



1 引 言
在移动互联网和大数据时代,网络社区和社交媒体成为自由、匿名言论的聚集地。越来越多的网民可以在这些网络平台上分享自己的意见、见解和对热点事件的看法,因此这些网络平台每天都会产生海量的文本数据。许多不法分子和极端主义者利用网络平台的匿名性、便捷性和超越时空限制等特性,大肆发表、传播、分享虚假信息或不良言论等情况时有发生,给网络空间安全带来很大影响。此类网络舆情的频发也刺激了网络舆情监测技术的发展,传统的人工监测方式很难适应当前网络舆情的发展趋势。网络舆情监测预警是一个相对繁琐的数据收集和处理过程,主要包括网络舆情信息采集、信息归档分类、文本分析、话题识别、情感倾向判别等[1]。其中,如何及时高效地发现、检测网络社区随时产生的不良言论或虚假信息,是网络舆情监测预警研究中的一个重点研究方向和热点问题。
本文在现有的文本分析技术和文本判别模型基础上,提出一种基于领域语义关系图的短文本实时分析模型。在文本分析知识库和数据来源层面,由已有的词典扩展到网络平台实时产生的文本数据,利用真实网络数据构建相关领域语义关系图,同时实现实时动态更新知识库;在文本分析模型层面,采用具有领域背景的语义关系图作为知识库,并优化文本得分计算公式,实现文本领域语义分析;在系统应用层面,将目前工业界主流的大数据流处理框架Spark Streaming、消息队列Kafka与系统分析模型相结合,对网络社区文本进行实时分析。
对国内外主流的舆情预警系统和相关文本分析模型进行调研。其中,针对网络舆情预警领域中的文本分析问题,国内外主流方法包含以下两类:
(1)基于知识库或词典的文本分析模型,利用相关知识库或词典,结合依存句法分析、词汇类别等,通过合理的词汇得分计算公式,得到文本的情感或舆情得分,从而实现对文本的分析。例如,丁诗晴针对网络评论进行情感倾向分析和主题提取,提高评论的可靠性和有用性[2]。张璐研究基于情感计算的网络社区舆情分析预警模型[3]。严仲培研究在线评论中的情感因素和用户旅游意向之间的关系[4]。杨郁琪利用网络情感词典研究网络用户评论满意度[5]。范宁利用词汇得分计算模型对评论内容进行情感分析[6]。Ramanathan等研究基于领域特定本体的情感分析方法,并分析推特(Twitter)平台中关于阿曼旅游相关的文本,提高针对阿曼旅游情绪分析的准确度[7]。这些研究普遍具备知识库构建快捷方便,分析算法直观易操作等优点;但同时也存在准确度不高,模型普适性较差等问题。
(2)将网络舆情文本分析问题转化为文本分类问题。文本分类是一种有监督的机器学习算法,通过对带标签的训练样本进行学习,建立一个最优模型(函数集合),再利用这个模型对位置数据集进行分类。常见的分类算法主要包含K近邻(KNN)算法、决策树算法、朴素贝叶斯算法、神经网络算法和支持向量机(SVM)算法等[8]。Ramadhani等利用多层深度反馈神经网络对推特平台中的文本数据进行情绪分析[9]。Halibas等采用K-means聚类方法,分析推特中消费者对某商品或服务正面和负面的看法[10]。张祥采用改进后的SVM算法,实现了政务文本分类[11]。这些方法在准确度方面有较大优势;但同时也存在前期训练工作量大、动态更新难度大、分析模型普适性差等问题。
2 整体框架
在调研国内外主流的网络社区文本分析模型后,本文提出一种基于领域语义关系图的短文本实时分析模型。整体研究架构如图1所示。
图1
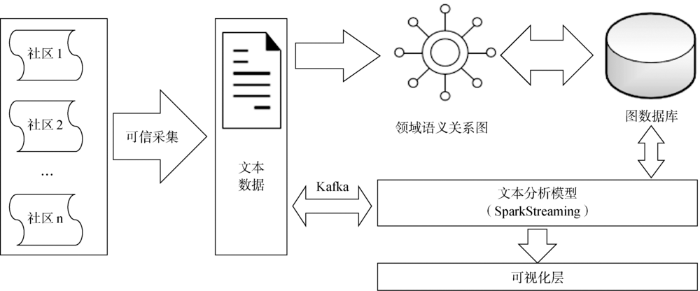
系统结构总共包括5个部分:可信采集模块、领域语义关系图、图数据库、文本分析模型、大数据流处理。详细介绍如下:
(1)可信采集模块:设计安全、可信、可靠的网络社区文本采集策略,采用WebMagic实时获取网络社区开放性平台文本数据;
