1 引 言
在信息过载的大数据时代,推荐系统已经成为用户快捷获取信息的必要手段。同时,推荐系统能够大大提升各类信息服务平台的用户粘性,进而为提升商家收益提供帮助。现有推荐系统大多为用户推荐一件可能购买的物品。然而在真实场景中,用户购物行为往往是在购物篮中放置多件物品并一起购买,比如用户可能将面包和啤酒放在一起购买。购物篮推荐任务就是针对这种场景为用户推荐下一次可能购买的多件物品。相比于传统推荐系统[1 ,2 ,3 ,4 ] ,购物篮推荐任务的挑战性在于不仅要考虑用户购买行为之间的序列关系,还需对同一购物篮内的物品关系进行有效建模。
作为一类重要的个性化推荐任务,购物篮推荐任务已得到广泛关注,研究者提出多种购物篮推荐方法。传统购物篮推荐方法主要包括基于统计的方法、基于频繁模式的方法和基于马尔可夫链的方法等。基于统计的方法主要基于用户历史购买数据的统计信息进行推荐,基于频繁模式的方法侧重于考虑同一个购物篮中不同物品之间的共现关系,基于马尔可夫链的方法则侧重于考虑不同购物篮之间的序列关系。近年来,深度学习技术也被应用于购物篮推荐任务,基本方法是使用池化技术构建购物篮向量,使用循环神经网络捕捉购物篮序列信息。
虽然基于深度神经网络的购物篮推荐方法取得了比传统方法更好的性能,但还存在如下问题:
(1)现有方法在构建购物篮向量时使用各种池化技术,以均值池化为例,将所有物品的向量取均值作为购物量向量,然而购物篮中不同的物品权重应该是不同的,比如一个购物篮中的小众物品往往更能反映该用户的偏好,因此现有方法并不能很好地对购物篮中的物品关系进行有效建模;
(2)现有方法大多仅考虑用户的购买信息,侧重于对其中的时序特征进行建模,而没用很好地利用物品的属性信息。
针对以上问题,本文提出一种基于多头自注意力神经网络的购物篮推荐方法。使用自注意力机制为购物篮中的物品自动计算权重,从而得到更优的购物篮向量表示;另外使用多头注意力机制将属性信息融入模型中,实现对购物篮更为全面的建模。
2 研究现状
(1)基于协同过滤的方法主要使用协同过滤技术提取用户偏好信息,并根据用户偏好为用户推荐物品[5 ,6 ] 。由于协同过滤技术仅能直接处理传统的用户-物品评分或购买关系矩阵,所以难以对购物篮内部不同物品之间的关系进行建模,同时也未考虑购物篮之间的序列信息。
(2)基于频繁模式的方法主要从购物篮数据中挖掘物品的频繁模式[7 ,8 ] ,这类方法的基本思想是通过挖掘用户历史购买记录中的频繁模式实现购物篮推荐。代表性工作有:Lazcorreta等分两个阶段应用扩展的Apriori算法挖掘多角度的用户购买模式[8 ] ;Guidotti等考虑用户购买行为的共现性、序列性、周期性和再现性等4个因素,提出一种时序标注循环模式,并以之作为购物篮推荐的决策因素[9 ] 。该方法的不足主要在于频繁模式的表达能力通常有限,而且在大规模用户历史购买数据中挖掘频繁模式需要较高的时空开销。
(3)基于马尔可夫链的方法主要侧重于应用马尔可夫链建模方法[10 ] 捕捉购物篮的序列信息。代表性工作有:Rendle等将矩阵分解技术融入到马尔可夫链模型中,从而可以捕捉购物篮的序列信息和用户对物品的偏好信息[11 ] ;Chen等针对用户偏好中存在的遗忘特性,提出一种个性化兴趣遗忘马尔可夫链模型,实验结果表明引入遗忘特性能够显著提升推荐的准确性[12 ] 。该方法的不足主要在于马尔可夫链虽然提供了一种较好的序列建模方法,但是当现实数据不符合马尔可夫特性时,其效果往往受到制约;此外,马尔可夫链建模方法通常假设所有物品是独立的,忽略了同一个购物篮中不同物品之间的关系。
(4)基于深度学习的方法是近年来购物篮推荐研究的一个热点方向,基本思想是应用各种深度神经网络模型解决购物篮推荐中的购物篮建模、序列建模等问题。代表性工作有:Wang等提出一种层次化表示模型,对一个购物篮中的所有物品进行聚合得到购物篮向量表示,之后对一个用户最近的N个历史购物篮进行聚合得到用户偏好的向量表示,聚合采用均值池化或最大池化两种方式[13 ] ;Yu等对层次化表示模型进行改进,购物篮聚合层使用长短期记忆网络(Long Short-Term Memory, LSTM),从而捕捉购物篮之间的序列信息[14 ] ;Bai等使用注意力机制将物品的属性信息加入到购物篮向量中,进一步提升了购物篮推荐的准确性[15 ] 。整体而言,基于深度学习的购物篮推荐刚刚起步,使用的深度神经网络模型还较为简单,在购物篮建模和序列建模等方面还存在很大的改进空间。
3 研究框架与方法
3.1 购物篮推荐任务描述
令U 和I 分别表示所有用户的集合和所有物品的集合, u ∈ U i ∈ I u 的历史购买记录由一系列购物篮构成,可以表示为 B 1 : T u = < B 1 u , B 2 u , ⋯ , B T u > B t u ⊆ I ( 1 ≤ t ≤ T ) u 在时刻t 购买的物品集合,即一个购物篮。每个物品包含一些属性信息,比如物品类别、物品价格等,为能够对物品属性进行统一表示,令C 表示所有属性取值的集合,物品i 的属性表示为 c i ∈ C B t u C t u = { c i | i ∈ B t u }
基于上述符号表示,购物篮推荐任务的目标是给定用户u 的历史购买记录 B 1 : T u B T + 1 u u 给所有物品进行打分并排序,将排在前K 位的物品作为最终推荐结果。
3.2 多头自注意力机制
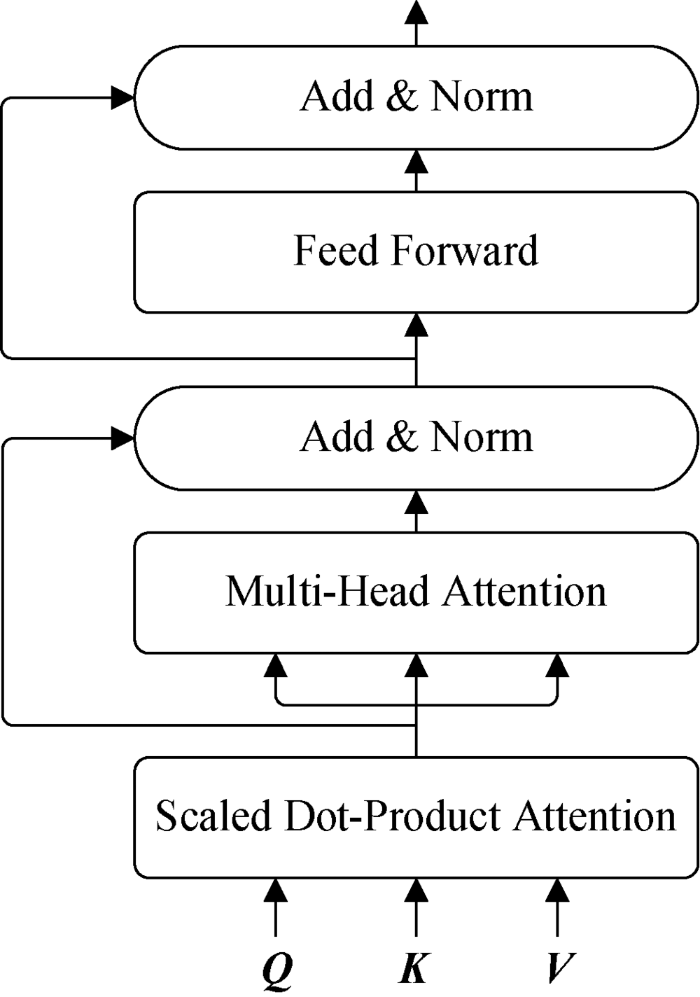
