1 引 言
随着移动互联网的普及,越来越多的游客在社交平台上分享自己的旅游日志。记录旅游经历的游记蕴含着游客的旅行目的地、旅游路线、景点评价、旅行体验等历史行为信息,从中提取规则化表示,构建形成可读性较强的行程,有助于直观呈现游客的行程,也有助于相关平台实现自动目录构建、自动标题生成等应用。但是,由于游客发表游记的随意性,游记中出现的景点存在着重复性、时间不一致性及景点非相关性等特点。如何从游记中挖掘游客真正到访的景点,并按景点访问的先后次序自动化形成游客游览的真实轨迹,是一个值得深入研究的问题。
基于游记文本的行程重构,需要从游记文本中自动化识别行程的景点信息。游记中的景点关键词,表征游客的游览足迹,具有地理空间特征,蕴含着个人的旅游倾向和偏好。景点识别问题的本质是命名实体识别,主要分为基于规则的方法和基于统计的方法两大类[1 ] 。
(1)基于规则的方法,是从词本身的组成结构特征进行识别,例如“陕西历史博物馆”,该词是由代表区位的省份名“陕西”、代表主题的特征词“历史”和代表机构的关键词“博物馆”构成,根据这种特殊的构词规则就可识别出类似的景点。但是,对于那些命名无规则的实体,基于规则的方法会识别出拥有相同构词规则的无关实体。
(2)基于统计的方法,包括最大熵模型(Maximum Entropy Model, MEM)、隐马尔可夫模型(Hidden Markov Model, HMM)、决策树(Decision Tree)、条件随机场(Conditional Random Field, CRF)等。但是,这类方法训练集的实体需要标注,如果训练语料集数据规模大,则识别过程的工程量浩大。
有效景点自动化识别后,还需从游记中构建游客的真实游览轨迹,即游览行程的重构问题。然而,游客撰写游记往往不按旅游时间的先后次序,并且缺失游览的时间信息,这使得从社交平台上的自由文本中实现游客的真实游览行程的自动化重构变得困难。
围绕上述问题,文本提出一种基于社交媒体游记文本内容的游客行程构建方法。该方法分两个阶段实现游客真实游览行程的构建。在第一个阶段,针对上述景点识别问题,提出一种TF-IDF和Word2Vec相结合的基于本文相似度的自动化景点识别方法,该方法无需对训练集进行标注便可以批量自动化识别景点名称。在第二个阶段,针对缺少时间信息的行程重构问题,提出一个基于马尔可夫性、空间特征和统计模型相结合的行程重构模型,在缺失时间信息的情况下,实现游客游览行程的重构。
2 相关研究
20世纪70年代开始出现从文本数据中抽取表征用户行为的历史行程的相关研究。随着互联网的发展和自媒体时代的到来,网络上记录个人历史行程的文本数据呈指数级增长,这使得该项研究拥有了更多的数据支撑和现实价值。近年来,关于旅游领域的模式挖掘研究也日渐丰富,例如Phithakkitnukoon等[2 ] 针对日本国内的旅游数据挖掘出游客的出行规律和行程模式,分析旅游业存在的问题并给出有助于旅游业和游客的建议。Budig等[3 ] 提出一种从历史文本数据中提取行程的模型,该模型依赖于文本撰写的先后次序。由于网络自由文本形式的游记存在着景点的乱序性,该方法并不适用于解决本文的行程提取问题。Blank等[4 ] 针对路线重构提出一种基于编辑的解决方案。该方案由光学字符识别、路线解析、地名解析和路线查找4个步骤组成,在已知历史行程和兴趣点的前提下生成路线。本文的行程重构模型借鉴文献[4 ]的思想,从历史行程数据中构建统计模型作为先验知识。Blank等[5 ] 提出一种启发式方法,将路线中的地名与字符串距离、几何距离联系起来。该算法通过采用文本和地理空间的过滤器修剪待重构兴趣点的搜索空间,从而减少候选的行程。这种方法在实际应用中效果较好,但是缺少搜索优化目标,并且算法时间代价较大。
为降低算法的时间复杂度,从文本中提取关键信息必不可少。Adelfio等[6 ] 提出从电子表格和网页中识别和提取关键词的方法。本文的研究内容是从大量游记文本中重构行程,同样也需要提取蕴含地理信息的景点。因此,景点名称的识别和提取成为重构行程的关键前提。关于中文文本中命名实体识别的研究,已有较多方法和成果[7 ] ,但早期工作大多都是基于规则的方法或者基于统计的方法。张玥杰等[8 ] 提出一种融合多特征的最大熵模型,在语言无关的统计学方法基础上加入语言相关的规则,通过两者相结合的方式提高命名实体识别性能;康才畯等[9 ] 提出采用条件随机场(CRF)模型识别命名实体的方法;何炎祥等[10 ] 提出一种基于规则和条件随机场相结合的地理命名实体识别方法。这些方法均是基于统计学经典方法上的改进与应用,都需要在训练集的语料中进行大量标注工作,但是,对大量训练集进行实体标注是非常巨大的工程,费时费力,此外,如果是训练集没出现过的实体则无法识别。而张永富等[11 ] 利用自然语言处理中文本相似度的计算方法识别环境科学命名实体就显得省时省力。由于景点可能存在简称或者别名,所以本文采用基于文本相似性度量的方法实现景点名称的批量识别,该方法的优势在于:(1)无训练集和测试集的划分,即无需标注任何数据,大大降低了工作量;(2)可处理大批量的文本数据;(3)由于不依赖于训练集的实体标注,所以可识别出尽可能多的相关实体。
从游记中识别出景点后不足以重构行程,通常还需要考虑一些特征,比如景点的空间分布特征。Southall等[12 ] 根据先验知识和地理位置信息发现了新的历史学家和分布规律。在自然语言处理中,信息的空间分布特征常常被研究者忽略,但在空间人文学科中却高度相关[13 ] 。本文的行程重构模型借鉴该思想,在基于历史行程的统计模型基础上,加入地理位置特征。根据文本信息确定地理位置及进行地理编码是地理信息检索的热门研究领域。Melo等[14 ] 提出一种从文本数据中提取地理信息的方法。该方法表明为从文本中提取地理信息,就必须识别出蕴含地理信息的关键词,而这些关键词往往都是能够映射地理位置的实体。最后将提取出的实体与其蕴含的地理位置一一映射即可得到包含地理空间特征的实体。映射方法可以是包含地理位置的实体知识库,也可以是包含省市区等位置信息的数据库。然而,并非所有的实体都有现成的数据库,可自行构建包含这些实体的数据库。如此,实体的自动提取并赋予更多的特征就变得可行。例如,Khan等[15 ] 通过自行构造数据库的方法赋予实体更多特征,从而为重构行程提供了更多依据。由于景点信息的缺乏,本文借鉴上述思想构造景点信息库,从而对实体赋予地理空间信息。
识别并赋予空间信息后,接下来的工作便是重构旅游行程。行程重构问题与地图匹配问题有着一些相似之处。Newson等[16 ] 提出一种新的基于隐马尔可夫模型的地图匹配算法;Budig等[3 ] 构建一种加入空间特征的隐马尔可夫模型从文本数据中重构行程;Moncla等[17 ] 提出一种从带有注释或者标签的文本中构建行程的方法;Moncla等[18 ] 实现了从具有地理位置标签的远足文本数据中重构行程。无论采用何种方式,这些文献提出的方法都以马尔可夫性这一假设为前提。为降低模型的计算复杂度,本文同样基于一阶马尔可夫性构建模型。
上述方法或者思想,部分考虑了历史数据的统计概率模型、关键信息提取、空间特征、马尔可夫性等。由于网络自由文本自身的特点,从游记文本中提取游客的游览行程仅仅考虑部分因素是不够的。因此,本文首先从游记中提取景点这一关键信息,然后在行程重构中,基于一阶马尔可夫性,加入历史行程的统计模型和景点的空间特征,从而达到较好的行程重构效果。
