刘洪伟 , 詹明君
, 詹明君
Liu Hongwei, Zhan Mingjun
中图分类号: TP391.4 F713.8
通讯作者:
收稿日期: 2017-09-1
修回日期: 2017-10-26
网络出版日期: 2018-02-25
版权声明: 2018 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】了解用户在线购物中的兴趣需求变化有利于个性化推荐。本文提出结合用户浏览行为分析的隐式动态兴趣识别和管理模型。【方法】通过三阶段实验构造用户点击流数据, 以天猫和淘宝网页功能键为数据粒度对页面分类, 再采用Bisecting K-means聚类算法进行兴趣状态挖掘, 最后总结归纳兴趣与行为的特征映射。【结果】用户隐式兴趣存在4种状态: 关注、理解信息、态度和购买意图, 在态度和购买意图状态下, 更倾向于产生购买; 在不同状态的浏览路径特征有所差异。【局限】未添加网页广告促销等非结构化数据进行分析。【结论】从实时动态兴趣的角度, 对购物决策中兴趣的状态进行验证挖掘, 拓展动态兴趣研究; 为电商网站管理用户行为提供了一个实现动态个性化推荐的视角。
关键词:
Abstract
[Objective] This paper proposes a model to identify the interests of online shoppers based on their browsing behaviors, aiming to improve the personalized recommendation services. [Methods] First, we launched experiment to collect clickstream data from Taobao and TMall. Second, we used the Bisecting K-means algorithm to analyze the retrieved data. Finally, we established the relationship mapping structure between interests and behaviors. [Results] We found four types of user’s implicit interests: Attention, Comprehension, Attitudes and Intention. Users with the Attitude and Intention types tended to make purchase. The characteristics of browsing paths were different among the users. [Limitations] We did not examine unstructured data, i.e., online sales advertisements, in this study. [Conclusions] This paper investigates the user interests in online shopping, and then improve the personalized recommendation services of the E-commerce platforms.
Keywords:
如何提高在线购买转化率, 对于学术界和商业界都是一项热门且艰巨的任务。而其中个性化推荐被认为是最有效的方法之一。个性化推荐服务最重要的原则是学习、追踪、甚至预测用户的兴趣和行为, 模拟销售人员帮助用户完成选择商品和决策的过程, 为用户定制独特的个性化商品和服务[1]。传统上认为用户的兴趣和浏览偏好在一段时间内是相对稳态的, 当前许多电商网站都是在此前提下, 通过分析用户历史信息来提供个性化定制信息或推荐服务[2]。目前推荐系统大致可以分为三种: 基于内容过滤、基于协同过滤、以及两者混合的系统[3]。基于内容过滤, 实质是一种文本挖掘技术, 通过构建一个由用户自己评分的兴趣文档进行推荐[4]。协同过滤算法则是被认为比较有效的且应用最广的推荐系统关键技术之一, 以用户购买的相似性为原理进行推荐[5]。前者的缺陷是过于偏重推荐的商品与以往购买的商品之间的关联度, 而后者则注重大众购买的相关性。为了弥补两者缺陷, 学者们提出了混合算法[6,7,8]。例如, 天猫是中国最大的B2C电商之一。天猫假设那些拥有类似购买记录的用户之间存在相近的兴趣, 除了通过用户历史购买行为推荐相似的商品, 也通过购买了同样商品的其他用户的购买记录进行商品推荐。目前整个推荐引导的成交量基本占到20%[9]。然而在线浏览时, 用户的兴趣是不断变化的且具有波动性, 会随时间逐渐衰减[10], 或者在受到外部信息刺激时会作出调节[4]。
如同Rana等指出, 传统推荐算法无法与用户兴趣和偏好改变的速度保持一致, 动态捕获用户潜在兴趣的推荐算法的研究显得尤为重要[3]。本文提出一个模型, 能够系统地描述用户在线购物时的隐式兴趣, 识别出用户当前的兴趣状态, 并且以此从兴趣角度预测出用户下一步的浏览路径。
从统计物理学科来看, 人类行为具有非泊松分布特性, 从而“人类动力学”被提出并成为人类行为统计特性生成机制研究中的主流理论[11]。Zhao等分析了人类兴趣的时间统计分布以及兴趣转变规律[12]。其认为偏好返回, 惯性效应, 探究新兴趣点是人类兴趣动力学的基本特征。Shang等提出兴趣存在波动性, 认为人类对某一事物的兴趣是不断改变的; 如果用户的购物行为是基于兴趣偏好的驱动, 那么初期会兴趣浓厚, 而随着时间的增加, 兴趣逐渐递减, 直到时间足够长时, 兴趣会消失[10]。不过, 兴趣也会受到广告推广、社会认同以及身边朋友的口碑推荐等信息输入而产生颠覆性的变化[13]。Estrin指出网络用户海量的行为轨迹数据, 包括点击流数据, 为揭示人类行为模式规律提供可能[14]。在线浏览时, 有些用户仅仅是在单纯地浏览, 有些则是对商品进行对比, 有些在了解商品具体信息后会选择丢弃或加入收藏夹或购物车, 有些直接购买, 有些则退出电商网站。在浏览轨迹中的每一个阶段, 用户潜在的实时的兴趣都会随时间改变或者受到广告营销和商品评价等信息输入而不断波动。传统的推荐算法并没有考虑以上这些用户兴趣的时间性和波动性。
实际上, 用户当前的兴趣和兴趣的变化很难被识别并跟踪。显式兴趣体现在用户的评分。若直接要求用户评分时, 大多数用户倾向于忽略提供信息或填写不完整、甚至给出错误信息。因此, 从客户端访问日志点击流数据得到用户浏览轨迹, 进而识别用户隐式兴趣至关重要, 这种方式能够真实客观地反映用户行为[15], 如果仅从客户端数据学习、分析出用户浏览行为隐含的兴趣, 这样便消除了用户评分的成本[16,17]。用户与系统的很多交互动作, 都能暗示其兴趣与喜好, 如查询、浏览页面和文章、点击鼠标、翻页/拉动滚动条次数、标记书签、菜单操作、网页浏览时间等[15-16, 18]。Kuo等采用K-means模型结合用户访问时间和访问次数来描述用户的兴趣度[19]。Jayawardhena等则利用实证的方法定义了兴趣特征以揭示用户在线行为, 采取K-means算法对用户聚类, 从而聚类出不同兴趣的用户类别[20]。朱志国结合电子商务站点用户网页访问时间与网页关键词信息对用户访问兴趣进行定义, 借鉴隐马尔可夫模型, 建立用户兴趣导航模型[21]。付关友等考虑用户长期积累的行为: 浏览时间、浏览动作次数、页面滚动次数, 通过菜单命令相加得到浏览行为总贡献值以表述用户隐式兴趣[22], 但其简单加和模型无法识别用户实时兴趣。Ding等和Li等先后采用线性效用函数模型, 认为用户的实时兴趣除了与过去自身浏览行为有关以外, 还与网页和营销刺激的累计作用有关[2, 23]。
上述研究层面都集中在网页页面之间, 而忽略了在线商品的品牌、价格、销量、评价等页面功能键对于用户隐式兴趣的影响。在线购物中, 商品的品牌、价格、销量、评价这些因素, 对于不同用户起到不同的影响; 同时在这些信息的刺激之下, 用户的兴趣也会随之改变[24,25]。电商用户在这些人机交互行为下, 浏览行为会因个人的异质性而出现偏颇, 进而影响用户的购买决策。Montgomery从人机交互角度, 对电商网页进行分类, 认为每一个页面都可以被归类为8个类别中的一个: 主页、账户、分类、产品、信息、购物车、订单, 及进入/退出页面[26,27]。但是这样的基于页面层面的分类粒度过于粗糙, 很多时候不能精确反映用户浏览行为背后的影响因素。本文以网页上的功能键为数据粒度进行网页分类; 在更细的数据粒度基础上, 从选择兴趣度、访问时间偏好、页面兴趣度三个维度对用户隐式动态兴趣进行描述。同时, 因为一般K-means方法严重受到初始簇心选取的影响, 本文将采用效能更高的Bisecting K-means模型对用户在浏览每一个网页呈现出的兴趣状态进行识别。
目前, 用户兴趣状态的种类确定仍存在争议。Montgomery等认为购买行为通常发生在兴趣从浏览状态(Browsing Orientation)转移至深思状态(Deliberation Orientation)时[27]。Ding等假设用户拥有越高的内在效用越有可能进行购买。即用户的兴趣越高, 购买可能性越大。其使用分层贝叶斯模型识别用户实时兴趣, 并分为高意图和低意图两种状态[2]。兴趣驱动人类动力学认为个体拥有众多的兴趣状态。通过对兴趣状态的发生频率排序, 发现在给定的时间间隔中, 一个人会产生不同的兴趣状态[12]。实际上, 用户实时兴趣状态的种类并不是只有简单的高和低两种。Howard- Sheth消费者购买理论框架认为, 如果用户在购物过程中受到外在因素以及刺激因素, 用户会将这些因素转化为信息进行学习, 在心理上对商品的属性进行感知并协调购物的需求, 购买兴趣也会随之变化[28]。