基于多头自注意力机制(Multi-Head Self-Attention Mechanism/Transformer)[16 ] 设计针对购物篮推荐任务的深度神经网络模型。谷歌公司在Transformer神经网络模型中首次使用多头自注意力机制,该机制最早被应用于机器翻译任务中,当时取得了最优效果。由于多头自注意力机制能够很好地捕捉长序列信息,且具有速度快、可解释性强等特点,现已广泛应用于自然语言处理等领域[17 ,18 ] 。然而,目前尚未有研究将多头自注意力机制应用于推荐系统任务中。
图1
图1
多头自注意力模型结构
Fig.1
Structure of Multi-Head Self-Attention
(1) 缩放点积注意力(Scaled Dot-Product Attention)
多头自注意力的输入包含查询向量或矩阵Q 、键矩阵K 、值矩阵V 。在自然语言处理领域中,Q 、K 、V 通常是由词向量构成的矩阵,比如它们均是同一个句子中各个位置的词向量矩阵,因此此时 Q = K = V Q 、K 、V 首先进入缩放点积注意力模块进行运算,如公式(1)[16 ] 所示。
(1) Attention ( Q , K , V ) = Softmax Q ⋅ K T d k ⋅ V
其中,Softmax 函数本质上根据Q 计算K 中每个键的权重, d k K 中每个键的向量维度,分母中的 d k
(2) 多头注意力(Multi-Head Attention)
为更全面地计算注意力,通常在计算缩放点积注意力时并不直接输入原始的Q 、K 、V ,而是先对它们进行多次不同的线性映射,之后对映射结果计算缩放点积注意力,其中每次计算结果称之为一个头(Head)。多头注意力模块计算如公式(2)和公式(3)[16 ] 所示:
(2) MultiHead ( Q , K , V ) = Concat ( h ea d 1 , h ea d 2 , ⋯ , h ea d n )
(3) h ea d i = Attention ( Q ⋅ W i Q , K ⋅ W i K , V ⋅ W i V )
其中, W i Q W i K W i V Q 、K 、V 的线性映射矩阵,Concat 表示对所有头的注意力计算结果进行连接操作。
得到多头注意力计算结果后,按层次进行归一化,并引入残差连接,以解决深度网络可能导致的退化问题。
归一化及残差连接模块输出后进入一个全连接网络,这个全连接网络包括两层全连接操作和一个ReLU激活函数,计算方法如公式(4)[16 ] 所示。
(4) FNN ( x ) = max ( 0 , W 1 ⋅ x + b 1 ) ⋅ W 2 + b 2
全连接网络的输出经过归一化及残差连接处理后作为整个模型的最终输出。
图1 所示的模型通常也被称之为Transformer神经网络,其可以被形式化表示如公式(5)所示。
(5) O = Transformer ( Q , K , V )
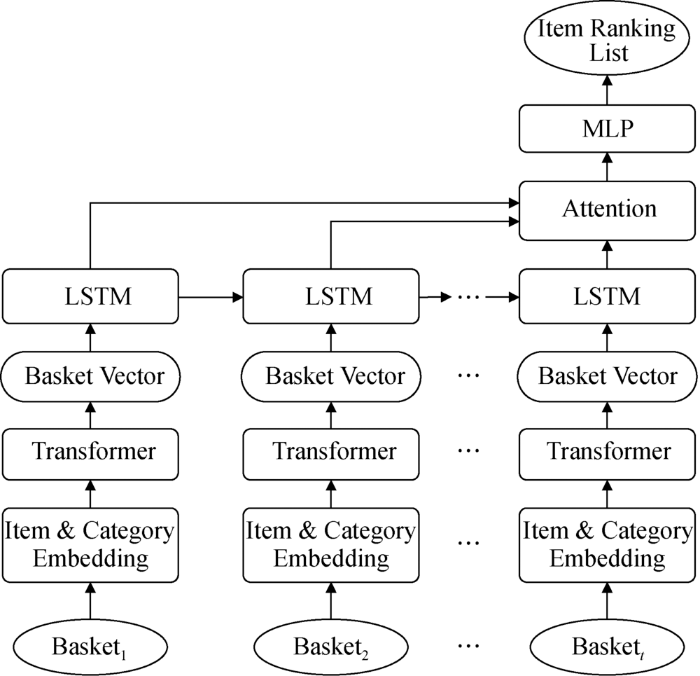
4 基于多头自注意力的购物篮推荐模型
基于多头自注意力的购物篮推荐模型总体结构如图2 所示,其中主要包括5个模块:融合属性信息的多头自注意力模块(Item & Category Embedding)、购物篮编码模块(Basket Vecter)、序列建模模块(LSTM)、序列注意力模块(Attention)、全连接输出模块(Multi-layer Perceptron,MLP)。
图2
图2
基于多头自注意力的购物篮推荐模型结构
Fig.2
Structure of Basket Recommendation Model Based on Multi-Head Self-Attention
4.1 融合属性信息的多头自注意力模块
物品属性是购物篮推荐任务中的一个重要考虑因素。为了能够对物品属性有效建模,在多头自注意力机制中引入物品的属性信息,基本思想是分别将物品自身和物品属性使用Q 、K 、V 编码,设计基于物品自身的注意力模型和基于物品属性的注意力模型,分别如公式(6)和公式(7)所示。
(6) O item = Transformer ( Q item , K item , V item )
(7) O catg = Transformer ( Q catg , K catg , V catg )
4.2 购物篮编码模块
一个购物篮是由一个或多个物品构成的。借鉴自然语言处理任务中将一个句子表示为向量的做法,即首先为所有句子设置一个标志位,用标志位与句子中所有的单词计算点积权重,利用计算出的权重对所有单词向量加权求和。在购物篮推荐任务中,为所有购物篮设置一个标志位,使用多头自注意力获得购物篮向量,如公式(8)所示。
(8) bvec = Transformer ( Flag , K , V )
其中,Flag 表示购物篮的标志位向量,代替传统多头自注意力机制中的Q ;K 和V 表示一个购物篮内的所有物品或属性向量构成的矩阵。由于Flag 是一个向量,公式(8)最后的输出也是一个向量,这个向量就是购物篮向量。
在上述基本结构的基础上,为融入物品属性信息,为每一个购物篮设置两个标志位,其中Flagitem 为购物篮物品标志位向量,Flagcatg 为购物篮属性标志位向量。基于4.2节中融合属性信息的多头自注意力模块,可以计算两类购物篮向量,如公式(9)和公式(10)所示。
(9) bve c item = Transformer ( Fla g item , K item , V item )
(10) bve c catg = Transformer ( Fla g catg , K catg , V catg )
公式(9)是由购物篮内物品自身信息得到的购物篮向量,而公式(10)是由购物篮内物品的属性信息得到的购物篮向量,可以认为,两者从不同角度反映了购物篮的信息,具有一定的互补性。因此,通过这种方法将属性信息加入到网络中。
