




1 引 言
计量分析人员使用的计量指标大部分是通用的[1,2],在应用这些指标的过程中会添加各种限制过滤条件以满足特定任务需求。将这些指标进行提炼总结,并归纳通用性计算过程,进而开发支持这些通用计量指标计算的系统,可以帮助计量人员从手工计算或者半自动计算中解放出来,将更多的精力投入指标分析中。传统计量分析系统多是以关系数据库为基础构建指标计算系统[3,4,5],虽然也能满足大部分需求,但是往往需要大量计算时间开销和计算硬件投入,限制了相关系统的推广和使用。现有的商业化计量分析平台(如:InCites等)能够满足大部分通用科学计量指标计算的需求,但是这些平台在分析的灵活性方面有所欠缺,比较难于满足用户的个性化定制需求。大数据技术的发展为用户提供了新的可广泛利用且高效计算的技术[5,6],为模块化计算分析平台提供了技术基础。
2 相关研究
InCites[9]提供了基于Web of Science (WOS)数据的计量分析系统。该系统有比较丰富的分析指标和过滤条件,但是由于该系统是面向全球用户的计量分析服务系统,难以满足特别个性化的定制需求,如限制特定ID(数据唯一标识符)范围内的数据进行相关指标分析等。InCites与本研究提供的服务相近,而本研究也参考了InCites的指标定制流程、条件限定等功能。
为满足计量人员个性化、普遍化的计量分析需求,参考业界大数据分析处理技术以及相关系统的服务模式,本研究以分布式大数据存储及分析技术为基础进行计量分析系统研发。
3 系统设计方案
3.1 系统架构
本系统采用三层逻辑架构,如图1所示。
图1
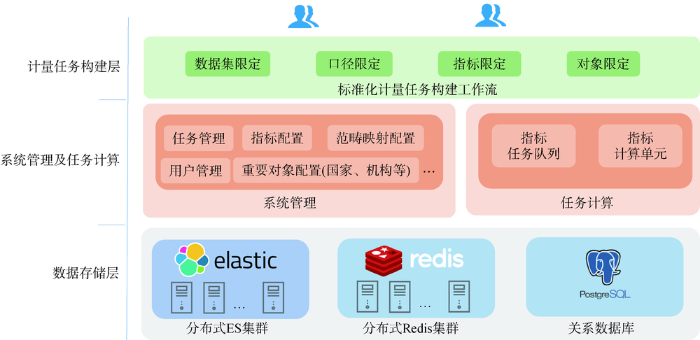
(1)计量任务构建层提供构建分析任务及分析指标的交互界面,用户可以根据研究需要进行数据集限定、计算方案限定、计算对象限定等操作,并构建计算任务及指标。同时也提供不同指标计算结果的呈现和下载等功能。
(2)系统管理及任务计算层实现系统管理配置和指标任务计算。面向普通用户提供任务管理(任务查看、结果查看、任务重启、执行概要等)功能。面向管理员提供指标配置、范畴映射配置、用户管理、重要对象管理(国家、机构等)等功能。任务计算功能包括任务队列构建和指标计算单元等。
(3)数据存储层提供基于大数据技术及关系数据库技术的文献数据、管理数据等的存储及指标计算功能。ES集群和Redis是两种广泛使用的NoSQL数据库,ES提供分布式数据存储和计算能力、准实时数据处理分析能力,是系统提供准实时指标计算的基础;Redis是一种Key-Value数据库,本系统中主要应用其高效的集合计算能力、队列管理及部分预计算结果缓存等功能。关系数据库存储了系统的各种管理数据、配置数据、用户任务数据等各种系统数据。
本研究采用的各种软件均为开放源码软件,具有丰富的文档和成熟的交互社区支持,保障了系统的开放性、稳定性、持续性。
3.2 用户分析任务管理方案
为实现对用户的计量需求进行统一管理和计算,本文设计了通用、可配置的指标构建及计算方案。
(1) 任务指标管理方案
