




1 引 言
日益增强的人类活动导致全球约60%的生态系统处于退化或者不可持续状态,荒漠化、水土流失、石漠化等退化土地已经至少占全球土地面积的四分之一。20世纪早期开始,美国、德国等发达国家启动大批生态保护项目,并从中积累了数量众多的生态治理技术,这些技术也从以单一目标为主演化为兼顾生态、经济、民生等多目标的复合模式[1]。中国是生态退化最为严重的国家之一,存在荒漠化、水土流失、石漠化、森林生态系统退化等问题的区域占国土面积的22%左右[2]。针对这些问题,中国自20世纪50年代起实施生态保护工程,同时对西北干旱区生态恢复、黄土高原水土流失综合治理、南方喀斯特区石漠化生态恢复等技术开展机理与示范研究,形成了多种生态治理模式和修复技术。
如果能从大量文本中抽取出生态治理技术名称、实施时间、实施的地理位置、实施地生态环境情况等内容,将其结构化存储并进行关联分析,将有利于把握生态治理技术发展演化的脉络和特征,对生态治理技术领域的情报分析有重要意义。在资源环境领域,开展资源环境相关的实体、属性、关系等的自动抽取和分析方法、技术的研究,也有利于促进大数据环境下基于文本挖掘的资源环境情报分析技术方法的研究和应用。
2 研究现状
当前文本挖掘模型的研究主要在机器学习及其相关应用领域。深度学习是机器学习的扩展,但针对更深的语言表示层。深度学习模型效率高,因为需要的特征工程量不大。长短期记忆网络(Long Short-Term Memory,LSTM)和条件随机场(Conditional Random Field, CRF)大大提高了命名实体识别的效率[3,4,5]。Huang等[6]提出使用循环神经网络(Recurrent Neural Network)作为文本建模工具,提出LSTM-CRF模型和Bi-LSTM+CRF模型,将双向长短期记忆神经网络模型(Bi-directional Long Short-Term Memory)结合CRF层的Bi-LSTM+CRF模型用于命名实体识别任务中。为解决Bi-LSTM模型无法充分利用硬件设备导致训练速度较慢的问题,Strubell等[7]提出使用迭代膨胀卷积神经网络(Iterated Dilated Convolutional Neural Networks,ID-CNNs))替代Bi-LSTM,与CRF层结合组成IDCNN-CRF模型,在提高训练速度的同时获得更好的性能表现。徐飞等[8]采用CRF、RNN、Bi-LSTM和Bi-LSTM+CRF等传统机器学习模型与深度学习模型对食品安全事件文本进行词性自动标注。还有一些用于文本挖掘任务,比如关系抽取[9]和问答系统[10]方面的基于深度学习的模型。深度学习需要大量的训练数据[11],而科学文本挖掘任务中,大规模训练语料的构建成本很高,需要依赖相关学科领域的专家;由于只能获得小规模训练语料,大多数科学文本挖掘模型不能充分利用深度学习技术。许多研究人员基于多任务模型[12]、Word2Vec[13]解决缺乏训练语料的问题。Bi-LSTM+CRF在脆弱生态治理技术相关实体抽取方面适应性和效率如何,有待本研究去探索。
从大量地球科学和资源环境相关领域的文献中抽取结构化信息,并从科学文本数据中发现知识是地球科学和资源环境相关领域逐步开始重视的一个主题,采用有效的方法从地球科学和资源环境相关文献中抽取命名实体和关系,将会促进基于内容的资源环境相关情报分析向自动化和细粒度发展。
3 研究思路与框架
3.1 研究思路
(1)对生态治理技术领域的时间、地名和生态治理技术名称等命名实体的特点和分类进行分析,并在此基础上构建相应的命名实体知识库,作为神经网络模型和词向量的训练语料,以获得质量更高的Word2Vec词向量,从而提升整体识别和抽取的效果。
(2)构建基于Bi-LSTM+CRF的命名实体抽取框架,并结合该框架开展生态治理技术相关命名实体的抽取实验。
(3)开展抽取效果评价。使用Bi-LSTM+CRF神经网络中的随机初始词向量进行命名实体识别模型的训练,作为基准方法;然后分别尝试将Word2Vec训练的两个未标注文本集合的词向量结果替换随机初始词向量,扩大训练语料方法,对比使用不同要素所产生的实验结果;最后评价Bi-LSTM+CRF用于生态治理技术相关命名实体抽取的可行性和效果。
3.2 研究框架
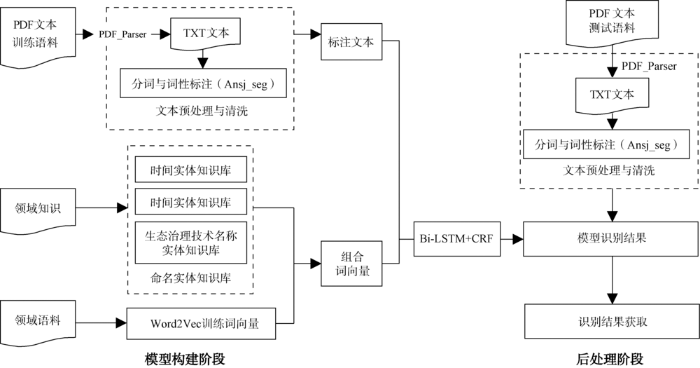
