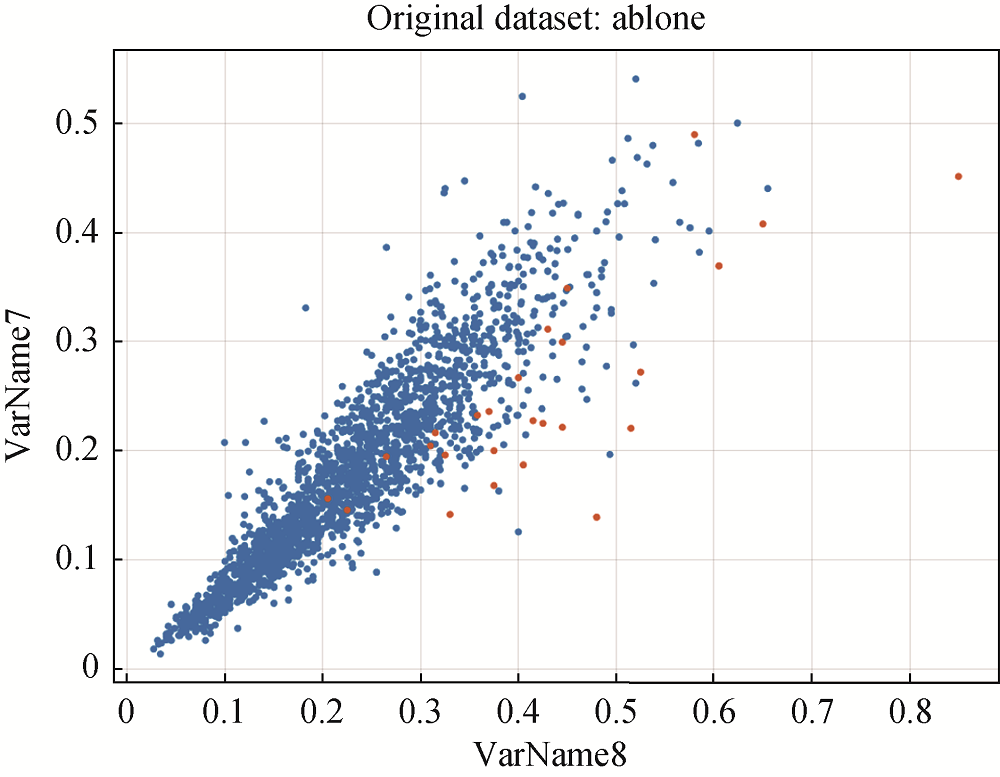
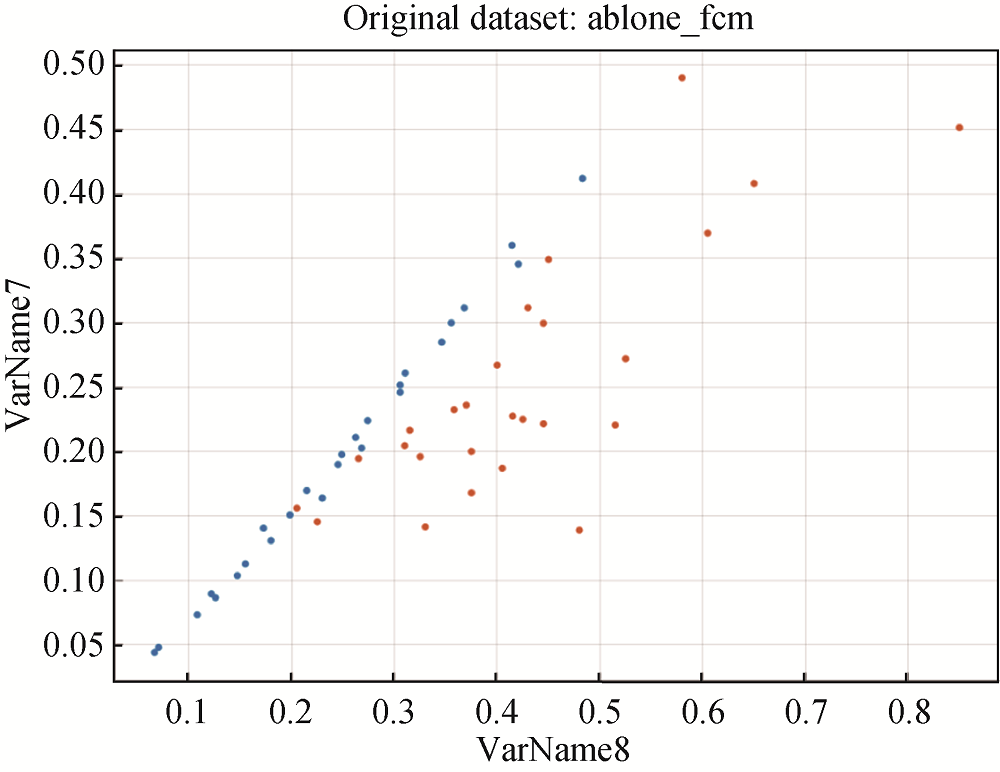
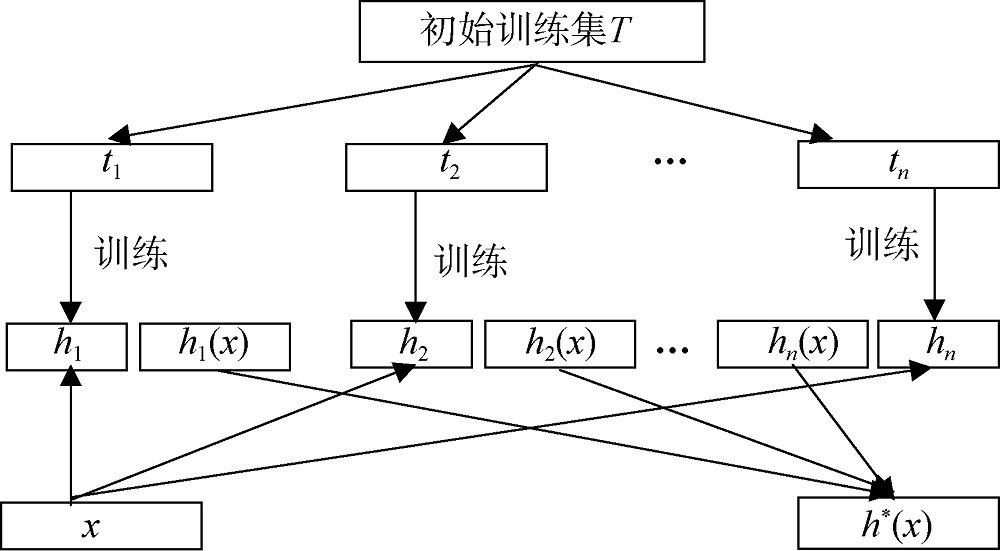
[Objective] This paper tries to solve the problem of the low accuracy of minority classification in the binary classification task due to class imbalance. [Methods] An under-sampling ensemble classification algorithm based on fuzzy c-means(FCM) clustering for imbalanced data is proposed. That is, the majority class samples are under-sampled based on FCM clustering, all these cluster center samples and all the minority samples are made up to a balance data set. We use the integrated learning algorithm based on Bagging to classify the balanced data sets. [Results] The Matlab simulation results of experiments on four imbalanced datasets show that the ECFCM algorithm improves Acc, AUC and F1 by up to 5.75%, 13.84% and 7.54%. [Limitations] Some standard data sets are used to verify the effectiveness of ECFCM. When in a specific