徐建民 , 许彩云
, 许彩云
河北大学网络空间安全与计算机学院 保定 071002
Xu Jianmin, Xu Caiyun
中图分类号: G202 TP391
通讯作者:
收稿日期: 2018-02-26
修回日期: 2018-02-26
网络出版日期: 2018-10-25
版权声明: 2018 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】针对仅利用文本信息计算科技文档相似度存在的不足, 提出一种结合文本和公式信息计算科技文档相似度的方法。【方法】将单个公式的特征元素映射为位置向量, 计算得到单个公式的相似度; 计算文档间的公式覆盖度和相似度; 结合文本和公式信息计算得到科技文档相似度。【结果】比较本文方法和传统向量空间方法的分类性能, 结果显示本文方法在宏平均F值上最大可提高6.7%。【局限】没有包含文档公式信息的公开测试集, 自行构建的数据集规模较小。【结论】结合公式信息计算文档相似度, 不仅能有效提高文档相似度计算的准确性, 而且可以实现跨语言文档的相似度计算。
关键词:
Abstract
[Objective] This paper proposes a new method to calculate the similarity of science and technology documents combining the information of texts and formulas, aiming to improve the performance of traditional methods. [Methods] Firstly, we mapped feature elements of single formula into position vector, which helped us calculate the similarity of single formula. Secondly, we computed the coverage and similarity of formula between documents. Finally, the similarity of science and technology documents were calculated by combining information of texts and formulas. [Results] We compared the classification results of the new method and the traditional ones. We found that the macro average F-score of the new method was increased by 6.7%. [Limitations] The test sets do not collect formula information of documents, which need to be expanded. [Conclusions] The new method could calculate document similarity more accurately.
Keywords:
文档相似度是一个用来衡量两个或多个文档匹配程度的参数[1], 广泛应用于信息检索、机器翻译、自动问答、社区发现、抄袭检测等领域[2,3,4]。目前, 文档相似度的计算方法主要包括向量空间模型方法[5]、集合运算模型方法[6]、基于文档结构方法[7]和基于引文图方法[8]等。但上述方法从文本、文档结构或文档链接关系计算文档相似度, 未考虑非文本的公式、表格、图像等信息。唐亚伟[9]和Amarnath等[10]分别将公式信息应用于论文查重和文档检索领域, 但未将其与文本信息结合应用于科技文档相似度计算。