针对本文设计的基于Bi-LSTM与CRF的方法,研究框架主要包括模型构建阶段和后处理阶段,如图1所示。模型构建阶段主要包括语料预处理、词向量的训练。后处理阶段主要包括将测试语料放入模型进行识别,并对识别结果进行处理。
图1
3.3 Bi-LSTM+CRF模型
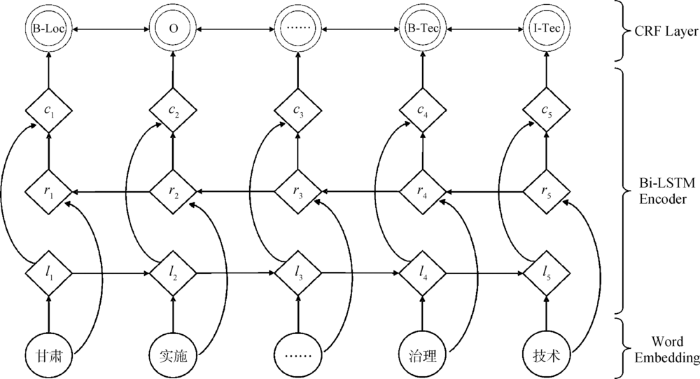
Bi-LSTM+CRF模型结构主要包括三个层次:输入层(Word Embedding)、双向LSTM层(其中包括Tanh层)和CRF层,如图2所示。整体结构确定的情况下,每个层次都需要考虑一些更细致的问题:
(1)输入层的信息,初始词向量的来源、处理工具和维度等内容;
图2
(2)双向LSTM层,包括单元数、网络层数、迭代次数、最大耐心值(即在开发集上的表现累计max_patience次没有提升时,训练即终止)等;
(3)CRF层,承担整个神经网络结构中分类器作用。
根据图2所示,单层圆圈代表Word Embedding输入层,菱形代表学习输入的决定性方程,双层圆圈代表随机变量。信息流将输入层的Word Embedding送到双向LSTM,l(i)代表word(i)和从左边传入的历史信号,r(i)代表word(i)以及从右边传入的未来信号,用c(i)连接这两个向量的信息,代表词word(i)。
在Word Embedding层,对语料进行处理,使用Word2Vec对语料的词进行嵌入,词嵌入的表示可以是纯粹预训练的,也可以在训练模型的时候进行微调,效果更好。在Bi-LSTM层,采用LSTM中的三个门控制送入Memory Cell的输入信息,以及遗忘之前阶段信息的比例,再对Cell状态进行更新,最后用Tanh方程对更新后的细胞状态再做处理,与Sigmoid叠加相乘作为最终输出。在CRF层,将深度神经网络最后学习的结果作为特征,用CRF模型连接起来。
4 研究和实验过程
4.1 实验数据集和运行环境
(1) 实验数据集
选用生态治理技术相关中文文献作为实验数据集,通过训练得到的模型,测试和验证Bi-LSTM+CRF神经网络模型的有效性,测评任务是识别和抽取中文文献中的时间、地名和生态治理技术名称实体。
随机选取CNKI数据库1978年-2017年荒漠化、石漠化和水土流失治理领域收录的文献为研究语料,随机抽取率为10%,得到634篇文献,将得到的数据集按照6∶2∶2的比例切分为训练集、验证/开发集、测试集。训练集用于训练最初模型,验证/开发集用于参数调整,测试集用于测试模型性能。三个集合均对需识别的三类命名实体进行标注,所有文档以TXT格式存储,如表1所示。
表1 数据集的实体数据统计
Table 1
| 任务数据集 | 文献数量 | 实体 数量 | 时间实体数量 | 地名实体数量 | 生态治理技术名称数量 |
|---|---|---|---|---|---|
| 训练集 | 380 | 66 223 | 13 276 | 29 333 | 23 614 |
| 验证/开发集 | 127 | 23 396 | 4 135 | 11 263 | 7 998 |
| 测试集 | 127 | 19 204 | 4 353 | 8 375 | 6 476 |
| 合计 | 634 | 108 823 | 21 764 | 48 971 | 38 088 |
用于Word2Vec训练的两个未标注文本集合如表2所示。
表2 用于Word2Vec训练的两个未标注文本集合
Table 2
| 文本集 | 来源 | 用于词向量训练的部分 |
|---|---|---|
| 未标注 文本集合1 | 634篇文献题录信息 | Title + Keyword + Abstract |
| 未标注 文本集合2 | 634篇文献题录信息 +实体知识库语料 | Title + Keyword + Abstract +Time + Place + Tech |
(2) 运行环境与编程语言
Bi-LSTM+CRF模型的实现采用TensorFlow深度学习框架,编程语言为Python,服务器运行环境为X shell平台(Ubuntu14.04.5 LTS,GNU/Linux 3.13.0-24-generic x86_64)。词向量训练阶段使用Word2Vec[19]工具,采用Java实现。
