操玮, 李灿 , 贺婷婷, 朱卫东
, 贺婷婷, 朱卫东
合肥工业大学经济学院 合肥 230601
Cao Wei, Li Can, He Tingting, Zhu Weidong
中图分类号: F832.4 G35
通讯作者:
收稿日期: 2018-01-9
修回日期: 2018-01-9
网络出版日期: 2018-10-25
版权声明: 2018 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】结合实际的中国网贷数据, 通过对不同流行集成方法的对比分析, 探索合适中国网贷信用风险监测的集成方法, 从而提高对中国网贷平台信用风险的监测效率。【方法】基于人人贷交易数据, 从借款人的5个方面提取特征信息并运用随机森林算法进行特征筛选, 基于此运用4种集成算法和5种基分类器, 构建信用风险预警模型实现对比分析。【结果】实验结果表明, Rotation Forest的准确度最高为99.32%, 误差率仅为1.71%。而且基于随机森林的特征选择过程能够提高相关模型的性能。【局限】实验数据集有待进一步扩充。【结论】Rotation Forest集成模型与识别风险的重要因素结合, 可以显著提高信用风险预测效率。
关键词:
Abstract
[Objective] This paper examines several popular ensemble-learning methods with real-world data, aiming to find the most suitable way to monitor the P2P credit risks facing China. [Methods] We extracted the borrower’s features from five aspects, and identified the most remarkable ones with Random Forest method. Then, we compared the prediction models based on four ensemble-learning methods and five base classifiers. [Results] We found that the Rotation Forest method had the highest accuracy rate of 99.32% and the lowest error rate of 1.71% . Feature selection processing based on Random Forest could improve the performance of all related models significantly. [Limitations] The sample dataset needs to be expanded. [Conclusions] The proposed method could identify credit risks more effectively.
Keywords:
P2P是一种新型的金融服务模式, 依托于互联网而存在, 因为其具有低门槛、高效率的特点而成为重要的金融补充手段。近年来P2P网络借贷行业飞速发展, 平台规模扩大, 行业整体平台数量剧增, 成为拓宽投-融资渠道的重要力量。但是, 由于征信系统不完善、法律法规不健全以及传统借贷业务所没有的互联网风险的影响, 中国P2P网络借贷平台存在严重的资金安全问题, 截至2017年10月底, P2P网络借贷行业正常运营平台数量只有1 975家, 累计停业及问题平台达到3 974家, 累计平台总量(含停业及问题平台)达到5 949家(https://xueqiu.com/9936619624/94775875)。因而如何利用海量的交易数据, 运用数据挖掘技术探索隐藏的信息, 帮助平台监控信用风险, 保障投资者资金安全至关重要。
信用风险的预警技术起步于传统的统计计量方法, 但由于其需要严格的假定条件, 在实际应用中具有局限性。人工智能的发展带来了不需要严格假定条件的机器学习技术, 出现了如人工神经网络(ANN)[1]、支持向量机(SVM)[2]、决策树(DT)[3]等经典的单个机器学习方法(单分类器)。由于能够融合多个单分类器的结果从而实现“二次学习”, 集成学习方法成为研究的热点, 常见的集成方法有Bagging[4,5,6]、Boosting[7,8,9]、Random Subspace[10]、Rotation Forest[11]等。集成学习模型预测效果往往优于单分类模型(如ANN、SVM等)[12,13,14,15,16], 但通过梳理国内外相关文献可知, 目前尚缺乏对不同集成学习方法的对比研究, 特别是针对中国网络借贷市场而言, 由于网络平台数据的难以获取和复杂性, 相关研究显得较为缺乏。而对集成学习方法适用性的探讨不仅能够更加准确地预警网络借贷信用风险, 也能进一步深入理解和监控中国网络借贷信用风险, 是一个非常重要但又尚未解决的问题。
综上, 为解决相关问题, 本文使用Python编写网络爬虫程序获取国内最大的网络借贷平台——人人贷中73 394条的交易数据, 基于5种经典的基分类器逻辑回归(LR)、CART、C4.5、多层感知神经网络(MLP)、支持向量机(SVM), 对比分析在前期研究中表现较好的4种集成学习模型(Bagging、Boosting、Random Subspace和Rotation Forest), 并对模型结果进行非参数统计检验, 以期探索适合中国网贷平台的最优信用风险预警模型。研究的创新点主要表现在:
(1) 在现有研究多数关注集成学习方法与单个机器学习模型对比分析的基础上, 创新对比分析了不同集成学习方法在特定网络借贷数据集上的预警表现;
(2) 从多个维度选取和挖掘中国网络借贷平台的实际大数据, 探讨不同集成学习方法的适用性问题;
(3) 运用随机森林的特征选择方法, 实现对多维数据的有效降维, 找出影响网络借贷信用风险的重要因素, 为深入理解和监控中国网络借贷信用风险提供参考。
本研究基于中国网络借贷平台的实际数据, 能够贴合中国的实际情况, 研究结果能够为大数据环境下监控网络借贷平台信用风险提供借鉴, 具有一定的理论和现实意义。
信用风险预警模型构建的方法主要有以下两 大类:
(1) 统计计量方法。通过构建统计模型描述风险预警问题中的函数关系, 从而实现风险评估的量化分析。早期Altman将多元判别分析运用到企业财务评估问题的研究中, 构建Z-score模型[17]。多元判别分析的运用需要自变量满足两个假设条件: 服从正态分布和协方差矩阵相等, 而实际函数关系往往很难满足。随后学者引入逻辑回归等方法研究风险评估问题[18,19], 但现实数据情况仍难以满足其相关先验条件, 具有局限性。
(2) 机器学习方法。随着人工智能的发展, 不需要先验假设的机器学习方法开始被广泛运用, 其中经典的方法包括ANN、SVM和决策树等。如Hens等结合SVM和分层随机抽样优化信用评分的计算过程, 准确率达86.76%[20]; Zhao等基于MLP构建反向传播人工神经网络用于信用评分, 准确率达92%[21]; 余华银等以529家网贷平台为研究对象, 运用决策树和逻辑回归建立信用风险评价模型, 结果表明决策树的预测能力相对更优, 误判率为20%[22]。但由于自身特点不同, 单个机器学习模型在不同研究数据上的表现具有差异性[2,22-23], 机器学习模型的稳健性成为一个需要解决的问题。
近年, 由于能够融合多个基分类器(单个机器学习模型)进行综合分析, 集成学习方法开始成为研究的热点。如Nanni等结合日本、澳大利亚和德国的信用数据, 运用Random Subspace、Bagging、Class Switching和Rotation Forest构建集成学习模型研究银行信用评估问题[16]; Abellán等基于日本、澳大利亚和德国的信用数据进行实证分析, 结果证明了Bagging集成方法的优越性[24]; Abellán等基于6个国家的实际信用数据, 引入5种集成学习方法(Bagging、Boosting、Random Subspace、DECORATE、Rotation Forest)构建信用风险评估模型, 结果表明与单个模型相比, 集成学习模 型具有更强的预警能力和稳健性[11]。类似的研究还 有Tsai等、Bequé等、Ala'raj等和Florez-Lopez等的研究[25,26,27,28]。
综上, 可以发现:
(1) 与传统的统计计量分析方法相比, 机器学习方法在信用风险预警问题上表现出优越性, 运用机器学习方法解决信用风险预警问题是合理、有效的方案;
(2) 众多机器学习方法中, 集成学习方法要优于单个机器学习模型, 但不同的集成学习方法中, 到底哪种集成学习方法最适用于信用风险预警仍是一个尚未解决的问题。
已有研究多是关注单个分类器模型的应用或是集成学习方法与单个模型的对比分析, 尚缺乏对多个集成学习方法的对比研究。另外, 已有研究的数据对象多是国外信用数据, 但由于中国P2P网贷信用风险问题与国外相比具有显著异质性, 不同集成算法在中国网贷信用风险问题上的表现亟需进一步探索, 而这又需要结合网贷平台的实际大数据进行分析, 国内网络平台数据的难获取性, 使得目前国内相关研究稍显不足。因此, 本文在已有研究的基础上, 运用Python编写爬虫程序获取国内网贷平台的实际数据, 选取在前期研究中表现较好的4种集成学习方法(Bagging、Boosting、Random Subspace、Rotation Forest)进行对比分析, 找出最适合中国网贷平台的信用风险预警模型, 从而提高相应的风险监控能力, 并在预警设计中加入特征选择过程, 有效提取信用风险影响因素的特征子集, 以便集成分析模型能够快速、高效地预警信用风险。
通过梳理相关文献可以看出, 集成学习可以融合多个单分类器以达到更优的预测效果, 为了进一步对比不同集成学习模型在中国网贷平台上的适用性, 本文选取信用风险预警问题中应用最广泛的监督学习方法LR、CART、C4.5、MLP和SVM建立基分类模 型[29], 在此基础上对比分析在前期研究中表现较好的Boosting, Bagging, Random Subspace和Rotation Forest[11], 探索集成方法在信用风险监测中的适用性。
(1) LR
LR通过极大似然估计的方法建立一个线性可分类模型, 实现对二值或多值分类变量的预测。若将借款人信用风险发生的概率设为P(未发生信用风险的概率为1-P), $P\in [0,1]$, 以P的logit变换为因变量, 建立逻辑回归方程[30], 如公式(1)和公式(2)所示。
$logit\left( P \right)=\ln \left( \frac{P}{1-P} \right)={{\beta }_{0}}+{{\beta }_{1}}{{x}_{1}}+{{\beta }_{2}}{{x}_{2}}+\cdot \cdot \cdot +{{\beta }_{n}}{{x}_{n}}$(1)
可求得: $P=1/(1+{{e}^{-({{\beta }_{0}}+{{\beta }_{1}}{{x}_{1}}+{{\beta }_{2}}{{x}_{2}}+\cdot \cdot \cdot +{{\beta }_{n}}{{x}_{n}})}})$ (2)
