1 引 言
随着城市化进程加快, 城市发展中面临的城市问题受到社会各界广泛关注。从文献检索结果发现, 现有研究主要关注城市问题的特征表现、原因分析和阶段性治理路径与策略三个层面; 研究领域集中在城市规划学、城市交通学和环境科学等“本位”学科; 缺少综合城市战略决策的大数据分析和情报支持等方面的思考, 也未能将情报服务理念融入到城市问题的解决方案中。尽管有学者提出健全城市舆情收集、研判和回应机制, 提高城市信息感知、分析和利用能力, 是发现并解决城市问题的关键方式[1 ,2 ] ; 但多数研究仍停留在缺少数据支持的城市问题治理模式和应对策略上, 对如何分析和利用海量、异构、动态变化的城市数据, 运用大数据思维和情报服务理念诊治城市问题缺乏经验。
笔者意识到, 感知、分析和利用城市画像, 能够获取公众认知视角下的城市发展概况, 发现城市发展中存在的主要问题; 也有助于搭建政府与公众之间对话的桥梁, 促进形成政府与公众统一的城市发展愿景。鉴于此, 本文从蕴含城市画像要素的社会化标签出发, 运用自然语言处理技术, 提取、清洗、整合社会化标签, 使之形成涵盖城市整体状况的标签集合; 依据标签相似度指标和凝聚式层次聚类算法, 构建具有“分面-亚面”结构的城市画像描述框架; 在改进传统资源模型的基础上, 计算不同社会化标签在揭示城市画像语义特征方面的重要程度, 感知公众对城市整体状况的共同认知, 从而获得揭示城市文化、功能和特性的城市画像。
2 相关研究
20世纪60年代, Lynch首次将印象或译为意象(Mental-Image)的概念应用于城市研究, 认为城市观察者与城市之间的双向作用会产生某种社会印象, 即城市画像。他采用绘制认知地图方法详细分析了波士顿、泽西城和洛杉矶三地的城市画像, 并将其构成要素概括为道路、边沿、区域、节点和标识[3 ] 。此后, 学者们普遍采用与之相似的问卷调查、深度访谈、意向草图等社会学调查方法, 对城市画像的构成要素、区域分布以及品质特征展开研究。然而, Lynch定义的城市画像限定并强调了城市观察者的所见事物, 只关注构筑城市的实体环境, 忽略了公众对城市的非物质认知。自20世纪80年代末以来, 学者们逐渐转变了城市画像的研究视角, 认为城市画像不仅包括公众对实体环境的视觉感知, 还包括公众更为复杂的社会感知, 即构成城市画像的非实体性元素[4 ,5 ] 。由此, 城市画像研究从原本单纯的实体空间结构研究, 发展到综合政治、经济、文化、环境等多种要素的社会研究, 并避开了心理学家感兴趣的个性化差异问题, 重点考虑公众对城市的共同认知。
随着移动终端和社交媒体的普及, 公众可以随时随地在网络中发表自身对某座城市的真实感受。通过分析这些描述城市特征的文字、图片和表情等行为数据, 可以挖掘公众对某座城市整体印象的共同认知。事实上, 社交媒体为过去以调查、访谈、认知地图等社会科学为主要研究手段的城市画像研究提供了大数据分析入口。典型研究包括: 谢永骏等利用社交网络中的微博数据, 运用自然语言处理技术和地理大数据分析方法, 获取城市热点区域的城市特征, 感知不同人群在不同场所的活动态度和偏好[6 ] ; Wong等利用TripAdvior旅游网站上的在线用户评论数据, 通过文本数据挖掘技术提取2005年至2013年间的澳门城市画像, 并应用可视化技术展现该段时间澳门城市画像的演化过程[7 ] ; Liu等运用深度学习技术对Panoramio和Flickr网站上的文本、图像数据集进行分类, 统计分析了全球7个典型城市的城市特征及其空间分布, 并进一步探讨了不同城市之间的相关性和差异性[8 ] 。
此外, 针对社会化标签(Social Tag)的相关理论、技术、方法和模型也在不断发展和完善, 并逐渐服务于多种不同目的的社会化标注系统。在众多研究之中, 采用自然语言处理技术和信息组织与融合技术处理采集的原始标签是所有基于社会化标签研究的研究基础, 其根本原因在于: 社会化标签是大众分类法的产物, 其受控程度较低, 层级结构未被清晰揭示, 致使用户利用标签标记资源时会出现异词同义、一词多义、上下文语境识别困难等诸多自然语言处理问题。这些问题对社会化标签的组织、分析和应用产生了极大影响。因此, 计算机和图书情报等领域的学者类比半结构化文本处理方式, 围绕社会化标签开展了标签清洗去重[9 ] 、可信度评估[10 ] 、层级关系构建[11 ] 、聚类分类[12 ,13 ] 等一系列研究工作, 从而为基于社会化标签的应用研究提供有力支撑。
综上所述, 利用社交网络数据获取、分析城市特征, 并将其分析结果服务于城市规划与管理, 已经得到部分学者的足够重视。城市画像研究与大数据分析、自然语言处理、信息组织与融合等技术(方法)之间存在紧密联系, 其目标是获取公众认知视角下的多维度城市特征标识, 是对以往用户画像研究的拓展和延伸。由此可见, 现有的理念、算法、模型及处理策略均为基于社会化标签的城市画像研究奠定了良好基础。
3 利用层级标签构建多维度的城市画像描述框架
社会化标签中蕴含了构成城市画像的各种因素, 其自身特性也可以保证从中获取城市画像具有可靠性。然而, 传统社会化标签的组织方式依据大众分类法(Folksonomy)。该方式过于自由和随意, 会产生大量重复且语义模糊的信息, 不利于准确地揭示、描述和刻画城市画像。为此, 本文在论述社会化标签对城市画像研究具有重要意义的基础上, 提出一种基于层级标签的城市画像描述框架的构建思路, 并进一步分析利用层级标签构建城市画像描述框架的优势。
3.1 社会化标签对城市画像研究的意义
在社交网络盛行的当下, 社交网络中每天都会产生数以亿计的社会化标签。这些标签涉及公众日常活动的方方面面, 在一定程度上直接或间接地反映了公众对待某件事物的认知和态度。很明显, 公众对某座城市的整体印象也可以通过社交网络中的社会化标签展现出来。某座城市拥有这些社会化标签的分布情况, 蕴含了公众对这座城市的整体评价; 单一社会化标签的标注情况, 反映了公众对这个城市特征的认可程度。
以社会化标签这种资源描述方式揭示城市特征并从中感知城市画像, 既揭示了城市个性与特征, 又体现了城市画像的社会属性。公众在社交网络中生成、描述、交换认知和态度时, 其标注行为和标注结果也受所在网络结构影响。在社会化交互的过程中, 公众因网络互动形成的相对统一的观点、意见和相对稳定的网络结构, 隐含着大量现实的社会关系和客观的资源描述。因此, 发掘、利用这些隐性的节点特征和网络结构, 对提取、分析和利用城市画像具有重要意义。例如, 从相对统一的观点、意见中, 可以抽取公众共同认知的城市画像, 从而避开因个性化差异导致的主观描述; 从相对稳定的网络结构中, 可以获取不同群体对待城市画像的感知差异, 以发现并满足不同群体实际的社会需求。
此外, 依据社会化标签之间的特定关系, 可以将用户、城市和画像关联起来, 构建基于标签语义特征的复杂网络。该网络不仅包含了社会化标签原有的资源描述内容, 而且可以运用社会网络分析方法获取网络结构特征, 进而发现网络节点之间的内在联系。例如, 依据网络结构计量指标中的节点关系强度计算方法, 可以测量不同城市节点之间的亲疏程度, 发现具有相似城市画像的城市社群, 并挖掘隐含在网络结构中的城市关系, 从而有利于更加全面地揭示一座城市的发展概况, 为城市发展和规划提供针对性的参考建议。
3.2 基于层级标签的城市画像描述框架构建思路
城市画像是一种十分复杂的社会感知, 综合了政治、经济、文化、环境等多种要素。公众也往往从多个维度去描述自身对某座城市的整体认知和态度。因此, 需要构建一个城市画像描述框架来揭示城市画像的描述维度。在该框架中, 各个描述维度应该相对独立并具有分面组配的性质, 可以共同组成一个具有层次性、系统性和协调性的客观知识体系。
韩松涛等在《基于“学术单元”的知识组织新框架: 多维度标签构建研究》一书中提出的利用分面组配方法组织、管理社会化标签的思想。韩松涛等人依据现有的客观知识体系, 把社会化标注系统中的全部标签划分为若干个分面(本体、对象、方法等), 并进一步细分为多个亚面(第一本体、核心对象、研究方法等), 从而实现通过组配不同分面下的社会化标签来描述资源特征[14 ] 。在这种具有“分面-亚面”的标签体系结构中, 用户仍然主导定义和选择具体标签。在保证社会化标签的动态性和鲜活性的同时, 整个标签集合具有较为严格和规范的体系结构, 不同粒度标签集合之间相互支持、相互补充, 最终提高了社会化标注系统对复杂资源的揭示和描述能力。
依据上述的构建思路, 某座城市的城市画像应该从多个维度(分面和亚面)揭示, 某个具体维度(分面或亚面)应该由多个处于同级平行结构的社会化标签描述。同时, 城市画像描述框架应该支持将某个维度划分为多个更细粒度的维度(例如, 将某个分面划分为多个亚面)。但必须指出的是, 城市画像描述框架应该仿照多维度资源标注体系, 事先设定并保留预留扩展维度, 以此提高该框架的活力, 为其今后发展及拓展增加可能性。
3.3 利用层级标签构建城市画像描述框架的优势
