1 引 言
随着社交网络的发展, 微博、网络评论、论坛互动等短文本数据呈爆发式增长。面对大规模的短文本数据, 需要准确地将其归类, 短文本分类技术发挥着极其重要的作用。同时, 短文本分类也是情感分析、问答系统、对话管理等自然语言处理应用中的关键技术之一。针对短文本分类问题, 传统方法大多是采用向量空间模型(Vector Space Model, VSM)进行文本表示, 通过特征扩展克服特征稀疏所带来的不利影响, 主要方法包括引入外部知识源, 如搜索引擎[1 ] 查询结果、大型语料库[2 ] 等; 或者从短文本自身出发引入主 题[3 ] 、相近词[4 ] 等, 最终利用传统的分类器给出分类结果。此类方法在特征扩展过程中, 对文本相似性判定提出了较高的要求, 同时难以避免引入干扰信息。所以, 通过特征扩展解决短文本分类问题提升效果十分有限。
随着深度学习的快速发展, 以词向量模型为基础的短文本分类方法层出不穷。Kaljahi等[5 ] 提出Any-gram核方法, 用于提取短文本的N-gram[6 ] 特征, 采用双向长短时记忆网络(Bidirectional Long-Short Term Memory Network, BLSTM)进行分类, 在基于主题和句子级的情感分析任务中取得了不错的效果。Kim等[7 ] 使用卷积神经网络(Convolutional Neural Networks, CNN)解决句子分类问题。Lee等[8 ] 结合循环神经网络(Recurrent Neural Network, RNN)和卷积神经网络对短文本进行分类。Hsu等[9 ] 将卷积神经网络和循环神经网络混合, 提出一种结构独立的门表示算法, 用于句子分类。Zhou等[10 ] 将二维最大池化操作引入到双向短时记忆网络(BLSTM), 在时间维度和特征维度上对文本的特征进行提取, 完成文本分类任务。以上方法在文本特征提取过程中, 未考虑词语在语义表示中的重要程度, 容易出现重点词被忽略, 而非重点词被重视等情况, 导致分类效果提升不明显。而注意力机制能够较好地对文本中词语重要程度进行区分, 更符合人类对于语义的认知。
注意力机制源于认知心理学中的人脑注意力机 制[11 ] , 能够有选择性地重点关注源数据的某些部分, 近来已被广泛应用于多种自然语言处理任务。Yang等[12 ] 提出层级注意力模型应用于文章分类。Zhou等[13 ] 在双向长短时记忆网络中引入注意力机制, 用于解决相关性分类问题。Wang等[14 ] 将词向量和主题向量结合作为输入, 在长短时记忆网络(Long-Short Term Memory Network, LSTM)的基础上, 利用注意力机制, 实现主题情感分类。Zhou等[15 ] 提出混合注意力模型, 采用卷积神经网络和循环神经网络提取字符级和词语级语义特征, 通过注意力机制进行混合, 实现中文短文本分类。传统注意力机制将上层输出通过全连接后进行注意力得分计算。然而, 文本中重点词的个数及位置不确定, 传统注意力机制并未充分利用文本的上下文信息。所以, 直接顺序地对上层输出进行注意力分数计算具有一定的局限性。
本文针对短文本篇幅有限、特征稀疏等问题, 提出一种基于双向长短时记忆网络的改进注意力短文本分类模型。针对传统注意力机制的隐层输入进行改进, 将双向长短时记忆网络的正向和反向输出进行融合, 得到每个词语包含上下文信息的语义表示向量, 用于全局权值计算, 从而有效地利用上下文语义信息。
2 相关工作
2.1 长短时记忆网络
长短时记忆网络(LSTM)由循环神经网络发展而来。循环神经网络[16 ] 是一种连续的前向传播神经网络。然而, 循环神经网络存在梯度弥散或者梯度爆炸的问题。为克服这些问题, Hochreiter等[17 ] 于1997年提出长短时记忆网络, 在循环神经网络基础上引入循环记忆神经元(Memory Cell)。LSTM具有学习长依赖性数据特征的能力, 之后, 众多学者对其进行一系列改进。
LSTM利用门结构让信息有选择地影响每个时刻的状态。输入向量包含当前时刻的输入信息和上一时刻的输出信息, 输入门根据输入向量决定这一时刻输入向量中的某些信息将被记录, 同时由输入向量生成候选向量, 会被保存到当前的自循环神经元; 遗忘门根据输入向量决定上一时刻的状态中某些信息将被“遗忘”; 当前时刻的循环单元状态由输入门、遗忘门、上一时刻的保存信息和当前的候选向量共同决定; 最终, 在输出结果中, 输出门根据输入向量决定循环单元状态在当前时刻的哪些信息将被输出送入下一时刻。所以, 该循环单元的状态传递关系取决于三种门的作用。
2.2 双向长短时记忆网络模型
双向长短时记忆网络模型(BLSTM)由两个独立的LSTM构成。输入序列将按照正序和倒序分别输入通过两个LSTM, 对同一时刻的隐层输出进行合并, 从而得到每一时刻的隐层输出向量。
BLSTM的设计理念是使每个时刻所获得特征数据同时拥有过去和将来之间的相关性信息。实验结果表明, 这种神经网络结构模型对文本特征提取效果和性能要优于单个LSTM。BLSTM中的两个LSTM参数相互独立, 但二者共享词向量列表。文本在表达语义的过程中, 关键词语之间间隔或大或小、顺序有前有后。利用BLSTM对序列信息具有部分记忆的能力, 将文本样本通过BLSTM, 对文本相互依赖词语信息进行提取, 从而获得短文本的语义表示。
2.3 注意力机制
注意力机制最早应用于序列转换模型中, 目前, 性能较好的序列转换模型大多基于由循环神经网络和卷积神经网络构成的编码器和解码器, 其中效果最好的模型是通过注意力机制将编码器与解码器进行连接实现的。随着研究的深入, 众多改进的注意力机制被提出并应用于自然语言处理任务中。Lin等[18 ] 提出自注意力机制用于获得句子的向量表示。Daniluk等[19 ] 提出Key-Value Attention应用于神经语言模型。Bahdanau等[20 ] 提出Soft-Attention机制应用于机器翻译任务。Yang等[12 ] 提出涵盖词语级注意力和文档级注意力的层级注意力模型实现文章分类, 其中词语级注意力过程如公式(1)至公式(3)所示。
(1) ${{u}_{t}}=\tanh ({{W}_{w}}{{h}_{t}}+{{b}_{w}})$
(2) ${{\alpha }_{t}}=\frac{\exp (u_{t}^{\mathrm{T}}{{u}_{w}})}{\sum\nolimits_{t}{\exp (u_{t}^{\mathrm{T}}{{u}_{w}})}}$
(3) $H=\sum\limits_{t}{{{\alpha }_{t}}{{h}_{t}}}$
在文本分类过程中, 主观上会根据文本语义决定其类别。而文本语义通常由文本的主语、谓语等关键词所决定。因此, 句中的所有词对于句子语义的表达所提供的信息是不同的。利用注意力机制根据词语在表达句子意思中的重要程度分配权重, 重视对句意表达重要的词, 弱化对句意表达不重要的词, 有助于获得包含更具语义特征的表示。所以, 本文基于BLSTM, 对注意力机制进行改进, 提出一种采用改进注意力的短文本分类模型, 完成短文本分类任务。
3 基于双向长短时记忆的改进注意力模型
3.1 模型结构
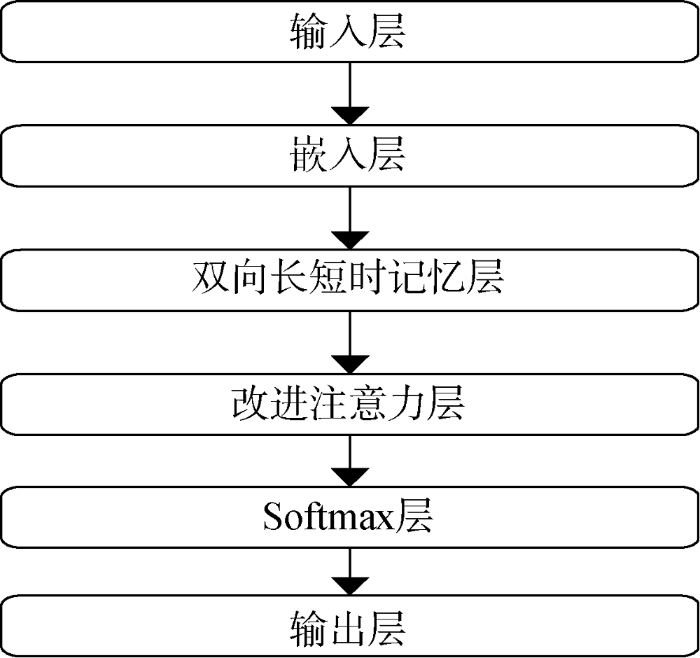
在BLSTM的基础上, 本文提出基于双向长短时记忆网络的改进注意力模型(Improved Attention BLSTM, IABLSTM), 以原始文本作为输入, 样本类别作为输出, 完成端到端的短文本分类任务, 模型结构如图1 所示。
图1
(1) 嵌入层(Embedding): 以分词后的短文本作为输入, 将文本转换为低维词向量。
