




1 引 言
引用对象是引用内容分析的重要研究单元,相比其他引用内容分析,引用对象直接地揭示了文献间的本质联系。引用对象概念雏形最早由Small[3]在1978年提出,即作者引用文献时提及引文的具体科学内容,以一种泛化的“概念符号”(Concept Symbols)描述引文中的概念或方法。引用对象是引文内容的一部分,但不包含作者对内容的主观评价。引用对象从内容层面展示引文的利用价值和学术贡献,与引文分类相比,可以更加直接地解释作者的引用行为,具有重要价值。通过识别引用对象,结合引用关系构建深度语义化的引文网络,可深入语义层面挖掘论文之间的潜在关联,从同行评议的角度帮助研究者快速发现论文的重要价值,为学术成果贡献分析、交叉学科链接点挖掘、知识发现、人才评价等提供重要维度,因此,引用对象的识别研究具有重要的理论意义和实际应用价值。
基于对引用对象的特征分析,本文尝试将引用对象识别转换为序列标注问题,提出基于特征融合的引用对象自动化识别方法。通过人工选取引用对象重要特征,设计特征向量表示和融合方法,为BiLSTM-CNN-CRF[11]神经网络模型提供更多的先验知识,同时为解决引用对象标注数据不足的问题,设计伪标签学习策噪音控制策略,提高算法准确性,最后通过探究不同特征以及组合特征对识别的影响,证明了本方法识别术语型引用对象的有效性。
2 相关研究
2.1 引用对象识别
2.2 基于深度学习的序列标注
基于神经网络的深度学习方法在各类序列标注问题上表现出比传统机器学习方法更高效的性能。为更好地解决实际研究问题,学者们从扩展特征表示、改进模型架构和解决标注数据有限三个方面不断探索,提高模型的泛化能力。
以词向量表示文本中词语之间存在的相关关系[12]是深度学习算法的核心技术之一,学者们利用词向量表示词语的特征,弥补了人工提取特征的不足。在词向量基础上,Santos等[13]利用CNN对输入序列中每个字符进行编码,捕捉单词字符级特征,在英文语料的词性标注任务中取得97.32%的准确性。Rei等[14]在Bi-LSTM-CRF模型的基础上,使用字符向量和词向量的拼接解决序列标注问题中未登录词的问题,在向量拼接时尝试了两种不同的向量拼接方式并对比实验结果。赵洪等[15]利用Bi-LSTM-CRF模型作为基础模型,融入词性和理论术语实体特征,结合自训练方法,在理论术语抽取任务中F1值达到0.85。Zhang等[16]提出一种通过多信息实体增强语言表证的知识驱动模型,通过在大规模文本语料库和知识库上预训练语言模型,将知识信息整合进语言模型中,在自然语言处理任务中获得很好效果。
综上,深度学习方法在各种序列标注问题上得到广泛的发展,本文利用深度学习方法尝试解决术语型引用对象自动化识别问题,根据引用对象的特点,构建面向引用对象识别模型,设计半监督学习方法,解决标注数据不足问题。
3 识别方法
3.1 模型选择
序列标注问题将引用句看作一个序列,输出一个等长的符号序列,其中每个符号都有特定的含义,引用对象以标签形式被符号所标记。传统的序列标注模型包括隐马尔科夫模型(Hidden Markov Model, HMM)[20]、条件随机场(Conditional Random Fields, CRF)[21]等方法,比较流行的是特征模板结合CRF的方法。特征模板通常是人工定义的一些特征函数,试图挖掘语句内部以及标注对象的语法、语义等特点,这种方式更多地依赖于特征和特征模板的选择。