




1 引言
随着人们生活水平的逐渐提高,越来越多的人喜欢旅游并通过旅游游记分享旅游体验。旅游游记含有丰富的经济型资源,景点是旅游过程中重要的组成部分,对景点的识别效率将直接影响旅游游记信息抽取的效果。对类似旅游游记的海量非结构化文本数据进行管理和挖掘对旅游领域问答系统、舆情分析、个性化推荐等研究具有重要意义。本文旨在利用知识迁移的方法解决旅游领域内景点实体识别中的标注数据难以获取的问题。
2 研究现状
命名实体识别(Named Entity Recognition, NER)一词在1996年的MUC-6会议上首次提出[1]。现有的命名实体识别方法主要分为基于规则和词典、基于机器学习、基于深度学习的方法。
(1)基于规则和词典[2]的实体识别方法主要依赖语言学家根据上下文语义结构归纳的模板,在词典中查找所存在的最长的命名实体。该方法移植性较差,识别效果不明显,且归纳过程代价较大。
综上,目前针对命名实体识别主要存在以下问题:
(1)实体不同语境下的不同含义问题在文本特征表示时得不到解决。
(2)对于特定的领域,没有文本规范格式。实体数量过多,无法枚举,在人工构建特征模板时耗时耗力。使用深度学习方法需要人工标注数据,且模型严重依赖标注数据的质量,标注数据难以获取。
针对问题(1),在现有研究基础上,本文构建一种改进的BERT+BiLSTM+CRF(简称BBC)深度学习实体识别模型;针对问题(2),本文研究一种AttTrBBC迁移学习算法,根据旅游领域景点与《人民日报》标注语料中的相似性,利用知识迁移的方法,将辅助领域中有效数据扩展到目标领域训练集中。
3 研究思路与框架
3.1 改进的融合BERT的BiLSTM+CRF方法
为解决实体识别过程中一词多义问题,本文提出改进的融合BERT[12]的BiLSTM+CRF[4]模型,整体模型如图1所示。首先使用BERT模型获取字向量,提取文本重要特征;然后通过BiLSTM[13]深度学习上下文特征信息,进行命名实体识别;最后CRF[14]层对BiLSTM的输出序列进行处理,结合CRF中的状态转移矩阵,根据相邻之间标签得到全局最优序列。BERT是一种预训练语言表征模型,能够计算词语之间的相互关系,并利用所计算的关系调节权重提取文本中的重要特征。使用自注意力机制的结构进行预训练,基于所有层融合左右两侧语境以预训练深度双向表征,能捕捉到真正意义的上下文信息,并能够学习到连续文本片段之间的关系。在文本特征提取时,能解决一词多义问题,因此本文将BERT模型引入到命名实体识别任务中。
图1

3.2 改进的知识迁移实体识别方法
(1) 迁移学习
迁移学习[15](Transfer Learning)是通过减小已有知识和新知识之间的分布差异,以此运用已有知识学习新的知识,可以通过减小辅助领域和目标领域的分布差异,利用相关领域有标定的数据完成对未知数据的标注。本文将迁移学习思想与BBC模型结合,提出一种改进的知识迁移实体识别算法AttTrBBC,主要改进是在知识迁移的基础上,针对旅游领域文本特点,提出使用关键词重要性、句子级别相似性和样本可扩展性三种方法评估辅助样本和目标样本的相似性,增强扩展过程中的严谨性,确保不会产生负迁移。
(2) 余弦相似性
本文用sim表示余弦相似性。余弦相似性用于计算句子的相似度和词语之间的相似性[16]。L和M可以表示两句子的n维句子向量,也可以表示两个n维的词向量,设
sim取值一般为(-1,1),值越大,则两个句子的相似性越大。
3.3 改进的知识迁移实体识别设计
旅游领域文本表示不规范。辅助领域文本为规范标注的数据,因此迁移的难点在于如何评估辅助领域到目标领域的相似性,保证特征提取和知识迁移的过程中,将辅助领域中尽可能多的关于目标领域的语义信息扩展但不产生负迁移。对此,本文针对旅游领域文本特点,提出关键词重要性、句子级别相似性、样本可扩展性三种不同的计算方式评估样本的好坏,以此评估辅助领域与目标领域的相似度。
(1) 关键词重要性
借鉴TF-IDF[17],本文提出关键词频率(Keyword Frequency,KF)和句子频率(Sentence Frequency,SF)的概念。KF表示样本句子中某个关键词的出现频率,KFi,j表示关键词i在句子j中的出现频率,计算方法如公式(2)所示。
其中,
SF表示句子频率,ISF(Inverse Sentence Frequency)表示反句子频率,计算方法如公式(3)所示。
其中,
某个词语i在句子j中的重要程度如公式(4)所示。
(2) 句子级别相似性
句子级别相似性计算方法如公式(5)所示。
(3) 样本可扩展性
样本可扩展性(Sample Extension Ability,SEA)计算方法如公式(6)所示。
其中
3.4 算法设计
