王树义 , 廖桦涛, 吴查科
, 廖桦涛, 吴查科
天津师范大学管理学院 天津 300387
Wang Shuyi, Liao Huatao, Wu Chake
中图分类号: TP393
通讯作者:
收稿日期: 2017-09-29
修回日期: 2017-11-6
网络出版日期: 2018-03-25
版权声明: 2018 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】在竞争情报分析中, 改进新闻报道信息主题识别效率, 降低情报搜集成本, 提升分析的即时性。【应用背景】适用于企业竞争情报人员通过新闻媒体对企业自身和竞争对手的报道抓取和主题识别, 及时感知重要动态。【方法】使用情感分析API对爬取的新闻报道数据做出分类, 利用LDA识别主题, 并进行可视化分析。采用Python完成数据采集、清洗、分析与可视化等流程。【结果】从共享单车新闻中, 识别出正负面情绪的不同主题, 并且找出对应的主要特征词汇。【结论】基于情感分类的主题挖掘方法有助于企业聚焦自身与竞争对手的主要优势与问题, 可以改进环境扫描与竞争情报的时效性和准确性。
关键词:
Abstract
[Objective] This paper aims to improve the efficiency of topic modeling from news reports, and reduce the cost of competitive intelligence analysis. [Context] The proposed method could help competitive intelligence analysts accomplish environmental scanning tasks with the help of news reports. [Methods] First, we retrieved news stories with the help of a web crawler. Then, we categorized these articles based on a sentiment analysis API. Third, we identified and visualized news topics with the help of Latent Dirichlet Allocation method. We used Python to finish the data collection, cleansing, analyzing and visualizing jobs. [Results] We identified positive and negative sentiments as well as related keywords from news reports on the bike-sharing industry. [Conclusions] The proposed topic mining method based on sentiment analysis helps enterprises identify competitive advantages. It also improves the effectiveness of environmental scanning for competitive intelligence.
Keywords:
企业的竞争环境瞬息万变, 及时把握企业产品或者服务的优缺点, 特别是与竞争对手进行比对, 将使企业在竞争中获得优势。传统的大型企业竞争情报部门需要耗用大量资金、人力和技术成本完成这一功能, 而中小企业, 尤其是初创公司往往无法担负如此高昂的成本, 因此会在竞争中处于不利地位[1,2]。
信息技术的发展, 特别是大数据开源分析技术的普及, 有助于扭转这一信息不对称的竞争局面。目前已有不少研究利用网络数据和免费的工具, 实时分析企业的产品、服务、口碑, 甚至识别竞争对手。其中, 文本挖掘技术, 特别是情感分析技术发挥了很大作用。文本挖掘的对象丰富多样, 主要包括商品评论和社交媒体数据等[3,4,5,6,7,8,9,10]。