(2) 双向长短时记忆网络层(BLSTM): 以嵌入层的输出作为输入, 使用双向长短时记忆网络提取上下文语义特征。
(3) 改进注意力层(Improved Attention): 将BLSTM输出的正向和反向特征进行融合, 用于权重计算; 之后, 对正向和反向特征分别进行加权求和; 最后, 通过合并得到样本的上下文语义特征表示。
(4) Softmax层: 对改进注意力层的输出进行分类, 输出分类结果。
模型实现过程: 以原始文本作为输入, 经由嵌入层对输入词语进行向量化, 通过双向长短时记忆网络层对文本上下文语义特征进行提取, 采用改进注意力机制增强有效特征, 弱化无效特征, 获得具有更高区分度的短文本表示向量, 最终由Softmax层分配类别标签。
3.2 嵌入层
每一条短文本S 由T 个词构成, 表示为$S=\left\{ {{w}_{1}},{{w}_{2}},\cdot \cdot \cdot ,{{w}_{T}} \right\}$, 其中每个词${{w}_{t}}$转换成低维实数向量${{x}_{t}}$。文本中每个词通过查询词向量矩阵获得相应的词向量, 词向量矩阵表示为${{W}^{word}}\in {{R}^{{{d}^{w}}\left| V \right|}}$, 其中, $\left| V \right|$表示词典个数, ${{d}^{w}}$为超参数, 表示词向量维度。词向量矩阵由公共语料库预训练获得词向量构造得到, 将输入的词通过查词典的方式得到其相应的词向量, 对于词典中未存在的词, 则通过随机生成获得。原始文本默认完成分词后, 经过嵌入层, 词语完成文本向数字向量的转换。
3.3 双向长短时记忆层
经过嵌入层后, 向量化的文本进入BLSTM进行上下文语义特征提取。本文参考Hochreiter等[17 ] 提出的LSTM结构, 如公式(4)至公式(9)所示。
(4) ${{i}_{t}}=\sigma ({{W}_{i}}[{{h}_{t-1}},{{x}_{t}}]+{{b}_{i}})$
(5) $g=\tanh ({{W}_{c}}[{{h}_{t-1}},{{x}_{t}}]+{{b}_{c}})$
(6) ${{f}_{t}}=\sigma ({{W}_{f}}[{{h}_{t-1}},{{x}_{t}}]+{{b}_{f}})$
(7) ${{C}_{t}}={{f}_{t}}\cdot {{C}_{t-1}}+{{i}_{t}}\cdot g$
(8) ${{o}_{t}}=\sigma ({{W}_{o}}[{{h}_{t-1}},{{x}_{t}}]+{{b}_{o}})$
(9) ${{h}_{t}}={{o}_{t}}\cdot \tanh ({{C}_{t}})$
其中, ${{x}_{t}}$表示当前时刻的输入信息, ${{h}_{t-1}}$表示上一时刻的输出信息, ${{i}_{t}}$表示当前时刻输入门, $g$表示候选的输入信息。${{f}_{t}}$表示当前时刻的遗忘门。${{C}_{t}}$表示自循环神经元, 用于保存序列信息。${{o}_{t}}$表示当前时刻的输出门, ${{h}_{t}}$是当前时刻的输出向量, $W$表示权重矩阵, $b$表示偏置向量, 函数$\sigma $表示Sigmoid非线性激活函数。
由两个LSTM建立BLSTM的双向通道, 向量化的文本分别通过正向和反向通道, 二者参数独立, 输出相互独立, 从而得到序列的正向和反向上下文语义特征。
3.4 改进的注意力层
在BLSTM完成上下文信息提取后, 其输出作为改进的注意力层的输入。本文针对词语级注意力在两个方面进行改进。
(1) 在隐层输入部分, 传统注意力机制将双向网络正向和反向特征合并后作为输入, 并未考虑正反向特征对注意力权重的不同影响; 本文考虑将正反向特征相互独立地作为输入, 通过分配相应的参数矩阵进行训练, 从而有效地利用样本词语的上下文信息, 提出公式(10)。在得到语义表示向量后, 计算注意力得分, 如公式(11)所示。通过将注意力得分进行归一化处理, 从而得到词语的语义权重, 如公式(12)所示。
(10) ${{u}_{t}}=\tanh ({{W}_{fw}}\overrightarrow{{{h}_{t}}}+{{W}_{bw}}\overleftarrow{{{h}_{t}}}+{{b}_{w}})$
(11) $f({{u}_{t}},{{u}_{w}})=u_{t}^{T}{{u}_{w}}$
(12) ${{\alpha }_{t}}=\frac{\exp (f({{u}_{t}},{{u}_{w}}))}{\sum\nolimits_{t}{\exp (f({{u}_{t}},{{u}_{w}}))}}$
其中, $\overrightarrow{{{h}_{t}}}$表示BLSTM的正向输出, $\overleftarrow{{{h}_{t}}}$表示BLSTM的反向输出, ${{W}_{fw}}$和${{W}_{bw}}$表示参数矩阵, ${{b}_{w}}$表示偏置项, ${{u}_{t}}$表示语义表示向量, ${{u}_{w}}$表示权重向量, $f({{u}_{t}},u{}_{w})$表示注意力得分, ${{\alpha }_{t}}$表示归一化语义权重。
(2) 在语义特征表示方面, 传统的注意力机制将合并后的正反向特征同注意力权重进行加权累加得到语义表示。本文将由正反向特征彼此独立参与得到的语义权重分别对正向特征和反向特征进行加权求和, 从而得到样本的正向和反向表示, 最后通过合并得到最终的样本语义表示向量, 由此提出公式(13)。
(13) $H=[\sum\limits_{t}{{{\alpha }_{t}}\overrightarrow{{{h}_{t}}}},\sum\limits_{t}{{{\alpha }_{t}}\overleftarrow{{{h}_{t}}}}]$
改进的注意力机制整体实现过程如下: 将每一词语经过BLSTM的正向特征和反向特征进行整合, 得到其语义表示; 完成注意力得分计算; 经过归一化处理得到每个词语的语义权重; 将样本中各词语正向特征和反向特征同其对应权重加权叠加、合并得到样本的深层语义特征表示, 如图2 所示。
图2
3.5 Softmax层
原始文本从嵌入层开始经过双向长短时记忆网络对短文本上下文信息进行提取, 通过改进注意力层对上下文信息进行融合, 获得具有深层语义特征表示, 经Softmax进行分类, 得到最终的分类结果, 计算如公式(14)所示。其中, ${{W}_{c}}$表示权重矩阵, ${{b}_{c}}$表示偏置项。
(14) $p=Softmax({{W}_{c}}H+{{b}_{c}})$
在训练过程中, 以交叉熵作为目标函数衡量模型损失, 加入正则项防止过拟合, 如公式(15)所示。训练目标是使所有训练样本的正确标签和预测标签下的交叉熵损失最小。
(15) $loss=\sum\limits_{i}{\sum\limits_{j}{y_{i}^{j}\log \hat{y}_{i}^{j}+\lambda {{\left\| \theta \right\|}^{2}}}}$
其中, $y_{i}^{j}$表示样本的正确标签; $\hat{y}_{i}^{j}$表示样本的预测标签; $i$表示样本个数; $j$表示类别; $\lambda $表示${{L}_{2}}$正则项系数; $\theta $表示模型的参数集合。
4 实验结果及分析
4.1 数据集
为了验证模型的分类性能, 本文通过6个文本分类数据集对模型的分类效果进行评估, 数据集信息如表1 所示。