其中, xi是自变量, β0是常数且与xi无关, ${{\beta }_{1}},{{\beta }_{2}},\cdot \cdot \cdot ,{{\beta }_{n}}$是回归系数, 代表xi对P的贡献量。LR计算出概率P, 通过设定阈值判定预测借款人的违约状况。
(2) CART
CART[31]由Breiman等提出, 它首先从根节点出发, 采用自上向下的方式按照Gini值在每个节点上选择分支属性, 直至到达能够实现对样本做出分类的叶子节点, Gini值的计算方法[32]如公式(3)所示。
$Gini(t)=1-\sum\nolimits_{i=0}^{y-1}{{{[p(i/t)]}^{2}}}$ (3)
其中, p(i / t)表示节点t中属于i类的样本所占全部样本的比例, y是类别数。
(3) C4.5
C4.5[33]以信息增益比率为属性选取标准, 它从根节点出发对该样本的属性逐步进行测试, 再沿着相应的分支向下行走, 直至到达某个叶节点, 此时叶节点所代表的类型即为该样本的类型[34]。C4.5有时会出现过拟合训练数据集, 产生节点数较多的大树。Kohavi 等发现在许多情况下特征选择可能会导致C4.5产生节点较少的小树[35]。
(4) MLP
为解决单层感知器模型中存在的非线性可分数据的多类别分解问题, Rumehart等提出了MLP[36]。它是一种单向误差逆传播训练的多层前馈网络模型。由输入层、输出层和隐藏层组成, 隐藏层可以是单层也可以是多层。各层中的神经元只与相邻层内的神经元有连接, 层内各神经元无连接。MLP中输入变量向前传播到隐藏层, 经过变换函数后, 将隐藏层的输出传播到输出层, 再输出最终结果。
(5) SVM
SVM[37]旨在属性空间中找到最优分类超平面以实现结构风险最小化。假设存在一个样本点x, 样本点x的类别$y\in \left\{ +1,-1 \right\}$。假设存在一个分隔超平面[38]:
${{H}_{1}}:w\cdot x+b>0$, 对于$y=+1$
${{H}_{2}}:w\cdot x+b\le 0$, 对于$y=-1$
因此, H1平面上方样本的y = +1, H2平面下方样本的$y=-1$。满足等式成立的样本称之为支持向量, 即H1平面上和H2平面上的样本。
(1) Boosting
AdaBoost是Boosting[39]中最优秀的算法之一, 能够降低数据随机性波动导致的泛化错误率, 具 有较强的泛化能力[40]。AdaBoost首先给样本$({{x}_{1}},{{y}_{1}}),({{x}_{2}},{{y}_{2}}),\cdot \cdot \cdot ,({{x}_{n}},{{y}_{n}})$赋予相等的权值1/n; 然后引入分类算法构建分类模型; 同时不断更新样本的权值, 提高被错判样本的权值, 降低被正确判断样本的权值, 使得模型更好地处理难分类的样本。重复迭代T次后得到预测函数${{f}_{1}},{{f}_{2}},\cdot \cdot \cdot ,{{f}_{T}}$, 预测函数的权值计算依据其预测效果的优劣, 预测效果越好权值越大, 反之越小。最终分类结果由${{f}_{1}},{{f}_{2}},\cdot \cdot \cdot ,{{f}_{T}}$的输出结果的加权投票决定。AdaBoost可能会使模型过分偏向于某些错判样本, 容易导致过拟合有噪声的训练数据, 稳定性较差。
(2) Bagging
Bagging[41]算法通过从训练集X中随机可放回抽取n个样本, 产生的子训练集(其样本空间小于X), 并在子训练集上构建基分类器, 重复抽取k次得到k个基分类器, 票选基分类器结果中最多的类作为Bagging模型输出。Breiman[41]指出稳定性是Bagging能否发挥作用的关键因素, Bagging能够显著提高不稳定学习算法的预测精度, 而对稳定的学习算法效果不明显, 甚至有时发生准确度降低的情形, Bagging更适用于高方差低偏差的不稳定学习模型。
(3) Random Subspace
Random Subspace[42]首先对训练集X的n个属性$({{f}_{1}}\mathrm{,}{{f}_{2}}\mathrm{,}\cdot \cdot \cdot {{f}_{n}})$进行随机抽取, 重复k次, 得到k个子属性集$({{f}_{1}}\mathrm{,}{{f}_{2}}\mathrm{,}\cdot \cdot \cdot {{f}_{k}})$, 然后运用分类算法对k个子属性集进行训练, 得到k个基分类器, 最后组合基分类模型的输出, 获得Random Subspace模型的输出结果。通过对属性空间的随机抽取, Random Subspace从多个不同角度分析分类问题, 减少了基分类器的输入特征数量, 实现特征空间的降维, 仅适用于处理含有大量冗余特征的数据集, 否则可能导致学习模型性能下降[43]。
(4) Rotation Forest
Rotation Forest[44]将属性集$F({{x}_{1}}\mathrm{,}{{x}_{2}}\mathrm{,}\cdot \cdot \cdot {{x}_{n}})$随机划分为k个子属性集$({{f}_{1}}\mathrm{,}{{f}_{2}}\mathrm{,}\cdot \cdot \cdot \mathrm{,}{{f}_{k}})$, 每个子属性集中有n/k个属性, 运用Bootstrap的方式从总体样本中提取数据, 并对k个子集分别运用主成分分析(PCA)进行特征变换, 得到新的样本数据xnew, 将xnew作为模型学习的输入变量, 整合各个基分类模型的结果, 输出最终预测结果。Rotation Forest随机分割属性集, 运用PCA提取主成分, 保留了原数据的全部或大部分信息, 不会造成数据信息丢失。这种处理方式增加了子集之间的差异性, 也起到数据预处理作用, 提高了基分类器的差异性和准确性。
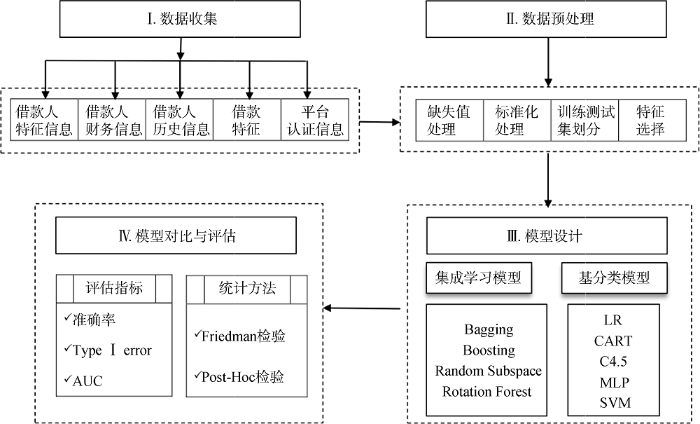
P2P网络借贷信用风险预警的研究过程主要分为4个阶段: 数据收集; 数据预处理; 模型设计; 模型对比与评估。模型设计路线如图1所示。
本文采用Python编写网络爬虫程序, 对人人贷平台借款客户ID为719578-793000的借贷标的信息进行提取, 获得借贷数据①(①https:www.we.com/lend/ detailPage.), 共收集73 394条数据, 其中违约样本总数为1 174, 非违约样本总数为72 220。数据集包含28个变量, 包括借款人的特征信息及其财务信息、历史信息、借款特征、平台认证信息等, 如表1所示。
表1 变量说明
| 变量类型 | 变量名 | 实际含义 | 变量数值化 |
|---|---|---|---|
| 因变量 | label | 借款违约与否 | 违约=1, 未违约=0 |
| 借款人特征信息 | F1 | 年龄 | 20-25岁=0, 26-31岁=1, 32-37岁=2, 38-43岁=3, 44-49岁=4, 50岁及以上=5 |
| F2 | 学历 | 高中及以下=0, 大专=1, 本科=2, 研究生=3 | |
| F3 | 婚姻状况 | 单身(包括未婚、离异和丧偶)=0, 已婚=1 | |
| F4 | 工作时间 | 空值=0, 1年及以下=2, 1-3年(含)=4, 3-5年(含)=6, 5年以上=8 | |
| F5 | 工作城市 | 东部=0, 中部=1, 西部=2 | |
| F6 | 公司行业 | 借款人所在公司所属行业* | |
| F7 | 公司规模 | 空值=0, 10人以下=1, 10-100人=2, 100-500人=3, 500人以上=4 | |
| 借款人财务信息 | F8 | 收入 | 1000元以下=0, 1000-2000元=1, 2000-5000元=2, 5000-1000元=3, 10000=20000元=4, 20000-50000元=5, 50000元以上=6 |
| F9 | 信用等级 | HR=0, E=1, D=2, C=3, B=4, A=5, AA=6 | |
| F10 | 信用额度 | 信用额度做Min-Max标准化处理 | |
| F11 | 房产 | 有房产=1, 无房产=0 | |
| F12 | 车产 | 有车产=1, 无车产=0 | |
| F13 | 房贷 | 无房贷=1, 有房贷=0 | |
| F14 | 车贷 | 无车贷=1, 有车贷=0 | |
| 借款人历史信息 | F15 | 成功借款 | 借款人成功借款数量 |
| F16 | 申请借款 | 借款人历史申请借款笔数 | |
| F17 | 逾期次数 | 借款人历史逾期次数 | |
| F18 | 严重逾期 | 存在严重逾期=1, 否则=0 | |
| 借款特征 | F19 | 借款金额 | 借款人预期借款金额做Min-Max标准化处理 |
| F20 | 用途 | 借款人的借款用途** | |
| F21 | 利率 | 借款年利率 | |
| F22 | 还款期限 | 借款期限, 按月衡量, 最短3个月, 最长36个月 | |
| F23 | 标的类型 | 机构担保标=0, 信用认证标=1, 实地认证标=2 | |
| 平台认证 信息 | F24 | 信用认证 | 借款人提供央行开具的个人征信报告, 认证通过=1, 其他=0 |
| F25 | 身份认证 | 借款人提供身份证复印件认证身份信息, 认证通过=1, 其他=0 | |
| F26 | 工作认证 | 借款人提供工作证复印件或劳动合同, 认证通过=1, 其他=0 | |
| F27 | 收入认证 | 借款人提供收入证明或工资卡银行流水, 认证通过=1, 其他=0 |
(1) 缺失值处理。已收集借款信息中存在缺失数据, 为避免缺失值对实证分析的影响, 必须对缺失值进行处理。公司行业、借款用途、公司规模和工作时间中存在的缺失值, 经分析决定将缺失信息赋值为0, 其余变量若存在缺失值, 则删除该样本。本研究不考虑已流标, 删除标的状态为已流标的数据, 最终得到34 072条数据, 违约样本总数为474, 非违约样本总数为33 598。
(2) 数据标准化。逾期次数为0的标记为0, 逾 期次数大于0的标记为1, 作为衡量是否违约的分 类变量。对变量做离散化处理, 对信用额度和借款金额做$\text{Min}-\text{Max}$标准化处理: ${{X}_{new}}=(X-\min (X))/$ $(\max (X)-\min (X))$。
(3) 训练测试集。将样本数据随机分为训练组和测试组, 以多个训练测试比(60:40, 70:30, 80:20)对数据进行划分, 防止出现过拟合和欠拟合现象。
(4) 特征选择
为深入了解变量性质, 找到影响信用风险评估的重要因素, 进行特征选择, 促进模型的学习速度, 建立高效模型。本文选择的特征选择方法是运用随机森林度量变量的重要程度, 认为排名前10的变量是重要变量, 将其作为模型的输入变量。随机森林是一个树形分类器的集合, 采用CART算法建立没有剪枝的决策树作为基分类器, 运用Bagging方法生成多个独立的训练数据集, 构造每个基分类器的过程中需要随机地依据某种标准选择特征(属性变量)进行节点分裂。随机森林衡量特征的重要性的标准是: 若给某个特征随机加入噪声之后, 袋外Gini值大幅度下降, 则说明这个特征对于样本的分类结果影响很大, 即它的重要程度比较高, 相应特征重要性度量值为原袋外Gini值与加入噪声后袋外Gini值之差。随机森林参数取值为系统默认值, 得到最优指标体系如表2所示。
