




1 引 言
随着互联网技术的快速发展,涌现出大量的商品评论、用户投诉等短文本形式的用户信息。海量的短文本纷繁复杂,蕴含着极大价值,短文本自动归类可以使企业更好地挖掘短文本的深层价值。以用户投诉文本为例,用户投诉本质是企业无法满足用户需求现象,如何处理用户投诉信息,挖掘投诉文本内在价值,对企业调整运营策略以减少客户流失、提升客户满意度有着重要导向作用[1]。
短文本分类是文本分类领域的重要研究方向,由于短文本内容较短、多为口语化形式,传统的文本分类方法难以有效提取短文本特征,故短文本分类大多是人工处理。企业对此投入大量时间和精力,但由于人工分类的标准无法统一且分类人员的能力参差不一,故分类效果不令人满意。本文研究解决短文本内容简短而引起的数据稀疏问题,提高短文本的分类效果。
随着自然语言处理技术的飞速发展,大量应用于文本分类的模型方法相继产生。目前主流的文本分类方法大多是将文本进行向量化,提取出文本特征,选择合适的分类器训练模型,训练好的模型用于预测未知文本的类别。现有的文本向量化模型主要有TF-IDF、LDA[2]、Doc2Vec等。常用的分类算法主要包括:朴素贝叶斯模型、决策树分类法、K-最近邻法(K-Nearest Neighbor, KNN)、支持向量机(Support Vector Machine, SVM),还有Boosting、Bagging、随机森林(Random Forest,RF)等集成学习方法。这些方法的产生为短文本分类方法提供了良好的理论和技术支持,有助于对短文本特征及分类方法进行深入研究,进一步提高短文本分类的准确性和效率。
2 相关研究
2.1 短文本建模
短文本分类首先通过短文本建模提取短文本特征,选择合适的数据特征可以提升模型的性能,对短文本分类效果影响巨大。周源等[3]利用PageRank模型计算特征词的PR值,融合TF-IDF模型,提取出融合PR值、TF值和IDF值的特征,用于文本特征提取。马建红等[4]使用改进的TF-IDF对Word2Vec词向量进行加权,用于专利短文本表示。在短文本向量化表示时,为解决短文本稀疏性问题,李湘东等[5]采用语料库扩展短文本特征,通过改进TF-IDF获得候选词集,基于维基百科对文档特征进行扩展,为分类算法提供良好的文本特征。岳文应[6]使用Doc2Vec模型获取聊天短文本的特征向量,用于SVM聊天内容分类的输入,得到了较高准确率。
传统的短文本建模方式在处理文本时,特征维度受到文本集规模影响,文本集规模过大,所构建的短文本特征维度也随之增大。LDA是一种非监督学习方法,由于同时具有可解释性和降维特性,因而广泛应用于文本的特征抽取。LDA是典型的词袋模型,包含文本、主题、词三层结构,可以挖掘出文本隐含的主题信息。胡勇军等[7]使用LDA主题模型对原始短文本向量进行特征扩展,解决短文本特征稀疏问题。Burkhardt等[8]在LDA模型文档、主题、词三层结构基础上增加了标签层,通过标签主题分布学习标签依赖性,用于多标签分类。Zhang等[9]利用隐藏的主题丰富语料库和短文本,进而获得单词和主题向量表示文本特征。LDA模型很好地挖掘了文本潜在语义信息,但在文本建模时忽略词语间的顺序信息[10]。
主题模型不仅能使数据有效降维,还可以解决“一词多义”和“一义多词”问题,但由于LDA是词袋模型,忽略了词语顺序关系,故不能获得文本的上下文语境特征。Doc2Vec通过三层神经网络实现文本建模,不仅可以获取文本语义信息,而且更关注文本中的上下文逻辑信息,故本文将主题向量和Doc2Vec向量融合,得到的特征向量所表达的语义信息更加丰富。
2.2 文本分类算法