从信息检索与服务角度看, 社会化标签是用户对网络资源的一种索引或元数据描述。有效组织、存储和利用这种索引或元数据, 可以辅助基于社会化标签的分析与应用研究。然而, 在当前主流的社会标注系统中, 用户添加标签时不主动界定标签之间的语义关系。这样形成标签体系事实上是一种无结构的、平面化标签集合, 缺乏明晰的语义、语用关联, 极大地影响了社会化标注系统中分众分类的有效性, 不能构造出具有语义结构的“标签网络”。简而言之, 在应用层面上, 这种标注机制只能生成“标签云”, 不能直接生成具有层级结构的城市画像描述框架。由此, 本文依据社会化标签之间的潜在层级关系, 生成具有层级结构的标签集合来解决上述问题, 并以此为基础构建城市画像描述框架。
层次化的标签组织结构既可以提高社会化标签的有用性和准确性, 又可以避免公众在语义理解、资源描述及其标引方式等方面由于自身认知结构不同对城市特征的描述结果产生个性化偏差。这种网络资源组织方式与以往社会标注系统中的大众分类法相比更具灵活性和便捷性, 可以根据标签层级实现不同粒度标签集合的合并与集成, 从而优化和序化社会化标注系统中散乱的原始标签集合。与此同时, 公众标注的社会化标签及其生成的标签集合相对独立, 并具有分面组配的性质, 能够在城市画像描述框架中被分解成为多个相互支持、相互补充的层次结构。这种蕴含语义关系的层次结构支持语义网技术标准, 能够生成标签本体和结构化数据集, 从而有利于在社会化标注系统中揭示和利用城市特征。
此外, 基于层级标签构建的城市画像描述框架具有很高的应用性, 可以以此为基础开展不同视角下的城市画像分析与应用研究。例如, 可以分别提取不同维度下公众对某座城市的社会化标签, 依据标签分层聚类后形成的多粒度标签集合, 生成反映公众共同认知的不同城市侧面的城市画像; 还可以通过分析不同维度下城市画像的公众情感特征及其演化规律, 综合评估每座城市发展的实际情况, 并进一步构建由相似或耦合城市画像关系形成的社会网络, 测算各个城市之间的亲疏程度, 发现具有相似城市特征的城市社群。
4 面向城市画像描述框架构建的层级标签生成方法
蕴含城市画像要素的社会化标签的丰富性和准确性是构建城市画像描述框架的基础, 也直接影响了获取、分析和利用城市画像的过程与结果。本文首先通过数据预处理环节规范化处理标签, 提高标签的数据质量; 然后定义标签相似度指标, 计算标签(或标签集合)间的空间距离, 并以此作为确定不同标签(或标签集合)间关系的主要依据; 最后采用凝聚式层次聚类算法, 层次聚类标签(或标签集合), 生成具有“分面-亚面”结构的城市画像描述框架。
4.1 数据预处理
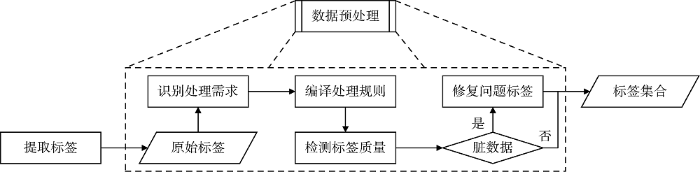
数据预处理目的是提高社会化标签的数据质量, 满足城市画像识别过程中的数据处理要求。数据预处理应从获取的原始标签出发, 分析原始标签存在的主要问题, 并制定相应的标签处理要求; 针对具体的标签处理要求, 编译与之对应的标签处理规则; 最后, 开展数据检测和数据修复工作, 修复存在质量问题的社会化标签。如图1 所示。其中, 数据预处理的重点在于标签清洗、词汇标准化和词汇过滤三个环节。
(1) 标签清洗。通过替换、补全等操作, 规范社会化标签的标注格式, 过滤非正式的社会化标签(例如, 拼写错误、缩写、简写、包含特殊符号等)。
(2) 词汇标准化。依据规范词表(如叙词表、领域词典、WordNet等)规范社会化标签的表达方式, 约束使用词语的数量、顺序和内容, 归并、整合相同语义的社会化标签。
(3) 词汇过滤。过滤停用词和低频词。依据统计结果可知, 出现频率很高的停用词(如感叹词、连词、介词等)和出现频率很低的低频词, 由于揭示城市特征的信息量很少或无具体实意, 应该从原始标签集中删除。
图1
4.2 标签相似度计算
标签相似度计算与文本相似度计算之间存在很大差别。文本中含有大量的语义信息, 可以直接对分词后的两个文本进行余弦相似度计算。而标签大多是少数几个词或短语, 含有的语义信息量很小, 难以利用这种方法获得精确的标签相似度计算结果。现有研究中已有学者利用传统TF-IDF算法对标签进行特征抽取, 以此为基础实现标签间的相似度计算, 并取得了较为精确的标签聚类效果[15 ,16 ] 。本文借鉴这一方法计算标签(或标签集合)之间的相关程度, 从而为生成具有层次结构的城市画像描述框架做数据准备, 其具体步骤如下:
(1) 利用分词技术将标签${{T}_{a}}$划分为n 个经过数据预处理的词${{t}_{i}}$, 并用空间向量${{T}_{a}}=({{t}_{1}},{{t}_{2}},\cdots ,{{t}_{n}})$表示。
(2) 根据TF-IDF算法定义, 如公式(1)所示, 赋予每个词组${{t}_{i}}$相应权重${{w}_{{{t}_{i}}}}$, 并将描述标签${{T}_{a}}$的空间向量表示为: ${{V}_{{{T}_{a}}}}=({{t}_{1}}\times {{w}_{{{t}_{1}}}},{{t}_{2}}\times {{w}_{{{t}_{2}}}},\cdots ,{{t}_{n}}\times {{w}_{{{t}_{n}}}})$。其中, ${{f}_{{{t}_{i}}}}$表示${{t}_{i}}$在${{V}_{{{T}_{i}}}}$中出现的频率; N 表示标签集合拥有所有词组的总数; ${{n}_{{{t}_{i}}}}$表示${{t}_{i}}$在标签集合中出现的次数。
(1) ${{w}_{{{t}_{i}}}}=\log {{f}_{{{t}_{i}}}}\times \log (N/{{n}_{{{t}_{i}}}}+1)$
(3) 计算描述标签的空间向量间的相似度, 以$sim({{v}_{a}},{{v}_{b}})$表示空间向量${{v}_{a}}$和${{v}_{b}}$的相似度为例, 采用余弦相似度计算, 即$sim({{v}_{a}},{{v}_{b}})=\cos ({{v}_{a}},{{v}_{b}})$。此外, 该方法还可以计算标签集合间的平均相似度, 以满足标签聚类等数据处理环节。若定义$si{{m}_{A}}({{C}_{i}},{{C}_{j}})$表示标签集合${{C}_{i}}$与${{C}_{j}}$的平均相似度, 则有公式(2)。
(2) $si{{m}_{A}}({{C}_{i}},{{C}_{j}})=\frac{1}{|{{C}_{i}}||{{C}_{j}}|}\sum\limits_{{{v}_{a}}\in {{C}_{i}}}{\sum\limits_{{{v}_{b}}\in {{C}_{j}}}{\cos ({{v}_{a}},{{v}_{b}})}}$
4.3 基于凝聚式层次聚类的城市画像描述框架生成方法
本文选用凝聚式层次聚类算法(Hierarchical Agglomerative Clustering)构建城市画像描述框架, 其主要原因是: 需要构建具有上下位类等级关系的城市画像描述框架, 而其他常用的聚类方法只能获得平面化的聚类结果(如K-means、EM、AP等); 凝聚式层次聚类算法避免了选择初始点和聚类数, 计算各个社会化标签(或标签集合)之间的距离时会经过多次遍历, 其聚类结果不会陷入局部最优。
具体而言, 基于凝聚式层次聚类构建城市画像描述框架的基本流程是: 通过自底向上地分析目标文档中的所有标签后, 划分聚类样本并确定其中的样本点; 将每个样本点作为一个聚类任务, 根据各空间向量间的距离(即标签相似度$si{{m}_{A}}({{C}_{i}},{{C}_{j}})$)生成标签集合; 不断重复地将距离最近的两个标签集合聚类合并, 直至满足迭代终止条件为止。当聚类算法停止时, 凝聚式层次聚类的最终结果就是具有“分面-亚面”结构的城市画像描述框架。
由此, 本文可以依据城市画像描述框架对所有从社会化标注系统中获取的所有标签进行分类, 进而得到不同城市画像分面(或亚面)下的多粒度标签集合。这些多粒度标签集合是刻画不同分面(或亚面)下城市画像的重要数据来源。
5 基于标签语义挖掘的城市画像提取方法
城市画像是公众对城市整体状况的共同认知。开展城市画像研究时, 应避免纳入公众因自身认知结构不同产生的具有个性化偏差的社会化标签。因此, 本文在改进传统资源模型的基础上, 计算不同标签在揭示城市画像语义特征方面的重要程度, 并以此为主要依据从获取的标签中抽取城市画像。
5.1 基于潜在语义分析的标签权重计算方法
本文利用传统资源模型将城市和标签组成城市-标签矩阵${{A}_{ij}}$, 并以此描述不同城市拥有的城市画像。其中, i 表示社会化标签, j 表示城市, aij 表示社会化标签i 对城市j 的标注次数。然而, 传统资源模型生成的城市-标签矩阵${{A}_{ij}}$仅仅依据标签的标记频次衡量标签对城市的重要程度, 忽略了不同标签分辨城市的能力以及标签确定城市特征语义的能力。有学者发现利用潜在语义分析方法(LSA)不仅能够反映标签在标签集合中的分布情况, 还可以通过加权变换挖掘标签间的潜在语义关系及其语义结构[17 ,18 ] 。权重较大的标签间隐含的语义关系, 以及能够为标签提供更多信息量的资源中包含的标签间的语义关系, 更容易被LSA认为是重要的语义关系因而保留。基于以上分析, 借鉴基于LSA的标签潜在语义挖掘思想, 定义标签-城市矩阵${{A}_{ij}}$的权重值$W(i,j)$由标签局部权重${{P}_{w}}(i,j)$、标签全局权重${{T}_{w}}(i)$和资源全局权重${{R}_{w}}(j)$三个部分构成, 并给出对应权重的量化函数及其推导过程, 如公式(3)-公式(8)所示。
