1 引 言
类似于电商中用户关于某类产品的评价,在线医疗社区中也包含患者对于现实医疗服务的评价数据,对这些患者评论数据的主题进行有效的识别与归纳,在为社区其他患者提供就医参考咨询的同时,也能够帮助医疗服务提供者有针对性地改善医疗服务[1 ] 。但是在应用基于监督学习的方法进行患者评论识别时,会面临以下问题:语料库样本数据标签的不均衡问题[2 ] ;文本分布式表示问题[3 ] ;语义特征抽取问题等[4 ] 。鉴于此,本研究提出一种基于混合采样与迁移学习的患者评论识别模型。混合采样技术能够保证不均衡样本中正负样本比例失调的问题,同时本文引入迁移学习的思想,将均衡样本中学习到的知识迁移到不均衡样本的知识学习中,从而提高相应主题识别模型的效果。另外采用Word2Vec与卷积神经网络相结合的端到端深度学习架构解决文本分布式表示、特征提取与模型训练的问题,从而提升模型的整体预测能力。
2 相关研究
2.1 评论识别模型
患者评论识别在自然语言处理领域通常可以看作文本挖掘的过程,就技术而言,当下流行的方法可以划分为基于无监督学习和有监督学习的方法[5 ] 。有研究者通过N-gram模型结合UMLS超级叙词表对患者评论文本进行术语抽取,并用期望最大值(Expectation Maximization, EM)算法对术语集合进行主题聚类[6 ] 。此外也有研究者采用LDA主题模型对在线患者评论主题进行识别[7 ] 。在无监督学习中,研究者将评论文本中的词语单元按照某种指标进行聚类或者以特定概率分布的主题模型进行主题划分,然而实际中单纯的主题聚类会面临一些问题,诸如:
基于有监督学习的文本挖掘方法通常被看作文本分类的过程,需要研究者事先构建相应的语料库,然后将文本内容与标签分别进行向量化表示,以供特定的算法进行特征提取与模型训练。从现有研究来看,基于有监督学习的患者评论识别研究是远远少于基于无监督方法的。Rivas等[8 ] 从收集的患者评论文本中随机抽样600条评论,按照10类主题进行标注,并采用支持向量机、卷积神经网络、随机森林以及基于依存树分类器(Dependency Tree-Based Classifier, DTC)算法建立各个主题的分类模型,选出效果最优的模型用于主题识别。
2.2 样本采样技术
非均衡数据从形式上可以表述为小类样本(正样本)与大类样本(负样本)的比例失衡问题。在对非平衡数据进行批量训练时,由于不能很好地捕捉到低比例样本的信息,从而导致小类样本的召回率偏低。然而这些小比例的正样本往往具有重要的现实意义,比如欺诈监测中的欺诈样本,疾病预测中的疑难疾病等[9 ] 。当前的研究主要从样本采样和算法改进两个层面处理数据不均衡问题。样本采样是通过对训练样本集进行重构以解决数据不均衡的问题,主要是增加或减少某类样本的数量来达到降低样本偏倚的目的,从而有效地对小类样本进行分类。重采样的方法大体分为过采样(Over Sampling)与欠采样(Under Sampling)两类。前者通过增加小类样本的数量平衡数据集中的样本分布,而后者则是通过减少大类样本的数量平衡数据集中的样本分布。
欠采样中常见的算法包括:基于随机欠采样(Random Under Sampling)的方法、基于最邻近编辑规则(Edited Nearest Neighbor)[10 ] 的方法、基于单边采样的方法[11 ] 等。虽然欠采样的方法可以在一定情况下解决样本不均衡的问题,但是在实际中往往会丢失大类样本中较多的信息,而这些被忽略掉的大类样本中可能包含较为重要的信息,从而无法有效保证模型分类的准确性[12 ] 。基于SMOTE的方法是过采样技术中主流的算法[13 ] ,主要通过样本与其连线上的样本随机生成样本点来平衡样本,这种方法可以有效解决随机采样带来的过拟合问题,但是也会带来一定的样本重叠问题。部分学者在这种算法的基础上做出一定改进,比如对边界情况[14 ,15 ] 进行考虑等。
2.3 迁移学习技术
迁移学习是将现有领域知识进行跨领域求解的一种机器学习方法。按照输入空间与输出空间的不同,迁移学习可以划分为同构空间的迁移学习与异构空间的迁移学习[16 ,17 ,18 ] 。而按照内容的角度,迁移学习则包含基于特征迁移[19 ,20 ] 、基于参数迁移[21 ] 、基于实例迁移[22 ] 以及基于关联迁移[23 ] 。迁移学习在传统机器学习领域得到较为广泛的应用,特别是较多地应用于图像处理[24 ,25 ] 领域,在自然语言处理领域,尤其是面向不均衡数据源,探索与应用还较少。本文引入迁移学习的思想,将均衡样本中学习到的知识迁移到不均衡样本的知识学习中,以提升不均衡样本分类的效果。
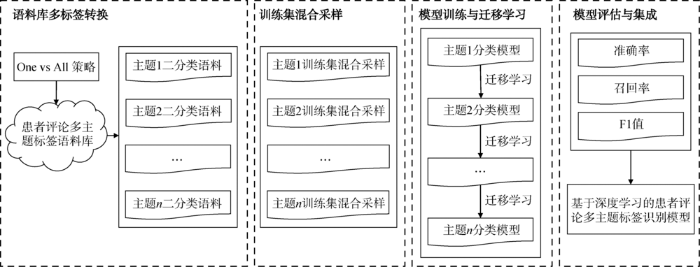
3 研究框架设计
图1
图1
基于混合采样与迁移学习的多主题标签识别框架
Fig.1
Recognition Framework of Multi-label Data Based on Mixed Sampling and Transfer Learning
(1)语料库多标签转换,将语料库中评论多主题标签数据转换为各自主题的正/负样本数据;
(2)训练集生成批数据时对大类样本与小类样本混合采样,平衡不均衡样本中正/负标签比例失调的问题;
(3)模型训练与迁移学习,对均衡样本进行模型训练,并将均衡样本中学习到的知识迁移到不均衡样本的知识学习中;
(4)以准确率、召回率、F1值为指标评估模型效果,并将各自主题的分类模型进行集成,用于患者评论识别。
3.1 语料库多标签转换
本文使用的患者评论语料库是多主题标签的,即一条评论对应多个主题标签。要将语料转换为可供算法训练的形式,首先要考虑多标签转换的问题。One-vs-All的策略是文本多标签分类中的常用方法,其核心思想是将多标签的训练集转换为各自标签的单个数据集,对应到每条数据中则为该标签的正/负样本,以此分别训练单个标签的二分类器,每个分类器对各自标签的正/负样本进行分类。在模型集成时,每个单独的二分类器会以此对未知样本进行预测,如果结果为正,则添加到预测标签集中。