3 方法设计
3.1 整体架构
本文提出的基于游记文本的游客旅游行程重构方法的架构如图1 所示。该方法分两个阶段,在第一阶段,采用基于文本相似度的方法自动化识别蕴含地理位置信息的景点;第二阶段,在满足一阶马尔可夫性的前提下,基于历史数据的统计模型和景点的空间特征构建模型,从而对游记的行程进行重构。其中,所需的游记和景点信息均来自马蜂窝旅游网站① (①https://www.mafengwo.cn/ .),并通过百度开放平台② (②http://lbsyun.baidu.com/index.php?title=webapi/guide/webservice-geocoding .)获取景点的位置信息。
图1
图1
游客行程自动化重构方法整体架构
Fig. 1
The Framework of Automatic Reconstruction Method of Tourist Itinerary
3.2 景点识别
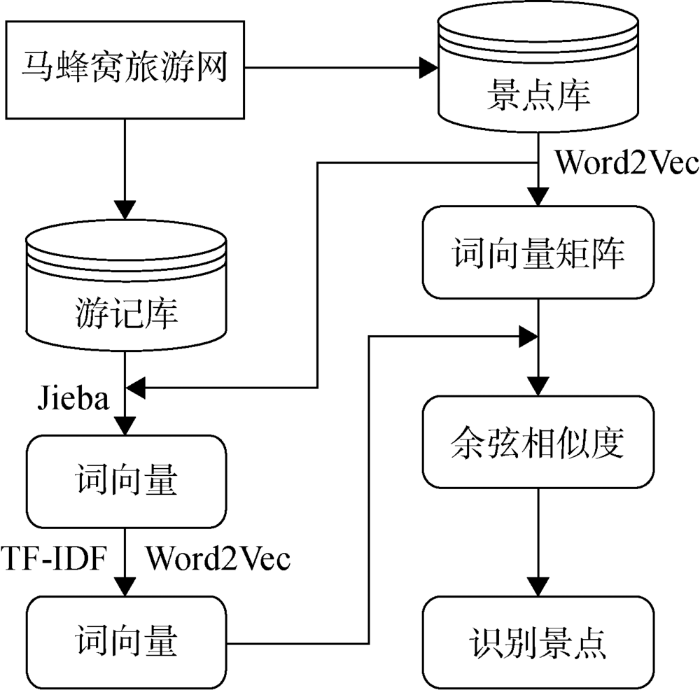
本文采用基于文本相似性的景点实体识别方法,对无标签的文本数据实现自动化识别景点。该方法结合TF-IDF和Word2Vec算法,利用爬取的景点信息,从大量游记中批量识别并提取景点。
图2
图2
景点识别技术路线
Fig.2
Technology Roadmap of Attractions Identification Method
其基本思路是:构造景点库,该库包含丝绸之路旅游的景点名称;以词频作为Word2Vec的输入将景点库中的所有景点转化为词向量矩阵;将景点库添加到分词库中对游记文本进行分词,并利用TF-IDF计算出分词的普遍重要性作为Word2Vec的输入,将每个分词转化为词向量并计算出与词向量矩阵中每一个向量的余弦相似度;最后,依据相似度识别出景点名称实体。
TF-IDF[19 ] 是一种基于统计的词的关键性计算方法,该方法计算词在当前文档的出现次数和出现过该词的文档数,如果该词在当前文档中出现的次数越多并且在其他文档中出现的次数越少,表明该词对于当前文档来说更具关键性。
游记中的每个分词 t i tf 如公式(1)所示。
(1) t f i = n i ∑ k n k
逆向文件词频 idf t i
(2) id f i = log | D | { d : t i ∈ d }
(3) tf - idf = t f i ⋅ id f i
其中, n i D n i ∑ k n k D | D | | { d : t i ∈ d } | t i
经过计算的 tf - idf
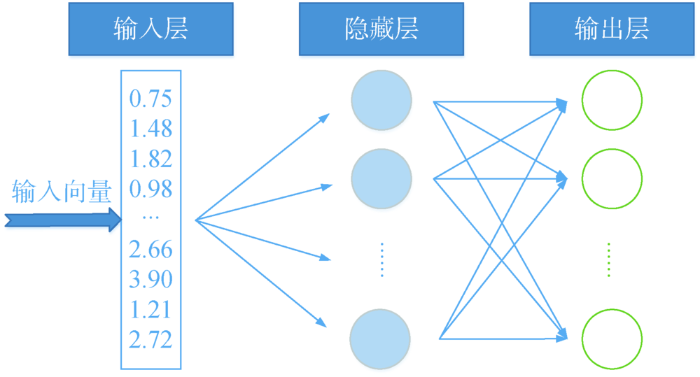
本文选用Word2Vec将词语转化为词向量,实现词与词之间的相关性计算。Word2Vec是包含一层隐含层的神经网络,其模型示意如图3 所示。
图3
图3
Word2Vec转化词向量模型
Fig.3
Word2Vec Model
Word2Vec模型的输入是能够表征词的特征向量,该特征向量通常为词频向量,隐藏层是一维线性单元,采用全连接的方式,并不使用激活函数,输出层采用Softmax回归。与其他网络不同的是,Word2Vec不是使用训练好的模型去测试新数据,而是将训练好的参数(比如隐含层的权值)作为输入词转换后的词向量。
在本文的景点识别中,模型输入是代表游记中每个分词重要性的一维特征向量,输出是每个分词对应的词向量。
本文采用余弦相似度计算词与词的相似度,通过计算两个词向量的余弦值来评估相似度。
(4) align ( w i ) = max 0 < j ≤ m ( cos ( w i , w j ) )
其中, w i i w j j m align ( w i ) i
3.3 行程重构模型
本文提出一种以一阶马尔可夫性为前提的、基于概率模型和空间特征的游客行程重构模型。通过人工标注的历史行程得到概率模型,加入景点的空间特征构建模型。该问题可以描述为:已知一次行程的起点s 和景点集合S ,实现游客游览行程的重构。根据这一问题,笔者提出根据当前景点,选择某一目标景点的概率模型,其表达形式如公式(5)所示。
(5) P i = 1 D i × P ( A i ) P ( A i | B ) P B i = 1,2 , … , N , A i ∈ C
其中, P ( A i ) A i P ( A i | B ) A i B P B B D i A i B P i B A i A i A i C C C
模型中表示当前景点与目标景点间的距离 D i [21 ] 所示。
(6) D i = R × P i × arccos θ 180 i = 1,2 , … , N
(7) θ = sin ( la t a ) × sin ( la t b ) × cos ( lon g a - lon g b ) + cos ( la t a ) × cos ( la t b )
其中, la t a lon g a la t b lon g b R
极端情况下,模型计算先验知识中并未出现的新景点的结果为零,因此,对新出现景点的先验概率和条件概率进行平滑处理。笔者提出先验概率 P ( A i ) P ( A i | B )
(8) P ( A i ) = ∑ p = 1 m A ip ∑ q = 1 n S q A i ∈ S 1 ∑ q = 1 n S q + 1 A i ∉ S i = 1,2 , … , N
(9) P ( A i | B ) = P ( A i , B ) P ( B ) = ∑ p = 1 m ( A ip , B ) ∑ q = 1 n B q A i ∈ S 1 ∑ q = 1 n B q + 1 A i ∉ S i = 1,2 , … , N
公式(8)中, ∑ p = 1 m A ip A i ∑ q = 1 n S q S ∑ p = 1 m ( A ip , B ) B A i ∑ q = 1 n B q B
4 实验及结果分析
4.1 实验数据
本文实验数据来自马蜂窝旅游网[1 ] ,以关键词“丝绸之路”搜索全部的景点名称,编写Python代码获取所有的景点名称,并通过百度地图开放平台[20 ] 进行坐标拾取,以此作为景点数据库;同样在马蜂窝旅游网爬取相关的游记文本信息,从而形成游记数据库。
最终形成的景点数据库中包含2 257个景点,包括每个景点所在的省市区县、经纬度、评论数目等;游记数据库包含1 116篇游记,包括每篇游记的全文、用户ID、游记URL、文字数、图片数、浏览数等。
为比较算法性能,本文在数据预处理阶段,通过手工标注部分数据,共100篇游记的景点和旅游行程。
4.2 行程重构实验结果
通过Word2Vec将景点库中所有景点转化为词向量矩阵;对游记进行分词,根据TF-IDF计算丝绸之路游记中分词的重要性,计算结果如表1 所示。
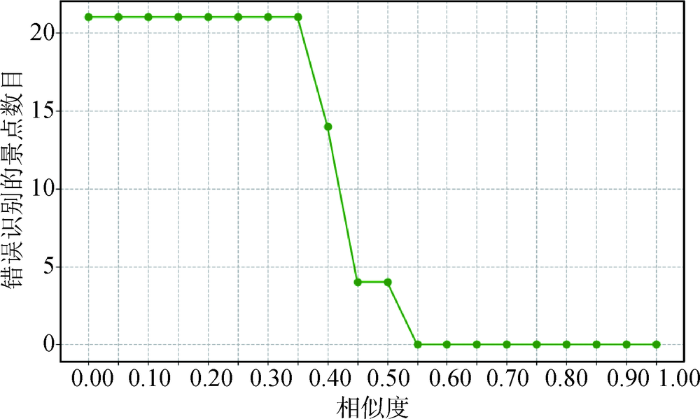
将此作为特征向量输入到Word2Vec模型,从而得到游记中每个分词的词向量;计算每一分词的词向量与景点库词向量矩阵的余弦相似度,设置不同的相似度阈值,匹配出最相似的景点名称。随着相似度的变化识别出景点的查准率如图4 所示,随着相似度的变化识别出错误的景点个数如图5 所示。随着相似度的提高,查准率在不断提高,在相似度为55%左右时出现明显临界点;错误识别的景点数目随着相似度的提高在不断降低,并且在相似度为55%左右时达到最低后维持不变。实验表明,相似度设为55%以上时识别效果最佳,查全率达90.72%。