(1) CNH: 中文新闻标题分类[21 ] 。根据新闻标题内容为其分配标签, 如政治、军事、娱乐等, 共18类。训练集包含156 000个样本, 验证集有18 000个样本, 测试集有18 000个样本。
(2) MR: 电影评论数据集[22 ] 。每一条电影评论作为一条样本。类别为两类: 积极或消极。其中, 数据集包含7 462个训练样本, 1 589个验证样本, 1 589个测试样本。
(3) TREC: TREC问题分类数据集[23 ] 。分类目标是确定问题所属类别标签, 标签共有6类, 即DESC, ENTY, ABBR, HUM, NUM, LOC。训练集包含5 357个样本, 测试集包含592个样本, 由于数据集较小, 验证集等同于测试集。
(4) IMDB: 电影评论数据集。该数据集判断用 户评论态度为积极或是消极, 即两类。训练集包含 25 000个样本, 验证集包含12 500个样本, 测试集包含12 500个样本。
(5) IMDB_10: 电影评分数据集[24 ] 。将用户的电影评论根据其评分进行分类。共分为10类, 即评分从 1到10。训练集包含25 000个样本, 验证集包含12 500个样本, 测试集包含12 500个样本。
(6) Yelp: 选取Yelp中的产品评论构建数据集, 类别标签为评分1至5。训练集包含25 000个样本, 验证集包含5 000个样本, 测试集包含5 000个样本。
4.2 基线模型
(1) CNN: 根据Kim[7 ] 实现词语级卷积神经网络模型, 以词向量作为输入, 卷积核数为128; 卷积核大小分别为3、4、5; 卷积层数为1。
(2) LSTM: 模型来源于文献[17 ]。长短时记忆网络模型隐层神经元数为300, 层数为1。
(3) BLSTM: 该模型表示双向长短时记忆网络模型, 由两个上述长短时记忆模型构成。BLSTM以LSTM最终时刻隐层输出作为序列的单向输出向量, 通过合并正反向向量, 得到最后的双向输出向量进行分类。BLSTM模型中正反向LSTM神经元数均为300。
(4) BLSTM_ave: 该模型基于双向长短时记忆网络模型以取均值的方式得到样本语义特征。文本经过双向长短时记忆网络得到每个词的正反向特征并将二者合并, 通过将样本中所有词语取均值的方式得到整体的高阶语义表示, 用于分类。BLSTM_ave隐层神经元个数设置与BLSTM相同。
(5) ABLSTM: 基于双向长短时记忆网络的注意力模型将注意力机制与BLSTM相结合, 注意力机制来自Yang等[12 ] 提出的词语级注意力。以词向量作为输入, 通过BLSTM对句子上下文信息进行提取, 正向和反向输出合并后, 通过注意力机制对句子中的词分配权重并求和得到相应的短文本表示, 最后通过Softmax对其进行分类。ABLSTM模型中双向长短时记忆网络各通道隐层数为300, 层数为1。
(6) HAN: Yang等[12 ] 提出的层级注意力网络模型(Hierarchical Attention Network, HAN)。在实验过程中, 将每一条样本视为一条文档样本进行分类, 文档长度设为1。
4.3 模型训练
本文数据集包含中文和英文两种语言。中文文本利用jieba中文分词包完成分词; 英文文本通过空格进行划分。中文词向量采用以中文数据集为语料库, 利用Word2Vec[25 ] 模型训练得到的开源词向量, 维度为300; 考虑到英文样本与Twitter数据具有较高相似性, 而且大规模语料包含词语量更大, 所以英文词向量是由GloVe[26 ] 基于大规模Twitter语料库训练得到的词向量, 维度均为300。
序列长度指短文本经过分词后的词数。由于不同短文本样本长度大不相同, 需要将输入样本处理成统一长度的序列, 当输入样本长度小于设定序列长度时, 使用0进行填充; 当输入样本长度大于设定序列长度时, 对其进行截断。设定序列长度过大造成模型参数过多, 特征稀疏; 设定序列过小将造成原始文本信息丢失。本文通过统计数据集的文本长度, 设置序列长度为300。
本文所有模型均以中文新闻标题分类数据集为基础确定超参数, 以其最佳分类效果时模型参数为最终参数。其中, 本文所提模型LSTM隐层输出维度为300; 模型的训练步数设置为100; 学习率是按照指数衰减的方式生成, 初始值为0.001, 衰减系数为0.9, 衰减速度为40; 正则项系数为0.001。保持参数不变, 在其他数据集上完成分类实验, 测试其在不同条件下的泛化能力。实验模型采用Python语言, 基于Keras框架进行实现。模型训练环境为Ubuntu 14.04, 64GB内存, CPU为Inter(R) i7-6850K处理器, GPU为英伟达1080Ti。
4.4 实验结果
本文采用精度(Accuracy)作为模型性能的衡量指标, 对模型性能进行评估。将基线模型同本文IABLSTM模型在多个不同形式的数据集上的分类效果进行对比, 实验结果如表2 所示。
IABLSTM在所有数据集上分类精度均高于未引入注意力机制模型, 相比于CNN在中文新闻标题分类数据集(CNH)上提升最高为19.1%; 相比于LSTM在电影评分(IMDB_10)提升为9.1%; 相较于BLSTM和以总体均值为输出的BLSTM_ave在问题分类(TREC)上提升最大为3.6%。本文所提模型同ABLSTM对比, 在问题分类(TREC)、电影评分(IMDB_10)、中文新闻标题(CNH)上提升较为明显, 其中在电影评分(IMDB_10)上提升最高为2.6%, 其他部分数据集上也有略微提高。本文所提模型与目前较为先进的HAN进行比较, 在电影评论(MR)、电影评论(IMDB)、问题分类(TREC)上提升效果较为明显, 在TREC提升最高为1.9%; 而在电影评分(IMDB_10)上HAN达到其最好的49.4%, 本文所提模型与之持平, 其他数据集上略有提升。
4.5 实验分析
CNN类似于传统的N-gram模型, 通过捕捉样本的局部语义特征进行分类, Kim等采用卷积神经网络模型(CNN)在问题分类数据集(TREC)上分类效果达到93.6%, 高于本文所提模型。本文以中文新闻标题分类数据集为基础确定模型参数以及预训练词向量词语规模与Kim等[7 ] 实验词语规模存在一定差距, 导致本文所实现CNN和本文所提模型在问题分类数据集上(TREC)分类效果不佳。
LSTM依靠具有记忆能力的记忆单元提取序列语义特征用于分类; BLSTM和以总体均值为输出的BLSTM_ave在提取序列语义特征的基础上, 整合上下文信息实现分类; 本文所提模型在双向长短时记忆网络基础上, 考虑将词语在语义表示中的重要程度引入到文本的语义特征表示中, 利用改进注意力机制完成语义权重的确定, 相较于上述模型提升了分类效果。从而证明了引入注意力机制有助于提升分类性能。
ABLSTM模型将双向长短时记忆网络的正反向特征进行合并用于注意力权重计算; 而本文所提模型通过将正反向特征彼此独立地参与注意力权重计算, 文本中决定中心词在语义表达中重要程度的词语其位置可能位于中心词之前或之后, 本文所提模型的计算方式更符合这一规律, 从而能够更为有效地利用上下文信息。本文所提模型对上下文特征的细化, 导致其对于多分类问题效果提升更为明显, 例如在电影评论数据集(IMDB)二分类, 二者分类精度接近; 而在电影评分(IMDB_10)上多分类, 本文所提模型明显高于ABLSTM。
