




1 引 言
随着大数据和机器学习在工业上的广泛应用,数据的产生与更新速度加快,数据量呈爆发式增长,数据中心的数据量从PB(1PB=240B),EB(1EB=250B)迈入ZB(1ZB=260B),YB(1YB=270B)[1]。然而数据质量参差不齐,甚至不乏错误的信息表述,如何在数据中选择出优质的数据训练模型对提高机器学习的效率十分重要。
2003年,Franc等[2]提出利用贪心算法(Greedy Kernel Principal Component Analysis,GKPCA)寻找表示训练数据的低维空间基向量,该算法在支持向量机(Support Vector Machine,SVM)中降低了分类器的复杂度,但该数据选择算法本身的时间复杂度达到O(nm3),其中n为训练集大小,m为基向量个数,不适用于大型数据集。
在统计机器翻译(Statistical Machine Translation,SMT)方面,Lü等[3]在SMT中使用词频-逆文档频次算法(Term Frequency-Inverse Document Frequency,TF-IDF)进行样本选择,发现从原数据中选择出相似数据进行训练可减小模型大小,同时不影响模型的性能。随后,Yasuda等[4]提出使用困惑度在SMT中进行样本选择,与Lü等[3]的模型相比,该模型压缩为原来的22%,且BLEU(Bilingual Evaluation Understudy)提高0.76%。Axelrod等[5]在SMT中提出使用交叉熵、不同语料的交叉熵差、源与目标语料库交叉熵差的和进行排序和样本选择,使得在数据量减少99%的情况下,BLEU增加1.8%,但其翻译模型的性能低于Lü等[3]的模型。
学者们在机器学习方面的研究工作,证实训练数据的子集选择不同,对模型产生的影响不同,选择合适的样本训练模型至关重要。样本选择算法大多应用于数据为图片的分类任务,对文本数据,尤其是中文文本,并未广泛应用。对此,本文探究过滤式与嵌入式算法在中文文本数据选择方面的应用,贡献如下:
(1)提出一种过滤式的小批量协方差估计样本选择算法;
(2)将遗忘数据的可选择性应用于中文文本数据的样本选择;
(3)将两种算法应用于中文阅读理解模型,并与经典的过滤式样本选择算法TF-IDF以及常用的随机扰动法进行对比,探究两种算法的有效性。
2 相关工作
2.1 机器阅读理解
本文基于文档的机器阅读理解模型,聚焦智能交互文本阅读的应用,涉及深度学习、自然语言处理和信息检索,支持计算机帮助人类在大量文本中找到想要的答案,降低人们获取信息的成本。
2.2 词向量
基于神经网络模型的分布式表示对中文文本数据进行编码,利用谷歌在2013年推出的自然语言处理工具——Word2Vec①(①
2.3 过滤式与嵌入式样本选择算法
3 过滤式小批量协方差估计样本选择算法
3.1 协方差估计
引入概率和统计学中协方差与样本协方差的概念。设神经网络的一个Batch的输入
协方差矩阵是一个
协方差矩阵的一般无偏估计协方差阵称为样本协方差矩阵,简称样本协差阵,即
3.2 小批量协方差估计样本选择算法
在中文阅读理解模型中,使用BiLSTM网络,应用协方差估计样本选择算法,根据公式(2)分批次计算输入数据编码后的向量之间的样本协差阵,并对其进行排序分析,设定一个阈值(Threshold)为0.5,选择阈值范围内的数据作为神经网络的输入数据,示例如图1所示。
图1
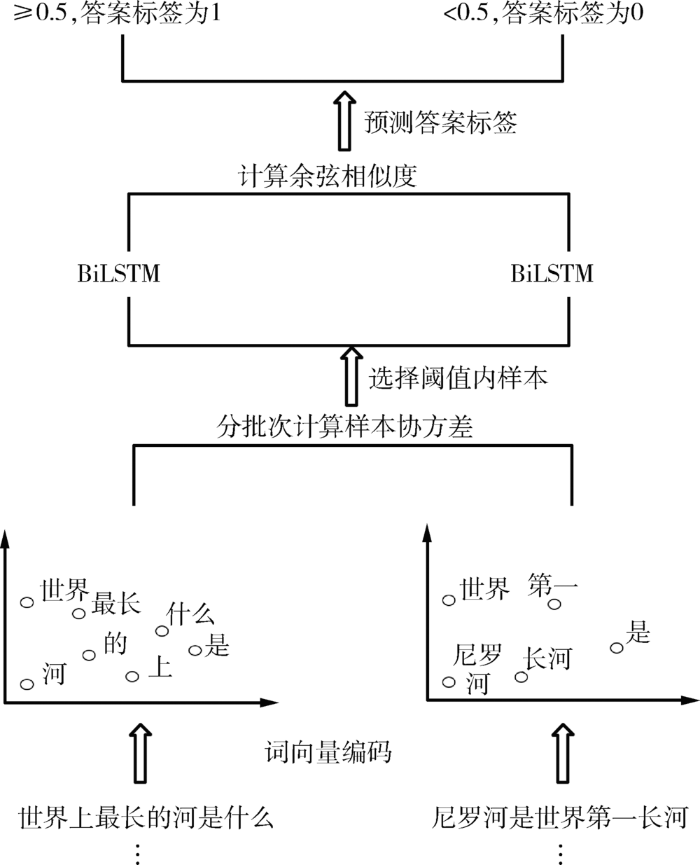
图1
协方差估计样本选择算法应用示例
Fig.1
Example of Covariance Estimator Sample Selection Algorithm
对数据使用词向量进行编码,将词向量数据分批次计算其样本协差阵;在批次内按升序排序,取给定阈值范围内的数据作为神经网络的输入;分别将问题和答案输入两个BiLSTM网络,计算两个输出值的余弦相似度,根据相似度预测答案是否为正确答案。