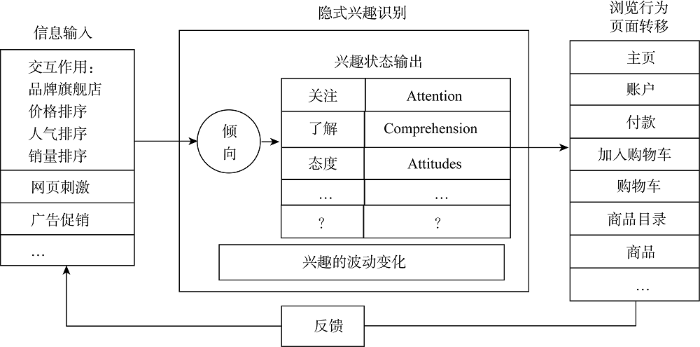
本文提出的识别用户的隐式兴趣变化规律及在线浏览规律模型, 是基于人类动力学和消费者购买理论的两者结合。本文研究框架如图1所示, 用户受到兴趣的驱动产生浏览行为, 经过一段时间后, 兴趣发生衰减; 然而如果伴随浏览时信息的输入影响, 兴趣可以被提高或降低。这时, 兴趣状态的输出可能是: 关注(Attention)、理解信息(Comprehension)、对商品偏好或厌恶等的态度(Attitudes)等多种未知的兴趣状态, 兴趣状态的种类选择取决于用户在实际购物中所表现出来的多种状况。这些兴趣状态的输出可以影响其浏览行为的决策。在此过程, 不断地往复循环刺激, 用户的兴趣不断波动, 浏览行为也不断变化。
在线购物中, 最初所有用户看到的网站内容与结构都是相同的, 但用户的兴趣变化一旦被识别, 系统便会对网页内容和结构进行调整, 从而形成个性化推荐。针对用户在每一个网页的兴趣差别, 本文首先针对点击流数据基于关键词进行页面分类, 然后从隐式兴趣变量对网页进行Bisecting K-means聚类建模, 进而分析个体用户在浏览不同的网页时所处的兴趣状态, 识别实时潜在的兴趣状态。
K-means聚类算法是MacQueen在1967年提出的, 是一个最经典的基于划分的聚类方法[29,30], 是目前最流行的聚类算法之一[31,32]。这个算法的基本思想是以空间中k个点为中心进行聚类, 对最靠近它们的样本进行归类。通过迭代的方法, 逐次更新各个簇中心的值, 直至得到最好的聚类结果。但原始算法受初始点选取影响很大, 而Bisecting K-means算法因为执行了多次二分试验, 并选择了具有最小的误差总和的试验结果, 且每一步都仅有两个簇中心, 很好地避免了原始算法受初始化问题的影响, 能很快达到全局最优。因此选择Bisecting K-means聚类进行兴趣状态识别建模。
轮廓系数(Silhouette Index)是对数据在簇中的一致性进行解释和验证的评价指标[33,34], 其有机结合了簇的凝聚度(Cohesion)和分离度(Separation), 是一种用于评估聚类有效性的指标, 轮廓系数定义如公式(1)所示:
${{s}_{k}}=\frac{1}{N}\sum\limits_{i=1}^{N}{\frac{b({{x}_{i}})-a({{x}_{i}})}{\max \{a({{x}_{i}}),b({{x}_{i}})\}}}$ (1)
其中, $N$表示数据集中所有的页面数, $a({{x}_{i}})$表示计算页面${{x}_{i}}$与本簇内所有其他页面距离的平均值, 用于计算簇内的凝聚度; $b({{x}_{i}})$指${{x}_{i}}$到其他簇中所有页面的平均距离的最小值, 用于量化簇之间的分离度。
轮廓系数${{s}_{k}}$在$[-1,1]$之间, 若sk趋近-1时, 表示页面${{x}_{i}}$越接近其他簇, 而非本簇, ${{x}_{i}}$被分配到错误的簇中; 若${{s}_{k}}$接近0, 则表明页面数据集合X中不存在自然簇, 当中的页面是服从随机分布的; 若${{s}_{k}}$趋近1, 表明${{x}_{i}}$非常远离其他簇, 而接近其所在的簇, 其被分配到一个紧密独立的簇中。
以淘宝和天猫为研究平台, 收集这两个平台上用户的点击流数据进行分析。如果用户使用“销量”的排序功能键, 但仅仅用页面到页面的切换的分类方案定义页面, 就无法分析出用户对于销量可能具有偏好性。本文提出数据粒度更精细的页面归类方法, 将归类的数据粒度从页面降到以电商平台的功能键为基础, 对每一类页面进行定义, 从更小的数据粒度获取用户行为。根据URL的差异确认用户行为。例如: 用户浏览的某次会话(Session)中有以下两条连续的记录, 其URL字段值为:
https: //s.taobao.com/search?q=%E8%83%8C%E5%8C%85
https://s.taobao.com/search?q=%E8%83%8C%E5%8C%85&sort=sale-desc
前者是淘宝页面的搜索结果, 而后者的关键词sort=sale, 则反映了用户浏览时对于商品销量有所偏好的行为特征。这里用户会话是指, 用户的一次访问网站期间, 从进入到离开网站的一系列浏览活动。
当一个用户偏重商品评价时, 往往会使用鼠标点击商品的累计评价。但是这种浏览行为无法被记录在URL中, 因此需要通过收集鼠标点击的信息结合URL两个字段中的关键词来分析用户的这种口碑偏好。
为了更好地识别用户的隐式兴趣, 捕获用户对商品的偏好, 首先编写一个Java Script的Google浏览器插件, 除了获取访问日志数据外, 还能捕捉用户鼠标点击的信息。笔者设计的插件收集到访问日志数据包括的重要字段如表1所示。
表1 浏览器日志字段及含义
| 字段 | 含义 |
|---|---|
| user_Id | 用户ID |
| sessionId | 会话ID |
| tabId | 标签页记录ID |
| title | 网页主题 |
| url | 用户访问地址 |
| visitedTime | 用户访问时间 |
| goodlist | 商品列表 |
| Info | 鼠标点击信息 |
为了准确地表示出用户的浏览行为, 从访问日志中抽离出用户会话, 并对每一次会话中的行为进行结构化的形式表示。
在用户偏好的页面分类方案前提下, 本文提出用户选择兴趣度、访问时间偏好、页面兴趣度三个维度描述用户的隐式兴趣。
设U为所有会话中所有页面类别的集合, H是所有浏览页面类别的子路径的集合。存在$h$属于H集合, 对于有限序列组$s$属于$h$($s$是$u$属于$U$集合组成的浏览页面类别的序列, 称其中第$i$个浏览页面为第$i$位), 它们的前$k$位均相同, 则第$k+1$位有$n$种不同页面类别进行选择。
(1) 选择兴趣度
在一个会话中, 用户离开页面类别$q$之后, 下一步的浏览中有$n$种选择。其中相对选择次数越高的页面, 则认为是浏览者偏好越强的页面, 即越感兴趣的页面。将第$i(k=1,2,\cdots ,n)$种页面的选择兴趣度定义如公式(2)所示:
${{P}_{i}}=\frac{{{N}_{i}}}{\sum\limits_{i=1}^{n}{{{N}_{k}}}}$ (2)
其中, ${{N}_{i}}$表示用户第$i$种选择的支持度, 即离开页面$q$到下一步第$i$种页面的频数。以选择兴趣度作为概率转移矩阵。
(2) 访问时间偏好
①页面持续时间
用户在页面$q$的持续时间越长, 表明用户在对于该页面的偏好更强。页面持续时间定义如公式(3)所示:
$Time(q)={{T}_{i}}-{{T}_{q}}$ (3)
$Time(q)$表示用户在页面$q$的持续时间, 即页面$q$开始时到下一个页面$i$浏览记录开始时(即离开页面$q$时)的时间间隔。${{T}_{i}}$表示页面$i$开始的时间。
②页面相对浏览时间率
用户进行购物浏览, 往往是在一个会话中完成的。对于$Time(q)$, 忽略了单一会话中用户对不同页面的时间偏好。因此笔者提出一个页面相对浏览时间率来描述这种偏好, 如公式(4)所示:
$Timeratio(i)=\frac{Time(i)}{\sum\limits_{i=0}^{m}{Time(i)}}$ (4)
其中, $m$表示用户在某个会话中总共浏览$m$个页面。
(3) 页面兴趣度
①页面点击率
用户对于页面的特别偏好, 定义如如公式(5)所示:
$Clickratio(i)=\frac{visit(i)}{m}$ (5)
其中, m表示用户某个会话中总共浏览m个页面; visit(i)表示在此次会话中用户对于第i种页面类型的访问数。
②会话访问深度
在一个会话中, 用户按时序打开浏览页面的唯一标签值(Page Tab), 即当前用户的会话访问深度, 表明了用户在会话过程中的页面数访问深度。如用户在第二次打开淘宝主页taobao.com, 该页面的唯一标签值为2; 然后跳转到具体的A产品页面, 标签值为3, 随即跳到B产品, 标签值为4。即使随后浏览大量其他页面, 但重新打开A产品页时, 标签值仍为3。由此可见, 用户浏览过程中, 随着浏览页面数量的增加, 用户的页面数访问深度加大, 但若返回先前已打开过的重复页面时, 用户访问深度则回到初次状态, 说明用户再次重新浏览, 可能存在货比三家的兴趣状态。因此笔者将页面标签值定义为会话访问深度, 表示用户浏览网页i在会话中的起始时刻, 如公式(6)所示:
$Sessiondepth(i)=tabId(i)$ (6)
该变量值越大表明用户首次打开页面的时间越晚, 该变量是兴趣状态在一个会话中的时刻控制变量。
本文采取实验室田野实验方法, 随机抽取10名大学生实验者进行在线商品选购, 记录用户行为数据、构造点击流数据, 识别并管理用户动态兴趣。
实验具体流程如图2所示, 分为三阶段: 初步预实验, 利用调查问卷获取实验者日常的电商消费行为习惯; 正式实验, 要求实验者在天猫和淘宝网站进行商品选购, 实验同时, 嵌入在Google浏览器的拓展插件会自动获取实验者的浏览行为数据; 最后阶段针对实验者的初步调查问卷与行为实验结果的对比, 进行深度访谈, 有成功付款购买行为获得30元补贴, 无购买行为获得20元补贴。数据集包括14个会话、1 772个页面的访问日志和鼠标点击的数据, 其中发生7次购买行为。
采用更细的数据粒度基于功能键元素进行页面分类, 处理后的数据集中, 页面集合$U$含有$n=14$种页面类别, 描述性统计如表2所示。
表2 页面类别统计描述表