表2 特征选择结果
| 变量类型 | 变量 | 含义 |
|---|---|---|
| 借款人特征信息 | F1 | 年龄 |
| F3 | 婚姻状况 | |
| 借款人财务信息 | F9 | 信用等级 |
| F10 | 信用额度 | |
| 借款人历史信息 | F17 | 逾期次数 |
| F18 | 严重逾期 | |
| 借款特征 | F19 | 借款金额 |
| F22 | 还款期限 | |
| 平台认证信息 | F26 | 工作认证 |
| F27 | 收入认证 |
本实验目的是分析不同集成学习算法的预测性能以及基分类器对集成预警性能的影响。选择的集成学习算法是Bagging、Boosting、Random Subspace和Rotation Forest, 基分类器是LR、CART、C4.5、MLP和SVM。实际上, 将比较20个不同的集成学习模型。实验设计是通过Weka软件实现, C4.5由Weka实现, 其余模型使用Weka提供的默认配置。根据Abellán等的研究[11], 确定参数设置。本文采用10次交叉验证, 将10次实验的平均结果作为最终结果, 以避免计算误差、提高结果的稳健性。
(1) 评价指标
选择三个评估指标(准确率、 Type-I error和AUC)测度预警模型的性能。对于数据集的每一个测试样本, 模型有4种可能的预测结果, 表3是两分类预警问题的混合矩阵, 根据混合矩阵定义评估指标。
准确率=(TP+TN)/(TP+FN+FP+TN)。准确率为违约样本和未违约样本被正确预测的样本总数占总样本数的比率, 比率越大则模型的性能越好。
Type-I error=FN/(TP+FN)。Type-I error是违约样本中被误判为未违约的比率。相较于非违约样本被误判为违约, 违约样本被误判为未违约会导致更大的损失。Type-I error是衡量误判损失的重要评估指标。
AUC(Area Under roc Curve )是衡量非平衡分类模型性能的主流方法。它反映模型在不同阈值时真正率 ($\frac{TP}{TP+FN}$)和负正率($\frac{FP}{FP+TN}$)的关系。AUC的取值范围为[0,1], AUC越接近于1, 预测模型的性能越好。
(2) 统计评价方法
根据Demšar的研究[45], 本文采用Friedman检验(也称为弗里德曼双向评秩方差分析)比较不同模型的准确性有无显著差异。Friedman检验是一种非参数检验方法, 根据数据集对每种分类模型进行排序, 表现最好的等级为1, 较次的等级为2, 以此类推。Friedman检验的统计量服从自由度为n-1的卡方分布, 检验统计量为:
$\chi _{F}^{2}=\frac{12m}{n(n+1)}[\underset{j}{\mathop \sum }\,{{(\underset{i}{\mathop \sum }\,r_{i}^{j})}^{2}}-\frac{n{{(n+1)}^{2}}}{4}]$
其中, n为模型的个数, m为样本数。原假设H0:所有模型没有显著差异。备择假设H1:模型存在显著差异。Friedman检验只能检验所有模型的整体差异性, 无法实现某个模型与其余模型的比较。当原假设被拒绝时, 运用Post-Hoc 检验对多个模型进行两两比较。Bonferroni-Dunn检验用于比较所有模型与某模型的差异[11]。根据Bonferroni-Dunn检验, 如果两个或多个模型的准确率显著不同, 那么它们之间的排名差值至少要大于下面的临界值:
$CD={{q}_{\alpha ,\infty ,n}}\sqrt{\frac{n(n+1)}{m}}$
其中, ${{q}_{\alpha ,\infty ,n}}$为Bonferroni-Dunn检验在相应的显著性水平下的临界值。
根据随机森林计算出的变量Gini系数下降量, 选取Gini系数下降量最大的前10个变量(见表2)和全部变量分别为输入变量, 分析20个集成学习模型的预测性能, 结果如表4-表8所示。其中A表示模型的输入变量为收集的全部变量, FS表示模型的输入变量为特征选择后的重要变量, 下文以A、FS表示模型输入变量的性质。
表4 根据三个指标的集成模型准确性评估 (训练测试比为60:40)
| 集成算法 | 基分类器 | 准确率(%) | Type-I error (%) | AUC | |||
|---|---|---|---|---|---|---|---|
| A | FS | A | FS | A | FS | ||
| Bagging | LR | 97.17 | 98.79 | 7.47 | 6.71 | 0.987 | 0.989 |
| CART | 98.08 | 98.58 | 6.32 | 2.87 | 0.936 | 0.999 | |
| C4.5 | 97.67 | 98.28 | 6.90 | 2.87 | 0.949 | 0.998 | |
| MLP | 96.06 | 98.08 | 10.92 | 8.05 | 0.988 | 0.998 | |
| SVM | 97.47 | 97.97 | 9.20 | 6.32 | 0.973 | 0.995 | |
| Boosting | LR | 97.98 | 98.48 | 5.74 | 3.45 | 0.984 | 0.898 |
| CART | 97.17 | 98.88 | 6.32 | 5.17 | 0.983 | 0.994 | |
| C4.5 | 97.17 | 98.07 | 5.17 | 4.02 | 0.995 | 0.996 | |
| MLP | 97.27 | 98.88 | 8.05 | 2.30 | 0.995 | 0.999 | |
| SVM | 97.97 | 98.28 | 8.62 | 4.59 | 0.954 | 0.971 | |
| Random Subspace | LR | 95.55 | 97.27 | 15.52 | 8.05 | 0.984 | 0.996 |
| CART | 96.46 | 97.17 | 4.59 | 2.87 | 0.940 | 0.981 | |
| C4.5 | 95.05 | 98.07 | 6.32 | 4.02 | 0.961 | 0.994 | |
| MLP | 95.45 | 97.67 | 8.62 | 7.47 | 0.965 | 0.997 | |
| SVM | 96.87 | 97.37 | 9.77 | 7.47 | 0.955 | 0.963 | |
| Rotation Forest | LR | 98.68 | 99.69 | 3.45 | 0.57 | 0.998 | 1.000 |
| CART | 98.48 | 99.19 | 3.45 | 1.15 | 0.992 | 0.998 | |
| C4.5 | 97.97 | 98.99 | 6.90 | 5.17 | 0.954 | 0.996 | |
| MLP | 98.07 | 99.29 | 6.32 | 1.15 | 0.997 | 1.000 | |
| SVM | 98.78 | 99.79 | 4.59 | 0.00 | 0.975 | 0.999 | |
表5 根据三个指标的集成模型准确性评估 (训练测试比为70:30)
| 集成算法 | 基分类器 | 准确率(%) | Type-I error (%) | AUC | |||
|---|---|---|---|---|---|---|---|
| A | FS | A | FS | A | FS | ||
| Bagging | LR | 98.65 | 99.46 | 6.03 | 2.59 | 0.990 | 0.998 |
| CART | 97.71 | 98.65 | 6.03 | 5.17 | 0.977 | 0.996 | |
| C4.5 | 97.71 | 98.65 | 12.93 | 5.17 | 0.992 | 0.998 | |
| MLP | 96.36 | 98.38 | 10.34 | 5.17 | 0.992 | 0.998 | |
| SVM | 98.52 | 98.92 | 5.17 | 1.72 | 0.974 | 0.994 | |
| Boosting | LR | 97.98 | 98.48 | 5.74 | 3.45 | 0.984 | 0.898 |
| CART | 97.71 | 99.59 | 5.17 | 1.72 | 0.984 | 0.999 | |
| C4.5 | 97.30 | 98.38 | 6.03 | 3.45 | 0.981 | 0.997 | |
| MLP | 97.30 | 99.32 | 7.76 | 3.44 | 0.996 | 0.999 | |
| SVM | 98.52 | 98.65 | 4.31 | 2.59 | 0.974 | 0.981 | |
| Random Subspace | LR | 97.71 | 98.79 | 7.41 | 4.31 | 0.988 | 0.994 |
| CART | 96.23 | 97.04 | 12.93 | 5.17 | 0.975 | 0.976 | |
| C4.5 | 96.36 | 97.57 | 12.07 | 3.45 | 0.957 | 0.997 | |
| MLP | 96.77 | 97.57 | 12.93 | 4.31 | 0.993 | 0.995 | |
| SVM | 97.98 | 98.25 | 7.76 | 4.31 | 0.956 | 0.994 | |
| Rotation Forest | LR | 98.65 | 99.59 | 4.31 | 0.86 | 0.998 | 1.000 |
| CART | 98.11 | 98.65 | 3.44 | 1.72 | 0.993 | 0.995 | |
| C4.5 | 98.65 | 99.05 | 6.03 | 3.45 | 0.985 | 0.999 | |
| MLP | 97.84 | 99.46 | 7.76 | 2.59 | 0.995 | 0.999 | |
| SVM | 98.92 | 99.73 | 4.31 | 1.72 | 0.976 | 1.000 | |
表6 根据三个指标的集成模型准确性评估 (训练测试比为80:20)
| 集成算法 | 基分类器 | 准确率(%) | Type-I error (%) | AUC | |||
|---|---|---|---|---|---|---|---|
| A | FS | A | FS | A | FS | ||
| Bagging | LR | 97.17 | 98.99 | 7.32 | 4.90 | 0.962 | 0.990 |
| CART | 97.17 | 98.78 | 8.53 | 6.09 | 0.968 | 0.994 | |
| C4.5 | 97.57 | 98.58 | 9.76 | 4.90 | 0.995 | 0.997 | |
| MLP | 96.56 | 98.79 | 8.53 | 6.09 | 0.989 | 0.985 | |
