




1 引 言
随着学术资源的电子化与爆炸式增长,文献自动标引的重要性不言而喻,科学、规范的标引词,有助于提升检索效率,从而促进学术成果的传播、交流与利用。按照标引词的来源,文献标引可分为赋词标引和抽词标引:赋词标引采用主题词或叙词组织、表示文献的主题概念[1],对标引人员的专业技能要求较高;抽词标引则是从文献中抽取关键词,但考虑到作者使用的关键词所包含的信息量较少,自动标引源亦可来自题名、摘要、引文和首尾章节。标引和检索是两个互为因果的逆过程[2],学术资源检索系统相应地提供了不同的主题、题名、关键词等检索入口,如Web of Science提供的主题(Topic)检索入口包含题名、摘要、作者关键词(Author Keywords)和附加关键词(Keywords Plus),其中附加关键词[3]是通过Garfield提出的引文标题关键词法[4]从引文集合中抽取出来的词或短语,而中文数据库尚无附加关键词字段。倒排索引是匹配检索词和标引词的关键环节,由于检索词与用户需求相关,形式多样且不可控,因此索引术语的质量评估大多从标引词的角度出发。
本课题组在TDM的基础上提出更稳定的术语区分能力(Term Discriminative Capacity, TDC),并应用于索引术语的质量评价,然而在术语抽取环节发现了问题:篇名和摘要在语义上具有连贯性,需要在分词和去除停用词后抽取术语;而大部分关键词是短语结构,那么是直接把逗号分隔的关键词作为术语,还是与篇名和摘要的处理方式保持一致?不同的术语粒度会对实验结果产生怎样的影响?鉴于以上问题,本文以中文社会科学引文索引(CSSCI)收录的论文作为实验对象,比较不同字段的中文术语粒度对其区分能力测度的影响,探究中文学术论文数据库中标引源和标引颗粒度的重要性。
2 相关研究
Luhn[7]早在1957年就开始自动标引的相关研究,将计算机技术引入文献标引,开创了以词频为特征加权的自动标引法;20世纪90年代,全文索引被广泛应用且能基本满足用户的检索需求;但随着信息爆炸时代的来临,全文索引的功能难以满足用户日渐精确的检索需求,抽词标引成为信息检索领域的重要研究方向,也产出了丰富的研究成果,从方法论的角度可划分为语言分析(词法分析[8]、句法分析[9]、语义分析[10]、篇章分析[11]等)和统计学习(简单统计[12]、一般机器学习[13]、深度学习[14]等)两大类。但是,自动标引研究仍存在一些亟待解决的问题:影响标引质量的一个重要方面是选择标引源,题名和关键词的信息量偏少,可引入摘要作为补充,全文扫描则存在数据量大和截取词汇多的问题,有研究把首尾章节或章节的首尾段也作为标引源[15];文献自动标引中存在的另一个普遍问题是标引颗粒度,一般来说,特异性较强的词适合作为关键词,但特异性越强则越专指,在信息检索的实际应用中,使用过于专指的词作为检索入口,查全率将不甚理想,且增加了构建索引的难度;除此之外,如何构建自动标引的评价指标以减少专家评价的成本与主观性[16],也具有较高的研究价值。
综上所述,针对标引源的确立、标引颗粒度和标引结果评价等文献自动标引中存在的问题,本文将TDC测度应用于不同标引源的术语质量评估,从检索的角度比较中文术语粒度对其区分能力测度的影响,也为文献的标引结果评价提供一种定量的参考方法。
3 数据与方法
3.1 研究框架