4.2 基于实体特点的命名实体知识库构建
研究每种命名实体的特点和分类,并构建相应的命名实体知识库,作为神经网络模型和词向量的训练语料,从而提升整体识别和抽取的效果。
(1) 生态治理技术名称特点和分类
本文研究的生态治理技术主要是荒漠化、石漠化和水土流失等方面生态退化问题的治理技术。生态治理技术作为资源环境领域命名实体中一种特别的命名实体,具有一般资源环境领域命名实体的特点和独有特点,比如资源环境命名实体通常命名方式过长,命名实体存在嵌套等形式,这些特性增加了对其识别的难度。在中文文本中,生态治理技术名称描述有以下特点:
①生态治理技术名称描述中可能包含地名实体
技术名称中经常包含技术实施的地理位置信息,且以地名实体的形式嵌套在技术名称中,如“高寒干旱沙地杨树深栽造林”等。
②生态治理技术名称描述中可能包含生态系统或生态区类型
部分技术名称以实施的生态区、或生态区和地名的组合进行命名,如“绿洲农林间作”、“黄土高原梯田技术”等。
③生态治理技术名称描述中可能包含生态退化类型
技术名称对技术的描述通常与生态退化的类型相结合,指示适用于某退化类型的技术,如“荒漠化综合治理技术”等。
④生态治理技术名称描述中可能包含触发词汇
文本中会出现“技术”、“措施”、“工程”等后缀,以及“实施”、“开展”、“采用”等左边界词,用于指示文本中的技术名称。
⑤生态治理技术名称的指代和省略现象
技术名称可能在上下文中以指代形式出现,如“此次治理过程中,……”中的“此次”、“该技术……”中的“该技术”等。
⑥生态治理技术名称缺失现象
部分技术,人们通常以触发词汇与退化类型或技术类型进行描述,而没有具体、完整的技术名称,特别是一些技术大类,或者不明确的技术,如“植物措施”、“化学措施”等。
生态治理技术的分类讨论,可以按照治理的退化生态系统类型或退化原因分类,也可以按照治理技术类型分类,还可以按照治理技术的生物和非生物类型分类。
(2)生态治理技术名称知识库和规则库
表3 生态治理技术名称常用词及其触发词举例
Table 3
| 触发词类型 | 举例 |
|---|---|
| 左边界词 | 实施;设置;计划;开展;采用;治理;营造;种植;发展…… |
| 右边界词 | 技术;模式;体系;方案;措施;工程;治理;修复;方法;XX法;组合;结合;改良;利用…… |
| 技术类别 | 植物措施/方法/技术/模式、动物措施、微生物措施、农业措施、工程措施、化学措施、物理措施、管理措施…… |
| 触发词 | 沙障;沙墙;沙沟;栅栏;阻沙、草方格;固沙;防护林;混交;粘合剂;固沙剂;喷播;补播;草膜;补种;封禁;梯田;造林;流沙固定;防沙治沙;水土保持;农林复合经营;节水集水;沙产业;可再生能源利用…… |
| 技术名称 | 草方格沙障;高立式活沙障;飞播治沙技术;铁路防沙治沙技术;划区轮牧;鱼鳞坑状反坡整地;黄土梯田;旱地农田防护林;造林模式;绿洲农林间作;绿洲农田防护林;农田林网化;砂田技术;盐碱地改造;林草复合法;乔灌混交;改变种植作物;草田轮作;机械阻沙:设置挡沙墙、截沙沟、阻沙栅栏、防沙网;沙障固沙:草方格沙障固沙、黏土沙障、砾石沙障、沙袋沙障…… |
表4 生态治理技术抽取规则样例
Table 4
| 技术名称类型 | 技术名称子类型及表达模式 | 样例 |
|---|---|---|
| 辅助技术名称识别相关词表 | 左边界词(LeftWord) | 实施、开展、采用… |
| 右边界词(RightWord) | 技术、措施、工程… | |
| 土壤类型(Agrotype) | 沙地、草甸土… | |
| 生态系统/生态区(ECO) | 黄土高原、高寒草甸… | |
| 生态退化类型(EcoDegType) | 荒漠化、石漠化…… | |
| 简单技术名称 | 触发词(TriggerWords) | 沙障、防护林、固沙剂… |
| 技术类别(TCategory) | 生物措施、工程措施… | |
| 包含其他实体的技术名称 | 包含地名(Place)和土壤类型(Agrotype) 表达模式:( LeftWord ) + Place + ( Agrotype )+ TriggerWords + ( RightWord ) | 柴达木沙地杨树深栽造林 |
| 包含生态系统类型/生态区(ECO) 表达模式:ECO + TriggerWords + (RightWord) | 绿洲农林间作 黄土高原梯田技术 | |