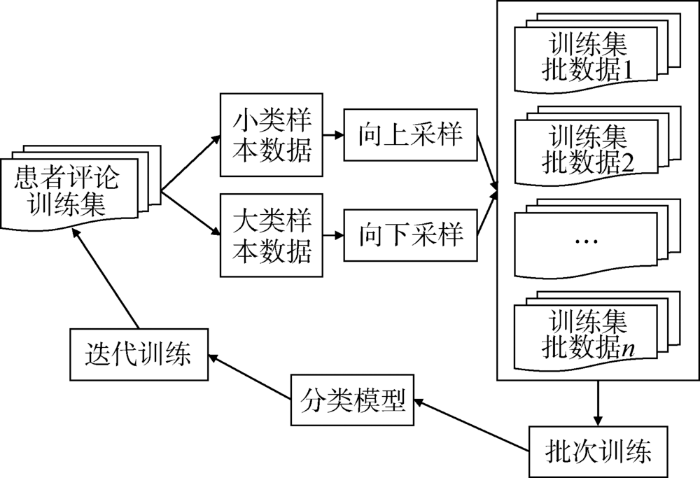
3.2 训练数据混合采样
本文所提出的混合采样的基本思想是在训练集生成批数据(Batch Data)时分别对小类样本、大类样本进行采样,具体过程如图2 所示。
图2
图2
混合采样过程
Fig.2
Mixed Sampling Process
假定某一主题的原始训练集为 D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( x n , y n ) } , x i ∈ X ⊆ R n y i ∈ { C P , C n } C P C n N 。
(1)将原始训练集拆分为小类样本集合 y i = C P y i = C n
(2)设定小类样本的采样数为 M 1 M 1
(3)设定大类样本的采样数为 M 2 M 2
(4)采集的每一个批数据大小为 M 1 + M 2 N M 1 + M 2
(5)训练集迭代训练,重复步骤(1)-步骤(4),直到模型收敛。
3.3 小样本迁移学习
除了采用混合采样的方式处理不均衡数据中正/负样本比例失调的问题,本研究也引入迁移学习的思想,用于小样本主题数据集的模型训练。基本思想是通过迁移学习使得不均衡样本能够学习到与其相近的均衡样本中的领域知识,从而使得模型更快地收敛,提高模型预测的准确率。其具体过程可以表述为:
(1)对于多主题标签语料库 D = { ( x 1 , y 11 , y 12 , … , y 1 j ) , ( x 2 , y 21 , y 22 , … , y 2 j ) , … , ( x i , y i 1 , y i 2 , … , y ij ) } , x i ∈ X ⊆ R n y ij ∈ { C 1 , C 2 , … , C K } K 为主题标签类型的个数,对于任意 C i , C j N ( C i , C j )
(1) N ( C i , C j ) = ∑ ( x i , y i 1 , y i 2 , … , y ij ) ∈ D I ( C i , C j )
(2) I ( C i , C j ) = 0 , C i ∉ ( x i , y i 1 , y i 2 , … , y ij ) or C j ∉ ( x i , y i 1 , y i 2 , … , y ij ) 1 , C i ∈ ( x i , y i 1 , y i 2 , … , y ij ) and C j ∈ ( x i , y i 1 , y i 2 , … , y ij )
(2)对于二分类数据集合 { D 1 , D 2 , … , D k } D i C i C i C j C j D j Model ( D j )
(3)以 Model ( D j ) C i D i
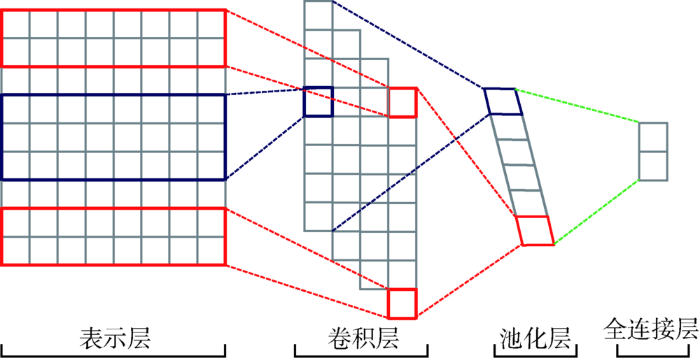
3.4 端到端卷积神经网络
在传统机器学习中,文本分类任务往往是由多个独立的模块构成,诸如文本表示、特征提取、模型预测等,每一个模块对应独立的步骤,其结果的好坏都会影响到最终模型预测的结果。而在深度学习中,则将数据从输入端到输出端整个过程连接为一个整体,模型最终的训练会得到相应误差,这个误差信号会在深度网络的各层间传递,每一层也会由此做出相应调整,这种过程可以看作端到端学习(End-to-End Learning)[26 ] 。本文所采用的端到端的卷积神经网络(Convolutional Neural Network, CNN)如图3 所示,由表示层、卷积层、池化层与全连接层组成[27 ] 。
图3
图3
基于端到端卷积神经网络的患者评论识别模型
Fig.3
Patient Reviews Recognition Model Based on End-to-End CNN
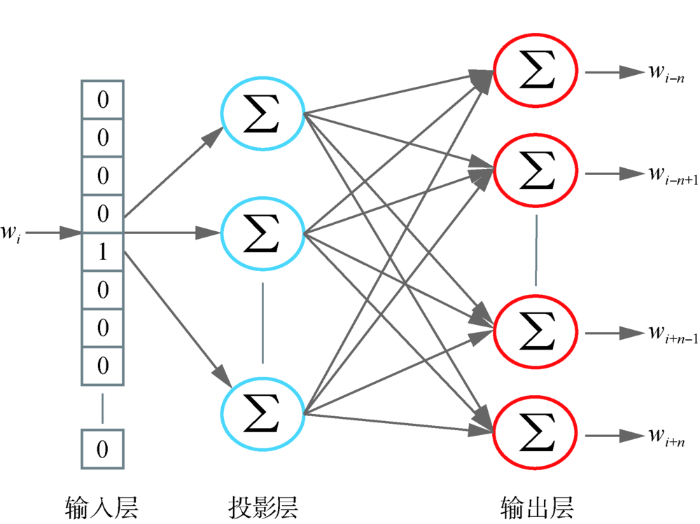
Word2Vec的思想解决了基于词袋模型(Bag of Words)中高维度、高稀疏、低语义的问题,在自然语言处理领域取得了很好的效果[28 ] 。本文采用Skip-Gram的词向量模型,其核心思想是用文档中的词 w i n 内上下文的词 { w i - n , w i - n + 1 , … , w i + n - 1 , w i + n } 图4 所示。利用该模型在大规模语料上训练词语的向量化表示,保留模型中投影层的权重矩阵,即对应于词 w i
图4
图4
Skip-Gram词向量模型
Fig.4
Skip-Gram Model
卷积层是对输入层的二维文本矩阵进行卷积操作,给定文本矩阵 V ∈ R n × d W ∈ R m × d n 为文本中词语个数, m d m X i : i + m - 1 ∈ R m × d f ( ) W X i : i + m - 1 m b
(3) C i = f ( W • X i : i + m - 1 + b )
随着卷积核在文本矩阵上移动平滑,这个过程生成较多的特征映射,并通过连接操作形成特征映射矩阵,如公式(4)所示。
(4) F i = [ C 1 , C 2 , … , C n + m - 1 ]
文本矩阵通过多个不同大小卷积核进行卷积操作后会产生多维的特征向量矩阵,通常具有较高的维度,难以直接用于分类。在此需要通过池化层进行降维并捕捉重要语义特征的处理。本文采用最大池化(Maximum Pooling)操作。其计算过程如公式(5)-公式(7)所示。
(5) x i = Down ( F i )
(6) Y i = max ( x i )
(7) Y i ' = f ( ω i · Y i + b i )
其中,对于每一个特征映射 F i x i Y i f ( ) ω i b i Y i '
表示层、卷积层以及池化层都是将文本原始数据映射到隐层空间并进行特征提取,而全连接层则是为了将隐层中的特征映射到文本标签空间,即解决最终的文本分类问题。在此采用Softmax回归,如公式(8)所示。