然而, 社交媒体充斥了大量噪声, 可能会对分析结果造成干扰。商品的评论中也有许多不真实、不客观的内容。不加区分地进行分析, 会给分析结果的真实性和准确性带来损失。这些现象已进入了情报学研究者的视野[11,12,13,14]。正式的新闻报道来自于权威媒体, 其真实性、客观性因为媒体声誉的担保与工作流程的规约, 一般会更有保障。
有些突发性的新闻报道, 是企业危机公关等关键职能的基础和保障[15]。如果没有及时处理, 可能会给企业造成非常重大的损失[16]。新闻报道的内容发布频率高, 且来源众多。如果采用人工处理方式进行阅读和分析, 时效性会有欠缺, 而且成本很高。因而对新闻报道信息进行适当的自动化分析, 有助于改善竞争情报工作的效果。
本文提出在篇章级情感分类的基础上, 利用开源数据分析与可视化工具, 对不同情感类别中的新闻进行主题挖掘。该方法可以帮助企业竞争情报人员使用低成本的即时性分析手段, 随时监控新闻报道中的重要话题, 并且与竞争对手的相关新闻进行对比, 从而有效扫描竞争环境的变化。并以共享单车企业作为样例进行实践分析, 以验证本方法的有效性。
竞争情报领域对情感分析工具的利用已经有很多成功案例。王伟等在研究中识别出评论信息中蕴含的比较观点, 并将其归结为产品竞争力的体现; 利用数据挖掘和情感分析技术, 分析评论信息中的“比较观点对”, 对产品竞争优势做出识别[4]。肖璐等尝试利用用户评论数据, 以情感分析技术设计特征情感权重算法, 利用产品向量的相似度, 挖掘类似或互补的商品与服务, 从而发现产品级竞争对手[3]。在社交媒体广泛应用的时代, 单一从用户评论信息中采集竞争情报是不够全面的。有学者采用Twitter和Facebook数据挖掘用户对于不同披萨连锁店的喜好程度[7], 在后续研究中, 又将其扩展为社交媒体信息情感分析框架[8]。
但是通过对于领域文献的梳理, 笔者发现了绝大部分研究采用的文本来源, 都是单位字数很少的社交媒体数据或者是评论数据[3,4,5,6,7,8,9,10]。而权威性与可靠性更高的新闻等长文本, 在现有的竞争情报情感分析研究中, 被用作信息来源的几率很低。
正如唐晓波等指出, 目前“对于长文本的细粒度情感分析是情感分析的难点问题”, 它们“包含许多非观点内容以及多个评价对象, 观点及情感表达也没有短文本明显”, 目前的主流工具尚不足以精确处理[5]。研究者转而将情感分析的来源放在技术上更为可行的短文本上。
但是真实竞争环境中的企业却不能只分析短文本, 而完全忽视正式新闻报道等长文本信息[17,18,19,20,21]。篇章级的情感分析虽然无法精准刻画企业优势与劣势的关键点, 但是却可以对新闻报道做出大致分类[22]。将正面报道和负面报道区别对待, 将为之后的主题建模提供良好的基础和前提条件。
主题识别是目前机器学习领域的一项热门技术。自从Latent Dirichlet Allocation (LDA)方法提出后, 便在各个领域迅速应用[23]。竞争情报领域也采用LDA方法, 挖掘与识别不同信息来源的主题。
刘启华提出利用LDA和领域本体的方法, 构建竞争情报的采集系统, 实验结果表明该系统可以提升主题获取率, 其分析数据是Web页面和Web连接[24]。Shi等提出利用企业业务描述等非结构化数据分析与LDA主题建模手段, 量化企业在产品、市场和科技空间中的位置, 从而为美国高科技产业公司提供竞争情报[25]。Wang等提出抽取LTE专利内容中的科技词汇等信息, 采用扩展LDA模型分析不同专利之间的联系[26]。
将LDA与情感分析手段相结合的研究目前比较少见。国内潘云仙等基于LDA模型提出的JST模型, 可以改进新闻文本情感分类效果[27]。这与本文研究的主题识别的目标关联较小。国外Calheiros等对于用户评论的分析采用情感分类基础上的主题识别, 但是其研究对象依然是短文本, 而且缺乏足够直观的可视化结果[28]。
针对LDA的超参数调整, 是一个至今没有得到完美解决的难点问题。主题数量需要尝试不同取值, 并且通过领域专家的人工审核。过程繁琐而且不够直观[29]。Sievert等开发了一种LDA可视化分析框架, 可以直观展现分类的情况, 包括主题间距、主题包含文献数量、描述主题词语序列等; 可以动态调节参数, 查看主题建模结果[30]。本文将其纳入研究流程, 以便快捷、直观而高效地调节LDA主题数量参数。
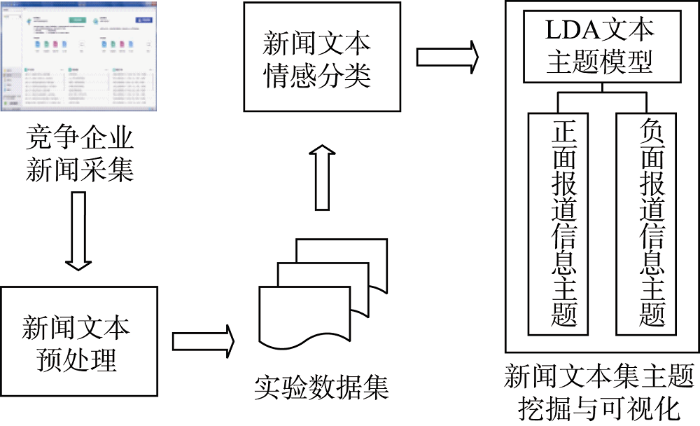
本文的整体技术思路如图1所示。
针对竞争企业新闻情感分类的主题挖掘主要分为以下4个步骤:
(1) 竞争企业新闻采集