对于计算出的两种购物篮向量,采用拼接的方式将两者进行融合作为最终的购物篮向量表示,如公式(11)所示。
(11) bvec = Concat ( bve c item , bve c c atg )
4.3 序列建模模块
对于用户u 的历史购物篮信息 B u = < B 1 u , B 2 u , ⋯ , B T u > < bve c 1 u , bve c 2 u , ⋯ bve c T u > [19 ] 进行建模,其在每个时刻t 的输入是 bve c t u t 时刻之前的序列编码向量,输出t 时刻的编码向量,如公式(12)所示。
(12) h t u = LSTM ( bve c t u , h t - 1 u )
4.4 序列注意力模块
经过LSTM可以得到用户购物篮序列中每个时刻的编码 < h 1 u , h 2 u , ⋯ h T u >
(13) uvec = ∑ t = 1 T α t × h t
(14) α t = exp ( score ( h t , h T ) ) ∑ t ' = 1 T exp ( score ( h t ' , h T ) )
在购物篮推荐任务中,用户在最近时刻T 的购买信息往往对于推荐结果具有最大的影响,因此每个时刻的权重依据该时刻编码向量与最近时刻编码向量的关系进行计算,如公式(15)所示。
(15) score ( h t , h T ) = h t ⋅ W att ⋅ h T
4.5 全连接输出模块
序列注意力模块的输出可以被认为是一个用户历史购物记录的编码向量,将其输入至一个全连接网络中,该网络的输出大小等于所有物品的数量 | I |
(16) p = softmax ( W out , uvec )
其中, p ∈ R | I |
为尽可能提高网络学习效果,使用带权交叉熵作为损失函数,如公式(17)所示。
(17) L = ∑ u ∈ U ∑ t = 1 T - 1 ∑ i ∈ I - m ⋅ y t + 1 u ( i ) ⋅ log ( p t u ( i ) ) - n ⋅ ( 1 - y t + 1 u ( i ) ) ⋅ log ( 1 - p t u ( i ) )
其中, p t u ( i ) i 在t 时刻的得分,即物品i 在 t + 1 u 购买的概率; y t + 1 u ( i ) u 在 t + 1 i ,如果购买,则 y t + 1 u ( i ) = 1 y t + 1 u ( i ) = 0 m 和n 分别是正类和负类的权重。由于用户购买的物品数量仅占所有物品中的一小部分,即负类样本数量远远大于正类样本数量,因此要为正类和负类设置不同的权重大小,以解决样本的类别不均衡问题。
5 实验结果及分析
5.1 数据集
(1)Ta-Feng数据集① (①http://www.bigdatalab.ac.cn/benchmark/bm/dd?data=Ta-Feng. ):记录了2000年11月-2001年2月期间用户在Ta-Feng超市的购物篮记录,由ACM推荐系统国际会议公开。
(2)JingDong数据集② (②https://jdata.jd.com/html/detail.html?id=1. ),记录了2016年02月-2016年4月期间用户在京东商城的购物信息,由京东高潜用户购买意向预测比赛公开。
(3)TaoBao数据集③ (③https://tianchi.aliyun.com/competition/entrance/1/introduction?spm=5176.12281957.1004.4.38b04c2aMgKVsd. ),记录了2014年11月-2014年12月期间用户在淘宝商城的购物信息,由天池天猫重复购买预测比赛公开。
对上述数据集进行预处理,移除购物篮个数少于10的用户或被购买次数少于4的物品。在进行实验时,选择前n 个购物篮作为训练数据,最后一个购物篮作为测试数据。
经过数据预处理后三个数据集的基本信息如表1 所示,包括每个数据集的用户数量、物品数量、物品属性数量和购物篮数量。
5.2 评价指标
本文设计的购物篮推荐模型可以为每个物品计算一个得分,对所有物品得分进行排序,选择前5个物品作为推荐结果,记作 R ( u ) T ( u )
(18) Precision = T ( u ) ⋂ R ( u ) R ( u )
(19) Recall = T ( u ) ⋂ R ( u ) T ( u )
(20) F 1 = 2 × Precision × Recall Precision + Recall
(21) Hit - Rate = ∑ u ∈ U I T ( u ) ⋂ R ( u ) ≠ ϕ | U |
(5) NDCG值(Normalized Discounted Cumulative Gain)
(22) ND CG @ k = 1 N k ∑ j = 1 k 2 I ( R j ( u ) ∈ T ( u ) ) - 1 log ( j + 1 )
其中, I ( ⋅ )
5.3 对比实验
为验证本文方法的优越性,采用如下经典的购物篮推荐方法作为基线方法:
(1)TOP:基于物品流行度(被购买的次数)的推荐方法。
(2)Item-CF[5 ] :基于物品的协同过滤推荐方法。
(3)NFM[20 ] :基于非负矩阵分解的推荐方法,其被证实为传统方法中效果最好的方法之一。
(4)DREAM[14 ] :基于循环神经网络的推荐方法。
(5)NAM[15 ] :基于注意力机制和循环神经网络的推荐方法。
(6)ANAM[15 ] :在NAM方法基础上进一步引入物品属性信息,其被证实为当前效果最好的购物篮推荐方法。