图4
图4
查准率与相似度的关系
Fig.4
The Relationship Between Precision and Similarity
图5
图5
识别错误数目与相似度的关系
Fig.5
The Relationship Between Number of Recognition Errors and Similarity
采用本文方法与传统条件随机场识别效果如表2 所示,可以看到本文景点识别方法要优于条件随机场。
采用本文提出的基于一阶马尔可夫性、先验知识和空间特征的模型进行行程重构,并在真实数据集上进行行程相似性的对比实验。本文采用最长公共子序列(Longest Common Subsequence, LCS)对相似性进行计算。实验结果表明,本文提出的从游记中重构行程的方法与真实行程的相似度达到83.24%,行程重构模型能够较好地还原真实的行程。
5 结 语
本文较好地解决了从网络游记文本中重构游客的行程问题。提出一种TF-IDF和Word2Vec相结合的基于文本相似度的景点名称识别方法,各项指标均优于主流的统计学模型条件随机场,该方法最大的优势是无需数据标注和模型训练。借鉴隐马尔可夫模型构建一个新的行程重构模型,实验结果表明,该模型的结果较为真实地还原了游客的游览行程。在景点自动化识别中,本文方法依赖于景点信息库,所以景点信息库的完整度对结果会产生一定影响。
作者贡献声明
施元磊,高原,冯筠,张蕾:论文撰写及最终版本修订。
支撑数据
支撑数据由作者自存储,E-mail:1052678743@qq.com。
[1] 施元磊. 丝绸之路景点.xlsx. 马蜂窝景点数据.
[2] 施元磊. 丝绸之路游记.xlsx. 马蜂窝游记数据.
[3] 施元磊. 人工标注景点和行程.xlsx. 人工标注100篇游记的景点和旅游行程,用于模型测试.
[4] 施元磊. 机器识别景点.xlsx. 基于文本相似度的景点识别结果.
[5] 施元磊. 行程重构结果.xlsx. 本文方法实现游记行程重构的结果.
参考文献
View Option
[1]
张晓艳 , 王挺 , 陈火旺 . 命名实体识别研究
[J]. 计算机科学 , 2005 ,32 (4 ):44 -48 .
[本文引用: 2]
( Zhang Xiaoyan Wang Ting Chen Huowang . Research on Named Entity Recognition
[J]. Computer Science , 2005 ,32 (4 ):44 -48 .)
[本文引用: 2]
[2]
Phithakkitnukoon S Horanont T Witayangkurn A , et al . Understanding Tourist Behavior Using Large-Scale Mobile Sensing Approach: A Case Study of Mobile Phone Users in Japan
[J]. Pervasive and Mobile Computing , 2015 ,18 :18 -39 .
[本文引用: 1]
[3]
Budig B Van Dijk T C . Journeys of the Past: A Hidden Markov Approach to Georeferencing Historical Itineraries
[C]// Proceedings of the 11th Workshop on Geographic Information Retrieval. ACM , 2017 : Article No. 7 .
[本文引用: 2]
[4]
Blank D Henrich A . Geocoding Place Names from Historic Route Descriptions
[C]// Proceedings of the 9th Workshop on Geographic Information Retrieval. ACM , 2015 : Article No. 9 .
[本文引用: 2]
[5]
Blank D Henrich A . A Depth-First Branch-and-Bound Algorithm for Geocoding Historic Itinerary Tables
[C]// Proceedings of the 10th Workshop on Geographic Information Retrieval. ACM , 2016 : Article No. 3 .
[本文引用: 1]
[6]
Adelfio M D Samet H . Itinerary Retrieval: Travelers, Like Traveling Salesmen, Prefer Efficient Routes
[C]// Proceedings of the 8th Workshop on Geographic Information Retrieval. ACM , 2014 : Article No. 1 .
[本文引用: 1]
[7]
Zhou J Li B Chen G . Automatically Building Large-Scale Named Entity Recognition Corpora from Chinese Wikipedia
[J]. Frontiers of Information Technology & Electronic Engineering , 2015 ,16 (11 ):940 -956 .
[本文引用: 1]
[8]
张玥杰 , 徐智婷 , 薛向阳 . 融合多特征的最大熵汉语命名实体识别模型
[J]. 计算机研究与发展 , 2008 ,45 (6 ):1004 -1010 .
[本文引用: 1]
( Zhang Yuejie Xu Zhiting Xue Xiangyang . Fusion of Multiple Features for Chinese Named Entity Recognition Based on Maximum Entropy Model
[J]. Journal of Computer Research and Development , 2008 ,45 (6 ):1004 -1010 .)
[本文引用: 1]
[9]
康才畯 , 龙从军 , 江荻 . 基于条件随机场的藏文人名识别研究
[J]. 计算机工程与应用 , 2015 ,51 (3 ):109 -111, 185 .
[本文引用: 1]
( Kang Caijun Long Congjun Jiang Di . Tibetan Names Recognition Research Based on CRF
[J]. Computer Engineering & Applications , 2015 ,51 (3 ):109 -111, 185 .)