(3) $W(i,j)={{P}_{w}}(i,j)\times {{T}_{w}}(i)\times {{R}_{w}}(j)$
标签局部权重${{P}_{w}}(i,j)$与标签对城市的标注频数有关, 其具体定义如公式(4)所示。
(4) ${{P}_{w}}(i,j)={{\log }_{2}}(P(i,j)+1)$
其中, $P(i,j)$表示标签i 对城市j 中的标注次数; “+1”是为了避免出现$P(i,j)$为0的情况; 取对数是为了避免高频率标签掩盖低频率标签对生成潜在语义空间的贡献。
标签全局权重${{T}_{w}}(i)$的含义和条件熵的定义相同, 其原因在于局部权重$P(i,j)$不能衡量不同标签区别不同城市的能力。本文借鉴条件熵定义[19 ] 标签全局权重${{T}_{w}}(i)$, 将城市集合看作符合某种概率分布的信息源, 将城市和标签看作两个随机变量, 依靠城市集合的信息熵和标签的条件熵之间信息量的增益关系确定社会化标签描述某座城市的重要程度。由此, 在某个标签确定的情况下其对应城市的条件熵计算方法如公式(5)所示。
(5) $H(R|{{T}_{i}})=-\sum\limits_{j}{P({{T}_{i}})P}({{R}_{j}}|{{T}_{i}}){{\log }_{2}}P({{R}_{j}}|{{T}_{i}})$
其中, $P({{R}_{j}}|{{T}_{i}})$表示标签${{T}_{i}}$出现情况下城市${{R}_{j}}$出现的概率。当标签${{T}_{i}}$确定时, $P({{T}_{i}})=1$, 简化公式(5)得到标签全局权重${{T}_{w}}(i)$的计算公式, 如公式(6)所示。
(6) ${{T}_{w}}(i)=1+H(R|{{T}_{i}})=1-\sum\limits_{j}{\left( \frac{P(i,j)}{\sum\limits_{j=1}^{|R|}{P(i,j)}} \right){{\log }_{2}}}\left( \frac{P(i,j)}{\sum\limits_{j=1}^{|R|}{P(i,j)}} \right)$
其中, $\left| R \right|$表示城市集合中城市的总数; $P(i,j)$表示标签${{T}_{i}}$在城市${{R}_{j}}$中出现的频数; $\sum\limits_{j=1}^{|R|}{P(i,j)}$表示标签${{T}_{i}}$在整个城市集合中出现的频数。
资源全局权重${{R}_{w}}(j)$用来解释标签的语义歧义性问题, 其原理来自Gale等人为度量随机事件相关性而提出的信息熵的引申概念“互信息”[20 ] 。利用“互信息”可以揭示不同城市对每个标签提供的信息量, 以此找出与每个标签语义相近的其他标签。依据“互信息”的性质, 本文定义资源全局权重${{R}_{w}}(j)$的计算方法如公式(7)所示。
(7) $\begin{align}& {{R}_{w}}(j)=1+I(T,{{R}_{j}})=1+I({{R}_{j}},T)=1+H({{R}_{j}})-H({{R}_{j}}|T) \\& \ \ \ \ \ \ \ \ \ =1+H({{R}_{j}})+\sum\limits_{i}{\left( \frac{P(i,j)}{\sum\limits_{i=1}^{|T|}{P(i,j)}} \right)}{{\log }_{2}}\left( \frac{P(i,j)}{\sum\limits_{i=1}^{|T|}{P(i,j)}} \right) \\\end{align}$
其中, $\left| T \right|$表示标签集合中标签的总数; $\sum\limits_{i=1}^{|T|}{P(i,j)}$表示标签${{T}_{i}}$在城市${{R}_{j}}$中出现的频数和。由于$H({{R}_{j}})=-P({{R}_{j}}){{\log }_{2}}P({{R}_{j}})$, 可以将$1+H({{R}_{j}})$视为一个常数$M$, 则简化公式(7)可得公式(8)。
(8) ${{R}_{w}}(j)\approx M+\sum\limits_{i}{\left( \frac{P(i,j)}{\sum\limits_{i=1}^{|T|}{P(i,j)}} \right)}{{\log }_{2}}\left( \frac{P(i,j)}{\sum\limits_{i=1}^{|T|}{P(i,j)}} \right)$
5.2 城市画像抽取方法
城市画像是公众对城市的群体印象, 而不是个体的特有印象。由于城市的复杂性和动态性, 以及个体在生活经历和文化背景等方面的差异, 公众描述城市画像的社会化标签带有明显的个性化色彩。因此, 应该对多粒度标签集合中的标签进行筛选, 以此获取每座城市在多数公众心中共同的心理图像。为避免纳入因个体差异产生的标签, 本文依据权重值$W(i,j)$从多粒度标签集合中抽取公众共同认知的城市画像, 并生成最终的标签-城市矩阵$A_{ij}^{'}$, 如公式(9)所示。
(9) $A_{ij}^{'}={{t}_{i}}|W(i,j)={{t}_{i}}|{{P}_{w}}(i,j)\times {{T}_{w}}(i)\times {{R}_{w}}(j)$
此外, 运用奇异值分解法(SVD)语义标引标签-城市矩阵$A_{ij}^{'}$, 生成更为小巧的语义空间结构, 可以降低矩阵计算的复杂度, 缩小计算问题的规模。与此同时, 将LSA与SVD结合也可以揭示出词语之间潜在的语义关系, 有助于识别“一词多义”和“多词一义”现象。由此, 标签在标签-城市矩阵$A_{ij}^{'}$中的最终权重均从标签标注频数、区分城市能力、语义相近的其他标签三个方面衡量。每座城市的城市画像就是其对应标签集合中具有较高权重的标签。它们依然隶属于本文构建的城市画像描述框架之下, 具有凝聚式层次聚类之后的“分面-亚面”结构及其特性。
6 实证研究
6.1 实验数据获取
利用网络爬虫技术获取知乎平台中描述中国中部6省省会城市(长沙、合肥、南昌、太原、武汉、郑州)主要特征的用户问答内容, 包括“XX是一个怎样的城市?”、“关于XX, 你印象最深的是什么?”、“XX有什么好玩的地方?”等58个话题, 涉及公众对各城市在经济、政治、环境、人文等多个维度的用户问答内容。同时, 为获得规范化的社会化标签, 满足城市画像提取过程中的数据处理要求, 按照上文所述的数据预处理步骤, 依据编译处理规则对原始数据进行数据清洗, 通过词汇标准化处理和过滤得到18 406条规范化标签, 并以此作为实证部分的基础数据。
选择知乎平台获取公众描述城市整体状况的社会化标签, 主要基于以下考虑: 首先, 知乎社区中话题丰富, 不仅包含大量涉及城市各个方面的有关城市特征的话题, 而且能够反映公众对城市的整体认知, 符合本文对数据集在全面性上的要求; 其次, 与其他网站相比, 知乎社区中用户评论更符合本文对数据集在客观性上的要求。例如, 城市留言板中涉及的用户评论多为公众对政府部门的诉求, 多为负面情绪; 而知乎社区中涉及的用户评论更多的是网络用户对某座城市的客观评价。
6.2 城市画像描述框架构建过程
以数据预处理后的社会化标签为标签集合, 利用文本空间向量表示社会化标签; 通过计算空间向量之间的余弦相似度衡量社会化标签之间的相似度, 进而根据相似度构造社会化标签之间的相异矩阵; 将相异矩阵导入SPSS, 通过凝聚式层次聚类算法聚类标签集合, 最终形成具有层次结构的城市画像描述框架。
首先借助分词词库(搜狗细胞词库——“XX市城市信息精选”词库)和自建停用词表, 利用自动分词技术将社会化标签表示为文本空间向量, 并根据公式(1)计算文本空间向量中各个词组的语义权重, 如表1 所示; 然后依据空间余弦相似度计算公式获取社会化标签之间的语义相似度, 如表2 所示。
为使社会化标签依据语义相似度聚集起来生成具有层级结构的城市画像描述框架, 首先利用表2 中的计算结果, 生成标签间的语义相异度矩阵。具体计算方法是标签间的语义相异度等于1减去标签间的语义相似度, 假如标签${{T}_{a}}$与${{T}_{b}}$间的语义相似度为0.3, 则它们之间的语义相异度为0.7。然后, 将语义相异度矩阵导入SPSS中, 借助Ward算法对所有标签进行凝聚式层次聚类。最后, 通过人工划分聚类主题, 获得具有“分面-亚面”结构的城市画像描述框架, 如图2 所示。
图2
6.3 城市画像提取过程
依据不同标签标记各城市的次数构建原始城市-标签矩阵$A{}_{ij}$, 如表3 所示; 按照公式(9)的标签权重计算方法, 进一步挖掘标签间的潜在语义关系, 对原始城市-标签矩阵进行加权变换。
为避免掩盖低频标签对生成潜在语义空间的贡献, 按照公式(4)计算原始矩阵中各标签的标签局部权重${{P}_{w}}(i,j)$, 结果如表4 所示。对比表3 与表4 可以发现: 标签局部权重${{P}_{w}}(i,j)$缩小了高频标签与低频标签之间的差距, 在一定程度上有助于提高低频标签对提取城市画像的贡献。