各个基线方法的具体实现方案为:三个传统方法TOP、Item-CF、NFM均基于Scikit-Learn 0.21机器学习库① (①https://scikit-learn.org/. )实现;三个基于深度学习的方法DREAM、NAM、ANAM均基于PyTorch 0.4.0深度学习库② (②https://pytorch.org/. )实现,相关参数使用原始论文中给出的默认值。
本文方法也基于PyTorch 0.4.0深度学习库实现,物品向量和属性向量维度均设置为50,多头自注意力机制中的头数设置为2,优化器使用Adam,学习率设置为0.001,正样本权重设置为50,负样本权重设置为1。基线方法和本文方法在三个数据集上的效果如表2 -表4 所示。
(1)在TOP、Item-CF、NFM三个传统方法中,TOP和Item-CF的效果较差,其主要原因是它们仅考虑用户历史购物记录的基本统计信息,而NFM取得了接近深度学习方法的效果,这说明传统的矩阵分解方法在购物篮推荐任务中依然具有一定应用价值。
(2)DREAM、NAM、ANAM三个基于深度学习的方法在大多数情况下均取得了比传统方法更优的效果,这说明深度学习已成为购物篮推荐任务中的主流方法。整体而言,这三个方法的效果呈现不断上升趋势,这是由于DREAM仅使用LSTM捕捉购物篮的序列信息,NAM进一步引入注意力机制,ANAM则进一步将属性信息融入网络模型中,随着网络结果的不断复杂,学习效果不断提升。
(3)本文方法在三个数据集中都获得最优效果,验证了本文模型能够更好地对购物篮信息进行建模。特别地,本文方法在TaoBao数据集上提升的效果最为明显。根据表1 可以发现,TaoBao数据集是三个数据集中规模最小的,这一定程度上说明本文方法更适用于小数据集。
5.4 网络模块效果分析
为评估网络中某一部分结构对于最终推荐结果的影响,在实验中移除图2 所示网络模型中的某些模块,评估剩余部分的推荐效果。具体而言,设计了如下由部分网络结构构成的推荐模型:
(1)-category-attention:对购物篮建模时不使用属性信息,且移除序列建模中的注意力模块;
(2)-category-transformer:对购物篮建模时不使用属性信息,使用平均池化技术代替购物篮建模中的多头自注意力模块;
(3)-multihead:仅使用单头自注意力模块对购物篮进行建模;
(4)-attention:仅移除序列建模中的注意力模块;
(5)-transformer:使用平均池化技术代替购物篮建模中的多头自注意力模块。
各部分网络模型在三个数据集上的效果如表5 -表7 所示。
(1)对比-category-attention与-attention、-category-transformer与-transformer,去除物品类别信息后在大多数情况下推荐效果均有所下降,这说明物品属性对于提升购物篮推荐效果十分重要;
(2)对比-category-attention与-category-transformer、-attention与-transformer,去除序列注意力与去除多头自注意力均会导致推荐效果下降,其中在Ta-Feng和TaoBao数据集上去除多头自注意力导致的效果下降更显著,在JingDong数据集上去除序列注意力导致的效果下降更显著,这说明不同模块在不同数据集上的重要性也存在区别;
(3)完整网络模型在Ta-Feng和JingDong数据集上取得了最优效能,但在TaoBao数据集上略低于去除多头机制的模型,其主要原因是TaoBao数据集规模较小,而多头机制会导致更多的参数,在小数据集上可能存在参数学习不充分的现象。
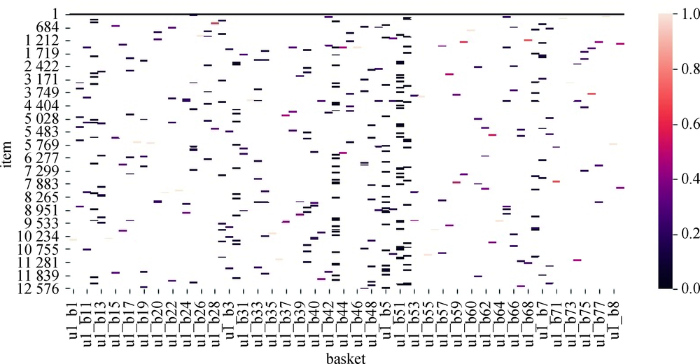
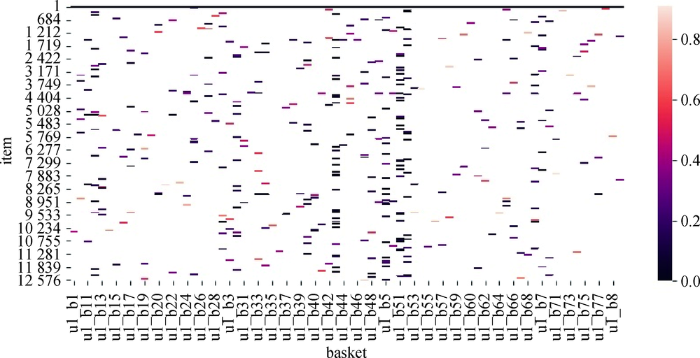
5.5 购物篮建模可视化分析
本文使用多头自注意力机制对购物篮进行建模,相比于现有工作中采用的平均池化等方式,其优势在于能够自动学习购物篮中每个物品的权重。在本实验中对物品权重进行可视化展示,以更为直观地理解多头自注意力机制的作用。具体而言,以Ta-Feng数据集为例,对公式(9)和公式(10)得到的基于物品自身的物品权重和基于物品属性的物品权重使用热度图进行可视化展示,分别如图3 和图4 所示。图中的横轴为各个购物篮,纵轴为各个物品,颜色深浅表示权重大小。对比图3 和图4 可以发现,同一购物篮内不同物品的权重通常是不同的,且不同方式得到的物品权重具有很大差异,这印证了购物篮内的物品不应被同等对待。此外,本文使用的多头自注意力机制能够有效对购物篮的物品信息和属性信息进行建模。
图3
图3
基于物品的自注意力权重可视化
Fig. 3
Visualization of Weights of Item-based Self-Attention
图4
图4
基于属性的自注意力权重可视化
Fig. 4
Visualization of Weights of Attribute-based Self-Attention
6 结 语
本文基于多头自注意力神经网络提出一种新的购物篮推荐模型。该方法在构建购物篮向量时使用多头自注意力机制为不同的物品计算不同的权值,且解决了物品属性信息融合的问题,此外使用具有注意力的LSTM网络捕捉用户购物篮的序列信息。在三个真实数据集上开展实验研究,结果表明本文方法的推荐效果优于传统推荐方法和现有的基于深度学习的推荐方法,网络模块效果分析和购物篮建模可视化分析也证实了本文模型中各模块的有效性。
在个性化推荐领域,购物篮推荐是一个较新的研究话题,推荐效果仍有很大的提升空间。本文提出的基于多头自注意力的购物篮推荐方法虽然在准确性上得到较大提升,但是依然存在可解释性差等不足,如何提升基于深度学习的购物篮推荐方法的可解释性是未来的一个重要研究方向。
支撑数据