(2)领域语义关系图:利用可信采集获得的网络文本数据,半自动构建具有领域背景意义的语义关系图,为文本分析模型打下基础;
(3)文本分析模型:基于领域语义关系图,结合优化后的语义计算公式,对网络社区文本进行领域分析;
(4)图数据库:采用工业界主流的图数据库Neo4j,对构建的领域语义关系图进行可信存储,同时实现领域语义关系图的可视化;
(5)大数据流处理技术:采用消息队列Kafka和流数据处理技术SparkStreaming,缩短整体文本分析时间,提高文本分析效率。
3 领域语义关系图
3.1 领域语义关系图设计
在自然语言中,一个词语的含义往往是多样的,在具体语言环境中的功能也往往是多样的,与其他词语的关系更是错综复杂,包括语义关系、依存句法关系等。图是一种非常适合表现这样复杂关系的结构[14]。图由节点和连接节点的弧(或称为边)组成,节点代表不同的个体,弧代表个体之间的关系。图中任意节点之间都可以通过一条弧发生联系,这些弧代表了节点间的各种关系,这使得图可以用来表示复杂的关系网。将表示词语间语义关系的图结构称为语义关系图,基于某一领域知识为主体构建的语义关系图为领域语义关系图。领域语义关系图由表示语义的节点和表示节点间语义关联关系的边组成。
(1) 语义节点
在领域语义关系图中,语义节点由领域要素组成。如人物、机构、地点、专有名词等实体词汇和事件词汇。
语义节点的属性包括两部分:自然属性和领域专属属性。其中领域专属属性用于描述词语在专属领域中所代表的概念或意义。语义节点属性定义如表1所示。
表1 语义节点属性
Table 1
| 词语 | 自然属性 | 领域专属属性 | ||
|---|---|---|---|---|
| POS | Engilsh | 关注指数 | 类型 | |
| 偷窃 | v | steal | 8 | PS(财产安全) |
| 小偷 | n | thief | 6 | PS(财产安全) |
| … | … | … | … | … |
词汇“偷窃”具有自然属性和领域专属属性,其中自然属性有“v”和“steal”;领域专属属性有关注指数“8”,事件类型为“财产安全”。
(2) 语义关系
语义关系是两个或两个以上概念或实体之间有意义的关联,以[概念1]→语义关系→[概念2]这种三元组形式展示[15]。例如地点关系、时间关系、主动关系、被动关系、因果关系等。
语义关系边由两个语义节点和它们之间的语义关系构成,采用三元组方式存储,具体结构为(语义节点1,语义节点2,语义关系R),为有向关系,含义是“语义节点1”和“语义节点2”具有“语义关系R”。以网络平台真实文本数据“今天中午在老食堂二楼吃出一只苍蝇来,当时就恶心吐了,希望领导能多管管呀”为例,结合领域背景知识,可得领域语义关系,如图2所示。
图2
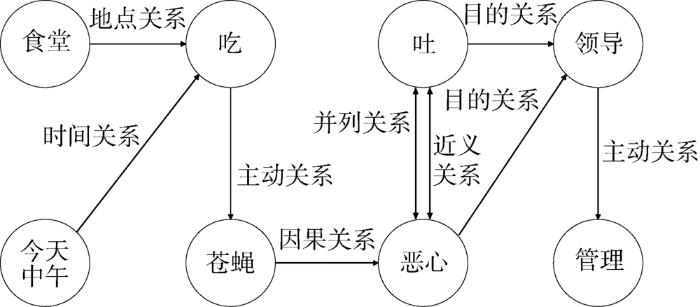
表2 语义关系
Table 2
| 关系起始项 | 关系终止项 | 语义关系 |
|---|---|---|
| 食堂 | 吃 | 地点关系 |
| 今天中午 | 吃 | 时间关系 |
| 吃 | 苍蝇 | 主动关系 |
| 苍蝇 | 恶心 | 因果关系 |
| 恶心 | 吐 | 并列关系、近义关系 |
| 吐 | 恶心 | 并列关系、近义关系 |
| 恶心 | 领导 | 目的关系 |
| 吐 | 领导 | 目的关系 |
| 领导 | 管理 | 主动关系 |
3.2 领域语义关系图构建
领域语义关系图的构建流程如图3所示。
图3
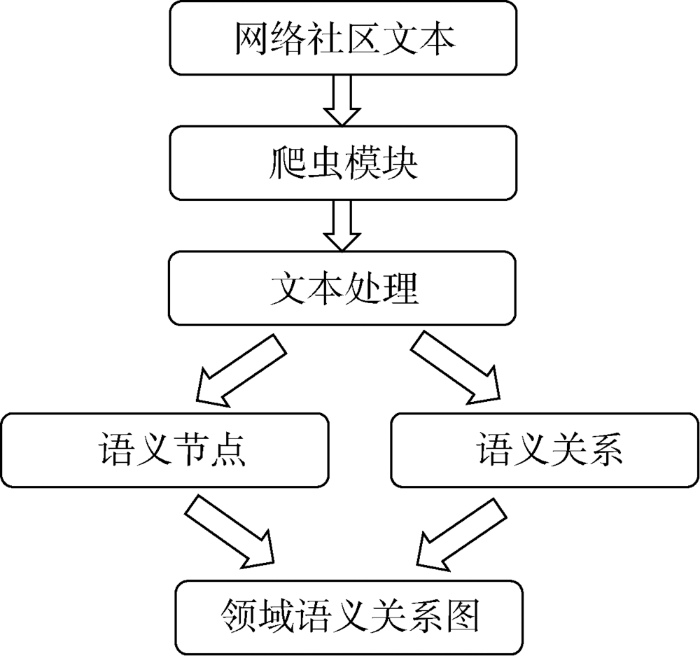
(1)数据源选取:从实际应用场景出发,选择与领域相关网络平台,将这些网络平台的文本数据用作构建领域语义关系图的语料。