HAN用于解决文档分类问题, 通过合并双向GRU输出利用词语级注意力和文档级注意力获得文档的语义特征表示。本文所提模型针对短文本在词语级引入改进注意力机制, 充分利用上下文语义特征。上下文特征以合并的方式作为双向网络的最终输出, 将其以整体的形式进行注意力计算, 容易造成二者区分度下降。而将上下文特征彼此独立对待, 共同影响注意力权重计算, 有助于获得更具区分度的深层语义表示。通过对比本文所提模型同HAN的实验数据发现: 在样本长度普遍较短的数据集上, 如电影评论(MR)和问题分类(TREC), 本文所提模型分类效果提升较大; 而在样本较长数据集上, 如电影评论(IMDB)、产品评论(Yelp)等, 本文所提模型分类效果提升较小或与基线模型持平。所以IABLSTM在完成短文本分类的同时, 也可以用于实现长文本分类, 从而表明其用于解决短文本分类的有效性及适应性。综上所述, 通过在不同数据集上与基线模型进行对比, 证明了本文所提出IABLSTM模型在短文本分类精度取得了一定提升。
5 结 语
本文以短文本自身为基础, 从短文本深层语义向量提取的角度出发为改善其分类效果进行探索。首先研究短文本分类中相关深度学习方法的应用情况, 传统卷积神经网络、长短时记忆网络和双向长短时记忆网络模型未考虑词语在语义表示中的重要程度。针对这一问题, 本文引入注意力机制衡量词语的重要程度。针对传统注意力机制的文本表示向量, 以双向长短时记忆网络的正反向输出为基础进行改进, 使得注意力分数计算能够更加有效地利用上下文信息, 从而获得样本的语义表示。在包含二分类、多分类任务, 中英文不同语言的多个数据集下进行实验, 结果表明: 基于双向长短时记忆网络的改进注意力模型(IABLSTM)相比于传统卷积神经网络、长短时记忆网络和双向长短时记忆网络模型分类精度最高提升19.1%, 相较于基于双向长短时记忆网络的注意力模型(ABLSTM)提高2.6%, 由此可得本文提出的模型有效地缓解了传统双向长短时记忆网络特征融合时造成的语义信息丢失等问题, 同时针对不同语言的短文本分类精度取得一定提升。
本文研究也存在一些不足和改进空间, 如本文所提出的模型对于输入数据长度进行设置, 从而导致模型对较长文本, 分类精度下降, 如何使模型对不同长度输入文本进行准确分类是有待研究的问题; 注意力机制通过训练迭代计算权重, 未来考虑采用词性对注意力机制加以约束, 这样权重分配更具有针对性。
支撑数据
支撑数据由作者自存储, E-mail: lixiaobing_lgd@163.com。
[1] 李小兵. MR.zip. 电影评论数据集.
[2] 李小兵. acImdb.zip. IMDB评论数据集.
[3] 李小兵. imdb_10.zip. IMDB评论评分数据集.
[4] 李小兵. nlp_newsheadlines.zip. 中文新闻标题分类数据集.
[5] 李小兵. trec.zip. TREC问题分类数据集.
[6] 李小兵. yelp.zip. Yelp产品评论数据集。
[7] 李小兵. glove.zip. 英文预训练词向量.
[8] 李小兵. zh.zip. 中文预训练词向量.
[9] 李小兵. 实验结果.csv. 模型Accuracy对比结果.
[10] 李小兵. 数据集信息统计.csv. 数据集信息统计结果.
参考文献
View Option
[1]
Bollegala D Mastsuo Y Lshizuka M . Measuring Semantic Similarity Between Words Using Web Search Engines
[C] //Proceedings of the 2nd ACM International Conference on World Wide Web. ACM , 2007 : 757 -766 .
[本文引用: 1]
[2]
Li J Cai Y Cai Z , et al . Wikipedia Based Short Text Classification Method
[C]//Proceedings of the 2017 International Conference on Database Systems for Advanced Applications. Springer Cham , 2017 : 275 -286 .
[本文引用: 1]
[3]
吕超镇 , 姬东鸿 , 吴飞飞 . 基于LDA特征扩展的短文本分类
[J]. 计算机工程与应用 , 2015 ,51 (4 ):123 -127 .
[本文引用: 1]
( Lv Chaozhen Ji Donghong Wu Feifei . Short Text Classification Based on Expanding Feature of LDA
[J]. Computer Engineering and Applications , 2015 ,15 (4 ):123 -127 .)
[本文引用: 1]
[4]
Ma C Zhao Q Pan J , et al . Short Text Classification Based on Distributional Representations of Words
[J]. IEICE Transactions on Information and Systems , 2016 ,99 (10 ):2562 -2565 .
[本文引用: 1]
[5]
Kaljahi R Foster J . Any-gram Kernels for Sentence Classification: A Sentiment Analysis Case Study
[OL]. arXiv Preprint , arXiv : 1712.07004v1.
[本文引用: 1]
[6]
Li B Zhao Z Liu T , et al . Weighted Neural Bag-of-n-grams Model: New Baselines for Text Classification
[C]// Proceedings of the 26th International Conference on Computational Linguistics. 2016 : 1591 -1600 .
[本文引用: 1]
[7]
Kim Y . Convolutional Neural Networks for Sentence Classification
[OL]. arXiv Preprint , arXiv : 1408.5882v2.
[本文引用: 3]
[8]
Lee J Y Dernoncourt F . Sequential Short-text Classification with Recurrent and Convolutional Neural Networks
[OL]. arXiv Preprint , arXiv : 1603.03827.
[本文引用: 1]
[9]
Hsu S T Moon C Jones P , et al . A Hybrid CNN-RNN Alignment Model for Phrase-aware Sentence Classification
[C]// Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics. Association for Computational Linguistics , 2017 : 443 -449 .
[本文引用: 1]
[10]
Zhou P Qi Z Zheng S , et al . Text Classification Improved by Integrating Bidirectional LSTM with Two-dimensional Max Pooling
[OL]. arXiv Preprint , arXiv :1611.06639.