application, a targeted research on classification algorithm is needed. [Conclusions] The ECFCM algorithm performs good to a certain extent, which is conducive to improve the binary classification accuracy of the minority class on imbalanced datasets.
本文将基于模糊C-均值聚类的欠采样方法与集成学习算法进行融合, 提出基于模糊C-均值聚类的欠采样集成不平衡数据分类算法(under-sampling Ensemble Classification algorithm based on Fuzzy C-Means clustering for imbalanced data, ECFCM), 以提高不平衡数据中少数类的分类准确度。
2.2 模糊C-均值聚类算法
FCM算法起源于“硬”聚类目标函数的优化过程。借助于均方逼近理论, 人们构造出带约束条件的非线性目标规划函数, 从而将聚类问题转化为非线性目标规划问题进行求解。因此, 类内平方误差和(Within-Groups Sum of Squared error, WGSS) J1通常被当做聚类目标函数使用。以后的研究中, Dunn[15]将WGSS函数J1扩展到J2, 即类内加权平方误差和函数。Bezdek等[16]引入新的参数m, 将J2推广到一个目标函数的无限簇, 形成目前所熟知的FCM算法。
YangX, LoD, HuangQ, et al.Automated Identification of High Impact Bug Reports Leveraging Imbalanced Learning Strategies[C]//Proceedings of the 40th IEEE Annual Computer Software and Applications Conference, Atlanta, Georgia,USA. IEEE Press, 2016: 227-232.