| SVM | 96.37 | 98.38 | 9.76 | 3.66 | 0.976 | 0.986 | |
| Boosting | LR | 96.56 | 97.57 | 13.41 | 6.09 | 0.966 | 0.995 |
| CART | 97.37 | 97.77 | 8.53 | 3.66 | 0.995 | 0.997 | |
| C4.5 | 95.14 | 97.36 | 8.53 | 4.90 | 0.972 | 0.980 | |
| MLP | 97.37 | 98.58 | 9.76 | 6.09 | 0.993 | 0.996 | |
| SVM | 97.37 | 98.18 | 7.32 | 3.66 | 0.982 | 0.990 | |
| Random Subspace | LR | 94.13 | 97.36 | 20.73 | 8.53 | 0.966 | 0.994 |
| CART | 96.56 | 96.96 | 14.63 | 9.76 | 0.940 | 0.997 | |
| C4.5 | 96.56 | 97.16 | 12.20 | 10.98 | 0.964 | 0.975 | |
| MLP | 95.95 | 97.97 | 8.53 | 7.32 | 0.968 | 0.991 | |
| SVM | 96.56 | 97.77 | 14.63 | 9.76 | 0.967 | 0.983 | |
| Rotation Forest | LR | 98.38 | 99.39 | 6.09 | 1.20 | 0.994 | 1.000 |
| CART | 97.57 | 99.19 | 6.09 | 1.20 | 0.992 | 0.996 | |
| C4.5 | 97.57 | 99.19 | 7.32 | 1.20 | 0.981 | 0.998 | |
| MLP | 98.38 | 99.19 | 7.32 | 2.44 | 0.992 | 1.000 | |
| SVM | 98.58 | 99.39 | 6.09 | 1.20 | 0.981 | 1.000 | |
表7 平均准确率(%)
| 训练 测试比 | Bagging | Boosting | Random Subspace | Rotation Forest | ||||
|---|---|---|---|---|---|---|---|---|
| A | FS | A | FS | A | FS | A | FS | |
| 60:40 | 97.29 | 98.34 | 97.51 | 98.52 | 95.88 | 97.51 | 98.40 | 99.39 |
| 70:30 | 97.79 | 98.81 | 97.71 | 98.92 | 97.01 | 97.84 | 98.43 | 99.30 |
| 80:20 | 96.97 | 98.70 | 96.76 | 97.89 | 95.95 | 97.44 | 98.10 | 99.27 |
| 平均值 | 97.35 | 98.62 | 97.32 | 98.44 | 96.27 | 97.60 | 98.31 | 99.32 |
表8 平均Type-I error(%)
| 训练 测试比 | Bagging | Boosting | Random Subspace | Rotation Forest | ||||
|---|---|---|---|---|---|---|---|---|
| A | FS | A | FS | A | FS | A | FS | |
| 60:40 | 8.16 | 5.36 | 6.78 | 3.91 | 8.96 | 5.98 | 4.94 | 1.61 |
| 70:30 | 8.10 | 4.00 | 7.24 | 3.27 | 10.62 | 4.31 | 5.17 | 2.07 |
| 80:20 | 8.78 | 5.13 | 9.51 | 4.88 | 14.14 | 9.27 | 6.58 | 1.45 |
| 平均值 | 8.35 | 4.82 | 7.84 | 4.02 | 11.24 | 6.52 | 5.56 | 1.71 |
(1) 由表7-表8可知, Rotation Forest组集成模型表现最优。无论是基于特征选择的重要变量还是原始特征集, Rotation Forest的准确性优于其余模型。例如训练测试比为60:40时, Rotation Forest-FS的准确率为99.39%, 高出Random Subspace-FS约1.88%, 其误差率为1.61%, 低于Random Subspace-FS约4.37%。输入变量集为全部变量(A组)的集成学习模型中Rotation Forest-A的准确率为98.40%, 误差率为4.94%, 优于其余A组模型。当训练测试比发生变化时, Rotation Forest的准确率仍显著高于其余模型, 体现出模型的高稳健性。其次是Boosting, 平均准确率最高可达98.44%, 误差率为4.02%。表现最差的是Random Subspace, 平均误差率高达11.24%。
(2) 集成模型的预测效果除了与自身集成策略相关, 另一个重要因素是基分类器。本文选择5种基分类器, LR、CART、C4.5、MLP和SVM。表4-表6的实验结果表明没有适用于所有集成学习模型的最优基分类器, 不同基分类器在不同集成模型中的表现存在差异性。
(3) 在不同的训练测试比下, 随机森林进行特征选择(FS)后的模型性能提升明显。训练测试比为60:40时, Random Subspace-CART的准确率由95.05%提高到98.07%, 误差率由6.32%下降到4.02%。训练测试比为70:30时, Boosting-CART的准确率由97.71%提高到99.59%, 误差率由5.17%下降到1.72%。这是因为利用随机森林特征选择模型分析变量的重要性, 通过深入地掌握变量性质以加快模型的学习速度。从实证结果来看, 特征选择提高了准确率和AUC, 更重要的是能够有效降低分类错误率, 大大提高模型的预测性能。此外, 该实验结果有利于投资者在决策中对借款人相关特征的关注和识别, 提高投资效率。
对准确率和Type-I error运用Friedman计算不同集成模型的平均排名(Friedman得分), 以此为基准进行进一步的对比分析。具体排名情况如表9所示。
表9 模型排名
| 标准 | Bagging | Boosting | Random Subspace | Rotation Forest | ||||
|---|---|---|---|---|---|---|---|---|
| A | FS | A | FS | A | FS | A | FS | |
| 准确率 | 6.00 | 2.67 | 6.33 | 2.50 | 8.00 | 5.67 | 3.83 | 1.00 |
| Type-I error | 6.33 | 3.33 | 6.33 | 2.00 | 8.00 | 5.00 | 4.00 | 1.00 |
Friedman检验已经证实不同模型的准确率和Type-I error存在显著差异性, 运用Bonferroni-Dunn检验进一步分析, 结果如图2所示。图2绘制集成学习模型平均排名, 按照排名的高低排序, 两条水平线分别表示显著性水平0.05和0.1时的CD值。即水平线以上的模型比最优模型显著更差。由图2可以看出, 根据准确率和Type-I error计算平均排名, 基于特征选择(FS)的集成模型显著优于未进行特征选择(A)的模型, FS模型中表现最好的是Rotation Forest-FS, 其次是Boosting-FS和Bagging-FS, 表现最差的是Random- Subspace-FS。A模型中表现最好的是Rotation Forest-A, 其次是Boosting-A和Bagging-A, 表现最差的是Random Subspace-A。这与上一节中的实证分析的结论一致。
根据上述实验结果, Rotation Forest的整体表现显著优于其他模型, Bagging和Boosting的表现差异不大, 预测性能次于Rotation Forest, 最后是Random Subspace。尝试分析出现此情形的可能原因: 本研究考虑到数据集中的缺失值、异常值和不相关特征可能会导致变量分布复杂[46], 使得模型的预测准确性不高, 同时含有较多冗余特征的模型往往计算速度更慢[47]。因此, 首先对原始样本数据进行预处理, 解决数据中缺失值问题, 运用分段赋值和归一化处理降低异常点对模型的影响, 其次运用随机森林进行特征选择实现冗余特征消减, 得到样本量充足、数据质量较高且特征维度较低的实验数据。在此情形下, 善于处理含有大量冗余特征问题的Random Subspace和能够显著提高不稳定学习算法的预测精度的Bagging很难发挥算法的优势, 集成效果较不显著。相反, Rotation Forest算法在数据质量较高、特征变量维度较低的问题中, 综合运用旋转变换思想和Bootstrap抽样方式, 使得模型中基分类器间的差异性更加显著, 最终获得更好的集成效果, 这是其优于其他集成学习方法的主要原因。
本文结合中国网贷平台的实际大数据, 对比分析不同集成方法在中国网贷平台信用风险预警问题上的适用性。首先运用随机森林构建特征选择模型, 通过特征排序和筛选分析, 从众多影响因素中找到10个重要因素作为后续模型的输入, 在此基础上采用评估指标(准确率、Type-I error和AUC)和Friedman统计检验方法对比4种集成学习模型(包含5种基分类器)的表现。研究结果表明Rotation Forest集成模型的预警能力要高于其余三种集成学习模型, 相对更适用于中国网贷信用风险分析, 这可能和Rotation Forest算法能够增加样本差异化的优势有关。另外, 研究结果表明通过随机森林的特征筛选能够降低模型复杂度, 加快模型的学习速度, 选择出的重要特征能够提升相关模型的预警能力。实证结果证明研究方案设计的有效性, 为中国网络借贷借款人信用风险评估提供了较为可靠的方法, 也为进一步的风险监控提供参考。
本文的局限在于: 在样本选择上仅采用一家P2P平台的数据为研究对象。由于P2P平台的数据不易获得, 且每家P2P平台披露的信息有一定差异, 不同P2P平台难以在变量选择上进行统一。
后续研究将完善: 经济发展水平对借款者发生违约的概率存在影响, 考虑引入反映宏观经济水平的变量; 扩大样本数量, 构建更复杂、更智能的领先信用风险识别模型, 如利用深度学习算法进行建模等。
操玮, 李灿, 朱卫东: 提出研究思路, 设计研究方案;
操玮, 李灿: 采集、清洗和分析数据, 程序设计;
李灿: 论文起草;
操玮, 李灿, 贺婷婷: 论文最终版本修订。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: lc2016314@163.com。
[1] 操玮, 李灿. Borrower.xlsx. 从人人贷平台抓取借贷标的信息的原始数据集.
[2] 操玮, 李灿. Borrower_data.xlsx. 数据预处理后的数据集.
[3] 操玮, 李灿. data_FS.xlsx. 经过特征选择后仅含有重要特征的数据集.