由于协方差可度量两随机变量相关性的特点,可对数据之间的相似性进行排序。根据Lü等[3]算法的结论,选择相似数据,可保证模型拥有良好的泛化性,不影响模型性能。
4 基于遗忘事件的嵌入式样本选择算法
4.1 遗忘事件
引用Toneva等[8]对遗忘事件的定义。在神经网络训练过程中,给定数据集
当
4.2 遗忘算法
根据训练样本的遗忘性,对样本进行选择,使用遗忘事件的样本训练模型,将基于遗忘事件的嵌入式样本选择算法简称为遗忘算法,其伪代码如下:
Initialize prev_acci = 0 ,i∈D
Initialize forgetting T[i]= 0 ,i∈D
Initialize num_epoch= k
Initialize train_sample= []
While not training done do
for j in range(num_epoch) do
B ~D #B 为一个batch
for example i ∈B do
compute acci
if prev_acci > acci then
T[i]= T[i] +1
prev_acci = acci
#根据Batch的梯度,更新网络
if T[i] > len(num_epoch) do
train_sample.append(T[i])
Return train_sample
在预训练过程中,记录每个样本的遗忘情况,删掉从未发生遗忘的样本,将剩下的样本重新训练模型。也就是删掉神经网络很容易学习到的样本,针对不易学习的样本进行训练,这样既删减了数据,又在一定程度上不影响神经网络的性能。
从人类行为学方面解释,对很容易记住的事情,少花时间学习,在比较难的任务上,多下功夫。
5 实验与分析
5.1 数据来源与处理
(1)选取中国全国大学生数学建模竞赛组织委员会主办的第6届泰迪杯数据挖掘大赛C题所给的训练数据train_data_complete.json①(①
(2)选取2017年NLPCC(Natural Language Processing and Chinese Computing)Shared Task Sample Data的训练数据②(②
(3)选取2018年百度数据集DuReader_v2.0中的FACT和DESCRIPTION数据③(③
(4)设置三个随机数,在以上三个来源的数据集上分别随机选择5万个样本,为保证数据的连续性再选取每个样本的前一个样本和后两个样本,得到20万个样本,最后对选择出的样本去重,得到三个数据集,如表1所示。对每个数据集随机分割为训练集和测试集,比例为9∶1。
表1 本文数据集的描述
Table 1
| 数据来源 | 总样本数量(个) | 正样本数量(个) | 正样本数量/样本数量(%) |
|---|---|---|---|
| 泰迪杯C题训练数据 | 477 019 | 127 328 | 26.69% |
| NLPCC训练数据 | 181 882 | 9 198 | 5.06% |
| 百度 DuReader_v2.0 | 80 485 | 80 485 | 100.00% |
| 以上三个数据集总计 | 739 386 | 217 011 | 29.35% |
| 随机数 1 数据集 | 175 042 | 51 507 | 29.43% |
| 随机数 2 数据集 | 174 537 | 51 507 | 29.51% |
| 随机数 3 数据集 | 174 955 | 52 003 | 29.72% |
5.2 评估指标
使用准确率(Accuracy)、召回率(Recall)和F1指标(F1-Score)作为模型的评估指标,检验问答系统模型的预测能力。准确率即模型预测正确的比例,召回率衡量正样本被预测准确的比例,可以反映出模型较多的信息,评估模型的能力较强[22]。F1是精确率(Precision)和召回率的调和平均。
其中,
5.3 实验结果与分析