为探究中文术语粒度对其术语区分能力测度的影响,本文设计研究框架如图1所示。在一定的学科和时间范围内,每个学科随机采样等量文献,并从文献著录项中抽取题名、关键词、摘要,而附加关键词则采用基于条件随机场(CRFs)的方法从文献的引文集合中抽取;其中,题名和摘要在语义上具有连续性,需要进行分词和去除停用词,而大部分关键词和附加关键词是短语,如果与题名和摘要字段保持一致的术语粒度(词),可以得到不含短语的术语库,作为实验组,也可以保留原有的短语结构,作为对照组的术语库;基于本文提出的TDC测度,计算术语库内所有术语的TDC值;这些术语可能来自不同的学科和字段,且存在大量交叉,最后使用方差分析(Analysis of Variance, ANOVA)[23]对不同组别的TDC值进行差异性检测,由于本文探讨的是术语粒度和来源字段对术语区分能力的影响,所以以字段为组别,特别观察关键词与附加关键词在实验组与对照组中的表现。
图1

3.2 数据来源与预处理
鉴于CSSCI是受到学术共同体广泛认可的人文社会科学引文索引,本文从CSSCI(2013-2014)中选取具有代表意义的学科,包括哲学、历史学、经济学、社会学和图书馆、情报与文献学,获取以上学科期刊的科技文献作为实验对象,其中哲学与历史学是人文类学科,经济学与社会学则属于社会科学范畴,而图书馆、情报与文献学是典型的交叉型学科。
表1 各学科的文献与有效记录情况
Table 1
| 序号 | 学科 | 学科简称 | 文献 检索数 | 有效 记录数 | 有效 百分比 | 学科类型 |
|---|---|---|---|---|---|---|
| 1 | 哲学 | PHI | 8 160 | 3 861 | 47.32% | 人文 |
| 2 | 历史学 | HIS | 7 341 | 3 624 | 49.37% | 人文 |
| 3 | 经济学 | ECO | 34 255 | 19 149 | 55.90% | 社科 |
| 4 | 社会学 | SOC | 4 622 | 2 268 | 49.07% | 社科 |
| 5 | 图书馆、情报与文献学 | LIS | 10 285 | 6 440 | 62.62% | 交叉 |
考虑到大规模数据可能会导致维度灾难,同时为保证各学科的术语比例均衡,因此只在各学科抽取200条文献记录,总计1 000条。实验组数据采用NLPIR[25]汉语分词系统对文献记录的所有字段进行分词,并结合停用词表(哈尔滨工业大学停用词表、四川大学机器智能实验室停用词库、百度停用词表),去除非中文字符串、停用词和无实际检索意义的虚词,得到术语库;在对照组中则保留了关键词和附加关键词中的短语结构。
3.3 TDC的测度算法
借鉴词袋模型的思想,利用文档库和术语库构建术语空间(Term Space, TS),循环抽取单个术语,通过计算所有术语与术语空间中心的平均相似度的变化度量该术语的区分能力,TDC的具体计算过程如下:
(1)构建文档-术语矩阵(Document-Term Matrix, DTM),DTM是一个m×n维的不对称0-1矩阵,在一定范围内文档数量m将会远小于术语数量n,DTM[i][j]表示术语j是否在文档i中出现过;转置DTM矩阵,得到术语-文档矩阵(Term-Document Matrix, TDM),矩阵的每一行是一个术语向量;再用术语向量的余弦相似度描述术语向量,转换为术语-术语矩阵(Term-Term Matrix, TTM),TTM是一个n×n维的对称矩阵,即n维术语空间。
(2)计算术语空间的密度(Term Space Density,TSD),TSD在这里定义为TS内所有术语到术语空间中心Centroid的平均距离,术语Ti到Centroid的距离如公式(1)所示。
其中,Dist使用的是欧几里得距离。