支撑数据由作者自存储,E-mail: liu_tongtong@foxmail.com。
[1] 刘彤. Ta-Feng.txt. Ta-Feng购物篮数据集.
[2] 刘彤. JingDong.txt. JingDong购物篮数据集.
[3] 刘彤. TaoBao.txt. TaoBao购物篮数据集.
参考文献
View Option
[1]
Hidasi B Karatzoglou A Baltrunas L , et al . Session-based Recommendations with Recurrent Neural Networks
[OL]. arXiv Preprint , arXiv: 1511.06939.
[本文引用: 1]
[2]
Hidasi B Quadrana M Karatzoglou A . Parallel Recurrent Neural Network Architectures for Feature-rich Session-based Recommendations
[C]// Proceedings of the 10th ACM Conference on Recommender Systems, Boston, USA. ACM , 2016 : 241 -248 .
[本文引用: 1]
[3]
Quadrana M Karatzoglou A Hidasi B , et al . Personalizing Session-based Recommendations with Hierarchical Recurrent Neural Networks
[C]// Proceedings of the 11th ACM Conference on Recommender Systems, Como, Italy. ACM , 2017 : 130 -137 .
[本文引用: 1]
[4]
Jannach D Ludewig M . When Recurrent Neural Networks Meet the Neighborhood for Session-based Recommendation
[C]// Proceedings of the 11th ACM Conference on Recommender Systems, Como, Italy. ACM , 2017 : 306 -310 .
[本文引用: 1]
[5]
De Montjoye Y A Shmueli E Wang S S . openPDS: Protecting the Privacy of Metadata Through Safe Answers
[J]. PLoS One , 2014 ,9 (7 ):e98790 .
[本文引用: 2]
[6]
Vescovi M Perentis C Leonardi C , et al . My Data Store: Toward User Awareness and Control on Personal Data
[C]// Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing: Adjunct Publication, Seattle, USA. ACM , 2014 : 179 -182 .
[本文引用: 1]
[7]
Hsu C N Chung H H Huang H S . Mining Skewed and Sparse Transaction Data for Personalized Shopping Recommendation
[J]. Machine Learning , 2004 ,57 (1-2 ):35 -59 .
[本文引用: 1]
[8]
Lazcorreta E Botella F Fernández-Caballero A . Towards Personalized Recommendation by Two-step Modified Apriori Data Mining Algorithm
[J]. Expert Systems with Applications , 2008 ,35 (3 ):1422 -1429 .
[本文引用: 2]
[9]
Guidotti R Rossetti G Pappalardo L , et al . Next Basket Prediction Using Recurring Sequential Patterns
[OL]. arXiv Preprint , arXiv: 1702.07158.
[本文引用: 1]
[10]
Chand C Thakkar A Ganatra A . Sequential Pattern Mining: Survey and Current Research Challenges
[J]. International Journal of Soft Computing and Engineering , 2012 ,1 (2 ):185 -193 .
[本文引用: 1]
[11]
Rendle S Freudenthaler C Schmidt-Thieme L . Factorizing Personalized Markov Chains for Next-Basket Recommendation
[C]// Proceedings of the 19th International Conference on World Wide Web. New York: ACM , 2010 : 811 -820 .