(2)爬虫模块:根据对应的网络平台数据源,设计开发具有针对性的网络爬虫方案和策略,实时获取领域相关文本数据。
(3)文本处理:将获取的数据进行去噪、去重等操作,去除其中的非文本数据,筛选出文本数据。针对文本数据,利用HanLP分词工具,将文本拆分为单个词汇,通过词性做初步筛选,主要筛选出其中的动词、名词等,再通过人工筛选,筛选出与领域相关的领域词汇,作为构建领域语义关系图的语料。
(4)语义节点:将文本处理的语料,根据词性分为名词、动词、副词等。根据词汇所属事件类别,采用人工标注方法,对每个词汇进行领域专属属性标注,形成一张语义节点Excel表。导入图数据库中,自动生成领域语义节点。
(5)语义关系:构建语义关系规则,确定同类事件词汇直接相关,相似事件核心词汇间接相关的思维;采用半自动的方式,将语义节点按照类别、词汇属性(人物、地点、事件等)进行分类,并将同类事件词汇中的“人物-事件”、“地点-事件”进行连接;相似事件中,“事件词汇-事件词汇”进行连接。最终生成一张包含语义关系边信息的Excel表。
(6)领域语义关系图:将语义节点的Excel表和语义关系的Excel表,导入Neo4j图数据库,自动生成一张与领域相关的语义关系图,记为领域语义关系图。
3.3 领域语义关系图的自动扩展
虽然领域语义关系图可以反映词汇以及词汇之间所具有的语义关联关系,但是想要穷尽词汇或词汇之间的语义关联关系是不太可能的,同时由于人力、物力以及构造人员知识局限性的限制,构建的领域语义关系图中的词汇和语义关系只是最基本的、很少的一部分。为使领域语义关系图中的语义节点和语义关联关系信息更完整、更全面,需要对构建的领域语义关系做进一步扩展,丰富其中蕴含的语义关联信息。具体的扩充策略如下:
(1)针对新发现的短文本数据,进行文本处理,提炼出其中新出现的领域词汇,并根据领域先验知识,生成领域语义节点;
(2)根据语义关系规则,生成与其他词汇的语义关联关系,作为语义关系边;
(3)将最新生成的语义节点和语义关系边加入到领域语义关系图中。
经过以上处理,实现了对领域语义关系图的自动扩展,丰富了领域语义关系图中的语义节点与语义关系,得到相对完善的语义关系图。在语义关系图的基础上,可以利用图论的相关知识和理论对词语之间错综复杂的语义关系进行处理,实现对短文本数据的语义分析。
4 基于领域语义关系图的短文本实时分析模型
4.1 模型的基本定义
为更好地阐述算法,首先给出算法中涉及到的基本定义和假设。根据实际应用场景,针对语义节点领域属性做如下定义:
定义1 关注指数:用于表示词汇在领域中的关注程度,取值从1到10。关注指数越高,表示该词汇受关注程度越高。词汇i的关注指数记为
根据图论相关知识,给出领域语义关联、语义关联路径及语义关联路径长度的定义:
定义2 语义关联:在领域语义关系图中,如果从节点
定义3 语义关联路径:在领域语义关系图中,两个语义关联的节点之间的路径称为语义关联路径。
定义4 语义关联路径长度:在领域语义关系图中,如果节点
4.2 短文本分析模型
(1) 文本词汇得分
根据定义1可知,在领域语义关系图中,词汇都具有领域专属属性,其中包含关注指数属性。在范宁[6]提出的文本情感倾向计算公式基础上进行如下两点改进:增加词汇的有效次数
其中,
(2) 词汇联合得分
在张仰森等[13]提出的词语语义相关度计算公式基础上,做如下改进:
根据领域语义关系图实际情况,将语义连通路径每条边的权重系数βk赋值为1;同时,加入节点权重系数
其中,
通过公式(2)可以计算得到两个词汇之间的联动得分
①词汇节点间不存在语义关联路径
词汇间不存在语义连通路径分为两种情况,第一种为存在至少一个词汇不属于领域语义关系图时,此时词汇间不存在领域语义关联,语义关联路径长度
②词汇节点间存在语义关联路径