| 包含生态退化类型 表达模式:(EcoDegType);EcoDegType + (TriggerWords) + RightWord | 荒漠化综合治理技术 冻融荒漠化防治 | |
| 技术名称短语 | LeftWord + TriggerWords + ( RightWord ) TriggerWords + RightWord TCategory + RightWord | 设置生物围栏;采用乔灌混交技术 草方格沙障技术;林草复合法 植物/农业/工程措施 |
(注:表达模式中符号()表示其中的内容可以出现也可以不出现。)
(3)时间实体抽取研究
汉语中的时间信息研究中需要分析时间要素、时间词语构成形式等。根据中文文本中时间表达形式的规律性,形成时间实体抽取的规则。
①基本元素
在精确时间中,表达式“2017年9月10日上午9时30分”可以分解为[2017年][9月][10日][上午][9时][30分]独立的时间元素进行的组合,上下文跨度小。
②时间触发词
时间信息的出现通常与表达时间单位的触发词相结合,如“2017年9月10日上午9时30分”的“年”、“月”、“日”、“时”、“分”等。
③省略现象
在时间表述过程中,出于表达的简洁或连贯性需要,常出现省略现象,因此很多时间的描述可能不完整,如“9月10日”等,没有出现年份。
④随意性和模糊性
在描述时间信息的过程中,人们经常使用相对时间或未指明具体时间长度的段时间来表示时间。如,过去、现在、将来;季度;周末;上午、晚上等。
⑤相同时间的不同表示
相同的时间可能存在不同的时间层次或不同的表示方法,如阳历和阴历对同一天的表示完全不同;“2017年12月25日”、“2017-12-25”、“2017/12/25”与“2017年圣诞节”表示同一天等。
⑤无显性触发词
这类时间信息主要是事件类时间,即通过事件发生或语义内容反映时间。如,“实施治理之后…”等描述中没有显性时间触发词,但表达了时序关系。
(4)地名实体抽取研究
地名实体的研究主要侧重于两个方面:一是文本中地名实体的识别(Geo-Parsing),二是将识别的地名实体映射为地图上的坐标,即地理编码过程(Geo-Coding)。总结中文文本中地名信息的抽取规则,部分规则样例如表5所示。
表5 地名实体抽取规则样例
Table 5
| 地名实体类型 | 地名实体子类型 | 地名实体表达模式 | 样例 |
|---|---|---|---|
| 单独出现的地名实体 | 无通名用字的地名(Place) | Place | 中国、山东、青海…… |
| 地名实体简称(PlaceAbb) | PlaceAbb | 京、津、冀…… | |
| 地名实体别名(PlaceAli) | PlaceAli | 燕京、大都、首都、宝岛、六朝古都…… | |
| 辅助地名识别相关词表 | 左边界词(LeftWord) | - | 位于、流经、抵达…… |
| 右边界词(RightWord) | - | 南部、西岸、境内…… | |
| 通名用字(GeneralWord) | - | 省、市、县、地区、高原、平原、流域…… | |
| 复合地名短语 | 后缀式地名 | Place + GeneralWord Place + RightWord | 西北地区、兰州市南部 |
| 组合式地名 | n × [ Place + (GeneralWord) || PlaceAbb || PlaceAli] | 甘肃省兰州市东岗路、 中国甘肃兰州 | |
| 并列式地名 | n × [ [PlaceAbb || PlaceAli || Place + (GeneralWord) ] + “-”或“、”或“<”或“>”或“和”或“与”+ [PlaceAbb || PlaceAli || Place + (GeneralWord) ] ] | 银川-环县-西安、陕>宁>青>甘>新 | |
| 地名介词短语 | LeftWord + Place + GeneralWord LeftWord + Place + ( GeneralWord ) + RightWord LeftWord + [ PlaceAbb || PlaceAli ] | 途径兰州市、抵达兰州市境内、位于六朝古都 | |