科技文档资源是一种多模态数据, 除文本信息外, 还包括丰富的公式、表格、图像等信息。这些信息与占据主导地位的文本信息相互说明, 互为补充, 使用户能够充分理解科技文档资源的知识[11]。相对于表格和图像, 公式更能准确地表达一篇科技文档的内容。在外形上, 公式呈非线性结构, 可以用于描述和展示比表格和图像更加复杂的逻辑关系; 在内容上, 公式简洁明了, 对问题的描述和表达比表格和图像更精 确[12]; 在应用上, 公式是国际学术交流通用的语言, 应用范围比较广[13]; 在稳定性上, 公式更稳定且不易更改。在利用文本信息的基础上, 结合公式信息, 不仅能有效提高科技文档相似度计算的准确性, 而且可以实现跨语言文档的相似度计算。基于此, 本文提出一种文本和公式相结合计算科技文档相似度的方法, 并通过实验验证该方法的有效性。
一篇科技文档di可以由文本和公式两部分表示, 即${{d}_{i}}={{T}_{i}}\bigcup {{F}_{i}}$, $i\in {{N}^{+}}$。其中Ti表示科技文档di的特征词集合, Fi表示科技文档di的公式集合, N +表示正整数集。
科技文档di中的文本用向量空间模型表示。该方法将每个特征词看作是特征空间中的独立一维, 并将特 征词的权重作为每一维的坐标值, 进而把整个文本看作是由一组特征词组成的特征向量, 即: ${{\mathbf{T}}_{i}}=(({{t}_{i1}}:{{w}_{i1}}),$ $({{t}_{i2}}:{{w}_{i1}}),\cdots ,({{t}_{in}}:{{w}_{in}}))$。tik表示文本向量Ti中的第k个特征词, wik表示特征词tik的权值。
特征词tik的权值wik, 可采用TF-IDF方法得出, 常用公式(1)[14]计算。
${{w}_{ik}}=\frac{\log (t{{f}_{ik}}+1)}{\log T}\log \frac{N}{{{n}_{ik}}}$ (1)
其中, tfik表示特征词tik在文本di中出现的频率, N表示文本集的大小, nik表示含有特征词tik的文本数, T表示文本di包含的特征词总数。
定义1: 在自然科学中用数学形式表示几个量之间关系(如定律或定理)的式子称作公式[15]。公式通常都可以提取其特征元素并用来唯一标识自己。不失一般性, 本文以数学公式为例进行论述。文档中的数学公式可以分为独立公式和内嵌公式, 独立公式单独作为一行且行中不包括文本, 而内嵌公式与文本交杂在一起[11]。由于大部分内嵌公式都是对独立公式的说明, 因此在本文中提到的数学公式均指独立公式。
(1) 公式的归一化
科技文档中公式的表示方法有很多种, 并且格式常常不统一, 为了便于公式特征元素的提取和表示, 必须对公式进行归一化处理。公式归一化处理的步骤如下。
①预处理: 对公式进行等价变形操作, 如分式形式统一使用除号、乘号统一使用叉乘、去除多余的括号等。
②归一化: 将等价变形后的公式转化成二叉树的形式。一些运算符的操作数具有可交换性, 交换前后语义不变, 但树形结构可能不同, 因此需对二叉树结构做归一化处理[9]: 当可交换性操作符连接的是叶子节点时, 若左右叶子节点值的数据类型(变量或常量)不同, 通过交换左右叶子节点, 使常量在左叶子节点上, 变量在右叶子节点上; 当可交换性操作符连接的是非叶子节点时, 通过交换具有可交换性操作符节点的左右子树, 使二叉树的可交换节点的左子树高度小于等于右子树高度[16]。
③转化成字符串: 中序遍历归一化后的二叉树, 得到由公式转化成的字符串。
(2) 公式特征元素的提取
公式由变量、运算符、常量和括号等有序组成。公式特征元素提取原则如下。
①不提取变量作为特征元素。变量名一般与公式含义无关, 故不提取。
②按序提取特征元素。有些运算符不具有交换性, 不按序提取可能会改变源公式含义。
③提取运算符、常量和括号作为特征元素。运算符是对公式元素进行特定类型运算的符号, 运算符不同, 公式的含义不同; 常量是一种确定的数值, 具有确定性; 括号是用来规定运算次序的符号, 运算次序不同, 公式的含义也可能 不同。
例如公式$z=(x+5)\div y$和$z=(a+5)\div b$, 可以按序提取等号“=”、左括号“(”、运算符“+”、常量“5”、右括号“)”和运算符“÷”作为其特征元素。
(3) 公式的表示
公式可以由有序特征元素构成的字符串表示。文档di中的第k个公式fik可表示为: ${{f}_{ik}}=z_{ik}^{1}$ $z_{ik}^{2}\cdots z_{ik}^{p}$, $p\in {{N}^{+}}$其中, $z_{ik}^{m}$表示公式fik的第m个特征元素。
