




1 引 言
随着大数据时代的到来,知识成为时代创新进步的主要动力来源,知识网络作为信息传播的载体,可以对生产的大规模知识进行有效传递与分享,并逐渐成为情报学领域的研究热点。然而,随着互联网的迅速发展,在不同领域和不同模态等情境下,知识网络的表示呈现出高度的多样性和复杂性。传统的网络表示方法为基于图的表示,使用独热向量(One-Hot)形式的邻接矩阵描述图的存储结构。近年来产生了DeepWalk[1]、LINE[2]、Node2Vec[3]和SDNE[4]等一系列新的网络表示学习算法,这些方法得到的向量在向量空间中具有表示和推理的能力,同时可以作为机器学习模型的输入,并运用到网络可视化、节点分类、链接预测、社区发现等任务中。但多种网络表示学习方法的出现也为算法的选择带来困难,因此如何利用已有的网络表示学习算法更好地表示知识对象的语义关系成为一个重要的研究问题。
在上述背景下,在已有网络表示学习算法的基础上,本文借助集成学习和深度学习思想,提出组合式知识网络表示学习模型(Combined Knowledge Network Representation Learning, CKNRL),试图提高网络表示学习算法对知识对象语义关系的表达能力,解决多种知识网络表示学习算法难以选择的问题。
2 研究现状
2.1 知识网络
对于科学知识网络,按照不同的知识网络节点可以构建不同的知识网络,主要包括共词网络(以关键词作为网络节点)、合作网络(以合作者作为网络节点)、引文网络(以引用文献作为网络节点)等。
(1)在共词网络方面,当前主要有两方面的研究,一方面是共词网络基础上的词聚类分析以及知识结构演化分析。具体研究包括:郑彦宁等[5]利用研究前沿识别指标提出新的基于关键词共现的研究前沿识别方法,并将该方法应用到LED领域,有效识别出LED领域的研究前沿;商宪丽等[6]使用微博文本构建动态共词网络实现文本特征提取,实验结果表明该方法相比传统的文档频率法取得更优的微博话题识别效果,因此更适合用于微博文本的特征提取;孙耀吾等[7]基于2001年以来SSCI管理学期刊中的141篇技术标准化主题文献,从时间和高频词汇两个维度表现学术关注度,并运用共词分析方法分阶段进行网络的可视化研究;马红等[8]和蔡永明等[9]在传统的LDA模型中加入共词网络建立共词网络LDA模型,并针对中文文本进行主题分析,取得了较好的效果;宫雪等[10]突破共词网络“描述”阶段的研究,针对生物医学领域的主题词构建共词网络,并进一步研究未来链接预测的问题,是情报学领域的一项新探索。另一方面研究词语在网络中的影响力评价,当前这方面的研究较少。高继平等[11]从共词网络中连线的抽取与计量、计量指标的定义方面展开研究,并应用到关键技术的识别中,弥补了单个词在关键技术应用中语境不足、难以定位具体技术的缺陷。
(2)在合作网络方面,国内的研究主要集中在产学研合作、学科专利合作、学者影响力评测等领域。李纲等[12]依据社群发现方法,对燃料电池电动汽车领域的专利权人合作网络进行实证分析,揭示团队的研发主题与合作方式,为专利分析和产业发展提供指导。吕鹏辉等[13]将科研合作网络细化为作者、机构和国家这三种合作网络,通过深度分析和横向对比,验证作者合作网络的非连通性和稀疏性,同时对合作网络方法的局限性进行总结。陈伟等[14]以新能源汽车为研究对象构建加权专利合作网络,并使用社会网络的分析方法,探究该网络典型的结构特征。范如霞等[15]提出高合作学者识别算法和学者影响力模式识别算法,分别对高合作学者及其动态学术影响力模式进行识别,实验结果表明两种算法均有较好的识别效果。施晓华等[16]基于传统的科学合作网络及典型的社区发现方法,使用情报学领域论文作为数据建立科学合作网络,实现了社区数量的自动获取。
(3)在引文网络方面,吕鹏辉等[17]利用SSCI数据库收集了70多万情报学领域的文献数据,分析文献被引的时序变化情况,并绘制引文网络图以研究中心度高的节点;隗玲等[18]基于引文网络主路径分析方法存在的问题,使用元路径分析度量引文节点基于其关联属性的相关性,并与搜索路径计数遍历结合构建新的遍历权重指标,进一步促进了引文网络主路径方法的发展。此外,知识网络也被应用到社区网络、药物网络中,王忠义等[19]将知识网络应用到网络问答社区中,研究用户节点在网络问答社区中的知识传递效用,结果表明节点的知识存量越少,网络学习效率越高。范馨月等[20]构建药物靶点蛋白质相互作用网络,并基于网络的拓扑属性,运用机器学习方法有效预测潜在药物靶点。
2.2 网络表示学习
网络表示学习算法是网络分析中一个热点研究方向,其要求主要有两点:
(1)通过学习网络的表示保留网络的拓扑结构信息;
(2)根据网络的表示学习进行网络推断任务,如节点分类任务、链接预测任务等。