| 缩写 | H | A | S | D | F | G | R | B | P | Y | V | T | C | O |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 类名 | 主页 | 账户 | 付款 购买 | 加入购物车& 收藏夹 | 购物车 | 商品 | 评价 | 品牌或旗舰店 | 价格 | 人气 | 销量 | 商品 属性 | 目录 | 其他 |
| 频数 | 138 | 96 | 7 | 30 | 52 | 170 | 11 | 142 | 17 | 5 | 4 | 588 | 438 | 74 |
| 频率(%) | 7.79 | 5.42 | 0.40 | 1.69 | 2.93 | 9.59 | 0.62 | 8.01 | 0.96 | 0.28 | 0.23 | 33.18 | 24.72 | 4.18 |
如表2所示, 在14种页面中, 用户在线购物时, 浏览“商品属性”(T)页面最多, 占到33.18%。商品“目录”(C)列表, “商品”(G)页面紧随其后。而能够反映用户对于商品的偏好的页面中, “品牌”(B)页面最多, 评价、价格、人气、销量则相对较少。
从表3兴趣指标的描述性可知, 平均每个页面浏览的持续时间为12.28秒。但在一个会话中, 用户对于页面的浏览速度很快, 每个页面相对浏览时间率为0.71%; 而对于用户点击行为而言, 每种页面类型平均被点击率低于30%; 会话访问深度均值是28.20页, 表明用户在一个会话中平均浏览页面数目达到28页。通过描述性统计, 可以看出页面持续时间存在异常值情况, 其中位数为3秒, 极值却达到1 492秒, 笔者使用箱线图对其进行异常点判断及处理, 为后续建模做准备。
表3 兴趣指标描述性统计
| 变量 | 均值 | 标准差 | 最小值 | 中位数 | 最大值 |
|---|---|---|---|---|---|
| 页面持续时间(秒) | 12.28 | 45.32 | 0.00 | 3.00 | 1492.00 |
| 页面相对浏览 时间率(%) | 0.71 | 3.42 | 0.00 | 0.09 | 100.00 |
| 页面点击率(%) | 27.67 | 18.76 | 0.27 | 26.01 | 100.00 |
| 会话访问深度(页) | 28.20 | 25.72 | 2.00 | 22.00 | 102.00 |
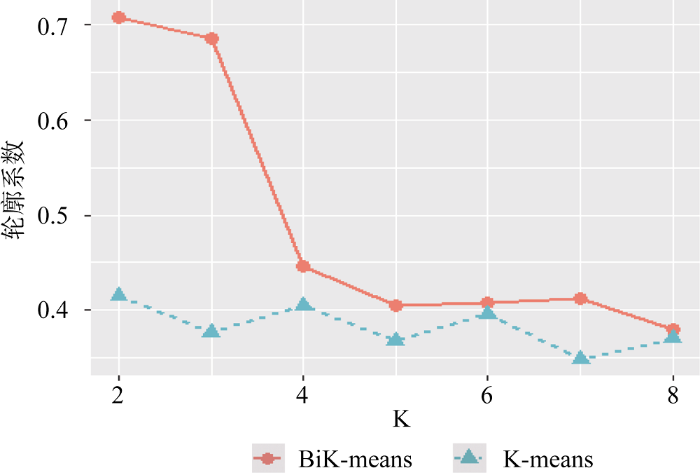
本文从用户隐式动态兴趣的角度, 采用访问日志中的页面持续时间、页面相对浏览时间率、页面点击率, 以及会话访问深度4个兴趣变量构建聚类建模指标体系。用户购买兴趣的K类状态存在不确定性, 使用统计软件R语言(R-3.3.2)进行Bisecting K-means聚类算法和原始K-means算法的实现, 量化识别用户对每一步浏览页面时的隐式兴趣状态, 从轮廓系数评价聚类K簇的选择优劣, 选取出最优K值, 以此最优K值确定用户动态兴趣状态的种类。由于K值太大会失去解释性, 因此通常K值不会太大, K取值为2到8。
从图3可以看出, Bisecting K-means算法避免了原始K-means算法受初始点设置的影响问题, 在K=2时轮廓系数最大; 但在实践应用中, 通常使用启发式的手肘法(Elbow Method)[35]进行判断。在K=2之后, 每一步增加1, 轮廓系数下降, 直到曲线急剧下降到4时, 然后继续增大K值, 曲线下降缓慢, 新簇的特征非常接近先前的簇, 增加的新簇所含的信息不足以使各簇之间形成显著差异化, 对信息的归类无影响。K取4时是曲线的肘部, 有明显拐点, 笔者结合轮廓系数认为用户的动态兴趣状态最适合分为4簇, 如表4所示。
表4 4类用户兴趣的簇中心
| 动态兴趣 | Time | Timeratio | Clickratio | Sessiondepth |
|---|---|---|---|---|
| 第1簇 | 5.283270 | 0.5805210 | 50.57808 | 16.92205 |
| 第2簇 | 7.042510 | 0.2328121 | 19.05581 | 64.23077 |
| 第3簇 | 11.558824 | 0.6666170 | 17.15118 | 12.02801 |
| 第4簇 | 155.5405 | 8.1338870 | 21.005 | 19.62162 |
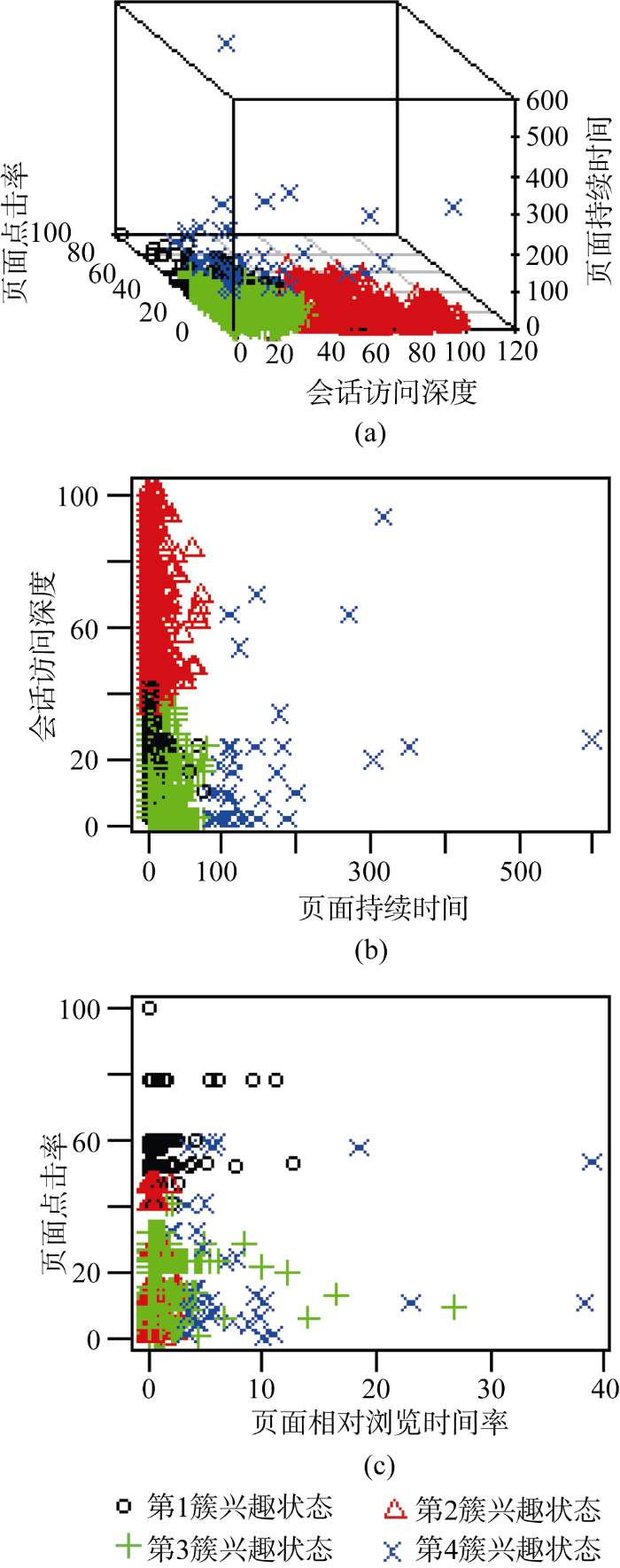
在所有页面中, 第1簇页面数目占比最高, 达到29.7%, 用户在此簇页面浏览的平均持续时间约为5.28秒, 页面点击率在4簇之中最大。而相反第4簇页面数目最少仅占2.9%, 但页面持续时间与相对浏览时间率最高。对于第2簇, 该过程用户点击浏览的页面较多, 同时对于会话访问深度也是最深, 但是浏览时间非常短。而第3簇, 尽管页面点击率和会话访问深度在4种兴趣状态中为最小, 但其页面持续时间与页面相对浏览时间率却都处在较高水平。
在购物过程中, 无论是筛选品牌、寻找旗舰店、价格排序、人气排序等用户特定偏好行为, 还是页面的刺激、广告促销等产生的信息, 用户因为对不同信息的敏感程度差异会形成感知倾向, 输出实时的兴趣状态。Howard等认为感知倾向(Predisposition)会如图1“隐式兴趣识别”框架中作为信息的反馈机制, 掌控对信息的灵敏程度, 同时令用户产生不同的兴趣输出状态, 进而影响用户的下一步浏览行为[28]。
为了进一步探讨购物行为中产生的信息与兴趣状态之间的特征映射关系, 将兴趣变量作为分析维度, 以4簇兴趣状态作为标签, 标注原始数据, 数据可视化结果如图4所示。
(1) 购买意图(Intention)广泛定义为后续真实购买的预测指标, 是一种用户预计购买的感知状态[36]。在目前研究中, 在线购买意图是指在线购物者使用他或她的虚拟购物车作为手段在当前会话期间进行购买的打算。购买意图与其他功利性动机都是以目标或任务为导向的, 比如将商品加入购物车[37], 据此用户在4种兴趣状态中, 将商品加入购物车和收藏夹频数越高的状态意味着更高的购买意图。用户在电子商务网站的浏览时间正向促进购买意图[38]。某种意义上, 在线虚拟购物车是用户暂时存放目标商品的购物篮, 尤其是当用户使用购物车频次越高时, 用户购买意图更高,完成购买行为的概率更高[37]。基于以上考虑, 将浏览购物车和加入商品到购物车行为归结为使用购物车行为, 认为购买意图兴趣是用户在长时间浏览网页且使用购物车频率较高的情况下发生的。
为了识别出购买意图这一兴趣状态, 将“加入购物车&收藏夹”(D)和使用“购物车”(F)频数与用户实际“付款购买”(S)频数进行相关检验, 相关性越高的簇, 表明用户在该簇中购买意图越高, 表5为检验结果。经过Pearson相关检验之后, 只有第4簇的使用购物车行为与用户实际购买行为正向显著相关, 同时此簇平均页面浏览时间大于其他三簇, 可认为这种兴趣状态下用户产生了购买意图。
表5 各簇中使用购物车行为次数与实际购买次数相关检验
| 4类动态兴趣 | 相关系数 |
|---|---|
| 第1簇 | / |
| 第2簇 | -0.022 |
| 第3簇 | -0.081 |
| 第4簇 | 0.679** |
(2) 态度状态(Attitudes): 用户对于一个潜在能满足其需求的商品的评价是用户对商品的态度[39]。Hawkins等指出态度是环境刺激的产物, 正如将产品提供给用户一段时间后, 用户会产生讨论评价[40]。在学术研究中态度很早被定义为是给定一个物品, 在用户倾向产生一段时间后的喜好或不喜好的反应[41]。
用户将商品加入购物车和放入收藏夹行为表明用户对该商品是喜好的, 据此针对14个会话中4种兴趣状态下“加入购物车&收藏夹”(D)页面频数高低, 判断用户在浏览会话中对于产品的偏好高低。
“加入购物车&收藏夹”频数均值的95%置信区间图如图5所示, 用户在第2簇与第3簇的状态下表现出对商品的喜好态度大于其他两种状态。据表4可知, 用户处在第3簇兴趣状态下比第2簇平均浏览时间更长, 表明第3簇为用户处在对商品了解一段时间后产生表露态度的兴趣状态。
(3) 关注状态(Attention)表现为用户对信息的灵敏反应, 通常被定义为感知中的选择[42]。关注的测量是在用户接受信息的时段中[28]。一些研究聚焦于视觉中关注的层面研究, 用户在关注阶段存在“概览”、“比较”和“检查”层面[43,44,45]。由图4可知, 用户在第1簇的状态中页面持续时间和页面相对时间浏览率分布最低, 结合表4可知页面点击率在第1簇中最高; Glöckner等研究表明在短时间浏览大量视觉模块的是处于信息的初始搜索阶段或扫描的关注阶段[46], 同时第1簇会话访问深度较浅, 表示在该状态中用户浏览的多是先前打开的网页, 处于或跳转到初始网页浏览阶段, 因此认为第1簇兴趣状态是用户在初期短时间内浏览大量网页的关注兴趣状态。
(4) 理解状态(Comprehension), 指对品牌知识、商品或服务的信息全面了解[28]。随着用户在浏览过程中会话的加深, 对商品信息的理解更加全面。商品的知识与信息, 作为商品的潜在来源与其他相关的收益, 在购买决策过程中用户理解的知识越多, 对商品的模糊歧义认知越少, 购买的兴趣越高, 第2簇用户平均会话访问深度最大, 且页面点击率较高, 判断此时用户处在对商品信息的理解兴趣状态。
用户的隐式动态兴趣已经通过以上数学模型进行了求解识别。在一个会话中, 由于用户所处兴趣状态的异质性, 用户的浏览路径特征有所不同。