[本文引用: 1]
[11]
Itti L Koch C Niebur E . A Model of Saliency-based Visual Attention for Rapid Scene Analysis
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 1998 ,20 (11 ):1254 -1259 .
[本文引用: 1]
[12]
Yang Z Yang D Dyer C , et al . Hierarchical Attention Networks for Document Classification
[C]//Proceedings of Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics , 2016 : 1480 -1489 .
[本文引用: 4]
[13]
Zhou P Shi W Tian J , et al . Attention-based Bidirectional Long Short-Term Memory Networks for Relation Classification
[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Lingustics. Berlin, Germany: Association for Computational Linguistics , 2016 : 207 -212 .
[本文引用: 1]
[14]
Wang Y Huang M Zhao L , et al . Attention-based LSTM for Aspect-level Sentiment Classification
[C]//Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics , 2016 : 606 -615 .
[本文引用: 1]
[15]
Zhou Y Xu J Cao J , et al . Hybrid Attention Networks for Chinese Short Text Classification
[J]. Computación y Sistemas , 2018 ,21 (4 ):759 -769 .
[本文引用: 1]
[16]
Zaremba W Sutskever I Vinyals O . Recurrent Neural Network Regularization
[OL]. arXiv Preprint , arXiv : 1409.2329v5.
[本文引用: 1]
[17]
Hochreiter S Schmidhuber J . Long Short Term Memory
[J]. Neural Computation , 1997 ,9 (8 ):1735 -1780 .
[本文引用: 3]
[18]
Lin Z Feng M Santos C N D , et al . A Structured Self-attentive Sentence Embedding
[OL]. arXiv Preprint , arXiv : 1703.03130.
[本文引用: 1]
[19]
Daniluk M Rocktaschel T Welbl J , et al . Frustratingly Short Attention Spans in Neural Language Modeling
[OL]. arXiv Preprint , arXiv : 1702.04521.
[本文引用: 1]
[20]
Bahdanau D Cho K Bengio Y . Neural Machine Translation by Jointly Learning to Align and Translate
[OL]. arXiv Preprint , arXiv : 1409.0473.
[本文引用: 1]
[21]
Qiu X Gong J Huang X . Overview of the NLPCC 2017 Shared Tash: Chinese News Headline Categorization
[C] //Proceedings of NLPCC 2017: Natural Language Processing and Chinese Computing. Sprintger , 2017 : 948 -953 .
[本文引用: 1]
[22]
Pang B Lee L . A Sentimental Education: Sentiment Analysis Using Subjectivity Summarization Based on Minimum Cuts
[C]//Proceedings of the 42nd Annual Meeting on Association for Computational Linguistics. Association for Computational Linguistics , 2004 : 271 -278 .
[本文引用: 1]
[23]
Li X Roth D . Learning Question Classifiers
[C]//Proceedings of the 19th International Conference on Computational Linguistics-Volume 1. Association for Computational Linguistics , 2002 : 1 -7 .
[本文引用: 1]
[24]
Diao Q Qiu M Wu C Y , et al . Jointly Modeling Aspects, Ratings and Sentiments for Movie Recommendation (JMARS)
[C]//Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM , 2014 : 193 -202 .
[本文引用: 1]
[25]
Mikolov T Sutskever I Chen K , et al . Distributed Representations of Words and Phrases and Their Compositionality
[C]//Proceedings of Advances in Neural Information Processing Systems. Neural Information Processing Systems , 2013 : 3111 -3119 .
[本文引用: 1]
[26]
Pentington J Socher R Manning C D . Glove: Global Vectors for Word Representation
[C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing(EMNLP). Computational Linguistics , 2014 : 1532 -1543 .
[本文引用: 1]
Measuring Semantic Similarity Between Words Using Web Search Engines
1
2007
... 随着社交网络的发展, 微博、网络评论、论坛互动等短文本数据呈爆发式增长.面对大规模的短文本数据, 需要准确地将其归类, 短文本分类技术发挥着极其重要的作用.同时, 短文本分类也是情感分析、问答系统、对话管理等自然语言处理应用中的关键技术之一.针对短文本分类问题, 传统方法大多是采用向量空间模型(Vector Space Model, VSM)进行文本表示, 通过特征扩展克服特征稀疏所带来的不利影响, 主要方法包括引入外部知识源, 如搜索引擎[1 ] 查询结果、大型语料库[2 ] 等; 或者从短文本自身出发引入主 题[3 ] 、相近词[4 ] 等, 最终利用传统的分类器给出分类结果.此类方法在特征扩展过程中, 对文本相似性判定提出了较高的要求, 同时难以避免引入干扰信息.所以, 通过特征扩展解决短文本分类问题提升效果十分有限. ...
Wikipedia Based Short Text Classification Method
1
2017
... 随着社交网络的发展, 微博、网络评论、论坛互动等短文本数据呈爆发式增长.面对大规模的短文本数据, 需要准确地将其归类, 短文本分类技术发挥着极其重要的作用.同时, 短文本分类也是情感分析、问答系统、对话管理等自然语言处理应用中的关键技术之一.针对短文本分类问题, 传统方法大多是采用向量空间模型(Vector Space Model, VSM)进行文本表示, 通过特征扩展克服特征稀疏所带来的不利影响, 主要方法包括引入外部知识源, 如搜索引擎[1 ] 查询结果、大型语料库[2 ] 等; 或者从短文本自身出发引入主 题[3 ] 、相近词[4 ] 等, 最终利用传统的分类器给出分类结果.此类方法在特征扩展过程中, 对文本相似性判定提出了较高的要求, 同时难以避免引入干扰信息.所以, 通过特征扩展解决短文本分类问题提升效果十分有限. ...
基于LDA特征扩展的短文本分类
1
2015
... 随着社交网络的发展, 微博、网络评论、论坛互动等短文本数据呈爆发式增长.面对大规模的短文本数据, 需要准确地将其归类, 短文本分类技术发挥着极其重要的作用.同时, 短文本分类也是情感分析、问答系统、对话管理等自然语言处理应用中的关键技术之一.针对短文本分类问题, 传统方法大多是采用向量空间模型(Vector Space Model, VSM)进行文本表示, 通过特征扩展克服特征稀疏所带来的不利影响, 主要方法包括引入外部知识源, 如搜索引擎[1 ] 查询结果、大型语料库[2 ] 等; 或者从短文本自身出发引入主 题[3 ] 、相近词[4 ] 等, 最终利用传统的分类器给出分类结果.此类方法在特征扩展过程中, 对文本相似性判定提出了较高的要求, 同时难以避免引入干扰信息.所以, 通过特征扩展解决短文本分类问题提升效果十分有限. ...
基于LDA特征扩展的短文本分类
1
2015
... 随着社交网络的发展, 微博、网络评论、论坛互动等短文本数据呈爆发式增长.面对大规模的短文本数据, 需要准确地将其归类, 短文本分类技术发挥着极其重要的作用.同时, 短文本分类也是情感分析、问答系统、对话管理等自然语言处理应用中的关键技术之一.针对短文本分类问题, 传统方法大多是采用向量空间模型(Vector Space Model, VSM)进行文本表示, 通过特征扩展克服特征稀疏所带来的不利影响, 主要方法包括引入外部知识源, 如搜索引擎[1 ] 查询结果、大型语料库[2 ] 等; 或者从短文本自身出发引入主 题[3 ] 、相近词[4 ] 等, 最终利用传统的分类器给出分类结果.此类方法在特征扩展过程中, 对文本相似性判定提出了较高的要求, 同时难以避免引入干扰信息.所以, 通过特征扩展解决短文本分类问题提升效果十分有限. ...