近年来,一系列新的网络表示算法被相继提出。Perozzi等[1]在2014年提出使用语言模型中的Word2Vec来学习图的邻接矩阵的隐含表示的算法DeepWalk,通过简单的随机游走策略生成一些路径后,作为文本语料输入Word2Vec中学习节点的向量表示。此后,Tang等[2]提出LINE算法,通过定义一个精巧的目标函数保留节点的一阶或二阶相似度,并将每个节点的两类特征表示连接起来作为最终表示,由于考虑了网络结构中更高阶的信息,从而获得了较好的效果。Grover等[3]在DeepWalk的基础上针对其随机游走的策略提出改进算法Node2Vec,使得随机游走的过程兼顾了广度优先搜索和深度优先搜索,从而提高了随机游走生成路径的质量。Wang等[4]也提出一个深度学习模型SDNE(Structural Deep Network Embedding),该模型在半监督学习模型中联合优化节点的一阶相似度和二阶相似度,能够同时保留网络的局部结构和全局结构。其中,DeepWalk和Node2Vec使用的都是浅层神经网络,在刻画网络结构上有先天的局限,相较而言,SDNE使用了多层自编码器,因此具有更好的表现。
现有的网络表示学习算法已被应用到跨领域情感分析、商品推荐、观点检索、链路预测等多个方面。余传明等[21]提出一种跨领域知识迁移的深度表示模型,采用无监督的特征提取方法Sparse Filtering,充分利用无标注文档中与语言无关的语义表示,实现将不同领域的文档投影到同一空间,并将其应用到跨领域情感分析任务中。李宇琦等[22]提出商品网络表示学习模型PGE,利用商品节点的邻边作为当前商品节点的上下文信息,通过统计商品节点共享相邻节点的数量比较商品间的相似性,可以针对特定用户更有效地进行商品推荐。张金柱等[23]在科研合作网络中,通过LINE网络表示学习方法得到稠密低纬度的作者向量表示,显著提高了海量数据背景下科研合作预测的效率。刘姝雯等[24]提出一种基于层次多项逻辑回归的CBOW算法,将用户表示为低维稠密的向量,用以识别微博水军。樊玮等[25]构建包含论文、作者和期刊的异构网络表示学习的模型,将三种不同类型的节点表示到稠密低维的向量空间中,能够充分利用网络的局部结构信息,实现对论文未来影响力的预测。孙晓玲等[26]提出将深度表示学习引入知识计量领域,对知识进行关键词表示学习、文献表示学习和其他以知识单元为基础的知识表示学习,显著提高了知识发现、融合以及推理的效率。廖祥文等[27]提出一种局部特性建模的网络表示算法,将知识图谱中的节点表示为低维向量,并引入基于统计机器学习的方法进行文本观点挖掘,有效提高了多种检索模型的观点检索性能。刘思等[28]提出一种基于深度学习的网络表示学习算法,学习网络节点的潜在结构特征,将网络中的各节点表示到低维的向量空间中,最终通过在链路预测任务上的实验验证了算法的有效性。
值得说明的是,当前组合式表示学习尚未系统地应用于知识网络的表示研究。鉴于此,本文尝试构建组合式知识网络表示学习模型,采用网络嵌入融合和网络表示学习算法融合两种模型融合方式,增强网络表示学习算法对知识对象语义关系的表达能力。同时,以中文文本构建中文共词网络,验证CKNRL模型在共词网络中的可行性和有效性。
3 研究问题与研究方法
3.1 研究问题及相关定义
所谓知识网络表示学习[29],是指在给定单个语言(或单个领域、单个模态)下的知识网络NetworkA(简记为A),将知识网络中每个节点映射为低维向量的过程。具体而言,假定
为表述方便,本文的相关符号定义如表1所示。
表1 相关符号说明
Table 1
| 符号表示 | 说明 |
|---|---|
| DeepWalk算法获得的针对网络中第i个节点的表征 | |
| Node2Vec算法获得的针对网络中第i个节点的表征 | |
| SDNE算法获得的针对网络中第i个节点的表征 | |
| DeepWalk算法针对第j个节点对的分类结果(概率) | |
| Node2Vec算法针对第j个节点对的分类结果(概率) | |
| SDNE算法针对第j个节点对的分类结果(概率) |
3.2 模型描述
单语言知识网络深度表示研究部分主要提出组合式知识网络表示学习模型(CKNRL),该模型完成单语言情境下的链接预测任务,以发现单语言知识网络中的潜在相似节点。CKNRL将DeepWalk、Node2Vec和SDNE三种算法得到的网络嵌入通过加权的方式分别进行网络嵌入融合和网络表示学习算法分类结果融合,以增强网络表示学习算法对知识对象语义关系的表达能力。本文主要探索CKNRL模型在单语言链接预测问题上的有效性,并通过系列基础实验,探索CKNRL模型在不同网络嵌入维度大小、不同滑动窗口大小、不同特征构造方法、不同模型融合方式以及不同机器学习算法等5个方面的工作效果,以找出最佳的超参数组合,最大程度提升单语言情境下的知识网络链接预测效果。具体流程如图1所示。
图1
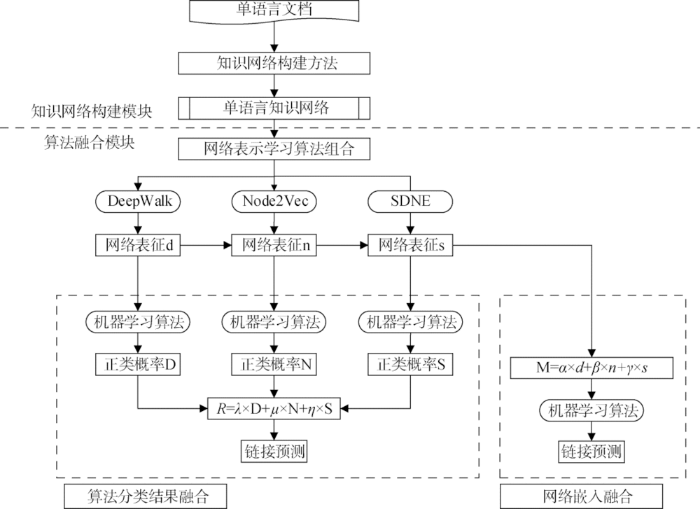
(1) 基础模型
DeepWalk[1]:在网络上采样生成大量的随机游走序列,然后用Skip-gram和Hierarchical Softmax模型对随机游走序列中每个局部窗口内的节点进行概率建模,最大化随机游走序列的似然概率,并采用随机梯度下降和反向传播算法优化节点表示向量,最后训练生成每个节点最优的向量表示。
Node2Vec[3]:通过改变随机游走序列生成的方式进一步扩展DeepWalk算法。DeepWalk选取随机游走序列中下一个节点的方式是均匀随机分布的,而Node2Vec通过引入两个参数p和q,将广度优先搜索和深度优先搜索引入随机游走序列的生成过程。广度优先搜索注重邻近的节点并刻画了相对局部的一种网络表示,广度优先中的节点一般会出现很多次,从而降低刻画中心节点的邻居节点的方差;深度优先搜索反映了更高层面上的节点间的同质性。