随着深度学习的发展,神经网络模型在解决传统自然语言处理任务中取得显著效果。神经网络模型以其强大的提取特征能力,避免了人工定义特征模版对准确性的影响。通过调研序列标注中常见的深度学习模型,最终采用能够捕捉序列中长距离上下文依赖和字符级特征的BiLSTM-CNN-CRF模型[11]作为本次实验的基础模型。长短期记忆模型(Long Short Term Memory, LSTM)是一种循环神经网络(Recurrent Neural Network, RNN),改进了RNN模型存在的梯度消失问题,用一个记忆单元替换RNN中的隐层节点。记忆单元由记忆细胞、输入门、遗忘门和输出门组成,记忆细胞主要负责记忆长时间的依赖关系,这种特殊结构可以捕捉长远的上下文信息,非常适合对基于上下文的序列数据建模。单纯的LSTM模型对句子建模时遵循从前到后的顺序,无法捕捉从后到前的信息特征,故选择双向BiLSTM以更好地捕捉前后完整的序列信息。
本文采用的基础模型BiLSTM-CNN-CRF整体框架如图1所示,由词嵌入结合字符表示作为模型的输入层,经过双向LSTM编码后,得到每个词所有标签的概率值,CRF层利用LSTM的输出以及转移概率矩阵作为输入,采用动态优化算法获得全局最优的输出序列即解决最终标签预测。
图1
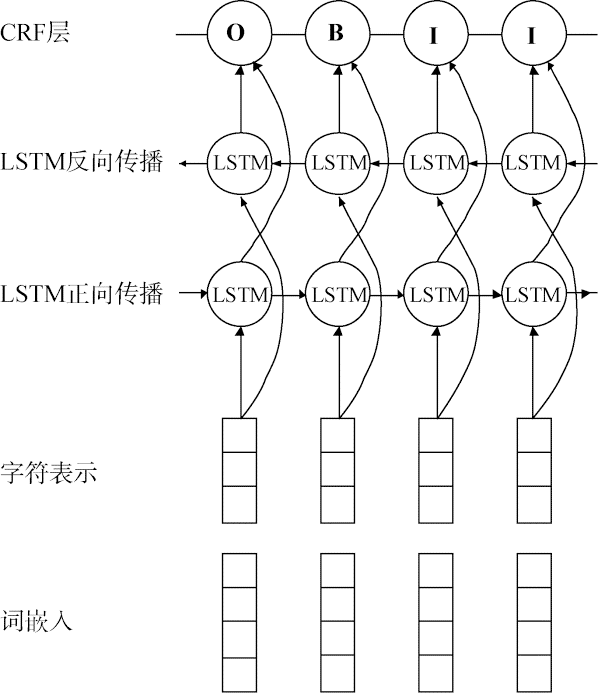
模型中的字符表示层主要任务为抽取字符局部特征,例如字母大小写、前后缀等。字符表示由卷积神经网络CNN训练得到,句中单词的每一个字符通过卷积层提取数据局部特征,通过最大池化层决定保留最具有代表性部分作为特征向量,如图2所示。字符级特征在实体识别领域有很好的辅助效果,因此引入CNN训练单词中每个字符的字符表示。
图2

3.2 特征选择与表示
深度学习方法的优势在于无需特征工程,由模型自身复杂的结构完成句子级特征提取工作,但研究表明,人工特征的加入可以进一步提高模型准确性[22]。
本文在深度学习模型的基础上,融合术语型引用对象的语言学特征和启发式特征,研究这两类特征对引用对象识别的效果。术语型引用对象特征表示如图3所示,在BiLSTM的输入层分别融合了词特征向量、字符特征向量、词性特征向量、位置特征向量和标识词特征向量共计5种特征向量,增强引用对象的特征表示。基于此,引用句被表示为多元特征矩阵,再利用BiLSTM神经网络学习序列特征以及上下文语义依赖关系,使得模型对引用对象有更好的理解,进而提高预测准确性。
图3

(1) 语言学特征
语言学特征是指术语型引用对象在语言表达上具有的特点,主要包括词、字符以及词性三个特征。
① 词特征
② 字符特征
为捕捉到更多单词本身的特征,例如大小写、前缀后缀和拼写规律等,训练字符级别特征
③ 词性特征
通过对引用对象的特征分析可以发现,术语型引用对象往往是名词或名词短语,并且具有一定词语搭配特点,如跟在动词、介词或介词短语之后,综合考虑加入词性特征
(2)启发式特征
在引用对象特征分析中发现,引用标签在引用对象判断时具有重要指示作用,术语型引用对象与引用标签距离也具有一定特点。鉴于此,本文提出两种启发式特征并观察其在该任务中的有效性。
① 标识符特征
无论引用标签在引用句中是否承担句法成分,引用标签作为引用对象识别的触发词和切入点,对引用对象识别起到一定的标识作用,故选取引用标签记为特征
② 位置特征