[本文引用:1]
[3]
ZakaryazadA, DumanE.A Profit-driven Artificial Neural Network (ANN) with Applications to Fraud Detection and Direct Marketing[J]. Neurocomputing, 2016, 175: 121-131.
The rapid growth in data capture and computational power has led to an increasing focus on data-driven research. So far, most of the research is focused on predictive modeling using statistical optimization, while profit maximization has been given less priority. It is exactly this gap that will be addressed in this study by taking a profit-driven approach to develop a profit-driven Artificial Neural Network (ANN) classification technique. In order to do this, we have first introduced an ANN model with a new penalty function which gives variable penalties to the misclassification of instances considering their individual importance (profit of correctly classification and/or cost of misclassification) and then we have considered maximizing the total net profit. In order to generate individual penalties, we have modified the sum of squared errors (SSE) function by changing its values with respect to profit of each instance. We have implemented different versions of ANN of which five of them are new ones contributed in this study and two benchmarks from relevant literature. We appraise the effectiveness of the proposed models on two real-life data sets from fraud detection and a University of California Irvine (UCI) repository data set about bank direct marketing. For the comparison, we have considered both statistical and profit-driven performance metrics. Empirical results revealed that, although in most cases the statistical performance of new models are not better than previous ones, they turn out to be better when profit is the concern.
Prusa JD, Khoshgoftaar TM, SeliyaN.Enhancing Ensemble Learners with Data Sampling on High-Dimensional Imbalanced Tweet Sentiment Data[C]//Proceedings of the 29th International Florida Artificial Intelligence Research Society Conference(FLAIRS2016), Florida, USA. AAAI Press, 2016: 322-328.
(FangLei, MaXijun.An Applied Research on Improved Entropy-based SVM Churn Prediction Model[J]. Journal of the China Society for Scientific and Technical Information, 2011, 30(6): 643-648.)
[6]
GalarM, FernandezA, BarrenecheaE, et al.A Review on Ensembles for the Class Imbalance Problem: Bagging-, Boosting-, and Hybrid-Based Approaches[J]. IEEE Transactions on Systems, Man & Cybernetics, Part C:Applications & Reviews, 2012, 42(4): 463-484.
Classifier learning with data-sets that suffer from imbalanced class distributions is a challenging problem in data mining community. This issue occurs when the number of examples that represent one class is much lower than the ones of the other classes. Its presence in many real-world applications has brought along a growth of attention from researchers. In machine learning, the ensemble of classifiers are known to increase the accuracy of single classifiers by combining several of them, but neither of these learning techniques alone solve the class imbalance problem, to deal with this issue the ensemble learning algorithms have to be designed specifically. In this paper, our aim is to review the state of the art on ensemble techniques in the framework of imbalanced data-sets, with focus on two-class problems. We propose a taxonomy for ensemble-based methods to address the class imbalance where each proposal can be categorized depending on the inner ensemble methodology in which it is based. In addition, we develop a thorough empirical comparison by the consideration of the most significant published approaches, within the families of the taxonomy proposed, to show whether any of them makes a difference. This comparison has shown the good behavior of the simplest approaches which combine random undersampling techniques with bagging or boosting ensembles. In addition, the positive synergy between sampling techniques and bagging has stood out. Furthermore, our results show empirically that ensemble-based algorithms are worthwhile since they outperform the mere use of preprocessing techniques before learning the classifier, therefore justifying the increase of complexity by means of a significant enhancement of the results.
LiuG, YangY, LiB.Fuzzy Rule-based Oversampling Technique for Imbalanced and Incomplete Data Learning[J]. Knowledge-Based Systems, 2018, 158: 154-174.