整个科技文档di中的公式采用集合方法表示, 把每一个不同的公式看作集合中的一个元素, 对于相同公式, 为了不影响公式相似度的计算, 只保留其中一个。结合上文中公式的表示方法, 科技文档di中的公式可表示为集合${{F}_{i}}=\{{{f}_{i1}},{{f}_{i2}},\cdots ,{{f}_{ir}}\}$。
科技文档由文本和公式两部分表示, 因此科技文档的相似度也可由文本相似度和公式相似度两部分 构成。
采用常见的余弦相似度计算方法计算文本相似度, 如公式(2)[17]所示。
$sim({{\mathbf{T}}_{i}},{{\mathbf{T}}_{j}})=\frac{\sum\limits_{k=1}^{n}{({{w}_{ik}}\times {{w}_{jk}})}}{\sqrt{\sum\limits_{k=1}^{n}{{{({{w}_{ik}})}^{2}}}}\sqrt{\sum\limits_{k=1}^{n}{{{({{w}_{jk}})}^{2}}}}}$ (2)
(1) 单个公式的相似度计算
一个公式是由运算符、常量和各类括号等有序组成的字符串, 不具有二义性, 所以单个公式相似度的值为1或0。借鉴董刊生等[18]计算词序相似度的思想, 本文提出单个公式相似度的计算方法, 具体步骤 如下。
①如果两个公式fik和fjl的字符串长度不等, 那么两个公式的相似度为0。
②如果两个公式fik和fjl的字符串长度相等, 则:
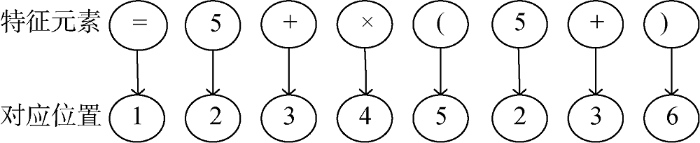
1)将公式fik中的特征元素按位置映射, 由位置序列形成标准向量$\mathbf{V}=(1,2,\cdots ,p)$。同一特征元素在公式fik中多次出现时, 仅记录首次位置。例如公式$z=5+y\times (5+x)$的特征元素通过位置映射形成的标准向量为$\mathbf{V}=(1,2,3,4,5,2,3,6)$, 如图1所示。
2)将公式fjl的特征元素按照其在公式fik中的位置映射, 由位置序列形成向量$\mathbf{{V}'}=({{{v}'}_{1}},{{{v}'}_{2}},\cdots {{{v}'}_{3}})$。如果公式fjl的特征元素${{z}_{i{{k}_{t}}}}$$(1\le t\le n)$在公式fik中不存在, 则设${{{v}'}_{t}}$等于0。例如公式$z=y\times (5+x)-5$的特征元素按照在公式$z=5+y\times (5+x)$中位置映射, 由位置序列得到的向量$\mathbf{{V}'}=(1,4,5,2,3,6,0,2)$, 如图2所示。
3)通过1)和2)可知, 两个公式fik和fjl的相似度可转化为两个向量V和$\mathbf{{V}'}$是否相等的问题。向量相等的充分必要条件是: 向量的模相等且方向相同。因此, 本文提出公式fik和${{f}_{jl}}$的相似度计算如公式(3)所示。
$sim({{f}_{ik}},{{f}_{jl}})=\left\{ \begin{matrix} 1 & |\mathbf{V}|=|\mathbf{{V}'}|and\text{ }\mathrm{cos}\text{ }(\mathbf{V},\mathbf{{V}'})=1 \\ 0 & others \\\end{matrix} \right.$(3)
其中, $|\mathbf{V}|$表示向量V的模, $\cos (\mathbf{V},\mathbf{{V}'})=1$表示向量V和$\mathbf{{V}'}$的方向相同。
(2) 文档间的公式相似度计算
文档间公式的覆盖度不仅可以反映文档间公式的引用关系, 还可以反映文档间公式的相似程度。基于此, 本文给出文档间公式覆盖度和相似度的定义。
定义2: 公式集${{F}_{i}}=\{{{f}_{i1}},{{f}_{i2}},\cdots ,{{f}_{ir}}\}$对公式集${{F}_{j}}=\{{{f}_{i1}},{{f}_{i2}},\cdots ,{{f}_{is}}\}$的覆盖度表示为两个公式集中相同公式占公式集Fj的比例, 如公式(4)所示。