Short Text Classification Based on Distributional Representations of Words
1
2016
... 随着社交网络的发展, 微博、网络评论、论坛互动等短文本数据呈爆发式增长.面对大规模的短文本数据, 需要准确地将其归类, 短文本分类技术发挥着极其重要的作用.同时, 短文本分类也是情感分析、问答系统、对话管理等自然语言处理应用中的关键技术之一.针对短文本分类问题, 传统方法大多是采用向量空间模型(Vector Space Model, VSM)进行文本表示, 通过特征扩展克服特征稀疏所带来的不利影响, 主要方法包括引入外部知识源, 如搜索引擎[1 ] 查询结果、大型语料库[2 ] 等; 或者从短文本自身出发引入主 题[3 ] 、相近词[4 ] 等, 最终利用传统的分类器给出分类结果.此类方法在特征扩展过程中, 对文本相似性判定提出了较高的要求, 同时难以避免引入干扰信息.所以, 通过特征扩展解决短文本分类问题提升效果十分有限. ...
Any-gram Kernels for Sentence Classification: A Sentiment Analysis Case Study
1
... 随着深度学习的快速发展, 以词向量模型为基础的短文本分类方法层出不穷.Kaljahi等[5 ] 提出Any-gram核方法, 用于提取短文本的N-gram[6 ] 特征, 采用双向长短时记忆网络(Bidirectional Long-Short Term Memory Network, BLSTM)进行分类, 在基于主题和句子级的情感分析任务中取得了不错的效果.Kim等[7 ] 使用卷积神经网络(Convolutional Neural Networks, CNN)解决句子分类问题.Lee等[8 ] 结合循环神经网络(Recurrent Neural Network, RNN)和卷积神经网络对短文本进行分类.Hsu等[9 ] 将卷积神经网络和循环神经网络混合, 提出一种结构独立的门表示算法, 用于句子分类.Zhou等[10 ] 将二维最大池化操作引入到双向短时记忆网络(BLSTM), 在时间维度和特征维度上对文本的特征进行提取, 完成文本分类任务.以上方法在文本特征提取过程中, 未考虑词语在语义表示中的重要程度, 容易出现重点词被忽略, 而非重点词被重视等情况, 导致分类效果提升不明显.而注意力机制能够较好地对文本中词语重要程度进行区分, 更符合人类对于语义的认知. ...
Weighted Neural Bag-of-n-grams Model: New Baselines for Text Classification
1
2016
... 随着深度学习的快速发展, 以词向量模型为基础的短文本分类方法层出不穷.Kaljahi等[5 ] 提出Any-gram核方法, 用于提取短文本的N-gram[6 ] 特征, 采用双向长短时记忆网络(Bidirectional Long-Short Term Memory Network, BLSTM)进行分类, 在基于主题和句子级的情感分析任务中取得了不错的效果.Kim等[7 ] 使用卷积神经网络(Convolutional Neural Networks, CNN)解决句子分类问题.Lee等[8 ] 结合循环神经网络(Recurrent Neural Network, RNN)和卷积神经网络对短文本进行分类.Hsu等[9 ] 将卷积神经网络和循环神经网络混合, 提出一种结构独立的门表示算法, 用于句子分类.Zhou等[10 ] 将二维最大池化操作引入到双向短时记忆网络(BLSTM), 在时间维度和特征维度上对文本的特征进行提取, 完成文本分类任务.以上方法在文本特征提取过程中, 未考虑词语在语义表示中的重要程度, 容易出现重点词被忽略, 而非重点词被重视等情况, 导致分类效果提升不明显.而注意力机制能够较好地对文本中词语重要程度进行区分, 更符合人类对于语义的认知. ...
Convolutional Neural Networks for Sentence Classification
3
... 随着深度学习的快速发展, 以词向量模型为基础的短文本分类方法层出不穷.Kaljahi等[5 ] 提出Any-gram核方法, 用于提取短文本的N-gram[6 ] 特征, 采用双向长短时记忆网络(Bidirectional Long-Short Term Memory Network, BLSTM)进行分类, 在基于主题和句子级的情感分析任务中取得了不错的效果.Kim等[7 ] 使用卷积神经网络(Convolutional Neural Networks, CNN)解决句子分类问题.Lee等[8 ] 结合循环神经网络(Recurrent Neural Network, RNN)和卷积神经网络对短文本进行分类.Hsu等[9 ] 将卷积神经网络和循环神经网络混合, 提出一种结构独立的门表示算法, 用于句子分类.Zhou等[10 ] 将二维最大池化操作引入到双向短时记忆网络(BLSTM), 在时间维度和特征维度上对文本的特征进行提取, 完成文本分类任务.以上方法在文本特征提取过程中, 未考虑词语在语义表示中的重要程度, 容易出现重点词被忽略, 而非重点词被重视等情况, 导致分类效果提升不明显.而注意力机制能够较好地对文本中词语重要程度进行区分, 更符合人类对于语义的认知. ...
... (1) CNN: 根据Kim[7 ] 实现词语级卷积神经网络模型, 以词向量作为输入, 卷积核数为128; 卷积核大小分别为3、4、5; 卷积层数为1. ...
... CNN类似于传统的N-gram模型, 通过捕捉样本的局部语义特征进行分类, Kim等采用卷积神经网络模型(CNN)在问题分类数据集(TREC)上分类效果达到93.6%, 高于本文所提模型.本文以中文新闻标题分类数据集为基础确定模型参数以及预训练词向量词语规模与Kim等[7 ] 实验词语规模存在一定差距, 导致本文所实现CNN和本文所提模型在问题分类数据集上(TREC)分类效果不佳. ...
Sequential Short-text Classification with Recurrent and Convolutional Neural Networks
1
... 随着深度学习的快速发展, 以词向量模型为基础的短文本分类方法层出不穷.Kaljahi等[5 ] 提出Any-gram核方法, 用于提取短文本的N-gram[6 ] 特征, 采用双向长短时记忆网络(Bidirectional Long-Short Term Memory Network, BLSTM)进行分类, 在基于主题和句子级的情感分析任务中取得了不错的效果.Kim等[7 ] 使用卷积神经网络(Convolutional Neural Networks, CNN)解决句子分类问题.Lee等[8 ] 结合循环神经网络(Recurrent Neural Network, RNN)和卷积神经网络对短文本进行分类.Hsu等[9 ] 将卷积神经网络和循环神经网络混合, 提出一种结构独立的门表示算法, 用于句子分类.Zhou等[10 ] 将二维最大池化操作引入到双向短时记忆网络(BLSTM), 在时间维度和特征维度上对文本的特征进行提取, 完成文本分类任务.以上方法在文本特征提取过程中, 未考虑词语在语义表示中的重要程度, 容易出现重点词被忽略, 而非重点词被重视等情况, 导致分类效果提升不明显.而注意力机制能够较好地对文本中词语重要程度进行区分, 更符合人类对于语义的认知. ...
A Hybrid CNN-RNN Alignment Model for Phrase-aware Sentence Classification
1
2017
... 随着深度学习的快速发展, 以词向量模型为基础的短文本分类方法层出不穷.Kaljahi等[5 ] 提出Any-gram核方法, 用于提取短文本的N-gram[6 ] 特征, 采用双向长短时记忆网络(Bidirectional Long-Short Term Memory Network, BLSTM)进行分类, 在基于主题和句子级的情感分析任务中取得了不错的效果.Kim等[7 ] 使用卷积神经网络(Convolutional Neural Networks, CNN)解决句子分类问题.Lee等[8 ] 结合循环神经网络(Recurrent Neural Network, RNN)和卷积神经网络对短文本进行分类.Hsu等[9 ] 将卷积神经网络和循环神经网络混合, 提出一种结构独立的门表示算法, 用于句子分类.Zhou等[10 ] 将二维最大池化操作引入到双向短时记忆网络(BLSTM), 在时间维度和特征维度上对文本的特征进行提取, 完成文本分类任务.以上方法在文本特征提取过程中, 未考虑词语在语义表示中的重要程度, 容易出现重点词被忽略, 而非重点词被重视等情况, 导致分类效果提升不明显.而注意力机制能够较好地对文本中词语重要程度进行区分, 更符合人类对于语义的认知. ...