随着时间改变, 兴趣状态和用户选择页面类型也会随之变化, 以其中一名用户为例详细说明。图6描述了某用户的某个会话中的部分浏览路径。该用户从“其他”(O)网页跳转到天猫和淘宝“主页”(H), 这两个页面用户维持在态度的兴趣状态, 具备较高兴趣。但是经过检索之后进入天猫平台的商品“目录”(C)列表后, 用户在浏览商品时兴趣降低为关注状态, 但在选购“品牌或旗舰店”(B)时, 购买兴趣增强。兴趣是不断波动的, 该用户在品牌商品的刺激信号输入之下, 兴趣被重新激起, 与兴趣驱动的人类动力波动规律一致[13], 但随着时间的推移, 兴趣出现衰减, 该用户浏览完品牌页面后, 在商品“目录”(C)页面的不断跳转浏览下, 仍然处于最低的关注兴趣状态, 用户选中目标商品后, 即在浏览“商品”(G)页面时, 兴趣又被提升, 进入“商品属性”(T)页面后, 最终在较高的态度兴趣持续阶段, 从“账户”(A)页面跳转完成“付款购买”(S)行为。实时地识别用户的潜在兴趣状态的意义在于帮助电商平台进行个性化推荐, 不仅能减少购物者的搜索成本, 还能提高电商购买转化率。
为了进一步分析每个兴趣状态下的用户行为模式, 采用图形化的方式表示每一个簇的一步转移概率矩阵。图7中通过方格的灰度深浅来表示转移概率的大小: 颜色越浅概率越大。右侧矩形条代表该状态下的概率图例, 中间的方格显示了由公式(2)选择兴趣度定义的一步转移概率。
由图7(a)所示的一步转移概率看出, 该聚类用户的兴趣状态处于关注状态, 如果用户当前时刻在浏览主页, 那么点击切换的下一页可能还是主页, 而很少点击其他页面。如果当前时刻用户正在关注品牌, 该用户最有可能下一步仍然在旗舰店或品牌店进行浏览, 也有可能通过品牌的页面选中自己想要的产品, 继而跳转到产品页面; 如果用户处于产品的浏览阶段, 有可能会详细查看产品的属性, 但在这一兴趣状态过程中, 用户没有发生购买行为。这种浏览模式说明很多用户在某些情况下, 可能对搜索结果并不满意, 仅仅停留在电商平台随意浏览的阶段, 没有进一步的购买意愿。图7(c)显示在该状态下, 用户经常在商品属性、评价、购物车等页面进行下一步的操作。若当前处于登录账号的页面, 下一步则很可能会查看或修改自己账号内信息, 也有可能跳转到主页进行搜索。搜索完之后可能进入产品目录列表页面, 或直接选中产品。经过不同兴趣状态下的切换之后, 用户可能对商品产生喜爱的态度, 然后登录账号页面, 转移到购买付款页面, 完成一次购买行为。这种行为特征说明了用户在对商品开始表现出厌恶或者喜爱的态度后, 对于购物车会进行移除、添加或购买的操作。
用户由于实时兴趣的转变, 会在不同兴趣状态下进行切换, 进而促使用户的浏览行为的改变。本模型通过用户动态兴趣的捕捉, 判断用户当前所属的兴趣状态, 研究预测用户下一步的浏览行为或是购物的决策行为。
本文对浏览器日志点击流数据进行分析, 建模结果表明网页的浏览序列能够有效识别用户的隐式实时兴趣。以淘宝和天猫电商平台页面上的功能键作为数据粒度, 进行网页分类, 以此将电商网站分成14个页面类别, 与以往单纯使用单一元素进行的网页分类方案相比[27], 本文能在页面分类上体现出用户在线购物时的浏览偏好: 评价、品牌、价格、人气、销量。在此分类方案的基础上, 对用户的浏览行为进行量化, 从选择兴趣度、访问时间偏好、页面兴趣度三个维度描述用户隐式动态兴趣。另外, 使用Bisecting K-means算法识别用户的隐式动态兴趣, 得到4种最优的兴趣状态类型。结果表明用户处于态度(Attitude)或购买意图(Intention)时候的兴趣状态更有可能进行购买。同时, 本文讨论了不同兴趣状态下的一步转移概率, 从实时兴趣的角度分析用户的访问路径特征, 为动态地改变网页设计提供帮助。上述研究结果为电商网站提供一个新的分析角度, 从用户对每一个网页的实时兴趣角度出发, 有助于制定电商网站的推荐策略, 并为制定营销方案提供了数据支持。
电商网站推荐策略还有很多方面, 比如广告和促销是个性化推荐服务的重要刺激因素。本研究也存在一定局限性, 例如未能添加网页促销广告等文本数据, 非结构化数据也许能更有效理解用户浏览时的兴趣以及访问路径。仅以天猫一个电商平台进行实验, 研究结果欠缺普适性。尽管从客户端获取的数据拥有数据量大、真实反映用户的浏览行为等特征, 但是如果能够结合消费者行为的主观感知数据, 那么对用户购买行为决策将会有很好的解释, 这将成为个性化推荐服务研究领域的新方向。
刘洪伟: 构建研究思路, 确立研究范式;
高鸿铭: 提出研究命题, 设计实验, 分析数据并建模;
陈丽, 詹明君: 撰写论文;
梁周扬: Google浏览器插件的实现。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: gaohongming_gdut@163.com。
[1] 高鸿铭. dataset.rar. 插件抓取数据集及分析结果数据集.
| [1] |
“互联网+”时代网络个性化推荐采纳意愿影响因素研究 [J].Research on the Adoption Intention of Online Personalized Recommender in the Internet Plus Era [J]. |
| [2] |
Learning User Real-Time Intent for Optimal Dynamic Web Page Transformation [J].https://doi.org/10.1287/isre.2015.0568 URL [本文引用: 3] 摘要
Many e-commerce websites struggle to turn visitors into real buyers. Understanding online users’ real-time intent and dynamic shopping cart choices may have important implications in this realm. This study presents an individual-level, dynamic model with concurrent optimal page adaptation that learns users’ real-time, unobserved intent from their online cart choices, then immediately performs optimal Web page adaptation to enhance the conversion of users into buyers. To suggest optimal strategies for concurrent page adaptation, the model analyzes each individual user’s browsing behavior, tests the effectiveness of different marketing and Web stimuli, as well as comparison shopping activities at other sites, and performs optimal Web page transformation. Data from an online retailer and a laboratory experiment reveal that concurrent learning of the user’s unobserved purchase intent and real-time, intent-based optimal interventions greatly reduce shopping cart abandonment and increase purchase conversions. If the concurrent, intent-based optimal page transformation for the focal site starts after the first page view, shopping cart abandonment declines by 32.4% and purchase conversion improves by 6.9%. The optimal timing for the site to intervene is after three page views, to achieve efficient learning of users’ intent and early intervention simultaneously.
|
| [3] |
A Study of the Dynamic Features of Recommender Systems [J].https://doi.org/10.1007/s10462-012-9359-6 URL [本文引用: 2] 摘要
The extensive usage of internet is fundamentally changing the way we live and communicate. Consequently, the requirements of users while browsing internet are changing drastically. Recommender Systems (RSs) provide a technology that helps users in finding relevant contents on internet. Revolutionary innovations in the field of internet and their consequent effects on users have activated the research in the area of recommender systems. This paper presents issues related to the changing needs of user requirements as well as changes in the systems' contents. The RSs involving said issues are termed as Dynamic Recommender Systems (DRSs). The paper first defines the concept of DRS and explores the various parameters that contribute in developing a DRS. The paper also discusses the scope of contributions in this field and concludes citing in possible extensions that can improve the dynamic qualities of recommendation systems in future.