文本分类算法本质是根据给定文档集的数据特征,将其划分到正确的类别集中[11]。短文本建模可以表示出隐含在短文本内的特征,将文本转化为特征向量,而分类算法可以更好地区分短文本之间的特征,进而提升短文本的分类效果。
随着短文本分类的深入研究与机器学习的飞速发展,越来越多的学者将机器学习应用到短文本分类中。樊兴华等[12]将朴素贝叶斯与KNN模型融合,提出两步策略的中文短文本分类方法。孙建旺等[13]通过计算短文本语义的最大匹配度得到短文本相似度,然后采用KNN对新浪、搜狐等网站的跟帖与评论进行分类。陈燕方[14]基于在线商品的多项指标,构造针对多分类问题的DDAG-SVM多分类器。张浩等[15]使用Sentence-LDA主题模型对短文本进行语义扩展,输入SVM模型进行分类。黄沛杰等[16]采用无标签的微博数据对OOD话语进行内容扩展,通过对比最大熵模型、CNN、RF的分类效果,发现RF具有更好的泛化性能。
在现有的短文本分类算法中,SVM、朴素贝叶斯、KNN、RF等机器学习方法应用较广,集成学习也取得了较好效果。施瑞朗[21]对比SVM、朴素贝叶斯、KNN、决策树在短文本分类上的表现,发现SVM准确率更高。SVM为使样本数据有效降维,通过寻找最优分割超平面实现样本划分,在小样本数据集上效果很好。RF为避免数据发生过拟合,通过集成具有不同特征的决策树提高分类准确率,拥有更强的泛化能力。故本文集成SVM和RF两种分类器,学习短文本数据集的多维特征,以改善模型的学习性能,提高短文本分类算法的准确性。
3 基于nLD-SVM-RF短文本分类
3.1 模型概述
基于上述分析,本文提出基于nLD-SVM-RF(n Latent Dirichlet Allocation and Doc2Vec-Support Vector Machines-Random Forests)多分类器集成的短文本分类方法,该方法使用多通道建模方法,分别抽取短文本的主题特征和语义、语序特征,采用拼接的方式进行向量融合,为提高分类效果,使用SVM和RF作为基分类器进行集成分类,采用投票决定最终分类结果。模型框架如图1所示。
图1
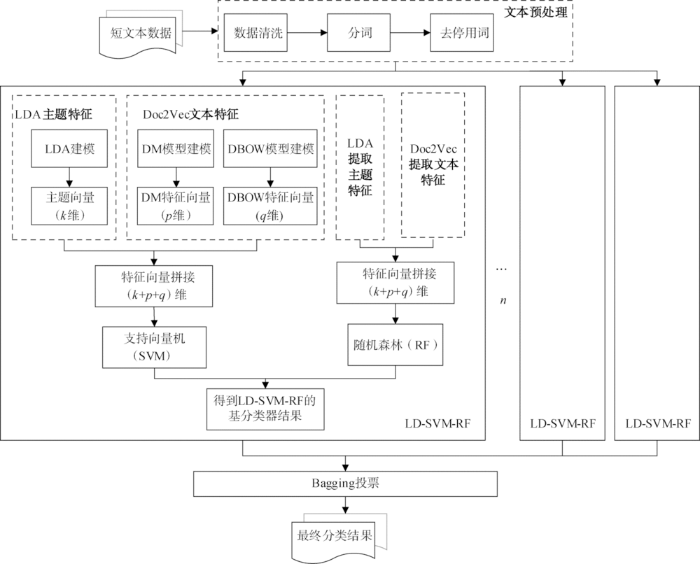
(1)对收集的短文本进行预处理,主要包括数据清洗、分词、去停用词、建立语料库;
(2)nLD-SVM-RF短文本的多通道建模,利用LDA主题模型对语料库建模获得短文本的k维主题向量特征,利用Doc2Vec提取短文本向量特征,利用DM模型对语料库建模获得p维特征,利用DBOW模型对语料库建模获得q维特征;
(3)构建短文本表示向量,将三种多通道模型提取的特征向量进行拼接,得到(k+p+q)维LD(Latent Dirichlet Allocation and Doc2Vec)多通道短文本特征,此特征向量能更好地反映短文本特征;
(4)重复步骤(2)-步骤(3),获得语料库的两组LD多通道短文本特征向量,分别输入到SVM和RF分类器中,得到LD-SVM-RF的基分类器结果;
(5)重复步骤(2)-(4),对n个LD-SVM-RF进行集成,采用Bagging方法投票得到最终分类结果。
3.2 多通道短文本特征建模
(1) 多通道短文本特征融合
图2
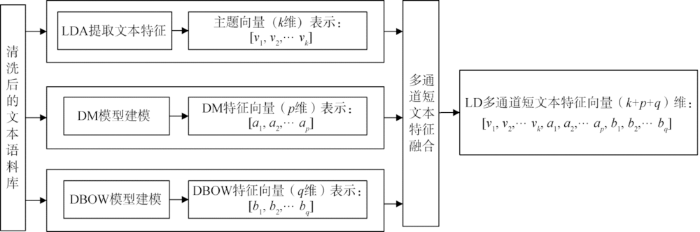
分别对清洗过的语料库,采用LDA、DM、DBOW三通道进行建模,三通道分别提取短文本不同特征向量,通过向量拼接方式实现短文本的特征融合,最终得到(k+p+q)维LD多通道短文本特征向量表示,作为分类器输入。该模型的文本建模方法融合了LDA主题模型和Doc2Vec模型的DBOW、DM模型短文本特征提取的优势,所获得的文本表示向量兼具主题特征、语义特征、上下文语境特征,可有效解决短文本数据稀疏、特征难以抽取问题。