(8) p ( y = c | x ) = softmax ( w c T x + b c ) = exp ( w c T x + b c ) ∑ c C ( w c T x + b c )
其中, x y ∈ { 1,2 , … , c } w c T b c p ( y = c | x ) x c
本文中是两类标签,所以Softmax回归的决策函数如公式(9)所示。
(9) y ̂ = argmax y ∈ { 0,1 } ( exp ( w y T x + b y ) )
计算损失时采用交叉熵损失,训练方式采用随机梯度下降的方法更新模型参数,同时为防止过拟合,在全连接层进行Dropout与L2正则化优化。
4 实验过程与结果分析
4.1 实验数据
本研究采用的数据是笔者所在实验室标注的患者评论私有数据集,数据来源于微医网中患者就诊后的评论数据,具体描述如表1 所示。其中,“态度”代表患者对就医过程中医生态度、医德等主观性服务评价;“能力”代表患者对就医过程中医生医术、经验、水平等客观性能力评价;“措施”代表患者对就医过程所接受的诸如检查、手术、用药等具体医疗措施的评价;“效果”代表患者对就医过程医疗效果的评价;“环境”代表患者对医院的软硬件环境的评价;“费用”代表患者对就医花费的评价。
除此之外,引入不均衡率(Imbalance Ratio, IR)表征数据集标签的不均衡程度[29 ] ,IR值为实验数据集中大类样本标签与小类样本标签的比值。以此为依据,设定态度、能力、措施、效果主题标签所在数据集为大类数据集,环境、费用主题标签所在数据集为小类数据集。小类数据集中主题标签与大类数据集中标签的共现频次如表2 所示,其中环境与态度、费用与措施的共现频次分别在各自组中最高。以此为依据,选择态度主题数据集训练的模型为环境主题迁移学习的原始模型,措施主题数据集训练的模型为费用主题迁移学习的原始模型。
4.2 模型参数设置与效果评估
表示层中,采用自训练的领域文本词向量,数据源为笔者所在实验室所采集的281 339条患者就诊后评论文本,词向量的训练参数如表3 所示。卷积神经网络卷积层、池化层、全连接层参数如表4 所示。
为有效地评估分类器的分类效果与泛化能力,选用10折交叉验证法,将训练样本集随机分为10份大小相等的互斥子集,每次以其中1份作为测试集,余下7份子集的并集作为训练集,2份子集的并集作为验证集,在此基础上测试10次实验结果,并以测试结果准确率(Precision)、召回率(Recall)、F1值的平均值为模型性能的度量指标。
4.3 结果分析
不同主题数据集分类模型的准确率、召回率、F1值分别如表5 -表7 所示。
相比于以SVM为代表的机器学习算法,本文的端到端卷积神经网络深度模型在大部分主题分类任务上取得了较好的效果,特别是对于不均衡样本数据的分类任务。深度学习模型相比SVM,在准确率、召回率以及F1值上都有明显的提升。相比单一的CNN模型,本文提出的混合采样方法主要是通过提升样本预测的召回率,从而提升模型的整体分类效果;而采用迁移学习的方法相比于单一的CNN模型在准确率、召回率上都有明显提升,因而整体的分类效果得到提升。在此基础上,本文基于混合采样与迁移学习的分类模型(CNN+MS+TL)相比其他模型取得了更好的分类效果(环境主题F1值0.7724,费用主题F1值 0.7124)。
(1)传统机器学习模型进行分类建模时,特征表示、特征提取以及特征学习的过程是相互割裂的,不能很好地表示文本语义特征,进行相应处理的过程中也会丢失很多重要的语义特征,从而分类效果不理想。而本文采用的深度学习网络是一个端到端的模型,输入端为文本的整体分布式表示信息,通过卷积神经网络进行语义特征的抽取,在全连接层进行分类预测,整个模型由深度网络模型自主调控,减少了人为干预所产生的语义丢失等问题,所以能够获得更好的预测效果。值得注意的是,SVM模型在态度主题上取得的效果与CNN相接近,态度主题数据集中大部分文本会直接涉及态度一词,而SVM模型由此能够很好地捕捉浅层次语义信息,构建对应的支持向量,从而取得很好的效果,由此也反映出以SVM为代表的传统机器学习模型相比深度神经网络,对于深层次语义信息的捕捉能力更为薄弱。
(2)采用混合采样技术,在训练集通过对小类样本、大类样本的分开采样,有效保证批数据训练时样本的均衡性,能够使得模型更多地关注小类样本,捕捉其中的语义信息,从而有效提升小类样本的召回率,以此提升模型的整体预测能力。
(3)本文引入迁移学习的思想,在均衡样本数据上训练模型,并作为不均衡样本的初始化模型。通过统计标签的共现情况,发现环境主题-态度主题,费用主题-措施主题具有很高的共现频次,符合患者实际的语用环境,所以在进行迁移学习时均衡样本的领域知识对不均衡样本的学习是有效的,从实验结果来看也是一致的。
5 结 语
对于患者评论识别中的样本不均衡问题,本文提出一种基于混合采样与迁移学习的方法,并采用端到端的卷积神经网络进行建模与预测,混合采样能够使得模型有效地关注不均衡样本中的小类样本数据,以学习到其中的语义信息;迁移学习能够使得不均衡样本数据的分类模型学习到均衡样本数据中的近似领域知识;端到端的卷积神经网络能够以词向量嵌入的形式对文本进行分布式的表示,作为模型的输入,并将输入层、特征提取层、预测层纳入整体的模型中,从而捕捉文本中的深层次语义信息。实验结果显示,本文方法在准确率、召回率以及F1值上都有很好的提升,表明该方法是切实可行的。
本研究的局限在于:一是采样方法可以进一步完善,比如考虑在批次训练时根据模型对样本预测置信度动态更新采样概率;二是为了更好证明混合采样和迁移学习方法对不均衡数据的处理效果,需要进一步在公开数据集上进行验证。在未来的研究中将针对这几个方面对深度模型与采样方法进行优化,并采用本文所提方法与人工监督相结合的方法对语料库进行扩充。
支撑数据
支撑数据由作者自存储,E-mail: shelton@hust.edu.com。
[1] 谢耀谈.annotation.csv.患者评论主题语料库.
[2] 谢耀谈.实验结果.xlsx.模型训练结果统计.