为衡量各标签对不同城市的区分能力, 按照公式(6)计算各标签的标签局部权重${{T}_{w}}(i)$。根据表5 可知, 标签“有雾霾”和“发展快”对中国中部6省省会城市的整体解释能力较大, 难以依据它们区分不同城市的城市特征; 标签“小龙虾”和“面食多”对中部6省省会城市的整体解释能力较小, 能够较为容易依据它们分辨出不同城市的城市特征。
为了揭示不同城市对各标签提供的信息量, 按照公式(8)计算不同城市的资源全局权重的指标${{R}_{w}}(j)$, 结果如表6 所示。实验结果表明, 在中部6省省会城市中, 郑州为标签集合提供的信息量最多; 长沙为标签集合提供的信息量最少。由此可知, 描述郑州城市特征的社会化标签更具有通用性, 而长沙城市特征的社会化标签更具有独特性。
依据标签局部权重${{P}_{w}}(i,j)$、标签全局权重${{T}_{w}}(i)$和资源全局权重${{R}_{w}}(j)$的计算结果生成最终的标签-城市矩阵$A_{ij}^{'}$, 实现从标签标注频数、区分城市特征能力、语义相近的其他标签三个方面衡量不同标签对各座城市的重要程度, 如表7 所示。标签对城市的权重大小能够反映公众对该标签能否作为城市当前城市画像的共同认知。某座城市当前的城市画像由其对应标签集合中具有较高权重的标签组成。依据权重值降序排列不同城市对应标签集合中的社会化标签, 可以选取权重值较高的社会化标签作为描述城市画像的基础数据, 进而依据构建的城市画像描述框架对抽取出的社会化标签进行分类, 最终可以获得具有层级结构的中国中部6省省会城市的城市画像。
由表7 可知, 社交网络中公众描述一座城市的主要特征时, 着重考虑“饮食特色”、“历史文化”、“气候状况”、“污染状况”、“居住感受”、“城市发展”、“包容性”、“吸引力”、“交通”、“物价”、“收入”等方面。在这些分面(或亚面)下根据标签权重筛选出来的城市画像描述, 就像是城市的一张名片, 能够突出反映不同城市的个性与特征, 展现不同城市的形象与内涵。与图2 所述的城市画像描述框架相比, 尽管这些城市画像描述难以完全覆盖一座城市的所有特征, 但却对城市的规划与管理、城市特色的塑造、城市文化的传承等方面具有重要意义。在实际应用过程中, 可以基于城市画像描述框架选择特定分面(或亚面)下的标签权重计算结果, 以此获得不同城市在不同维度、不同粒度的城市画像描述。
7 结 语
本文提出基于层级标签的城市画像描述框架构建思路、主要优势及其现实方法; 借助LSA衡量不同社会化标签在揭示城市特征方面的能力; 以“知乎”平台中描述中部6省省会城市主要特征的用户问答内容作为数据源, 获得公众对这些城市在各个方面的共同认知。实验结果表明, 本文提出的研究方法能够基于潜在语义关系从海量标签中提取反映公众认知的城市画像, 并能深入到层级结构内部展开细粒度的城市画像描述。然而, 原始实验数据中标签质量直接决定着抽取出的城市画像的质量。随着自然语言处理技术的日益发展, 如何实现从社会化问答社区中自动化抽取高质量的社会化标签, 并引入语义词典计算标签语义相似度有待进一步探究。
作者贡献声明
毕崇武: 设计研究方案, 论文起草和最终版本修订;
叶光辉: 提出研究思路, 对论文内容提出修改意见;
支撑数据
支撑数据由作者自存储, E-mail: 3879-4081@163.com。
[1] 毕崇武, 叶光辉, 李明倩, 曾杰妍. answerdata.xlsx. 2011-2019年“知乎”平台中部6省省会城市主要特征回答数据集.
[2] 毕崇武, 叶光辉, 李明倩, 曾杰妍. tagdata.xlsx. 人工抽取社会化标签数据集.
[3] 毕崇武, 叶光辉, 李明倩, 曾杰妍. clusteringresult.xlsx. 中部6省省会城市社会化标签聚类结果.
[4] 毕崇武, 叶光辉, 李明倩, 曾杰妍. cityprofiles.xlsx. 中部6省省会城市的城市画像提取结果.
参考文献
View Option
[1]
李纲 , 李阳 . 面向决策的“城市病”诊治情报服务探索
[J]. 图书情报工作 , 2016 ,60 (14 ):121 -127 .
[本文引用: 1]
( Li Gang Li Yang . Decision-Oriented Intelligence Service on the Diagnosis and Treatment of the “Urban Disease”
[J]. Library and Information Service , 2016 ,60 (14 ):121 -127 .)
[本文引用: 1]
[2]
李阳 , 李纲 . 从情报学视角看“城市病”:一个新的解析与应用
[J]. 情报杂志 , 2016 ,35 (7 ):31 -36 .
[本文引用: 1]
( Li Yang Li Gang . Some Studies on Urban Disease from the Perspective of Intelligence Studies: New Analysis and Application
[J]. Journal of Intelligence , 2016 ,35 (7 ):31 -36 .)
[本文引用: 1]
[3]
林奇·凯文 . 城市的印象 [M]. 项秉仁译. 北京 : 中国建筑工业出版社 , 1990 .
[本文引用: 1]
( Lynch K . Impression of the City [M]. Translated by Xiang Bingren. Beijing : China Architecture & Building Press , 1990 .)
[本文引用: 1]
[4]
Laaksonen P Laaksonen M Borisov P , et al . Measuring Image of a City: A Qualitative Approach with Case Example
[J]. Place Branding , 2006 ,2 (3 ):210 -219 .
[本文引用: 1]
[5]
Luque-Martínez T Barrio-García S D Ibáñez-Zapata J Á , et al . Modeling a City’s Image: The Case of Granada
[J]. Cities , 2007 ,24 (5 ):335 -352 .
[本文引用: 1]
[6]
谢永俊 , 彭霞 , 黄舟 , 等 . 基于微博数据的北京市热点区域意象感知
[J]. 地理科学进展 , 2017 ,36 (9 ):1099 -1110 .
[本文引用: 1]
( Xie Yongjun Peng Xia Huang Zhou , et al . Image Perception of Beijing’s Regional Hotspots Based on Microblog Data
[J]. Progress in Geography , 2017 ,36 (9 ):1099 -1110 .)
[本文引用: 1]
[7]
Wong C U I Qi S . Tracking the Evolution of a Destination’s Image by Text-mining Online Reviews - the Case of Macau
[J]. Tourism Management Perspectives , 2017 ,23 :19 -29 .
[本文引用: 1]
[8]
Liu L Zhou B L Zhao J H , et al . C-IMAGE: City Cognitive Mapping Through Geo-tagged Photos
[J]. Geo Journal , 2016 ,81 (6 ):817 -861 .
[本文引用: 1]
[9]
张恒婷 . 社交网络图像垃圾标签去除研究
[D]. 保定: 华北电力大学 , 2012 .
[本文引用: 1]
( Zhang Hengting . Research on Filtering Tag Spam of Social Network Images
[D]. Baoding:North China Electric Power University , 2012 .)
[本文引用: 1]
[10]
王贤兵 . 社会标注可信度评价方法研究
[D]. 武汉: 华中科技大学 , 2012 .
[本文引用: 1]
( Wang Xianbing . Research on Method of Evaluating Confidence of Social Annotations
[D]. Wuhan: Huazhong University of Science & Technology , 2012 .)
[本文引用: 1]
[11]
刘苏祺 , 白光伟 , 沈航 . 基于用户自描述标签的层次分类体系构建方法
[J]. 计算机科学 , 2016 ,43 (7 ):224 -229, 239 .
[本文引用: 1]
( Liu Suqi Bai Guangwei Shen Hang . Taxonomy Construction Based on User Self-describling Tags
[J]. Computer Science , 2016 ,43 (7 ):224 -229, 239 .)