(2) 短文本特征提取
① LDA主题特征提取
LDA是一个三层贝叶斯模型,包含文档、主题、词三层结构,认为每篇文档都是以一定概率选择某个主题,并从该主题下以一定概率选择某个词,文档到主题服从多项分布,主题到词服从多项分布。LDA通常采用Gibbs采样进行求解,具体步骤为:
1)对于给定文档中的词,随机赋值一个主题编号;
2)对于语料库的中每一个词,根据Gibbs采样公式更新主题编号;
3)重复步骤2),当Gibbs采样收敛后,即可得到所有词所属的主题;
4)统计语料库中每篇文档中词的所属主题,即可得到文档主题分布。
利用LDA主题建模得到文本的k维主题向量,可以有效获取文本的文档-主题概率分布信息,提取短文本的主题特征。
② Doc2Vec文本特征提取
图3

Doc2Vec关注词语位置信息,通过DM模型和DBOW模型可获得短文本的p维特征向量和q维特征向量,将DM特征向量和DBOW特征向量拼接,得到p+q维向量表示短文本特征,可以更好地挖掘短文本的上下文语义信息。
3.3 分类器选择与集成
特征提取后需要基于文本特征对文本划分类别,选择合适的分类器对分类结果影响巨大,集成学习组合多个分类器,具有更好的泛化性能。影响集成学习效果的两大因素是分类器的差异性与基分类器的精度,故选择分类器精度较高的两种分类算法(SVM和RF)做基分类器,并对两种分类算法进行集成。
(1) 支持向量机
假设对于样本集
该二次规划问题求解可用拉格朗日乘子法,每条约束添加拉格朗日乘子
对于线性不可分问题,需要将原始空间的样本映射到高维空间,在高维空间构造最优分离超平面,令
核函数将特征向量映射到高维空间中,使原本不可分数据变得线性可分。核函数的选择对SVM至关重要,常用的核函数主要有线性核、多项式核、高斯核、Sigmoid核。线性核函数是样本特征在原始空间的内积,适用于数据集在原始空间本身可分的情况,其参数少,且执行速度快,对于一般数据,能够得到较理想分类效果。为提高短文本分类的准确性和效率,选择线性核作为核函数。
SVM本身是一个二分类器,对于多分类问题可以转化为“一对多法”和“一对一法”。为更好地处理多分类问题,采用“一对一法”进行多分类。该方法的准确率较高,适用于类别较少的样本数据。“一对多法”在训练时将某类样本分为一类,其余分为另一类,需训练全部样本,训练速度较慢,且负样本过多,会出现样本不对称情况,分类效果不够理想。“一对一法”是对k类样本中任意两类样本构造一个SVM分类器,共设计k(k-1)/2个SVM,对一个未知分类样本,得票最多的类别为该样本类别。“一对一法”的每个分类器只需训练两类样本,故计算复杂度低、训练速度快,训练的分类器数量随着类别数量增加而增加,适用于k较小的情况。
(2) 随机森林
随机森林(RF)[27]是把多个决策树放在一起,形成一片森林,通过对决策树进行集成,进而将多个弱分类器组合为一个强分类器。随机森林解决了决策树泛化性能差的问题,准确率相较于决策树大大提升。
采用随机森林对短文本进行分类,随机森林利用Bootstrap从样本数据中随机且有放回地抽取多个样本集。根据短文本多维特征融合方法,获取样本集中每个短文本的k+p+q维特征。随机森林可以从样本的所有特征中随机选取多个特征,选择最佳分割特征作为节点建立CART决策树,构造多个决策树,多个决策树通过投票表决确定分类结果。随机森林中每棵树都是独立的,训练过程互不影响,通过合并多个决策树,可以获得更准确、更稳健的预测结果,且随机森林对于含有噪声的数据具有较好的降噪效果。