依次从术语空间中抽取出术语Ti,得到n-1维的术语空间TSn-1,重新计算新术语空间的密度TSDi,如公式(2)所示[19]。TSDi越大,则说明该术语空间内的术语分布越分散,区分度越好。
笔者对Salton等[19]提出的TDV计算公式做出改进,通过计算术语空间密度的变化,衡量术语的区分能力,记作TDC,计算方法如公式(3)所示。经过标准化处理后,若TDCi为正值,说明术语Ti在该术语空间内起积极区分作用;相反,若TDCi为负值,那么认为该术语有消极区分作用;若TDCi为零,则认为该术语对文档区分几乎没有影响。
其中,TSDavg是术语空间的平均密度差,计算方法如公式(4)所示。
4 实验结果及分析
4.1 各字段的术语数量与粒度比较
表2 字段符号及其简称
Table 2
| 字段(Field) | 编号 | 简称 |
|---|---|---|
| 题名 | 1 | TI |
| 摘要 | 2 | AB |
| 关键词 | 3 | KW |
| 附加关键词 | 4 | KP |
表3 术语数量的统计情况(单位:个)
Table 3
| 组别 字段 | TI | AB | KW | KP | All |
|---|---|---|---|---|---|
| 对照组 | 2 772 | 8 997 | 3 294 | 7 986 | 18 891 |
| 实验组 | 2 772 | 8 997 | 2 693 | 5 188 | 11 173 |
可以看出,术语数量与来源字段的篇幅长短相关。来自AB的术语数量最多,无论是指示型、结构型还是综述型摘要,都是篇幅较长的文摘,所以抽取出的术语较多;其次是KP字段,据中国科学技术信息研究所的统计,中国科技期刊在2013和2014年的篇均引文数分别为15.9和17.1[26],引文集合的关键词多于单篇文献的关键词,因而从附加关键词中抽取的术语多于关键词术语;此外,TI在对照组中术语数量最少,而实验组中KW的术语数量最少。通常情况下,中文学术文献的篇名不超过25个字,有3-8个关键词,关键词短语的特异性较强,如“信息检索方法”与“信息检索策略”这两个不同的关键词具有相同的语义,因而KW在对照组中的术语数量多于TI,但当关键词短语被切分为粒度更细的词语时,即新术语为“信息检索”、“方法”和“策略”,这些词语更为普遍,去重后得到的KW术语数量减少。整体来看,这4类术语之间存在部分交叉,术语总数量也大幅度减少。
此外,不同来源的术语在粒度上也存在明显差异。两组实验的术语平均长度变化如表4所示,对照组的术语平均长度为3.31,来自KW和KP的术语多为组合短语,其平均长度明显大于来自TI和AB的术语,最长的术语来自于KP字段,有15字之长,如“国家人口与健康科学数据共享平台”,KW的最长术语有12字,如“改革开放前后两个历史时期”和“应计制与真实活动盈余管理”,除人名、机构名、历史事件名等实体名称外,这类关键词过于专指,在实际信息检索中的查全率不甚满意,在语义上完全有进一步切分的必要;而在实验组中,术语平均长度为2.06,各字段在术语粒度上普遍更短而无明显差异,AB字段的术语粒度略大。
表4 术语平均长度的统计情况(单位:字)
Table 4
| 字段 | TI | AB | KW | KP | All |
|---|---|---|---|---|---|
| 对照组 | 1.94 | 2.05 | 4.11 | 4.37 | 3.31 |
| 实验组 | 1.94 | 2.05 | 1.95 | 1.95 | 2.06 |
基于以上统计,将4字以上的术语记为“长术语”,而4字及以下的记作“短术语”,两组实验的短术语比例变化如图2所示,可以发现,实验组中各字段的短术语比例大致相等,而对照组的差异较大。