参考文献
View Option
[1]
Hao H Zhang K Wang W , et al . A Tale of Two Countries: International Comparison of Online Doctor Reviews Between China and the United States
[J]. International Journal of Medical Informatics , 2017 ,99 :37 -44 .
[本文引用: 1]
[2]
陈旭 , 刘鹏鹤 , 孙毓忠 , 等 . 面向不均衡医学数据集的疾病预测模型研究
[J]. 计算机学报 , 2019 ,42 (3 ):596 -609 .
[本文引用: 1]
( Chen Xu Liu Penghe Sun Yuzhong , et al . Research on Disease Prediction Models Based on Imbalanced Medical Data Sets
[J]. Chinese Journal of Computers , 2019 ,42 (3 ):596 -609 .)
[本文引用: 1]
[3]
Johns B T Mewhort D J K Jones M N . The Role of Negative Information in Distributional Semantic Learning
[J]. Cognitive Science , 2019 ,43 (5 ):e12730 .
[本文引用: 1]
[4]
Liang H Sun X Sun Y , et al . Text Feature Extraction Based on Deep Learning: A Review
[J]. EURASIP Journal on Wireless Communications and Networking , 2017 : Article No. 211 .
[本文引用: 1]
[5]
Luque C Luna J M Luque M , et al . An Advanced Review on Text Mining in Medicine
[J]. Wiley Interdisciplinary Reviews-Data Mining and Knowledge Discovery , 2019 ,9 (3 ):e1302 .
[本文引用: 1]
[6]
Lu Y Wu Y Liu J , et al . Understanding Health Care Social Media Use from Different Stakeholder Perspectives: A Content Analysis of an Online Health Community
[J]. Journal of Medical Internet Research , 2017 ,19 (4 ):e109 .
[本文引用: 1]
[7]
Hao H Zhang K . The Voice of Chinese Health Consumers: A Text Mining Approach to Web-Based Physician Reviews
[J]. Journal of Medical Internet Research , 2016 ,18 (5 ):e108 .
[本文引用: 1]
[8]
Rivas R Montazeri N Le N X T , et al . Automatic Classification of Online Doctor Reviews: Evaluation of Text Classifier Algorithms
[J]. Journal of Medical Internet Research , 2018 ,20 (11 ):e11141 .
[本文引用: 1]
[9]
金旭 , 王磊 , 孙国梓 , 等 . 一种基于质心空间的不均衡数据欠采样方法
[J]. 计算机科学 , 2019 ,46 (2 ):50 -55 .
[本文引用: 1]
( Jin Xu Wang Lei Sun Guozi , et al . Under-Sampling Method for Unbalanced Data Based on Centroid Space
[J]. Computer Science , 2019 ,46 (2 ):50 -55 .)
[本文引用: 1]
[10]
Wilson D L . Asymptotic Properties of Nearest Neighbor Rules Using Edited Data
[J]. IEEE Transactions on Systems, Man, and Cybernetics , 1972 ,2 (3 ):408 -421 .
[本文引用: 1]
[11]
Kermanidis K Maragoudakis M Fakotakis N , et al . Learning Greek Verb Complements: Addressing the Class Imbalance
[C]//Proceedings of the 20th International Conference on Computational Linguistics. 2004 : 1065 -1071 .
[本文引用: 1]
[12]
古平 , 欧阳源遊 . 基于混合采样的非平衡数据集分类研究
[J]. 计算机应用研究 , 2015 ,32 (2 ):379 -381 .
[本文引用: 1]
( Gu Ping Ouyang Yuanyou . Classification Research for Unbalanced Data Based on Mixed-Sampling
[J]. Application Research of Computers , 2015 ,32 (2 ):379 -381 .)
[本文引用: 1]
[13]
Chawla N V Bowyer K W Hall L O , et al . SMOTE: Synthetic Minority Over-Sampling Technique
[J]. Journal of Artificial Intelligence Research , 2002 ,16 :321 -357 .
[本文引用: 1]
[14]
Han H Wang W Y Mao B H . Borderline-SMOTE: A New Over-Sampling Method in Imbalanced Data Sets Learning
[C]// Proceedings of the 2005 International Conference on Intelligent Computing. 2005 : 878 -887 .
[本文引用: 1]
[15]
Perez-Ortiz M Gutierrez P A Hervas-Martinez C . Borderline Kernel Based Over-Sampling
[C]// Proceedings of the 8th International Conference on Hybrid Artificial Intelligence Systems. 2013 : 472 -481 .
[本文引用: 1]
[16]
Ling X Dai W Xue G R , et al . Spectral Domain-Transfer Learning
[C]// Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM , 2008 : 488 -496 .
[本文引用: 1]
[17]
Dai W Chen Y Xue G R , et al . Translated Learning: Transfer Learning Across Different Feature Spaces
[C]// Proceedings of the 22nd Annual Conference on Neural Information Processing Systems. 2008 : 353 -360 .
[本文引用: 1]
[18]
Pan S J Ni X Sun J , et al . Cross-Domain Sentiment Classification via Spectral Feature Alignment
[C]// Proceedings of the 19th International Conference on World Wide Web. 2010 : 751 -760 .
[本文引用: 1]
[19]
Pan S J Kwok J T Yang Q . Transfer Learning via Dimensionality Reduction
[C]// Proceedings of the 23rd AAAI Conference on Artificial Intelligence. AAAI , 2008 : 677 -682 .
[本文引用: 1]
[20]
Si S Tao D Geng B . Bregman Divergence-Based Regularization for Transfer Subspace Learning
[J]. IEEE Transactions on Knowledge and Data Engineering , 2010 ,22 (7 ):929 -942 .
[本文引用: 1]
[21]
Bonilla E V Chai K M A Williams C K I . Multi-Task Gaussian Process Prediction
[J]. Advances in Neural Information Processing Systems , 2008 ,20 :153 -160 .
[本文引用: 1]
[22]
Dai W Y Yang Q Xue G R , et al . Boosting for Transfer Learning
[C]// Proceedings of the 24th International Conference on Machine Learning. 2007 : 193 -200 .
[本文引用: 1]
[23]
Davis J Domingos P . Deep Transfer via Second-Order Markov Logic
[C]// Proceedings of the 26th International Conference on Machine Learning. 2009 : 217 -224 .
[本文引用: 1]
[24]
Artem B Victor L . Aggregating Deep Convolutional Features for Image Retrieval
[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. 2015 : 1269 -1277 .
[本文引用: 1]
[25]
Zhou B Khosla A Lapedriza A , et al . Object Detectors Emerge in Deep Scene CNNs
[OL]. arXiv Preprint , arXiv:1412.6856.
[本文引用: 1]
[26]
Jaipurkar S S Jie W Zeng Z , et al . Automated Classification Using End-to-End Deep Learning
[C]// Proceedings of the 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society. 2018 : 706 -709 .
[本文引用: 1]
[27]
Kim Y . Convolutional Neural Networks for Sentence Classification
[OL]. arXiv Preprint ,arXiv:1408.5882.
[本文引用: 1]
[28]
Mikolov T Chen K Corrado G , et al . Efficient Estimation of Word Representations in Vector Space
[OL]. arXiv Preprint , arXiv:1301.3781.