(3) 多分类器集成
在分类器选择方面,SVM是建立在结构风险最小化原理上,通过寻找最优超平面将样本划分,主要用于小样本预测,在分类问题上取得了很好的效果。随机森林可以处理高维度数据、有效评估各个特征对于分类问题的重要性,具有较高的准确率和较强的泛化能力。
一般来说,集成学习的基分类器越精确、差异越大,效果越好。为使短文本获得更好的分类效果,本文选择两种分类效果较好且具有较大差异的模型作为基分类器,分别是基于线性核函数的SVM分类器和RF分类器。将LDA、DM、DBOW三通道提取的短文本特征向量进行拼接后,得到(k+p+q)维的多特征融合向量。将融合向量输入SVM分类器,得到LD-SVM模型的分类结果,将融合向量输入RF分类器,得到LD-RF模型的分类结果。将LD-SVM与LD-RF两种分类结果融合,得到LD-SVM-RF的基分类器分类结果。最后,为提高算法准确性,采用Bagging方法对多个LD-SVM-RF集成,通过投票机制得到nLD-SVM-RF模型的最终分类结果。
4 实验设计与分析
4.1 实验数据及评价方法
本实验以电信投诉文本验证nLD-SVM-RF模型效果。企业对投诉文本的处理流程为:收集投诉信息、投诉文本分类、反馈给相关部门、部门处理。电信投诉文本包含大量对电信产品和服务的投诉信息,对此类短文本数据分类可以帮助企业发现产品问题、判断用户需求,进而帮助企业提升产品竞争力和用户服务满意度。
实验数据为8 409条电信投诉文本,问题可以分为以下4类:业务提供与运营管理、移动通信质量、业务宣传与市场推广、政策与业务规定制定。实验中将训练集和测试集按9∶1划分。其中,LDA模型中通过训练数据设置的主题参数k取50维,DM与DBOW模型中,p、q的取值借鉴文献[28],取300维。由于训练集大小限制,采取Bootstrap方法,每次随机从训练集中选取70%作为每个基分类器的训练数据,将数据分别进行多通道建模,提取短文本特征。训练数据共抽两次,一次用作LD-SVM的输入,一次用作LD-RF的输入,得到LD-SVM-RF的基分类器分类结果,最后将n个LD-SVM-RF结果采用Bagging方法投票选出最优分类结果。为减少实验环境的统计误差对分类结果的影响,每组实验重复5次,取均值作为分类结果。
使用准确率
4.2 实验结果与分析
(1) 不同文本特征对分类效果的影响
使用SVM和RF对比不同的文本表示模型(LDA、Doc2Vec、LD多通道短文本特征)获取文本向量的分类结果,其中,Doc2Vec文本特征采用DM模型与DBOW模型获得的特征向量拼接得到。结果如图4所示,仅使用Doc2Vec表示的效果虽然也比较好,但随着数据集的增加,Doc2Vec模型得到的特征向量维度要随之增加,LDA主题向量的维度却不受数据集影响,能有效防止文本特征维度过大。对于SVM分类器和RF分类器,仅使用LDA表示文本和仅使用Doc2Vec表示文本,准确率均没有LD多通道短文本特征向量的结果好。为验证LD多通道短文本特征的效果,在其他短文本分类数据集上进行对比实验,得到了较好的验证。
图4
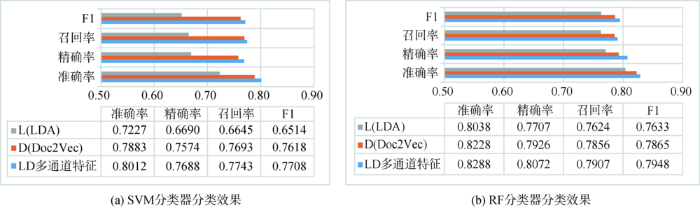
图4
LDA、Doc2Vec、LD多通道短文本特征的文本建模对比
Fig.4
Text Modeling Comparison of LDA, Doc2Vec, LD Multi-channel Short Text Features
(2) 对比不同的基分类器效果