在权威新闻网站中, 检索竞争企业报道。使用网络爬虫采集新闻报道的文本数据, 分别以新闻标题、发表时间、正文内容三个数据字段获取对应的数据元素。为了方便采集, 本文利用八爪鱼Web爬虫进行新闻数据爬取。
(2) 新闻文本预处理
采集完成后, 新闻条目以结构化形式保存在电子表格中。丢弃掉爬取异常导致的缺失条目, 剔除可能出现的重复数据。将日期格式转化为计算机程序可以识别的形式。对于同时出现两个竞争企业关键词的报道, 依据关键词出现频率, 将其主要描述对象划归为某一企业。
(3) 新闻文本情感分类
使用中文新闻文本情感自动化分类模型, 对实验数据集进行情感分类。获得每篇新闻文本的情感概率值, 依据模型的划分标准, 将不同企业的新闻报道分别分为正、负面两种情感文本集合。
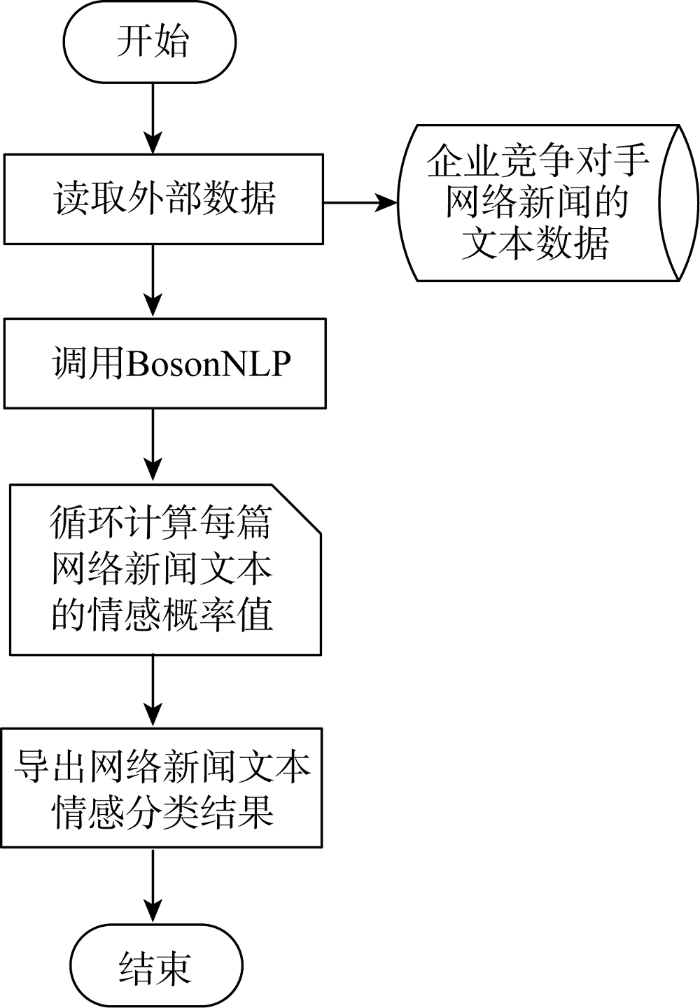
如图2所示, 采用BosonNLP中文语义开放平台的新闻情感分析模型对新闻文本进行篇章级情感分类。该模块已对数十万人工标注过的新闻语料进行训练, 情感分类准确度可达85%-90%。
(4) 新闻文本集主题挖掘与可视化
分别对不同企业、不同情感类别的整合后的新闻文本集合进行中文分词。本文采用常见的“结巴分词”(jieba)的Python包。其特点是免费易用。
对于分词后的结果, 处理停用词并且构建检索词频率矩阵(Term Frequency Matrix)。本文采用两种停用词去除方式。
①去除全局停用词。结合哈尔滨工业大学停用词表、四川大学机器智能实验室停用词库和百度停用词表, 将中文语料中常见的停用词统一去除。
②去除局部停用词。针对不同领域的新闻内容, 通过调节文本向量化函数中的max_df和min_df阈值, 去除全部文档内出现几率过大或者过小的词汇。两个参数的取值范围为0-1之间, 代表某个词汇出现的文档占全部文档的比例。局部停用词剔除的词汇要么过于普遍, 缺乏针对性; 要么过于罕见, 而LDA模型对于这些词汇比较敏感, 容易捕捉到噪声。
利用LDA模型对向量化后的检索词频率矩阵进行主题挖掘, 如公式(1)所示。
$\begin{align} & P(W,Z,\theta ,\phi ;\alpha ,\beta )= \\ & \prod\limits_{i=1}^{K}{P({{\phi }_{i}};\beta )}\prod\limits_{j=1}^{M}{P({{\theta }_{j}};\alpha )}\prod\limits_{t=1}^{N}{P({{Z}_{j,t}}|{{\theta }_{j}})P({{W}_{j,t}}|\phi {{z}_{j,t}})} \\ \end{align}$ (1)
其中, K为主题数量, M为文档数量, N为全部词数量, α为不同主题在文档中分布的先验权重, β为单词在主题中分布的先验权重, θj为文档j中主题分布概率, ϕi为主题i中单词分布概率, Zj,t为t单词在j文档中对应的主题数量, Wj,t为文档j中单词t出现的次数。
LDA中的超参数(Hypter-Parameters)调整是一项比较困难的工作。LDA对各项参数极为敏感, 轻微的调整会令结果差异显著。实践中, 竞争情报分析人员没有条件在这项枯燥乏味的工作中投入过多时间和精力, 否则会令主题识别的效率非常低下。主流的LDA工具都提供了默认参数设置, 研究人员只需要设定一个必要的参数主题数量K。
主题数量设置可以有许多种选择。如何验证设置的正确性是困扰研究者的难点问题。Underwood指出, “明显单一的主题一致性虽强, 但是从中难以找到令人激动的新信息”, 而那些“看似模糊的词语集合中, 往往包含了前人不曾认识的洞察”[31]。
本文采用的主题数量设定方式, 是将主题建模结果可视化, 在二维空间上查看主题距离与交叠程度。
在LDA可视化工具研究中, Sievert等提出公式(2)[30]。
$r(w,k|\lambda )=\lambda \log ({{\phi }_{kw}})+(1-\lambda )\log \left( \frac{{{\phi }_{kw}}}{{{p}_{w}}} \right)$ (2)
其中, k表示某个主题, w表示单词, r表示单词与主题关联程度, ϕkw表示在主题k中单词w的概率, λ决定主题k下单词w与其全局出现概率的相对权重。当λ=1时, 主题下关键词关联程度为该主题出现概率; 当λ=0时, 主题下关键词关联程度为其全局出现概率。
