堂的消费总次数${{F}_{4}}$, 中午在食堂消费的平均时间${{F}_{5}}$, 中午在食堂消费的时间方差${{F}_{6}}$, 中午在食堂消费的总次数${{F}_{7}}$, 晚上在食堂消费的平均时间${{F}_{8}}$, 晚上在食堂消费的时间方差${{F}_{9}}$, 晚上在食堂消费的总次数${{F}_{10}}$, 浴室消费的平均时间${{F}_{11}}$, 浴室消费的时间方差${{F}_{12}}$, 浴室消费的总次数${{F}_{13}}$。
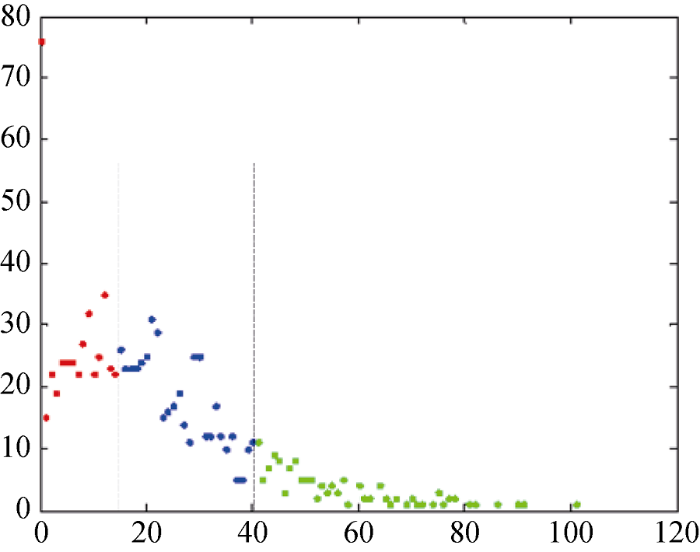
由于这些语义特征没有确定数量的子特征, 生成的子特征规则集规模不确定, 采用现有的数据挖掘方法就无法直接提取规则, 必须先作离散化处理, 但单独对每维作离散化处理会导致关联信息的丢失, 所以采用集成SRM的数据挖掘方法进行学生一卡通消费行为的规则挖掘分析。在此, 设定SRM中参数$N$为996, $M$为13, Kj的上限设为10。为得到目标函数最优解, 子特征的数目以及子特征占比会自适应调节, 特征量${{F}_{4}}$的分布划分结果如图4所示, 特征量${{F}_{7}}$的分布划分结果如图5所示。可知, 这些实际数据分布简单规则性较弱, 使用常规聚类划分手段无法找到合理可靠的立足点。
过滤子特征数目为1的特征量, 学生消费行为特征划分的实验结果如表5所示。其中, 标签${{L}_{1}}$、${{L}_{2}}$、${{L}_{3}}$对应的子特征的数值趋势从小到大, 标签${{L}_{e}}$表示无该特征记录的数据项类别。
表5 基于SRM的学生消费行为特征划分实验结果
| 语义化特征量 | 标签L1 | 标签L2 | 标签L3 | 标签Le (无记录) |
|---|---|---|---|---|
| F1 | 67.77% | 31.83% | 0.40% | / |
| F2 | 41.97% | 56.63% | / | 1.40% |
| F3 | 46.69% | 43.57% | 9.74% | / |
| F4 | 29.52% | 42.37% | 28.11% | / |
| F5 | 46.29% | 50.90% | / | 2.81% |
| F6 | 20.98% | 46.69% | 32.33% | / |