对比KNN(LD-KNN)、决策树(LD-Decision Tree)、SVM(LD-SVM)、RF(LD-RF)、LD-SVM-RF的分类效果,如图5所示。RF和SVM单分类器可达到准确率0.80左右,分类效果明显强于其他分类器。为增大基分类器的差异性以获取更好的分类效果,选择LD-RF与LD-SVM两种基分类器用于集成分类。由LD-SVM-RF集成模型同其他单分类器对比可知,LD-SVM-RF模型具有较高准确率。使用两种分类器集成,可以增大基分类器的差异性,便于后期集成获得更好的分类效果。
图5
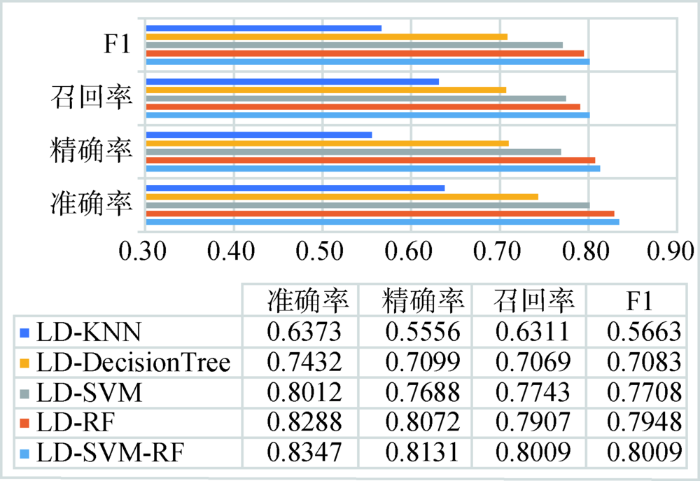
图5
LD-KNN、LD-DecisionTree、LD-SVM、LD-RF、LD-SVM-RF分类效果对比
Fig.5
Comparison of LD-KNN, LD-DecisionTree, LD-SVM, LD-RF, LD-SVM-RF Classification Effects
(3) n取值对分类效果的影响
对比分类器集成时,n的取值对集成效果的影响,结果如图6所示。随着n值逐渐增大,准确率、精确率、召回率、F1均是增大趋势。当n≥5时,分类效果提升缓慢,这是因为,集成学习在理论上是基分类器越多越好,但实际情况中,当分类器到达一定数量,再增加基分类器的数量,效果很难再提升,且训练时间将大大增大。故n=5时,该模型对投诉短文本分类效率最高。
图6

图6
n=1、3、5、7、9分类效果对比
Fig.6
Comparison of Classification Effects of n = 1, 3, 5, 7, 9
综上所述,不同的文本表示模型(LDA、Doc2Vec、LD多通道短文本特征)对分类效果有较大影响,融合主题向量与Doc2Vec文本向量的LD多通道文本特征提取方法比单独使用主题向量、单独使用Doc2Vec向量的表示方法,分类效果有一定改善;在采用LD多通道短文本特征作为文本向量表示时,对于不同的单分类器,SVM和RF是表现效果比较好的两种分类方法,LD-SVM准确率可达0.8012,LD-RF可达0.8288,LD-SVM-RF集成两种方法,增大基分类器的差异性;最后,在nLD-SVM-RF算法中,随着n值的逐渐增大,效果逐渐增强,但当n≥5时,分类效果的提升不再明显,且训练时间大大增加。故集成学习对分类效果的提升起着重大作用,可以在一定范围内增加分类器集成的数量。
5 结 语
本文提出nLD-SVM-RF算法,采用多通道的方式对短文本进行建模,分别提取短文本的主题特征和语义、语序特征,并对特征进行融合,可以解决短文本特征稀疏的特点,使得文本特征表征更加充分。通过将SVM和RF分类器作为基分类器组合,得到多组分类结果,对多个结果采取投票形式得到最终结果。该方法不仅可以兼顾SVM用于小样本的降维特性,还兼顾了RF准确性高、泛化能力强等特点。通过对电信投诉文本的大量实验分析,验证了nLD-SVM-RF算法具有较好的分类效果,为企业快速解决短文本分类问题、挖掘用户信息的潜在价值提供了依据。
但是本文仍存在一些不足之处,例如,文本数据量过小,没有对大样本数据进行验证。如何使文本特征更丰富,还有待研究。此外,该方法将来可用于其他领域的短文本分类问题,提高应用价值。
作者贡献声明
余本功:提出研究思路,设计修改研究方法;
曹雨蒙:进行实验,分析数据,起草及修改论文;
陈杨楠:设计研究方案,调整文章结构;
杨颖:分析数据,设计研究方案。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据
支撑数据由作者自存储,E-mail:caoyumeng1029@163.com。
[1] 曹雨蒙.投诉数据.xlsx.实验使用的投诉文本数据.