将LDA主题识别结果(调整了λ参数之后)交由领域专家进行人工验证, 以确认本方法的有效性。
2016年底, 中国共享单车市场整体用户数量已达到1886.4万。共享单车品牌ofo与摩拜在获得新一轮融资后, 两者的市场份额之和已超过九成。
以中国新闻网官方网站(简称“中新网”)作为数据来源。2017年8月, 在该网站分别以“ofo”和“摩拜”为关键词进行新闻检索, 使用八爪鱼网页采集器对新闻进行爬取。去除只有图片或者视频以及无关的新闻报道后, 分别获得相关报道130篇和150篇。
利用Python数据分析框架Pandas, 从两个集合中共找到12篇重复新闻。通过关键词频统计的方法, 确定交叠新闻的归属。这些交叉部分中, 包含关键词“ofo”(已考虑大小写因素)多于“摩拜”的为3篇; 包含“摩拜”多于“ofo”的为6篇。其余3篇两者词频相当, 被暂时移除。经过数据清理, 保留“ofo”新闻数量为124篇, “摩拜”文章数量为147篇。这两个集合里不再有任何重叠。
调用BosonNLP的情感分析模块, 分别对124篇“ofo”新闻和147篇“摩拜”新闻进行情感分类并计算相应的情感概率值。BosonNLP依据预训练模型, 对文本中出现的情感词汇进行加权分析, 获得的情感分析结果呈现为取值区间从0到1的实数。结果在[0, 0.5]之间的情感概率值判定为负面情感, 结果在(0.5, 1]之间的情感概率值判定为正向情感。
本文临时将情感分析结果数值整体下调0.5, 使得正向情感的结果依然为正数, 负向情感的结果变为负数, 以获得更为直观的可视化效果。
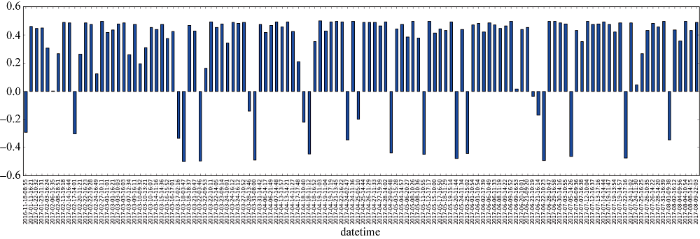
图3以时间顺序, 显示了ofo新闻的情感分析结果。可以看到, 整体上, 正面新闻的数量更多。负面新闻出现的情况并不集中。大部分情感分析的结果极性较强。虽有部分情感取值趋向于0, 但是这样的结果并不占主流, 使得分类结果比较鲜明。2017年的3月、5月和6月分别较为集中地出现了几次负面新闻。
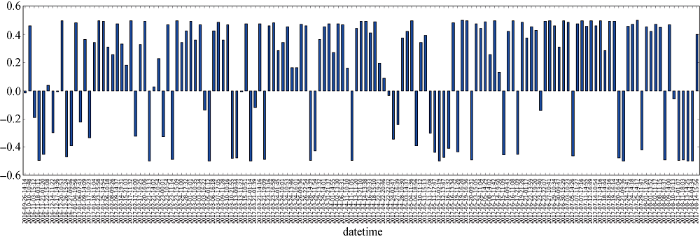
图4显示了摩拜新闻的情感分析结果。摩拜单车的正向情感新闻报道数量同样比负面情感新闻报道更多。但是可以清楚看到, 摩拜单车负面新闻出现的比率更大, 而且更加集中。尤其在2017年的2月和4月, 负面新闻报道较多。
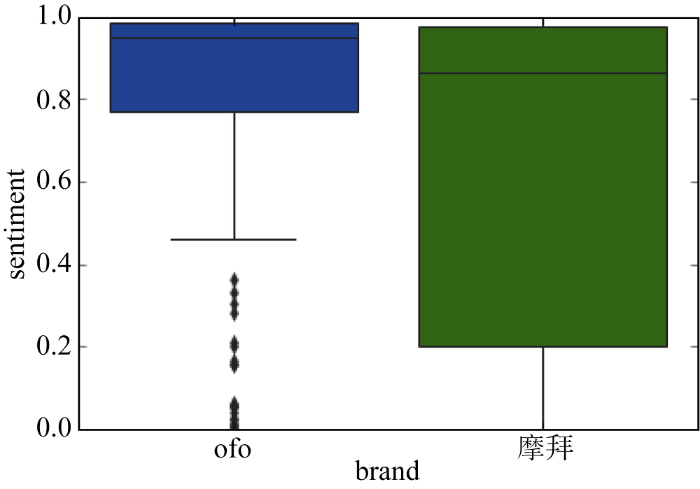
为了验证直观对比感受, 使用箱形图描绘了两种共享单车新闻情感分析结果的分布趋势。如图5所示, ofo的情感结果数值分布更为集中, 而摩拜的分析结果较为分散。ofo情感分析均值要高于摩拜, 第一四分位数几乎接近于中性(0.5)。但是有一些比较明显的异常点, 属于负面情感。
经过情感分类, ofo数据集包含正向情感新闻103篇, 负向情感新闻21篇; 摩拜数据集包含正向情感新闻98篇, 负向情感新闻49篇。本研究对这4类信息分别进行存储, 以进行主题建模。
以ofo正向情感数据集为例, 首先采用结巴分词, 将新闻文本全文分解为单词(token), 然后利用scikit-learn向量化工具CounterVectorizer, 设定max_df为0.6, min_df为0.1, 将文档集合向量化。
调用基于Python的机器学习工具包scikit-learn中的LatentDirichletAllocation函数, 设定主题数量为4个, 经过最大50轮次的迭代过程, 获得初步的主题识别结果。
因为LDA属于非监督学习, 因而结果中并不能包含主题的显式名称标记, 只有一系列对应的高频关键字描述该主题。本文指定主题输出关键字数量为20个, 其中某一主题(主题之间并没有顺序)的描述关键字序列为: “数据北京技术运营企业合作绿色智能全国未来连接方式交通计划社会管理联网滴滴20创始人”。
在确定主题内容之前, 需要对主题识别的结果进行验证。本文采用的是pyLDAvis软件包, 进行交互式可视化检验。该软件包原本是R环境下的工具, 后来被移植到Python下。
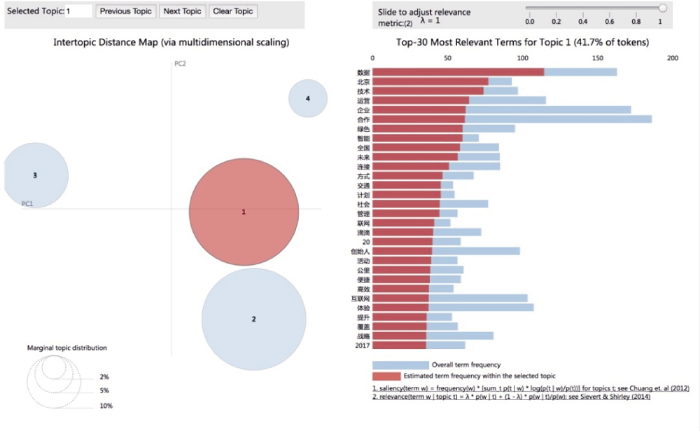
将LDA分析结果作为输入传递进入pyLDAvis, 获得的可视化图形如图6所示。
从图6可以看出, pyLDAvis工具对不同主题进行编号。它直观地提示用户不同主题在二维向量空间上的距离。不同圆圈的大小代表主题包含文章的数量。