词汇节点间存在语义连通路径,则说明两个词汇均存在于领域语义关系图中,且存在至少一条路径使语义节点相互连通。此时,可通过词汇关注指数和词汇间语义关联路径长度计算得到词汇联动得分。当词汇间出现多条语义关联路径时,
(3) 短文本领域得分
文本是由语句构成的,语句是由词汇及其句法关系构成的。通过对文本词汇分析,词汇关联分析,从一定程度上可以实现相关领域的语义分析。设置可调节的权重系数
其中,
(4) 归一化处理
由于网络文本数据存在长度不一、语句数量不确定,导致不同文本最终得分存在较大差异。因此,可以对文本领域总得分进行归一化处理,将文本总得分控制在[0,1]。采用非线性回归模型中的指数函数模型,并将最大值设为1,得到归一化处理如公式(4)所示。
其中,
由公式(1)-公式(4)可得文本的领域归一化得分。文本中包含的词汇数量越多,包含的词汇领域关注指数越高,词汇间存在的语义连通路径越短,此时文本的领域归一化得分越高。
基于领域语义关系构建短文本实时分析模型,具体过程描述算法如下。
输入:领域语义关系图G,短文本数据
输出:短文本领域得分
①对短文本进行分句操作,按照汉语言的习惯,将文本按照标点符号例如{。?!~;}等进行分句处理。得到短文本语句集合A,其中语句个数为n;执行步骤②和步骤④。
②遍历语句集合A,针对每个语句,进行分词操作,将分词的结果进行存储,得到包含所有词汇的数组B,执行步骤③。
③遍历词汇数组B,查询每个词汇在领域语义关系图中的关注指数,如果该词汇存在于领域语义关系图中,则返回该词汇的关注指数;如果不存在则返回数值0。通过公式(1)得到该文本的词汇得分Sw,执行步骤⑤。
④遍历语句集合A,针对每个语句,进行依存句法分析,得到依存句法关系树。遍历依存句法树中的主谓关系、动宾关系等涉及到的词汇,利用公式(2)计算得到词汇的联合得分Sr,执行步骤⑤。
⑤将步骤③、步骤④得到的Sw、Sr,通过公式(3)和公式(4)计算得到文本的领域总得分并归一化。
5 实验验证
5.1 高校学生舆情领域语义关系图
以高校学生舆情领域为实验对象,采集数据源包括水木清华、北大未名、向北航行等55个网络社区,和微博、知乎、贴吧等31个社交平台。基于WebMagic,结合对应网络社区网页结构,开发爬虫程序,自动化获取网络社区文本数据。截至2019年4月10日,总计采集文本数据478 303条,通过人工筛选,提炼出与高校学生舆情相关的文本数据81 427条,构建了包含5 248个节点,16 488条边的高校舆情领域语义关系图,局部截图如图4所示。
图4
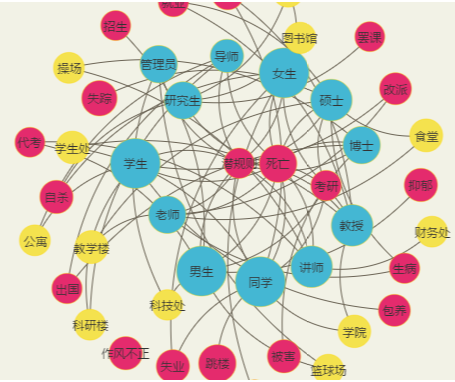
图4
高校舆情领域语义关系图(局部)
Fig.4
Part of the Semantic Diagram of University Public Opinion
5.2 实验测试数据集
为保证实验的可信性、有效性和客观性,采用实际网络平台作为实验数据采集源。从5.1节数据源中,自2019年4月11日至2019年4月20日,共计获取文本数据40 000条。采用人工标注方式,将该文本数据中与高校学生舆情领域相关的文本数据记为领域相关文本,其他记为非领域相关文本。将标记后文本数据集分为训练集和测试集,如表3所示。
表3 实验数据集统计表
Table 3
| 数据集 | 领域相关文本数量 | 文本总数量 |
|---|---|---|
| 训练集 | 7 350 | 20 000 |
| 测试集 | 6 840 | 20 000 |
5.3 文本分析模型验证
(1) 阈值选取实验
对领域文本判别阈值A的选取进行验证。利用5.2节建立的实验测试数据集作为数据输入源,将高于阈值A的文本判别为与领域相关文本,将低于阈值A的文本判别为与领域无关的文本。文本准确度与阈值A的关系如图5所示。
图5