图2
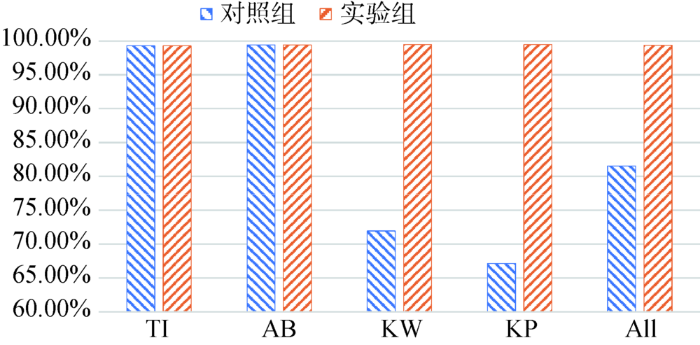
以上术语数量和粒度上的变化可以说明,当直接以KW和KP作为术语时,通常比一般词语形式的术语更长,相同语义的短语可能有不同的组合方式,因此对照组在术语数量上大于实验组;实验组得到的大部分是4字及以下的短术语,消除了短语之间的语义交叉,长术语比例随之降低,术语总数量相应减少。但是这会对术语的区分能力测度产生怎样的影响,下文将采用ANOVA分析进一步探讨。
4.2 各字段的中文术语区分能力比较
实验数据共涉及5个人文社会科学学科,考虑学科的影响因素,以术语的来源字段为自变量,从部分到整体依次对单学科和所有学科的术语的TDC值进行One-way ANOVA和Two-way ANOVA分析,通过比较两次实验结果之间的差异,探究中文术语粒度对不同字段的术语区分能力的影响。
(1) 对照组
在对照组的数据处理过程中,直接以完整的关键词和附加关键词作为术语,这类术语的粒度大,特异性较强。在微观层面上,每个术语在术语空间内可能具有不同程度的区分能力,笔者绘制TDC散点图如图3所示,x轴表示按照TDC值升序排列后的术语序号,y轴表示术语的TDC值。可以发现:
图3
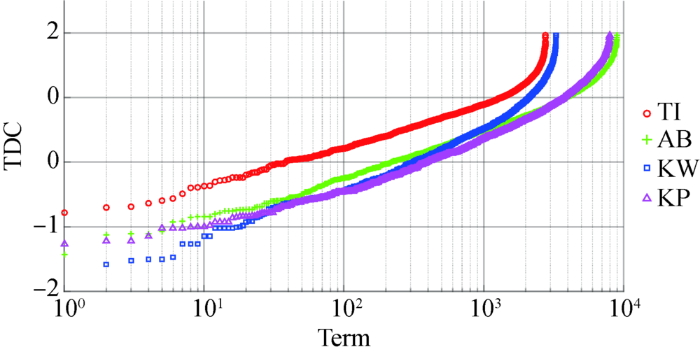
①TI字段的术语数量最少,且其术语区分能力普遍较强;
②AB字段的术语数量最多,其术语的TDC值分布较广,既包含大量区分能力强的术语,也有部分区分能力弱的术语;
③区分能力较弱的术语主要来自KW和KP字段。
图4
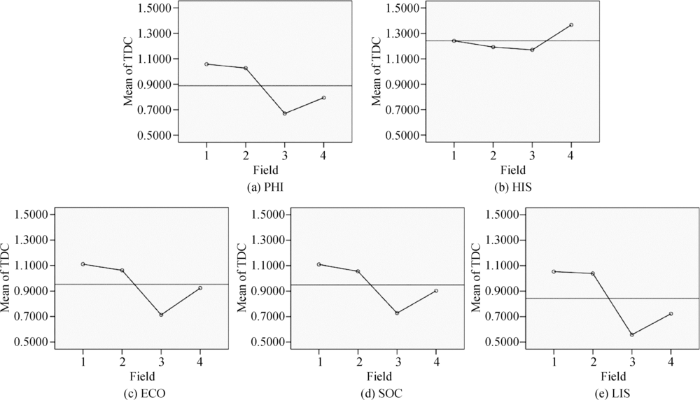
图4
字段的One-way ANOVA均值折线图(对照组)
Fig.4
Line Plots of One-way ANOVA Mean of TDC and Filed (Control Group)
①学科HIS的TDC均值参考线明显高于其他4个学科,而LIS的TDC均值参考线最低,考虑到LIS是典型的交叉型学科,这在很大程度是由于HIS与其他4个学科在2013-2014年的研究内容上存在较少交叉;
②除学科HIS外,ECO、SOC、PHI和LIS的TDC均值图走势相同,字段间的排序依次是TI>AB>KP>KW,TI字段的术语区分能力最强,AB字段次之,而KW和KP字段的TDC均值都低于其学科的平均值,尤其是KW字段表现出最弱的术语区分能力;
③在学科HIS中,各字段在TDC均值上的差异较小,排序依次是KP>TI>AB>KW,KP字段的表现优于TI和AB,而KW字段的术语区分能力同样最弱。
综上,除KP字段外,TI、AB和KW字段的TDC均值在以上学科中的相对排序是一致的,尽管这三者都是由作者给出,但TI和AB字段的术语粒度为字或词,而KW字段的术语粒度多是短语。关键词短语具有很强的主观随意性,有时候甚至伴随着不准确、不规范的问题,因而在选择标引词时,来自TI和AB字段的术语比未经处理的关键词更能揭示文献的内容。附加关键词作为关键词的补充,是基于一定规则从参考文献集合中筛选、抽取出来的,在整体的丰富性和规范性上优于关键词,因此在术语粒度同为短语的情况下,附加关键词比关键词更适合作为标引词,亦可作为检索入口。
(2) 实验组
在实验组中,各字段的术语抽取策略保持一致,关键词与附加关键词的切分粒度为词,术语粒度更细。TDC-Number散点图如图5所示,由于绝大部分术语在单字段内出现的次数(Number)不超过100,因此x轴取0-100,y轴表示术语的TDC值。
图5