[本文引用: 1]
[12]
杨尊琦 , 赵瑾珺 . 新浪微博用户领域分类标签的结构和互动研究
[J]. 情报杂志 , 2014 ,33 (4 ):122 -127 .
[本文引用: 1]
( Yang Zunqi Zhao Jinjun . Structure and Interaction: The User Category Tags on the Sina Microblog
[J]. Journal of Intelligence , 2014 ,33 (4 ):122 -127 .)
[本文引用: 1]
[13]
于海鹏 , 翟红生 . 一种子空间聚类算法在多标签文本分类中应用
[J]. 计算机应用与软件 , 2014 ,31 (8 ):288 -291 .
[本文引用: 1]
( Yu Haipeng Zhai Hongsheng . Applying a Subspace Clustering Algorithm in Multi-label Text Classification
[J]. Computer Applications and Software , 2014 ,31 (8 ):288 -291 .)
[本文引用: 1]
[14]
韩松涛 , 潘云鹤 . 基于“学术单元”的知识组织新框架: 多维度标签构建研究 [M]. 杭州 : 浙江大学出版社 , 2017 .
[本文引用: 1]
( Han Songtao Pan Yunhe . A New Framework for Knowledge Organization Based on “Academic Unit” [M]. Hangzhou : Zhejiang University Press , 2017 .)
[本文引用: 1]
[15]
曹高辉 , 焦玉英 , 成全 . 基于凝聚式层次聚类算法的标签聚类研究
[J]. 现代图书情报技术 , 2008 (4 ):23 -28 .
[本文引用: 1]
( Cao Gaohui Jiao Yuying Cheng Quan . Research on Tag Cluster Based on Hierarchical Agglomerative Clustering Algorithm
[J]. New Technology of Library and Information Service , 2008 (4 ):23 -28 .)
[本文引用: 1]
[16]
熊回香 . 面向Web3.0的大众分类研究
[D]. 武汉: 华中师范大学 , 2011 .
[本文引用: 1]
( Xiong Huixiang . Research on Folksonomy Oriented to Web3.0
[D]. Wuhan: Central China Normal University , 2011 .)
[本文引用: 1]
[17]
宣云干 . 基于潜在语义分析的社会化标注系统标签语义检索研究
[D]. 南京: 南京大学 , 2011 .
[本文引用: 1]
( Xuan Yungan . Research on Tag Semantic Retrieval Based on LSA in Social Tagging System
[D]. Nanjing: Nanjing University , 2011 .)
[本文引用: 1]
[18]
宣云干 . 社会化标签的语义检索研究 [M]. 南京 : 东南大学出版社 , 2013 .
[本文引用: 1]
( Xuan Yungan . Research on Semantic Retrieval of Social Tags [M]. Nanjing : Southeast University Press , 2013 .)
[本文引用: 1]
[19]
Shannon C E . A Mathematical Theory of Communication
[J]. The Bell System Technical Journal , 1948 ,27 (3 ):379 -423 .
[本文引用: 1]
[20]
Gale W A Church K W Yarowsky D . A Method for Disambiguating Word Senses in a Large Corpus
[J]. Computers & the Humanities , 1992 ,26 (5-6 ):415 -439 .
[本文引用: 1]
面向决策的“城市病”诊治情报服务探索
1
2016
... 随着城市化进程加快, 城市发展中面临的城市问题受到社会各界广泛关注.从文献检索结果发现, 现有研究主要关注城市问题的特征表现、原因分析和阶段性治理路径与策略三个层面; 研究领域集中在城市规划学、城市交通学和环境科学等“本位”学科; 缺少综合城市战略决策的大数据分析和情报支持等方面的思考, 也未能将情报服务理念融入到城市问题的解决方案中.尽管有学者提出健全城市舆情收集、研判和回应机制, 提高城市信息感知、分析和利用能力, 是发现并解决城市问题的关键方式[1 ,2 ] ; 但多数研究仍停留在缺少数据支持的城市问题治理模式和应对策略上, 对如何分析和利用海量、异构、动态变化的城市数据, 运用大数据思维和情报服务理念诊治城市问题缺乏经验. ...
面向决策的“城市病”诊治情报服务探索
1
2016
... 随着城市化进程加快, 城市发展中面临的城市问题受到社会各界广泛关注.从文献检索结果发现, 现有研究主要关注城市问题的特征表现、原因分析和阶段性治理路径与策略三个层面; 研究领域集中在城市规划学、城市交通学和环境科学等“本位”学科; 缺少综合城市战略决策的大数据分析和情报支持等方面的思考, 也未能将情报服务理念融入到城市问题的解决方案中.尽管有学者提出健全城市舆情收集、研判和回应机制, 提高城市信息感知、分析和利用能力, 是发现并解决城市问题的关键方式[1 ,2 ] ; 但多数研究仍停留在缺少数据支持的城市问题治理模式和应对策略上, 对如何分析和利用海量、异构、动态变化的城市数据, 运用大数据思维和情报服务理念诊治城市问题缺乏经验. ...
从情报学视角看“城市病”:一个新的解析与应用
1
2016
... 随着城市化进程加快, 城市发展中面临的城市问题受到社会各界广泛关注.从文献检索结果发现, 现有研究主要关注城市问题的特征表现、原因分析和阶段性治理路径与策略三个层面; 研究领域集中在城市规划学、城市交通学和环境科学等“本位”学科; 缺少综合城市战略决策的大数据分析和情报支持等方面的思考, 也未能将情报服务理念融入到城市问题的解决方案中.尽管有学者提出健全城市舆情收集、研判和回应机制, 提高城市信息感知、分析和利用能力, 是发现并解决城市问题的关键方式[1 ,2 ] ; 但多数研究仍停留在缺少数据支持的城市问题治理模式和应对策略上, 对如何分析和利用海量、异构、动态变化的城市数据, 运用大数据思维和情报服务理念诊治城市问题缺乏经验. ...
从情报学视角看“城市病”:一个新的解析与应用
1
2016
... 随着城市化进程加快, 城市发展中面临的城市问题受到社会各界广泛关注.从文献检索结果发现, 现有研究主要关注城市问题的特征表现、原因分析和阶段性治理路径与策略三个层面; 研究领域集中在城市规划学、城市交通学和环境科学等“本位”学科; 缺少综合城市战略决策的大数据分析和情报支持等方面的思考, 也未能将情报服务理念融入到城市问题的解决方案中.尽管有学者提出健全城市舆情收集、研判和回应机制, 提高城市信息感知、分析和利用能力, 是发现并解决城市问题的关键方式[1 ,2 ] ; 但多数研究仍停留在缺少数据支持的城市问题治理模式和应对策略上, 对如何分析和利用海量、异构、动态变化的城市数据, 运用大数据思维和情报服务理念诊治城市问题缺乏经验. ...
1
1990
... 20世纪60年代, Lynch首次将印象或译为意象(Mental-Image)的概念应用于城市研究, 认为城市观察者与城市之间的双向作用会产生某种社会印象, 即城市画像.他采用绘制认知地图方法详细分析了波士顿、泽西城和洛杉矶三地的城市画像, 并将其构成要素概括为道路、边沿、区域、节点和标识[3 ] .此后, 学者们普遍采用与之相似的问卷调查、深度访谈、意向草图等社会学调查方法, 对城市画像的构成要素、区域分布以及品质特征展开研究.然而, Lynch定义的城市画像限定并强调了城市观察者的所见事物, 只关注构筑城市的实体环境, 忽略了公众对城市的非物质认知.自20世纪80年代末以来, 学者们逐渐转变了城市画像的研究视角, 认为城市画像不仅包括公众对实体环境的视觉感知, 还包括公众更为复杂的社会感知, 即构成城市画像的非实体性元素[4 ,5 ] .由此, 城市画像研究从原本单纯的实体空间结构研究, 发展到综合政治、经济、文化、环境等多种要素的社会研究, 并避开了心理学家感兴趣的个性化差异问题, 重点考虑公众对城市的共同认知. ...
1
1990
... 20世纪60年代, Lynch首次将印象或译为意象(Mental-Image)的概念应用于城市研究, 认为城市观察者与城市之间的双向作用会产生某种社会印象, 即城市画像.他采用绘制认知地图方法详细分析了波士顿、泽西城和洛杉矶三地的城市画像, 并将其构成要素概括为道路、边沿、区域、节点和标识[3 ] .此后, 学者们普遍采用与之相似的问卷调查、深度访谈、意向草图等社会学调查方法, 对城市画像的构成要素、区域分布以及品质特征展开研究.然而, Lynch定义的城市画像限定并强调了城市观察者的所见事物, 只关注构筑城市的实体环境, 忽略了公众对城市的非物质认知.自20世纪80年代末以来, 学者们逐渐转变了城市画像的研究视角, 认为城市画像不仅包括公众对实体环境的视觉感知, 还包括公众更为复杂的社会感知, 即构成城市画像的非实体性元素[4 ,5 ] .由此, 城市画像研究从原本单纯的实体空间结构研究, 发展到综合政治、经济、文化、环境等多种要素的社会研究, 并避开了心理学家感兴趣的个性化差异问题, 重点考虑公众对城市的共同认知. ...