[本文引用: 1]
[10]
何炎祥 , 罗楚威 , 胡彬尧 . 基于CRF和规则相结合的地理命名实体识别方法
[J]. 计算机应用与软件 , 2015 ,32 (1 ):179 -185, 202 .
[本文引用: 1]
( He Yanxiang Luo Chuwei Hu Binyao . Geographic Entity Recognition Method Based on CRF Model and Rules Combination
[J]. Computer Applications and Software , 2015 ,32 (1 ):179 -185,202 .)
[本文引用: 1]
[11]
张永富 , 李志宏 , 李军军 , 等 . 一种基于自然语言处理的环境科学命名实体识别方法
[J]. 科技创新导报 , 2017 ,14 (21 ):120 -121 .
[本文引用: 1]
( Zhang Yongfu Li Zhihong Li Junjun , et al . A Named Entity Recognition Method for Environmental Science Based on Natural Language Processing
[J]. Science and Technology Innovation Herald , 2017 ,14 (21 ):120 -121 .)
[本文引用: 1]
[12]
Southall H Mostern R Berman M L . On Historical Gazetteers
[J]. International Journal of Humanities and Arts Computing , 2011 ,5 (2 ):127 -145 .
[本文引用: 1]
[13]
Jordan P . Placing Names: Enriching and Integrating Gazetteers
[J]. The Cartographic Journal , 2017 ,54 (4 ):377 -379 .
[本文引用: 1]
[14]
Melo F Martins B . Automated Geocoding of Textual Documents: A Survey of Current Approaches
[J]. Transactions in GIS , 2017 ,21 (1 ):3 -38 .
[本文引用: 1]
[15]
Khan A Vasardani M Winter S . Extracting Spatial Information from Place Descriptions
[C]// Proceedings of the 1st ACM SIGSPATIAL International Workshop on Computational Models of Place. 2013 : 62 -69 .
[本文引用: 1]
[16]
Newson P Krumm J . Hidden Markov Map Matching Through Noise and Sparseness
[C]// Proceedings of the 17th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems. 2009 : 336 -343 .
[本文引用: 1]
[17]
Moncla L Gaio M Noguerasiso J , et al . Reconstruction of Itineraries from Annotated Text with an Informed Spanning Tree Algorithm
[J]. International Journal of Geographical Information Science , 2016 ,30 (6 ):1137 -1160 .
[本文引用: 1]
[18]
Moncla L Renteria-Agualimpia W Noguerasiso J , et al . Geocoding for Texts with Fine-Grain Toponyms: An Experiment on a Geoparsed Hiking Descriptions Corpus
[C]// Proceedings of the 22nd ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems. 2014 : 183 -192 .
[本文引用: 1]
[19]
Salton G Buckley C . Term-weighting Approaches in Automatic Text Retrieval
[J]. Information Processing & Management , 1988 ,24 (5 ):513 -523 .
[本文引用: 1]
[20]
武永亮 , 赵书良 , 李长镜 , 等 . 基于TF-IDF和余弦相似度的文本分类方法
[J]. 中文信息学报 , 2017 ,31 (5 ):138 -145 .
[本文引用: 2]
( Wu Yongliang Zhao Shuliang Li Changjing , et al . Text Classification Method Based on TF-IDF and Cosine Similarity
[J]. Journal of Chinese Information Processing , 2017 ,31 (5 ):138 -145 .)
[本文引用: 2]
[21]
Niu K Zhang H Zhou T , et al . A Novel Spatio-Temporal Model for City-Scale Traffic Speed Prediction
[J]. IEEE Access , 2019 ,7 :30050 -30057 .
[本文引用: 1]
命名实体识别研究
2
2005
... 基于游记文本的行程重构,需要从游记文本中自动化识别行程的景点信息.游记中的景点关键词,表征游客的游览足迹,具有地理空间特征,蕴含着个人的旅游倾向和偏好.景点识别问题的本质是命名实体识别,主要分为基于规则的方法和基于统计的方法两大类[1 ] . ...
... 本文实验数据来自马蜂窝旅游网[1 ] ,以关键词“丝绸之路”搜索全部的景点名称,编写Python代码获取所有的景点名称,并通过百度地图开放平台[20 ] 进行坐标拾取,以此作为景点数据库;同样在马蜂窝旅游网爬取相关的游记文本信息,从而形成游记数据库. ...
命名实体识别研究
2
2005
... 基于游记文本的行程重构,需要从游记文本中自动化识别行程的景点信息.游记中的景点关键词,表征游客的游览足迹,具有地理空间特征,蕴含着个人的旅游倾向和偏好.景点识别问题的本质是命名实体识别,主要分为基于规则的方法和基于统计的方法两大类[1 ] . ...
... 本文实验数据来自马蜂窝旅游网[1 ] ,以关键词“丝绸之路”搜索全部的景点名称,编写Python代码获取所有的景点名称,并通过百度地图开放平台[20 ] 进行坐标拾取,以此作为景点数据库;同样在马蜂窝旅游网爬取相关的游记文本信息,从而形成游记数据库. ...
Understanding Tourist Behavior Using Large-Scale Mobile Sensing Approach: A Case Study of Mobile Phone Users in Japan
1
2015
... 20世纪70年代开始出现从文本数据中抽取表征用户行为的历史行程的相关研究.随着互联网的发展和自媒体时代的到来,网络上记录个人历史行程的文本数据呈指数级增长,这使得该项研究拥有了更多的数据支撑和现实价值.近年来,关于旅游领域的模式挖掘研究也日渐丰富,例如Phithakkitnukoon等[2 ] 针对日本国内的旅游数据挖掘出游客的出行规律和行程模式,分析旅游业存在的问题并给出有助于旅游业和游客的建议.Budig等[3 ] 提出一种从历史文本数据中提取行程的模型,该模型依赖于文本撰写的先后次序.由于网络自由文本形式的游记存在着景点的乱序性,该方法并不适用于解决本文的行程提取问题.Blank等[4 ] 针对路线重构提出一种基于编辑的解决方案.该方案由光学字符识别、路线解析、地名解析和路线查找4个步骤组成,在已知历史行程和兴趣点的前提下生成路线.本文的行程重构模型借鉴文献[4 ]的思想,从历史行程数据中构建统计模型作为先验知识.Blank等[5 ] 提出一种启发式方法,将路线中的地名与字符串距离、几何距离联系起来.该算法通过采用文本和地理空间的过滤器修剪待重构兴趣点的搜索空间,从而减少候选的行程.这种方法在实际应用中效果较好,但是缺少搜索优化目标,并且算法时间代价较大. ...
Journeys of the Past: A Hidden Markov Approach to Georeferencing Historical Itineraries
2
2017
... 20世纪70年代开始出现从文本数据中抽取表征用户行为的历史行程的相关研究.随着互联网的发展和自媒体时代的到来,网络上记录个人历史行程的文本数据呈指数级增长,这使得该项研究拥有了更多的数据支撑和现实价值.近年来,关于旅游领域的模式挖掘研究也日渐丰富,例如Phithakkitnukoon等[2 ] 针对日本国内的旅游数据挖掘出游客的出行规律和行程模式,分析旅游业存在的问题并给出有助于旅游业和游客的建议.Budig等[3 ] 提出一种从历史文本数据中提取行程的模型,该模型依赖于文本撰写的先后次序.由于网络自由文本形式的游记存在着景点的乱序性,该方法并不适用于解决本文的行程提取问题.Blank等[4 ] 针对路线重构提出一种基于编辑的解决方案.该方案由光学字符识别、路线解析、地名解析和路线查找4个步骤组成,在已知历史行程和兴趣点的前提下生成路线.本文的行程重构模型借鉴文献[4 ]的思想,从历史行程数据中构建统计模型作为先验知识.Blank等[5 ] 提出一种启发式方法,将路线中的地名与字符串距离、几何距离联系起来.该算法通过采用文本和地理空间的过滤器修剪待重构兴趣点的搜索空间,从而减少候选的行程.这种方法在实际应用中效果较好,但是缺少搜索优化目标,并且算法时间代价较大. ...