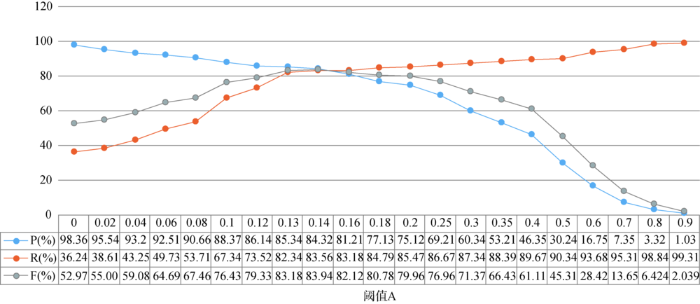
由图5可知,当阈值A=0.14时,F值取得最大值83.94%,则认为0.14是判断文本是否与领域相关的最合理阈值。在[0.14,1]范围内,F值随着阈值A的增加而减少。此阶段中,由于阈值A的持续增加,提高了领域文本的查全率。但阈值的不断增加,让越来越多与领域相关的文本被标识为非领域相关,降低了领域文本的准确率,最终导致F值不断下降。
(2) 文本分析准确度
采用目前界内准确度较好的支持向量机(SVM)方法、朴素贝叶斯(NB)方法和基于深度学习卷积神经网络(CNN)方法作为对比,采用5.2节标记的训练集对以上方法进行训练。最终使用准确率P、查全率R和F值作为评价指标。基于领域语义关系图的文本分析模型判别阈值设为0.14。结果对比如表4所示。
表4 准确度对比
Table 4
| 测试方法 | P(%) | R(%) | F(%) |
|---|---|---|---|
| SVM | 78.23 | 72.35 | 75.18 |
| NB | 76.36 | 79.24 | 77.77 |
| CNN | 80.64 | 78.35 | 79.47 |
| 本文短文本实时分析方法 | 84.32 | 83.12 | 83.74 |
由表4可得,本文所提方法在准确率、查全率和F值方面都有一定程度的提升。其中,相对于SVM、NB、CNN,本文方法在F值方面分别有8.56%、5.97%、4.27%的提升。
(3) 短文本实时分析速度测评
表5 时效性测评
Table 5
| 测试方法 | 数据流量(篇/秒) | 延迟时间(秒) |
|---|---|---|
| 实时主题检测TopicSketch | 50 | 0.71±0.5 |
| 本文短文本实时分析方法 | 22 | 1.36±0.4 |
由表5可得,本文方法的文本处理效率虽然达不到TopicSketch方法的处理速率(每秒获取文章50篇和每篇文本的平均延迟时间0.71±0.5秒),但是能够达到秒级,可以满足实时处理的基本需求。由于在文本数据领域得分计算过程中,需要频繁查询图数据库Neo4j,导致文本处理时间较长。
6 结 语
本文提出一种基于领域语义关系图的短文本实时分析模型。该模型从相关网络平台中获取与领域相关的文本数据;通过对文本数据进行分析处理,提炼出领域关注的实体和事件,并结合领域背景知识,构建具有领域专属属性的语义关系图。该图由领域语义节点和语义关系边构成,为短文本分析提供了一种有效的处理方式。实验表明,基于领域语义关系图的短文本分析模型可以有效地识别短文本中包含的领域关注词汇、实现对文本领域相关性的判别。本文在网络舆情分析中引入领域语义关系图实现语义分析,提出的语义关系图目前尚无法完全自动构建,需要花费大量的时间和人力进行相关领域属性标注等工作,后期可研究利用分类思想结合自然语言处理技术实现自动化构建领域语义关系图。另外,目前领域语义关系图的扩充需要辅助人工判别,后期可以尝试建立更加完善的反馈机制,在满足网络舆情准确度需求的前提下,实现领域语义关系图的自动扩充。在建立自动化构建领域语义关系图机制的基础上,可继续尝试建立完善的网络舆情判别分析反馈机制,将最新的分析结果作为输入,持续扩充领域语义关系图。
作者贡献声明
田钟林:提出研究思路,设计研究方案,实验验证,论文起草;
许晋,颉夏青:网络社区文本数据处理,人工标记领域相关文本数据;
吴旭,陆月明:论文最终版本修订。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据
支撑数据由作者自存储,E-mail:18810692507@163.com。
[1] 田钟林.高校舆情领域语义关系图.png.