$coverage({{F}_{i}},{{F}_{j}})=\frac{\sum\limits_{l=1}^{r}{\sum\limits_{k=1}^{s}{sim({{f}_{ik}},{{f}_{jl}})}}}{len({{F}_{j}})}$ (4)
同理可得, 公式集Fj对公式集Fi的覆盖度可采用公式(5)计算。
$coverage({{F}_{j}},{{F}_{i}})=\frac{\sum\limits_{l=1}^{r}{\sum\limits_{k=1}^{s}{sim({{f}_{ik}},{{f}_{jl}})}}}{len({{F}_{i}})}$ (5)
其中, len(Fj)表示文档dj中公式的个数。
定义3: 假设文档di的公式集${{F}_{i}}=\{{{f}_{i1}},{{f}_{i2}},\cdots ,{{f}_{ir}}\}$, 文档dj的公式集${{F}_{j}}=\{{{f}_{i1}},{{f}_{i2}},\cdots ,{{f}_{is}}\}$, 则文档di和dj的公式相似度可表示为公式集Fi和Fj对彼此覆盖度的调和平均值, 如公式(6)所示。
$sim({{F}_{i}},{{F}_{j}})=\frac{2}{\frac{1}{coverage({{F}_{i}},{{F}_{j}})}+\frac{1}{coverage({{F}_{j}},{{F}_{i}})}}$ (6)
在得到文本相似度和公式相似度的基础上, 参考线性组合方法[19], 本文提出文档di和dj的相似度计算公式, 如公式(7)所示。
$sim({{d}_{i}},{{d}_{j}})=\alpha sim({{\mathbf{T}}_{i}},{{\mathbf{T}}_{j}})+(1-\alpha )sim({{F}_{i}},{{F}_{j}})$ (7)
其中, $\alpha$是可调节的参数, 当$\alpha $=0时, 该公式的意义是只计算文档间公式的相似度, 可以应用于跨语言科技文档相似度计算; 当$\alpha $=1时, 该公式的意义是只计算文本的相似度, 可应用于纯文本的文档相似度的计算。
为了验证本文算法的有效性, 设计本文方法与向量空间模型方法的对比实验。两种方法都采用KNN方法[20]对人工构建的数据集进行分类, 并比较分类 性能。
文本分类领域中, Reuters-21578数据集[21]是使用最广泛的标准英文数据集之一, 国内常用的是复旦大学提供的中文文本数据集[22]。但这些数据集是基于同种语言的, 且没有考虑公式要素。本文参照国外小型数据集的构建方法[23], 人工构建一个小型数据集。小型数据集限定于计算机领域, 包括贝叶斯检索、个性化推荐、人脸识别、用户影响力和文本分类5个主题, 共300篇文档, 构造方法如下。
针对每个主题, 确定一篇基准文档, 在基准文档基础上按下述方法进行扩充。
(1) 通过基准文档的参考文献或研究综述找到部分具有文本或公式天然相似性的科技文档。
(2) 为保证数据集的真实性和客观性, 对文档进行背靠背地文字修改, 即在保证修改后文档与原文档所表达的内容一致的前提下, 由人员B对人员A找到的文档进行文字修改。
(3) 英文文档翻译成对应的中文文档。数据集的基本数据如表1所示。
表1 数据集统计
| 数据集构成 | 贝叶斯检索(60篇) | 个性化推荐(60篇) | 人脸识别(60篇) | 用户影响力(60篇) | 文本分类(60篇) |
|---|---|---|---|---|---|
| 基准文档 | 1 | 1 | 1 | 1 | 1 |
| 天然相似 | 17 | 11 | 11 | 11 | 11 |
| 背靠背修改 | 24 | 48 | 48 | 48 | 48 |
| 中英互译 | 18 | 0 | 0 | 0 | 0 |
分类结果评价标准如下。
(1) 对于单个类别的分类效果采用精确率(P), 召回率(R)、F值(F)衡量。
(2) 对多个类别的整体分类效果采用宏平均精确率(MP)、宏平均召回率(MR)、宏平均F值(MF)衡量。
将数据集中60%的文档作为训练集, 40%的文档作为测试集。数据集中各主题的总文档数都为60篇, 因此每个主题各抽取36篇文档作为训练集, 24篇文档作为测试集。
(1) 确定KNN分类中参数K
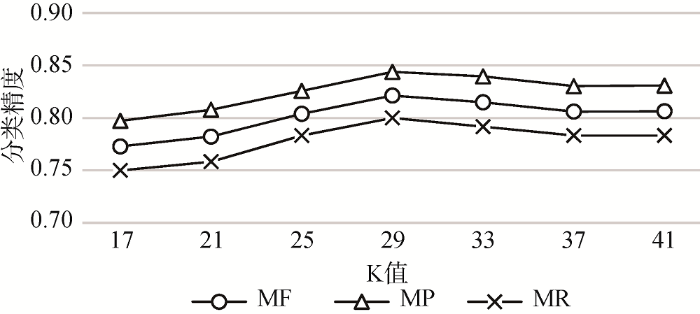