任务指标管理方案如图2所示,将用户的每次分析需求构建为一个计算任务,每个计算任务包含若干指标。每个计算任务记录了本次计算所限定各种条件,包括:数据范围、被引方式、年限、对象等,为本次所有任务指标共享使用;每个指标都继承自通用的指标父类,包含指标计算需要的通用属性;每个指标对应特定的计算逻辑实现及结果展示逻辑,可以通过指标的配置信息找到相应的计算逻辑单元,在结果展示阶段自动找到展示逻辑单元。通过任务+指标的双层结构,实现对用户分析任务的有效管理。计算逻辑的可配置属性为弹性计算提供了计算基础。展示逻辑的可配置性降低了系统开发难度,提高了系统研发效率。用户通过计算任务查看各指标的计算状态,进行计算重启等操作。这种设计方式增强了设计重用性并兼容不同指标的差异性。
图2

(2) 弹性指标计算方案
为满足大量用户指标计算需求,本文设计了生产者(计算指标队列)和消费者(指标计算单元)模式。消费者可以根据指标计算的需求动态增减以满足大批量指标计算需求,如图3所示。
图3
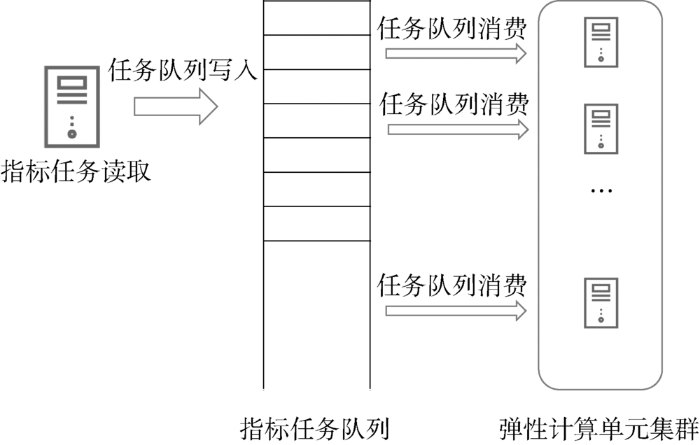
当用户任务产生之后,指标生产者将用户待计算指标推入待计算任务队列当中,消费者则实时读取队列进行消费计算。
弹性计算单元根据任务队列的压力动态增减,以满足用户高效计算任务的需求。得益于底层大数据的伸缩性架构(ES、Redis等),当上层计算单元扩展过多之后同时可能需要底层大数据集群相应节点进行扩展以满足计算需求。
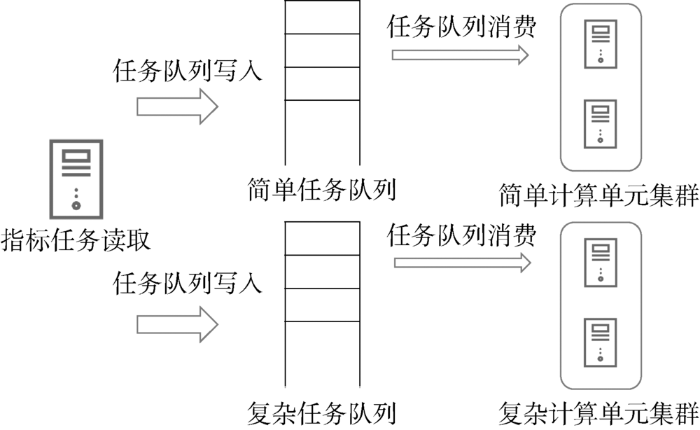
基于这种弹性扩展模式,可以根据需求将不同的指标计算分割成不同的计算队列,以不同的计算单元解决不同的计算任务。队列分割方式计算如图4所示,可将复杂任务单独做一个队列,使用特定处理单元完成特定计算需求。
图4
3.3 指标计算支持
为充分利用大数据技术提供的计算便捷性、实时性,本系统主要通过以下方式将指标计算转化为ES支持的实时性数据运算及Redis集合计算。
(1) 将统计量转化为ES搜索的结果数或聚合函数数量
关系数据指标计算流程与ES计算指标的流程及对比如图5所示。关系数据库计算需要进行多表连接计算,随着限制条件的增加多,表连接开销会逐渐增大,极大地消耗系统资源并降低计算速度。而ES则直接利用索引进行计算,不会随着条件增加而明显降低计算速度。
图5
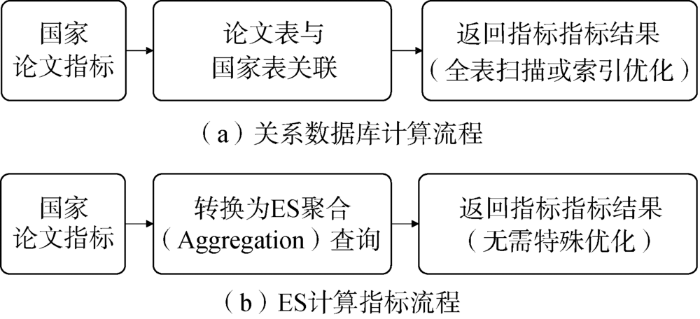
图5
关系数据库计算及ES指标计算
Fig.5
Comparison of Calculation Process Between ES and Relation Database
除了构建直接的检索式之外,还可以使用Script [15]查询动态构建一些灵活查询,例如计算被引基线的时候需要使用多年的累积被引量作为衡量条件,这时使用Script查询可以构建灵活的查询结果。以2007(cited_2007)年、2008(cited_2008)年累积被引量为例,假设需要计算两年累积被引量大于等于20的查询则构建的Script查询是“doc[‘cited_2007’]+doc[‘cited_2008’]>=20”。
(2) 通过预计算加快计算速度