| F7 | 42.87% | 43.88% | 13.25% | / |
| F8 | 47.79% | 35.54% | / | 16.67% |
| F10 | 69.48% | 30.52% | / | / |
| F11 | 43.07% | 25.30% | / | 31.63% |
| F12 | 82.03% | 17.97% | / | / |
| F13 | 85.14% | 14.86% | / | / |
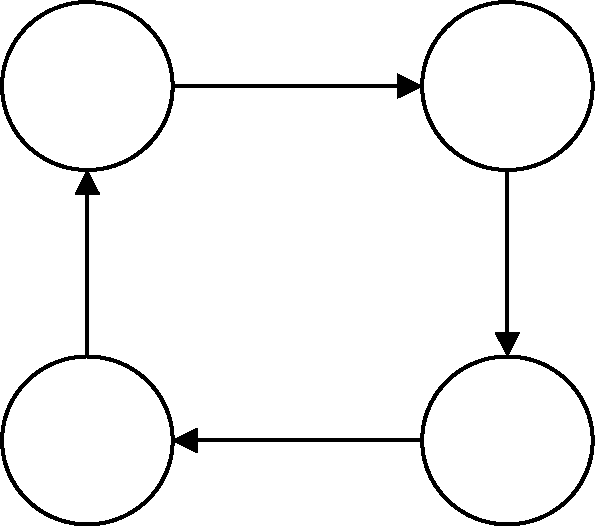
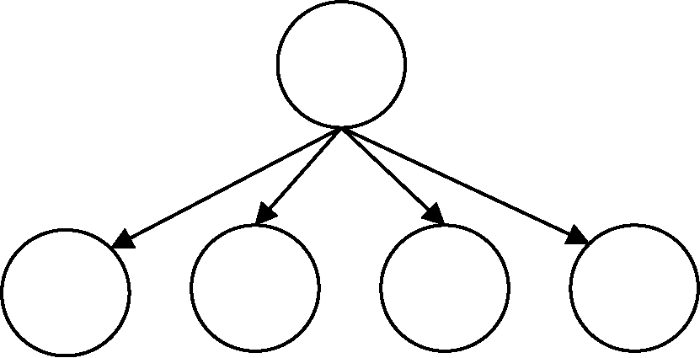
为进一步分析得出重要潜在规则, 考虑引入如图6和图7所示的两种局部节点关系。图6是一种节点间能构成闭环的节点关系拓扑结构, 表明节点间存在强耦合规则关系; 图7是一种星形的节点关系拓扑结构, 表明节点间存在中心依赖规则关系。
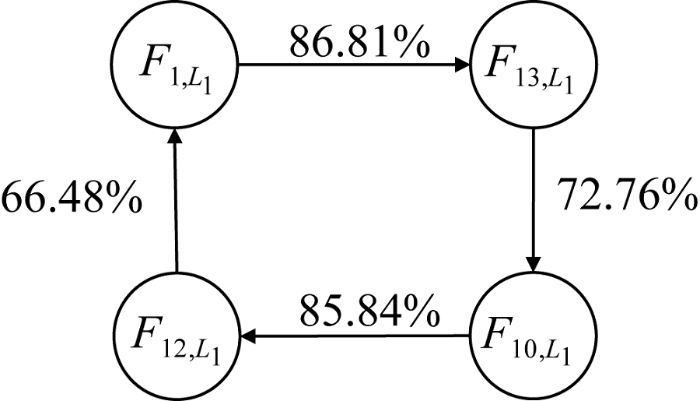
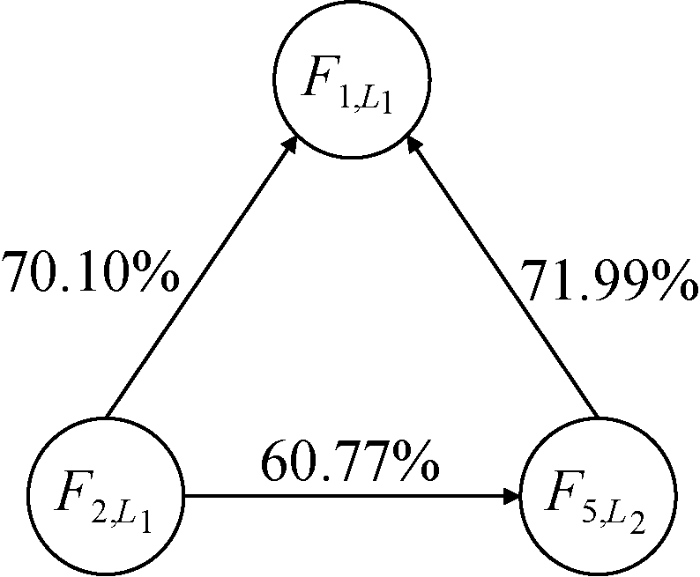
基于图6所示的闭环规则, 分析前述学生一卡通消费数据建模结果, 可得到图8所示的关于学生校园卡消费行为的一个强关联规则。可知, 学生次平均消费低的占比67.77%, 浴室消费次数少的占比85.14%, 浴室消费时间方差小的占比82.03%, 这综合表明, 大部分学生没有铺张浪费的消费行为, 洗澡的行为比较稳定。
进一步, 基于图7所示的星形规则提取方法, 筛选归纳得到以下学生校园卡消费行为规则。
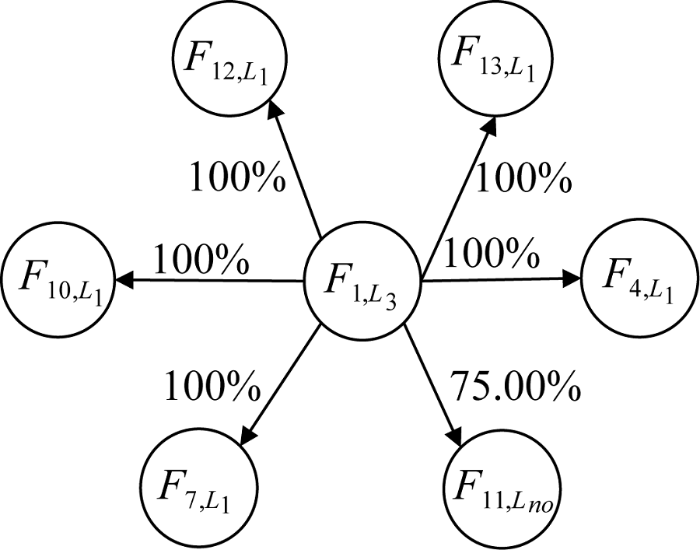
(1) 图9中, 有一部分次平均消费极高的学生人群, 在总学生占比为0.43%, 他们在食堂与浴室的消费次数很少, 但在浴室消费时间却较为稳定, 可以推想, 该类学生平时基本不在食堂就餐, 可能偶尔会有食堂内的多人请客等高消费, 其在校内正常住宿生活的可能性较小, 或许为在外实习的学生。
(2) 图10中, 有一部分早上消费时间较早的学生, 而中午就餐时间却较晚, 且他们的次平均消费金额较低, 推测这是一群学习较为认真且能勤俭节约的学生, 经进一步统计可知, 同时满足上述三类特征的学生占比为15.43%, 这部分学生人数与学院优秀生的比例较为接近, 推测主要为该类学生。