(注:表达模式中符号()表示其中的内容可以出现也可以不出现;符号“||”表示“或”等。)
4.3 实验过程
(1) 语料预处理
将文献利用PDFBox①(①
①标注文本:本研究使用的分类及标注方法如表6所示。
表6 实体分类及标注体系
Table 6
| 符号 | 含义 | 符号 | 含义 |
|---|---|---|---|
| O | 非实体 | I-Place | 地名中间 |
| B-Time | 时间开头 | B-Tech | 技术开头 |
| I-Time | 时间中间 | I-Tech | 技术中间 |
| B-Place | 地名开头 |
在对语料进行处理后的文本格式中,第一列为文本中的词语,第二列是该词的词性,第三列表示的是该词在句子中代表的实体,以IOB2标注的实例如表7所示。
表7 实体标注举例
Table 7
| 文本中词语 | 词性 | IOB2标注 |
|---|---|---|
| 在 | p | O |
| 毛乌素 | ns | B-Place |
| 沙地 | n | I-Place |
| 应 | v | O |
| 推行 | v | O |
| 灌草 | nw | B-Tech |
| 乔 | nr | I-Tech |
| 相结合 | nz | I-Tech |
| 以 | p | O |
| …… | …… | …… |
②词向量:本研究使用大规模无标注语料训练得到的词向量,替换神经网络模型的初始词向量,使神经网络模型在初始阶段就能够应用词向量中已包含的丰富信息,以提高模型的性能。使用谷歌开源的词向量工具Word2Vec①(①
为比较未标注语料对Word2Vec训练的效果,将上述题录信息语料和实体知识库语料组合成两个未标注集合,模型选择CBOW,词向量的维度设为100维,上下文窗口大小为5,采样的阈值1e-3,开始的Learning Rate为0.025。
(2) 后处理阶段
将预测语料进行文本预处理与清洗,通过分词等将文本整理为已构建模型适用的格式,预测语料输入Bi-LSTM+CRF模型,经过模型输出识别结果,对识别结果进行获取和后处理。
三类实体内容的获取过程如下:
①已训练Bi-LSTM+CRF模型对测试数据进行识别,提取识别后的分类标签,并将相应的标签转化为相应的实体字符串,作为候选实体。
②根据候选实体在文本中的位置确定不同实体之间的关系。
Word2Vec词向量训练过程得到10 976个词的100维词向量,将获得的词向量传给双向的LSTM层,训练模型。其中dev_size表示验证/开发集占训练集的比例(本文中为0.25);Bi-LSTM单元数设为256;激活函数采用Tanh函数。模型参数如表8所示。
表8 Bi-LSTM神经网络模型实验参数
Table 8
| 参数 | 设置 |
|---|---|
| 词向量 | 100维,Word2Vec分布式向量 |
| Bi-LSTM单元数 | Num_Units: 256 |
| 学习率 | Learning_Rate: 0.002 |
| 梯度裁剪 | Clip: 10 |
| Dropout | Dropout_Rate: 0.5;L2_Rate: 0.01(加在全连接层权重上) |
| 句子最大长度 | Sequence_Length(Preprocessing.py输出结果中有句子分布) |
| 迭代次数 | Nb_Epoch: 200(可提前终止) |
| dev_size | 0.25 |
基于Bi-LSTM+CRF的命名实体识别模型训练过程算法如下。
1. 对每次循环有:
2. 对每次循环有:
3. ①Bi-LSTM+CRF模型前向传递:
4. 前—LSTM单元状态信息向前传递
5. 后—LSTM单元状态信息向前传递
6. ②CRF层前向后向传递
7. ③Bi-LSTM+CRF模型向后传递:
8. 前—LSTM单元状态信息向后传递
9. 后—LSTM单元状态信息向后传递
10. ④更新参数
11. 结束循环
12. 结束循环
本研究模型构建的思路主要是融合已有研究显示效果较好的策略,同时进一步提供质量更高的Word2Vec词向量,以及更加精准的训练语料。因此,模型构建待解决的关键问题是:探索质量更高的Word2Vec词向量,使用其替换模型随机初始的词向量;模型的各种个性化需求(实验数据与分类标签映射、网络的层数和单元数等);Bi-LSTM+CRF模型结构中的参数设置和激活函数的选择。