在指标计算过程中,一些指标值会被反复使用,采取预计算并存储这些指标值可以明显加快计算过程,将指标计算在有限步骤中完成。提前计算的指标值包括文献近10年的被引量、近10年的论文基线被引量等。一些特殊标志也在文档中单独提取,如第一作者的国家、机构等信息,通讯作者的国家、机构等信息。这样在计算中可以直接使用这些信息进行检索。
(3) 使用Redis集合支持快速集合运算
Redis作为数据缓存提供了快速获取数据的功能,本系统中除了利用这些常用功能之外,还利用其提供的集合计算功能。在计算一些矩阵指标过程中,矩阵交叉点结果数量需要计算两种结果集合的交集数量。通过Redis的集合操作,可以快速获得矩阵中各交叉点数据。
A、B、C三个国家共引文献量的计算过程如图6所示。将A、B、C三国引用文献ID存储到Redis集合SetA、SetB、SetC中,分别计算集合两两之间的交集数量,如x即为SetA与SetB的交集数量。实际计算中可能涉及更多对象之间的共引形成结果矩阵。
图6

(4) 使用PostgreSQL存储管理数据、配置数据
使用关系数据库可以实现对系统管理配置数据的高效管理。例如用户的任务生成、任务与指标的对应关系、任务的数据源配置、过滤条件配置等;以及系统的一些规范名称、范畴映射等系统配置数据。由于这些数据至多只有几万条,使用关系数据库即可以快速管理。
(5) 基于JSON文本的计算结果存储及使用
由于各个指标的目标不同,计算出的数据结构大部分不能兼容,如果将这些结果完全按照结构化数据进行存储需要设计大量表格,扩展和兼容旧数据非常不便。基于JSON的文本数据可以很好地保存数据的数据结构,最大限度保留数据本身的数据和结构信息。笔者针对各个指标设计了其对应的JSON结构,将计算结果存储到JSON文本中。同时针对不同的JSON结果数据结构,设计对应的可视化展示前台逻辑。
基于JSON的结果存储及使用过程如图7所示。指标的计算结果存储在特定路径的JSON文本中,当需要展示结果的时候,直接将该JSON文本作为数据源传递到页面供展示。
图7
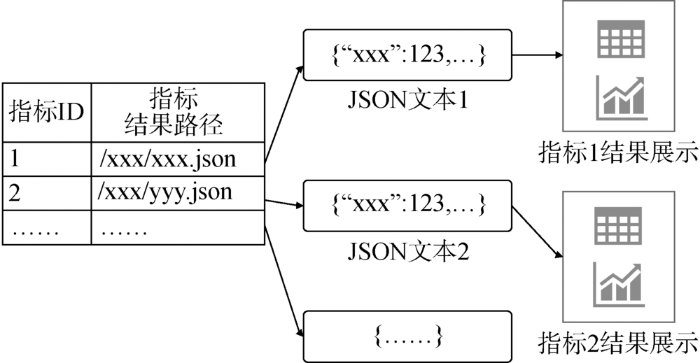
图7
JSON结果存储及使用示意
Fig.7
Demonstration of the Storage and Utilization of the JSON Results
4 实现效果
基于上文的架构设计、任务指标设计、指标计算及展示方案设计,使用WoS的文献及被引数据,实现了科学计量模块化分析平台①(①
4.1 流程化指标构建
图8
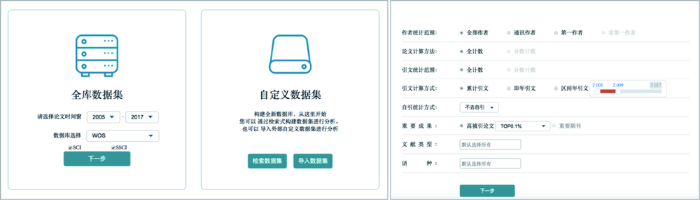
图9
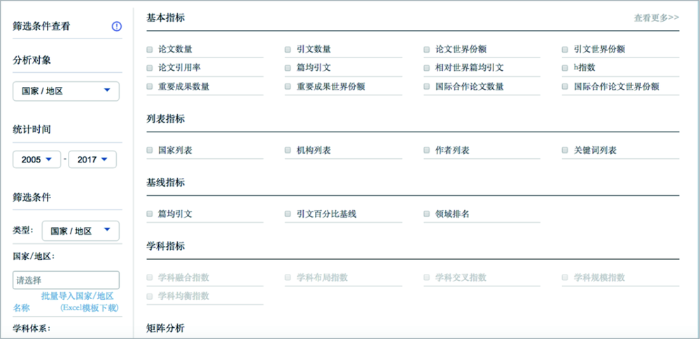
图10
4.2 指标计算结果
每次计算任务的指标计算结果会在展示页面集中展示,用户可以点击指标进行指标结果切换。同时给出指标数据和可视化展示两种方式。用户也可以在页面上对展示结果进行过滤。计算结果展示方式如图11所示。
图11

4.3 指标计算效率
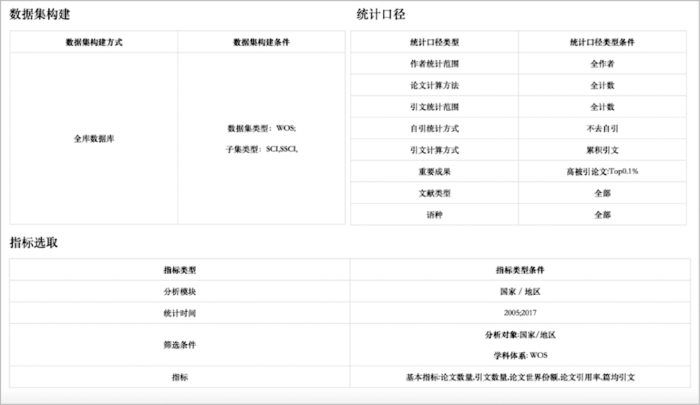