SDNE[4]:使用深层神经网络对节点表示间的非线性进行建模。整个模型可以被分为两个部分:一个是由有监督的Laplace矩阵对第一级相似度关系进行建模的模块,另一个是由无监督的深层自编码器对第二级相似度关系进行建模,最终SDNE算法将深层自编码器的中间层作为节点的网络表示。相较而言,DeepWalk和Node2Vec使用的都是浅层神经网络,在刻画网络结构上有先天的局限,而SDNE使用多层自编码器,因此在具体任务上有更好的表现。
(2) 知识网络模块
网络表示学习算法的输入对象为二维网络数据(用邻接矩阵表示),当前拥有的数据为一维文档数据,需要将一维文档数据转换为二维网络数据,通过文档转化得到的网络被称为知识网络。
网络由节点和边两个模块构成。在知识网络中,节点对应的是“词”,边对应的是“给定窗口内词和词之间的共现关系”。具体地,假定在一个窗口大小内(假设为3,中文为分词后的3个词,英文为3个单词),所有词之间相互联系,在知识网络中则体现为窗口内的词对应的节点之间均有边相连。
构建知识网络具体包括三部分,具体描述如下:
①分词:原始的中文文档和英文文档以句子形式存在,而知识网络中每个节点对应一个词汇,需要将句子切分为词才能与知识网络中的节点一一对应。
②确定窗口大小:在知识网络中,需要确定哪些词之间相互关联,本文假定一个窗口大小下的所有词之间相互关联。
③构建词典和索引:构建词典V,对其中的每个词建立索引;遍历原始文档,将一个窗口内的每个词和剩下的词之间建立链接关系L;通过词典V将“文字链接关系L”转化为“索引链接关系”,从而得到由一一配对的词对应索引组成的邻接矩阵。
(3) 算法融合模块
在获取邻接矩阵之后,将邻接矩阵作为表示学习算法的输入部分,输出知识网络中每个节点对应的向量表示。由于网络表示学习算法不同,每种算法各有优劣,单纯依靠某算法完成链接预测任务存在一定缺陷。本文尝试将几种网络表示学习算法得到的网络嵌入进行融合,并探讨最佳的融合方式,以融合后的网络嵌入完成链接预测任务。网络表示学习算法的融合分为两种形式:网络嵌入融合和网络表示学习算法分类结果融合。
就网络嵌入融合而言,以DeepWalk、Node2Vec和SDNE三种算法作为CKNRL的基础组成模块。假定针对第i个节点,以上三种算法获得的网络嵌入分别是
将组合后的节点嵌入M作为特征,运用机器学习方法完成单语言知识网络链接预测任务。相对于人工寻找词的特征,通过表示学习方法获得节点向量的方式在一定程度上减少了人力成本;此外,表示学习算法利用了网络的结构信息,因此通过表示学习算法得到的节点向量具有表示网络结构的能力。
就网络表示学习算法分类结果融合而言,同样以DeepWalk、Node2Vec和SDNE三种算法作为CKNRL的基础组成模块。假定针对第j个节点(样本),DeepWak算法获得网络嵌入后,通过机器学习算法完成链接预测,得到链接预测结果
从作用层次角度看,网络嵌入融合方法作用于特征层次,而网络表示学习算法分类结果融合方法则作用于表示学习算法层次,通过在不同层次的融合提高算法对知识对象语义关系的表达能力。
4 实验结果与讨论
4.1 数据集
本次实验数据集来自新闻领域的中文数据集[30]。首先对数据集进行预处理,包含数据清洗和知识网络构建两个部分。数据清洗主要是对中文语料中标点符号、空格、停用词等进行删除。知识网络的构建分为三步:
(1)使用中文分词工具Jieba[31]对数据清洗后的中文语料进行分词;
(2)确定窗口大小为3;
(3)构建词典及每个词的索引,根据固定窗口下词和词之间的共现关系,建立对应索引组成的邻接矩阵。
原始中文文本语料经过预处理之后,得到中文知识节点5 480个,其中各个词性的中文知识节点情况如表2所示。
表2 单语言知识网络统计数据
Table 2
| 网络信息 | 中文网络 |
|---|---|
| 名词性节点 | 3 132 |
| 动词性节点 | 1 956 |
| 形容词性节点 | 342 |
| 其他知识节点 | 50 |
| 边数 | 110 301 |
4.2 参数设置
表3 深度表示学习实验相关情况说明
Table 3
| 相关操作 | 详细说明 |
|---|---|
| 表示学习算法种类 | DeepWalk、Node2Vec、SDNE |
| 完成任务 | 链接预测 |
| 数据不平衡比例 | 正例:负例=1:3 |
| 选取变量 | 网络嵌入维度大小 滑动窗口大小 特征构造方法 模型融合方式 机器学习算法 |
| 训练集和测试比例 | 8:2 |
| 评估指标 | Precision、Recall、F1、Accuracy、AUC |
| 机器学习算法 | XGBoost、LightGBM、NB、LR、MLP、RF |
表4 各表示学习算法参数
Table 4
| 算法 | 参数名 | 参数值 |
|---|---|---|
| DeepWalk | 迭代次数 | 80 |
| 随机游走长度 | 40 | |
| 嵌入维度 | 50、100、150、200 | |
| Node2Vec | 迭代次数 | 100 |
| 随机游走长度 | 80 | |