Measuring Image of a City: A Qualitative Approach with Case Example
1
2006
... 20世纪60年代, Lynch首次将印象或译为意象(Mental-Image)的概念应用于城市研究, 认为城市观察者与城市之间的双向作用会产生某种社会印象, 即城市画像.他采用绘制认知地图方法详细分析了波士顿、泽西城和洛杉矶三地的城市画像, 并将其构成要素概括为道路、边沿、区域、节点和标识[3 ] .此后, 学者们普遍采用与之相似的问卷调查、深度访谈、意向草图等社会学调查方法, 对城市画像的构成要素、区域分布以及品质特征展开研究.然而, Lynch定义的城市画像限定并强调了城市观察者的所见事物, 只关注构筑城市的实体环境, 忽略了公众对城市的非物质认知.自20世纪80年代末以来, 学者们逐渐转变了城市画像的研究视角, 认为城市画像不仅包括公众对实体环境的视觉感知, 还包括公众更为复杂的社会感知, 即构成城市画像的非实体性元素[4 ,5 ] .由此, 城市画像研究从原本单纯的实体空间结构研究, 发展到综合政治、经济、文化、环境等多种要素的社会研究, 并避开了心理学家感兴趣的个性化差异问题, 重点考虑公众对城市的共同认知. ...
Modeling a City’s Image: The Case of Granada
1
2007
... 20世纪60年代, Lynch首次将印象或译为意象(Mental-Image)的概念应用于城市研究, 认为城市观察者与城市之间的双向作用会产生某种社会印象, 即城市画像.他采用绘制认知地图方法详细分析了波士顿、泽西城和洛杉矶三地的城市画像, 并将其构成要素概括为道路、边沿、区域、节点和标识[3 ] .此后, 学者们普遍采用与之相似的问卷调查、深度访谈、意向草图等社会学调查方法, 对城市画像的构成要素、区域分布以及品质特征展开研究.然而, Lynch定义的城市画像限定并强调了城市观察者的所见事物, 只关注构筑城市的实体环境, 忽略了公众对城市的非物质认知.自20世纪80年代末以来, 学者们逐渐转变了城市画像的研究视角, 认为城市画像不仅包括公众对实体环境的视觉感知, 还包括公众更为复杂的社会感知, 即构成城市画像的非实体性元素[4 ,5 ] .由此, 城市画像研究从原本单纯的实体空间结构研究, 发展到综合政治、经济、文化、环境等多种要素的社会研究, 并避开了心理学家感兴趣的个性化差异问题, 重点考虑公众对城市的共同认知. ...
基于微博数据的北京市热点区域意象感知
1
2017
... 随着移动终端和社交媒体的普及, 公众可以随时随地在网络中发表自身对某座城市的真实感受.通过分析这些描述城市特征的文字、图片和表情等行为数据, 可以挖掘公众对某座城市整体印象的共同认知.事实上, 社交媒体为过去以调查、访谈、认知地图等社会科学为主要研究手段的城市画像研究提供了大数据分析入口.典型研究包括: 谢永骏等利用社交网络中的微博数据, 运用自然语言处理技术和地理大数据分析方法, 获取城市热点区域的城市特征, 感知不同人群在不同场所的活动态度和偏好[6 ] ; Wong等利用TripAdvior旅游网站上的在线用户评论数据, 通过文本数据挖掘技术提取2005年至2013年间的澳门城市画像, 并应用可视化技术展现该段时间澳门城市画像的演化过程[7 ] ; Liu等运用深度学习技术对Panoramio和Flickr网站上的文本、图像数据集进行分类, 统计分析了全球7个典型城市的城市特征及其空间分布, 并进一步探讨了不同城市之间的相关性和差异性[8 ] . ...
基于微博数据的北京市热点区域意象感知
1
2017
... 随着移动终端和社交媒体的普及, 公众可以随时随地在网络中发表自身对某座城市的真实感受.通过分析这些描述城市特征的文字、图片和表情等行为数据, 可以挖掘公众对某座城市整体印象的共同认知.事实上, 社交媒体为过去以调查、访谈、认知地图等社会科学为主要研究手段的城市画像研究提供了大数据分析入口.典型研究包括: 谢永骏等利用社交网络中的微博数据, 运用自然语言处理技术和地理大数据分析方法, 获取城市热点区域的城市特征, 感知不同人群在不同场所的活动态度和偏好[6 ] ; Wong等利用TripAdvior旅游网站上的在线用户评论数据, 通过文本数据挖掘技术提取2005年至2013年间的澳门城市画像, 并应用可视化技术展现该段时间澳门城市画像的演化过程[7 ] ; Liu等运用深度学习技术对Panoramio和Flickr网站上的文本、图像数据集进行分类, 统计分析了全球7个典型城市的城市特征及其空间分布, 并进一步探讨了不同城市之间的相关性和差异性[8 ] . ...
Tracking the Evolution of a Destination’s Image by Text-mining Online Reviews - the Case of Macau
1
2017
... 随着移动终端和社交媒体的普及, 公众可以随时随地在网络中发表自身对某座城市的真实感受.通过分析这些描述城市特征的文字、图片和表情等行为数据, 可以挖掘公众对某座城市整体印象的共同认知.事实上, 社交媒体为过去以调查、访谈、认知地图等社会科学为主要研究手段的城市画像研究提供了大数据分析入口.典型研究包括: 谢永骏等利用社交网络中的微博数据, 运用自然语言处理技术和地理大数据分析方法, 获取城市热点区域的城市特征, 感知不同人群在不同场所的活动态度和偏好[6 ] ; Wong等利用TripAdvior旅游网站上的在线用户评论数据, 通过文本数据挖掘技术提取2005年至2013年间的澳门城市画像, 并应用可视化技术展现该段时间澳门城市画像的演化过程[7 ] ; Liu等运用深度学习技术对Panoramio和Flickr网站上的文本、图像数据集进行分类, 统计分析了全球7个典型城市的城市特征及其空间分布, 并进一步探讨了不同城市之间的相关性和差异性[8 ] . ...
C-IMAGE: City Cognitive Mapping Through Geo-tagged Photos
1
2016
... 随着移动终端和社交媒体的普及, 公众可以随时随地在网络中发表自身对某座城市的真实感受.通过分析这些描述城市特征的文字、图片和表情等行为数据, 可以挖掘公众对某座城市整体印象的共同认知.事实上, 社交媒体为过去以调查、访谈、认知地图等社会科学为主要研究手段的城市画像研究提供了大数据分析入口.典型研究包括: 谢永骏等利用社交网络中的微博数据, 运用自然语言处理技术和地理大数据分析方法, 获取城市热点区域的城市特征, 感知不同人群在不同场所的活动态度和偏好[6 ] ; Wong等利用TripAdvior旅游网站上的在线用户评论数据, 通过文本数据挖掘技术提取2005年至2013年间的澳门城市画像, 并应用可视化技术展现该段时间澳门城市画像的演化过程[7 ] ; Liu等运用深度学习技术对Panoramio和Flickr网站上的文本、图像数据集进行分类, 统计分析了全球7个典型城市的城市特征及其空间分布, 并进一步探讨了不同城市之间的相关性和差异性[8 ] . ...
社交网络图像垃圾标签去除研究
1
2012
... 此外, 针对社会化标签(Social Tag)的相关理论、技术、方法和模型也在不断发展和完善, 并逐渐服务于多种不同目的的社会化标注系统.在众多研究之中, 采用自然语言处理技术和信息组织与融合技术处理采集的原始标签是所有基于社会化标签研究的研究基础, 其根本原因在于: 社会化标签是大众分类法的产物, 其受控程度较低, 层级结构未被清晰揭示, 致使用户利用标签标记资源时会出现异词同义、一词多义、上下文语境识别困难等诸多自然语言处理问题.这些问题对社会化标签的组织、分析和应用产生了极大影响.因此, 计算机和图书情报等领域的学者类比半结构化文本处理方式, 围绕社会化标签开展了标签清洗去重[9 ] 、可信度评估[10 ] 、层级关系构建[11 ] 、聚类分类[12 ,13 ] 等一系列研究工作, 从而为基于社会化标签的应用研究提供有力支撑. ...
社交网络图像垃圾标签去除研究
1
2012
... 此外, 针对社会化标签(Social Tag)的相关理论、技术、方法和模型也在不断发展和完善, 并逐渐服务于多种不同目的的社会化标注系统.在众多研究之中, 采用自然语言处理技术和信息组织与融合技术处理采集的原始标签是所有基于社会化标签研究的研究基础, 其根本原因在于: 社会化标签是大众分类法的产物, 其受控程度较低, 层级结构未被清晰揭示, 致使用户利用标签标记资源时会出现异词同义、一词多义、上下文语境识别困难等诸多自然语言处理问题.这些问题对社会化标签的组织、分析和应用产生了极大影响.因此, 计算机和图书情报等领域的学者类比半结构化文本处理方式, 围绕社会化标签开展了标签清洗去重[9 ] 、可信度评估[10 ] 、层级关系构建[11 ] 、聚类分类[12 ,13 ] 等一系列研究工作, 从而为基于社会化标签的应用研究提供有力支撑. ...