... 识别并赋予空间信息后,接下来的工作便是重构旅游行程.行程重构问题与地图匹配问题有着一些相似之处.Newson等[16 ] 提出一种新的基于隐马尔可夫模型的地图匹配算法;Budig等[3 ] 构建一种加入空间特征的隐马尔可夫模型从文本数据中重构行程;Moncla等[17 ] 提出一种从带有注释或者标签的文本中构建行程的方法;Moncla等[18 ] 实现了从具有地理位置标签的远足文本数据中重构行程.无论采用何种方式,这些文献提出的方法都以马尔可夫性这一假设为前提.为降低模型的计算复杂度,本文同样基于一阶马尔可夫性构建模型. ...
Geocoding Place Names from Historic Route Descriptions
2
2015
... 20世纪70年代开始出现从文本数据中抽取表征用户行为的历史行程的相关研究.随着互联网的发展和自媒体时代的到来,网络上记录个人历史行程的文本数据呈指数级增长,这使得该项研究拥有了更多的数据支撑和现实价值.近年来,关于旅游领域的模式挖掘研究也日渐丰富,例如Phithakkitnukoon等[2 ] 针对日本国内的旅游数据挖掘出游客的出行规律和行程模式,分析旅游业存在的问题并给出有助于旅游业和游客的建议.Budig等[3 ] 提出一种从历史文本数据中提取行程的模型,该模型依赖于文本撰写的先后次序.由于网络自由文本形式的游记存在着景点的乱序性,该方法并不适用于解决本文的行程提取问题.Blank等[4 ] 针对路线重构提出一种基于编辑的解决方案.该方案由光学字符识别、路线解析、地名解析和路线查找4个步骤组成,在已知历史行程和兴趣点的前提下生成路线.本文的行程重构模型借鉴文献[4 ]的思想,从历史行程数据中构建统计模型作为先验知识.Blank等[5 ] 提出一种启发式方法,将路线中的地名与字符串距离、几何距离联系起来.该算法通过采用文本和地理空间的过滤器修剪待重构兴趣点的搜索空间,从而减少候选的行程.这种方法在实际应用中效果较好,但是缺少搜索优化目标,并且算法时间代价较大. ...
... 针对路线重构提出一种基于编辑的解决方案.该方案由光学字符识别、路线解析、地名解析和路线查找4个步骤组成,在已知历史行程和兴趣点的前提下生成路线.本文的行程重构模型借鉴文献[4 ]的思想,从历史行程数据中构建统计模型作为先验知识.Blank等[5 ] 提出一种启发式方法,将路线中的地名与字符串距离、几何距离联系起来.该算法通过采用文本和地理空间的过滤器修剪待重构兴趣点的搜索空间,从而减少候选的行程.这种方法在实际应用中效果较好,但是缺少搜索优化目标,并且算法时间代价较大. ...
A Depth-First Branch-and-Bound Algorithm for Geocoding Historic Itinerary Tables
1
2016
... 20世纪70年代开始出现从文本数据中抽取表征用户行为的历史行程的相关研究.随着互联网的发展和自媒体时代的到来,网络上记录个人历史行程的文本数据呈指数级增长,这使得该项研究拥有了更多的数据支撑和现实价值.近年来,关于旅游领域的模式挖掘研究也日渐丰富,例如Phithakkitnukoon等[2 ] 针对日本国内的旅游数据挖掘出游客的出行规律和行程模式,分析旅游业存在的问题并给出有助于旅游业和游客的建议.Budig等[3 ] 提出一种从历史文本数据中提取行程的模型,该模型依赖于文本撰写的先后次序.由于网络自由文本形式的游记存在着景点的乱序性,该方法并不适用于解决本文的行程提取问题.Blank等[4 ] 针对路线重构提出一种基于编辑的解决方案.该方案由光学字符识别、路线解析、地名解析和路线查找4个步骤组成,在已知历史行程和兴趣点的前提下生成路线.本文的行程重构模型借鉴文献[4 ]的思想,从历史行程数据中构建统计模型作为先验知识.Blank等[5 ] 提出一种启发式方法,将路线中的地名与字符串距离、几何距离联系起来.该算法通过采用文本和地理空间的过滤器修剪待重构兴趣点的搜索空间,从而减少候选的行程.这种方法在实际应用中效果较好,但是缺少搜索优化目标,并且算法时间代价较大. ...
Itinerary Retrieval: Travelers, Like Traveling Salesmen, Prefer Efficient Routes
1
2014
... 为降低算法的时间复杂度,从文本中提取关键信息必不可少.Adelfio等[6 ] 提出从电子表格和网页中识别和提取关键词的方法.本文的研究内容是从大量游记文本中重构行程,同样也需要提取蕴含地理信息的景点.因此,景点名称的识别和提取成为重构行程的关键前提.关于中文文本中命名实体识别的研究,已有较多方法和成果[7 ] ,但早期工作大多都是基于规则的方法或者基于统计的方法.张玥杰等[8 ] 提出一种融合多特征的最大熵模型,在语言无关的统计学方法基础上加入语言相关的规则,通过两者相结合的方式提高命名实体识别性能;康才畯等[9 ] 提出采用条件随机场(CRF)模型识别命名实体的方法;何炎祥等[10 ] 提出一种基于规则和条件随机场相结合的地理命名实体识别方法.这些方法均是基于统计学经典方法上的改进与应用,都需要在训练集的语料中进行大量标注工作,但是,对大量训练集进行实体标注是非常巨大的工程,费时费力,此外,如果是训练集没出现过的实体则无法识别.而张永富等[11 ] 利用自然语言处理中文本相似度的计算方法识别环境科学命名实体就显得省时省力.由于景点可能存在简称或者别名,所以本文采用基于文本相似性度量的方法实现景点名称的批量识别,该方法的优势在于:(1)无训练集和测试集的划分,即无需标注任何数据,大大降低了工作量;(2)可处理大批量的文本数据;(3)由于不依赖于训练集的实体标注,所以可识别出尽可能多的相关实体. ...
Automatically Building Large-Scale Named Entity Recognition Corpora from Chinese Wikipedia
1
2015
... 为降低算法的时间复杂度,从文本中提取关键信息必不可少.Adelfio等[6 ] 提出从电子表格和网页中识别和提取关键词的方法.本文的研究内容是从大量游记文本中重构行程,同样也需要提取蕴含地理信息的景点.因此,景点名称的识别和提取成为重构行程的关键前提.关于中文文本中命名实体识别的研究,已有较多方法和成果[7 ] ,但早期工作大多都是基于规则的方法或者基于统计的方法.张玥杰等[8 ] 提出一种融合多特征的最大熵模型,在语言无关的统计学方法基础上加入语言相关的规则,通过两者相结合的方式提高命名实体识别性能;康才畯等[9 ] 提出采用条件随机场(CRF)模型识别命名实体的方法;何炎祥等[10 ] 提出一种基于规则和条件随机场相结合的地理命名实体识别方法.这些方法均是基于统计学经典方法上的改进与应用,都需要在训练集的语料中进行大量标注工作,但是,对大量训练集进行实体标注是非常巨大的工程,费时费力,此外,如果是训练集没出现过的实体则无法识别.而张永富等[11 ] 利用自然语言处理中文本相似度的计算方法识别环境科学命名实体就显得省时省力.由于景点可能存在简称或者别名,所以本文采用基于文本相似性度量的方法实现景点名称的批量识别,该方法的优势在于:(1)无训练集和测试集的划分,即无需标注任何数据,大大降低了工作量;(2)可处理大批量的文本数据;(3)由于不依赖于训练集的实体标注,所以可识别出尽可能多的相关实体. ...