KNN算法中K是非常重要的参数。为了验证适合本文测试集的最佳K值, 选取不同的K值, 利用向量空间方法计算其对文档分类的影响, 结果如图3所示。
从图3可以看出, 当K<29时, 分类性能随着K值不断变化, 分类精度变化的波动比较大, 说明K值过小时, 噪声对分类的影响较大; 当37<K<41时, 分类性能随着K值不断变化, 分类精度变化的波动比较小, 原因是训练集中每个主题的文档数都为36篇, 此时噪声对分类的影响较小。当K=29时, MF有最大值, 因此将29作为K的最优值。
(2) 实验结果及其分析
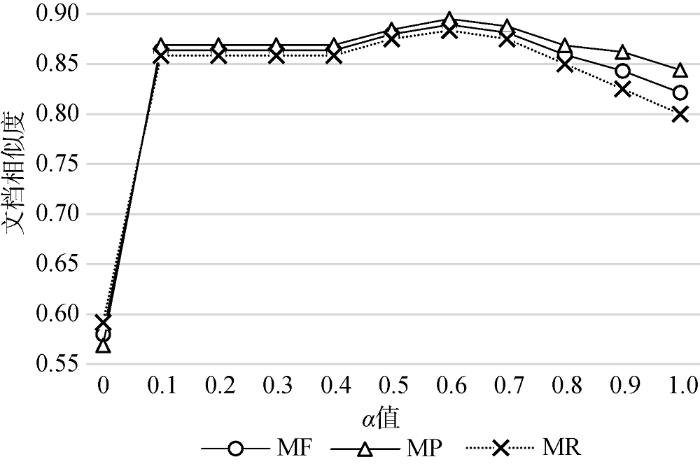
文档相似度计算公式中的参数$\alpha $, 不同的数据集和主题类别应有不同的取值。为了得到本文数据集中参数$\alpha$]的值, 利用宏平均精确率MP、宏平均召回率MR和宏平均F值作为评价标准, 采用反复训练的方法获得其较优值。在K=29时, 运用本文方法分别计算$\alpha $=0, 0.1, 0.2, ···, 1时, 对测试集整体分类性能的影响, 结果如图4 所示。
从图4可以看出, 当$\alpha$=0.6时, MF、MR和MP都达到最大值。分析可知, 该数据集中各主题文档之间内容存在一致性, 但其使用的方法不同导致该数据集中公式因素对文档相似度的影响较小。将$\alpha$=0.6作为算法中的最优值, 如果想得到更为合理的$\alpha $值, 可进一步细化训练0.5-0.7范围内的MF值。后续实验将$\alpha $=0.6作为文档相似度计算的参数值。
图4中, $\alpha $=1时所对应的MF, MR, MP值表示向量空间模型方法对测试集整体分类的效果; 0<$\alpha $<1时表示文本和公式结合方法对测试集整体分类的效果。可以看出, 当$\alpha $取(0,1)之间的任何值时, 文本和公式结合方法都优于传统的向量空间模型, 产生该结果的原因是该方法有效考虑了科技文献中公式的重要性和不易更改性。
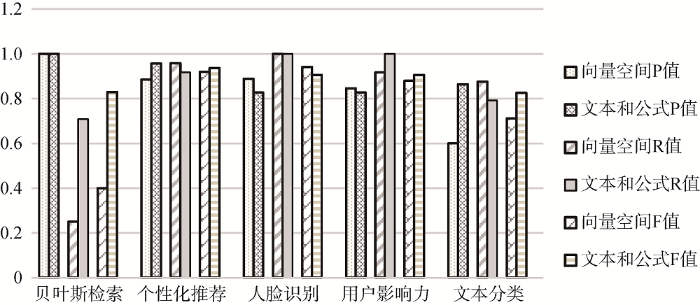
表2 两种方法不同主题分类性能的三种指标值
| 主题 | 向量空间 | 文本和公式 | ||||
|---|---|---|---|---|---|---|
| P | R | F | P | R | F | |
| 贝叶斯检索 | 1 | 0.25 | 0.4 | 1 | 0.71 | 0.83 |
| 个性化推荐 | 0.88 | 0.96 | 0.92 | 0.96 | 0.92 | 0.94 |
| 人脸识别 | 0.89 | 1 | 0.94 | 0.83 | 1 | 0.91 |
| 用户影响力 | 0.85 | 0.92 | 0.88 | 0.83 | 1 | 0.91 |
| 文本分类 | 0.6 | 0.88 | 0.71 | 0.86 | 0.79 | 0.83 |
从图5可以看出, 在5个主题分类中文本和公式结合方法的性能整体优于向量空间方法。人脸识别主题分类中, 文本和公式结合方法的性能略低于向量空间方法, 其原因是人脸识别文档中所采用卷积神经网络技术被应用到文本分类领域, 当文本因素所占的比重减少时, 导致被错分到该类的文档数比之前多; 贝叶斯主题分类中, 文本和公式结合方法的性能明显优于向量空间方法, 其原因是贝叶斯检索中包含中英文混合文档, 当英文文档被翻译成中文文档时, 利用向量空间方法两者之间的相似度值很小, 很容易被错分到其他类中, 同时也说明本文方法适用于跨语言文档相似度计算。
本文将公式信息应用于文档的相似度计算, 提出一种综合考虑文本和公式信息的科技文档相似度计算方法, 并与向量空间模型方法进行比较。实验结果表明, 该方法不仅可以提高文档相似度计算的准确性, 而且适用于跨语言文档相似度计算。存在不足是: 实验采用的数据集规模较小, 并且未考虑科技文档中文本和公式的语义信息。
徐建民: 提出论文选题与研究思路, 设计研究方案, 修改论文;
许彩云: 研究方案实施, 撰写论文, 数据采集, 实验设计与分析。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: 1490676361@qq.com。
[1] 许彩云. dataset.rar. 实验数据集.