| 嵌入维度 | 50、100、150、200 | |
| p | 1 | |
| q | 0.5 | |
| SDNE | 迭代次数 | 300 |
| 学习率 | 0.01 | |
| 批处理样本数 | 64 | |
| 嵌入维度 | 50、100、150、200 | |
| Alpha | 100 | |
| Gamma | 1 | |
| Beta | 10 | |
| XGBoost | Thread | 5 |
| scale_pos_weight | 3 |
4.3 评价指标
评价指标主要有5种,分别是Precision(准确率)、Recall(召回率)、F1值、Accuracy(精确率)和AUC值。
4.4 基线方法
为验证CKNRL模型的效果,从以下两个方面对CKNRL模型和基线方法进行比较:
(1)在系列基础实验方面,分别以网络嵌入维度大小、滑动窗口大小、特征构造方法、模型融合方式以及机器学习算法5种因素为变量,探究5种因素对于链接预测效果的影响,以得到CKNRL模型的最优参数。
(2)在知识网络表示学习方面,以DeepWalk、Node2Vec和SDNE三种算法为基线方法,与CKNRL模型进行对比,以判断其在完成单一网络链接预测任务上的有效性。
4.5 实验结果
(1) 嵌入维度对网络表示学习效果的影响
为探究不同网络嵌入维度对链接预测效果的影响,需要完成不同维度下的链接预测实验。以网络嵌入维度大小为变量,分别取50、100、150、200等4种维度,其他超参数固定,其中滑动窗口大小为5,根据实验(4)的结果选择最优参数作为
表5 不同嵌入维度完成链接预测任务的实验结果
Table 5
| 维度大小 | Precision | Recall | F1 | Accuracy | AUC |
|---|---|---|---|---|---|
| 50 | 0.74 | 0.69 | 0.72 | 0.864 | 0.912 |
| 100 | 0.79 | 0.69 | 0.74 | 0.876 | 0.917 |
| 150 | 0.78 | 0.69 | 0.73 | 0.873 | 0.915 |
| 200 | 0.75 | 0.72 | 0.73 | 0.870 | 0.912 |
从表5的实验结果看,当CKNRL模型的网络嵌入维度为100维时,链接预测效果最好(AUC值为0.917),而在50维和200维下的链接预测效果最差(AUC值为0.912)。实验结果表明维度大小与链接预测效果并非呈正比关系,而是存在一个最合适的嵌入维度(本实验中最合适的嵌入维度为100)。
(2) 滑动窗口大小对网络表示学习效果的影响
为探究不同滑动窗口大小对链接预测的影响,需完成不同窗口大小下的链接预测实验。此处以滑动窗口大小为变量(分别为3、5、7、9),固定其他变量,网络嵌入维度为100,根据实验(4)的结果选择最优参数作为
表6 不同窗口大小完成链接预测任务的实验结果
Table 6
| 窗口大小 | Precision | Recall | F1 | Accuracy | AUC |
|---|---|---|---|---|---|
| 3 | 0.80 | 0.53 | 0.63 | 0.848 | 0.869 |
| 5 | 0.79 | 0.69 | 0.74 | 0.876 | 0.917 |
| 7 | 0.75 | 0.73 | 0.74 | 0.871 | 0.921 |
| 9 | 0.74 | 0.77 | 0.75 | 0.875 | 0.928 |
由表6可知,滑动窗口大小与链接预测效果成正比。从信息量角度来看,滑动窗口越大,知识网络的边会越丰富,网络所包含的信息也会越丰富,因此网络表示学习的效果越好。从算法的角度来看,当滑动窗口变大时,输入数据量也越大,深度学习算法的效果越好,网络数据量同时也在增大,因此网络表示学习算法能够获得更好的网络表示效果。
(3) 特征构造方法对网络表示学习效果的影响
为探究不同特征构造方法对链接预测的影响,需完成不同特征构造方法下的链接预测实验。此处以特征构造方法为变量,其中,构造方法有5种,分别是“拼接”、“点乘”、“相减并取绝对值”、“相加取平均”和“相减取平方”,其他变量固定,网络嵌入维度为100,滑动窗口大小为9,根据实验(4)的结果选择最优参数作为
表7 不同特征构造方法对链接预测的影响
Table 7
| 特征构造方法 | Precision | Recall | F1 | Accuracy | AUC |
|---|---|---|---|---|---|
| 拼接 | 0.63 | 0.78 | 0.69 | 0.828 | 0.891 |
| 点乘 | 0.69 | 0.78 | 0.74 | 0.859 | 0.919 |
| 相减取绝对值 | 0.74 | 0.76 | 0.75 | 0.872 | 0.927 |
| 相加取平均 | 0.54 | 0.73 | 0.62 | 0.775 | 0.828 |
| 相减取平方 | 0.73 | 0.77 | 0.75 | 0.872 | 0.927 |