在二维向量空间上, 4个主题间有明显的差别, 而且没有交叠。这种结果说明, 指定4个主题类别的结果是可接受的。注意: LDA模型中不存在“完美结果”的概念。图6中主题1、主题2相距较近, 主题3、主题4的位置更加远离中心。
当鼠标悬停在主题1上时, 右侧的列表显示描述该主题的关键词。经检验与之前文本形式输出的关键词列表吻合。关键词右侧的蓝色柱状图, 统计了词频。而红色的柱状图, 统计了该关键词在本主题之内的词频。
反之, 当鼠标悬停在右侧的关键词上时, 左侧的主题可视化图形会发生变化, 如图7所示。
在图7中, 将鼠标悬停在“芝麻”这个词上, 左侧的主题1、主题4圆圈消失, 主题3变大, 主题2变小。这意味着“芝麻”这个关键词仅仅出现在主题2、主题3中, 其中主题3出现的频率要远远高于主题2。
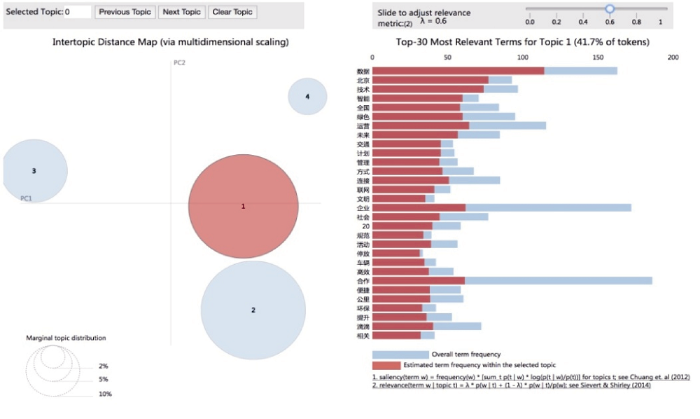
在右上方拖曳条, 可以调整λ参数。当λ设定为1时, 显示结果与LDA输出高频词环节相同, 关键词排序仅仅依靠词语出现的频度; 当λ趋近于0时, 那些仅仅在本主题中出现的独特关键词的位置排序会显著提升。
λ的选择并没有一定之规。在可视化图形上, 可以通过调整λ参数, 寻找潜在主题的规律。如图8所示, 将λ调整为0.6左右时, 词语排序出现显著变化, “智能”替代了“运营”, 提升到第4的位置。从新的关键词列表中, 可以估计主题1对应共享单车带来的智能交通与绿色出行, 因而这一部分新闻会出现在正向情感分类结果中。
按照同样的方式, 对ofo和摩拜的正、负面新闻均进行主题挖掘, 通过互动可视化方式检验分类可行性, 以及利用关键词估计主题含义。最终结果如表1所示。
表1 “ofo”与“摩拜”正负面报道信息的相关主题
| 分类 | ofo | 摩拜 |
|---|---|---|
| 正面报道 信息主题 | 智能绿色 押金支付 定位系统 公司合作 | 红包福利 合作伙伴 车身结构 海外运营 市场份额 |
| 负面报道 信息主题 | 单车停放 交通事故 软件漏洞 | 单车停放 支付诈骗 软件漏洞 专利侵权 |
通过表1中主题的对比, 可以看出新闻报道中提及的ofo主要优势所在, 包括“智能绿色”、“押金支付”等。摩拜的“红包福利”受到赞扬, “车身结构”被反复提及, 而且“市场份额”与“海外运营”也得到媒体的正面报道。二者共有的特色, 包括“合作伙伴”等。共享单车的发展, 为自行车企业带来了很多的订单。
相比正面报道, 竞争情报工作者更需要留意企业负面报道。ofo和摩拜最为诟病的方面就是“停放问题”, 这与人们的观察和常识相吻合。另外二者都遭受到“软件漏洞”带来的不良影响。ofo的“交通事故”问题, 摩拜的“支付诈骗”与“专利侵权”问题作为各自的特色负面新闻报道主题, 需要引起竞争情报工作人员的警觉。
本研究请教了对共享单车跟踪研究的新闻领域专业人士, 对主题挖掘结果进行检验, 并得到肯定的结果, 证明本文所采用的技术路线在实践中的有效性。
本文通过情感分类及主题挖掘等文本挖掘技术方法, 对企业竞争对手的网络新闻信息进行分析。以共享单车的两个主要竞争对手“ofo”与“摩拜”的新闻为数据来源, 通过自动化流程步骤, 辅以可视化交互验证手段, 比较全面地分析出新闻报道中蕴含的共享单车主要竞争企业正面与负面报道主题。本方法可以为竞争情报从业人员提供简便、快捷和低成本的新闻文本信息分析手段。
本研究的局限性在于, 分析流程依赖于自动化情感分类与主题挖掘算法的准确性; 情感分类粒度为篇章级, 对于文本中不同部分的权重并不能更加细致地加以区分。
在后续研究中, 将尝试借助最新的自然语言处理科研成果, 结合知识图谱、深度学习等技术手段, 细化情感分析的粒度, 以期对新闻报道的情感与主题, 获得更为精确的分析结果。
王树义, 廖桦涛: 提出研究思路, 设计研究方案;
王树义, 廖桦涛, 吴查科: 进行实验, 采集、清洗和分析数据;
廖桦涛, 王树义: 论文起草;
王树义, 吴查科: 论文最终版本修订。
所有作者声明不存在利益冲突关系。
支撑数据见期刊网络版http://www.infotech.ac.cn。
[1] 廖桦涛. ofo正面新闻.xlsx. ofo正面新闻报道.
[2] 廖桦涛. ofo负面新闻.xlsx. ofo负面新闻报道.
[3] 廖桦涛. 摩拜正面新闻.xlsx. 摩拜正面新闻报道.