选择两种过滤式样本选择算法:基于文档的TF-IDF样本选择算法和设置随机种子选择样本的随机扰动算法,与本文所提两种算法进行对比实验。TF-IDF样本选择算法首先计算问答对的TF-IDF权重值,再选择权重值较小的阈值内样本进行模型训练。随机扰动算法使用随机种子,随机选择固定样本数量的训练集。
本文涉及的超参数以及实验环境如表2所示。
表2 超参数及实验环境配置数值
Table 2
| 参数 | 取值 |
|---|---|
| 遗忘算法预训练epoch | 10 |
| 训练模型epoch | 30 |
| Batchsize/协方差估计批量大小 | 128 |
| 优化算法 | 小批量随机梯度下降法 |
| Dropout | 1.0 |
| 学习率 | 0.1 |
| 句子最大词汇数 | 100 |
| 显卡配置 | GTX 1080 四卡 E5 8核64GB |
(1) 遗忘事件预训练结果展示
使用遗忘算法从样本中选择训练数据,与预训练中训练数据是否发生遗忘事件有关。若样本发生了遗忘事件,则被选择出来作为训练数据。设置epoch=10,得到三个数据集的遗忘事件量与学习事件量的比率如图2所示。
图2
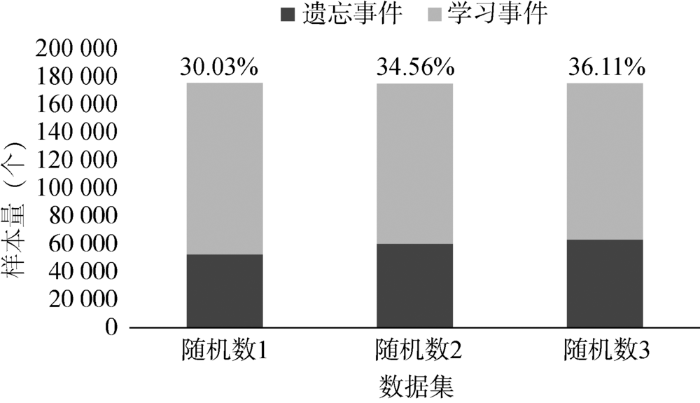
图2
不同数据集遗忘事件量与学习事件量对比
Fig.2
The Amounts of Forgot Events and Learned Events in Different Datasets
可以看到,在三个随机选取的数据集里面,接近66%的数据都很容易被神经网络学习,只有34%左右的数据需被选择出来训练样本。
(2) 实验结果与分析
①随机扰动、TD-IDF、小批量协方差估计在样本选择中遗弃的数据量与阈值有关,由于随机扰动为给定样本数量的随机样本,其参考价值不大,故探究不同阈值对TD-IDF、小批量协方差估计的Accuracy、Recall、F1指标的影响。以随机数1数据集为例,如表3所示。
表3 不同阈值对TD-IDF、小批量协方差估计样本选择算法评价指标的影响
Table 3
| 算法 | 阈值 | Accuracy | Recall | F1 |
|---|---|---|---|---|
| TF-IDF | 0.4 | 0.793 | 0.725 | 0.615 |
| 0.5 | 0.795 | 0.740 | 0.628 | |
| 0.6 | 0.802 | 0.740 | 0.638 | |
| 0.7 | 0.802 | 0.700 | 0.571 | |
| 小批量协方差估计 | 0.4 | 0.796 | 0.733 | 0.623 |
| 0.5 | 0.793 | 0.743 | 0.638 | |
| 0.6 | 0.805 | 0.735 | 0.607 | |
| 0.7 | 0.803 | 0.700 | 0.572 |
其中,阈值为0.4表示选择40%的数据作为训练数据,其余数据丢弃,阈值越小,丢弃数据越多。三个指标在阈值为0.5、0.6达到较高值。同时遗忘算法的训练数据量为34%的数据,故综合模型的有效性以及与遗忘算法的一致性,取阈值为0.5。
②对比使用不同算法的模型所需时间,当阈值取0.5,训练数据为随机数1数据集时,不同算法的使用时间和对应模型训练时间如图3所示。
图3
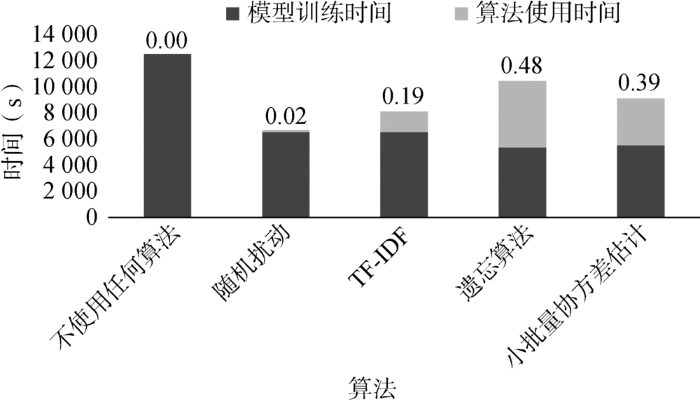
图3
样本选择算法使用时间与模型训练时间对比
Fig.3
Time Comparison Between the Sample Selection Algorithm and Model Training
图3中整个柱长为整体所用时间,小数为算法使用时间与整体所用时间的比例。可以看到随机扰动的算法使用时间最短,遗忘算法的使用时间最长。遗忘算法的使用时间与epoch密切相关,一般来说,模型所需要迭代的epoch越大,其使用时间相对来说会变短。TF-IDF与小批量协方差估计的整体所用时间相差1 328 s,约占不使用任何算法使用时间的16%。同时,可以看到使用样本选择算法后,与不使用任何算法的模型相比,训练时间至少减少一半。