[本文引用: 1]
[29]
Alcala-Fdez J Fernandez A Luengo J , et al . KEEL Data-Mining Software Tool: Data Set Repository, Integration of Algorithms and Experimental Analysis Framework
[J]. Journal of Multiple-Valued Logic and Soft Computing , 2011 ,17 :255 -287 .
[本文引用: 1]
A Tale of Two Countries: International Comparison of Online Doctor Reviews Between China and the United States
1
2017
... 类似于电商中用户关于某类产品的评价,在线医疗社区中也包含患者对于现实医疗服务的评价数据,对这些患者评论数据的主题进行有效的识别与归纳,在为社区其他患者提供就医参考咨询的同时,也能够帮助医疗服务提供者有针对性地改善医疗服务[1 ] .但是在应用基于监督学习的方法进行患者评论识别时,会面临以下问题:语料库样本数据标签的不均衡问题[2 ] ;文本分布式表示问题[3 ] ;语义特征抽取问题等[4 ] .鉴于此,本研究提出一种基于混合采样与迁移学习的患者评论识别模型.混合采样技术能够保证不均衡样本中正负样本比例失调的问题,同时本文引入迁移学习的思想,将均衡样本中学习到的知识迁移到不均衡样本的知识学习中,从而提高相应主题识别模型的效果.另外采用Word2Vec与卷积神经网络相结合的端到端深度学习架构解决文本分布式表示、特征提取与模型训练的问题,从而提升模型的整体预测能力. ...
面向不均衡医学数据集的疾病预测模型研究
1
2019
... 类似于电商中用户关于某类产品的评价,在线医疗社区中也包含患者对于现实医疗服务的评价数据,对这些患者评论数据的主题进行有效的识别与归纳,在为社区其他患者提供就医参考咨询的同时,也能够帮助医疗服务提供者有针对性地改善医疗服务[1 ] .但是在应用基于监督学习的方法进行患者评论识别时,会面临以下问题:语料库样本数据标签的不均衡问题[2 ] ;文本分布式表示问题[3 ] ;语义特征抽取问题等[4 ] .鉴于此,本研究提出一种基于混合采样与迁移学习的患者评论识别模型.混合采样技术能够保证不均衡样本中正负样本比例失调的问题,同时本文引入迁移学习的思想,将均衡样本中学习到的知识迁移到不均衡样本的知识学习中,从而提高相应主题识别模型的效果.另外采用Word2Vec与卷积神经网络相结合的端到端深度学习架构解决文本分布式表示、特征提取与模型训练的问题,从而提升模型的整体预测能力. ...
面向不均衡医学数据集的疾病预测模型研究
1
2019
... 类似于电商中用户关于某类产品的评价,在线医疗社区中也包含患者对于现实医疗服务的评价数据,对这些患者评论数据的主题进行有效的识别与归纳,在为社区其他患者提供就医参考咨询的同时,也能够帮助医疗服务提供者有针对性地改善医疗服务[1 ] .但是在应用基于监督学习的方法进行患者评论识别时,会面临以下问题:语料库样本数据标签的不均衡问题[2 ] ;文本分布式表示问题[3 ] ;语义特征抽取问题等[4 ] .鉴于此,本研究提出一种基于混合采样与迁移学习的患者评论识别模型.混合采样技术能够保证不均衡样本中正负样本比例失调的问题,同时本文引入迁移学习的思想,将均衡样本中学习到的知识迁移到不均衡样本的知识学习中,从而提高相应主题识别模型的效果.另外采用Word2Vec与卷积神经网络相结合的端到端深度学习架构解决文本分布式表示、特征提取与模型训练的问题,从而提升模型的整体预测能力. ...
The Role of Negative Information in Distributional Semantic Learning
1
2019
... 类似于电商中用户关于某类产品的评价,在线医疗社区中也包含患者对于现实医疗服务的评价数据,对这些患者评论数据的主题进行有效的识别与归纳,在为社区其他患者提供就医参考咨询的同时,也能够帮助医疗服务提供者有针对性地改善医疗服务[1 ] .但是在应用基于监督学习的方法进行患者评论识别时,会面临以下问题:语料库样本数据标签的不均衡问题[2 ] ;文本分布式表示问题[3 ] ;语义特征抽取问题等[4 ] .鉴于此,本研究提出一种基于混合采样与迁移学习的患者评论识别模型.混合采样技术能够保证不均衡样本中正负样本比例失调的问题,同时本文引入迁移学习的思想,将均衡样本中学习到的知识迁移到不均衡样本的知识学习中,从而提高相应主题识别模型的效果.另外采用Word2Vec与卷积神经网络相结合的端到端深度学习架构解决文本分布式表示、特征提取与模型训练的问题,从而提升模型的整体预测能力. ...
Text Feature Extraction Based on Deep Learning: A Review
1
2017
... 类似于电商中用户关于某类产品的评价,在线医疗社区中也包含患者对于现实医疗服务的评价数据,对这些患者评论数据的主题进行有效的识别与归纳,在为社区其他患者提供就医参考咨询的同时,也能够帮助医疗服务提供者有针对性地改善医疗服务[1 ] .但是在应用基于监督学习的方法进行患者评论识别时,会面临以下问题:语料库样本数据标签的不均衡问题[2 ] ;文本分布式表示问题[3 ] ;语义特征抽取问题等[4 ] .鉴于此,本研究提出一种基于混合采样与迁移学习的患者评论识别模型.混合采样技术能够保证不均衡样本中正负样本比例失调的问题,同时本文引入迁移学习的思想,将均衡样本中学习到的知识迁移到不均衡样本的知识学习中,从而提高相应主题识别模型的效果.另外采用Word2Vec与卷积神经网络相结合的端到端深度学习架构解决文本分布式表示、特征提取与模型训练的问题,从而提升模型的整体预测能力. ...
An Advanced Review on Text Mining in Medicine
1
2019
... 患者评论识别在自然语言处理领域通常可以看作文本挖掘的过程,就技术而言,当下流行的方法可以划分为基于无监督学习和有监督学习的方法[5 ] .有研究者通过N-gram模型结合UMLS超级叙词表对患者评论文本进行术语抽取,并用期望最大值(Expectation Maximization, EM)算法对术语集合进行主题聚类[6 ] .此外也有研究者采用LDA主题模型对在线患者评论主题进行识别[7 ] .在无监督学习中,研究者将评论文本中的词语单元按照某种指标进行聚类或者以特定概率分布的主题模型进行主题划分,然而实际中单纯的主题聚类会面临一些问题,诸如: ...
Understanding Health Care Social Media Use from Different Stakeholder Perspectives: A Content Analysis of an Online Health Community
1
2017
... 患者评论识别在自然语言处理领域通常可以看作文本挖掘的过程,就技术而言,当下流行的方法可以划分为基于无监督学习和有监督学习的方法[5 ] .有研究者通过N-gram模型结合UMLS超级叙词表对患者评论文本进行术语抽取,并用期望最大值(Expectation Maximization, EM)算法对术语集合进行主题聚类[6 ] .此外也有研究者采用LDA主题模型对在线患者评论主题进行识别[7 ] .在无监督学习中,研究者将评论文本中的词语单元按照某种指标进行聚类或者以特定概率分布的主题模型进行主题划分,然而实际中单纯的主题聚类会面临一些问题,诸如: ...