[4] 廖桦涛. 摩拜负面新闻.xlsx. 摩拜负面新闻报道.
| [1] |
Competitive Intelligence-Conducting an Analysis of a Business Environment [D]. |
| [2] |
Organizational Social Capital as a Moderator for the Effect of Entrepreneurial Orientation on Competitive Intelligence [J].https://doi.org/10.1080/0965254X.2015.1076884 URL [本文引用: 1] 摘要
AbstractChange force in entrepreneurial strategic posture navigates an organization toward market forces, especially competitive force, through which opportunities for its sustainable growth can be identified. One purpose of this study is thus to investigate the role of entrepreneurial orientation (EO) in cultivating competitive intelligence (CI). The study also seeks to establish the moderating role of organizational social capital (OSC) for the effect of EO on CI. Cross-sectional data from respondents from chemical companies in Vietnam business context were analyzed through hierarchical multiple regression. The study provided evidence on the predictive role of EO for CI. The two components of OSC – trust and goal congruence – were also found to play a moderating role for the EO–CI relationship.
|
| [3] |
基于情感分析的企业产品级竞争对手识别研究——以用户评论为数据源 [J].https://doi.org/10.13266/j.issn.0252-3116.2016.01.012 URL [本文引用: 3] 摘要
[目的 /意义]针对传统方法的不足,提出一种以用户评论为数据源的企业产品级竞争对手识别方法。[方法/过程]首先,根据企业分析维度确定候选竞争产品,进行相关评论文本采集;其次,利用信息抽取技术从本企业产品评论中抽取用户较为关注的产品特征;然后,基于情感分析技术设计特征情感权重算法;利用该算法对本企业产品特征进行优劣势分析,获取优势与劣势特征集,完成待分析产品向量空间表示与相似度计算;分析计算结果,挖掘出与本企业产品优势相似及劣势互补的候选竞争产品,并选择优势相似且劣势互补的产品为主要竞争对手,其他优势相似的产品为次要竞争对手。在实证部分,选择"红米Note"手机为分析对象,以"淘宝""京东""中关村在线"多源评论为数据源,利用基于情感分析的竞争对手识别方法挖掘该产品的主要和次要竞争对手。[结果/结论]本文的基于情感分析的竞争对手识别方法能够实现企业产品级竞争对手的识别与分析。
Study on Identification of Enterprise Product Level Competitor Based on Sentiment Analysis: Taking User Reviews for Data Resources [J].https://doi.org/10.13266/j.issn.0252-3116.2016.01.012 URL [本文引用: 3] 摘要
[目的 /意义]针对传统方法的不足,提出一种以用户评论为数据源的企业产品级竞争对手识别方法。[方法/过程]首先,根据企业分析维度确定候选竞争产品,进行相关评论文本采集;其次,利用信息抽取技术从本企业产品评论中抽取用户较为关注的产品特征;然后,基于情感分析技术设计特征情感权重算法;利用该算法对本企业产品特征进行优劣势分析,获取优势与劣势特征集,完成待分析产品向量空间表示与相似度计算;分析计算结果,挖掘出与本企业产品优势相似及劣势互补的候选竞争产品,并选择优势相似且劣势互补的产品为主要竞争对手,其他优势相似的产品为次要竞争对手。在实证部分,选择"红米Note"手机为分析对象,以"淘宝""京东""中关村在线"多源评论为数据源,利用基于情感分析的竞争对手识别方法挖掘该产品的主要和次要竞争对手。[结果/结论]本文的基于情感分析的竞争对手识别方法能够实现企业产品级竞争对手的识别与分析。
|
| [4] |
面向竞争力的特征比较网络: 情感分析方法 [J].Comparative Network for Product Competition in Feature-levels Through Sentiment Analysis [J]. |
| [5] |
细粒度情感分析研究综述 [J].Research Review on Fine-grained Sentiment Analysis [J]. |
| [6] |
在线中文用户评论研究综述: 基于情感计算的视角 [J].Research on Online Users’ Reviews in Chinese: Basing on the Perspective of Affective Computing [J]. |
| [7] |
Social Media Competitive Analysis and Text Mining: A Case Study in the Pizza Industry [J].https://doi.org/10.1016/j.ijinfomgt.2013.01.001 URL [本文引用: 3] 摘要
Social media have been adopted by many businesses. More and more companies are using social media tools such as Facebook and Twitter to provide various services and interact with customers. As a result, a large amount of user-generated content is freely available on social media sites. To increase competitive advantage and effectively assess the competitive environment of businesses, companies need to monitor and analyze not only the customer-generated content on their own social media sites, but also the textual information on their competitors' social media sites. In an effort to help companies understand how to perform a social media competitive analysis and transform social media data into knowledge for decision makers and e-marketers, this paper describes an in-depth case study which applies text mining to analyze unstructured text content on Facebook and Twitter sites of the three largest pizza chains: Pizza Hut, Domino's Pizza and Papa John's Pizza. The results reveal the value of social media competitive analysis and the power of text mining as an effective technique to extract business value from the vast amount of available social media data. Recommendations are also provided to help companies develop their social media competitive analysis strategy. (C) 2013 Elsevier Ltd. All rights reserved.
|
| [8] |
A Novel Social Media Competitive Analytics Framework with Sentiment Benchmarks [J].https://doi.org/10.1016/j.im.2015.04.006 URL [本文引用: 3] 摘要
In today's competitive business environment, there is a strong need for businesses to collect, monitor, and analyze user-generated data on their own and on their competitors’ social media sites, such as Facebook, Twitter, and blogs. To achieve a competitive advantage, it is often necessary to listen to and understand what customers are saying about competitors’ products and services. Current social media analytics frameworks do not provide benchmarks that allow businesses to compare customer sentiment on social media to easily understand where businesses are doing well and where they need to improve. In this paper, we present a social media competitive analytics framework with sentiment benchmarks that can be used to glean industry-specific marketing intelligence. Based on the idea of the proposed framework, new social media competitive analytics with sentiment benchmarks can be developed to enhance marketing intelligence and to identify specific actionable areas in which businesses are leading and lagging to further improve their customers’ experience using customer opinions gleaned from social media. Guided by the proposed framework, an innovative business-driven social media competitive analytics tool named VOZIQ is developed. We use VOZIQ to analyze tweets associated with five large retail sector companies and to generate meaningful business insight reports.