在方法上的改进:
1)本研究构建了一种基于Bi-LSTM+CRF的神经网络模型,包括如下步骤:使用Word2Vec获得初始词向量;将词向量输入传到双向LSTM神经网络对每个词的上下文信息进行建模;在Bi-LSTM神经网络的输出端,利用连续的条件随机场对句子进行标签解码,并标注句子中的实体。相较于传统的机器学习方法,此方案基于统计概率学,并能够利用词汇上下文依赖关系,应用场景更广泛。
2)优化Word2Vec初始词向量。初始词向量是神经网络模型的重要输入,而词向量的效果与语料的领域和规模密切相关。
5 结果及讨论
5.1 不同要素与组合的实验结果
对比使用不同词向量和训练语料要素所产生的实验结果,以研究命名实体抽取中不同要素对模型性能的影响,结果如表9所示。
表9 不同要素组合的实验结果
Table 9
| 序号 | 输入特征 | P(%) | R(%) | F1(%) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Time | Place | Tech | Time | Place | Tech | Time | Place | Tech | ||
| ① | Baseline | 62.66 | 21.69 | 32.22 | ||||||
| 61.85 | 61.88 | 66.10 | 30.31 | 35.40 | 8.89 | 40.68 | 45.04 | 15.68 | ||
| ② | w2v-1 | 70.23 | 56.19 | 62.43 | ||||||
| 79.79 | 75.12 | 63.84 | 66.01 | 52.18 | 54.96 | 72.25 | 61.58 | 59.07 | ||
| ③ | w2v-2 | 70.99 | 56.41 | 62.86 | ||||||
| 79.14 | 72.05 | 67.26 | 62.32 | 53.19 | 56.21 | 69.73 | 61.20 | 61.24 | ||
| ④ | w2v-2 + MoreData | 73.10 | 59.94 | 65.87 | ||||||
| 74.16 | 75.82 | 65.04 | 67.06 | 63.10 | 53.78 | 70.43 | 68.88 | 58.04 | ||
| ⑤ | w2v-2 +MoreData+ dictionaries | 74.34 | 64.04 | 68.81 | ||||||
| 78.63 | 82.02 | 66.02 | 72.20 | 65.71 | 58.75 | 75.27 | 72.97 | 62.17 | ||
(注:①基准方法(Baseline):随机初始词向量;②Word2Vec词向量-1(w2v-1):未标注文本集合1投入Word2Vec得到的词向量;③Word2Vec词向量-2(w2v-2):未标注文本集合2投入Word2Vec得到的词向量;选择其中较好的词向量结果,作为后续的改进的基准;④词向量+扩大训练语料(不同规模);⑤词向量+扩大训练语料+高质量词典。)
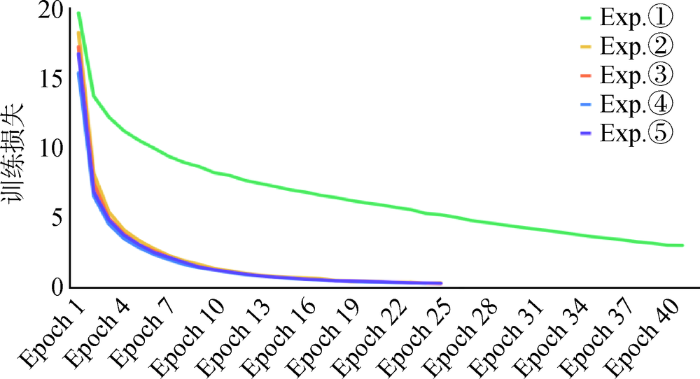
(1) 模型的训练损失变化
Bi-LSTM+CRF在模型训练过程中,5次实验中训练损失的变化如图3所示,呈逐步下降趋势,随着模型在开发集上的表现不再有提升,损失逐步趋于平稳,训练终止。实验1的训练损失整体明显大于后4次实验,因而一个与训练语料相关的初始词向量很重要。
图3
(2) Word2Vec未标注训练语料的影响
相较于随机初始化词向量,未标注文本集合1训练得到的词向量获得较好的效果,P、R、F1分别提升7.57%、34.50%、30.21%。未标注文本集合2训练得到的词向量在未标注文本集合1得到词向量基础上P、R、F1又分别提高0.76%、0.22%、0.43%,两个文本集合都与抽取的领域内容高度相关,但集合2的体量更大。来斯惟[20]认为训练词向量首先需要选择一个与任务相匹配语料,本研究在其此基础上增加了相关语料的数量。实验证明,对于确定类型的语料,语料规模越大,词向量的性能越好。作为神经网络的关键输入信息,一个好的词向量很重要。
(3) 扩大训练语料的影响