|
| [4] |
Text-Learning and Related Intelligent Agents: A Survey [J].https://doi.org/10.1109/5254.784084 URL [本文引用: 2] 摘要
Analysis of text data using intelligent information retrieval, machine learning, natural language processing or other related methods is becoming an important issue for the development of intelligent agents. There are two frequently used approaches to the development of intelligent agents using machine learning techniques: a content-based and a collaborative approach. In the first approach, the content (eg., text) plays an important role, while in the second approach, the existence of several knowledge sources (eg., several users) is required. We can say that the usage of machine learning techniques on text databases (usually referred to as text-learning) is an important part of the content-based approach. Examples are agents for locating information on World Wide Web and Usenet news filtering agents. There are different research questions important for the development of text-learning intelligent agents. We focus on three of them: what representation is used for documents, how is the high number of features dealt with and which learning algorithm is used. These questions are addressed in an overview of the existing approaches to text classification. For illustration we give a brief description of the content-based personal intelligent agent named Personal WebWatcher that uses text-learning for user customized Web browsing.
|
| [5] |
Personalized Recommendation on Dynamic Content Using Predictive Bilinear Models [C]// |
| [6] |
Hybrid Web Recommender Systems [A]// The Adaptive Web: Methods and Strategies of Web Personalization, Lecture Notes in Computer Science [M]. |
| [7] |
A Novel Approach to Hybrid Recommendation Systems Based on Association Rules Mining for Content Recommendation in Asynchronous Discussion Groups [J].https://doi.org/10.1016/j.ins.2012.07.011 URL [本文引用: 1] 摘要
Recommender systems have been developed in variety of domains, including asynchronous discussion group which is one of the most interesting ones. Due to the information overload and its varieties in discussion groups, it is difficult to draw out the relevant information. Therefore, recommender systems play an important role in filtering and customizing the desired information. Nowadays, collaborative and content-based filtering are the most adopted techniques being utilized in recommender systems. The collaborative filtering technique recommends items based on liked-mind users' opinions and users' preferences. Alternatively, the aim of the content-based filtering technique is the identification of items which are similar to those a user has preferred in past. To overcome the drawbacks of the aforementioned techniques, a hybrid recommender system combines two or more recommendation techniques to obtain more accuracy. The most important achievement of this study is to present a novel approach in hybrid recommendation systems, which identifies the user similarity neighborhood from implicit information being collected in a discussion group. In the proposed system, initially the association rules mining technique is applied to discover the similar users, and then the related posts are recommended to them. To select the appropriate contents in the transacted posts, it is necessary to focus on the concepts rather than the key words. Therefore, to locate the semantic related concepts Word Sense Disambiguation strategy based on WordNet lexical database is exploited. The experiments carried out on the discussion group datasets proved a noticeable improvement on the accuracy of useful posts recommended to the users in comparison to content-based and the collaborative filtering techniques as well. (C) 2012 Elsevier Inc. All rights reserved.