| [1] |
基于VSM的文本相似度计算的研究 [J].https://doi.org/10.3969/j.issn.1001-3695.2008.11.015 URL [本文引用: 1] 摘要
文本相似度的计算作为其他文本信息处理的基础和关键,其计算准确率和效率直接影响其他文本信息处理的结果。提出改进的DF算法和TD-IDF算法,一方面利用了DF算法具有线性的时间复杂度,比较适合大规模文本处理的特点,并通过适当增加关键词的方法,弥补了其对个别有用信息错误过滤的不足;另一方面,利用特征项在特征选择阶段的权重对TD-IDF方法进行加权处理,在不增加开销的情况下扩大了文档集的规模,还提高了相似度计算的精确度。
Similarity Computing of Documents Based on VSM [J].https://doi.org/10.3969/j.issn.1001-3695.2008.11.015 URL [本文引用: 1] 摘要
文本相似度的计算作为其他文本信息处理的基础和关键,其计算准确率和效率直接影响其他文本信息处理的结果。提出改进的DF算法和TD-IDF算法,一方面利用了DF算法具有线性的时间复杂度,比较适合大规模文本处理的特点,并通过适当增加关键词的方法,弥补了其对个别有用信息错误过滤的不足;另一方面,利用特征项在特征选择阶段的权重对TD-IDF方法进行加权处理,在不增加开销的情况下扩大了文档集的规模,还提高了相似度计算的精确度。
|
| [2] |
基于Word2Vec的中文文本相似度研究与实现[D] .Research and Implementation of Document Similarity Based on Word2Vec[D] . |
| [3] |
Set-based Vector Model: An Efficient Approach for Correlation-based Ranking [J].https://doi.org/10.1145/1095872 URL [本文引用: 1] |
| [4] |
面向开放领域文本的实体关系抽取[D] .Entity Relation Extraction for Open Domain Text[D] . |
| [5] |
向量空间模型文本建模的语义增量化改进研究[J] .Semantic Incremental Improvement on Vector Space Model for Text Modeling[J] . |
| [6] |
|
| [7] |
Novel Method for Measuring Structure and Semantic Similarity of XML Documents Based on Extended Adjacency Matrix [J].https://doi.org/10.1016/j.phpro.2012.02.215 URL [本文引用: 1] 摘要
Similarity measurement of XML documents is crucial to meet various needs of approximate searches and document classifications in XML-oriented applications. Some methods have been proposed for this purpose. Nevertheless, few methods can be elegantly exploited to depict structure and semantic information and hence to effectively measure the similarity of XML documents. In this paper, we present a new method of computing the structure and semantic similarity of XML documents based on extended adjacency matrix(EAM). Different from a general adjacency matrix, in an EAM, the structure information of not only the adjacent layers but also the ancestor-descendant layers can be stored. For measuring the similarity of two XML documents, the proposed method firstly stores the structure and semantic information in two extended adjacency matrices(M1, M2). Then it computes similarity of the two documents through cos(M1, M2) Experimental results on bench-mark data show that the method holds high efficiency and accuracy.
|
| [8] |
Document Similarity Detection Using Semantic Social Network Analysis on RDF Citation Graph [C]// |
| [9] |
公式相似度算法及其在论文查重中的应用研究[D] .Research on Mathematical Formula Similarity Algorithm and the Application Research in Paper Plagiarism Detection[D] . |
| [10] |
MathIRs: Retrieval System for Scientific Documents [J]. |
| [11] |
科技文献的多模态语义关联特征提取与表示体系研究——以数学公式为例[D] .Research on Multi-modal Semantic Features Extraction and Expression System in Scientific and Technical Literature —— The Case of Mathematical Formula[D] . |
| [12] |
科技文档中数学公式的描述与检索[D] .The Description and Retrieval of Math Formulas in Scientific Documents[D] . |
| [13] |
PDF文档的数学公式识别与检索研究[D] .Research on Method of Mathematical Formula Detection in PDF Documents[D] . |
| [14] |
Turning from TF-IDF to TF-IGM for Term Weighting in Text Classification [J].https://doi.org/10.1016/j.eswa.2016.09.009 URL [本文引用: 1] 摘要
Massive textual data management and mining usually rely on automatic text classification technology. Term weighting is a basic problem in text classification and directly affects the classification accuracy. Since the traditional TF-IDF (term frequency & inverse document frequency) is not fully effective for text classification, various alternatives have been proposed by researchers. In this paper we make comparative studies on different term weighting schemes and propose a new term weighting scheme, TF-IGM (term frequency & inverse gravity moment), as well as its variants. TF-IGM incorporates a new statistical model to precisely measure the class distinguishing power of a term. Particularly, it makes full use of the fine-grained term distribution across different classes of text. The effectiveness of TF-IGM is validated by extensive experiments of text classification using SVM (support vector machine) andkNN (knearest neighbors) classifiers on three commonly used corpora. The experimental results show that TF-IGM outperforms the famous TF-IDF and the state-of-the-art supervised term weighting schemes. In addition, some new findings different from previous studies are obtained and analyzed in depth in the paper.
|
| [15] |
数学公式的演变及其规范表达 [J].The Evolution of Mathematical Formula and Its Canonical Expression [J]. |
| [16] |
A Mathematics Retrieval System for Formulae in Layout Presentations [C]// |
| [17] |
|
| [18] |
基于向量距离的词序相似度算法 [J].