[4] 操玮, 李灿. train_0.6.csv. 训练集数据(训练测试比为60:40).
[5] 操玮, 李灿. test_0.6.csv. 测试集数据(训练测试比为60:40).
[6] 操玮, 李灿. train_0.7.csv. 训练集数据(训练测试比为70: 30) .
[7] 操玮, 李灿. test_0.7.csv. 测试集数据(训练测试比为70:30).
[8] 操玮, 李灿. train_0.8.csv. 训练集数据(训练测试比为80:20).
[9] 操玮, 李灿. test_0.8.csv. 测试集数据(训练测试比为80:20).
| [1] |
Early Warning Models Against Bankruptcy Risk for Central European and Latin American Enterprises [J].https://doi.org/10.1016/j.econmod.2012.11.017 URL [本文引用: 1] 摘要
78 The paper examines the relationship between financial development and energy use. 78 We find that the impact of financial development on energy use is positive. 78 The feedback effect exists between financial development and energy consumption.
|
| [2] |
基于BP神经网络和SVM的个人信用评估比较研究[D] .The Comparative Research of Personal Credit Assessment Model Based on BP Neural Network and SVM[D] . |
| [3] |
The Use of Profit Scoring as an Alternative to Credit Scoring Systems in Peer-to-Peer (P2P) Lending [J].https://doi.org/10.1016/j.dss.2016.06.014 URL [本文引用: 1] 摘要
This study goes beyond peer-to-peer (P2P) lending credit scoring systems by proposing a profit scoring. Credit scoring systems estimate loan default probability. Although failed borrowers do not reimburse the entire loan, certain amounts may be recovered. Moreover, the riskiest types of loans possess a high probability of default, but they also pay high interest rates that can compensate for delinquent loans. Unlike prior studies, which generally seek to determine the probability of default, we focus on predicting the expected profitability of investing in P2P loans, measured by the internal rate of return. Overall, 40,901 P2P loans are examined in this study. Factors that determine loan profitability are analyzed, finding that these factors differ from factors that determine the probability of default. The results show that P2P lending is not currently a fully efficient market. This means that data mining techniques are able to identify the most profitable loans, or in financial jargon, eat the market. In the analyzed sample, it is found that a lender selecting loans by applying a profit scoring system using multivariate regression outperforms the results obtained by using a traditional credit scoring system, based on logistic regression.
|
| [4] |
A Feature Selection Enabled Hybrid-Bagging Algorithm for Credit Risk Evaluation [J].https://doi.org/10.1111/exsy.12217 URL [本文引用: 1] 摘要
react-text: 353 In credit risk evaluation the accuracy of a classifier is very significant for classifying the high-risk loan applicants correctly. Feature selection is one way of improving the accuracy of a classifier. It provides the classifier with important and relevant features for model development. This study uses the ensemble of multiple feature ranking techniques for feature selection of credit data.... /react-text react-text: 354 /react-text [Show full abstract]
|
| [5] |
A Novel Heterogeneous Ensemble Credit Scoring Model Based on Stacking Approach [J].https://doi.org/10.1016/j.eswa.2017.10.022 URL [本文引用: 1] |
| [6] |
Imbalanced Enterprise Credit Evaluation with DTE-SBD: Decision Tree Ensemble Based on SMOTE and Bagging with Differentiated Sampling Rates [J].https://doi.org/10.1016/j.ins.2017.10.017 URL [本文引用: 1] |
| [7] |
Comparison of Individual, Ensemble and Integrated Ensemble Machine Learning Methods to Predict China’s SME Credit Risk in Supply Chain Finance [J]. |
| [8] |
A Novel Ensemble Method for Credit Scoring: Adaption of Different Imbalance Ratios [J].https://doi.org/10.1016/j.eswa.2018.01.012 URL [本文引用: 1] 摘要
In the past few decades, credit scoring has become an increasing concern for financial institutions and is currently a popular topic of research. This study aims to generate a novel ensemble model for credit scoring, to obtain superior performance and high robustness, adapting to different imbalance ratio datasets. First, according to the credit scoring data characteristics, the proposed model extends the BalanceCascade approach to generate adjustable balanced subsets based on the imbalance ratios of training data. Further, it reduces the negative effect of imbalanced data and improves the comprehensive performance of the predictive model. Second, the proposed model adopts two kinds of tree-based classifiers, random forest and extreme gradient boosting, as the base classifiers for a three-stage ensemble model. This includes the use of stacking to generate predicted results of the former layer as new explanatory features in the latter layer, and the use of a particle swarm optimization algorithm for parameters optimization of the base classifiers. Finally, the results indicate that the average performance of the proposed model is superior to other comparative algorithms as reflected in most evaluation measures for different datasets. It demonstrates that the proposed model is robust and represents a positive development in credit scoring.