通过观察术语型引用对象特征发现,引用对象常常出现在引用标签附近,即引用标签附近的词或词语成为引用对象的概率较大,位置特征可以帮助模型更好地捕捉全局特征,同样采用随机初始化的方式,维度为20,表示为
通过上述特征描述,建立词向量、字符向量、引用标签向量、位置特征向量、词性向量5种不同描述角度的特征向量,对不同特征向量直接拼接,拼接顺序为词向量、字符向量、词性向量、位置向量和引用标签向量,向量维度为100+30+20+20+20=190维,表示为
3.3 伪标签学习
图4

伪标签学习中比较关键的问题是如何降低伪标签带来的噪声问题,如何有效降低伪标签噪声进而最大化利用廉价的未标注数据提升模型效果。由于本文采用的训练数据是随机采样获得的引用句,并没有预先经过人工判断,所以数据集中包含所有类型的引用对象。对于术语型引用对象识别任务来说,事实型引用对象和不含有引用对象的引用句会极大地影响模型训练效果,所以考虑从训练前和训练后两个方面联合限制伪标签数据带来的噪声。
噪声控制策具体略设计如下:对于无标签引用句集合
在伪标签学习过程中主要依靠选择候选术语型引用句结合,限定伪标签采样规则和模型预测效果联合控制伪标签带来的噪音,当伪标签带来严重噪音导致模型预测能力下降时,去除这部分伪标签回溯到上一模型状态,继续迭代训练。通过不断的伪标签学习,改进训练数据集不足的问题,提高模型的泛化能力。
4 实 验
4.1 实验数据及预处理
由于目前引用对象识别暂无公开语料,本文随机选取计算机语言协会数据集(Association for Computational Linguistics Anthology Network,ANN)[27]为基础数据,采用人工标注引用对象的方法获得基础训练数据。搭建轻量级在线标注工具BRAT( http://brat.nlplab.org/.),邀请两位图书情报领域研究生根据标注规范对引用对象进行标注。为检验标注一致性,采用Fleiss Kappa指标计算两位标注人员的标注一致性。Kappa系数是一个被广泛使用的一致性评价机制,其计算方法如公式(1)所示。
其中,P0为标注结果实际一致率,Pe为标注结果理论一致率。
随机选取5篇文献供两位标注者共同标注,对标注结果做交叉检验,结果显示Kappa一致性为0.51。根据Fleiss Kappa指标分布区间,Kappa大于0.75时已经取得相当满意的程度,小于0.40表示一致性差。Kappa值显示本次标注结果达到一个相对可靠的一致性水平。通过对比标注结果和与标注人员进行沟通,标注人员能够判断引用对象基本范围,但有些引用对象的边界存在差异,这是一致性指标不高的主要原因。通过人工标注最终构建术语型引用对象训练数据2 438条,未标注引用对象的引用句12 872条。
数据预处理阶段主要完成以下几项工作:
(1)对引用句中的引用标签进行规范化处理,根据论文遵循的哈佛引用格式标准,编写正则表达式匹配引用标签,使用“REF+文中参考文献序号”标签替代引用标签对数据对引用句进行预处理,如例1所示。既避免年和作者姓对分析带来的影响,又保留了引文在原文中的对照,为科研评价应用奠定基础。
例1: The DSO corpus (Ng and Lee,1996) contains 192,800 annotated examples for 121 nouns and 70 verbs, drawn from BC and WSJ.