社会标注可信度评价方法研究
1
2012
... 此外, 针对社会化标签(Social Tag)的相关理论、技术、方法和模型也在不断发展和完善, 并逐渐服务于多种不同目的的社会化标注系统.在众多研究之中, 采用自然语言处理技术和信息组织与融合技术处理采集的原始标签是所有基于社会化标签研究的研究基础, 其根本原因在于: 社会化标签是大众分类法的产物, 其受控程度较低, 层级结构未被清晰揭示, 致使用户利用标签标记资源时会出现异词同义、一词多义、上下文语境识别困难等诸多自然语言处理问题.这些问题对社会化标签的组织、分析和应用产生了极大影响.因此, 计算机和图书情报等领域的学者类比半结构化文本处理方式, 围绕社会化标签开展了标签清洗去重[9 ] 、可信度评估[10 ] 、层级关系构建[11 ] 、聚类分类[12 ,13 ] 等一系列研究工作, 从而为基于社会化标签的应用研究提供有力支撑. ...
社会标注可信度评价方法研究
1
2012
... 此外, 针对社会化标签(Social Tag)的相关理论、技术、方法和模型也在不断发展和完善, 并逐渐服务于多种不同目的的社会化标注系统.在众多研究之中, 采用自然语言处理技术和信息组织与融合技术处理采集的原始标签是所有基于社会化标签研究的研究基础, 其根本原因在于: 社会化标签是大众分类法的产物, 其受控程度较低, 层级结构未被清晰揭示, 致使用户利用标签标记资源时会出现异词同义、一词多义、上下文语境识别困难等诸多自然语言处理问题.这些问题对社会化标签的组织、分析和应用产生了极大影响.因此, 计算机和图书情报等领域的学者类比半结构化文本处理方式, 围绕社会化标签开展了标签清洗去重[9 ] 、可信度评估[10 ] 、层级关系构建[11 ] 、聚类分类[12 ,13 ] 等一系列研究工作, 从而为基于社会化标签的应用研究提供有力支撑. ...
基于用户自描述标签的层次分类体系构建方法
1
2016
... 此外, 针对社会化标签(Social Tag)的相关理论、技术、方法和模型也在不断发展和完善, 并逐渐服务于多种不同目的的社会化标注系统.在众多研究之中, 采用自然语言处理技术和信息组织与融合技术处理采集的原始标签是所有基于社会化标签研究的研究基础, 其根本原因在于: 社会化标签是大众分类法的产物, 其受控程度较低, 层级结构未被清晰揭示, 致使用户利用标签标记资源时会出现异词同义、一词多义、上下文语境识别困难等诸多自然语言处理问题.这些问题对社会化标签的组织、分析和应用产生了极大影响.因此, 计算机和图书情报等领域的学者类比半结构化文本处理方式, 围绕社会化标签开展了标签清洗去重[9 ] 、可信度评估[10 ] 、层级关系构建[11 ] 、聚类分类[12 ,13 ] 等一系列研究工作, 从而为基于社会化标签的应用研究提供有力支撑. ...
基于用户自描述标签的层次分类体系构建方法
1
2016
... 此外, 针对社会化标签(Social Tag)的相关理论、技术、方法和模型也在不断发展和完善, 并逐渐服务于多种不同目的的社会化标注系统.在众多研究之中, 采用自然语言处理技术和信息组织与融合技术处理采集的原始标签是所有基于社会化标签研究的研究基础, 其根本原因在于: 社会化标签是大众分类法的产物, 其受控程度较低, 层级结构未被清晰揭示, 致使用户利用标签标记资源时会出现异词同义、一词多义、上下文语境识别困难等诸多自然语言处理问题.这些问题对社会化标签的组织、分析和应用产生了极大影响.因此, 计算机和图书情报等领域的学者类比半结构化文本处理方式, 围绕社会化标签开展了标签清洗去重[9 ] 、可信度评估[10 ] 、层级关系构建[11 ] 、聚类分类[12 ,13 ] 等一系列研究工作, 从而为基于社会化标签的应用研究提供有力支撑. ...
新浪微博用户领域分类标签的结构和互动研究
1
2014
... 此外, 针对社会化标签(Social Tag)的相关理论、技术、方法和模型也在不断发展和完善, 并逐渐服务于多种不同目的的社会化标注系统.在众多研究之中, 采用自然语言处理技术和信息组织与融合技术处理采集的原始标签是所有基于社会化标签研究的研究基础, 其根本原因在于: 社会化标签是大众分类法的产物, 其受控程度较低, 层级结构未被清晰揭示, 致使用户利用标签标记资源时会出现异词同义、一词多义、上下文语境识别困难等诸多自然语言处理问题.这些问题对社会化标签的组织、分析和应用产生了极大影响.因此, 计算机和图书情报等领域的学者类比半结构化文本处理方式, 围绕社会化标签开展了标签清洗去重[9 ] 、可信度评估[10 ] 、层级关系构建[11 ] 、聚类分类[12 ,13 ] 等一系列研究工作, 从而为基于社会化标签的应用研究提供有力支撑. ...
新浪微博用户领域分类标签的结构和互动研究
1
2014
... 此外, 针对社会化标签(Social Tag)的相关理论、技术、方法和模型也在不断发展和完善, 并逐渐服务于多种不同目的的社会化标注系统.在众多研究之中, 采用自然语言处理技术和信息组织与融合技术处理采集的原始标签是所有基于社会化标签研究的研究基础, 其根本原因在于: 社会化标签是大众分类法的产物, 其受控程度较低, 层级结构未被清晰揭示, 致使用户利用标签标记资源时会出现异词同义、一词多义、上下文语境识别困难等诸多自然语言处理问题.这些问题对社会化标签的组织、分析和应用产生了极大影响.因此, 计算机和图书情报等领域的学者类比半结构化文本处理方式, 围绕社会化标签开展了标签清洗去重[9 ] 、可信度评估[10 ] 、层级关系构建[11 ] 、聚类分类[12 ,13 ] 等一系列研究工作, 从而为基于社会化标签的应用研究提供有力支撑. ...
一种子空间聚类算法在多标签文本分类中应用
1
2014
... 此外, 针对社会化标签(Social Tag)的相关理论、技术、方法和模型也在不断发展和完善, 并逐渐服务于多种不同目的的社会化标注系统.在众多研究之中, 采用自然语言处理技术和信息组织与融合技术处理采集的原始标签是所有基于社会化标签研究的研究基础, 其根本原因在于: 社会化标签是大众分类法的产物, 其受控程度较低, 层级结构未被清晰揭示, 致使用户利用标签标记资源时会出现异词同义、一词多义、上下文语境识别困难等诸多自然语言处理问题.这些问题对社会化标签的组织、分析和应用产生了极大影响.因此, 计算机和图书情报等领域的学者类比半结构化文本处理方式, 围绕社会化标签开展了标签清洗去重[9 ] 、可信度评估[10 ] 、层级关系构建[11 ] 、聚类分类[12 ,13 ] 等一系列研究工作, 从而为基于社会化标签的应用研究提供有力支撑. ...
一种子空间聚类算法在多标签文本分类中应用
1
2014
... 此外, 针对社会化标签(Social Tag)的相关理论、技术、方法和模型也在不断发展和完善, 并逐渐服务于多种不同目的的社会化标注系统.在众多研究之中, 采用自然语言处理技术和信息组织与融合技术处理采集的原始标签是所有基于社会化标签研究的研究基础, 其根本原因在于: 社会化标签是大众分类法的产物, 其受控程度较低, 层级结构未被清晰揭示, 致使用户利用标签标记资源时会出现异词同义、一词多义、上下文语境识别困难等诸多自然语言处理问题.这些问题对社会化标签的组织、分析和应用产生了极大影响.因此, 计算机和图书情报等领域的学者类比半结构化文本处理方式, 围绕社会化标签开展了标签清洗去重[9 ] 、可信度评估[10 ] 、层级关系构建[11 ] 、聚类分类[12 ,13 ] 等一系列研究工作, 从而为基于社会化标签的应用研究提供有力支撑. ...
1
2017
... 韩松涛等在《基于“学术单元”的知识组织新框架: 多维度标签构建研究》一书中提出的利用分面组配方法组织、管理社会化标签的思想.韩松涛等人依据现有的客观知识体系, 把社会化标注系统中的全部标签划分为若干个分面(本体、对象、方法等), 并进一步细分为多个亚面(第一本体、核心对象、研究方法等), 从而实现通过组配不同分面下的社会化标签来描述资源特征[14 ] .在这种具有“分面-亚面”的标签体系结构中, 用户仍然主导定义和选择具体标签.在保证社会化标签的动态性和鲜活性的同时, 整个标签集合具有较为严格和规范的体系结构, 不同粒度标签集合之间相互支持、相互补充, 最终提高了社会化标注系统对复杂资源的揭示和描述能力. ...
1
2017
... 韩松涛等在《基于“学术单元”的知识组织新框架: 多维度标签构建研究》一书中提出的利用分面组配方法组织、管理社会化标签的思想.韩松涛等人依据现有的客观知识体系, 把社会化标注系统中的全部标签划分为若干个分面(本体、对象、方法等), 并进一步细分为多个亚面(第一本体、核心对象、研究方法等), 从而实现通过组配不同分面下的社会化标签来描述资源特征[14 ] .在这种具有“分面-亚面”的标签体系结构中, 用户仍然主导定义和选择具体标签.在保证社会化标签的动态性和鲜活性的同时, 整个标签集合具有较为严格和规范的体系结构, 不同粒度标签集合之间相互支持、相互补充, 最终提高了社会化标注系统对复杂资源的揭示和描述能力. ...