|
| [8] |
A Hybrid News Recommendation Algorithm Based on User’s Browsing Path [C]// |
| [9] |
天猫推荐算法实践 [EB/OL]. (Recommendation of TMall [EB/OL]. ( |
| [10] |
Interest-Driven Model for Human Dynamics [J].https://doi.org/10.1088/0256-307X/27/4/048701 URL [本文引用: 2] 摘要
Empirical observations indicate that the interevent time distribution of human actions exhibits heavy-tailed features. The queuing model based on task priorities is to some extent successful in explaining the origin of such heavy tails, however, it cannot explain all the temporal statistics of human behavior especially for the daily entertainments. We propose an interest-driven model, which can reproduce the power-law distribution of interevent time. The exponent can be analytically obtained and is in good accordance with the simulations. This model well explains the observed relationship between activities and power-law exponents, as reported recently for web-based behavior and the instant message communications.
|
| [11] |
The Origin of Bursts and Heavy Tails in Human Dynamics [J].https://doi.org/10.1038/nature03459 URL PMID: 15889093 [本文引用: 1] 摘要
Abstract: Understanding human dynamics is of major scientific and practical importance and can be increasingly addressed in a quantitative fashion thanks to electronic records capturing various human activity patterns. The authors of Ref. [1] revisit the datasets studied in Ref. [2], making four technical observations. Some of the observations of Ref. [1] are based on the authors' unfamiliarity with the details of the data collection process and have little relevance to the findings of Ref. [2] and others are resolved in quantitative fashion by other authors [3].
|
| [12] |
Emergence of Scaling in Human-Interest Dynamics [J].https://doi.org/10.1038/srep03472 URL PMID: 3858797 [本文引用: 2] 摘要
Abstract Human behaviors are often driven by human interests. Despite intense recent efforts in exploring the dynamics of human behaviors, little is known about human-interest dynamics, partly due to the extreme difficulty in accessing the human mind from observations. However, the availability of large-scale data, such as those from e-commerce and smart-phone communications, makes it possible to probe into and quantify the dynamics of human interest. Using three prototypical "Big Data" sets, we investigate the scaling behaviors associated with human-interest dynamics. In particular, from the data sets we uncover fat-tailed (possibly power-law) distributions associated with the three basic quantities: (1) the length of continuous interest, (2) the return time of visiting certain interest, and (3) interest ranking and transition. We argue that there are three basic ingredients underlying human-interest dynamics: preferential return to previously visited interests, inertial effect, and exploration of new interests. We develop a biased random-walk model, incorporating the three ingredients, to account for the observed fat-tailed distributions. Our study represents the first attempt to understand the dynamical processes underlying human interest, which has significant applications in science and engineering, commerce, as well as defense, in terms of specific tasks such as recommendation and human-behavior prediction.
|
| [13] |
Modeling Human Dynamics with Adaptive Interest [J].https://doi.org/10.1088/1367-2630/10/7/073010 URL [本文引用: 2] 摘要
Recently, increasing empirical evidence indicates the extensive existence of heavy tails in the interevent time distributions of various human behaviors. Based on the queuing theory, the Barab\'asi model and its variations suggest the highest-priority-first protocol a potential origin of those heavy tails. However, some human activity patterns, also displaying the heavy-tailed temporal statistics, could not be explained by a task-based mechanism. In this paper, different from the mainstream, we propose an interest-based model. Both the simulation and analysis indicate a power-law interevent time distribution with exponent -1, which is in accordance with some empirical observations in human-initiated systems.
|
| [14] |
Where n = me [J]. |
| [15] |
User Implicit Interest Indicators Learned from the Browser on the Client Side [C]// |
| [16] |
Implicit Interest Indicators [C]// |
| [17] |
基于隐式浏览输入的用户聚类分析 [J].https://doi.org/10.3969/j.issn.1001-3695.2011.08.017 URL [本文引用: 1] 摘要
立足于隐式浏览信息难以获取的实际,首先定义能够描绘用户心理和行为的隐式兴趣度表达公式;接着得到了用户对产品类的兴趣度,从而得到了基于兴趣度的用户聚类分析结果.该研究不仅从一定程度上解决了用户信息获取的难题,也为推荐系统中的算法研究和推荐输出研究奠定了基础.
User Clustering Analysis Based on Implicit Navigation [J].https://doi.org/10.3969/j.issn.1001-3695.2011.08.017 URL [本文引用: 1] 摘要
立足于隐式浏览信息难以获取的实际,首先定义能够描绘用户心理和行为的隐式兴趣度表达公式;接着得到了用户对产品类的兴趣度,从而得到了基于兴趣度的用户聚类分析结果.该研究不仅从一定程度上解决了用户信息获取的难题,也为推荐系统中的算法研究和推荐输出研究奠定了基础.
|
| [18] |
Letizia: An Agent That Assists Web Browsing [C]// |
| [19] |
Integration of ART2 Neural Network and Genetic K-means Algorithm for Analyzing Web Browsing Paths in Electronic Commerce [J].https://doi.org/10.1016/j.dss.2004.04.010 URL [本文引用: 1] 摘要
In order to verify the proposed method, data from a Monte Carlo Simulation are used. The simulation results show that the ART2+GKA is significantly better than the ART2+K-means, both for mean within cluster variations and misclassification rate. A real-world problem, a recommendation agent system for a Web PDA company, is investigated. In this system, the browsing paths are used for clustering in order to analyze the browsing preferences of customers. These results also show that, based on the mean within-cluster variations, ART2+GKA is much more effective.
|
| [20] |
Consumers Online: Intentions, Orientations and Segmentation [J].https://doi.org/10.1108/09590550710750377 URL [本文引用: 1] 摘要
Purpose - The purpose of this paper is to examine the purchase intentions of online retail consumers, segmented by their purchase orientation. Design/methodology/approach - An e-mail/web survey was addressed to a consumer panel concerning their online shopping experiences and motivations, n=396. Findings - It is empirically shown that consumer purchase orientations have no significant effect on their propensity to shop online. This contradicts the pervasive view that internet consumers are principally motivated by convenience. It was found that aspects that do have a significant effect on purchase intention are prior purchase and gender. Research limitations/implications - There are two limitations. First, the sample contained only UK internet users, thus generalisations about the entire population of internet users may be questionable. Second, in our measurement of purchase intentions, we did not measure purchase intent per se. Practical implications - These findings indicate that consumer purchase orientations in both the traditional world and on the internet are largely similar. Therefore, both academics and businesses are advised to treat the internet as an extension to existing traditional activities brought about by advances in technology, i.e. the multi-channel approach. Originality/value - The paper adds to the understanding of the purchase orientations of different clusters of e-consumers.
|
| [21] |
基于隐马尔可夫链模型的电子商务用户兴趣导航模式发现 [J].
用户智能导航模式发现已经成为电子商务领域中的一个研究热点。为此,结合电子商务站点用户网页访问时间与网页关键字信息对用户访问兴趣进行定义,借鉴经典隐马尔可夫链模型,建立用户兴趣导航模型。给出在此模型中用户兴趣导航路径的发现方法及算法描述。通过模拟数据、某B2C在线图书销售站点中的真实数据以及与经典方法的对比等方面的实验验证,结果表明:给出的模型方法能够准确、高效地找到带有用户访问兴趣的关联路径信息。这个方法可以作为一种应用于电子商务领域更为有效、实用的智能导航发现工具。
Discovery of E-Commerce Users’ Interest Navigation Patterns Based on Hidden Markov Chains Model [J].