从表7的实验结果看,“相减取绝对值”和“相减取平方”的特征构造方法在各个评价指标上表现较好,其他的特征构造方法(如拼接、点乘和平均)与上述两种方法相比,仍然有一定差距。从物理意义上看,“向量相减”的系列方法表征的是空间中两点的距离,具有实际的物理意义,且构造的特征属于强特征类型。此外,“点乘”和“平均”这两种特征构造方法则没有较为清晰的物理意义,“拼接”方法虽是通过增大特征的个数来提高链接预测准确率,但构造的特征与“向量相减”系列方式相比依旧较弱,这导致“拼接”方法虽能完成预测,但其AUC值低于“向量相减”系列方法。
(4) 模型融合方式对于链接预测的影响
就网络嵌入融合而言,由于CKNRL模型由三种表示算法构成,有必要探索最佳的超参数
表8 不同模型融合方式完成链接预测任务的部分实验结果(网络嵌入融合)
Table 8
| Precision | Recall | F1 | AUC | |||
|---|---|---|---|---|---|---|
| 0.0 | 0.0 | 1.0 | 0.65 | 0.77 | 0.71 | 0.899 |
| 0.0 | 0.3 | 0.7 | 0.67 | 0.74 | 0.70 | 0.896 |
| 0.0 | 0.6 | 0.4 | 0.59 | 0.71 | 0.64 | 0.861 |
| 0.0 | 0.9 | 0.1 | 0.73 | 0.76 | 0.75 | 0.925 |
| 0.1 | 0.0 | 0.9 | 0.67 | 0.77 | 0.72 | 0.906 |
| 0.1 | 0.3 | 0.6 | 0.67 | 0.74 | 0.70 | 0.893 |
| 0.1 | 0.6 | 0.3 | 0.64 | 0.73 | 0.68 | 0.885 |
| 0.1 | 0.9 | 0.0 | 0.74 | 0.77 | 0.75 | 0.929 |
| 0.2 | 0.0 | 0.8 | 0.67 | 0.77 | 0.72 | 0.905 |
| 0.2 | 0.3 | 0.5 | 0.65 | 0.73 | 0.69 | 0.880 |
| 0.2 | 0.6 | 0.2 | 0.69 | 0.75 | 0.72 | 0.908 |
| 0.3 | 0.0 | 0.7 | 0.68 | 0.76 | 0.72 | 0.901 |
| 0.3 | 0.3 | 0.4 | 0.60 | 0.70 | 0.65 | 0.857 |
| 0.3 | 0.6 | 0.1 | 0.71 | 0.77 | 0.74 | 0.917 |
| 0.4 | 0.1 | 0.5 | 0.66 | 0.73 | 0.69 | 0.884 |
| 0.4 | 0.4 | 0.2 | 0.66 | 0.75 | 0.70 | 0.897 |
| 0.5 | 0.0 | 0.5 | 0.64 | 0.72 | 0.68 | 0.877 |
| 0.5 | 0.3 | 0.2 | 0.64 | 0.75 | 0.69 | 0.896 |
| 0.6 | 0.0 | 0.4 | 0.60 | 0.72 | 0.66 | 0.862 |
| 0.6 | 0.3 | 0.1 | 0.70 | 0.78 | 0.73 | 0.917 |
| 0.7 | 0.1 | 0.2 | 0.69 | 0.77 | 0.73 | 0.911 |
| 0.8 | 0.0 | 0.2 | 0.70 | 0.77 | 0.73 | 0.915 |
| 0.9 | 0.0 | 0.1 | 0.71 | 0.79 | 0.75 | 0.922 |
| 1.0 | 0.0 | 0.0 | 0.72 | 0.78 | 0.75 | 0.925 |
当
就网络表示学习算法分类结果融合而言,其变量是DeepWalk、Node2Vec和SDNE三种算法分类结果对应的权重(
表9 不同模型融合方式完成链接预测任务的部分实验结果(分类结果融合)
Table 9
| Precision | Recall | F1 | AUC | |||
|---|---|---|---|---|---|---|
| 0.0 | 0.0 | 1.0 | 0.50 | 0.90 | 0.64 | 0.898 |
| 0.0 | 0.5 | 0.5 | 0.54 | 0.93 | 0.68 | 0.925 |
| 0.0 | 1.0 | 0.0 | 0.55 | 0.93 | 0.69 | 0.928 |
| 0.1 | 0.0 | 0.9 | 0.51 | 0.91 | 0.65 | 0.905 |
| 0.1 | 0.5 | 0.4 | 0.55 | 0.93 | 0.69 | 0.929 |
| 0.2 | 0.0 | 0.8 | 0.52 | 0.91 | 0.66 | 0.911 |
| 0.2 | 0.5 | 0.3 | 0.56 | 0.94 | 0.70 | 0.932 |
| 0.3 | 0.0 | 0.7 | 0.53 | 0.91 | 0.67 | 0.916 |
| 0.3 | 0.5 | 0.2 | 0.57 | 0.94 | 0.71 | 0.934 |
| 0.3 | 0.6 | 0.1 | 0.57 | 0.94 | 0.71 | 0.935 |