|
| [9] |
A Novel Ensemble Method for Classifying Imbalanced Data [J].https://doi.org/10.1016/j.patcog.2014.11.014 URL [本文引用: 1] 摘要
61We propose a novel ensemble method to handle imbalanced binary data.61The method turns imbalanced data learning into multiple balanced data learning.61Our method usually performs better than the conventional methods on imbalanced data.
|
| [10] |
Ensemble Classification Based on Supervised Clustering for Credit Scoring [J].https://doi.org/10.1016/j.asoc.2016.02.022 URL [本文引用: 1] 摘要
Credit scoring aims to assess the risk associated with lending to individual consumers. Recently, ensemble classification methodology has become popular in this field. However, most researches utilize random sampling to generate training subsets for constructing the base classifiers. Therefore, their diversity is not guaranteed, which may lead to a degradation of overall classification performance. In this paper, we propose an ensemble classification approach based on supervised clustering for credit scoring. In the proposed approach, supervised clustering is employed to partition the data samples of each class into a number of clusters. Clusters from different classes are then pairwise combined to form a number of training subsets. In each training subset, a specific base classifier is constructed. For a sample whose class label needs to be predicted, the outputs of these base classifiers are combined by weighted voting. The weight associated with a base classifier is determined by its classification performance in the neighborhood of the sample. In the experimental study, two benchmark credit data sets are adopted for performance evaluation, and an industrial case study is conducted. The results show that compared to other ensemble classification methods, the proposed approach is able to generate base classifiers with higher diversity and local accuracy, and improve the accuracy of credit scoring.
|
| [11] |
A Comparative Study on Base Classifiers in Ensemble Method for Credit Scoring [J].https://doi.org/10.1016/j.eswa.2016.12.020 URL [本文引用: 5] 摘要
In the last years, the application of artificial intelligence methods on credit risk assessment has meant an improvement over classic methods. Small improvements in the systems about credit scoring and bankruptcy prediction can suppose great profits. Then, any improvement represents a high interest to banks and financial institutions. Recent works show that ensembles of classifiers achieve the better results for this kind of tasks. In this paper, it is extended a previous work about the selection of the best base classifier used in ensembles on credit data sets. It is shown that a very simple base classifier, based on imprecise probabilities and uncertainty measures, attains a better trade-off among some aspects of interest for this type of studies such as accuracy and area under ROC curve (AUC). The AUC measure can be considered as a more appropriate measure in this grounds, where the different type of errors have different costs or consequences. The results shown here present to this simple classifier as an interesting choice to be used as base classifier in ensembles for credit scoring and bankruptcy prediction, proving that not only the individual performance of a classifier is the key point to be selected for an ensemble scheme.
|
| [12] |
集成学习方法在企业财务危机预警中的应用 [J].Ensemble Learning Method and Its Application in Enterprise Financial Crisis Early Warning [J]. |
| [13] |
一种基于Boosting的集成学习算法在不均衡数据中的分类 [J].A Boosting Based Ensemble Learning Algorithm in Imbalanced Data Classification [J]. |
| [14] |
集成学习中若干关键问题的研究[D] .Research on Several Key Problems of Ensemble Learning Algorithms[D] . |
| [15] |
An Experimental Comparison of Three Methods for Constructing Ensembles of Decision Trees: Bagging, Boosting, and Randomization [J].https://doi.org/10.1023/A:1007607513941 URL [本文引用: 1] 摘要
Bagging and boosting are methods that generate a diverse ensemble of classifiers by manipulating the training data given to a “base” learning algorithm. Breiman has pointed out that they rely for their effectiveness on the instability of the base learning algorithm. An alternative approach to generating an ensemble is to randomize the internal decisions made by the base algorithm. This general approach has been studied previously by Ali and Pazzani and by Dietterich and Kong. This paper compares the effectiveness of randomization, bagging, and boosting for improving the performance of the decision-tree algorithm C4.5. The experiments show that in situations with little or no classification noise, randomization is competitive with (and perhaps slightly superior to) bagging but not as accurate as boosting. In situations with substantial classification noise, bagging is much better than boosting, and sometimes better than randomization.
|
| [16] |
An Experimental Comparison of Ensemble Classifiers for Bankruptcy Prediction and Credit Scoring [J].https://doi.org/10.1016/j.eswa.2008.01.018 URL [本文引用: 2] 摘要
In this paper, we investigate the performance of several systems based on ensemble of classifiers for bankruptcy prediction and credit scoring. The obtained results are very encouraging, our results improved the performance obtained using the stand-alone classifiers. We show that the method “Random Subspace” outperforms the other ensemble methods tested in this paper. Moreover, the best stand-alone method is the multi-layer perceptron neural net, while the best method tested in this work is the Random Subspace of Levenberg–Marquardt neural net. In this work, three financial datasets are chosen for the experiments: Australian credit, German credit, and Japanese credit.
|
| [17] |
Financial Ratios, Discriminant Analysis and the Prediction of Corporate Bankruptcy [J].https://doi.org/10.2307/2978933 URL [本文引用: 1] 摘要
No abstract is available for this item.
|
| [18] |
P2P网贷个人信用评价指标体系的构建 [J].https://doi.org/10.3969/j.issn.2095-042X.2016.01.012 URL [本文引用: 1] 摘要
为增加P2P网贷平台信用评价的可信性,改善因信息不对称而导致的企业信用风险问题,结合实际业务需求从表征信息、行为信息及状态信息三个方面选择个人信用评价指标变量。通过计算变量的WOE(Weight of Evidence)、IV(Information Value)值初步观测变量对目标的显著程度,再用SAS软件对整体变量进行逻辑回归。以IV和逻辑回归相结合的方式筛选指标,遴选出22个指标作为P2P网贷平台信用评价体系指标。这种个人信用评估指标的遴选结果保留了信息量大,对信用评价贡献概率大的指标。
The Construction of P2P Network Lending Personal Credit Evaluation Index System [J].https://doi.org/10.3969/j.issn.2095-042X.2016.01.012 URL [本文引用: 1] 摘要
为增加P2P网贷平台信用评价的可信性,改善因信息不对称而导致的企业信用风险问题,结合实际业务需求从表征信息、行为信息及状态信息三个方面选择个人信用评价指标变量。通过计算变量的WOE(Weight of Evidence)、IV(Information Value)值初步观测变量对目标的显著程度,再用SAS软件对整体变量进行逻辑回归。以IV和逻辑回归相结合的方式筛选指标,遴选出22个指标作为P2P网贷平台信用评价体系指标。这种个人信用评估指标的遴选结果保留了信息量大,对信用评价贡献概率大的指标。
|
| [19] |
基于证据权重逻辑回归模型的P2P公司信用风险评估[D] .Based on the Weight of Evidence Logistic Regression Model to Assess P2P Company’s Credit Risk [D]. |
| [20] |
Computational Time Reduction for Credit Scoring: An Integrated Approach Based on Support Vector Machine and Stratified Sampling Method [J].https://doi.org/10.1016/j.eswa.2011.12.057 URL [本文引用: 1] 摘要
With the rapid growth of credit industry, credit scoring model has a great significance to issue a credit card to the applicant with a minimum risk. So credit scoring is very important in financial firm like bans etc. With the previous data, a model is established. From that model is decision is taken whether he will be granted for issuing loans, credit cards or he will be rejected. There are several methodologies to construct credit scoring model i.e. neural network model, statistical classification techniques, genetic programming, support vector model etc. Computational time for running a model has a great importance in the 21st century. The algorithms or models with less computational time are more efficient and thus gives more profit to the banks or firms. In this study, we proposed a new strategy to reduce the computational time for credit scoring. In this approach we have used SVM incorporated with the concept of reduction of features using F score and taking a sample instead of taking the whole dataset to create the credit scoring model. We run our method two real dataset to see the performance of the new method. We have compared the result of the new method with the result obtained from other well known method. It is shown that new method for credit scoring model is very much competitive to other method in the view of its accuracy as well as new method has a less computational time than the other methods.
|
| [21] |
Investigation and Improvement of Multi-Layer Perceptron Neural Networks for Credit Scoring [J].https://doi.org/10.1016/j.eswa.2014.12.006 URL [本文引用: 1] |
| [22] |
基于决策树与Logistic回归的P2P网贷平台信用风险评价比较分析 [J].Comparative Analysis on Credit Risk Evaluation of P2P Network Loan Platform Based on Decision Tree and Logistic Regression [J]. |
| [23] |
基于卷积神经网络的互联网金融信用风险预测研究 [J].