[本文引用: 1]
[12]
Chen J Wang C Wang J . A Personalized Interest-forgetting Markov Model for Recommendations
[C]// Proceedings of the 29th AAAI Conference on Artificial Intelligence. 2015 .
[本文引用: 1]
[13]
Wang P Guo J Lan Y , et al . Learning Hierarchical Representation Model for Next Basket Recommendation
[C]// Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile. ACM , 2015 : 403 -412 .
[本文引用: 1]
[14]
Yu F Liu Q Wu S , et al . A Dynamic Recurrent Model for Next Basket Recommendation
[C]// Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval, Pisa, Italy. ACM , 2016 : 729 -732 .
[本文引用: 2]
[15]
Bai T Nie J Y Zhao W X , et al . An Attribute-aware Neural Attentive Model for Next Basket Recommendation
[C]// Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA. ACM , 2018 : 1201 -1204 .
[本文引用: 3]
[16]
Vaswani A Shazeer N Parmar N , et al . Attention is All You Need
[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. 2017 : 5998 -6008 .
[本文引用: 4]
[17]
Yu A W Dohan D Luong M T , et al . QANet: Combining Local Convolution with Global Self-Attention for Reading Comprehension
[OL]. arXiv Preprint , arXiv: 1804.09541.
[本文引用: 1]
[18]
Shen T Zhou T Long G , et al . DiSAN: Directional Self-Attention Network for RNN/CNN-Free Language Understanding
[C]// Proceedings of the 32nd AAAI Conference on Artificial Intelligence. 2018 .
[本文引用: 1]
[19]
Hochreiter S Schmidhuber J . Long Short-term Memory
[J]. Neural Computation , 1997 ,9 (8 ):1735 -1780 .
[本文引用: 1]
[20]
Lee D D Seung H S . Algorithms for Non-negative Matrix Factorization
[C]// Proceedings of the 13th International Conference on Neural Information Processing Systems. 2001 : 556 -562 .
[本文引用: 1]
Session-based Recommendations with Recurrent Neural Networks
1
... 在信息过载的大数据时代,推荐系统已经成为用户快捷获取信息的必要手段.同时,推荐系统能够大大提升各类信息服务平台的用户粘性,进而为提升商家收益提供帮助.现有推荐系统大多为用户推荐一件可能购买的物品.然而在真实场景中,用户购物行为往往是在购物篮中放置多件物品并一起购买,比如用户可能将面包和啤酒放在一起购买.购物篮推荐任务就是针对这种场景为用户推荐下一次可能购买的多件物品.相比于传统推荐系统[1 ,2 ,3 ,4 ] ,购物篮推荐任务的挑战性在于不仅要考虑用户购买行为之间的序列关系,还需对同一购物篮内的物品关系进行有效建模. ...
Parallel Recurrent Neural Network Architectures for Feature-rich Session-based Recommendations
1
2016
... 在信息过载的大数据时代,推荐系统已经成为用户快捷获取信息的必要手段.同时,推荐系统能够大大提升各类信息服务平台的用户粘性,进而为提升商家收益提供帮助.现有推荐系统大多为用户推荐一件可能购买的物品.然而在真实场景中,用户购物行为往往是在购物篮中放置多件物品并一起购买,比如用户可能将面包和啤酒放在一起购买.购物篮推荐任务就是针对这种场景为用户推荐下一次可能购买的多件物品.相比于传统推荐系统[1 ,2 ,3 ,4 ] ,购物篮推荐任务的挑战性在于不仅要考虑用户购买行为之间的序列关系,还需对同一购物篮内的物品关系进行有效建模. ...
Personalizing Session-based Recommendations with Hierarchical Recurrent Neural Networks
1
2017
... 在信息过载的大数据时代,推荐系统已经成为用户快捷获取信息的必要手段.同时,推荐系统能够大大提升各类信息服务平台的用户粘性,进而为提升商家收益提供帮助.现有推荐系统大多为用户推荐一件可能购买的物品.然而在真实场景中,用户购物行为往往是在购物篮中放置多件物品并一起购买,比如用户可能将面包和啤酒放在一起购买.购物篮推荐任务就是针对这种场景为用户推荐下一次可能购买的多件物品.相比于传统推荐系统[1 ,2 ,3 ,4 ] ,购物篮推荐任务的挑战性在于不仅要考虑用户购买行为之间的序列关系,还需对同一购物篮内的物品关系进行有效建模. ...
When Recurrent Neural Networks Meet the Neighborhood for Session-based Recommendation
1
2017
... 在信息过载的大数据时代,推荐系统已经成为用户快捷获取信息的必要手段.同时,推荐系统能够大大提升各类信息服务平台的用户粘性,进而为提升商家收益提供帮助.现有推荐系统大多为用户推荐一件可能购买的物品.然而在真实场景中,用户购物行为往往是在购物篮中放置多件物品并一起购买,比如用户可能将面包和啤酒放在一起购买.购物篮推荐任务就是针对这种场景为用户推荐下一次可能购买的多件物品.相比于传统推荐系统[1 ,2 ,3 ,4 ] ,购物篮推荐任务的挑战性在于不仅要考虑用户购买行为之间的序列关系,还需对同一购物篮内的物品关系进行有效建模. ...
openPDS: Protecting the Privacy of Metadata Through Safe Answers
2
2014
... (1)基于协同过滤的方法主要使用协同过滤技术提取用户偏好信息,并根据用户偏好为用户推荐物品[5 ,6 ] .由于协同过滤技术仅能直接处理传统的用户-物品评分或购买关系矩阵,所以难以对购物篮内部不同物品之间的关系进行建模,同时也未考虑购物篮之间的序列信息. ...
... (2)Item-CF[5 ] :基于物品的协同过滤推荐方法. ...
My Data Store: Toward User Awareness and Control on Personal Data
1
2014
... (1)基于协同过滤的方法主要使用协同过滤技术提取用户偏好信息,并根据用户偏好为用户推荐物品[5 ,6 ] .由于协同过滤技术仅能直接处理传统的用户-物品评分或购买关系矩阵,所以难以对购物篮内部不同物品之间的关系进行建模,同时也未考虑购物篮之间的序列信息. ...