| 0.4 | 0.0 | 0.6 | 0.53 | 0.91 | 0.67 | 0.920 |
| 0.4 | 0.5 | 0.1 | 0.58 | 0.94 | 0.72 | 0.935 |
| 0.5 | 0.0 | 0.5 | 0.54 | 0.92 | 0.68 | 0.922 |
| 0.5 | 0.5 | 0.0 | 0.58 | 0.94 | 0.72 | 0.934 |
| 0.6 | 0.0 | 0.4 | 0.55 | 0.92 | 0.69 | 0.924 |
| 0.7 | 0.0 | 0.3 | 0.56 | 0.92 | 0.70 | 0.926 |
| 0.7 | 0.1 | 0.2 | 0.57 | 0.93 | 0.70 | 0.928 |
| 0.8 | 0.0 | 0.2 | 0.57 | 0.92 | 0.70 | 0.926 |
| 0.9 | 0.0 | 0.1 | 0.57 | 0.92 | 0.70 | 0.925 |
| 1.0 | 0.0 | 0.0 | 0.57 | 0.92 | 0.70 | 0.924 |
当
(5) 机器学习算法对于链接预测的影响
为探究不同机器学习算法对链接预测的影响,需完成不同机器学习算法下的链接预测实验。此处选择9种不同的机器学习算法,分别是朴素贝叶斯(Naive Bayes, NB)、Logistic回归(Logistic Regression,LR)、XGBoost、LightGBM、多层感知机(Multi-Layer Perceptron,MLP)、随机森林(Random Forest,RF)、Bagging、Voting和Bagging and Voting(BVC)。其中Bagging方法与随机森林类似,都是集成学习方法,其不同点在于基分类器不同。具体来说,随机森林的基分类器为决策树(Decision Tree),而Bagging方法的基分类器可以是任何一种机器学习算法,此处选取LR作为Bagging的基分类器。Voting算法本质上是集成学习算法中的Bagging算法,与RF的不同在于Voting中的基分类器各不相同,此处选取LR、NB和XGBoost作为基分类器。BVC算法是先用Bagging方法构建集成学习分类器,然后用Voting方法在集成分类器的基础上构建集成学习分类器。其他变量固定,网络嵌入维度为100,滑动窗口大小为9,
表10 机器学习算法对于链接预测的影响(网络嵌入融合)
Table 10
| Algorithm | Precision | Recall | F1 | AUC |
|---|---|---|---|---|
| NB | 0.74 | 0.76 | 0.75 | 0.929 |
| LR | 0.75 | 0.75 | 0.75 | 0.928 |
| XGBoost | 0.69 | 0.82 | 0.75 | 0.927 |
| LightGBM | 0.75 | 0.75 | 0.75 | 0.925 |
| MLP | 0.75 | 0.73 | 0.74 | 0.914 |
| RF | 0.66 | 0.77 | 0.71 | 0.903 |
| Bagging | 0.66 | 0.73 | 0.69 | 0.893 |
| BVC | 0.67 | 0.75 | 0.71 | 0.903 |
| Voting | 0.78 | 0.74 | 0.76 | 0.924 |
由表10可知,网络嵌入融合方法对应的最佳机器学习算法为NB,其AUC值为0.929,高于其他机器学习方法。从原理上看,本实验采用的NB算法中假定先验分布为高斯分布,当原始数据分布与高斯分布接近时,此算法可产生较好结果。相对于其他算法而言,NB算法比较简单,不会出现过拟合现象。
模型融合方法为网络表示学习算法分类结果融合时,机器学习算法对于链接预测的影响如表11所示。
表11 机器学习算法对于链接预测的影响(分类结果融合)
Table 11
| Algorithm | Precision | Recall | F1 | AUC |
|---|---|---|---|---|
| RF | 0.70 | 0.77 | 0.73 | 0.917 |
| LR | 0.79 | 0.72 | 0.75 | 0.935 |
| MLP | 0.79 | 0.69 | 0.74 | 0.918 |
| XGBoost | 0.71 | 0.84 | 0.77 | 0.937 |
| LightGBM | 0.78 | 0.74 | 0.76 | 0.936 |
| NB | 0.78 | 0.76 | 0.77 | 0.920 |
| Bagging | 0.72 | 0.75 | 0.73 | 0.920 |
| Voting | 0.78 | 0.75 | 0.76 | 0.933 |
| BVC | 0.72 | 0.78 | 0.75 | 0.924 |
由表11可知,网络表示学习算法分类结果融合方法对应的最佳机器学习算法为XGBoost,获得最高的AUC值0.937,高于其他机器学习方法,但其Precision(0.71)和Recall(0.84)值差别过大。