AttTrBBC算法采用基于特征的知识迁移的思想改进BBC识别方法,设计流程如图2所示。其中,
图2
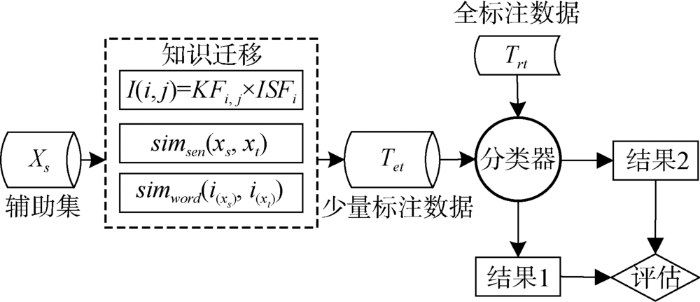
AttTrBBC算法描述如下:
输入:Xs,Xt,Tet,BBC分类模型,相似度阈值m,目标领域少量标注数据占总扩展集的比例μ;
输出:实体识别结果和扩展后的数据集。
①Xt=Tet,对Xs和Xt预处理,初始化m,μ;
②训练语言模型,对
③
④对
⑤从v(xs)和v(xt)分别获取i(xs)和i(xt)对应的词向量vi(xs)和vi(xt);
⑥根据公式(1)对vi(xs)和vi(xt)计算simword(vi(xs),vi(xt));
⑦
⑧对扩展后的Tet训练新的分类器
⑨对Tet使用BBC分类器预测,得到识别结果;
⑩更新m值重复步骤③-步骤⑨,返回
⑪根据分类器模型识别效果选取合适的m值,当
4 实验过程
4.1 数据源
(1) 目标领域数据库
使用Python中的Beautiful Soup对马蜂窝等互联网旅游网站上的游记文章进行网页解析处理,获取2010年至2017年的一万余篇游记文章。游记文本为高度非结构化数据,包含错别字、语法错误、新流行的网络用语以及一些无用的URL信息等,需要首先进行预处理。预处理的过程是:将数据解析成TXT文件;通过正则表达式去除无用的网址、特殊的标点符号(‘ 
(2) 辅助领域数据集
景点属于地名的一种,因此本文辅助领域中的数据选取《人民日报》公开数据——由北京大学计算机语言学研究所制作的现代汉语多级加工语料库[18],共有2 022万余字的实体标注,通过交叉验证的方法选取其中1 000万条标注语料作为实验训练数据,22万条数据作为测试数据。
(3) 数据特点分析
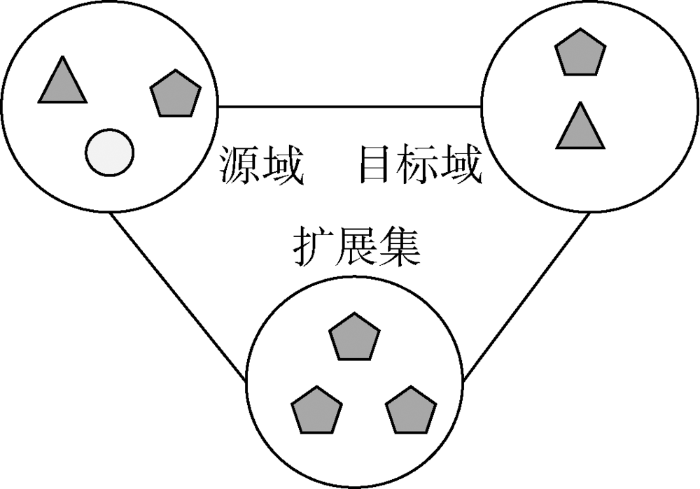
源域、目标域中的数据能共享共同的特征,如图3所示。源域中标准化标注了地名、人名、机构名等。目标域中的景点是地名的一种,针对这一相似性,对源域进行特征提取,不断筛选出与目标域相似度高的数据,进行训练和学习,得到扩展后的目标领域训练集,以解决目标领域的标注数据难于获取的问题。
图3
4.2 实验设计
本文基于TensorFlow构建实验模型。训练集batch_size为32,验证集和测试集batch_siz为8,dropout rate为0.5,为了搜索最佳学习率,采用warm up学习率,learning rate初始值为0.001,设置Gradient Clipping为0.5裁剪梯度,控制有效权重。实验评估采用MUC[1]评测会议上提出的评价指标:准确率P、召回率R和F1值。
(1) 融合BERT的BiLSTM+CRF方法
表3 模型分层验证
Table 3
| 方法 | P | R | F1 |
|---|---|---|---|
| CRF | 86.67% | 87.84% | 87.25% |
| BiLSTM | 93.25% | 87.98% | 90.53% |
| BiLSTM+CRF | 94.97% | 92.10% | 93.52% |
| BBC | 96.79% | 96.85% | 96.74% |
由表3可知,和其他模型相比,本文提出的BBC模型性能有一定程度的提升。单层BiLSTM不能考虑标签序列顺序性,会将一个完整的实体(如“北京动物园”)拆分成“北京”和“动物园”。去掉BERT层,在特征表示时不能考虑一词多义问题(如“北京海洋馆”)中的“海洋”在不同语境下可以指人名也可以指地名,这会影响实验结果。综上,BBC模型识别结果相比其他三组单层模型高。
为了验证AttTrBBC算法中关键词重要性、句子级别相似度、样本可扩展性三种阈值设置对算法有效性的影响,分别设计了实验(2)-实验(4);同时为了研究AttTrBBC算法对少量目标训练集不同大小的依赖程度,设计实验(5)。
(2) 关键词重要性阈值选取
针对关键词重要性i值的实验设置主要目的是探究算法AttTrBBC中,关键词重要性阈值对迁移效果的影响,分别设置5组不同的相似度阈值,目标领域标注数据大小设置为1/5,实验结果如表4所示。可知,在关键词重要性阈值设置为0.55时,P值最高,设置为0.45时R值和F值最高。
表4 不同i值的实验结果
Table 4
| i | P | R | F1 |
|---|---|---|---|
| 0.40 | 84.64% | 64.01% | 72.89% |
| 0.45 | 87.26% | 69.28% | 77.24% |
| 0.50 | 90.93% | 53.85% | 67.64% |
| 0.55 | 93.14% | 55.42% | 69.49% |