融合多特征的最大熵汉语命名实体识别模型
1
2008
... 为降低算法的时间复杂度,从文本中提取关键信息必不可少.Adelfio等[6 ] 提出从电子表格和网页中识别和提取关键词的方法.本文的研究内容是从大量游记文本中重构行程,同样也需要提取蕴含地理信息的景点.因此,景点名称的识别和提取成为重构行程的关键前提.关于中文文本中命名实体识别的研究,已有较多方法和成果[7 ] ,但早期工作大多都是基于规则的方法或者基于统计的方法.张玥杰等[8 ] 提出一种融合多特征的最大熵模型,在语言无关的统计学方法基础上加入语言相关的规则,通过两者相结合的方式提高命名实体识别性能;康才畯等[9 ] 提出采用条件随机场(CRF)模型识别命名实体的方法;何炎祥等[10 ] 提出一种基于规则和条件随机场相结合的地理命名实体识别方法.这些方法均是基于统计学经典方法上的改进与应用,都需要在训练集的语料中进行大量标注工作,但是,对大量训练集进行实体标注是非常巨大的工程,费时费力,此外,如果是训练集没出现过的实体则无法识别.而张永富等[11 ] 利用自然语言处理中文本相似度的计算方法识别环境科学命名实体就显得省时省力.由于景点可能存在简称或者别名,所以本文采用基于文本相似性度量的方法实现景点名称的批量识别,该方法的优势在于:(1)无训练集和测试集的划分,即无需标注任何数据,大大降低了工作量;(2)可处理大批量的文本数据;(3)由于不依赖于训练集的实体标注,所以可识别出尽可能多的相关实体. ...
融合多特征的最大熵汉语命名实体识别模型
1
2008
... 为降低算法的时间复杂度,从文本中提取关键信息必不可少.Adelfio等[6 ] 提出从电子表格和网页中识别和提取关键词的方法.本文的研究内容是从大量游记文本中重构行程,同样也需要提取蕴含地理信息的景点.因此,景点名称的识别和提取成为重构行程的关键前提.关于中文文本中命名实体识别的研究,已有较多方法和成果[7 ] ,但早期工作大多都是基于规则的方法或者基于统计的方法.张玥杰等[8 ] 提出一种融合多特征的最大熵模型,在语言无关的统计学方法基础上加入语言相关的规则,通过两者相结合的方式提高命名实体识别性能;康才畯等[9 ] 提出采用条件随机场(CRF)模型识别命名实体的方法;何炎祥等[10 ] 提出一种基于规则和条件随机场相结合的地理命名实体识别方法.这些方法均是基于统计学经典方法上的改进与应用,都需要在训练集的语料中进行大量标注工作,但是,对大量训练集进行实体标注是非常巨大的工程,费时费力,此外,如果是训练集没出现过的实体则无法识别.而张永富等[11 ] 利用自然语言处理中文本相似度的计算方法识别环境科学命名实体就显得省时省力.由于景点可能存在简称或者别名,所以本文采用基于文本相似性度量的方法实现景点名称的批量识别,该方法的优势在于:(1)无训练集和测试集的划分,即无需标注任何数据,大大降低了工作量;(2)可处理大批量的文本数据;(3)由于不依赖于训练集的实体标注,所以可识别出尽可能多的相关实体. ...
基于条件随机场的藏文人名识别研究
1
2015
... 为降低算法的时间复杂度,从文本中提取关键信息必不可少.Adelfio等[6 ] 提出从电子表格和网页中识别和提取关键词的方法.本文的研究内容是从大量游记文本中重构行程,同样也需要提取蕴含地理信息的景点.因此,景点名称的识别和提取成为重构行程的关键前提.关于中文文本中命名实体识别的研究,已有较多方法和成果[7 ] ,但早期工作大多都是基于规则的方法或者基于统计的方法.张玥杰等[8 ] 提出一种融合多特征的最大熵模型,在语言无关的统计学方法基础上加入语言相关的规则,通过两者相结合的方式提高命名实体识别性能;康才畯等[9 ] 提出采用条件随机场(CRF)模型识别命名实体的方法;何炎祥等[10 ] 提出一种基于规则和条件随机场相结合的地理命名实体识别方法.这些方法均是基于统计学经典方法上的改进与应用,都需要在训练集的语料中进行大量标注工作,但是,对大量训练集进行实体标注是非常巨大的工程,费时费力,此外,如果是训练集没出现过的实体则无法识别.而张永富等[11 ] 利用自然语言处理中文本相似度的计算方法识别环境科学命名实体就显得省时省力.由于景点可能存在简称或者别名,所以本文采用基于文本相似性度量的方法实现景点名称的批量识别,该方法的优势在于:(1)无训练集和测试集的划分,即无需标注任何数据,大大降低了工作量;(2)可处理大批量的文本数据;(3)由于不依赖于训练集的实体标注,所以可识别出尽可能多的相关实体. ...
基于条件随机场的藏文人名识别研究
1
2015
... 为降低算法的时间复杂度,从文本中提取关键信息必不可少.Adelfio等[6 ] 提出从电子表格和网页中识别和提取关键词的方法.本文的研究内容是从大量游记文本中重构行程,同样也需要提取蕴含地理信息的景点.因此,景点名称的识别和提取成为重构行程的关键前提.关于中文文本中命名实体识别的研究,已有较多方法和成果[7 ] ,但早期工作大多都是基于规则的方法或者基于统计的方法.张玥杰等[8 ] 提出一种融合多特征的最大熵模型,在语言无关的统计学方法基础上加入语言相关的规则,通过两者相结合的方式提高命名实体识别性能;康才畯等[9 ] 提出采用条件随机场(CRF)模型识别命名实体的方法;何炎祥等[10 ] 提出一种基于规则和条件随机场相结合的地理命名实体识别方法.这些方法均是基于统计学经典方法上的改进与应用,都需要在训练集的语料中进行大量标注工作,但是,对大量训练集进行实体标注是非常巨大的工程,费时费力,此外,如果是训练集没出现过的实体则无法识别.而张永富等[11 ] 利用自然语言处理中文本相似度的计算方法识别环境科学命名实体就显得省时省力.由于景点可能存在简称或者别名,所以本文采用基于文本相似性度量的方法实现景点名称的批量识别,该方法的优势在于:(1)无训练集和测试集的划分,即无需标注任何数据,大大降低了工作量;(2)可处理大批量的文本数据;(3)由于不依赖于训练集的实体标注,所以可识别出尽可能多的相关实体. ...