构建检索数据集和分析指标:选择SCI全部数据集,时间窗为2005年-2017年,分析对象选择国家/地区,同时选定5个国家(美国、中国、德国、英国、日本),采用不去除自引的方式计算引文,选择15个指标(分别是论文数量、引文数量、论文世界份额、引文世界份额、篇均引文、相对世界篇均引文、H指数、国际合作论文数量、国际合作论文世界份额、国际合作引文数量、国际合作引文世界份额、自主研究论文数量、自主研究论文世界份额、自主研究引文数量、自主研究引文世界份额)。采用两个逻辑计算单元(分别处理普通指标和H指数指标计算),最终在64秒内计算完毕,单指标平均计算时间为4.3秒,具体结果如表1所示。
5 结 语
利用分布式大数据技术ES及Redis提供的分布式数据存储、分布式计算能力,抽象计量任务的计算模型,设计可配置、可独立计算的逻辑计算单元,配置弹性队列计算框架,实现了灵活、通用、高效的模块化计量分析服务平台。平台为用户提供丰富的数据筛选、条件过滤、计算指标配置等界面接口,完成近实时指标分析,节省用户单独编写处理过程及等待时间。
目前系统已初步具备服务能力,但也存在一些问题。由于ES和Redis分属两套不同系统,当需要将ES的数据结构导入Redis时,需要大量时间。一种解决方案是编写与ES宿主对应的分布式程序,并部署到ES宿主机中读取本地ES结果,但这需要维护一套分布式程序,需要单独开发。同时系统对于用户的个性化对象配置、多数据源数据融合分析等方面还有进一步探索的空间,未来会以此为基础完善丰富系统的相关功能。
作者贡献声明
师洪波:设计研究方案,系统部分代码实现,撰写论文;
郭红梅:提出系统需求,设计指标计算公式;
岳婷:提出系统需求,设计指标计算公式;
钱力:参与系统研究方案设计;
黄定余:系统代码实现;
常志军:ES系统维护及数据导入。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据
支撑数据由作者自存储,E-mail: shihb@mail.las.ac.cn。
[1] 师洪波. count.zip. 指标计算详细实现Java代码.
[1] 师洪波. include.zip. 指标计算结果前台显示代码.
参考文献
The Principles of the Design of the State Scientometric System
[J].
Development of the Chinese Scientometric Indicators (CSI)
[J].
A Computer System for Big Scientometrics at the Age of the World Wide Web
[J].
文献计量学共引分析系统设计与开发
[J].
Development of Co-citation Cluster Analysis System
[J].
大数据系统和分析技术综述
[J].
Survey on Big Data System and Analytic Technology
[J].
大数据分析系统创新平台与生态建设
[J].
Innovation Platform and Ecology Construction of Big Data Analysis System
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}