针对互联网金融行业的信用风险评估问题,提出了一种基于卷积神经网络的客户违约风险预测方法。首先将输入数据分为动态数据和静态数据,将动态数据和静态数据分别转换为矩阵和向量,然后利用改进的卷积神经网络来自动提取特征并进行分类,最后使用ROC曲线、AUC值和KS值作为评价指标,将该方法与其他机器学习算法(Logistic回归、随机森林)进行比较。实验结果表明,卷积神经网络模型对于信用风险的预测效果要优于对比模型。
Prediction of Credit Riskin Internet Financial Industry Based on Convolutional Neural Network [J].
针对互联网金融行业的信用风险评估问题,提出了一种基于卷积神经网络的客户违约风险预测方法。首先将输入数据分为动态数据和静态数据,将动态数据和静态数据分别转换为矩阵和向量,然后利用改进的卷积神经网络来自动提取特征并进行分类,最后使用ROC曲线、AUC值和KS值作为评价指标,将该方法与其他机器学习算法(Logistic回归、随机森林)进行比较。实验结果表明,卷积神经网络模型对于信用风险的预测效果要优于对比模型。
|
| [24] |
Improving Experimental Studies about Ensembles of Classifiers for Bankruptcy Prediction and Credit Scoring [J].https://doi.org/10.1016/j.eswa.2013.12.003 URL [本文引用: 1] |
| [25] |
A Comparative Study of Classifier Ensembles for Bankruptcy Prediction [J].https://doi.org/10.1016/j.asoc.2014.08.047 URL [本文引用: 1] 摘要
The aim of bankruptcy prediction in the areas of data mining and machine learning is to develop an effective model which can provide the higher prediction accuracy. In the prior literature, various classification techniques have been developed and studied, in/with which classifier ensembles by combining multiple classifiers approach have shown their outperformance over many single classifiers. However, in terms of constructing classifier ensembles, there are three critical issues which can affect their performance. The first one is the classification technique actually used/adopted, and the other two are the combination method to combine multiple classifiers and the number of classifiers to be combined, respectively. Since there are limited, relevant studies examining these aforementioned disuses, this paper conducts a comprehensive study of comparing classifier ensembles by three widely used classification techniques including multilayer perceptron (MLP) neural networks, support vector machines (SVM), and decision trees (DT) based on two well-known combination methods including bagging and boosting and different numbers of combined classifiers. Our experimental results by three public datasets show that DT ensembles composed of 80 100 classifiers using the boosting method perform best. The Wilcoxon signed ranked test also demonstrates that DT ensembles by boosting perform significantly different from the other classifier ensembles. Moreover, a further study over a real-world case by a Taiwan bankruptcy dataset was conducted, which also demonstrates the superiority of DT ensembles by boosting over the others.
|
| [26] |
Extreme Learning Machines for Credit Scoring: An Empirical Evaluation [J].https://doi.org/10.1016/j.eswa.2017.05.050 URL [本文引用: 1] 摘要
Classification algorithms are used in many domains to extract information from data, predict the entry probability of events of interest, and, eventually, support decision making. This paper explores the potential of extreme learning machines (ELM), a recently proposed type of artificial neural network, for consumer credit risk management. ELM possess some interesting properties, which might enable them to improve the quality of model-based decision support. To test this, we empirically compare ELM to established scoring techniques according to three performance criteria: ease of use, resource consumption, and predictive accuracy. The mathematical roots of ELM suggest that they are especially suitable as a base model within ensemble classifiers. Therefore, to obtain a holistic picture of their potential, we assess ELM in isolation and in conjunction with different ensemble frameworks. The empirical results confirm the conceptual advantages of ELM and indicate that they are a valuable alternative to other credit risk modeling methods.
|
| [27] |
A New Hybrid Ensemble Credit Scoring Model Based on Classifiers Consensus System Approach [J].https://doi.org/10.1016/j.eswa.2016.07.017 URL [本文引用: 1] 摘要
During the last few years there has been marked attention towards hybrid and ensemble systems development, having proved their ability to be more accurate than single classifier models. However, among the hybrid and ensemble models developed in the literature there has been little consideration given to: 1) combining data filtering and feature selection methods 2) combining classifiers of different algorithms; and 3) exploring different classifier output combination techniques other than the traditional ones found in the literature. In this paper, the aim is to improve predictive performance by presenting a new hybrid ensemble credit scoring model through the combination of two data pre-processing methods based on Gabriel Neighbourhood Graph editing (GNG) and Multivariate Adaptive Regression Splines (MARS) in the hybrid modelling phase. In addition, a new classifier combination rule based on the consensus approach (ConsA) of different classification algorithms during the ensemble modelling phase is proposed. Several comparisons will be carried out in this paper, as follows: 1) Comparison of individual base classifiers with the GNG and MARS methods applied separately and combined in order to choose the best results for the ensemble modelling phase; 2) Comparison of the proposed method with all the base classifiers and ensemble classifiers with the traditional combination methods; and 3) Comparison of the proposed approach with recent related studies in the literature. Five of the well-known base classifiers are used, namely, neural networks (NN), support vector machines (SVM), random forests (RF), decision trees (DT), and na ve Bayes (NB). The experimental results, analysis and statistical tests prove the ability of the proposed method to improve prediction performance against all the base classifiers, hybrid and the traditional combination methods in terms of average accuracy, the area under the curve (AUC) H-measure and the Brier Score. The model was validated over seven real world credit datasets.
|
| [28] |
Enhancing Accuracy and Interpretability of Ensemble Strategies in Credit Risk Assessment: A Correlated-Adjusted Decision Forest Proposal [J].https://doi.org/10.1016/j.eswa.2015.02.042 URL [本文引用: 1] |
| [29] |
Machine Learning in Financial Crisis Prediction: A Survey [J].https://doi.org/10.1109/TSMCC.2011.2170420 URL [本文引用: 1] 摘要
For financial institutions, the ability to predict or forecast business failures is crucial, as incorrect decisions can have direct financial consequences. Bankruptcy prediction and credit scoring are the two major research problems in the accounting and finance domain. In the literature, a number of models have been developed to predict whether borrowers are in danger of bankruptcy and whether they should be considered a good or bad credit risk. Since the 1990s, machine-learning techniques, such as neural networks and decision trees, have been studied extensively as tools for bankruptcy prediction and credit score modeling. This paper reviews 130 related journal papers from the period between 1995 and 2010, focusing on the development of state-of-the-art machine-learning techniques, including hybrid and ensemble classifiers. Related studies are compared in terms of classifier design, datasets, baselines, and other experimental factors. This paper presents the current achievements and limitations associated with the development of bankruptcy-prediction and credit-scoring models employing machine learning. We also provide suggestions for future research.
|
| [30] |
|
| [31] |
Classification and Regression Trees (CART) [J]. |
| [32] |
The CART Decision Tree for Mining Data Streams [J].https://doi.org/10.1016/j.ins.2013.12.060 URL [本文引用: 1] 摘要
One of the most popular tools for mining data streams are decision trees. In this paper we propose a new algorithm, which is based on the commonly known CART algorithm. The most important task in constructing decision trees for data streams is to determine the best attribute to make a split in the considered node. To solve this problem we apply the Gaussian approximation. The presented algorithm allows to obtain high accuracy of classification, with a short processing time. The main result of this paper is the theorem showing that the best attribute computed in considered node according to the available data sample is the same, with some high probability, as the attribute derived from the whole data stream.
|
| [33] |
C4.5: Programs for Machine Learning [M]. |
| [34] |
A Study on C.5 Decision Tree Classification Algorithm for Risk Predictions During Pregnancy [J].https://doi.org/10.1016/j.protcy.2016.05.128 URL [本文引用: 1] 摘要
Complication during pregnancy has turned out o be a major problem for women of today's era. Pregnant women must be protected from these complications arising in period of gestation, a stage wherein every woman undergoes many physiological changes, sometimes inducing severe health problems leading to death of both mother and fetus. Technological interventions in the field of medical diagnosis can largely help to find a solution for this problem to protecting pregnant women, thus in turn reducing maternal and fetal mortalities to great extents. Decision Tree Classification method is a popularly used method whose algorithms are best suitable in medical diagnosis. C4.5 Decision Tree algorithm is one of the popular and effectively used classifier for pregnancy data classification in present study. The main aim of this paper is to pinpoint the importance of standardization of parameters selected for data collection in study, compare the results obtained from C4.5 classifier on both un-standardized and standardized datasets and analyse the performance of the C4.5 algorithm in terms of its prediction accuracy when applied on the created database from collected and standardized pregnancy data.
|
| [35] |
The Wrapper Approach[A]//Feature Extraction, Construction and Selection [M]. |
| [36] |
Parallel Distributed Processing: Explorations in the Microstructures of Cognition [J].https://doi.org/10.2307/415721 URL [本文引用: 1] |
| [37] |
Support Vector Networks [J]. |
| [38] |
Detection and Classification of Organophosphate Nerve Agent Simulants Using Support Vector Machines with Multiarray Sensors [J].https://doi.org/10.1021/ci034220i URL PMID: 15032529 [本文引用: 1] 摘要
The need for rapid and accurate detection systems is expanding and the utilization of cross-reactive sensor arrays to detect chemical warfare agents in conjunction with novel computational techniques may prove to be a potential solution to this challenge. We have investigated the detection, prediction, and classification of various organophosphate (OP) nerve agent simulants using sensor arrays with a novel learning scheme known as support vector machines (SVMs). The OPs tested include parathion, malathion, dichlorvos, trichlorfon, paraoxon, and diazinon. A new data reduction software program was written in MATLAB V. 6.1 to extract steady-state and kinetic data from the sensor arrays. The program also creates training sets by mixing and randomly sorting any combination of data categories into both positive and negative cases. The resulting signals were fed into SVM software for “pairwise” and “one” vs all classification. Experimental results for this new paradigm show a significant increase in classificati...