| 0.60 | 91.41% | 55.74% | 69.25% |
(3) 句子级别相似度阈值选取
针对不同的simsen阈值范围对AttTrBBC算法进行对比实验,根据关键词重要性实验结果,设置关键词重要性阈值为0.55,目标领域标注数据大小设置为1/5,实验结果如表5所示。实验结果表明,在同一个数据集上,AttTrBBC算法得到的扩展集在句子级别相似度阈值设置为0.50时,效果最佳。
表5 不同simsen值的实验结果
Table 5
| simsen | P | R | F1 |
|---|---|---|---|
| 0.40 | 89.01% | 56.07% | 68.80% |
| 0.45 | 91.30% | 57.79% | 70.78% |
| 0.50 | 92.05% | 58.16% | 71.28% |
| 0.55 | 91.03% | 55.99% | 69.33% |
| 0.60 | 90.81% | 56.50% | 69.66% |
(4) 样本可扩展性阈值选取
研究不同的SEA阈值选取对实验结果的影响,分别设置5组对比实验,该实验设置关键词重要性阈值为0.55,句子级别相似度阈值为0.50,目标领域标注数据大小设置为1/5,实验结果如表6所示。实验设置不同的样本可扩展性阈值对实验结果有一定程度的影响,综合考虑P、R和F1三个评价指标,设置SEA阈值为0.50时,识别结果最佳。
表6 不同SEA的实验结果
Table 6
| SEA | P | R | F1 |
|---|---|---|---|
| 0.40 | 87.26% | 79.28% | 83.07% |
| 0.45 | 90.93% | 83.85% | 87.24% |
| 0.50 | 93.14% | 85.42% | 89.11% |
| 0.55 | 91.41% | 85.74% | 88.48% |
| 0.60 | 90.81% | 83.50% | 87.00% |
(5) 目标域标注数据大小
为了验证少量目标领域标注数据集的大小对算法有效性的影响,分别设置4组不同的
表7
不同
Table 7
| P | R | F1 | |
|---|---|---|---|
| 1/5 | 93.14% | 85.42% | 89.11% |
| 1/4 | 95.06% | 82.12% | 88.12% |
| 1/3 | 97.91% | 89.15% | 93.30% |
| 1/2 | 98.41% | 88.09% | 92.97% |
可知,目标领域少量标注数据集在扩展集中对实验结果影响较大。仅使用1/5的目标领域标注数据集时,识别结果超过90%,说明该算法在不影响识别结果的前提下,大大减少了人工标注数据所花费的时间和精力。
5 实验结果
将3.1节的BBC分类器使用全标注数据训练模型并与改进的知识迁移景点实体识别算法(使用少量标注数据)进行对比,结果如表8所示。可知,改进的算法在使用1/4的标注数据与全标注实验结果在P值上相差1.73%。此外,使用1/2的标注数据的识别准确率要高于使用全部标注数据的模型1.62%。观察两种结果可知,使用全标注的实验主要存在半自动化标注过程中的实体标注错误。这说明原始训练集中已经存在错误的标注数据,导致在识别过程中准确率下降。而本文算法利用公开的《人民日报》数据通过知识迁移的思想解决了这一问题。
表8 全部标注与少量标注对比实验
Table 8
| 模型 | P | R | F1 | |
|---|---|---|---|---|
| BBC | 1 | 96.79% | 96.85% | 96.74% |
| 1/5 | 93.14% | 85.42% | 89.11% | |
| AttTrBBC | 1/4 | 95.06% | 82.12% | 88.12% |
| 1/3 | 97.91% | 89.15% | 93.30% | |
| 1/2 | 98.41% | 88.09% | 92.97% |
表9 工作对比分析
Table 9
6 结语
为解决旅游领域内景点实体中特征表示的一词多义问题,本文构建了改进的BiLSTM+CRF的中文命名实体识别模型;为了解决旅游领域标注数据难以获取的问题,提出一种改进的基于迁移学习思想的AttTrBBC算法。对于旅游领域目标训练集,将已有的辅助领域数据按照关键词重要性、句子级别相似性、样本可扩展性三个级别的评估扩展目标领域的训练集数据。实验表明,AttTrBBC算法在仅需要少量的标注数据下就能得到文本中重要的语义,准确率相比使用全部标注数据的模型有所提高。对旅游领域信息抽取的研究具有一定的意义,为自动化旅游路线推荐提供了技术支持。