(3) 图11中, 有一类次平均消费低的学生, 在早上、中午、晚上的消费次数也较多, 经进一步统计发现, 同时符合以上4个特征的学生人数占比为0.20%, 可以推测这部分学生为经济条件相对贫困的群体, 较少进行外出高消费。
(4) 图12中, 有一类学生晚上较少在食堂消费, 早上就餐晚、中午就餐却早, 符合这三个特征的学生数占比21.08%, 可以推测这部分学生生活习惯相对散漫, 且有较多的外出消费活动, 可能是需要重点关注的学习自制力不是很强的一批学生。
综上, SRM模型能够有效解决含有连续数值与标签特征量混合型数据集的规则挖掘问题, 得出有较高可信度的语义规则。
本文提出自解释归约数据建模表示模型, 以解决连续和标签量混合特征的数据建模及规则挖掘问题,通过多个角度进行实验分析, 结果表明新模型具有有效性和良好性能。并以江南大学数字媒体学院部分学生在2016年下半学年内的一卡通消费数据挖掘需求为例进行应用研究, 实验取得了较为可信和一些有趣的学生消费行为结果, 这在直接采用现有的数据挖掘算法是无法实现的。
江思伟: 实验研究, 论文撰写;
谢振平: 提出研究思路, 设计实验方案, 论文修订;
陈梅婕: 采集、清洗数据, 实验分析;
蔡明: 采集实证数据, 实验分析。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: hmsyjiangsiwei@126.com。
[1] 江思伟, 谢振平, 陈梅婕, 蔡明. glass.csv. UCI数据集glass.
[2] 江思伟, 谢振平, 陈梅婕, 蔡明. wine-quality white.csv. UCI数据集Wine-quality white.
[3] 江思伟, 谢振平, 陈梅婕, 蔡明. wine-quality red.csv. UCI数据集Wine-quality red.
[4] 江思伟, 谢振平, 陈梅婕, 蔡明. dermatology.csv. UCI数据集dermatology.
[5] 江思伟, 谢振平, 陈梅婕, 蔡明. ionosphere.csv. UCI数据集ionosphere.
[6] 江思伟, 谢振平, 陈梅婕, 蔡明. adult.csv. UCI数据集adult.