转换为:The DSO corpus REF13 contains 192,800 annotated examples for 121 nouns and 70 verbs, drawn from BC and WSJ.
(2)对引用句进行词性标注、引用标签标注、位置标注和序列标注标签标注,其中词性通过斯坦福大学提供的Stanford CoreNLP工具[28]获得;引用标签采用0,1标记,将引用句中的引用标签标记为1,其他词汇标记为0;位置特征采用数值标注,计算引用句中每个词语与引用标签的绝对距离,例如引用标签本身为0,左右第一个词均为1,左右第二个词均标记为2,以此类推;序列标注标签采用{B,I,O}标签格式,将引用句中的每个词标注为B-CIT、I-CIT和O,B-CIT表示引用对象的首词,I-CIT表示引用对象的中间词,O表示不属于引用对象的词,标注实例如例2所示。当引用句中存在多个引用对象与引文时,每次只标注一篇引文及其引用对象。标注后的实验数据遵循CoNLL2003命名实体识别任务[29]格式要求。
例2: REF6 describes a movie recommender system MadFilm where users can use speech and pointing to accept recommended movies.
标注为: REF6/NN/1/0/O describes/VBZ/0/1/O a/DT/0/2/O movie/NN/0/3/O recommender/NN/04/O system/NN/0/5/O MadFilm/NNP/06/B-CIT where/WRB/0/7/O users/NNS/0/8/O can/MD/0/9/O use/VB/0/10/O speech/NN/0/11/O and/CC/0/12/O pointing/VBG/0/13/O to/TO/0/14/O accept/VB/0/15/0 recommended/VBN/0/16/O movies/NNS/0/17/O.
4.2 实验过程
为观察不同特征以及不同特征的组配方式对识别效果的影响,在实验过程中对词向量、字符向量、词性向量、引用标签向量、位置向量5种特征分别进行组配实验,有效对比特征选择的有效性和必要性。根据抽样法将数据按80%、10%、10%的比例随机划分为训练集、验证集和测试集,每次伪标签数据所占比例不超过标签数据的十分之一。
为避免算法过度拟合造成的识别结果不准确问题,实验过程中引入三种防止过拟合机制,分别为Dropout、L2正则、提前停止(Early Stopping)。Dropout机制设置Dropout使网络训练中以一定概率随机丢失神经节点,避免模型过于依赖局部特征,从而提高模型泛化能力。L2正则在目标函数后加入L2正则化项,使训练得到的权重变小,从而降低网络复杂度,避免过拟合。提前停止训练条件为,循环100次或当验证集的Loss在5次循环之内均不再下降。模型效果测评采用国际标准测评工具Conlleval。
实验时,根据本文所提特征表示规则,将引用句中每个单词拼接为190维向量,输入BiLSTM-CNN-CRF模型进行训练,实验中使用的某些参数的值如损失函数、优化器、学习率、LSTM层数等在不同任务的神经网络模型训练中会有所不同,最终参数选择是通过结合已有研究的经验以及实验过程中多次调参结果,如表1所示,其余神经网络参数如权重矩阵w和偏置b随机初始化,在神经网络训练时随之优化。
表1 参数说明
Table1
| 训练参数 | 值 |
|---|---|
| LSTM层数 | 2 |
| 神经单元数量 | 100 |
| 学习率 | 0.015 |
| Dropout率 | 0.5 |
| 损失函数 | 交叉熵损失函数 |
| Batch_size | 10 |
| 优化器 | Adam |
| L2(权重衰减率) | 1.0e-8 |
| Char_max_len | 20 |
| 卷积核大小 | 3*3 |
| 卷积核数量 | 30 |
| 句子最大长度 | 300 |
4.3 实验结果与分析
采用准确率(Precision)、召回率(Recall)和F1值对加入不同特征的模型识别效果进行评测,计算方法如公式(2)-公式(4)所示。
各种特征组合在测试集上的测试结果如表2所示。
表2 各种特征组合在测试集上的测试结果
Table 2
| 模型-特征 | Precision | Recall | F1 |
|---|---|---|---|
| BiLSTM-CNN-CRF(Baseline) | 25.57% | 8.17% | 12.38% |
| BiLSTM-CNN-CRF(POS) | 30.43% | 15.26% | 20.33% |
| BiLSTM-CNN-CRF(POS+REF) | 60.42% | 49.15% | 54.21% |
| BiLSTM-CNN-CRF(POS+DIS) | 61.18% | 51.07% | 55.67% |
| BiLSTM-CNN-CRF(REF+DIS) | 61.71% | 56.02% | 58.73% |
| BiLSTM-CNN-CRF(POS+REF+DIS) | 62.96% | 57.63% | 60.18% |
| BERT | 52.13% | 51.55% | 51.94% |
(注:POS表示词性特征,REF表示引用标签特征,DIS表示位置特征。)