Text Classification Improved by Integrating Bidirectional LSTM with Two-dimensional Max Pooling
1
... 随着深度学习的快速发展, 以词向量模型为基础的短文本分类方法层出不穷.Kaljahi等[5 ] 提出Any-gram核方法, 用于提取短文本的N-gram[6 ] 特征, 采用双向长短时记忆网络(Bidirectional Long-Short Term Memory Network, BLSTM)进行分类, 在基于主题和句子级的情感分析任务中取得了不错的效果.Kim等[7 ] 使用卷积神经网络(Convolutional Neural Networks, CNN)解决句子分类问题.Lee等[8 ] 结合循环神经网络(Recurrent Neural Network, RNN)和卷积神经网络对短文本进行分类.Hsu等[9 ] 将卷积神经网络和循环神经网络混合, 提出一种结构独立的门表示算法, 用于句子分类.Zhou等[10 ] 将二维最大池化操作引入到双向短时记忆网络(BLSTM), 在时间维度和特征维度上对文本的特征进行提取, 完成文本分类任务.以上方法在文本特征提取过程中, 未考虑词语在语义表示中的重要程度, 容易出现重点词被忽略, 而非重点词被重视等情况, 导致分类效果提升不明显.而注意力机制能够较好地对文本中词语重要程度进行区分, 更符合人类对于语义的认知. ...
A Model of Saliency-based Visual Attention for Rapid Scene Analysis
1
1998
... 注意力机制源于认知心理学中的人脑注意力机 制[11 ] , 能够有选择性地重点关注源数据的某些部分, 近来已被广泛应用于多种自然语言处理任务.Yang等[12 ] 提出层级注意力模型应用于文章分类.Zhou等[13 ] 在双向长短时记忆网络中引入注意力机制, 用于解决相关性分类问题.Wang等[14 ] 将词向量和主题向量结合作为输入, 在长短时记忆网络(Long-Short Term Memory Network, LSTM)的基础上, 利用注意力机制, 实现主题情感分类.Zhou等[15 ] 提出混合注意力模型, 采用卷积神经网络和循环神经网络提取字符级和词语级语义特征, 通过注意力机制进行混合, 实现中文短文本分类.传统注意力机制将上层输出通过全连接后进行注意力得分计算.然而, 文本中重点词的个数及位置不确定, 传统注意力机制并未充分利用文本的上下文信息.所以, 直接顺序地对上层输出进行注意力分数计算具有一定的局限性. ...
Hierarchical Attention Networks for Document Classification
4
2016
... 注意力机制源于认知心理学中的人脑注意力机 制[11 ] , 能够有选择性地重点关注源数据的某些部分, 近来已被广泛应用于多种自然语言处理任务.Yang等[12 ] 提出层级注意力模型应用于文章分类.Zhou等[13 ] 在双向长短时记忆网络中引入注意力机制, 用于解决相关性分类问题.Wang等[14 ] 将词向量和主题向量结合作为输入, 在长短时记忆网络(Long-Short Term Memory Network, LSTM)的基础上, 利用注意力机制, 实现主题情感分类.Zhou等[15 ] 提出混合注意力模型, 采用卷积神经网络和循环神经网络提取字符级和词语级语义特征, 通过注意力机制进行混合, 实现中文短文本分类.传统注意力机制将上层输出通过全连接后进行注意力得分计算.然而, 文本中重点词的个数及位置不确定, 传统注意力机制并未充分利用文本的上下文信息.所以, 直接顺序地对上层输出进行注意力分数计算具有一定的局限性. ...
... 注意力机制最早应用于序列转换模型中, 目前, 性能较好的序列转换模型大多基于由循环神经网络和卷积神经网络构成的编码器和解码器, 其中效果最好的模型是通过注意力机制将编码器与解码器进行连接实现的.随着研究的深入, 众多改进的注意力机制被提出并应用于自然语言处理任务中.Lin等[18 ] 提出自注意力机制用于获得句子的向量表示.Daniluk等[19 ] 提出Key-Value Attention应用于神经语言模型.Bahdanau等[20 ] 提出Soft-Attention机制应用于机器翻译任务.Yang等[12 ] 提出涵盖词语级注意力和文档级注意力的层级注意力模型实现文章分类, 其中词语级注意力过程如公式(1)至公式(3)所示. ...
... (5) ABLSTM: 基于双向长短时记忆网络的注意力模型将注意力机制与BLSTM相结合, 注意力机制来自Yang等[12 ] 提出的词语级注意力.以词向量作为输入, 通过BLSTM对句子上下文信息进行提取, 正向和反向输出合并后, 通过注意力机制对句子中的词分配权重并求和得到相应的短文本表示, 最后通过Softmax对其进行分类.ABLSTM模型中双向长短时记忆网络各通道隐层数为300, 层数为1. ...
... (6) HAN: Yang等[12 ] 提出的层级注意力网络模型(Hierarchical Attention Network, HAN).在实验过程中, 将每一条样本视为一条文档样本进行分类, 文档长度设为1. ...
Attention-based Bidirectional Long Short-Term Memory Networks for Relation Classification
1
2016
... 注意力机制源于认知心理学中的人脑注意力机 制[11 ] , 能够有选择性地重点关注源数据的某些部分, 近来已被广泛应用于多种自然语言处理任务.Yang等[12 ] 提出层级注意力模型应用于文章分类.Zhou等[13 ] 在双向长短时记忆网络中引入注意力机制, 用于解决相关性分类问题.Wang等[14 ] 将词向量和主题向量结合作为输入, 在长短时记忆网络(Long-Short Term Memory Network, LSTM)的基础上, 利用注意力机制, 实现主题情感分类.Zhou等[15 ] 提出混合注意力模型, 采用卷积神经网络和循环神经网络提取字符级和词语级语义特征, 通过注意力机制进行混合, 实现中文短文本分类.传统注意力机制将上层输出通过全连接后进行注意力得分计算.然而, 文本中重点词的个数及位置不确定, 传统注意力机制并未充分利用文本的上下文信息.所以, 直接顺序地对上层输出进行注意力分数计算具有一定的局限性. ...
Attention-based LSTM for Aspect-level Sentiment Classification
1
2016
... 注意力机制源于认知心理学中的人脑注意力机 制[11 ] , 能够有选择性地重点关注源数据的某些部分, 近来已被广泛应用于多种自然语言处理任务.Yang等[12 ] 提出层级注意力模型应用于文章分类.Zhou等[13 ] 在双向长短时记忆网络中引入注意力机制, 用于解决相关性分类问题.Wang等[14 ] 将词向量和主题向量结合作为输入, 在长短时记忆网络(Long-Short Term Memory Network, LSTM)的基础上, 利用注意力机制, 实现主题情感分类.Zhou等[15 ] 提出混合注意力模型, 采用卷积神经网络和循环神经网络提取字符级和词语级语义特征, 通过注意力机制进行混合, 实现中文短文本分类.传统注意力机制将上层输出通过全连接后进行注意力得分计算.然而, 文本中重点词的个数及位置不确定, 传统注意力机制并未充分利用文本的上下文信息.所以, 直接顺序地对上层输出进行注意力分数计算具有一定的局限性. ...