表10 训练语料与增加训练语料中的实体数量
Table 10
| 语料 | 实体数量 | 时间实体数量 | 地名实体数量 | 生态治理技术名称数量 |
|---|---|---|---|---|
| 训练集 | 39 739 | 7 965 | 17 599 | 14 175 |
| 验证/开发集 | 14 037 | 2 481 | 6 757 | 4 799 |
| 增加的训练语料 | 35 843 | 6 965 | 16 240 | 12 638 |
| 增加实体词典 | 7 703 | 547 | 6 693 | 463 |
以每6 000个实体为一个节点,递增进行模型的训练,观察语料的增加对系统性能的影响。训练语料增加对准确率P和F1值的影响如图4所示。
图4
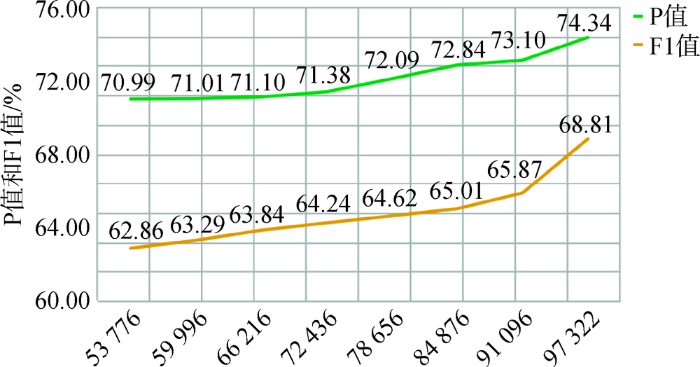
图4
训练语料增加对P和F1的影响
Fig.4
The Influence of Increasing Training Corpus on P and F1
从上述结果可知,相对于原始训练语料提供的53 776个实体而言,增加43 546个实体后,准确率P值提升3.35%,F1值提升5.95%。曲线趋势稳定上升,并未达到平滑,训练语料的数量增加依然还有进一步上升的空间。
5.2 与CRF方法的结果对比
为验证Bi-LSTM+CRF模型学习效果,同时采用CRF++①(
表11 Bi-LSTM+CRF结果与单独CRF结果对比
Table 11
| 研究方法 | 模型 | P(%) | R(%) | F1(%) |
|---|---|---|---|---|
| 传统机器学习 | 单独CRF方法 | 64.93 | 64.17 | 64.55 |
| 深度学习 | Bi-LSTM+CRF | 74.34 | 64.04 | 68.81 |
本研究中使用的Bi-LSTM+CRF神经网络模型方法比单独使用CRF方法获得更好的P值和F1值,而R值相对稍弱,但差距不大。本研究优势和局限性如下:
(1) 优 势
①采用语义相关度较高、体量较大的未标注语料,投入Word2Vec训练,获得效果更好的词向量,在源头上保证了模型输入词向量的优质性。②较大量新增的训练语料。在使用新增语料进行训练后,F1值从62.86%提升至68.81%,P值从70.99%提升至74.34%,说明训练语料的增加对系统性能影响显著。
(2) 局限性
①未融合先验知识。只利用了部分实体词典,大量的资源和先验知识(如人工选取的特征)未被利用,将其与深度学习模型结合能极大推动深度学习的效果。②未使用句法信息。③本研究的结果一定程度上依赖于分词软件的效果。
6 结 语
6.1 本研究的主要工作和贡献
(1)设计并实现了基于Bi-LSTM+CRF神经网络模型抽取中文文献中时间、地名和生态治理技术的方法,并进行了实验。
(2)提出并验证了优化的词向量对改进模型的效果。相关领域语料训练的词向量,训练语料规模越大,词向量的性能越好。加入知识资源的模型训练语料,训练语料规模越大,命名实体识别模型性能越好。
6.2 未来的技术方向和应用前景
本研究所采用的方法抽取出文本中生态治理技术名称、生态治理技术的实施时间等内容,将其结构化存储后进行关联分析,有利于把握生态治理技术发展演化的脉络和特征,这将对生态治理技术领域的情报分析工作有重要意义。
作者贡献声明
马建霞:提出研究思路,设计研究方案,论文修改和定稿;
袁慧:进行实验,撰写论文初稿;
蒋翔:完成部分语料标注、负责后期基于字嵌入的命名实体抽取实验。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据
支撑数据由作者自存储, E-mail: tanglin@dlut.edu.cn。
支撑数据由作者自存储,E-mail:majx@lzb.ac.cn。
[1]马建霞,袁慧,蒋翔. 634篇论文全文.rar. 脆弱生态治理领域634篇论文.
[2]马建霞,袁慧,蒋翔. 经过Bi-LSTM+CRF识别的语料.txt. 经过Bi-LSTM+CRF识别的语料.
[3]马建霞,袁慧,蒋翔. 生态治理技术相关命名实体抽取程序.rar. 生态治理技术相关命名实体抽取程序.
参考文献
生态技术评价方法及全球生态治理技术研究
[J].