用户智能导航模式发现已经成为电子商务领域中的一个研究热点。为此,结合电子商务站点用户网页访问时间与网页关键字信息对用户访问兴趣进行定义,借鉴经典隐马尔可夫链模型,建立用户兴趣导航模型。给出在此模型中用户兴趣导航路径的发现方法及算法描述。通过模拟数据、某B2C在线图书销售站点中的真实数据以及与经典方法的对比等方面的实验验证,结果表明:给出的模型方法能够准确、高效地找到带有用户访问兴趣的关联路径信息。这个方法可以作为一种应用于电子商务领域更为有效、实用的智能导航发现工具。
|
| [22] |
个性化服务中基于行为分析的用户兴趣建模 [J].https://doi.org/10.3969/j.issn.1007-130X.2005.12.026 URL Magsci [本文引用: 1] 摘要
<p>为了更好地为用户提供个性化服务,本文从心理学的角度运用内驱力理论发现Web用户的浏览行为和他对网页是否感兴趣密切相关,并提出用线性回归模型来描述它们之间的相关性。通过实验验证了我们提出的这种回归模型是成立的、合理的和有效的。通过分析用户浏览行为计算出来的兴趣度可以应用于Web信息服务领域中的许多方面,对个性<br />化服务系统的研制有着重要影响。</p>
A User Interest Modele Based on the Analysis of User Behaviors for Personalization [J].https://doi.org/10.3969/j.issn.1007-130X.2005.12.026 URL Magsci [本文引用: 1] 摘要
<p>为了更好地为用户提供个性化服务,本文从心理学的角度运用内驱力理论发现Web用户的浏览行为和他对网页是否感兴趣密切相关,并提出用线性回归模型来描述它们之间的相关性。通过实验验证了我们提出的这种回归模型是成立的、合理的和有效的。通过分析用户浏览行为计算出来的兴趣度可以应用于Web信息服务领域中的许多方面,对个性<br />化服务系统的研制有着重要影响。</p>
|
| [23] |
Cross-Selling the Right Product to the Right Customer at the Right Time [J].https://doi.org/10.2307/23033447 URL [本文引用: 1] 摘要
Firms are challenged to improve the effectiveness of cross-selling campaigns. the authors propose a customer-response model that recognizes the evolvement of customer demand for various products; the possible multifaceted roles of cross-selling solicitations for promotion, advertising, and education; and customer heterogeneous preference for communication channels. they formulate cross-selling campaigns as solutions to a stochastic dynamic programming problem in which the firm's goal is to maximize the long-term profit of its existing customers while taking into account the development of customer demand over time and the multistage role of cross-selling promotion. the model yields optimal cross-selling strategies for how to introduce the right product to the right customer at the right time using the right communication channel. applying the model to panel data with cross-selling solicitations provided by a national bank, the authors demonstrate that households have different preferences and responsiveness to cross-selling solicitations. in addition to generating immediate sales, cross-selling solicitations also help households move faster along the financial continuum (educational role) and build up goodwill (advertising role). a decomposition analysis shows that the educational effect (83%%) largely dominates the advertising effect (15%%) and instantaneous promotional effect (2%%). the cross-selling solicitations resulting from the proposed framework are more customized and dynamic and improve immediate response rate by 56%%, long-term response rate by 149%%, and long-term profit by 177%%.
|
| [24] |
The Mature Brand and Brand Interest: An Alternative Consequence of Ad-Evoked Affect [J].https://doi.org/10.2307/1252220 URL [本文引用: 1] 摘要
The authors propose that for mature brands, ad-evoked affect will not have a strong influence on brand attitude; they formulate brand interest, a new construct, as a more relevant consequence of ad-evoked affect. They present empirical evidence to support their theory regarding the consequences of ad-evoked affect for mature brands.
|
| [25] |
The Dynamics of Online Word-Of-Mouth and Product Sales — An Empirical Investigation of the Movie Industry [J].https://doi.org/10.1016/j.jretai.2008.04.005 URL [本文引用: 1] 摘要
There are growing interests in understanding how word-of-mouth (WOM) on the Internet is generated and how it influences consumers purchase decisions at retail outlets. A unique aspect of the WOM effect is the presence of a positive feedback mechanism between WOM and retail sales. We characterize the process through a dynamic simultaneous equation system, in which we separate the effect of online WOM as both a precursor to and an outcome of retail sales. We apply our approach to the movie industry, showing that both a movie's box office revenue and WOM valence significantly influence WOM volume. WOM volume in turn leads to higher box office performance. This positive feedback mechanism highlights the importance of WOM in generating and sustaining retail revenue.
|
| [26] |
Buying, Searching, or Browsing: Differentiating Between Online Shoppers Using In-Store Navigational Clickstream [J].https://doi.org/10.1207/S15327663JCP13-1&2_03 URL [本文引用: 1] 摘要
In the bricks-and-mortar environment, stores employ sales people that have learned to distinguish between shoppers based on their in-store behavior. Some shoppers appear to be very focused in looking for a specific product. In those cases, sales people may step in and help the shopper find what they are looking for. In other cases, the shopper is merely “window shopping.” The experienced sales person can identify these shoppers and either ignore them and let them continue window shopping, or intercede and try and stimulate a purchase in the appropriate manner. However, in the virtual shopping environment, there is no sales person to perform that role. Therefore, this article theoretically develops and empirically tests a typology of store visits in which visits vary according to the shoppers’ underlying objectives. By using page-to-page clickstream data from a given online store, visits are categorized as a buying, browsing, searching, or knowledge-building visit based on observed in-store navigational patterns, including the general content of the pages viewed. Each type of visit varies in terms of purchasing likelihood. The shoppers, in each case, are also driven by different motivations and therefore would respond differentially to various marketing messages. The ability to categorize visits in such a manner allows the e-commerce marketer to identify likely buyers and design more effective, customized promotional message.
|
| [27] |
Modeling Online Browsing and Path Analysis Using Clickstream Data [J].https://doi.org/10.1287/mksc.1040.0073 URL [本文引用: 3] 摘要
Clickstream data provide information about the sequence of pages or the path viewed by users as they navigate a website. We show how path information can be categorized and modeled using a dynamic multinomial probit model of Web browsing. We estimate this model using data from a major online bookseller. Our results show that the memory component of the model is crucial in accurately predicting a path. In comparison, traditional multinomial probit and first-order Markov models predict paths poorly. These results suggest that paths may reflect a user's goals, which could be helpful in predicting future movements at a website. One potential application of our model is to predict purchase conversion. We find that after only six viewings purchasers can be predicted with more than 40% accuracy, which is much better than the benchmark 7% purchase conversion prediction rate made without path information. This technique could be used to personalize Web designs and product offerings based upon a user's path.
|
| [28] |
The Theory of Buyer Behavior [M]. |
| [29] |
Some Methods for Classification and Analysis of MultiVariate Observations [C]// |
| [30] |
A Clustering Technique for Summarizing Multivariate Data [J].https://doi.org/10.1002/bs.3830120210 URL PMID: 6030099 [本文引用: 1] 摘要
Scientific measurements frequently involve large numbers of variables whose complex interactions are not easily found. A practical computing method termed ISODATA, which finds the cluster structure of such data, is described. The resulting description of the data provides a fit to the data of a set of cluster centers that tends to minimize the sum of the squared distances of each data point from its closest cluster center. An application to the grouping or clustering of the answers of 209 people to an 80-question sociological survey illustrates the utility of the method.
|
| [31] |
Data Clustering: 50 Years Beyond K-means [J].https://doi.org/10.1016/j.patrec.2009.09.011 URL [本文引用: 1] 摘要
Organizing data into sensible groupings is one of the most fundamental modes of understanding and learning. As an example, a common scheme of scientific classification puts organisms into a system of ranked taxa: domain, kingdom, phylum, class, etc. Cluster analysis is the formal study of methods and algorithms for grouping, or clustering, objects according to measured or perceived intrinsic characteristics or similarity. Cluster analysis does not use category labels that tag objects with prior identifiers, i.e., class labels. The absence of category information distinguishes data clustering (unsupervised learning) from classification or discriminant analysis (supervised learning). The aim of clustering is to find structure in data and is therefore exploratory in nature. Clustering has a long and rich history in a variety of scientific fields. One of the most popular and simple clustering algorithms, K-means, was first published in 1955. In spite of the fact that K-means was proposed over 50 years ago and thousands of clustering algorithms have been published since then, K-means is still widely used. This speaks to the difficulty in designing a general purpose clustering algorithm and the ill-posed problem of clustering. We provide a brief overview of clustering, summarize well known clustering methods, discuss the major challenges and key issues in designing clustering algorithms, and point out some of the emerging and useful research directions, including semi-supervised clustering, ensemble clustering, simultaneous feature selection during data clustering, and large scale data clustering.
|
| [32] |
K-Means Clustering: A Half-Century Synthesis [J].https://doi.org/10.1348/000711005X48266 URL PMID: 16709277 [本文引用: 1] 摘要
Abstract This paper synthesizes the results, methodology, and research conducted concerning the K-means clustering method over the last fifty years. The K-means method is first introduced, various formulations of the minimum variance loss function and alternative loss functions within the same class are outlined, and different methods of choosing the number of clusters and initialization, variable preprocessing, and data reduction schemes are discussed. Theoretic statistical results are provided and various extensions of K-means using different metrics or modifications of the original algorithm are given, leading to a unifying treatment of K-means and some of its extensions. Finally, several future studies are outlined that could enhance the understanding of numerous subtleties affecting the performance of the K-means method.