|
| [39] |
Cryptographic Limitations on Learning Boolean Formulae and Finite Automata [J].https://doi.org/10.1007/3-540-56483-7_21 URL [本文引用: 1] 摘要
In this paper, we prove the intractability of learning several classes of Boolean functions in the distribution-free model (also called the Probably Approximately Correct or PAC model) of learning from examples. These results are representation independent, in that they hold regardless of the syntactic form in which the learner chooses to represent its hypotheses.Our methods reduce the problems of cracking a number of well-known public-key cryptosystems to the learning problems. We prove that a polynomial-time learning algorithm for Boolean formulae, deterministic finite automata or constant-depth threshold circuits would have dramatic consequences for cryptography and number theory. In particular, such an algorithm could be used to break the RSA cryptosystem, factor Blum integers (composite numbers equivalent to 3 modulo 4), and detect quadratic residues. The results hold even if the learning algorithm is only required to obtain a slight advantage in prediction over random guessing. The techniques used demonstrate an interesting duality between learning and cryptography.We also apply our results to obtain strong intractability results for approximating a generalization of graph coloring.
|
| [40] |
AdaBoost算法研究进展与展望 [J].https://doi.org/10.3724/sp.j.1004.2013.00745 URL Magsci [本文引用: 1] 摘要
<p>AdaBoost是最优秀的Boosting算法之一, 有着坚实的理论基础, 在实践中得到了很好的推广和应用. 算法能够将比随机猜测略好的弱分类器提升为分类精度高的强分类器, 为学习算法的设计提供了新的思想和新的方法. 本文首先介绍Boosting猜想提出以及被证实的过程, 在此基础上, 引出AdaBoost算法的起源与最初设计思想;接着, 介绍AdaBoost算法训练误差与泛化误差分析方法, 解释了算法能够提高学习精度的原因;然后, 分析了AdaBoost算法的不同理论分析模型, 以及从这些模型衍生出的变种算法;之后, 介绍AdaBoost算法从二分类到多分类的推广. 同时, 介绍了AdaBoost及其变种算法在实际问题中的应用情况. 本文围绕AdaBoost及其变种算法来介绍在集成学习中有着重要地位的Boosting理论, 探讨Boosting理论研究的发展过程以及未来的研究方向, 为相关研究人员提供一些有用的线索. 最后,对今后研究进行了展望, 对于推导更紧致的泛化误差界、多分类问题中的弱分类器条件、更适合多分类问题的损失函数、 更精确的迭代停止条件、提高算法抗噪声能力以及从子分类器的多样性角度优化AdaBoost算法等问题值得进一步深入与完善.</p>
Advance and Prospects of AdaBoost Algorithm [J].https://doi.org/10.3724/sp.j.1004.2013.00745 URL Magsci [本文引用: 1] 摘要
<p>AdaBoost是最优秀的Boosting算法之一, 有着坚实的理论基础, 在实践中得到了很好的推广和应用. 算法能够将比随机猜测略好的弱分类器提升为分类精度高的强分类器, 为学习算法的设计提供了新的思想和新的方法. 本文首先介绍Boosting猜想提出以及被证实的过程, 在此基础上, 引出AdaBoost算法的起源与最初设计思想;接着, 介绍AdaBoost算法训练误差与泛化误差分析方法, 解释了算法能够提高学习精度的原因;然后, 分析了AdaBoost算法的不同理论分析模型, 以及从这些模型衍生出的变种算法;之后, 介绍AdaBoost算法从二分类到多分类的推广. 同时, 介绍了AdaBoost及其变种算法在实际问题中的应用情况. 本文围绕AdaBoost及其变种算法来介绍在集成学习中有着重要地位的Boosting理论, 探讨Boosting理论研究的发展过程以及未来的研究方向, 为相关研究人员提供一些有用的线索. 最后,对今后研究进行了展望, 对于推导更紧致的泛化误差界、多分类问题中的弱分类器条件、更适合多分类问题的损失函数、 更精确的迭代停止条件、提高算法抗噪声能力以及从子分类器的多样性角度优化AdaBoost算法等问题值得进一步深入与完善.</p>
|
| [41] |
Arcing Classifiers [J].https://doi.org/10.1214/aos/1024691079 URL [本文引用: 2] |
| [42] |
The Random Subspace Method for Constructing Decision Forests [J]. |
| [43] |
Error Correlation and Error Reduction in Ensemble Classifiers [J].https://doi.org/10.1080/095400996116839 URL [本文引用: 1] 摘要
Using an ensemble of classifiers, instead of a single classifier, can lead to improved generalization. The gains obtained by combining, however, are often affected more by the selection of what is presented to the combiner than by the actual combining method that is chosen. In this paper, we focus on data selection and classifier training methods, in order to 'prepare' classifiers for combining. We review a combining framework for classification problems that quantifies the need for reducing the correlation among individual classifiers. Then, we discuss several methods that make the classifiers in an ensemble more complementary. Experimental results are provided to illustrate the benefits and pitfalls of reducing the correlation among classifiers, especially when the training data are in limited supply.
|
| [44] |
Rotation Forest: A New Classifier Ensemble Method [J].https://doi.org/10.1109/TPAMI.2006.211 URL PMID: 16986543 [本文引用: 1] 摘要
Abstract We propose a method for generating classifier ensembles based on feature extraction. To create the training data for a base classifier, the feature set is randomly split into K subsets (K is a parameter of the algorithm) and Principal Component Analysis (PCA) is applied to each subset. All principal components are retained in order to preserve the variability information in the data. Thus, K axis rotations take place to form the new features for a base classifier. The idea of the rotation approach is to encourage simultaneously individual accuracy and diversity within the ensemble. Diversity is promoted through the feature extraction for each base classifier. Decision trees were chosen here because they are sensitive to rotation of the feature axes, hence the name "forest." Accuracy is sought by keeping all principal components and also using the whole data set to train each base classifier. Using WEKA, we examined the Rotation Forest ensemble on a random selection of 33 benchmark data sets from the UCI repository and compared it with Bagging, AdaBoost, and Random Forest. The results were favorable to Rotation Forest and prompted an investigation into diversity-accuracy landscape of the ensemble models. Diversity-error diagrams revealed that Rotation Forest ensembles construct individual classifiers which are more accurate than these in AdaBoost and Random Forest, and more diverse than these in Bagging, sometimes more accurate as well.
|
| [45] |
Statistical Comparisons of Classifiers over Multiple Data Sets [J].https://doi.org/10.1007/s10846-005-9016-2 URL [本文引用: 1] 摘要
Summary: While methods for comparing two learning algorithms on a single data set have been scrutinized for quite some time already, the issue of statistical tests for comparisons of more algorithms on multiple data sets, which is even more essential to typical machine learning studies, has been all but ignored. This article reviews the current practice and then theoretically and empirically examines several suitable tests. Based on that, we recommend a set of simple, yet safe and robust non-parametric tests for statistical comparisons of classifiers: the Wilcoxon signed ranks test for comparison of two classifiers and the Friedman test with the corresponding post-hoc tests for comparison of more classifiers over multiple data sets. Results of the latter can also be neatly presented with the newly introduced CD (critical difference) diagrams.
|
| [46] |
On Preprocessing Data for Financial Credit Risk Evaluation [J].https://doi.org/10.1016/j.eswa.2005.10.006 URL [本文引用: 1] 摘要
Financial credit-risk evaluation is among a class of problems known to be semi-structured, where not all variables that are used for decision-making are either known or captured without error. Machine learning has been successfully used for credit-evaluation decisions. However, blindly applying machine learning methods to financial credit risk evaluation data with minimal knowledge of data may not always lead to expected results. We present and evaluate some data and methodological considerations that are taken into account when using machine learning methods for these decisions. Specifically, we consider the effects of preprocessing of credit-risk evaluation data used as input for machine learning methods.
|
| [47] |
Data Mining Feature Selection for Credit-Scoring Models [J].https://doi.org/10.1057/palgrave.jors.2601976 URL [本文引用: 1] 摘要
The features used may have an important effect on the performance of credit scoring models. The process of choosing the best set of features for credit scoring models is usually unsystematic and dominated by somewhat arbitrary trial. This paper presents an empirical study of four machine learning feature selection methods. These methods provide an automatic data mining technique for reducing the feature space. The study illustrates how four feature selection methods-'ReliefF', 'Correlation-based', 'Consistency-based' and 'Wrapper' algorithms help to improve three aspects of the performance of scoring models: model simplicity, model speed and model accuracy. The experiments are conducted on real data sets using four classification algorithms-'model tree (M5)', 'neural network (multi-layer perceptron with back-propagation)', 'logistic regression', and 'k-nearest-neighbours'.
|

/
| 〈 |
|
〉 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}