|
| [9] |
Gaining Competitive Intelligence from Social Media Data: Evidence from Two Largest Retail Chains in the World [J]. |
| [10] |
The Power of Social Media Analytics [J].https://doi.org/10.1145/2602574 URL [本文引用: 2] 摘要
ABSTRACT In this paper, we explore how the explosion in social media necessitates the use of social media analytics; we explain the underlying stages of the social media analytics process; we describe the most common social media analytic techniques in use; and we discuss the ways in which social media analytics create business value.
|
| [11] |
Overview of the Special Issue on Trust and Veracity of Information in Social Media [J].https://doi.org/10.1145/2870630 URL [本文引用: 1] 摘要
Abstract CCS Concepts: 61 Information systems→Information retrieval; Web searching and information discovery; 61 Human-centered computing→Social networking sites.
|
| [12] |
Social Media and Fake News in the 2016 Election [J].https://doi.org/10.1257/jep.31.2.211 URL [本文引用: 1] 摘要
Following the 2016 U.S. presidential election, many have expressed concern about the effects of false stories (“fake news”), circulated largely through social media. We discuss the economics of fake news and present new data on its consumption prior to the election. Drawing on web browsing data, archives of fact-checking websites, and results from a new online survey, we find: (i) social media was an important but not dominant source of election news, with 14 percent of Americans calling social media their “most important” source; (ii) of the known false news stories that appeared in the three months before the election, those favoring Trump were shared a total of 30 million times on Facebook, while those favoring Clinton were shared 8 million times; (iii) the average American adult saw on the order of one or perhaps several fake news stories in the months around the election, with just over half of those who recalled seeing them believing them; and (iv) people are much more likely to believe stories that favor their preferred candidate, especially if they have ideologically segregated social media networks.
|
| [13] |
Fake It till You Make It: Reputation, Competition, and Yelp Review Fraud [J].https://doi.org/10.2139/ssrn.2293164 URL [本文引用: 1] 摘要
Consumer reviews are now part of everyday decision-making. Yet, the credibility of these reviews is fundamentally undermined when businesses commit review fraud, creating fake reviews for themselves or their competitors. We investigate the economic incentives to commit review fraud on the popular review platform Yelp, using two complementary approaches and datasets. We begin by analyzing restaurant reviews that are identified by Yelp's filtering algorithm as suspicious, or fake ? and treat these as a proxy for review fraud (an assumption we provide evidence for). We present four main findings. First, roughly 16% of restaurant reviews on Yelp are filtered. These reviews tend to be more extreme (favorable or unfavorable) than other reviews, and the prevalence of suspicious reviews has grown significantly over time. Second, a restaurant is more likely to commit review fraud when its reputation is weak, i.e., when it has few reviews, or it has recently received bad reviews. Third, chain restaurants ? which benefit less from Yelp ? are also less likely to commit review fraud. Fourth, when restaurants face increased competition, they become more likely to receive unfavorable fake reviews. Using a separate dataset, we analyze businesses that were caught soliciting fake reviews through a sting conducted by Yelp. These data support our main results, and shed further light on the economic incentives behind a business's decision to leave fake reviews.
|
| [14] |
E-WOM and Accommodation: An Analysis of the Factors That Influence Travelers’ Adoption of Information from Online Reviews [J].https://doi.org/10.1177/0047287513481274 URL [本文引用: 1] |
| [15] |
Crisis Communications: A Casebook Approach [M]. |
| [16] |
The Mediating Role of the News in the BP Oil Spill Crisis 2010: How US News is Influenced by Public Relations and in Turn Influences Public Awareness, Foreign News, and the Share Price [J].https://doi.org/10.1177/0093650213510940 URL [本文引用: 1] |
| [17] |
Using Environmental Scanning to Collect Strategic Information: A South African Survey [J].https://doi.org/10.1016/j.ijinfomgt.2015.08.005 URL [本文引用: 1] |
| [18] |
The Framework of Network Public Opinion Monitoring and Analyzing System Based on Semantic Content Identification [J].https://doi.org/10.4156/jcit.vol5.issue10.1 URL [本文引用: 1] 摘要
Abstract In this study, we use the computable general equilibrium (CGE) model to examine welfare and growth effects of expanding grain-based fuel ethanol production in China. The results show that reasonable development of grain-based fuel ethanol will accelerate China's economy, improve rural household income, and narrow the gap between the rich and the poor. However, expanding the production of grain-based fuel ethanol will also stimulate consumer price index (CPI).
|
| [19] |
BizPro: Extracting and Categorizing Business Intelligence Factors from Textual News Articles [J].https://doi.org/10.1016/j.ijinfomgt.2014.01.001 URL [本文引用: 1] 摘要
Company movements and market changes often are headlines of the news, providing managers with important business intelligence (BI). While existing corporate analyses are often based on numerical financial figures, relatively little work has been done to reveal from textual news articles factors that represent BI. In this research, we developed BizPro , an intelligent system for extracting and categorizing BI factors from news articles. BizPro consists of novel text mining procedures and BI factor modeling and categorization. Expert guidance and human knowledge (with high inter-rater reliability) were used to inform system development and profiling of BI factors. We conducted a case study of using the system to profile BI factors of four major IT companies based on 6859 sentences extracted from 231 news articles published in major news sources. The results show that the chosen techniques used in BizPro – Na07ve Bayes (NB) and Logistic Regression (LR) – significantly outperformed a benchmark technique. NB was found to outperform LR in terms of precision, recall, F -measure, and area under ROC curve. This research contributes to developing a new system for profiling company BI factors from news articles, to providing new empirical findings to enhance understanding in BI factor extraction and categorization, and to addressing an important yet under-explored concern of BI analysis.
|
| [20] |
Mining Company Competitor/Collaborator Network from Online News for Competitive Intelligence [C]// |
| [21] |
Mining Competitor Relationships from Online News: A Network-Based Approach [J].https://doi.org/10.1016/j.elerap.2010.11.006 URL [本文引用: 1] 摘要
Identifying competitors is important for businesses. We present an approach that uses graph-theoretic measures and machine learning techniques to infer competitor relationships on the basis of structure of an intercompany network derived from company citations (cooccurrence) in online news articles. We also estimate to what extent our approach complements the commercial company profile data sources, such as Hoover’s and Mergent.