|
| [33] |
On the Performance of Bisecting K-Means and PDDP [J].https://doi.org/10.1137/1.9781611972719.5 URL [本文引用: 1] 摘要
The problem this paper focuses on is the unsupervised clustering of a data-set. The data-p×
|
| [34] |
Silhouettes: A Graphical Aid to the Interpretation and Validation of Cluster Analysis [J].https://doi.org/10.1016/0377-0427(87)90125-7 URL [本文引用: 1] 摘要
A new graphical display is proposed for partitioning techniques. Each cluster is represented by a so-called silhouette , which is based on the comparison of its tightness and separation. This silhouette shows which objects lie well within their cluster, and which ones are merely somewhere in between clusters. The entire clustering is displayed by combining the silhouettes into a single plot, allowing an appreciation of the relative quality of the clusters and an overview of the data configuration. The average silhouette width provides an evaluation of clustering validity, and might be used to select an ‘appropriate’ number of clusters.
|
| [35] |
Review on Determining Number of Cluster in K-means Clustering [J]. |
| [36] |
A Survey of the Effect of Consumers’ Perceived Risk on Purchase Intention in e-Shopping [J].https://doi.org/10.4236/jssm.2015.81012 URL [本文引用: 1] 摘要
This research paper aims to compare the perceived risk level between Internet and store shopping, and revisit the relationships among past positive experience, perceived risk level, and future purchase intention within the Internet shopping environment. To achieve the research objectives and test hypotheses, paired sample t鈥搕est is used to analyze the mean differences of the individual and overall perceived risk levels in two buying situations. In addition, to analyze the relationships among shopping experiences, perceived risk, and purchase intention variables, Pearson correlation analysis and linear regression are used. The research revealed that consumers perceived more purchasing risk from the Internet than from the store. A more positive online shopping experience led to consumers%#39; less perceived purchasing risk level in the Internet. And a higher perceived risk led to less future purchasing intention from the Internet.
|
| [37] |
Beyond Buying: Motivations Behind Consumers’ Online Shopping Cart Use [J].https://doi.org/10.1016/j.jbusres.2009.01.022 URL [本文引用: 2] 摘要
The authors investigate consumers' motivations for placing items in an online shopping cart with or without buying, termed virtual cart use. While retailers offer virtual carts as a functional holding space for intended online purchases, this study, based on a national online sample, reveals other powerful utilitarian and hedonic motivations that explain the frequency of consumers' online cart use. Beyond current purchase intentions, the investigated reasons for why consumers place items in their carts include: securing online price promotions, obtaining more information on certain products, organizing shopping items, and entertainment. Based on empirical findings, the authors offer managerial suggestions for enhancing online shopping-to-buying conversion rates.
|
| [38] |
网络促销对消费者冲动性购买行为的影响研究 [D].Research on the Influence of the Network Promtion on Consumers’ Impluse Buying Behavior [D]. |
| [39] |
Consumer Attitude: Some Reflections on Its Concept, Trilogy, Relationship with Consumer Behavior, and Marketing Implications [J].
This paper is an attempt at providing some reflections on consumer attitude. It examines the concept of consumer attitudes toward marketing efforts of businesses. Furthermore, the paper identifies the trilogy of consumer attitude, including samples of their measurement scales; and how attitudes connect to the behaviors of consumers, but notes that the companies would have difficulty influencing the purchasing behaviors of their consumers directly. To indirectly influence the behaviors of prospects, the paper therefore, suggests that firms should provide credible evidence of their product benefits, correct their customer misconceptions, offer free samples, engage new technologies, and bring in new innovations in value defining, developing, and delivering processes. Specifically, this paper recommends that the behaviors of consumers can be effectively changed to firm desired behavior by altering the tri-components of their target consumer attitudes. Knowledge and application of these can enable a firm effectively design rent-yielding strategies Keyword s: Attitude, attitude change, attitude components, attitude function, consumer attitude.
|
| [40] |
Consumer Behavior: Building Marketing Strategy [M]. |
| [41] |
Attitude, Intention, and Behavior: An Introduction to Theory and Research [M]. |
| [42] |
A Neural Theory of Visual Attention: Bridging Cognition and Neurophysiology [J].https://doi.org/10.1037/0033-295X.112.2.291 URL [本文引用: 1] |
| [43] |
An Eye-Fixation Analysis of Choice Processes for Consumer Nondurables [J].https://doi.org/10.1086/209397 URL [本文引用: 1] 摘要
The nature of the choice process for commonly purchased nondurables was examined by tracking eye fixations in a laboratory simulation of supermarket shelving. The observed process contains three stages that were interpreted as (1) orientation, (2) evaluation, and (3) verification. Orientation consisted of an overview of the product display, although some initial screening out of alternatives also occurred. The evaluation stage, the longest by far, was dominated by direct comparisons between two or three alternative products. The last stage, devoted to verification of the tentatively chosen brand-size, mainly examined alternatives with few or no previous fixations. Greater familiarity with a product category led to a choice process that was shorter and that focused on fewer alternatives, but these effects were confined to the evaluation stage. The findings are fully compatible with the general view that the choice process is constructed to adapt to the immediate purchase environment. Copyright 1994 by the University of Chicago.
|
| [44] |
Visual Influence on In-store Buying Decisions: An Eye-Track Experiment on the Visual Influence of Packaging Design [J].https://doi.org/10.1362/026725707X250395 URL [本文引用: 1] 摘要
This article describes the impact of visual attention on consumers' in-store buying behaviour. Through an eye-track experiment, it demonstrates the advantage of a behaviour model that addresses visual attention and an increase in visual stimuli during the process. It reveals that consumers exhibit a muddled search strategy where packaging design influences the decision process in several phases. Five phases were found in an in-store decision process, and the post-purchase phase seems to be essential for even low-level in-store decision processes. Further knowledge on packaging design elements is needed for a broader understanding of visual influence during in-store purchase decisions.
|
| [45] |
Eye Movement Monitoring as a Process Tracing Methodology in Decision Making Research [J].https://doi.org/10.1037/a0020692 URL [本文引用: 1] 摘要
ABSTRACT Over the past half century, research on human decision making has expanded from a purely behaviorist approach that focuses on decision outcomes, to include a more cognitive approach that focuses on the decision processes that occur prior to the response. This newer approach, known as process tracing, has employed various methods, such as verbal protocols, information search displays, and eye movement monitoring, to identify and track psychological events that occur prior to the response (such as cognitive states, stages, or processes). In the present article, we review empirical studies that have employed eye movement monitoring as a process tracing method in decision making research, and we examine the potential of eye movement monitoring as a process tracing methodology. We also present an experiment that further illustrates the experimental manipulations and analysis techniques that are possible with modern eye tracking technology. In this experiment, a gaze-contingent display was used to manipulate stimulus exposure during decision making, which allowed us to test a specific hypothesis about the role of eye movements in preference decisions (the Gaze Cascade model; Shimojo, Simion, Shimojo, & Scheier, 2003). The results of the experiment did not confirm the predictions of the Gaze Cascade model, but instead support the idea that eye movements in these decisions reflect the screening and evaluation of decision alternatives. In summary, we argue that eye movement monitoring is a valuable tool for capturing decision makers' information search behaviors, and that modern eye tracking technology is highly compatible with other process tracing methods such as retrospective verbal protocols and neuroimaging techniques, and hence it is poised to be an integral part of the next wave of decision research. (PsycINFO Database Record (c) 2012 APA, all rights reserved)
|
| [46] |
An Eye‐Tracking Study on Information Processing in Risky Decisions: Evidence for Compensatory Strategies Based on Automatic Processes [J].https://doi.org/10.1002/bdm.684 URL [本文引用: 1] 摘要
Abstract Many everyday decisions have to be made under risk and can be interpreted as choices between gambles with different outcomes that are realized with specific probabilities. The underlying cognitive processes were investigated by testing six sets of hypotheses concerning choices, decision times, and information search derived from cumulative prospect theory, decision field theory, priority heuristic and parallel constraint satisfaction models. Our participants completed 40 decision tasks of two gambles with two non-negative outcomes each. Information search was recorded using eye-tracking technology. Results for choices, decision time, the amount of information searched for, fixation durations, the direction of the information search, and the distribution of fixations conflict with the prediction of the non-compensatory priority heuristic and indicate that individuals use compensatory strategies. Choice proportions are well in line with the predictions of cumulative prospect theory. Process measures indicate that individuals thereby do not rely on deliberate calculations of weighted sums. Information integration processes seem to be better explained by models that partially rely on automatic processes such as decision field theory or parallel constraint satisfaction models. Copyright 2010 John Wiley & Sons, Ltd.
|

/
| 〈 |
|
〉 |






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}