[2] 曹雨蒙.自定义用户词典.txt.实验的自定义词典.
[3] 曹雨蒙.敏感词与停用词表.txt.实验使用的敏感词与停用词表.
[4] 曹雨蒙.result.xlsx.可视化结果.
参考文献
电信业投诉分类方法及其应用研究
[J].
Text Categorization of Complain in Telecommunication Industry and Its Applied Research
[J].
Latent Dirichlet Allocation
[J].
基于改进TF-IDF特征提取的文本分类模型研究
[J].
Research of Text Classification Model Based on the Improved TF-IDF Feature Extraction
[J].
面向短文本的特征选择及文本表示
[J].
Text Feature Selection and Text Representation for Short Essays
[J].
基于维基百科的多种类型文献自动分类研究
[J].
Automatic Classification of Documents from Wikipedia
[J].
基于Doc2Vec与SVM的聊天内容过滤
[J].
Chat Content Filtering Based on Doc2Vec and SVM
[J].
基于LDA高频词扩展的中文短文本分类
[J].
A New Method of Keywords Extraction for Chinese Short-text Classification
[J].
Online Multi-Label Dependency Topic Models for Text Classification
[J].
Improving Short Text Classification by Learning Vector Representations of Both Words and Hidden Topics
[J].
Probabilistic Topic Models
[C]//
基于朴素贝叶斯的文本分类研究综述
[J].
Text Classification Based on Naive Bayes:A Review
[J].
大连海事大学学报
[J].
Chinese Short-Text Classification in Two-Steps
[J].
基于语义与最大匹配度的短文本分类研究
[J].
Short Text Classification Based on Semantics and Maximum Matching Degree
[J].
基于DDAG-SVM的在线商品评论可信度分类模型
[J].
Research on Reliability Classification Model of Online Product Reviews Based on DDAG-SVM
[J].
计算机与现代化
[J].
Chinese Short Text Classification Based on Sentence-LDA Topic Model
[J].
限定领域口语对话系统中超出领域话语的对话行为识别
[J].
Dialogue Act Recognition for Out-of-Domain Utterances in Spoken Dialogue System
[J].
基于句子级学习改进CNN的短文本分类方法
[J].
Improved CNN Based on Sentence-Level Supervised Learning for Short Text Classification
[J].
字符级卷积神经网络短文本分类算法
[J].
Character-Level Convolutional Neural Networks for Short Text Classification
[J].
面向个性化推荐的海量学术资源分类研究
[D].
Massive Academic Resources Classification Research for Personalized Recommender
[D].
基于文本挖掘和自动分类的法院裁判决策支持系统设计
[J].
Count Judgement Decision System Based on Text-mining and Machine Learning
[J].
基于社交平台数据的文本分类算法研究
[J].
Text Categorization Algorithm Based on Social Platform Data
[J].
Distributed Representations of Sentences and Documents
[C]//
网络舆情观点提取的LDA主题模型方法
[J].
Extraction Method of Network Public Opinion Based on LDA Topic Model
[J].
基于文档分布式表达的新浪微博情感分类研究
[J].
Sina Microblog Sentiment Classification Based on Distributed Representation of Documents
[J].
Random Forests[A]// Zhang C, Ma Y. Ensemble Machine Learning
[M].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}