[7] 江思伟, 谢振平, 陈梅婕, 蔡明. xsxf.csv. 2016下半学年江南大学数字媒体学院学生一卡通消费记录.
| [1] |
Mining Association Rules Between Sets of Items in Large Databases [C]// |
| [2] |
Why Discretization Works for Naive Bayesian Classifiers [C]// |
| [3] |
A Survey of Discretization Techniques: Taxonomy and Empirical Analysis in Supervised Learning [J].https://doi.org/10.1109/TKDE.2012.35 URL Magsci [本文引用: 1] 摘要
Discretization is an essential preprocessing technique used in many knowledge discovery and data mining tasks. Its main goal is to transform a set of continuous attributes into discrete ones, by associating categorical values to intervals and thus transforming quantitative data into qualitative data. In this manner, symbolic data mining algorithms can be applied over continuous data and the representation of information is simplified, making it more concise and specific. The literature provides numerous proposals of discretization and some attempts to categorize them into a taxonomy can be found. However, in previous papers, there is a lack of consensus in the definition of the properties and no formal categorization has been established yet, which may be confusing for practitioners. Furthermore, only a small set of discretizers have been widely considered, while many other methods have gone unnoticed. With the intention of alleviating these problems, this paper provides a survey of discretization methods proposed in the literature from a theoretical and empirical perspective. From the theoretical perspective, we develop a taxonomy based on the main properties pointed out in previous research, unifying the notation and including all the known methods up to date. Empirically, we conduct an experimental study in supervised classification involving the most representative and newest discretizers, different types of classifiers, and a large number of data sets. The results of their performances measured in terms of accuracy, number of intervals, and inconsistency have been verified by means of nonparametric statistical tests. Additionally, a set of discretizers are highlighted as the best performing ones.
|
| [4] |
Discretization in Gene Expression Data Analysis: A Selected Survey [C]// |
| [5] |
Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference [J]. |
| [6] |
Improving the Life Cycle Management of Power Transformers Transforming Data to Life [C]// |
| [7] |
Applications of Association Rule Mining in Health Informatics: A Survey [J].https://doi.org/10.1007/s10462-016-9483-9 URL [本文引用: 1] 摘要
Association rule mining is an effective data mining technique which has been used widely in health informatics research right from its introduction. Since health informatics has received a lot of atte
|
| [8] |
基于关联规则的文本主题深度挖掘应用研究 [J].
【目的】准确理解文本信息中潜在的知识关联,丰富文本知识挖掘的方法。【方法】将主题模型和关联规则相结合,运用LDA主题模型抽取文本中的主题集合,在实现文本降维的同时,实现文本在语义空间的表达;通过关联规则进一步挖掘文本中主题的语义关联。【结果】设置合理的支持度和置信度阈值,可以有效地挖掘文本中潜在知识的关联,实现对文本的深入“理解”。【局限】数据预处理过程中,用户自定义词典的设计会对实验结果产生一定的影响。【结论】提出一种非结构化文本信息潜在语义关联挖掘的新思路,改善了针对文本信息知识发现的效果。
Mining Document Topics Based on Association Rules [J].
【目的】准确理解文本信息中潜在的知识关联,丰富文本知识挖掘的方法。【方法】将主题模型和关联规则相结合,运用LDA主题模型抽取文本中的主题集合,在实现文本降维的同时,实现文本在语义空间的表达;通过关联规则进一步挖掘文本中主题的语义关联。【结果】设置合理的支持度和置信度阈值,可以有效地挖掘文本中潜在知识的关联,实现对文本的深入“理解”。【局限】数据预处理过程中,用户自定义词典的设计会对实验结果产生一定的影响。【结论】提出一种非结构化文本信息潜在语义关联挖掘的新思路,改善了针对文本信息知识发现的效果。
|
| [9] |
基于关联规则综合评价的图书推荐模型 [J].Books Recommended Model Based on Association Rules Comprehensive Evaluation [J]. |
| [10] |
A Fast Algorithm for Mining Association Rules [C]// |
| [11] |
Mining Frequent Patterns Without Candidate Generation [J]. |
| [12] |
Scalable Algorithms for Association Mining [J].https://doi.org/10.1109/69.846291 URL [本文引用: 1] 摘要
Abstract ssociation rule discovery has emerged as an important problem in knowledge discovery and data mining. The association mining task consists of identifying the frequent itemsets and then, forming conditional implication rules among them. In this paper, we present efficient algorithms for the discovery of frequent itemsets which forms the compute intensive phase of the task. The algorithms utilize the structural properties of frequent itemsets to facilitate fast discovery. The items are organized into a subset lattice search space, which is decomposed into small independent chunks or sublattices, which can be solved in memory. Efficient lattice traversal techniques are presented which quickly identify all the long frequent itemsets and their subsets if required. We also present the effect of using different database layout schemes combined with the proposed decomposition and traversal techniques. We experimentally compare the new algorithms against the previous approaches, obtaining improvements of more than an order of magnitude for our test databases.