Mining Skewed and Sparse Transaction Data for Personalized Shopping Recommendation
1
2004
... (2)基于频繁模式的方法主要从购物篮数据中挖掘物品的频繁模式[7 ,8 ] ,这类方法的基本思想是通过挖掘用户历史购买记录中的频繁模式实现购物篮推荐.代表性工作有:Lazcorreta等分两个阶段应用扩展的Apriori算法挖掘多角度的用户购买模式[8 ] ;Guidotti等考虑用户购买行为的共现性、序列性、周期性和再现性等4个因素,提出一种时序标注循环模式,并以之作为购物篮推荐的决策因素[9 ] .该方法的不足主要在于频繁模式的表达能力通常有限,而且在大规模用户历史购买数据中挖掘频繁模式需要较高的时空开销. ...
Towards Personalized Recommendation by Two-step Modified Apriori Data Mining Algorithm
2
2008
... (2)基于频繁模式的方法主要从购物篮数据中挖掘物品的频繁模式[7 ,8 ] ,这类方法的基本思想是通过挖掘用户历史购买记录中的频繁模式实现购物篮推荐.代表性工作有:Lazcorreta等分两个阶段应用扩展的Apriori算法挖掘多角度的用户购买模式[8 ] ;Guidotti等考虑用户购买行为的共现性、序列性、周期性和再现性等4个因素,提出一种时序标注循环模式,并以之作为购物篮推荐的决策因素[9 ] .该方法的不足主要在于频繁模式的表达能力通常有限,而且在大规模用户历史购买数据中挖掘频繁模式需要较高的时空开销. ...
... [8 ];Guidotti等考虑用户购买行为的共现性、序列性、周期性和再现性等4个因素,提出一种时序标注循环模式,并以之作为购物篮推荐的决策因素[9 ] .该方法的不足主要在于频繁模式的表达能力通常有限,而且在大规模用户历史购买数据中挖掘频繁模式需要较高的时空开销. ...
Next Basket Prediction Using Recurring Sequential Patterns
1
... (2)基于频繁模式的方法主要从购物篮数据中挖掘物品的频繁模式[7 ,8 ] ,这类方法的基本思想是通过挖掘用户历史购买记录中的频繁模式实现购物篮推荐.代表性工作有:Lazcorreta等分两个阶段应用扩展的Apriori算法挖掘多角度的用户购买模式[8 ] ;Guidotti等考虑用户购买行为的共现性、序列性、周期性和再现性等4个因素,提出一种时序标注循环模式,并以之作为购物篮推荐的决策因素[9 ] .该方法的不足主要在于频繁模式的表达能力通常有限,而且在大规模用户历史购买数据中挖掘频繁模式需要较高的时空开销. ...
Sequential Pattern Mining: Survey and Current Research Challenges
1
2012
... (3)基于马尔可夫链的方法主要侧重于应用马尔可夫链建模方法[10 ] 捕捉购物篮的序列信息.代表性工作有:Rendle等将矩阵分解技术融入到马尔可夫链模型中,从而可以捕捉购物篮的序列信息和用户对物品的偏好信息[11 ] ;Chen等针对用户偏好中存在的遗忘特性,提出一种个性化兴趣遗忘马尔可夫链模型,实验结果表明引入遗忘特性能够显著提升推荐的准确性[12 ] .该方法的不足主要在于马尔可夫链虽然提供了一种较好的序列建模方法,但是当现实数据不符合马尔可夫特性时,其效果往往受到制约;此外,马尔可夫链建模方法通常假设所有物品是独立的,忽略了同一个购物篮中不同物品之间的关系. ...
Factorizing Personalized Markov Chains for Next-Basket Recommendation
1
2010
... (3)基于马尔可夫链的方法主要侧重于应用马尔可夫链建模方法[10 ] 捕捉购物篮的序列信息.代表性工作有:Rendle等将矩阵分解技术融入到马尔可夫链模型中,从而可以捕捉购物篮的序列信息和用户对物品的偏好信息[11 ] ;Chen等针对用户偏好中存在的遗忘特性,提出一种个性化兴趣遗忘马尔可夫链模型,实验结果表明引入遗忘特性能够显著提升推荐的准确性[12 ] .该方法的不足主要在于马尔可夫链虽然提供了一种较好的序列建模方法,但是当现实数据不符合马尔可夫特性时,其效果往往受到制约;此外,马尔可夫链建模方法通常假设所有物品是独立的,忽略了同一个购物篮中不同物品之间的关系. ...
A Personalized Interest-forgetting Markov Model for Recommendations
1
2015
... (3)基于马尔可夫链的方法主要侧重于应用马尔可夫链建模方法[10 ] 捕捉购物篮的序列信息.代表性工作有:Rendle等将矩阵分解技术融入到马尔可夫链模型中,从而可以捕捉购物篮的序列信息和用户对物品的偏好信息[11 ] ;Chen等针对用户偏好中存在的遗忘特性,提出一种个性化兴趣遗忘马尔可夫链模型,实验结果表明引入遗忘特性能够显著提升推荐的准确性[12 ] .该方法的不足主要在于马尔可夫链虽然提供了一种较好的序列建模方法,但是当现实数据不符合马尔可夫特性时,其效果往往受到制约;此外,马尔可夫链建模方法通常假设所有物品是独立的,忽略了同一个购物篮中不同物品之间的关系. ...
Learning Hierarchical Representation Model for Next Basket Recommendation
1
2015
... (4)基于深度学习的方法是近年来购物篮推荐研究的一个热点方向,基本思想是应用各种深度神经网络模型解决购物篮推荐中的购物篮建模、序列建模等问题.代表性工作有:Wang等提出一种层次化表示模型,对一个购物篮中的所有物品进行聚合得到购物篮向量表示,之后对一个用户最近的N个历史购物篮进行聚合得到用户偏好的向量表示,聚合采用均值池化或最大池化两种方式[13 ] ;Yu等对层次化表示模型进行改进,购物篮聚合层使用长短期记忆网络(Long Short-Term Memory, LSTM),从而捕捉购物篮之间的序列信息[14 ] ;Bai等使用注意力机制将物品的属性信息加入到购物篮向量中,进一步提升了购物篮推荐的准确性[15 ] .整体而言,基于深度学习的购物篮推荐刚刚起步,使用的深度神经网络模型还较为简单,在购物篮建模和序列建模等方面还存在很大的改进空间. ...