|
| [22] |
Thumbs up?: Sentiment Classification Using Machine Learning Techniques [C]// |
| [23] |
Latent Dirichlet Allocation [J]. |
| [24] |
LDA 和领域本体的竞争情报采集研究 [J].A Study of Competitive Intelligence Acquisition System Based on LDA and Domain Ontology [J]. |
| [25] |
Toward a Better Measure of Business Proximity: Topic Modeling for Industry Intelligence [J].https://doi.org/10.25300/MISQ/2016/40.4.11 URL [本文引用: 1] 摘要
In this article, we propose a new data-analytic approach to measure firms’ dyadic business proximity. Specifically, our method analyzes the unstructured texts that describe firms’ businesses using the statistical learning technique of topic modeling, and constructs a novel business proximity measure based on the output. When compared with existent methods, our approach is scalable for large datasets and provides finer granularity on quantifying firms’ positions in the spaces of product, market, and technology. We then validate our business proximity measure in the context of industry intelligence and show the measure’s effectiveness in an empirical application of analyzing mergers and acquisitions in the U.S. high technology industry. Based on the research, we also build a cloud-based information system to facilitate competitive intelligence on the high technology industry.
|
| [26] |
Identifying Technological Topics and Institution-Topic Distribution Probability for Patent Competitive Intelligence Analysis: A Case Study in LTE Technology [J].https://doi.org/10.1007/s11192-014-1342-3 URL [本文引用: 1] 摘要
An extended latent Dirichlet allocation (LDA) model is presented in this paper for patent competitive intelligence analysis. After part-of-speech tagging and defining the noun phrase extraction rules, technological words have been extracted from patent titles and abstracts. This allows us to go one step further and perform patent analysis at content level. Then LDA model is used for identifying underlying topic structures based on latent relationships of technological words extracted. This helped us to review research hot spots and directions in subclasses of patented technology in a certain field. For the extension of the traditional LDA model, another institution-topic probability level is added to the original LDA model. Direct competing enterprises鈥 distribution probability and their technological positions are identified in each topic. Then a case study is carried on within one of the core patented technology in next generation telecommunication technology-LTE. This empirical study reveals emerging hot spots of LTE technology, and finds that major companies in this field have been focused on different technological fields with different competitive positions.
|
| [27] |
JST 模型的新闻文本的情感分类研究 [J].https://doi.org/10.3969/j.issn.1671-6841.2015.01.014 URL [本文引用: 1] 摘要
使用JST模型对中文新闻文本进行情感分析,相对于评论文本,新 闻文本主观性比较弱,而且大多是长文本,会影响JST模型的分类性能.给出一种抽取情感主题句的方法,将抽取得到的情感主题句结合现有的JST模型对新闻 文本的情感倾向进行了分析.实验表明,使用情感主题句进行情感分析,避免了与主题情感无关的句子对分析结果的影响,提高了分类准确率.
News-text Sentiment Classification Research Based on JST Model [J].https://doi.org/10.3969/j.issn.1671-6841.2015.01.014 URL [本文引用: 1] 摘要
使用JST模型对中文新闻文本进行情感分析,相对于评论文本,新 闻文本主观性比较弱,而且大多是长文本,会影响JST模型的分类性能.给出一种抽取情感主题句的方法,将抽取得到的情感主题句结合现有的JST模型对新闻 文本的情感倾向进行了分析.实验表明,使用情感主题句进行情感分析,避免了与主题情感无关的句子对分析结果的影响,提高了分类准确率.
|
| [28] |
Sentiment Classification of Consumer-Generated Online Reviews Using Topic Modeling [J].https://doi.org/10.1080/19368623.2017.1310075 URL [本文引用: 1] 摘要
Abstract The development of the Internet and mobile devices enabled the emergence of travel and hospitality review sites, leading to a large number of customer opinion posts. While such comments may influence future demand of the targeted hotels, they can also be used by hotel managers to improve customer experience. In this article, sentiment classification of an eco-hotel is assessed through a text mining approach using several different sources of customer reviews. The latent Dirichlet allocation modeling algorithm is applied to gather relevant topics that characterize a given hospitality issue by a sentiment. Several findings were unveiled including that hotel food generates ordinary positive sentiments, while hospitality generates both ordinary and strong positive feelings. Such results are valuable for hospitality management, validating the proposed approach.
|
| [29] |
Dense Distributions from Sparse Samples: Improved Gibbs Sampling Parameter Estimators for LDA [J].
Abstract: We introduce a novel approach for estimating Latent Dirichlet Allocation (LDA) parameters from collapsed Gibbs samples (CGS), by leveraging the full conditional distributions over the latent variable assignments to efficiently average over multiple samples, for little more computational cost than drawing a single additional collapsed Gibbs sample. Our approach can be understood as adapting the soft clustering methodology of Collapsed Variational Bayes (CVB0) to CGS parameter estimation, in order to get the best of both techniques. Our estimators can straightforwardly be applied to the output of any existing implementation of CGS, including modern accelerated variants. We perform extensive empirical comparisons of our estimators with those of standard collapsed inference algorithms on real-world data for both unsupervised LDA and Prior-LDA, a supervised variant of LDA for multi-label classification. Our results show a consistent advantage of our approach over traditional CGS under all experimental conditions, and over CVB0 inference in the majority of conditions. More broadly, our results highlight the importance of averaging over multiple samples in LDA parameter estimation, and the use of efficient computational techniques to do so.
|
| [30] |
LDAvis: A Method for Visualizing and Interpreting Topics [C]// |
| [31] |
|

/
| 〈 |
|
〉 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}