The Voice of Chinese Health Consumers: A Text Mining Approach to Web-Based Physician Reviews
1
2016
... 患者评论识别在自然语言处理领域通常可以看作文本挖掘的过程,就技术而言,当下流行的方法可以划分为基于无监督学习和有监督学习的方法[5 ] .有研究者通过N-gram模型结合UMLS超级叙词表对患者评论文本进行术语抽取,并用期望最大值(Expectation Maximization, EM)算法对术语集合进行主题聚类[6 ] .此外也有研究者采用LDA主题模型对在线患者评论主题进行识别[7 ] .在无监督学习中,研究者将评论文本中的词语单元按照某种指标进行聚类或者以特定概率分布的主题模型进行主题划分,然而实际中单纯的主题聚类会面临一些问题,诸如: ...
Automatic Classification of Online Doctor Reviews: Evaluation of Text Classifier Algorithms
1
2018
... 基于有监督学习的文本挖掘方法通常被看作文本分类的过程,需要研究者事先构建相应的语料库,然后将文本内容与标签分别进行向量化表示,以供特定的算法进行特征提取与模型训练.从现有研究来看,基于有监督学习的患者评论识别研究是远远少于基于无监督方法的.Rivas等[8 ] 从收集的患者评论文本中随机抽样600条评论,按照10类主题进行标注,并采用支持向量机、卷积神经网络、随机森林以及基于依存树分类器(Dependency Tree-Based Classifier, DTC)算法建立各个主题的分类模型,选出效果最优的模型用于主题识别. ...
一种基于质心空间的不均衡数据欠采样方法
1
2019
... 非均衡数据从形式上可以表述为小类样本(正样本)与大类样本(负样本)的比例失衡问题.在对非平衡数据进行批量训练时,由于不能很好地捕捉到低比例样本的信息,从而导致小类样本的召回率偏低.然而这些小比例的正样本往往具有重要的现实意义,比如欺诈监测中的欺诈样本,疾病预测中的疑难疾病等[9 ] .当前的研究主要从样本采样和算法改进两个层面处理数据不均衡问题.样本采样是通过对训练样本集进行重构以解决数据不均衡的问题,主要是增加或减少某类样本的数量来达到降低样本偏倚的目的,从而有效地对小类样本进行分类.重采样的方法大体分为过采样(Over Sampling)与欠采样(Under Sampling)两类.前者通过增加小类样本的数量平衡数据集中的样本分布,而后者则是通过减少大类样本的数量平衡数据集中的样本分布. ...
一种基于质心空间的不均衡数据欠采样方法
1
2019
... 非均衡数据从形式上可以表述为小类样本(正样本)与大类样本(负样本)的比例失衡问题.在对非平衡数据进行批量训练时,由于不能很好地捕捉到低比例样本的信息,从而导致小类样本的召回率偏低.然而这些小比例的正样本往往具有重要的现实意义,比如欺诈监测中的欺诈样本,疾病预测中的疑难疾病等[9 ] .当前的研究主要从样本采样和算法改进两个层面处理数据不均衡问题.样本采样是通过对训练样本集进行重构以解决数据不均衡的问题,主要是增加或减少某类样本的数量来达到降低样本偏倚的目的,从而有效地对小类样本进行分类.重采样的方法大体分为过采样(Over Sampling)与欠采样(Under Sampling)两类.前者通过增加小类样本的数量平衡数据集中的样本分布,而后者则是通过减少大类样本的数量平衡数据集中的样本分布. ...
Asymptotic Properties of Nearest Neighbor Rules Using Edited Data
1
1972
... 欠采样中常见的算法包括:基于随机欠采样(Random Under Sampling)的方法、基于最邻近编辑规则(Edited Nearest Neighbor)[10 ] 的方法、基于单边采样的方法[11 ] 等.虽然欠采样的方法可以在一定情况下解决样本不均衡的问题,但是在实际中往往会丢失大类样本中较多的信息,而这些被忽略掉的大类样本中可能包含较为重要的信息,从而无法有效保证模型分类的准确性[12 ] .基于SMOTE的方法是过采样技术中主流的算法[13 ] ,主要通过样本与其连线上的样本随机生成样本点来平衡样本,这种方法可以有效解决随机采样带来的过拟合问题,但是也会带来一定的样本重叠问题.部分学者在这种算法的基础上做出一定改进,比如对边界情况[14 ,15 ] 进行考虑等. ...
Learning Greek Verb Complements: Addressing the Class Imbalance
1
2004
... 欠采样中常见的算法包括:基于随机欠采样(Random Under Sampling)的方法、基于最邻近编辑规则(Edited Nearest Neighbor)[10 ] 的方法、基于单边采样的方法[11 ] 等.虽然欠采样的方法可以在一定情况下解决样本不均衡的问题,但是在实际中往往会丢失大类样本中较多的信息,而这些被忽略掉的大类样本中可能包含较为重要的信息,从而无法有效保证模型分类的准确性[12 ] .基于SMOTE的方法是过采样技术中主流的算法[13 ] ,主要通过样本与其连线上的样本随机生成样本点来平衡样本,这种方法可以有效解决随机采样带来的过拟合问题,但是也会带来一定的样本重叠问题.部分学者在这种算法的基础上做出一定改进,比如对边界情况[14 ,15 ] 进行考虑等. ...
基于混合采样的非平衡数据集分类研究
1
2015
... 欠采样中常见的算法包括:基于随机欠采样(Random Under Sampling)的方法、基于最邻近编辑规则(Edited Nearest Neighbor)[10 ] 的方法、基于单边采样的方法[11 ] 等.虽然欠采样的方法可以在一定情况下解决样本不均衡的问题,但是在实际中往往会丢失大类样本中较多的信息,而这些被忽略掉的大类样本中可能包含较为重要的信息,从而无法有效保证模型分类的准确性[12 ] .基于SMOTE的方法是过采样技术中主流的算法[13 ] ,主要通过样本与其连线上的样本随机生成样本点来平衡样本,这种方法可以有效解决随机采样带来的过拟合问题,但是也会带来一定的样本重叠问题.部分学者在这种算法的基础上做出一定改进,比如对边界情况[14 ,15 ] 进行考虑等. ...
基于混合采样的非平衡数据集分类研究
1
2015
... 欠采样中常见的算法包括:基于随机欠采样(Random Under Sampling)的方法、基于最邻近编辑规则(Edited Nearest Neighbor)[10 ] 的方法、基于单边采样的方法[11 ] 等.虽然欠采样的方法可以在一定情况下解决样本不均衡的问题,但是在实际中往往会丢失大类样本中较多的信息,而这些被忽略掉的大类样本中可能包含较为重要的信息,从而无法有效保证模型分类的准确性[12 ] .基于SMOTE的方法是过采样技术中主流的算法[13 ] ,主要通过样本与其连线上的样本随机生成样本点来平衡样本,这种方法可以有效解决随机采样带来的过拟合问题,但是也会带来一定的样本重叠问题.部分学者在这种算法的基础上做出一定改进,比如对边界情况[14 ,15 ] 进行考虑等. ...