A Dynamic Recurrent Model for Next Basket Recommendation
2
2016
... (4)基于深度学习的方法是近年来购物篮推荐研究的一个热点方向,基本思想是应用各种深度神经网络模型解决购物篮推荐中的购物篮建模、序列建模等问题.代表性工作有:Wang等提出一种层次化表示模型,对一个购物篮中的所有物品进行聚合得到购物篮向量表示,之后对一个用户最近的N个历史购物篮进行聚合得到用户偏好的向量表示,聚合采用均值池化或最大池化两种方式[13 ] ;Yu等对层次化表示模型进行改进,购物篮聚合层使用长短期记忆网络(Long Short-Term Memory, LSTM),从而捕捉购物篮之间的序列信息[14 ] ;Bai等使用注意力机制将物品的属性信息加入到购物篮向量中,进一步提升了购物篮推荐的准确性[15 ] .整体而言,基于深度学习的购物篮推荐刚刚起步,使用的深度神经网络模型还较为简单,在购物篮建模和序列建模等方面还存在很大的改进空间. ...
... (4)DREAM[14 ] :基于循环神经网络的推荐方法. ...
An Attribute-aware Neural Attentive Model for Next Basket Recommendation
3
2018
... (4)基于深度学习的方法是近年来购物篮推荐研究的一个热点方向,基本思想是应用各种深度神经网络模型解决购物篮推荐中的购物篮建模、序列建模等问题.代表性工作有:Wang等提出一种层次化表示模型,对一个购物篮中的所有物品进行聚合得到购物篮向量表示,之后对一个用户最近的N个历史购物篮进行聚合得到用户偏好的向量表示,聚合采用均值池化或最大池化两种方式[13 ] ;Yu等对层次化表示模型进行改进,购物篮聚合层使用长短期记忆网络(Long Short-Term Memory, LSTM),从而捕捉购物篮之间的序列信息[14 ] ;Bai等使用注意力机制将物品的属性信息加入到购物篮向量中,进一步提升了购物篮推荐的准确性[15 ] .整体而言,基于深度学习的购物篮推荐刚刚起步,使用的深度神经网络模型还较为简单,在购物篮建模和序列建模等方面还存在很大的改进空间. ...
... (5)NAM[15 ] :基于注意力机制和循环神经网络的推荐方法. ...
... (6)ANAM[15 ] :在NAM方法基础上进一步引入物品属性信息,其被证实为当前效果最好的购物篮推荐方法. ...
Attention is All You Need
4
2017
... 基于多头自注意力机制(Multi-Head Self-Attention Mechanism/Transformer)[16 ] 设计针对购物篮推荐任务的深度神经网络模型.谷歌公司在Transformer神经网络模型中首次使用多头自注意力机制,该机制最早被应用于机器翻译任务中,当时取得了最优效果.由于多头自注意力机制能够很好地捕捉长序列信息,且具有速度快、可解释性强等特点,现已广泛应用于自然语言处理等领域[17 ,18 ] .然而,目前尚未有研究将多头自注意力机制应用于推荐系统任务中. ...
... 多头自注意力的输入包含查询向量或矩阵Q 、键矩阵K 、值矩阵V .在自然语言处理领域中,Q 、K 、V 通常是由词向量构成的矩阵,比如它们均是同一个句子中各个位置的词向量矩阵,因此此时 Q = K = V Q 、K 、V 首先进入缩放点积注意力模块进行运算,如公式(1)[16 ] 所示. ...
... 为更全面地计算注意力,通常在计算缩放点积注意力时并不直接输入原始的Q 、K 、V ,而是先对它们进行多次不同的线性映射,之后对映射结果计算缩放点积注意力,其中每次计算结果称之为一个头(Head).多头注意力模块计算如公式(2)和公式(3)[16 ] 所示: ...
... 归一化及残差连接模块输出后进入一个全连接网络,这个全连接网络包括两层全连接操作和一个ReLU激活函数,计算方法如公式(4)[16 ] 所示. ...
QANet: Combining Local Convolution with Global Self-Attention for Reading Comprehension
1
... 基于多头自注意力机制(Multi-Head Self-Attention Mechanism/Transformer)[16 ] 设计针对购物篮推荐任务的深度神经网络模型.谷歌公司在Transformer神经网络模型中首次使用多头自注意力机制,该机制最早被应用于机器翻译任务中,当时取得了最优效果.由于多头自注意力机制能够很好地捕捉长序列信息,且具有速度快、可解释性强等特点,现已广泛应用于自然语言处理等领域[17 ,18 ] .然而,目前尚未有研究将多头自注意力机制应用于推荐系统任务中. ...
DiSAN: Directional Self-Attention Network for RNN/CNN-Free Language Understanding
1
2018
... 基于多头自注意力机制(Multi-Head Self-Attention Mechanism/Transformer)[16 ] 设计针对购物篮推荐任务的深度神经网络模型.谷歌公司在Transformer神经网络模型中首次使用多头自注意力机制,该机制最早被应用于机器翻译任务中,当时取得了最优效果.由于多头自注意力机制能够很好地捕捉长序列信息,且具有速度快、可解释性强等特点,现已广泛应用于自然语言处理等领域[17 ,18 ] .然而,目前尚未有研究将多头自注意力机制应用于推荐系统任务中. ...
Long Short-term Memory
1
1997
... 对于用户u 的历史购物篮信息 B u = < B 1 u , B 2 u , ⋯ , B T u > < bve c 1 u , bve c 2 u , ⋯ bve c T u > . 为有效捕捉用户历史行为信息,使用LSTM神经网络[19 ] 进行建模,其在每个时刻t 的输入是 bve c t u t 时刻之前的序列编码向量,输出t 时刻的编码向量,如公式(12)所示. ...
Algorithms for Non-negative Matrix Factorization
1
2001
... (3)NFM[20 ] :基于非负矩阵分解的推荐方法,其被证实为传统方法中效果最好的方法之一. ...






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}