Datasets that have skewed class distributions pose a difficulty to learning algorithms in pattern classification. A number of different methods to deal with this problem have been developed in recent years. Specifically, synthetic oversampling techniques focus on balancing the distribution between the training instances of the majority and minority classes by generating extra artificial minority class instances. Unfortunately, few of them can be spread to tackle the problem of imbalanced data with missing values. Moreover, in most cases, existing oversampling methods do not make full use of the correlation between attributes. To this end, in this paper, we propose a fuzzy rule-based oversampling technique (FRO) to handle the class imbalance problem. FRO firstly creates fuzzy rules from the training data and assigns each of them a rule weight, which represents the certainty degree of an instance belonging to the fuzzy subspace. Then it synthesizes new minority instances under the guidance of fuzzy rules. The number of minority instances to be generated under a given fuzzy rule is determined by the rule weight. In a similar way, FRO can also recover the missing values that exist in the imbalanced dataset. Extensive experiments using 55 real-world imbalanced datasets evaluate the performance of the proposed FRO technique. The results show that our method is better than or comparable with a set of alternative state-of-the-art imbalanced classification algorithms in terms of various assessment metrics.
Lin WC, Tsai CF, Hu YH, et al. Clustering-based Undersampling in Class-imbalanced Data[J]. Information Sciences, 2017, 409-410: 17-26.
Class imbalance is often a problem in various real-world data sets, where one class (i.e. the minority class) contains a small number of data points and the other (i.e. the majority class) contains a large number of data points. It is notably difficult to develop an effective model using current data mining and machine learning algorithms without considering data preprocessing to balance the imbalanced data sets. Random undersampling and oversampling have been used in numerous studies to ensure that the different classes contain the same number of data points. A classifier ensemble (i.e. a structure containing several classifiers) can be trained on several different balanced data sets for later classification purposes. In this paper, we introduce two undersampling strategies in which a clustering technique is used during the data preprocessing step. Specifically, the number of clusters in the majority class is set to be equal to the number of data points in the minority class. The first strategy uses the cluster centers to represent the majority class, whereas the second strategy uses the nearest neighbors of the cluster centers. A further study was conducted to examine the effect on performance of the addition or deletion of 5 to 10 cluster centers in the majority class. The experimental results obtained using 44 small-scale and 2 large-scale data sets revealed that the clustering-based undersampling approach with the second strategy outperformed five state-of-the-art approaches. Specifically, this approach combined with a single multilayer perceptron classifier and C4.5 decision tree classifier ensembles delivered optimal performance over both small- and large-scale data sets.
BłaszczyńskiJ, StefanowskiJ.Neighbourhood Sampling in Bagging for Imbalanced Data[J]. Neurocomputing, 2015, 150: 529-542.
Various approaches to extend bagging ensembles for class imbalanced data are considered. First, we review known extensions and compare them in a comprehensive experimental study. The results show that integrating bagging with under-sampling is more powerful than over-sampling. They also allow to distinguish Roughly Balanced Bagging as the most accurate extension. Then, we point out that complex and difficult distribution of the minority class can be handled by analyzing the content of a neighbourhood of examples. In our study we show that taking into account such local characteristics of the minority class distribution can be useful both for analyzing performance of ensembles with respect to data difficulty factors and for proposing new generalizations of bagging. We demonstrate it by proposing Neighbourhood Balanced Bagging, where sampling probabilities of examples are modified according to the class distribution in their neighbourhood. Two of its versions are considered: the first one keeping a larger size of bootstrap samples by hybrid over-sampling and the other reducing this size with stronger under-sampling. Experiments prove that the first version is significantly better than existing over-sampling bagging extensions while the other version is competitive to Roughly Balanced Bagging. Finally, we demonstrate that detecting types of minority examples depending on their neighbourhood may help explain why some ensembles work better for imbalanced data than others.
Batista G EA P A, Prati RC, Monard MC. A Study of the Behavior of Several Methods for Balancing Machine Learning Training Data[J]. ACM SIGKDD Explorations Newsletter, 2004, 6(1): 20-29.
ZhangJ, ManiI. kNN Approach to Unbalanced Data Distributions: A Case Study Involving Information Extraction [C]// Proceedings of the ICML2003 Workshop on Learning from Imbalanced Datasets, Washington, DC, USA. AAAI Press, 2003: 42-48.
[本文引用:1]
[12]
CateniS, CollaV, VannucciM.A Method for Resampling Imbalanced Datasets in Binary Classification Tasks for Real-World Problems[J]. Neurocomputing, 2014, 135: 32-41.