当训练数据为大规模数据集时,由于TF-IDF计算的IDF与整体数据有关,耗时将会陡然增加,而小批量协方差估计方法可以使用并行计算,不同批次计算的样本协差阵互不影响。故对于大规模数据集的模型训练,小批量协方差估计算法在时间上占一定优势。
表4 不同样本选择算法的评价指标对比
Table 4
| 算法 | 数据集 | Accuracy | Recall | F1 |
|---|---|---|---|---|
| 不使用任何算法 | 随机数 1 | 0.802 | 0.750 | 0.653 |
| 随机数 2 | 0.815 | 0.745 | 0.644 | |
| 随机数 3 | 0.819 | 0.755 | 0.660 | |
| 随机扰动 | 随机数 1 | 0.786 | 0.731 | 0.623 |
| 随机数 2 | 0.805 | 0.714 | 0.597 | |
| 随机数 3 | 0.804 | 0.711 | 0.587 | |
| TF-IDF | 随机数 1 | 0.795 | 0.740 | 0.628 |
| 随机数 2 | 0.804 | 0.707 | 0.585 | |
| 随机数 3 | 0.805 | 0.706 | 0.585 | |
| 遗忘算法 | 随机数 1 | 0.797 | 0.740 | 0.637 |
| 随机数 2 | 0.805 | 0.714 | 0.579 | |
| 随机数 3 | 0.800 | 0.736 | 0.631 | |
| 小批量协方差估计 | 随机数 1 | 0.793 | 0.743 | 0.638 |
| 随机数 2 | 0.794 | 0.729 | 0.623 | |
| 随机数 3 | 0.798 | 0.737 | 0.623 |
图4
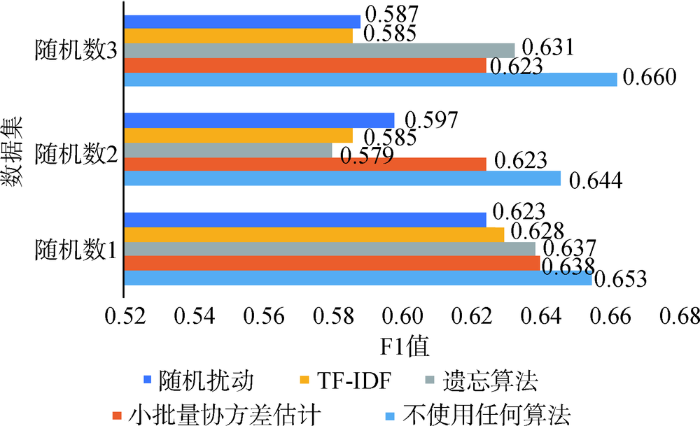
可以看出,小批量协方差估计的F1和Recall在三个数据集上均领先随机扰动和TD-IDF。在随机数1的数据集上,小批量协方差估计使用50%的数据集训练模型,与使用完整数据集的模型相比,F1指标仅相差0.015说明该算法对正样本的预测较为准确。
遗忘算法在三个数据集上,与随机扰动和TD-IDF相比,Recall指标表现优异,同时在1、2数据集上Accuracy指标达到三个算法里面最大值,在1、3数据集上,F1表现优于随机扰动和TD-IDF。综合来看,遗忘算法在使用最少训练数据的情况下,各指标表现优异,对答案的预测较为准确。
综上,面向大规模数据集的模型训练,使用小批量协方差估计的样本选择算法,可以减少模型训练时间,同时对模型的性能影响不大,且对正样本的预测最为准确。当模型训练需要迭代多次时,在对模型性能影响最小的情况下,基于遗忘算法的样本选择算法可以在很大程度上减少训练数据量与训练时间。
6 结 语
本文使用过滤式小批量协方差估计算法和嵌入式遗忘算法,对中文文本数据进行处理。小批量协方差估计算法对输入的词向量数据分批次计算其样本协差阵,通过排序选择相似数据进行训练。遗忘算法在模型预训练过程中记录样本的遗忘性,丢弃从未遗忘过的样本。当训练样本集规模较大时,小批量协方差估计算法的运算速度相对较快;当训练的epoch较大时,遗忘算法在运算时间可以接受的情况下,能减少66%的训练数据量。与其他算法相比,小批量协方差估计算法和遗忘算法的Accuracy、Recall、F1指标均占优势,且几乎不影响模型性能,同时能减少一半的模型训练时间。
小批量协方差估计样本选择算法利用词向量可表示样本的相似性进行样本选择,但如果训练数据为图像,如何应用该算法是未来研究的重要问题之一,同时在其他数据类型中是否有更好的表现也需要进一步验证。
作者贡献声明
刘书瑞:提出研究思路,设计研究方案,实验分析;
田继东:论文起草与修改;
陈普春:实验分析,论文修改;
赖 立:采集、清洗和分析数据;
宋国杰:论文最终版本修订。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据