作为Baseline的BiLSTM-CNN-CRF模型识别效果较差,证明对于表达形式灵活多变的引用对象,仅靠字向量和词向量特征无法达到识别要求,同时说明本文所提融合人类知识特征的识别方法的必要性。在词性、引用标签和位置三个特征中,词性特征结合位置特征或引用标签特征时,模型效果相似,但加入引用标签特征和位置特征时模型F1值达到58.73%,比其他两种特征组合提高3-4个百分点,说明两个启发式特征对模型效果的提升起到了主要作用,分析原因不难发现术语型引用对象经常出现在引用标签附近,引用标签和位置两个特征帮助模型在建模时更好地捕捉这一特征。当模型融入所有人工特征时,F1值达到最佳水平60.18%,说明语言学特征和启发式特征在模型中能够显著提高模型效果,具有不可替代的作用。证明了本文所提人工特征融合方法对术语型引用对象识别任务的有效性。
为进一步验证本文识别方法的效果,与BERT(Bidirectional Encoder Representation from Transformers)[19]模型进行对比。本文所提多特征融合方法比单纯使用BERT模型的识别效果F1值提升8.24%,说明增强特征表示的方法有助于提高模型效果。反过来看,BERT在没有添加任何额外特征的情况下,模型的学习能力惊人,远超BiLSTM-CNN-CRF模型。
对识别结果进行分析,观察预测结果发现,存在引用对象遗漏和错误识别的情况,并且在同时预测多个引用对象时,尤其是句子较长且引用多篇论文时,会遗漏句子尾部的引用对象,另外识别出现一个引用对象被拆分造成表述不完整的情况,模型预测差异实例如表3所示。模型预测错误可能有两方面原因:
表3 标注结果与预测结果差异实例
Table3
| 预测模型 | 预测结果 |
|---|---|
| BiLSTM-CNN-CRF(POS+REF+DIS) | We have adopted the Conditional Maximum Entropy (MaxEnt) modeling paradigm as outlined in REF3 and REF19 |
| To quickly (and approximately) evaluate this phenomenon, we trained the statistical IBM word-alignment model 4 REF7, using the GIZA ++ software REF11 for the following language pairs: Chinese-English, Italian-English, and Dutch-English, using the IWSLT-2006 corpus REF23 for the first two language pairs, and the Europarl corpus REF9 for the last one. | |
| In computational linguistic literature, much effort has been devoted to phonetic transliteration, such as English-Arabic, English-Chinese REF5, English-Japanese REF6 and English-Korean. | |
| Tokenisation, species word identification and chunking were implemented in-house using the LTXML2 tools REF4, whilst abbreviation extraction used the Schwartz and Hearst abbreviation extractor REF9 and lemmatisation used morpha REF12. |
(注:表中蓝色表示人工标注引用对象,红色表示预测错误的引用对象,绿色表示正确预测的引用对象范围。)
(1)训练数据的标注中缺少某些引用对象标注数据,导致模型学习效果有限,无法遍历所有引用句语言模式;
(2)词性特征的捕捉能力有限,比较明显的问题如有些名词词块型引用对象的识别边界错误,可尝试加入外部知识词典如IEEE术语词典[30]的形式,提高引用对象识别的完整性。
5 结 语
本文探索了术语型引用对象自动化识别方法,提出基于特征融合的神经网络模型识别方法,利用语言学特征和启发式特征增强引用对象特征表示,设计伪标签学习噪音控制机制解决引用对象标注数据不足问题,通过实验证明了本方法的有效性。
虽然本方法有效地探索了术语型引用对象自动化识别问题,但对标其他自然语言处理任务模型F1值较低,存在预测结果错误和漏预测情况,距离模型大规模的应用仍有一段距离。未来工作可以从特征和模型两方面进一步探索研究:
(1)特征方面,尝试增加引用句中单词或词组是否在引文原文出现特征、语块特征和外部知识库特征,增强对引用对象及其边界的识别准确度;
(2)模型方面,由于半监督学习对标注语料仍存在一定依赖,未来识别模型可向无监督学习方向发展,降低对语料的依赖性,增强方法的可移植性,例如集合单篇引文的全部引用句,加入深度语义分析和语言模式识别策略,抽取与引文内容相关的关键术语或关键短语,从不同方向探索引用对象自动识别方法,提高识别性能。
作者贡献声明