SMOTE: Synthetic Minority Over-Sampling Technique
1
2002
... 欠采样中常见的算法包括:基于随机欠采样(Random Under Sampling)的方法、基于最邻近编辑规则(Edited Nearest Neighbor)[10 ] 的方法、基于单边采样的方法[11 ] 等.虽然欠采样的方法可以在一定情况下解决样本不均衡的问题,但是在实际中往往会丢失大类样本中较多的信息,而这些被忽略掉的大类样本中可能包含较为重要的信息,从而无法有效保证模型分类的准确性[12 ] .基于SMOTE的方法是过采样技术中主流的算法[13 ] ,主要通过样本与其连线上的样本随机生成样本点来平衡样本,这种方法可以有效解决随机采样带来的过拟合问题,但是也会带来一定的样本重叠问题.部分学者在这种算法的基础上做出一定改进,比如对边界情况[14 ,15 ] 进行考虑等. ...
Borderline-SMOTE: A New Over-Sampling Method in Imbalanced Data Sets Learning
1
2005
... 欠采样中常见的算法包括:基于随机欠采样(Random Under Sampling)的方法、基于最邻近编辑规则(Edited Nearest Neighbor)[10 ] 的方法、基于单边采样的方法[11 ] 等.虽然欠采样的方法可以在一定情况下解决样本不均衡的问题,但是在实际中往往会丢失大类样本中较多的信息,而这些被忽略掉的大类样本中可能包含较为重要的信息,从而无法有效保证模型分类的准确性[12 ] .基于SMOTE的方法是过采样技术中主流的算法[13 ] ,主要通过样本与其连线上的样本随机生成样本点来平衡样本,这种方法可以有效解决随机采样带来的过拟合问题,但是也会带来一定的样本重叠问题.部分学者在这种算法的基础上做出一定改进,比如对边界情况[14 ,15 ] 进行考虑等. ...
Borderline Kernel Based Over-Sampling
1
2013
... 欠采样中常见的算法包括:基于随机欠采样(Random Under Sampling)的方法、基于最邻近编辑规则(Edited Nearest Neighbor)[10 ] 的方法、基于单边采样的方法[11 ] 等.虽然欠采样的方法可以在一定情况下解决样本不均衡的问题,但是在实际中往往会丢失大类样本中较多的信息,而这些被忽略掉的大类样本中可能包含较为重要的信息,从而无法有效保证模型分类的准确性[12 ] .基于SMOTE的方法是过采样技术中主流的算法[13 ] ,主要通过样本与其连线上的样本随机生成样本点来平衡样本,这种方法可以有效解决随机采样带来的过拟合问题,但是也会带来一定的样本重叠问题.部分学者在这种算法的基础上做出一定改进,比如对边界情况[14 ,15 ] 进行考虑等. ...
Spectral Domain-Transfer Learning
1
2008
... 迁移学习是将现有领域知识进行跨领域求解的一种机器学习方法.按照输入空间与输出空间的不同,迁移学习可以划分为同构空间的迁移学习与异构空间的迁移学习[16 ,17 ,18 ] .而按照内容的角度,迁移学习则包含基于特征迁移[19 ,20 ] 、基于参数迁移[21 ] 、基于实例迁移[22 ] 以及基于关联迁移[23 ] .迁移学习在传统机器学习领域得到较为广泛的应用,特别是较多地应用于图像处理[24 ,25 ] 领域,在自然语言处理领域,尤其是面向不均衡数据源,探索与应用还较少.本文引入迁移学习的思想,将均衡样本中学习到的知识迁移到不均衡样本的知识学习中,以提升不均衡样本分类的效果. ...
Translated Learning: Transfer Learning Across Different Feature Spaces
1
2008
... 迁移学习是将现有领域知识进行跨领域求解的一种机器学习方法.按照输入空间与输出空间的不同,迁移学习可以划分为同构空间的迁移学习与异构空间的迁移学习[16 ,17 ,18 ] .而按照内容的角度,迁移学习则包含基于特征迁移[19 ,20 ] 、基于参数迁移[21 ] 、基于实例迁移[22 ] 以及基于关联迁移[23 ] .迁移学习在传统机器学习领域得到较为广泛的应用,特别是较多地应用于图像处理[24 ,25 ] 领域,在自然语言处理领域,尤其是面向不均衡数据源,探索与应用还较少.本文引入迁移学习的思想,将均衡样本中学习到的知识迁移到不均衡样本的知识学习中,以提升不均衡样本分类的效果. ...
Cross-Domain Sentiment Classification via Spectral Feature Alignment
1
2010
... 迁移学习是将现有领域知识进行跨领域求解的一种机器学习方法.按照输入空间与输出空间的不同,迁移学习可以划分为同构空间的迁移学习与异构空间的迁移学习[16 ,17 ,18 ] .而按照内容的角度,迁移学习则包含基于特征迁移[19 ,20 ] 、基于参数迁移[21 ] 、基于实例迁移[22 ] 以及基于关联迁移[23 ] .迁移学习在传统机器学习领域得到较为广泛的应用,特别是较多地应用于图像处理[24 ,25 ] 领域,在自然语言处理领域,尤其是面向不均衡数据源,探索与应用还较少.本文引入迁移学习的思想,将均衡样本中学习到的知识迁移到不均衡样本的知识学习中,以提升不均衡样本分类的效果. ...
Transfer Learning via Dimensionality Reduction
1
2008
... 迁移学习是将现有领域知识进行跨领域求解的一种机器学习方法.按照输入空间与输出空间的不同,迁移学习可以划分为同构空间的迁移学习与异构空间的迁移学习[16 ,17 ,18 ] .而按照内容的角度,迁移学习则包含基于特征迁移[19 ,20 ] 、基于参数迁移[21 ] 、基于实例迁移[22 ] 以及基于关联迁移[23 ] .迁移学习在传统机器学习领域得到较为广泛的应用,特别是较多地应用于图像处理[24 ,25 ] 领域,在自然语言处理领域,尤其是面向不均衡数据源,探索与应用还较少.本文引入迁移学习的思想,将均衡样本中学习到的知识迁移到不均衡样本的知识学习中,以提升不均衡样本分类的效果. ...
Bregman Divergence-Based Regularization for Transfer Subspace Learning
1
2010
... 迁移学习是将现有领域知识进行跨领域求解的一种机器学习方法.按照输入空间与输出空间的不同,迁移学习可以划分为同构空间的迁移学习与异构空间的迁移学习[16 ,17 ,18 ] .而按照内容的角度,迁移学习则包含基于特征迁移[19 ,20 ] 、基于参数迁移[21 ] 、基于实例迁移[22 ] 以及基于关联迁移[23 ] .迁移学习在传统机器学习领域得到较为广泛的应用,特别是较多地应用于图像处理[24 ,25 ] 领域,在自然语言处理领域,尤其是面向不均衡数据源,探索与应用还较少.本文引入迁移学习的思想,将均衡样本中学习到的知识迁移到不均衡样本的知识学习中,以提升不均衡样本分类的效果. ...