[2] 田钟林.阈值A实验数据结果.xlsx.生成图5的实验数据.
参考文献
网络舆情研究综述:从理论研究到实践应用
[J].
A Review of Network Public Opinion: from Theoretical Research to Practical Application
[J].
基于在线网站评论的中文文本挖掘
[D].
Chinese Text Mining Based on Online Customer Review
[D].
基于情感计算的网络社区舆情分析预警技术研究
[D].
Analysis and Early Warning Technology Research Based on Affective Computing in Online Community
[D].
面向旅游在线评论的文本挖掘方法研究
[D].
Research on the Method of Text Mining for Travel Online Comments
[D].
基于文本挖掘的用户满意度影响因素研究
[D].
Study on the Influencing Factors of User Satisfaction Based on Text Mining
[D].
基于文本挖掘在民宿满意度中的研究
[D].
Research on Satisfaction of Homestay Based on Text Mining
[D].
Twitter Text Mining for Sentiment Analysis on People’s Feedback About Oman Tourism
[C]//
网络舆情分析系统中关键技术研究
[J].
Research on Key Technologies in Network Public Opinion Analysis System
[J].
Twitter Sentiment Analysis Using Deep Learning Methods
[C]//
Application of Text Classification and Clustering of Twitter Data for Business Analytics
[C]//
面向政务需求的网络舆情分析方法研究
[D].
Research on Public Opinion Analysis Method of the Network for the Needs of Government
[D].
一种基于语义关系图的词义消歧算法
[J].
Word Sense Disambiguation Algorithm Based on Semantic Relation Graph
[J].
一种基于语义关系图的词语语义相关度计算模型
[J].
A Model for Calculating Semantic Relatedness of Words Considering Semantic Relationship Graph
[J].
《知网》语义关系图的自动构建
[J].
The Automatic Construction of Lexical Semantic Graph Based on HowNet
[J].
图书馆工作与研究
[J].
The Concepts and Types of Semantic Relations in Information Organization
[J].
Topicsketch: Real-time Bursty Topic Detection from Twitter
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}