基于凝聚式层次聚类算法的标签聚类研究
1
2008
... 标签相似度计算与文本相似度计算之间存在很大差别.文本中含有大量的语义信息, 可以直接对分词后的两个文本进行余弦相似度计算.而标签大多是少数几个词或短语, 含有的语义信息量很小, 难以利用这种方法获得精确的标签相似度计算结果.现有研究中已有学者利用传统TF-IDF算法对标签进行特征抽取, 以此为基础实现标签间的相似度计算, 并取得了较为精确的标签聚类效果[15 ,16 ] .本文借鉴这一方法计算标签(或标签集合)之间的相关程度, 从而为生成具有层次结构的城市画像描述框架做数据准备, 其具体步骤如下: ...
基于凝聚式层次聚类算法的标签聚类研究
1
2008
... 标签相似度计算与文本相似度计算之间存在很大差别.文本中含有大量的语义信息, 可以直接对分词后的两个文本进行余弦相似度计算.而标签大多是少数几个词或短语, 含有的语义信息量很小, 难以利用这种方法获得精确的标签相似度计算结果.现有研究中已有学者利用传统TF-IDF算法对标签进行特征抽取, 以此为基础实现标签间的相似度计算, 并取得了较为精确的标签聚类效果[15 ,16 ] .本文借鉴这一方法计算标签(或标签集合)之间的相关程度, 从而为生成具有层次结构的城市画像描述框架做数据准备, 其具体步骤如下: ...
面向Web3.0的大众分类研究
1
2011
... 标签相似度计算与文本相似度计算之间存在很大差别.文本中含有大量的语义信息, 可以直接对分词后的两个文本进行余弦相似度计算.而标签大多是少数几个词或短语, 含有的语义信息量很小, 难以利用这种方法获得精确的标签相似度计算结果.现有研究中已有学者利用传统TF-IDF算法对标签进行特征抽取, 以此为基础实现标签间的相似度计算, 并取得了较为精确的标签聚类效果[15 ,16 ] .本文借鉴这一方法计算标签(或标签集合)之间的相关程度, 从而为生成具有层次结构的城市画像描述框架做数据准备, 其具体步骤如下: ...
面向Web3.0的大众分类研究
1
2011
... 标签相似度计算与文本相似度计算之间存在很大差别.文本中含有大量的语义信息, 可以直接对分词后的两个文本进行余弦相似度计算.而标签大多是少数几个词或短语, 含有的语义信息量很小, 难以利用这种方法获得精确的标签相似度计算结果.现有研究中已有学者利用传统TF-IDF算法对标签进行特征抽取, 以此为基础实现标签间的相似度计算, 并取得了较为精确的标签聚类效果[15 ,16 ] .本文借鉴这一方法计算标签(或标签集合)之间的相关程度, 从而为生成具有层次结构的城市画像描述框架做数据准备, 其具体步骤如下: ...
基于潜在语义分析的社会化标注系统标签语义检索研究
1
2011
... 本文利用传统资源模型将城市和标签组成城市-标签矩阵${{A}_{ij}}$, 并以此描述不同城市拥有的城市画像.其中, i 表示社会化标签, j 表示城市, aij 表示社会化标签i 对城市j 的标注次数.然而, 传统资源模型生成的城市-标签矩阵${{A}_{ij}}$仅仅依据标签的标记频次衡量标签对城市的重要程度, 忽略了不同标签分辨城市的能力以及标签确定城市特征语义的能力.有学者发现利用潜在语义分析方法(LSA)不仅能够反映标签在标签集合中的分布情况, 还可以通过加权变换挖掘标签间的潜在语义关系及其语义结构[17 ,18 ] .权重较大的标签间隐含的语义关系, 以及能够为标签提供更多信息量的资源中包含的标签间的语义关系, 更容易被LSA认为是重要的语义关系因而保留.基于以上分析, 借鉴基于LSA的标签潜在语义挖掘思想, 定义标签-城市矩阵${{A}_{ij}}$的权重值$W(i,j)$由标签局部权重${{P}_{w}}(i,j)$、标签全局权重${{T}_{w}}(i)$和资源全局权重${{R}_{w}}(j)$三个部分构成, 并给出对应权重的量化函数及其推导过程, 如公式(3)-公式(8)所示. ...
基于潜在语义分析的社会化标注系统标签语义检索研究
1
2011
... 本文利用传统资源模型将城市和标签组成城市-标签矩阵${{A}_{ij}}$, 并以此描述不同城市拥有的城市画像.其中, i 表示社会化标签, j 表示城市, aij 表示社会化标签i 对城市j 的标注次数.然而, 传统资源模型生成的城市-标签矩阵${{A}_{ij}}$仅仅依据标签的标记频次衡量标签对城市的重要程度, 忽略了不同标签分辨城市的能力以及标签确定城市特征语义的能力.有学者发现利用潜在语义分析方法(LSA)不仅能够反映标签在标签集合中的分布情况, 还可以通过加权变换挖掘标签间的潜在语义关系及其语义结构[17 ,18 ] .权重较大的标签间隐含的语义关系, 以及能够为标签提供更多信息量的资源中包含的标签间的语义关系, 更容易被LSA认为是重要的语义关系因而保留.基于以上分析, 借鉴基于LSA的标签潜在语义挖掘思想, 定义标签-城市矩阵${{A}_{ij}}$的权重值$W(i,j)$由标签局部权重${{P}_{w}}(i,j)$、标签全局权重${{T}_{w}}(i)$和资源全局权重${{R}_{w}}(j)$三个部分构成, 并给出对应权重的量化函数及其推导过程, 如公式(3)-公式(8)所示. ...
1
2013
... 本文利用传统资源模型将城市和标签组成城市-标签矩阵${{A}_{ij}}$, 并以此描述不同城市拥有的城市画像.其中, i 表示社会化标签, j 表示城市, aij 表示社会化标签i 对城市j 的标注次数.然而, 传统资源模型生成的城市-标签矩阵${{A}_{ij}}$仅仅依据标签的标记频次衡量标签对城市的重要程度, 忽略了不同标签分辨城市的能力以及标签确定城市特征语义的能力.有学者发现利用潜在语义分析方法(LSA)不仅能够反映标签在标签集合中的分布情况, 还可以通过加权变换挖掘标签间的潜在语义关系及其语义结构[17 ,18 ] .权重较大的标签间隐含的语义关系, 以及能够为标签提供更多信息量的资源中包含的标签间的语义关系, 更容易被LSA认为是重要的语义关系因而保留.基于以上分析, 借鉴基于LSA的标签潜在语义挖掘思想, 定义标签-城市矩阵${{A}_{ij}}$的权重值$W(i,j)$由标签局部权重${{P}_{w}}(i,j)$、标签全局权重${{T}_{w}}(i)$和资源全局权重${{R}_{w}}(j)$三个部分构成, 并给出对应权重的量化函数及其推导过程, 如公式(3)-公式(8)所示. ...
1
2013
... 本文利用传统资源模型将城市和标签组成城市-标签矩阵${{A}_{ij}}$, 并以此描述不同城市拥有的城市画像.其中, i 表示社会化标签, j 表示城市, aij 表示社会化标签i 对城市j 的标注次数.然而, 传统资源模型生成的城市-标签矩阵${{A}_{ij}}$仅仅依据标签的标记频次衡量标签对城市的重要程度, 忽略了不同标签分辨城市的能力以及标签确定城市特征语义的能力.有学者发现利用潜在语义分析方法(LSA)不仅能够反映标签在标签集合中的分布情况, 还可以通过加权变换挖掘标签间的潜在语义关系及其语义结构[17 ,18 ] .权重较大的标签间隐含的语义关系, 以及能够为标签提供更多信息量的资源中包含的标签间的语义关系, 更容易被LSA认为是重要的语义关系因而保留.基于以上分析, 借鉴基于LSA的标签潜在语义挖掘思想, 定义标签-城市矩阵${{A}_{ij}}$的权重值$W(i,j)$由标签局部权重${{P}_{w}}(i,j)$、标签全局权重${{T}_{w}}(i)$和资源全局权重${{R}_{w}}(j)$三个部分构成, 并给出对应权重的量化函数及其推导过程, 如公式(3)-公式(8)所示. ...
A Mathematical Theory of Communication
1
1948
... 标签全局权重${{T}_{w}}(i)$的含义和条件熵的定义相同, 其原因在于局部权重$P(i,j)$不能衡量不同标签区别不同城市的能力.本文借鉴条件熵定义[19 ] 标签全局权重${{T}_{w}}(i)$, 将城市集合看作符合某种概率分布的信息源, 将城市和标签看作两个随机变量, 依靠城市集合的信息熵和标签的条件熵之间信息量的增益关系确定社会化标签描述某座城市的重要程度.由此, 在某个标签确定的情况下其对应城市的条件熵计算方法如公式(5)所示. ...
A Method for Disambiguating Word Senses in a Large Corpus
1
1992
... 资源全局权重${{R}_{w}}(j)$用来解释标签的语义歧义性问题, 其原理来自Gale等人为度量随机事件相关性而提出的信息熵的引申概念“互信息”[20 ] .利用“互信息”可以揭示不同城市对每个标签提供的信息量, 以此找出与每个标签语义相近的其他标签.依据“互信息”的性质, 本文定义资源全局权重${{R}_{w}}(j)$的计算方法如公式(7)所示. ...







{kind=link}
{kind=link}
{kind=link}
{kind=link}