网络查询分类对提高搜索引擎的搜索质量有重要的意义。该文通过对真实用户查询日志的分析和标注,发现四种特征词(称之为“VASE”特征词)对查询分类起决定性作用。我们提取特征词并构造了一个特征词倒排索引,用于对查询进行主题分类。在此基础之上,提出了基于网络扩展和加权特征词的方法改善分类的效果。实验结果显示,基于此分类方法的正确率和召回率分别达到78.2%和77.3%。
Word Order Similarity Algorithm Based on Vector Distance [J].
网络查询分类对提高搜索引擎的搜索质量有重要的意义。该文通过对真实用户查询日志的分析和标注,发现四种特征词(称之为“VASE”特征词)对查询分类起决定性作用。我们提取特征词并构造了一个特征词倒排索引,用于对查询进行主题分类。在此基础之上,提出了基于网络扩展和加权特征词的方法改善分类的效果。实验结果显示,基于此分类方法的正确率和召回率分别达到78.2%和77.3%。
|
| [19] |
Assigning Appropriate Weights for the Linear Combination Data Fusion Method in Information Retrieval [J].https://doi.org/10.1016/j.ipm.2009.02.003 URL [本文引用: 1] 摘要
In data fusion, the linear combination method is a very flexible method since different weights can be assigned to different systems. However, it remains an open question which weighting schema should be used. In some previous investigations and experiments, a simple weighting schema was used: for a system, its weight is assigned as its average performance over a group of training queries. However, it is not clear if this weighting schema is good or not. In some other investigations, different numerical optimisation methods were used to search for appropriate weights for the component systems. One major problem with those numerical optimisation methods is their low efficiency. It might not be feasible to use them in some situations, for example in some dynamic environments, system weights need to be updated from time to time for reasonably good performance. In this paper, we investigate the weighting issue by extensive experiments. The key point is to try to find the relation between performances of component systems and their corresponding weights which can lead to good fusion performance. We demonstrate that a series of power functions of average performance, which can be implemented as efficiently as the simple weighting schema, is more effective than the simple weighting schema for the linear data fusion method. Some other features of the power function weighting schema and the linear combination method are also investigated. The observations obtained from this study can be used directly in fusion applications of component retrieval results. The observations are also very useful for optimisation methods to choose better starting points and therefore to obtain more effective weights more quickly.
|
| [20] |
基于维基百科的多种类型文献自动分类研究 [J].
随着互联网的逐渐普及,这些新兴的网络文本资源以极快的速度增长,这导致传统的手工分类方法由于效率较低,难以及时、有效地对这些网络数字资源进行合理地分类管理,因此必须利用自动文本分类技术来对其进行分类组织。而当前的自动文本分类技术往往研究的是针对来自同种文献类型的文本资源,而数字图书馆作为一种新型图书馆,其面临的待分类整理的文献来自图书、期刊、网页等等多种领域且属于多种类型,目前针对多种文献类型的自动分类研究还有待完善,所以研究改进针对多种文献类型的自动分类算法对数字图书馆的成长与发展能起到显著的推动作用。本文通过介绍与分析当前文本分类方面的相关研究及主要技术,提出了一种通过基于维基百科的特征扩展来提高针对不同类型文献分类效果的分类方法。针对由不同文献类型所造成的特征不匹配问题,本文认为通过第三方语料库可以有效地将原本不匹配的特征词进行关联,从而解决在特征词不匹配的情形下无法对不同类型文本间进行语义相关度计算的问题。一方面可以丰富当前待分类文本的语义特征,与由不同类型文献训练来得到的分类器产生相匹配特征,同时还可以解决在文本分类问题中普遍存在的特征稀疏等问题。本文主要进行的研究内容如下:(1)本文以互联网上的文本内容爆炸式增长为背景,论述未来数字图书馆面对以几何级数增加的网络文本分类管理困难的问题,引出了多种类型文献自动分类技术研究的必要性。继而本文提出的通过特征扩展解决上述问题的思路,并通过论述与分析当前相关研究的成果与进展来论证本文提出的文本分类方法的可行性与适用性。(2)本研究提出了一种基于特征扩展的多种类型文献文本分类方法,其中特征扩展操作是消除不同类型文献自动分类时文本间语义差异的核心步骤。而在进行特征扩展前需要从训练文本中提取一部分特征词作为特征扩展候选词集。本研究在论述传统特征选择方法的不足并举例说明其缺点的基础上,继而提出对其进行改进的原理与方法,并通过计算表明新的特征选择方法确实能解决原有不足。最后,本文使用改进的特征选择方法进行特征扩展候选词集的提取,并通过实验对比证明该方法的有效性。(3)为解决对不同类型文献间进行自动分类时遇到的特征不匹配等问题,本文提出一种基于特征扩展的文本分类方法,使用维基百科计算的语义相关度来准确衡量特征词之间的相关程度。在对待分类文本完成特征扩展之后,本文使用LDA主题模型对数据进行表示建模,但传统的LDA模型不能正常地对带权特征词进行建模,故而本文又对LDA模型进行改进,提出一种加权LDA模型使其能对带权特征词进行同样的建模与求解,同时由于特征词被赋予了不同权重,所以也提高了LDA模型本身的精度和准确性。
Automatic Classification of Documents from Wikipedia [J].