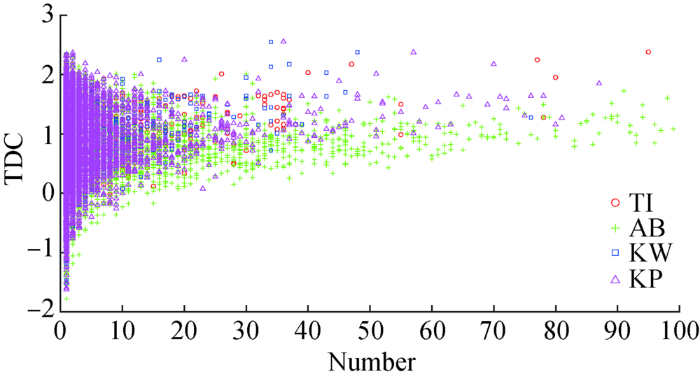
图5
字段的TDC-Number散点图(实验组)
Fig.5
Scatter Plot of TDC and Number by Filed (Experimental Group)
①术语的TDC值和词频无明显依赖关系,区分能力强的术语可能是高频词,亦可能是低频词;
②AB字段的术语数量最多,因而在高频词数量上也占有优势,从TDC值的分布来看,AB字段的术语区分能力普遍弱于其他字段;
③区分能力强的术语在各字段中皆有分布,但来源于KP字段的术语较多。
在学科层面上,同样对实验组术语的TDC均值进行One-way ANOVA分析,如图6所示,5个学科的4个字段呈现出不同的TDC均值走势。
图6
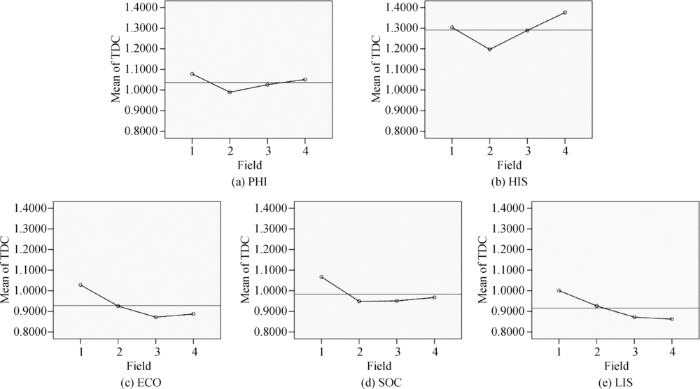
图6
字段的One-way ANOVA均值折线图(实验组)
Fig.6
Line Plots of One-way ANOVA Mean of TDC and Filed (Experimental Group)
①学科HIS的TDC均值仍明显高于其他学科,但区别于对照组的是,术语粒度为词的KW字段在区分能力上超过了AB字段,且非常接近TI字段的表现,KP字段的TDC均值仍高于其他字段;
②人文类学科PHI与HIS的TDC均值走势相似,KW字段在术语区分能力上也超过了AB字段但差距较小,PHI的KP字段的TDC均值略低于TI字段;
③社科类学科ECO和SOC在术语特征上比较相似,KW和KP字段在术语区分能力上的差异并不明显,但ECO在AB字段的TDC均值高于KW和KP;
④TDC均值最低的仍是学科LIS,在术语特征上与学科ECO更接近,TI字段的术语区分能力最强,AB字段次之,KW和KP字段的TDC均值相近。
KP字段来源于参考文献的关键词集合,理论上KW与KP字段在术语区分能力上的表现应该相似,但引文丰富的文献会抽取出比KW更丰富的KP,且未经处理的KW在规范性上不如KP,所以对照组中KW字段的TDC均值最小。但是在实验组中,不难发现,除学科HIS外,其他4个学科的KW和KP字段在TDC均值上趋近,这在很大程度上是因为KW字段的术语粒度更细且更加规范,其术语区分能力也相应提升,在学科PHI、HIS和SOC中的表现优于AB字段。
(3) 术语粒度的讨论
上文从微观和学科层面对字段的术语区分能力进行初步分析,为进一步从整体上讨论术语粒度对术语区分能力的影响,不区分学科类别,以来源字段为固定因子,术语粒度为随机因子,对实验组和对照组中所有术语的TDC值进行Two-way ANOVA分析,y轴表示TDC的预估边际平均值,如图7所示,两条曲线存在明显交叉,说明术语粒度对不同字段的术语区分能力存在显著影响。此外,对照组中KW和KP字段的TDC均值大幅度低于TI和AB字段,而实验组中KW和KP字段的术语区分能力明显高于在对照组中的表现,尤其是KW字段的TDC均值有大幅度增长,TI字段无明显变化,而AB字段的TDC均值相对对照组有小幅度降低。不难发现,由于KW字段在术语区分能力上的提升,各字段的TDC均值差距明显缩小,更接近理想状态下的自动抽词标引,即这4类字段都同样适合作为标引源和检索入口。
图7
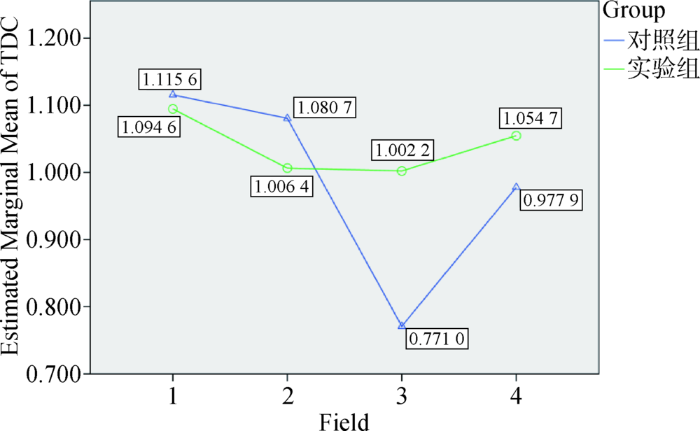
图7
字段与术语粒度的Two-way ANOVA折线图
Fig.7
Line Plots and Term Granularity of Two-way ANOVA Mean