未来研究将考虑对可扩展性融合多种特征,提高扩展后样本集的质量,提高召回率。并进一步根据游记中的景点实体以及游记内容通过分类器过滤用户仅提及而未真实前往的景点,生成一级节点(市一级景点)和二级节点,二级节点生成二级线路,最终开发出根据游记文字自动识别景点和旅游路线的自动推荐平台。
作者贡献声明
赵平,孙连英:提出研究思路,设计研究方案;
赵平:进行实验,采集、清洗和分析数据,起草论文;
赵平,万莹,孙连英,卞建玲,涂帅:论文最终版本修订。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据
支撑数据由作者自存储,E-mail: 932678068@qq.com。
[1] 赵平.游记文章.zip.原始游记文章.
[2] 赵平.f_src_train.txt.辅助训练集f_src_test.txt辅助测试集.
[3] 赵平.f_tag_train.txt.少量目标训练集f_tag_test.txt目标测试集.
[4] 赵平.T_L_DATA.zip.实验数据.
[5] 赵平.output.zip.实验模型、预测结果、实验过程数据等.
[6] 赵平.model_layer.csv.模型分层验证.
[7] 赵平.sim_word.csv.不同
[8] 赵平.sim_sen.csv.不同
[9] 赵平.sea.csv.不同
[10] 赵平.u.csv.不同
[11] 赵平.Partial_label.csv.全部标注与少量标注对比实验.
参考文献
Message Understanding Conference-6:A Brief History
[C]//
ProMiner: Rule-based Protein and Gene Entity Recognition
[J].
Neural Architectures for Named Entity Recognition
[C]//
Character-based LSTM-CRF with Radical-level Features for Chinese Named Entity Recognition
[C]//
HMM Based Named Entity Recognition for Inflectional Language
[C]//
基于HMM的中文旅游景点的识别
[J].
Recognition of HMM-Based Chinese Tourist Attractions
[J].
基于层叠条件随机场的旅游领域命名实体识别
[J].
Named Entity Recognition for the Tourism Domain Based on Cascaded Conditional Random Fields
[J].
Named Entity Recognition with Bidirectional LSTM-CNNs
[J].
结合主动学习的条件随机场模型用于法律术语的自动识别
[J].
Automatic Recognizing Legal Terminologies with Active Learning and Conditional Random Field Model
[J].
Marginal Likelihood Training of BiLSTM-CRF for Biomedical Named Entity Recognition from Disjoint Label Sets
[C]//
基于卷积神经网络的中文景点识别研究
[J/OL].
Research on Chinese Scenic Spot Named Entity Recognition Based on Convolutional Neural Network
[J/OL].
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
[C]//
Long Short-Term Memory
[J].
An Introduction to Conditional Random Fields
[J].
TL-NER: A Transfer Learning Model for Chinese Named Entity Recognition
[J].
A Survey of Text Similarity Approaches
[J].
A Comparative Study of TF*IDF, LSI and Multi-Words for Text Classification
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}