随着互联网的逐渐普及,这些新兴的网络文本资源以极快的速度增长,这导致传统的手工分类方法由于效率较低,难以及时、有效地对这些网络数字资源进行合理地分类管理,因此必须利用自动文本分类技术来对其进行分类组织。而当前的自动文本分类技术往往研究的是针对来自同种文献类型的文本资源,而数字图书馆作为一种新型图书馆,其面临的待分类整理的文献来自图书、期刊、网页等等多种领域且属于多种类型,目前针对多种文献类型的自动分类研究还有待完善,所以研究改进针对多种文献类型的自动分类算法对数字图书馆的成长与发展能起到显著的推动作用。本文通过介绍与分析当前文本分类方面的相关研究及主要技术,提出了一种通过基于维基百科的特征扩展来提高针对不同类型文献分类效果的分类方法。针对由不同文献类型所造成的特征不匹配问题,本文认为通过第三方语料库可以有效地将原本不匹配的特征词进行关联,从而解决在特征词不匹配的情形下无法对不同类型文本间进行语义相关度计算的问题。一方面可以丰富当前待分类文本的语义特征,与由不同类型文献训练来得到的分类器产生相匹配特征,同时还可以解决在文本分类问题中普遍存在的特征稀疏等问题。本文主要进行的研究内容如下:(1)本文以互联网上的文本内容爆炸式增长为背景,论述未来数字图书馆面对以几何级数增加的网络文本分类管理困难的问题,引出了多种类型文献自动分类技术研究的必要性。继而本文提出的通过特征扩展解决上述问题的思路,并通过论述与分析当前相关研究的成果与进展来论证本文提出的文本分类方法的可行性与适用性。(2)本研究提出了一种基于特征扩展的多种类型文献文本分类方法,其中特征扩展操作是消除不同类型文献自动分类时文本间语义差异的核心步骤。而在进行特征扩展前需要从训练文本中提取一部分特征词作为特征扩展候选词集。本研究在论述传统特征选择方法的不足并举例说明其缺点的基础上,继而提出对其进行改进的原理与方法,并通过计算表明新的特征选择方法确实能解决原有不足。最后,本文使用改进的特征选择方法进行特征扩展候选词集的提取,并通过实验对比证明该方法的有效性。(3)为解决对不同类型文献间进行自动分类时遇到的特征不匹配等问题,本文提出一种基于特征扩展的文本分类方法,使用维基百科计算的语义相关度来准确衡量特征词之间的相关程度。在对待分类文本完成特征扩展之后,本文使用LDA主题模型对数据进行表示建模,但传统的LDA模型不能正常地对带权特征词进行建模,故而本文又对LDA模型进行改进,提出一种加权LDA模型使其能对带权特征词进行同样的建模与求解,同时由于特征词被赋予了不同权重,所以也提高了LDA模型本身的精度和准确性。
|
| [21] |
Reuters-21578 Text Categorization Collection [DS/OL]. [ |
| [22] |
文本分类(复旦)测试语料 [OL]. [Text Classification Corpus (Fudan) [OL]. [ |
| [23] |
小型中文信息检索测试集的构建与分析 [J].https://doi.org/10.3969/j.issn.1002-1965.2009.01.004 URL [本文引用: 1] 摘要
在国内信息检索研究日益受到重 视的背景下,介绍了构建小型中文测试集的意义及测试集的研究现状。参考国外测试集的构建经验,论述了小型中文信息检索测试集的构建方法,实现了一个可应用 于信息检索研究的小型中文测试集。通过有效的统计分析,结果表明本测试集具有较高的可信度。
Small Chinese Information Retrieval Test Collections: Construction and Analysis [J].https://doi.org/10.3969/j.issn.1002-1965.2009.01.004 URL [本文引用: 1] 摘要
在国内信息检索研究日益受到重 视的背景下,介绍了构建小型中文测试集的意义及测试集的研究现状。参考国外测试集的构建经验,论述了小型中文信息检索测试集的构建方法,实现了一个可应用 于信息检索研究的小型中文测试集。通过有效的统计分析,结果表明本测试集具有较高的可信度。
|

/
| 〈 |
|
〉 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}