马娜:提出研究思路,设计研究方案,进行特征融合实验,起草并修改论文;
张智雄:优化研究方案及论文最终版本修订;
吴朋民:进行BERT实验,参与论文修改。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据
支撑数据由作者自存储,E-mail:mana@mail.las.ac.cn。
[1] 马娜. citobjdata_train.txt. 术语型引用对象训练数据集.
[2] 马娜. citobjdata_test.txt. 术语型引用对象测试数据集.
参考文献
Content-based Citation Analysis: The Next Generation of Citation Analysis
[J].
全文本引文分析——引文分析的新发展
[J].
Citation in Full-text:The Development of Citation Analysis
[J].
Cited Documents as Concept Symbols
[J].
Scientific Paper Summarization Using Citation Summary Networks
[C]//
Citation Summarization Through Keyphrase Extraction
[C]//
Content Models for Survey Generation: A Factoid-Based Evaluation
[C]//
What Have Scholars Retrieved from Walsh and Ungson (1991)? A Citation Context Study
[J].
Exploring Automatic Citation Classification
[D].
科技论文引用中的观点倾向分析
[D].
Sentiment Orientation Analysis for Evaluation Information of Citation on Scientific & Technical Paper
[D].
Reference Terms Identification of Cited Articles as Topics from Citation Contexts
[J].
End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF
[C]//
A Neural Probabilistic Language Model
[J].
Learning Character-Level Representations for Part-of-Speech Tagging
[C]//
Attending to Characters in Neural Sequence Labeling Models
[C]//
理论术语抽取的深度学习模型及自训练算法研究
[J].
A Deep Learning Model and Self-Training Algorithm for Theoretical Terms Extraction
[J].
ERNIE: Enhanced Language Representation with Informative Entities
[OL].
Deep Active Learning for Named Entity Recognition
[C]//
Hybrid Semi-Markov CRF for Neural Sequence Labeling
[OL].
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
[OL].
Nymble: A High-Performance Learning Name-finder
[C]//
Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data
[C]//
DM_NLP at SemEval-2018 Task 8: Neural Sequence Labeling with Linguistic Features
[C]//
Glove: Global Vectors for Word Representation
[C]//
Pseudo-Label: The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks
[C]//
Naive Semi-supervised Deep Learning Using Pseudo-label
[J].
Maximum Likelihood from Incomplete Data via the EM Algorithm
[J].
The ACL Anthology Network Corpus
[J].
The Stanford CoreNLP Natural Language Processing Toolkit
[C]//
Introduction to the CoNLL-2003 Shared Task: Language-Independent Named Entity Recognition
[OL].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}