在实际应用中,可根据实际情况选择不同的融合方法。若考虑到整体性能,则网络嵌入融合方法较为适合;若追求高召回率,则网络表示学习算法分类结果融合方法较为适合。
(6) 对比实验结果
为探究融合后模型的效果,将CKNRL模型与基线方法DeepWalk、Node2Vec和SDNE三种表示学习算法进行比较。基于这两个原则进行参数选择:一方面为与基线方法参数设置保持一致;另一方面根据上述系列实验结果选择最优的参数。参数取值分别为:网络嵌入维度为100,滑动窗口大小为9,模型融合方式为“网络嵌入融合”,
表12 表示学习对比实验结果
Table 12
| 方法 | Precision | Recall | F1 | Accuracy | AUC |
|---|---|---|---|---|---|
| CKNRL | 0.74 | 0.77 | 0.75 | 0.874 | 0.929 |
| DeepWalk | 0.72 | 0.78 | 0.75 | 0.868 | 0.925 |
| Node2Vec | 0.73 | 0.77 | 0.75 | 0.872 | 0.926 |
| SDNE | 0.65 | 0.77 | 0.71 | 0.840 | 0.899 |
CKNRL模型在Precision、AUC两个指标上均优于基线方法,在其他评估指标上相差不大。在最重要的指标(AUC)值上,CKNRL模型取得最高的AUC值(0.929),表明CKNRL模型能够取得相对于基线方法更好的结果。从CKNRL模型的本质上来看,CKNRL模型是一种组合表示学习算法,能够综合DeepWalk、Node2Vec和SDNE三种算法的优点,从而达到最好的链接预测结果。
4.6 讨 论
从数据的利用上看,本文通过构建新闻领域的中文知识网络,以完成中文网络节点链接预测任务。CKNRL模型设定网络嵌入维度大小、滑动窗口大小、特征构造方法、模型融合方式以及机器学习算法5种不同的超参数,目的是利用原始数据的内在信息,最大限度地表征单个词语义以及不同词汇之间的关系。通过设定不同的嵌入维度大小,寻找最合适的维度表征词汇语义;通过设定滑动窗口大小,保证窗口内部词汇呈现共现关系,完成原始文本数据到网络结构数据的转变;通过设定不同的特征构造方法,利用空间中两点的位置表征两个词汇之间的联系;通过设定不同的模型融合方式和不同的机器学习算法,探究网络嵌入融合和算法结果融合两种方式对链接预测结果的影响。
从模型的内在原理上看,由于每种表示学习算法都有各自适用的领域,将其迁移到其他领域时,单个表示学习算法的效果可能会下降,而组合式表示学习算法能够解决这一问题。类似于集成学习算法将多个弱分类器线性融合为一个强分类器的形式,组合式表示算法通过给每种表示学习算法得到的网络嵌入赋予不同的权重,以不均等的方式进行资源分配,达到不同领域以不同的融合方式进行预测的目的,从而使算法能够适应更广泛的领域。CKNRL模型是由多种表示学习算法融合的结果(隶属于组合式算法),在一定程度上,该模型能够更好地表示知识对象的语义关系,具有更广泛的适用性。
从模型的应用上看,CKNRL模型实质上是一种分析单个网络中知识节点间相关关系的框架。本文的研究对象是自然语言,网络节点中每个节点对应一个词汇,通过链接预测发现知识节点之间的近邻关系。推广来看,如果面对的领域为社交网络,则链接预测对应好友发现;如果面对的领域为科研合作网络,则链接预测对应合作推荐;如果面对的领域为引文网络,则链接预测对应引文推荐;如果面对的领域为交通网络,则链接预测为地域聚类。由此可知,CKNRL模型不仅可以用于自然语言处理领域,还可以推广到其他领域,具备潜在的商用价值。
5 结 语
本文从网络视角出发,对领域知识表示中的网络表示学习技术展开研究。回顾知识网络、表示学习等相关理论和方法;在单语言情境下提出组合式知识网络表示学习模型(CKNRL),通过权重组合方法,增强网络表示学习算法对知识对象语义关系的表达能力;最后,以中文文本构建中文共词网络,验证CKNRL模型在共词网络中的可行性和有效性,相对于传统的网络表示学习模型具有更好的融合性能。
CKNRL模型在不同类型知识网络中,对增强网络表示算法的稳定性具有重要作用。单个网络表示学习算法可能适合某种类型的知识网络(如共词网络),而不适合另外一种类型的知识网络(如合著网络),而组合式网络表示学习模型CKNRL可综合多种表示学习算法的优势,通过权重组合的方式找出最优的网络表示学习算法,以达到增强算法适用性的效果,同时提高网络表示学习算法在链接预测任务上的准确度。
本文的不足之处在于实证研究建立在共词网络的基础上,未来将进一步检验CKNRL模型在更多类型知识网络中链接预测任务的效果。
作者贡献声明
余传明:提出研究思路,设计研究方案,构建模型;
李浩男:采集、清洗数据,进行实验,撰写论文初稿;
王曼怡:基线对比实验,论文修改;
黄婷婷:扩展实验,论文修改;
安璐:论文最终版本修订。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据
支撑数据由作者自存储,E-mail: yuchuanming2003@126.com。
[1] 余传明.news-commentary-v11.en-zh.xliff.新闻平行语料原始数据集.