Hybrid Attention Networks for Chinese Short Text Classi?cation
1
2018
... 注意力机制源于认知心理学中的人脑注意力机 制[11 ] , 能够有选择性地重点关注源数据的某些部分, 近来已被广泛应用于多种自然语言处理任务.Yang等[12 ] 提出层级注意力模型应用于文章分类.Zhou等[13 ] 在双向长短时记忆网络中引入注意力机制, 用于解决相关性分类问题.Wang等[14 ] 将词向量和主题向量结合作为输入, 在长短时记忆网络(Long-Short Term Memory Network, LSTM)的基础上, 利用注意力机制, 实现主题情感分类.Zhou等[15 ] 提出混合注意力模型, 采用卷积神经网络和循环神经网络提取字符级和词语级语义特征, 通过注意力机制进行混合, 实现中文短文本分类.传统注意力机制将上层输出通过全连接后进行注意力得分计算.然而, 文本中重点词的个数及位置不确定, 传统注意力机制并未充分利用文本的上下文信息.所以, 直接顺序地对上层输出进行注意力分数计算具有一定的局限性. ...
Recurrent Neural Network Regularization
1
... 长短时记忆网络(LSTM)由循环神经网络发展而来.循环神经网络[16 ] 是一种连续的前向传播神经网络.然而, 循环神经网络存在梯度弥散或者梯度爆炸的问题.为克服这些问题, Hochreiter等[17 ] 于1997年提出长短时记忆网络, 在循环神经网络基础上引入循环记忆神经元(Memory Cell).LSTM具有学习长依赖性数据特征的能力, 之后, 众多学者对其进行一系列改进. ...
Long Short Term Memory
3
1997
... 长短时记忆网络(LSTM)由循环神经网络发展而来.循环神经网络[16 ] 是一种连续的前向传播神经网络.然而, 循环神经网络存在梯度弥散或者梯度爆炸的问题.为克服这些问题, Hochreiter等[17 ] 于1997年提出长短时记忆网络, 在循环神经网络基础上引入循环记忆神经元(Memory Cell).LSTM具有学习长依赖性数据特征的能力, 之后, 众多学者对其进行一系列改进. ...
... 经过嵌入层后, 向量化的文本进入BLSTM进行上下文语义特征提取.本文参考Hochreiter等[17 ] 提出的LSTM结构, 如公式(4)至公式(9)所示. ...
... (2) LSTM: 模型来源于文献[17 ].长短时记忆网络模型隐层神经元数为300, 层数为1. ...
A Structured Self-attentive Sentence Embedding
1
... 注意力机制最早应用于序列转换模型中, 目前, 性能较好的序列转换模型大多基于由循环神经网络和卷积神经网络构成的编码器和解码器, 其中效果最好的模型是通过注意力机制将编码器与解码器进行连接实现的.随着研究的深入, 众多改进的注意力机制被提出并应用于自然语言处理任务中.Lin等[18 ] 提出自注意力机制用于获得句子的向量表示.Daniluk等[19 ] 提出Key-Value Attention应用于神经语言模型.Bahdanau等[20 ] 提出Soft-Attention机制应用于机器翻译任务.Yang等[12 ] 提出涵盖词语级注意力和文档级注意力的层级注意力模型实现文章分类, 其中词语级注意力过程如公式(1)至公式(3)所示. ...
Frustratingly Short Attention Spans in Neural Language Modeling
1
... 注意力机制最早应用于序列转换模型中, 目前, 性能较好的序列转换模型大多基于由循环神经网络和卷积神经网络构成的编码器和解码器, 其中效果最好的模型是通过注意力机制将编码器与解码器进行连接实现的.随着研究的深入, 众多改进的注意力机制被提出并应用于自然语言处理任务中.Lin等[18 ] 提出自注意力机制用于获得句子的向量表示.Daniluk等[19 ] 提出Key-Value Attention应用于神经语言模型.Bahdanau等[20 ] 提出Soft-Attention机制应用于机器翻译任务.Yang等[12 ] 提出涵盖词语级注意力和文档级注意力的层级注意力模型实现文章分类, 其中词语级注意力过程如公式(1)至公式(3)所示. ...
Neural Machine Translation by Jointly Learning to Align and Translate
1
... 注意力机制最早应用于序列转换模型中, 目前, 性能较好的序列转换模型大多基于由循环神经网络和卷积神经网络构成的编码器和解码器, 其中效果最好的模型是通过注意力机制将编码器与解码器进行连接实现的.随着研究的深入, 众多改进的注意力机制被提出并应用于自然语言处理任务中.Lin等[18 ] 提出自注意力机制用于获得句子的向量表示.Daniluk等[19 ] 提出Key-Value Attention应用于神经语言模型.Bahdanau等[20 ] 提出Soft-Attention机制应用于机器翻译任务.Yang等[12 ] 提出涵盖词语级注意力和文档级注意力的层级注意力模型实现文章分类, 其中词语级注意力过程如公式(1)至公式(3)所示. ...
Overview of the NLPCC 2017 Shared Tash: Chinese News Headline Categorization
1
2017
... (1) CNH: 中文新闻标题分类[21 ] .根据新闻标题内容为其分配标签, 如政治、军事、娱乐等, 共18类.训练集包含156 000个样本, 验证集有18 000个样本, 测试集有18 000个样本. ...
A Sentimental Education: Sentiment Analysis Using Subjectivity Summarization Based on Minimum Cuts
1
2004
... (2) MR: 电影评论数据集[22 ] .每一条电影评论作为一条样本.类别为两类: 积极或消极.其中, 数据集包含7 462个训练样本, 1 589个验证样本, 1 589个测试样本. ...
Learning Question Classifiers
1
2002
... (3) TREC: TREC问题分类数据集[23 ] .分类目标是确定问题所属类别标签, 标签共有6类, 即DESC, ENTY, ABBR, HUM, NUM, LOC.训练集包含5 357个样本, 测试集包含592个样本, 由于数据集较小, 验证集等同于测试集. ...
Jointly Modeling Aspects, Ratings and Sentiments for Movie Recommendation (JMARS)
1
2014
... (5) IMDB_10: 电影评分数据集[24 ] .将用户的电影评论根据其评分进行分类.共分为10类, 即评分从 1到10.训练集包含25 000个样本, 验证集包含12 500个样本, 测试集包含12 500个样本. ...
Distributed Representations of Words and Phrases and Their Compositionality
1
2013
... 本文数据集包含中文和英文两种语言.中文文本利用jieba中文分词包完成分词; 英文文本通过空格进行划分.中文词向量采用以中文数据集为语料库, 利用Word2Vec[25 ] 模型训练得到的开源词向量, 维度为300; 考虑到英文样本与Twitter数据具有较高相似性, 而且大规模语料包含词语量更大, 所以英文词向量是由GloVe[26 ] 基于大规模Twitter语料库训练得到的词向量, 维度均为300. ...
Glove: Global Vectors for Word Representation
1
2014
... 本文数据集包含中文和英文两种语言.中文文本利用jieba中文分词包完成分词; 英文文本通过空格进行划分.中文词向量采用以中文数据集为语料库, 利用Word2Vec[25 ] 模型训练得到的开源词向量, 维度为300; 考虑到英文样本与Twitter数据具有较高相似性, 而且大规模语料包含词语量更大, 所以英文词向量是由GloVe[26 ] 基于大规模Twitter语料库训练得到的词向量, 维度均为300. ...







{kind=link}
{kind=link}
{kind=link}
{kind=link}