支撑数据由作者自存储,E-mail: tinnarey@qq.com。
[1] 刘书瑞.train.txt.训练数据.
[2] 刘书瑞.test.txt.测试数据.
[3] 刘书瑞.result.txt.训练结果.
参考文献
特征选择稳定性研究综述
[J].
Survey on Stability of Feature Selection
[J].
Greedy Algorithm for a Training Set Reduction in the Kernel Methods
[C]//
Improving Statistical Machine Translation Performance by Training Data Selection and Optimization
[C]//
Method of Selecting Training Data to Build a Compact and Efficient Translation Model
[C]//
Domain Adaptation via Pseudo In-domain Data Selection
[C]//
McCallum A. Active Bias: Training More Accurate Neural Networks by Emphasizing High Variance Samples
[C]//
Not All Samples are Created Equal: Deep Learning with Importance Sampling
[OL].
An Empirical Study of Example Forgetting During Deep Neural Network Learning
[OL].
Joint Relational Embeddings for Knowledge-Based Question Answering
[C]//
Building a Semantic Parser Overnight
[C]//
Compositional Semantic Parsing on Semi-Structured Tables
[OL].
Scaling Semantic Parsers with On-the-fly Ontology Matching
[C]//
旅游自动应答语义模型分析与实践
[J].
Analysis and Practice of Semantic Model in Tourism Auto-Answering System
[J].
Knowledge-based Question Answering as Machine Translation
[C]//
Semantic Parsing via Staged Query Graph Generation: Question Answering with Knowledge Base
[C]//
Lean Question Answering over Freebase from Scratch
[C]//
特定领域问答系统中基于语义检索的非事实型问题研究
[J].
Semantic Search on Non-Factoid Questions for Domain-Specific Question Answering Systems
[J].
Question Answering over Freebase with Multi-Column Convolutional Neural Networks
[C]//
面向问答系统的信息检索自动评价方法
[J].
Derive MAP-Like Metrics from Content Overlap for IR in QA System
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}