CNKI提供的主题检索入口包含题名、摘要和关键词,另有专门的篇名、摘要和关键词检索入口;而Web of Science在检索页面提供了题名和主题检索入口,并未单独提供摘要和关键词检索入口,主题指的是题名、摘要、作者关键词和附加关键词,作者关键词即传统意义上的关键词(KW)。这从侧面反映出中英文索引术语的异同:
①无论是中文还是英文文献,TI在用词规范上的要求都更加严格,尽管信息量有限但能简短有力地揭示文献的主题内容,所以在通常情况下都优先以TI作为检索入口,且检索效率较高;
②由于大部分英文术语在语义上都是独立的词,来自TI、AB、KW和KP字段的术语在检索任务中的表现并无显著差异,都同样包含在主题检索入口内;
③考虑到中文术语的组合方式多样,未经语义切分或规范化处理的KW术语,在区分能力上与来自TI和AB字段的术语有较明显差距,在检索任务中可能会表现出不同的检索效率,一般来说,短语的查准率高而查全率低,以字词为检索词则查全率更高,因此不同字段对应着不同的检索入口;
④当术语粒度都统一为词时,各字段在中文术语粒度上无明显差异,在术语区分能力上的差距也相应缩小。
5 结 语
本文在面向学术资源的术语区分能力测度实验中发现,关键词与附加关键词在数量和粒度上与题名和摘要不同,在术语提取策略方面也存在差异,于是设计对照组与实验组实验,选取CSSCI(2013-2014)的期刊文献作为实验对象,探究中文术语粒度在学术资源检索系统中对不同字段的术语区分能力的影响,为科技文献自动标引中标引源的确立、标引颗粒度和标引结果评价方法提供参考:
(1)当以未经处理的关键词和附加关键词作为术语时,来自题名的术语具有最强的区分能力,最适合作为标引源和检索入口,摘要字段次之,而不建议直接使用作者给出的关键词作为标引词,附加关键词在丰富性、规范性以及术语区分能力上整体优于关键词,亦更适合作为标引源;
(2)当术语粒度都为词时,各字段在术语区分能力上仍存在差异但差距缩小,在选择标引源和检索入口时,术语区分能力最强的题名仍是首选,附加关键词次之,因此建议中文学术论文数据库向Web of Science学习,从参考文献中抽取附加关键词作为标引词的补充。
在有限的数据存储和计算能力下,本文只能选取部分学科的期刊文献并系统抽样,样本代表性可能存在不足。在TDC的后续研究中,如以学科为评价对象,可将各字段的术语粒度统一为词,以降低字段因素的影响。
作者贡献声明
熊欣:实验论证,论文撰写;
王昊:提出研究思路,设计研究方案;
张海潮:数据收集及预处理;
张宝隆:论文最终版本修订。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据
支撑数据由作者自存储, E-mail: mgxinxiong@smail.nju.edu.cn。
[1] 熊欣,张海潮.data.txt.期刊文献的题录和引文数据.
[2] 熊欣,张海潮.tdc_group1.dbf.对照组的TDC数据.
[3] 熊欣,张海潮.tdc_group2.dbf.实验组的TDC数据.
参考文献
社科学术论文中关键词的标引
[J].
The Mark of Key Words in Social Academic Articles
[J].
简论标引用词和检索用词的差别
[J].
A Brief Discussion on the Differences Between Indexing Words and Retrieval Words
[J].
索引工作自动化:自动标引的主要方法
[J].
Automation of Indexing: On the Major Approaches to Automatic Indexing
[J].