基于CRF和规则相结合的地理命名实体识别方法
1
2015
... 为降低算法的时间复杂度,从文本中提取关键信息必不可少.Adelfio等[6 ] 提出从电子表格和网页中识别和提取关键词的方法.本文的研究内容是从大量游记文本中重构行程,同样也需要提取蕴含地理信息的景点.因此,景点名称的识别和提取成为重构行程的关键前提.关于中文文本中命名实体识别的研究,已有较多方法和成果[7 ] ,但早期工作大多都是基于规则的方法或者基于统计的方法.张玥杰等[8 ] 提出一种融合多特征的最大熵模型,在语言无关的统计学方法基础上加入语言相关的规则,通过两者相结合的方式提高命名实体识别性能;康才畯等[9 ] 提出采用条件随机场(CRF)模型识别命名实体的方法;何炎祥等[10 ] 提出一种基于规则和条件随机场相结合的地理命名实体识别方法.这些方法均是基于统计学经典方法上的改进与应用,都需要在训练集的语料中进行大量标注工作,但是,对大量训练集进行实体标注是非常巨大的工程,费时费力,此外,如果是训练集没出现过的实体则无法识别.而张永富等[11 ] 利用自然语言处理中文本相似度的计算方法识别环境科学命名实体就显得省时省力.由于景点可能存在简称或者别名,所以本文采用基于文本相似性度量的方法实现景点名称的批量识别,该方法的优势在于:(1)无训练集和测试集的划分,即无需标注任何数据,大大降低了工作量;(2)可处理大批量的文本数据;(3)由于不依赖于训练集的实体标注,所以可识别出尽可能多的相关实体. ...
基于CRF和规则相结合的地理命名实体识别方法
1
2015
... 为降低算法的时间复杂度,从文本中提取关键信息必不可少.Adelfio等[6 ] 提出从电子表格和网页中识别和提取关键词的方法.本文的研究内容是从大量游记文本中重构行程,同样也需要提取蕴含地理信息的景点.因此,景点名称的识别和提取成为重构行程的关键前提.关于中文文本中命名实体识别的研究,已有较多方法和成果[7 ] ,但早期工作大多都是基于规则的方法或者基于统计的方法.张玥杰等[8 ] 提出一种融合多特征的最大熵模型,在语言无关的统计学方法基础上加入语言相关的规则,通过两者相结合的方式提高命名实体识别性能;康才畯等[9 ] 提出采用条件随机场(CRF)模型识别命名实体的方法;何炎祥等[10 ] 提出一种基于规则和条件随机场相结合的地理命名实体识别方法.这些方法均是基于统计学经典方法上的改进与应用,都需要在训练集的语料中进行大量标注工作,但是,对大量训练集进行实体标注是非常巨大的工程,费时费力,此外,如果是训练集没出现过的实体则无法识别.而张永富等[11 ] 利用自然语言处理中文本相似度的计算方法识别环境科学命名实体就显得省时省力.由于景点可能存在简称或者别名,所以本文采用基于文本相似性度量的方法实现景点名称的批量识别,该方法的优势在于:(1)无训练集和测试集的划分,即无需标注任何数据,大大降低了工作量;(2)可处理大批量的文本数据;(3)由于不依赖于训练集的实体标注,所以可识别出尽可能多的相关实体. ...
一种基于自然语言处理的环境科学命名实体识别方法
1
2017
... 为降低算法的时间复杂度,从文本中提取关键信息必不可少.Adelfio等[6 ] 提出从电子表格和网页中识别和提取关键词的方法.本文的研究内容是从大量游记文本中重构行程,同样也需要提取蕴含地理信息的景点.因此,景点名称的识别和提取成为重构行程的关键前提.关于中文文本中命名实体识别的研究,已有较多方法和成果[7 ] ,但早期工作大多都是基于规则的方法或者基于统计的方法.张玥杰等[8 ] 提出一种融合多特征的最大熵模型,在语言无关的统计学方法基础上加入语言相关的规则,通过两者相结合的方式提高命名实体识别性能;康才畯等[9 ] 提出采用条件随机场(CRF)模型识别命名实体的方法;何炎祥等[10 ] 提出一种基于规则和条件随机场相结合的地理命名实体识别方法.这些方法均是基于统计学经典方法上的改进与应用,都需要在训练集的语料中进行大量标注工作,但是,对大量训练集进行实体标注是非常巨大的工程,费时费力,此外,如果是训练集没出现过的实体则无法识别.而张永富等[11 ] 利用自然语言处理中文本相似度的计算方法识别环境科学命名实体就显得省时省力.由于景点可能存在简称或者别名,所以本文采用基于文本相似性度量的方法实现景点名称的批量识别,该方法的优势在于:(1)无训练集和测试集的划分,即无需标注任何数据,大大降低了工作量;(2)可处理大批量的文本数据;(3)由于不依赖于训练集的实体标注,所以可识别出尽可能多的相关实体. ...
一种基于自然语言处理的环境科学命名实体识别方法
1
2017
... 为降低算法的时间复杂度,从文本中提取关键信息必不可少.Adelfio等[6 ] 提出从电子表格和网页中识别和提取关键词的方法.本文的研究内容是从大量游记文本中重构行程,同样也需要提取蕴含地理信息的景点.因此,景点名称的识别和提取成为重构行程的关键前提.关于中文文本中命名实体识别的研究,已有较多方法和成果[7 ] ,但早期工作大多都是基于规则的方法或者基于统计的方法.张玥杰等[8 ] 提出一种融合多特征的最大熵模型,在语言无关的统计学方法基础上加入语言相关的规则,通过两者相结合的方式提高命名实体识别性能;康才畯等[9 ] 提出采用条件随机场(CRF)模型识别命名实体的方法;何炎祥等[10 ] 提出一种基于规则和条件随机场相结合的地理命名实体识别方法.这些方法均是基于统计学经典方法上的改进与应用,都需要在训练集的语料中进行大量标注工作,但是,对大量训练集进行实体标注是非常巨大的工程,费时费力,此外,如果是训练集没出现过的实体则无法识别.而张永富等[11 ] 利用自然语言处理中文本相似度的计算方法识别环境科学命名实体就显得省时省力.由于景点可能存在简称或者别名,所以本文采用基于文本相似性度量的方法实现景点名称的批量识别,该方法的优势在于:(1)无训练集和测试集的划分,即无需标注任何数据,大大降低了工作量;(2)可处理大批量的文本数据;(3)由于不依赖于训练集的实体标注,所以可识别出尽可能多的相关实体. ...
On Historical Gazetteers
1
2011
... 从游记中识别出景点后不足以重构行程,通常还需要考虑一些特征,比如景点的空间分布特征.Southall等[12 ] 根据先验知识和地理位置信息发现了新的历史学家和分布规律.在自然语言处理中,信息的空间分布特征常常被研究者忽略,但在空间人文学科中却高度相关[13 ] .本文的行程重构模型借鉴该思想,在基于历史行程的统计模型基础上,加入地理位置特征.根据文本信息确定地理位置及进行地理编码是地理信息检索的热门研究领域.Melo等[14 ] 提出一种从文本数据中提取地理信息的方法.该方法表明为从文本中提取地理信息,就必须识别出蕴含地理信息的关键词,而这些关键词往往都是能够映射地理位置的实体.最后将提取出的实体与其蕴含的地理位置一一映射即可得到包含地理空间特征的实体.映射方法可以是包含地理位置的实体知识库,也可以是包含省市区等位置信息的数据库.然而,并非所有的实体都有现成的数据库,可自行构建包含这些实体的数据库.如此,实体的自动提取并赋予更多的特征就变得可行.例如,Khan等[15 ] 通过自行构造数据库的方法赋予实体更多特征,从而为重构行程提供了更多依据.由于景点信息的缺乏,本文借鉴上述思想构造景点信息库,从而对实体赋予地理空间信息. ...