Multi-Task Gaussian Process Prediction
1
2008
... 迁移学习是将现有领域知识进行跨领域求解的一种机器学习方法.按照输入空间与输出空间的不同,迁移学习可以划分为同构空间的迁移学习与异构空间的迁移学习[16 ,17 ,18 ] .而按照内容的角度,迁移学习则包含基于特征迁移[19 ,20 ] 、基于参数迁移[21 ] 、基于实例迁移[22 ] 以及基于关联迁移[23 ] .迁移学习在传统机器学习领域得到较为广泛的应用,特别是较多地应用于图像处理[24 ,25 ] 领域,在自然语言处理领域,尤其是面向不均衡数据源,探索与应用还较少.本文引入迁移学习的思想,将均衡样本中学习到的知识迁移到不均衡样本的知识学习中,以提升不均衡样本分类的效果. ...
Boosting for Transfer Learning
1
2007
... 迁移学习是将现有领域知识进行跨领域求解的一种机器学习方法.按照输入空间与输出空间的不同,迁移学习可以划分为同构空间的迁移学习与异构空间的迁移学习[16 ,17 ,18 ] .而按照内容的角度,迁移学习则包含基于特征迁移[19 ,20 ] 、基于参数迁移[21 ] 、基于实例迁移[22 ] 以及基于关联迁移[23 ] .迁移学习在传统机器学习领域得到较为广泛的应用,特别是较多地应用于图像处理[24 ,25 ] 领域,在自然语言处理领域,尤其是面向不均衡数据源,探索与应用还较少.本文引入迁移学习的思想,将均衡样本中学习到的知识迁移到不均衡样本的知识学习中,以提升不均衡样本分类的效果. ...
Deep Transfer via Second-Order Markov Logic
1
2009
... 迁移学习是将现有领域知识进行跨领域求解的一种机器学习方法.按照输入空间与输出空间的不同,迁移学习可以划分为同构空间的迁移学习与异构空间的迁移学习[16 ,17 ,18 ] .而按照内容的角度,迁移学习则包含基于特征迁移[19 ,20 ] 、基于参数迁移[21 ] 、基于实例迁移[22 ] 以及基于关联迁移[23 ] .迁移学习在传统机器学习领域得到较为广泛的应用,特别是较多地应用于图像处理[24 ,25 ] 领域,在自然语言处理领域,尤其是面向不均衡数据源,探索与应用还较少.本文引入迁移学习的思想,将均衡样本中学习到的知识迁移到不均衡样本的知识学习中,以提升不均衡样本分类的效果. ...
Aggregating Deep Convolutional Features for Image Retrieval
1
2015
... 迁移学习是将现有领域知识进行跨领域求解的一种机器学习方法.按照输入空间与输出空间的不同,迁移学习可以划分为同构空间的迁移学习与异构空间的迁移学习[16 ,17 ,18 ] .而按照内容的角度,迁移学习则包含基于特征迁移[19 ,20 ] 、基于参数迁移[21 ] 、基于实例迁移[22 ] 以及基于关联迁移[23 ] .迁移学习在传统机器学习领域得到较为广泛的应用,特别是较多地应用于图像处理[24 ,25 ] 领域,在自然语言处理领域,尤其是面向不均衡数据源,探索与应用还较少.本文引入迁移学习的思想,将均衡样本中学习到的知识迁移到不均衡样本的知识学习中,以提升不均衡样本分类的效果. ...
Object Detectors Emerge in Deep Scene CNNs
1
... 迁移学习是将现有领域知识进行跨领域求解的一种机器学习方法.按照输入空间与输出空间的不同,迁移学习可以划分为同构空间的迁移学习与异构空间的迁移学习[16 ,17 ,18 ] .而按照内容的角度,迁移学习则包含基于特征迁移[19 ,20 ] 、基于参数迁移[21 ] 、基于实例迁移[22 ] 以及基于关联迁移[23 ] .迁移学习在传统机器学习领域得到较为广泛的应用,特别是较多地应用于图像处理[24 ,25 ] 领域,在自然语言处理领域,尤其是面向不均衡数据源,探索与应用还较少.本文引入迁移学习的思想,将均衡样本中学习到的知识迁移到不均衡样本的知识学习中,以提升不均衡样本分类的效果. ...
Automated Classification Using End-to-End Deep Learning
1
2018
... 在传统机器学习中,文本分类任务往往是由多个独立的模块构成,诸如文本表示、特征提取、模型预测等,每一个模块对应独立的步骤,其结果的好坏都会影响到最终模型预测的结果.而在深度学习中,则将数据从输入端到输出端整个过程连接为一个整体,模型最终的训练会得到相应误差,这个误差信号会在深度网络的各层间传递,每一层也会由此做出相应调整,这种过程可以看作端到端学习(End-to-End Learning)[26 ] .本文所采用的端到端的卷积神经网络(Convolutional Neural Network, CNN)如图3 所示,由表示层、卷积层、池化层与全连接层组成[27 ] . ...
Convolutional Neural Networks for Sentence Classification
1
... 在传统机器学习中,文本分类任务往往是由多个独立的模块构成,诸如文本表示、特征提取、模型预测等,每一个模块对应独立的步骤,其结果的好坏都会影响到最终模型预测的结果.而在深度学习中,则将数据从输入端到输出端整个过程连接为一个整体,模型最终的训练会得到相应误差,这个误差信号会在深度网络的各层间传递,每一层也会由此做出相应调整,这种过程可以看作端到端学习(End-to-End Learning)[26 ] .本文所采用的端到端的卷积神经网络(Convolutional Neural Network, CNN)如图3 所示,由表示层、卷积层、池化层与全连接层组成[27 ] . ...
Efficient Estimation of Word Representations in Vector Space
1
... Word2Vec的思想解决了基于词袋模型(Bag of Words)中高维度、高稀疏、低语义的问题,在自然语言处理领域取得了很好的效果[28 ] .本文采用Skip-Gram的词向量模型,其核心思想是用文档中的词 w i n 内上下文的词 { w i - n , w i - n + 1 , … , w i + n - 1 , w i + n } . 其模型结构如图4 所示.利用该模型在大规模语料上训练词语的向量化表示,保留模型中投影层的权重矩阵,即对应于词 w i
KEEL Data-Mining Software Tool: Data Set Repository, Integration of Algorithms and Experimental Analysis Framework
1
2011
... 除此之外,引入不均衡率(Imbalance Ratio, IR)表征数据集标签的不均衡程度[29 ] ,IR值为实验数据集中大类样本标签与小类样本标签的比值.以此为依据,设定态度、能力、措施、效果主题标签所在数据集为大类数据集,环境、费用主题标签所在数据集为小类数据集.小类数据集中主题标签与大类数据集中标签的共现频次如表2 所示,其中环境与态度、费用与措施的共现频次分别在各自组中最高.以此为依据,选择态度主题数据集训练的模型为环境主题迁移学习的原始模型,措施主题数据集训练的模型为费用主题迁移学习的原始模型. ...






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}