The paper presents a novel resampling method for binary classification problems on imbalanced datasets. Imbalanced datasets are frequently found in many industrial applications: for instance, the occurrence of particular product defects, the diagnosis of severe diseases in a series of patients or machine faults are rare events whose detection is of utmost importance. In this paper a new resampling method is proposed combining an oversampling and an undersampling technique. Several tests have been developed aiming at assessing the efficiency of the proposed method. Four classifiers based, respectively, on Support Vector Machine, Decision Tree, labelled Self-Organizing Map and Bayesian Classifiers have been developed and applied for binary classification on the following four datasets: a synthetic dataset, a widely used public dataset and two datasets coming from industrial applications. The results that have been obtained in the tests are presented and discussed in the paper; in particular, the performances that are achieved by the four classifiers through the proposed novel resampling approach have been compared to the ones that are obtained, without any resampling, through a widely applied and well known resampling technique, i.e. the classical SMOTE approach, and through another approach coupling informed SMOTE-based oversampling and informed clustering-based undersampling.
HaJ, Lee JS.A New Under-Sampling Method Using Genetic Algorithm for Imbalanced Data Classification [C] //Proceedings of the 10th International Conference on Ubiquitous Information Management and Communication, Danang, Vietnam. ACM Press,2016: Article No.95.
[本文引用:1]
[14]
KocyigitY, SekerH.Imbalanced Data Classifier by Using Ensemble Fuzzy C-Means Clustering[C]// Proceedings of the IEEE-EMBS International Conference on Biomedical and Health Informatics (BHI 2012), Hong Kong, China. IEEE Press, 2012: 952-955.
[本文引用:1]
[15]
Dunn JC.A Fuzzy Relative of the ISODATA Process and Its Use in Detecting Compact Well-separated Clusters[J]. Journal of Cybernetics, 1973, 3(3): 32-57.
Two fuzzy versions of the k-means optimal, least squared error partitioning problem are formulated for finite subsets X of a general inner product space. In both cases, the extremizing solutions are shown to be fixed points of a certain operator T on the class of fuzzy, k-partitions of X, and simple iteration of T provides an algorithm which has the descent property relative to the least squared error criterion function. In the first case, the range of T consists largely of ordinary (i.e. non-fuzzy) partitions of X and the associated iteration scheme is essentially the well known ISODATA process of Ball and Hall. However, in the second case, the range of T consists mainly of fuzzy partitions and the associated algorithm is new; when X consists of k compact well separated (CWS) clusters, Xi, this algorithm generates a limiting partition with membership functions which closely approximate the characteristic functions of the clusters Xi. However, when X is not the union of k CWS clusters, the limiting partition is truly fuzzy in the sense that the values of its component membership functions differ substantially from 0 or 1 over certain regions of X. Thus, unlike ISODATA, the 090008fuzzy090009 algorithm signals the presence or absence of CWS clusters in X. Furthermore, the fuzzy algorithm seems significantly less prone to the 090008cluster-splitting090009 tendency of ISODATA and may also be less easily diverted to uninteresting locally optimal partitions. Finally, for data sets X consisting of dense CWS clusters embedded in a diffuse background of strays, the structure of X is accurately reflected in the limiting partition generated by the fuzzy algorithm. Mathematical arguments and numerical results are offered in support of the foregoing assertions.
This paper transmits a FORTRAN-IV coding of the fuzzy c-means (FCM) clustering program. The FCM program is applicable to a wide variety of geostatistical data analysis problems. This program generates fuzzy partitions and prototypes for any set of numerical data. These partitions are useful for corroborating known substructures or suggesting substructure in unexplored data. The clustering criterion used to aggregate subsets is a generalized least-squares objective function. Features of this program include a choice of three norms (Euclidean, Diagonal, or Mahalonobis), an adjustable weighting factor that essentially controls sensitivity to noise, acceptance of variable numbers of clusters, and outputs that include several measures of cluster validity.
(ZhangXiang, ZhouMingquan, GengGuohua, et al.Application of Bagging Algorithm to Chinese Text Categorization[J]. Computer Engineering and Applications, 2009, 45(5): 135-137, 179.)

 , 郜梦蕊, 苏新宁
, 郜梦蕊, 苏新宁



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}