|
| [13] |
Boosting Association Rule Mining in Large Datasets via Gibbs Sampling [J].https://doi.org/10.1073/pnas.1604553113 URL PMID: 27091963 [本文引用: 1] 摘要
Abstract Current algorithms for association rule mining from transaction data are mostly deterministic and enumerative. They can be computationally intractable even for mining a dataset containing just a few hundred transaction items, if no action is taken to constrain the search space. In this paper, we develop a Gibbs-sampling-induced stochastic search procedure to randomly sample association rules from the itemset space, and perform rule mining from the reduced transaction dataset generated by the sample. Also a general rule importance measure is proposed to direct the stochastic search so that, as a result of the randomly generated association rules constituting an ergodic Markov chain, the overall most important rules in the itemset space can be uncovered from the reduced dataset with probability 1 in the limit. In the simulation study and a real genomic data example, we show how to boost association rule mining by an integrated use of the stochastic search and the Apriori algorithm.
|
| [14] |
A Novel Association Rule Mining Method of Big Data for Power Transformers State Parameters Based on Probabilistic Graph Model [J].https://doi.org/10.1109/TSG.2016.2562123 URL [本文引用: 1] 摘要
The correlative change analysis of state parameters can provide powerful technical supports for safe, reliable and high-efficient operation of the power transformers. However, the analysis methods are primarily based on a single or a few state parameters, and hence the potential failures can hardly be found and predicted. In this paper, a data-driven method of association rule mining for transformer state parameters has been proposed by combining the Apriori algorithm and probabilistic graphical model. In this method the disadvantage that whenever the frequent items are searched the whole data items have to be scanned cyclically has been overcomed. This method is used in mining association rules of the numerical solutions of differential equations. The result indicates that association rules among the numerical solutions can be accurately mined. Finally, practical measured data of five 500kV transformers is analyzed by the proposed method. The association rules of various state parameters have been excavated, and then the mined association rules are used in modifying the prediction results of single state parameters. The results indicate that the application of the mined association rules improves the accuracy of prediction. Therefore, the effectiveness and feasibility of the proposed method in association rule mining has been proved.
|
| [15] |
From Observational Studies to Causal Rule Mining [J].https://doi.org/10.1145/2746410 URL [本文引用: 1] 摘要
Abstract: Randomised controlled trials (RCTs) are the most effective approach to causal discovery, but in many circumstances it is impossible to conduct RCTs. Therefore observational studies based on passively observed data are widely accepted as an alternative to RCTs. However, in observational studies, prior knowledge is required to generate the hypotheses about the cause-effect relationships to be tested, hence they can only be applied to problems with available domain knowledge and a handful of variables. In practice, many data sets are of high dimensionality, which leaves observational studies out of the opportunities for causal discovery from such a wealth of data sources. In another direction, many efficient data mining methods have been developed to identify associations among variables in large data sets. The problem is, causal relationships imply associations, but the reverse is not always true. However we can see the synergy between the two paradigms here. Specifically, association rule mining can be used to deal with the high-dimensionality problem while observational studies can be utilised to eliminate non-causal associations. In this paper we propose the concept of causal rules (CRs) and develop an algorithm for mining CRs in large data sets. We use the idea of retrospective cohort studies to detect CRs based on the results of association rule mining. Experiments with both synthetic and real world data sets have demonstrated the effectiveness and efficiency of CR mining. In comparison with the commonly used causal discovery methods, the proposed approach in general is faster and has better or competitive performance in finding correct or sensible causes. It is also capable of finding a cause consisting of multiple variables, a feature that other causal discovery methods do not possess.