Placing Names: Enriching and Integrating Gazetteers
1
2017
... 从游记中识别出景点后不足以重构行程,通常还需要考虑一些特征,比如景点的空间分布特征.Southall等[12 ] 根据先验知识和地理位置信息发现了新的历史学家和分布规律.在自然语言处理中,信息的空间分布特征常常被研究者忽略,但在空间人文学科中却高度相关[13 ] .本文的行程重构模型借鉴该思想,在基于历史行程的统计模型基础上,加入地理位置特征.根据文本信息确定地理位置及进行地理编码是地理信息检索的热门研究领域.Melo等[14 ] 提出一种从文本数据中提取地理信息的方法.该方法表明为从文本中提取地理信息,就必须识别出蕴含地理信息的关键词,而这些关键词往往都是能够映射地理位置的实体.最后将提取出的实体与其蕴含的地理位置一一映射即可得到包含地理空间特征的实体.映射方法可以是包含地理位置的实体知识库,也可以是包含省市区等位置信息的数据库.然而,并非所有的实体都有现成的数据库,可自行构建包含这些实体的数据库.如此,实体的自动提取并赋予更多的特征就变得可行.例如,Khan等[15 ] 通过自行构造数据库的方法赋予实体更多特征,从而为重构行程提供了更多依据.由于景点信息的缺乏,本文借鉴上述思想构造景点信息库,从而对实体赋予地理空间信息. ...
Automated Geocoding of Textual Documents: A Survey of Current Approaches
1
2017
... 从游记中识别出景点后不足以重构行程,通常还需要考虑一些特征,比如景点的空间分布特征.Southall等[12 ] 根据先验知识和地理位置信息发现了新的历史学家和分布规律.在自然语言处理中,信息的空间分布特征常常被研究者忽略,但在空间人文学科中却高度相关[13 ] .本文的行程重构模型借鉴该思想,在基于历史行程的统计模型基础上,加入地理位置特征.根据文本信息确定地理位置及进行地理编码是地理信息检索的热门研究领域.Melo等[14 ] 提出一种从文本数据中提取地理信息的方法.该方法表明为从文本中提取地理信息,就必须识别出蕴含地理信息的关键词,而这些关键词往往都是能够映射地理位置的实体.最后将提取出的实体与其蕴含的地理位置一一映射即可得到包含地理空间特征的实体.映射方法可以是包含地理位置的实体知识库,也可以是包含省市区等位置信息的数据库.然而,并非所有的实体都有现成的数据库,可自行构建包含这些实体的数据库.如此,实体的自动提取并赋予更多的特征就变得可行.例如,Khan等[15 ] 通过自行构造数据库的方法赋予实体更多特征,从而为重构行程提供了更多依据.由于景点信息的缺乏,本文借鉴上述思想构造景点信息库,从而对实体赋予地理空间信息. ...
Extracting Spatial Information from Place Descriptions
1
2013
... 从游记中识别出景点后不足以重构行程,通常还需要考虑一些特征,比如景点的空间分布特征.Southall等[12 ] 根据先验知识和地理位置信息发现了新的历史学家和分布规律.在自然语言处理中,信息的空间分布特征常常被研究者忽略,但在空间人文学科中却高度相关[13 ] .本文的行程重构模型借鉴该思想,在基于历史行程的统计模型基础上,加入地理位置特征.根据文本信息确定地理位置及进行地理编码是地理信息检索的热门研究领域.Melo等[14 ] 提出一种从文本数据中提取地理信息的方法.该方法表明为从文本中提取地理信息,就必须识别出蕴含地理信息的关键词,而这些关键词往往都是能够映射地理位置的实体.最后将提取出的实体与其蕴含的地理位置一一映射即可得到包含地理空间特征的实体.映射方法可以是包含地理位置的实体知识库,也可以是包含省市区等位置信息的数据库.然而,并非所有的实体都有现成的数据库,可自行构建包含这些实体的数据库.如此,实体的自动提取并赋予更多的特征就变得可行.例如,Khan等[15 ] 通过自行构造数据库的方法赋予实体更多特征,从而为重构行程提供了更多依据.由于景点信息的缺乏,本文借鉴上述思想构造景点信息库,从而对实体赋予地理空间信息. ...
Hidden Markov Map Matching Through Noise and Sparseness
1
2009
... 识别并赋予空间信息后,接下来的工作便是重构旅游行程.行程重构问题与地图匹配问题有着一些相似之处.Newson等[16 ] 提出一种新的基于隐马尔可夫模型的地图匹配算法;Budig等[3 ] 构建一种加入空间特征的隐马尔可夫模型从文本数据中重构行程;Moncla等[17 ] 提出一种从带有注释或者标签的文本中构建行程的方法;Moncla等[18 ] 实现了从具有地理位置标签的远足文本数据中重构行程.无论采用何种方式,这些文献提出的方法都以马尔可夫性这一假设为前提.为降低模型的计算复杂度,本文同样基于一阶马尔可夫性构建模型. ...
Reconstruction of Itineraries from Annotated Text with an Informed Spanning Tree Algorithm
1
2016
... 识别并赋予空间信息后,接下来的工作便是重构旅游行程.行程重构问题与地图匹配问题有着一些相似之处.Newson等[16 ] 提出一种新的基于隐马尔可夫模型的地图匹配算法;Budig等[3 ] 构建一种加入空间特征的隐马尔可夫模型从文本数据中重构行程;Moncla等[17 ] 提出一种从带有注释或者标签的文本中构建行程的方法;Moncla等[18 ] 实现了从具有地理位置标签的远足文本数据中重构行程.无论采用何种方式,这些文献提出的方法都以马尔可夫性这一假设为前提.为降低模型的计算复杂度,本文同样基于一阶马尔可夫性构建模型. ...
Geocoding for Texts with Fine-Grain Toponyms: An Experiment on a Geoparsed Hiking Descriptions Corpus
1
2014
... 识别并赋予空间信息后,接下来的工作便是重构旅游行程.行程重构问题与地图匹配问题有着一些相似之处.Newson等[16 ] 提出一种新的基于隐马尔可夫模型的地图匹配算法;Budig等[3 ] 构建一种加入空间特征的隐马尔可夫模型从文本数据中重构行程;Moncla等[17 ] 提出一种从带有注释或者标签的文本中构建行程的方法;Moncla等[18 ] 实现了从具有地理位置标签的远足文本数据中重构行程.无论采用何种方式,这些文献提出的方法都以马尔可夫性这一假设为前提.为降低模型的计算复杂度,本文同样基于一阶马尔可夫性构建模型. ...
Term-weighting Approaches in Automatic Text Retrieval
1
1988
... TF-IDF[19 ] 是一种基于统计的词的关键性计算方法,该方法计算词在当前文档的出现次数和出现过该词的文档数,如果该词在当前文档中出现的次数越多并且在其他文档中出现的次数越少,表明该词对于当前文档来说更具关键性. ...
基于TF-IDF和余弦相似度的文本分类方法
2
2017
... 余弦相似度计算方法如公式(4)所示[20 ] . ...
... 本文实验数据来自马蜂窝旅游网[1 ] ,以关键词“丝绸之路”搜索全部的景点名称,编写Python代码获取所有的景点名称,并通过百度地图开放平台[20 ] 进行坐标拾取,以此作为景点数据库;同样在马蜂窝旅游网爬取相关的游记文本信息,从而形成游记数据库. ...
基于TF-IDF和余弦相似度的文本分类方法
2
2017
... 余弦相似度计算方法如公式(4)所示[20 ] . ...
... 本文实验数据来自马蜂窝旅游网[1 ] ,以关键词“丝绸之路”搜索全部的景点名称,编写Python代码获取所有的景点名称,并通过百度地图开放平台[20 ] 进行坐标拾取,以此作为景点数据库;同样在马蜂窝旅游网爬取相关的游记文本信息,从而形成游记数据库. ...
A Novel Spatio-Temporal Model for City-Scale Traffic Speed Prediction
1
2019
... 模型中表示当前景点与目标景点间的距离 D i [21 ] 所示. ...








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}