The Methodology for Assessing Ecological Restoration Technologies and Evaluation of Global Ecosystem Rehabilitation Technologies
[J].
Deep Learning with Word Embeddings Improves Biomedical Named Entity Recognition
[J].
Cross-Type Biomedical Named Entity Recognition with Deep Multi-Task Learning
[J].
CollaboNet: Collaboration of Deep Neural Networks for Biomedical Named Entity Recognition
[J].
Bidirectional LSTM-CRF Models for Sequence Tagging
[OL].
Fast and Accurate Entity Recognition with Iterated Dilated Convolutions
[OL].
基于BiLSTM-CRF模型的食品安全事件词性自动标注研究
[J].
Part-of-Speech Automated Annotation of Food Safety Events Based on BiLSTM-CRF
[J].
Automatic Extraction of Gene-disease Associations from Literature Using Joint Ensemble Learning
[J].
Neural Domain Adaptation for Biomedical Question Answering
[OL].
Cross-Type Biomedical Named Entity Recognition with Deep Multi-Task Learning
[J].
Understanding the Topic Evolution of Scientific Literatures like an Evolving City: Using Google Word2Vec Model and Spatial Autocorrelation Analysis
[J].
Information Extraction and Knowledge Graph Construction from Geoscience Literature
[J].
The Paleobiology Database Application Programming Interface
[J].
A Machine Reading System for Assembling Synthetic Paleontological Databases
[J].
GeoDocA - Fast Analysis of Geological Content in Mineral Exploration Reports: A Text Mining Approach
[J].
Geoscience Keyphrase Extraction Algorithm Using Enhanced Word Embedding
[J].
Distributed Representations of Words and Phrases and Their Compositionality
[C]//
基于神经网络的词和文档语义向量表示方法研究
[D].
Word and Document Embeddings based on Neural Network Approaches[D]. Beijing: Institute of Automation,
Deep Contextualized Word Representations
[OL].
Bert: Pre-training of Deep Bidirectional Transformers for Language Understanding
[OL].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}