[2] 余传明.训练集与测试集数据.rar. 窗口为3、5、7、9的训练集与测试集数据.
[3] 余传明.附录.doc.不同特征组合方式完成链接预测任务的详细实验结果.
参考文献
DeepWalk: Online Learning of Social Representations
[C]//
LINE: Large-scale Information Network Embedding
[C]//
Node2Vec: Scalable Feature Learning for Networks
[C]//
Structural Deep Network Embedding
[C]//
基于关键词共现的研究前沿识别方法研究
[J].
Study on the Method of Identifying Research Fronts Based on Keywords Co-occurrence
[J].
图书情报知识
[J].
A Feature Selection Method Based on Dynamic Co-Word Network for Microblog Topic Detection
[J].
技术标准化主题学术关注度及共词网络演化研究
[J].
The Academic Interest of Technological Standardization Topic and Its Co-Word Network Evolution Research
[J].
共词网络LDA模型的中文文本主题分析:以交通法学文献( 2000 -2016)为例
[J].
A CA-LDA Model for Chinese Topic Analysis: Case Study of Transportation Law Literature
[J].
共词网络LDA模型的中文短文本主题分析
[J].
Chinese Short Text Topic Analysis by Latent Dirichlet Allocation Model with Co-Word Network Analysis
[J].
基于医学主题词共现网络的链接预测研究
[J].
Link Prediction in MeSH Terms Co-occurring Networks
[J].
共词网络中连线的重要性分析及其应用
[J].
Importance Analysis and Application of Connections in Co-Word Networks
[J].
专利权人合作网络的社群结构分析——以燃料电池电动汽车专利为例
[J].
Analysis of the Community Structure of Patentees’ Collaboration Network——Fuel Cell Electric Vehicle Patents as an Example
[J].
学科知识网络实证研究(Ⅳ)合作网络的结构与特征分析
[J].
Scientific Knowledge Networks in LIS(IV): Investigation on the Structure and Characteristics of Cooperation Networks
[J].
基于新能源汽车的加权专利合作网络研究
[J].
Research on the Weighted Patent Cooperation Network Based on New Energy Vehicles
[J].
基于合作网络的学者动态学术影响力模式识别研究
[J].
Recognizing Dynamic Academic Impacts of Scholars Based on Cooperative Network
[J].
基于矩阵分解学习的科学合作网络社区发现研究
[J].
Detecting Community in Scientific Collaboration Network with Bayesian Symmetric NMF
[J].
学科知识网络研究(Ⅰ)引文网络的结构、特征与演化
[J].
Scientific Knowledge Networks in LIS(I): Case Study on the Structure, Characteristics and Evolution of Citation Networks
[J].
基于文献关联属性的引文网络主路径识别——以合成生物学领域为例
[J].
Citation Network Main Path Identification Based on Associated Attributes of Articles: Case Study from Synthetic Biology
[J].
基于社会网络分析的网络问答社区知识传播研究
[J].
Studying Knowledge Dissemination of Online Q&A Community with Social Network Analysis
[J].
基于网络属性的抗肿瘤药物靶点预测方法及其应用
[J].
Predicting Antineoplastic Drug Targets Based on Network Properties
[J].
基于深度表示学习的跨领域情感分析
[J].
Sentiment Analysis in Cross-Domain Environment with Deep Representative Learning
[J].
基于网络表示学习的个性化商品推荐
[J].
Learning Graph-based Embedding for Personalized Product Recommendation
[J].
基于网络表示学习的科研合作预测研究
[J].
Predicting Research Collaborations Based on Network Embedding
[J].
基于用户表示学习的微博水军识别研究
[J].
Water Army Detection of Weibo Using User Representation Learning
[J].
基于网络表示学习的论文影响力预测算法
[J/OL].
Paper Influence Prediction Algorithm Based on Network Representation Learning
[J/OL].
深度学习中的表示学习研究及其对知识计量的影响
[J].
Study of Representation Learning in Deep Learning and Its Impact on Knowledge Measurement
[J].
融合文本概念化与网络表示的观点检索
[J].
Opinion Retrieval Method Combining Text Conceptualization and Network Embedding
[J].
基于网络表示学习与随机游走的链路预测算法
[J].
Link Prediction Algorithm Based on Network Representation Learning and Random Walk
[J].
知识表示学习研究进展
[J].
Knowledge Representation Learning: A Review
[J].
新闻平行语料数据集
[EB/OL]. [
News-commentary Corpus
[EB/OL]. [

{kind=link}
{kind=link}