|
| [16] |
Predictability-based Collective Class Association Rule Mining [J].https://doi.org/10.1016/j.eswa.2017.02.024 URL [本文引用: 1] |
| [17] |
Wolf Search Algorithm for Numeric Association Rule Mining [C]// |
| [18] |
Optimal Leverage Association Rules with Numerical Interval Conditions [J].https://doi.org/10.3233/IDA-2011-0509 URL Magsci [本文引用: 1] 摘要
ABSTRACT In this paper we propose a framework for defining and discovering optimal association rules involving a numerical attribute A in the consequent. The consequent has the form of interval conditions (A < x, A x or A I where I is an interval or a set of intervals of the form [x l , xu)). The optimality is with respect to leverage, one well known association rule interest measure. The generated rules are called Maximal Leverage Rules (MLR) and are generated from Distribution Rules. The principle for finding the MLR is related to the Kolmogorov-Smirnov goodness of fit statistical test. We propose different methods for MLR generation, taking into account leverage optimallity and readability. We theoretically demonstrate the optimality of the main exact methods, and measure the leverage loss of approximate methods. We show empirically that the discovery process is scalable.
|
| [19] |
Mining Optimized Association Rules with Categorical and Numeric Attributes [J].https://doi.org/10.1109/ICDE.1998.655813 URL [本文引用: 1] 摘要
Association rules are useful for determining correlations between attributes of a relation and have applications in marketing, financial and retail sectors. Furthermore, optimized association rules are an effective way to focus on the most interesting characteristics involving certain attributes. Optimized association rules are permitted to contain uninstantiated attributes and the problem is to determine instantiations such that either the support or confidence of the rule is maximized. We generalize the optimized association rules problem in three ways: (1) association rules are allowed to contain disjunctions over uninstantiated attributes; (2) association rules are permitted to contain an arbitrary number of uninstantiated attributes; and (3) uninstantiated attributes can be either categorical or numeric. Our generalized association rules enable us to extract more useful information about seasonal and local patterns involving multiple attributes. We present effective techniques for pruning the search space when computing optimized association rules for both categorical and numeric attributes. Finally, we report the results of our experiments that indicate that our pruning algorithms are efficient for a large number of uninstantiated attributes, disjunctions and values in the domain of the attributes.
|
| [20] |
Unsupervised Discretization Using Kernel Density Estimation [C]// |
| [21] |
Unsupervised Discretization Using Tree-based Density Estimation [C]// |
| [22] |
Unsupervised Discretization: An Analysis of Classification Approaches for Clinical Datasets [J].https://doi.org/10.19026/rjaset.14.3991 URL [本文引用: 1] 摘要
Discretization is a frequently used data preprocessing technique for enhancing the performance of data mining tasks in knowledge discovery from clinical data. It is used to transform the real-world quantitative data into qualitative data. The aim of this study is to present an experimental analysis of the variation in performance of two trivial unsupervised discretization methods with respect to different classification approaches. Equal width discretization and equal frequency discretization methods are applied for four benchmark clinical datasets obtained from the University of California, Irvine, machine learning repository. Both the methods were applied for transforming quantitative attributes into qualitative attributes with three, five, seven and ten intervals. Six classification approaches were evaluated using four evaluation measures. From the results of this experimental analysis, it can be observed that there is a variation in the performance of classification algorithms. Accuracy of classification varies with respect to the discretization method used and also with respect to the number of intervals of discretization. Moreover it can be inferred that different classification approaches require different discretization methods. No method can be deemed to be 'the best-suitable' for all applications; hence the choice of an appropriate discretization method depends on data distribution, data interpretability, correlation, classification performance and domain of application.
|
| [23] |
Estimation of Entropy and Mutual Information [J].https://doi.org/10.1162/089976603321780272 URL [本文引用: 1] 摘要
formula of Miller and Madow over a large region of parameter space. The two most practical implications of these results are negative: (1) information estimates in a certain data regime are likely contaminated by bias, even if “bias-corrected” estimators are used, and (2) confidence intervals calculated by standard techniques drastically underestimate the error of the most common estimation methods. Finally, we note a very useful connection between the bias of entropy estimators and a certain polynomial approximation problem. By casting bias calculation problems in this approximation theory framework, we obtain the best possible generalization of known asymptotic bias results. More interesting, this framework leads to an estimator with some nice properties: the estimator comes equipped with rigorous bounds on the maximum error over all possible underlying probability distributions, and this maximum error turns out to be surprisingly small. We demonstrate the application of this new estimator on both real and simulated data.
|
| [24] |
A Bayesian Analysis of Some Nonparametric Problems [J]. |
| [25] |
Hierarchical Dirichlet Processes [J]. |

/
| 〈 |
|
〉 |





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}