A Theory of Term Importance in Automatic Text Analysis
[J].
Automatic Text Processing: The Transformation, Analysis and Retrieval of Information by Computer
[M].
A Statistical Approach to Mechanized Encoding and Searching of Literary Information
[J].
中文全文标引的主题词标引和主题概念标引方法
[J].
Methods of Keyword and Subject Concept Indexing to Chinese Full-text
[J].
Improved Automatic Keyword Extraction Given More Linguistic Knowledge
[C]//
Using Lexical Chains for Keyword Extraction
[J].
Automatic Text Structuring and Retrieval-Experiments in Automatic Encyclopedia Searching
[C]//
Keyword Extraction from a Single Document Using Word Co-occurrence Statistical Information
[J].
Keyword Extraction Using Support Vector Machine
[C]//
Bidirectional LSTM-CRF Models for Sequence Tagging
[OL].
现代图书情报技术
[J].
On Automatic Indexing of Documents
[J].
现代图书情报技术
[J].
Review and Prospect of Automatic Indexing Research
[J].
Automatic MeSH Term Assignment and Quality Assessment
[C]//
Evaluation of Automatically Identified Index Terms for Browsing Electronic Documents
[C]//
On the Specification of Term Values in Automatic Indexing
[J].
On the Role of Words and Phrases in Automatic Text Analysis
[J].
An Algorithm for the Calculation of Exact Term Discrimination Values
[J].
Quality of Indexing in Online Databases: An Alternative Measure for a Term Discriminating Index
[J].
CRFs字角色标注方法在中文附加关键词抽取中的应用研究
[J].
Application of CRFs Chinese Character Role Labeling Method in Chinese Keywords Plus Extraction
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}